Questo documento nella sezione Framework dell'architettura Google Cloud: affidabilità fornisce dettagli sugli avvisi relativi agli SLO.
Un approccio errato all'introduzione di un nuovo sistema di osservabilità come gli SLO è utilizzare il sistema per sostituire completamente un sistema precedente. Piuttosto, dovresti considerare gli SLO come un sistema complementare. Ad esempio, anziché eliminare gli avvisi esistenti, ti consigliamo di eseguirli in parallelo con gli avvisi SLO introdotti qui. Questo approccio ti consente di scoprire quali avvisi precedenti sono predittivi degli avvisi SLO, quali avvisi vengono attivati in parallelo con gli avvisi SLO e quali avvisi non vengono mai attivati.
Uno dei principi dell'SRE è generare avvisi in base ai sintomi, non alle cause. Per loro stessa natura, gli SLO sono misurazioni dei sintomi. Quando adotti gli avvisi SLO, potresti scoprire che l'avviso relativo ai sintomi viene attivato insieme ad altri avvisi. Se scopri che gli avvisi precedenti basati su cause vengono attivati senza SLO o sintomi, questi sono buoni candidati per essere disattivati del tutto, trasformati in avvisi relativi ai ticket o registrati per riferimento futuro.
Per ulteriori informazioni, consulta SRE Workbook, Capitolo 5.
Burn rate SLO
La burn rate di uno SLO è una misura della rapidità con cui un'interruzione espone gli utenti a errori e esaurisce il budget di errore. Misurando la burn rate, puoi determinare il tempo che intercorre prima che un servizio violi il proprio SLO. La generazione di avvisi in base alla velocità di consumo SLO è un approccio utile. Ricorda che lo SLO si basa su una durata, che può essere piuttosto lunga (settimane o addirittura mesi). Tuttavia, l'obiettivo è rilevare rapidamente una condizione che comporta una violazione dello SLO prima che si verifichi effettivamente.
La tabella seguente mostra il tempo necessario per superare un obiettivo se il 100% delle richieste non va a buon fine per l'intervallo specificato, supponendo che il numero di query al secondo (QPS) sia costante. Ad esempio, se hai uno SLO del 99,9% misurato su 30 giorni, puoi resistere a 43,2 minuti di tempo di riposo completo durante questi 30 giorni. Ad esempio, il tempo di riposo può verificarsi contemporaneamente o essere distribuito su più incidenti.
| Obiettivo | 90 giorni | 30 giorni | 7 giorni | 1 giorno |
|---|---|---|---|---|
| 90% | 9 giorni | 3 giorni | 16,8 ore | 2,4 ore |
| 99% | 21,6 ore | 7,2 ore | 1,7 ore | 14,4 minuti |
| 99,9% | 2,2 ore | 43,2 minuti | 10,1 minuti | 1,4 minuti |
| 99,99% | 13 minuti | 4,3 minuti | 1 minuto | 8,6 secondi |
| 99,999% | 1,3 minuti | 25,9 secondi | 6 secondi | 0,9 secondi |
In pratica, non puoi permetterti incidenti di interruzione del 100% se vuoi ottenere percentuali di successo elevate. Tuttavia, molti sistemi distribuiti possono avere un malfunzionamento parziale o eseguire il degrado in modo corretto. Anche in questi casi, è comunque necessario sapere se è necessario l'intervento di un operatore, anche in caso di errori parziali, e gli avvisi SLO ti consentono di determinare se è così.
Quando inviare l'avviso
Una domanda importante è quando intervenire in base al tasso di utilizzo dello SLO. In genere, se esaurirai il budget di errore entro 24 ore, è ora di chiamare qualcuno per risolvere il problema.
La misurazione del tasso di errore non è sempre semplice. Una serie di piccoli errori potrebbe sembrare spaventosa sul momento, ma rivelarsi di breve durata e avere un impatto irrilevante sul tuo SLO. Analogamente, se un sistema è leggermente inattivo per molto tempo, questi errori possono sommarsi e comportare una violazione dello SLO.
Idealmente, il tuo team reagirà a questi indicatori in modo da spendere quasi tutto il budget di errore (senza superarlo) per un determinato periodo di tempo. Se spendi troppo, violi il tuo SLO. Se spendi troppo poco, non stai assumendo rischi sufficienti o potresti esaurire il tuo team di assistenza.
Devi avere un modo per determinare quando un sistema è abbastanza danneggiato da richiedere l'intervento di una persona. Le sezioni seguenti illustrano alcuni approcci a questa domanda.
Ustioni rapide
Un tipo di utilizzo dello SLO è un utilizzo rapido dello SLO perché esaurisce rapidamente il budget di errore e richiede un intervento per evitare una violazione dello SLO.
Supponiamo che il tuo servizio funzioni normalmente a 1000 query al secondo (QPS) e che tu voglia mantenere una disponibilità del 99% misurata su una settimana di sette giorni. Il tuo budget di errori è di circa 6 milioni di errori consentiti (su circa 600 milioni di richieste). Ad esempio, se hai 24 ore prima che budget di errore venga esaurito, hai un limite di circa 70 errori al secondo o 252.000 errori in un'ora. Questi parametri si basano sulla regola generale che gli incidenti richiamabili devono consumare almeno l'1% del budget di errore trimestrale.
Puoi scegliere di rilevare questa percentuale di errori prima che trascorra un'ora. Ad esempio, dopo aver osservato 15 minuti a una frequenza di 70 errori al secondo, potresti decidere di chiamare l'ingegnere di guardia, come mostrato nel seguente diagramma.
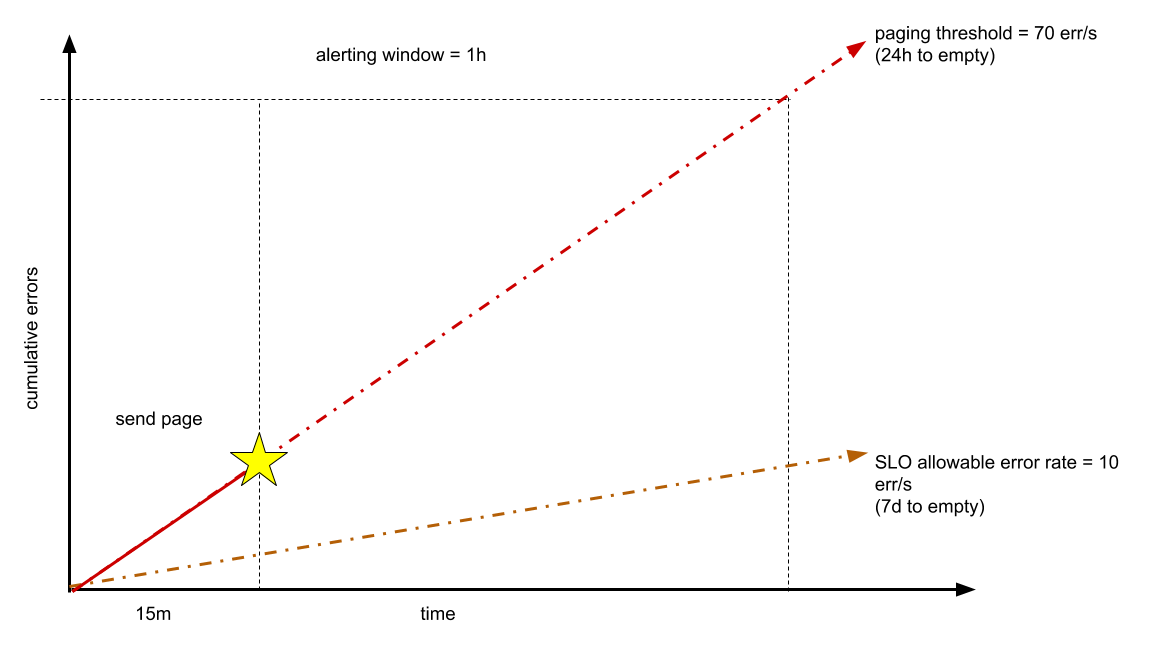
Idealmente, il problema viene risolto prima che tu abbia esaurito un'ora del tuo budget di 24 ore. Scegliere di rilevare questa frequenza in un periodo di tempo più breve (ad esempio un minuto) potrebbe essere troppo soggetta a errori. Se il tempo di rilevamento target è inferiore a 15 minuti, questo numero può essere modificato.
Incendi lenti
Un altro tipo di burn rate è la combustione lenta. Supponiamo che tu introduca un bug che esaurisce il budget settimanale degli errori entro il quinto o il sesto giorno o il budget mensile entro la seconda settimana. Qual è la risposta migliore?
In questo caso, puoi introdurre un avviso di utilizzo lento dello SLO che ti informa che stai per consumare l'intero budget di errore prima della fine della finestra di avviso. Naturalmente, questo avviso potrebbe restituire molti falsi positivi. Ad esempio, spesso potrebbe verificarsi una condizione in cui gli errori si verificano brevemente, ma a una frequenza che potrebbe consumare rapidamente il budget di errore. In questi casi, la condizione è un falso positivo perché dura solo per poco tempo e non rappresenta un rischio per il budget di errore a lungo termine. Ricorda che l'obiettivo non è eliminare tutte le fonti di errore, ma rimanere nell'intervallo accettabile per non superare il budget di errore. Vuoi evitare di avvisare un utente affinché intervenga per eventi che non rappresentano una minaccia legittima per il tuo budget di errore.
Per gli eventi a lenta combustione, ti consigliamo di inviare una notifica a una coda di ticket (anziché inviare una pagina o un'email). Gli eventi a lenta combustione non sono emergenze, ma richiedono l'intervento umano prima della scadenza del budget. Questi avvisi non devono essere email inviate a un elenco di gruppi, che diventano rapidamente una seccatura da ignorare. I biglietti devono essere tracciabili, assegnabili e trasferibili. I team devono sviluppare report per il carico dei ticket, le percentuali di chiusura, l'idoneità all'azione e i duplicati. I ticket eccessivi e non gestibili sono un ottimo esempio di lavoro.
Utilizzare gli avvisi SLO in modo efficace può richiedere tempo e dipendere dalla cultura e dalle aspettative del tuo team. Ricorda che puoi perfezionare gli avvisi SLO nel tempo. Puoi anche avere più metodi di avviso, con finestre di avviso diverse, a seconda delle tue esigenze.
Avvisi sulla latenza
Oltre agli avvisi di disponibilità, puoi anche avere avvisi di latenza. Con gli SLO relativi alla latenza, misuri la percentuale di richieste che non soddisfano un obiettivo di latenza. Se utilizzi questo modello, puoi utilizzare lo stesso modello di avviso che utilizzi per rilevare l'utilizzo rapido o lento del budget di errore.
Come indicato in precedenza in merito agli SLO di latenza media, la metà delle richieste può essere al di fuori dello SLO. In altre parole, i tuoi utenti possono riscontrare una latenza elevata per giorni prima che tu possa rilevare l'impatto sul budget di errore a lungo termine. I servizi devono invece definire obiettivi di latenza finale e di latenza tipica. Ti consigliamo di utilizzare il 90° percentile storico per definire il valore tipico e il 99° percentile per la coda. Dopo aver impostato questi target, puoi definire gli SLO in base al numero di richieste che prevedi di ricevere in ogni categoria di latenza e al numero di richieste troppo lente. Questo approccio è lo stesso concetto di un budget di errore e deve essere trattato allo stesso modo. Di conseguenza, potresti ottenere un'affermazione del tipo "Il 90% delle richieste verrà gestito entro la latenza tipica e il 99,9% entro i target di latenza coda". Questi obiettivi assicurano che la maggior parte degli utenti riscontri la latenza tipica e ti consentono comunque di monitorare quante richieste sono più lente rispetto ai tuoi obiettivi di latenza finale.
Per alcuni servizi, i tempi di esecuzione previsti potrebbero variare notevolmente. Ad esempio, potresti avere aspettative di rendimento molto diverse per la lettura da un sistema di datastore rispetto alla scrittura. Anziché elencare ogni possibile aspettativa, puoi introdurre bucket di prestazioni di runtime, come mostrato nelle seguenti tabelle. Questo approccio presuppone che questi tipi di richieste siano identificabili e preclassificati in ogni bucket. Non dovresti aspettarti di categorizzare le richieste al volo.
| Sito web rivolto agli utenti | |
|---|---|
| Bucket | Tempo di esecuzione massimo previsto |
| Leggi | 1 secondo |
| Scrittura / aggiornamento | 3 secondi |
| Sistemi di elaborazione dati | |
|---|---|
| Bucket | Tempo di esecuzione massimo previsto |
| Piccolo | 10 secondi |
| Medio | 1 minuto |
| Grande | 5 minuti |
| Gigante | 1 ora |
| Enorme | 8 ore |
Misurando il sistema così com'è oggi, puoi capire quanto tempo in genere richiedono queste richieste. Ad esempio, prendi in considerazione un sistema per l'elaborazione di caricamenti di video. Se il video è molto lungo, il tempo di elaborazione dovrebbe essere più lungo. Possiamo utilizzare la durata del video in secondi per classificare questo lavoro in un bucket, come mostrato nella tabella seguente. La tabella registra il numero di richieste per bucket, nonché vari percentile per la distribuzione del tempo di esecuzione nel corso di una settimana.
| Durata del video | Numero di richieste misurate in una settimana | 10% | 90% | 99,95% |
|---|---|---|---|---|
| Piccolo | 0 | - | - | - |
| Medio | 1,9 milioni | 864 millisecondi | 17 secondi | 86 secondi |
| Grande | 25 milioni | 1,8 secondi | 52 secondi | 9,6 minuti |
| Gigante | 4,3 milioni | 2 secondi | 43 secondi | 23,8 minuti |
| Enorme | 81.000 | 36 secondi | 1,2 minuti | 41 minuti |
Da questa analisi, puoi ricavare alcuni parametri per gli avvisi:
- fast_typical: al massimo il 10% delle richieste è più veloce di questo tempo. Se troppe richieste sono più rapide di questo tempo, i tuoi target potrebbero essere errati o potrebbe essere cambiato qualcosa nel tuo sistema.
- slow_typical: almeno il 90% delle richieste è più veloce di questo tempo. Questo limite determina lo SLO principale per la latenza. Questo parametro indica se la maggior parte delle richieste è abbastanza rapida.
- slow_tail: almeno il 99,95% delle richieste è più veloce di questo tempo. Questo limite garantisce che non ci siano troppe richieste lente.
- scadenza: il punto in cui un'elaborazione in background o RPC dell'utente scade e non va a buon fine (un limite in genere già hard-coded nel sistema). Queste richieste non saranno in realtà lente, ma non andranno a buon fine con un errore e verranno conteggiate ai fini dello SLO di disponibilità.
Una linea guida per la definizione dei bucket è mantenere fast_typical, slow_typical e slow_tail all'interno di un ordine di grandezza. Questa linea guida ti assicura di non avere un bucket troppo ampio. Ti consigliamo di non tentare di evitare sovrapposizioni o spazi tra i bucket.
| Bucket | fast_typical | slow_typical | slow_tail | scadenza |
|---|---|---|---|---|
| Piccolo | 100 millisecondi | 1 secondo | 10 secondi | 30 secondi |
| Medio | 600 millisecondi | 6 secondi | 60 secondi (1 minuto) | 300 secondi |
| Grande | 3 secondi | 30 secondi | 300 secondi (5 minuti) | 10 minuti |
| Gigante | 30 secondi | 6 minuti | 60 minuti (1 ora) | 3 ore |
| Enorme | 5 minuti | 50 minuti | 500 minuti (8 ore) | 12 ore |
Il risultato è una regola come api.method: SMALL => [1s, 10s].
In questo caso, il sistema di monitoraggio degli SLO vedrebbe una richiesta, ne determinerebbe il bucket
(ad esempio analizzando il nome del metodo o l'URI e confrontando il nome con una tabella di ricerca), quindi aggiornerebbe la statistica in base al tempo di esecuzione della richiesta. Se questo
ha richiesto 700 millisecondi, rientra nel target slow_typical. Se è di 3
secondi, rientra in slow_tail. Se è di 22 secondi, supera
slow_tail, ma non è ancora un errore.
In termini di soddisfazione utente, puoi considerare la latenza in coda mancante come equivalente alla mancata disponibilità. In altre parole, la risposta è così lenta da dover essere considerata un errore. Per questo motivo, ti consigliamo di utilizzare la stessa percentuale che utilizzi per la disponibilità, ad esempio:
La latenza che consideri tipica dipende da te. Alcuni team di Google considerano il 90% un buon target. Questo valore è correlato all'analisi e alla modalità di scelta delle durate per slow_typical. Ad esempio:
Avvisi suggeriti
In base a queste linee guida, la tabella seguente include un insieme di avvisi SLO di riferimento suggerito.
| SLO | Finestra di misurazione | Burn rate | Azione |
|---|---|---|---|
|
Disponibilità, burn veloce Latenza tipica Latenza finale |
Finestra di 1 ora | Mancano meno di 24 ore alla violazione dello SLO | Chiamare qualcuno |
|
Disponibilità, evoluzione lenta Latenza tipica, adozione graduale Latenza finale, adozione graduale |
Finestra di 7 giorni | Più di 24 ore prima della violazione dello SLO | Creare un ticket |
La generazione di avvisi SLO è una competenza che può richiedere tempo per essere sviluppata. Le durate riportate in questa sezione sono suggerimenti; puoi modificarle in base alle tue esigenze e al tuo livello di precisione. Potrebbe essere utile associare gli avvisi alla finestra di misurazione o alla spesa del budget di errore oppure aggiungere un altro livello di avviso tra le spese rapide e quelle lente.