Este artículo es la sexta parte de una serie en la que se trata la recuperación ante desastres (DR) en Google Cloud. En esta parte, se analiza el proceso para diseñar la arquitectura de cargas de trabajo mediante Google Cloud y los componentes básicos resilientes a las interrupciones en la infraestructura de nube.
La serie consta de estas partes:
- Guía de planificación para la recuperación ante desastres
- Componentes básicos de la recuperación ante desastres
- Situaciones de recuperación ante desastres para datos
- Situaciones de recuperación ante desastres para aplicaciones
- Arquitectura de recuperación ante desastres para cargas de trabajo con restricciones de localidad
- Arquitectura de recuperación ante desastres para interrupciones de la infraestructura de nube (este documento)
Introducción
A medida que las empresas trasladan las cargas de trabajo a la nube pública, necesitan traducir sus conocimientos de cómo compilar sistemas locales resilientes en la infraestructura de hiperescalamiento de los proveedores de servicios en la nube, como Google Cloud. En este artículo, se asignan conceptos estándar de la industria sobre la recuperación ante desastres, como el RTO (objetivo de tiempo de recuperación) y el RPO (objetivo de punto de recuperación) a la infraestructura de Google Cloud.
La orientación de este documento sigue uno de los principios clave de Google para lograr una disponibilidad de servicio muy alta: planificar la falla. Si bien Google Cloud ofrece un servicio muy confiable, ocurrirán desastres naturales, cortes de fibra y errores complejos de infraestructura; estos pueden causar interrupciones. La planificación para las interrupciones permite que los clientes de Google Cloud compilen aplicaciones que se ejecuten de manera predecibles durante estos eventos inevitables mediante el uso de productos de Google Cloud con mecanismos de DR “integrados”.
La recuperación ante desastres es un tema amplio que cubre mucho más que las fallas de infraestructura, como los errores de software o la corrupción de datos, y debes tener un plan integral de extremo a extremo. Sin embargo, este artículo se centra en una parte de un plan de DR general: cómo diseñar aplicaciones que sean resilientes a las interrupciones de la infraestructura de nube. En concreto, se explica lo siguiente:
- La infraestructura de Google Cloud, cómo se manifiestan los eventos de desastre como interrupciones de Google Cloud y cómo Google Cloud está diseñado para minimizar la frecuencia y el alcance de las interrupciones
- Una guía de planificación de la arquitectura que proporciona un framework para categorizar y diseñar aplicaciones según los resultados de confiabilidad deseados
- Una lista detallada de productos de Google Cloud seleccionados que ofrecen funciones de DR integradas que tal vez quieras usar en tu aplicación
Para obtener más detalles sobre la planificación general de la DR y el uso de Google Cloud como componente de tu estrategia de DR local, consulta la Guía de planificación para la recuperación ante desastres. Aunque la alta disponibilidad es un concepto muy relacionado con la recuperación ante desastres, no se aborda en este artículo. Si deseas obtener más detalles sobre la arquitectura de una alta disponibilidad, consulta el framework de la arquitectura de Google Cloud.
Nota sobre la terminología: Este artículo hace referencia a la disponibilidad cuando se describe la capacidad de un producto de que se acceda a él de manera significativa y se use a lo largo del tiempo, mientras que la confiabilidad se refiere a un conjunto de atributos que incluye la disponibilidad, además de funciones como la durabilidad y la corrección.
Cómo está diseñado Google Cloud para ofrecer resiliencia
Centros de datos de Google
Los centros de datos tradicionales se basan en maximizar la disponibilidad de componentes individuales. En la nube, la escala permite a operadores como Google distribuir servicios en muchos componentes mediante tecnologías de virtualización y, por lo tanto, superar la confiabilidad tradicional de los componentes. Esto significa que puedes dejar de enfocar la mentalidad de la arquitectura de confiabilidad en los innumerables detalles que te preocupaban en las instalaciones locales. En lugar de preocuparte por los distintos modos de falla de los componentes, como el enfriamiento y la entrega de energía, puedes planificar en torno a los productos de Google Cloud y sus métricas de confiabilidad indicadas. Estas métricas reflejan el riesgo de interrupción agregado de toda la infraestructura subyacente. De esta manera, puedes enfocarte mucho más en el diseño, la implementación y las operaciones de la aplicación en lugar de la administración de infraestructura.
Google diseña su infraestructura para cumplir con los objetivos de disponibilidad agresivos en función de nuestra vasta experiencia en el desarrollo y la ejecución de centros de datos modernos. Google es uno de los líderes mundiales en el diseño de centros de datos. Cada tecnología de centro de datos, desde la electricidad hasta el enfriamiento y las redes, tiene sus propias redundancias y mitigaciones, incluidos los planes de FMEA. El diseño de los centros de datos de Google balancea estos riesgos variados y presenta a los clientes un nivel coherente y esperado de disponibilidad para los productos de Google Cloud. Google usa su experiencia para modelar la disponibilidad de la arquitectura general del sistema físico y lógico a fin de garantizar que el diseño del centro de datos cumpla con las expectativas. Los ingenieros de Google hacen grandes esfuerzos operativos para garantizar que se cumplan esas expectativas. Es normal que la disponibilidad real exceda nuestros objetivos de diseño por un margen amplio.
Cuando se extraen todos estos riesgos y mitigaciones de los centros de datos en los productos para los usuarios, Google Cloud te evita esas responsabilidades operativas y de diseño. En cambio, puedes enfocarte en la confiabilidad integrada en el diseño de las regiones y las zonas de Google Cloud.
Regiones y zonas
Los productos de Google Cloud se proporcionan en una gran cantidad de regiones y zonas. Las regiones son áreas geográficas independientes que contienen tres zonas o más. Las zonas representan grupos de recursos de procesamiento físicos dentro de una región que tienen un alto grado de independencia entre sí en términos de infraestructura física y lógica. Proporcionan conexiones de red de latencia baja y ancho de banda alto a otras zonas de la misma región. Por ejemplo, la región asia-northeast1 en Japón contiene tres zonas: asia-northeast1-a, asia-northeast1-b y asia-northeast1-c.
Los productos de Google Cloud se dividen en recursos zonales, regionales y multirregionales.
Los recursos zonales se alojan en una sola zona. Una interrupción del servicio en esa zona puede afectar a todos los recursos de esa zona. Por ejemplo, una instancia de Compute Engine se ejecuta en una zona única y especificada. Si una falla de hardware interrumpe el servicio en esa zona, esa instancia de Compute Engine no estará disponible mientras dure la interrupción.
Los recursos regionales se implementan de forma redundante en varias zonas dentro de una región. Esto les brinda mayor confiabilidad en comparación con los recursos zonales.
Los recursos multirregionales se distribuyen dentro de las regiones y entre ellas. En general, los recursos multirregionales son más confiables que los regionales. Sin embargo, a este nivel, los productos deben optimizar la disponibilidad, el rendimiento y la eficiencia de los recursos. Como resultado, es importante comprender las compensaciones de cada producto multirregional que decidas usar. Estas compensaciones se documentan de forma específica para cada producto más adelante en este documento.
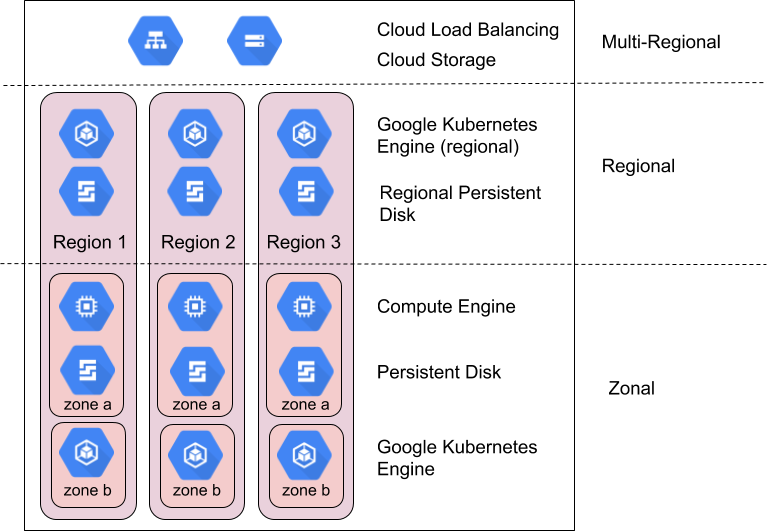
Cómo aprovechar las zonas y las regiones para lograr la confiabilidad
Las SRE de Google administran y escalan productos para usuarios globales de alta confiabilidad, como Gmail y Búsqueda, mediante una variedad de técnicas y tecnologías que aprovechan sin problemas la infraestructura de procesamiento en todo el mundo. Esto incluye el redireccionamiento del tráfico desde ubicaciones no disponibles mediante el balanceo de cargas global, la ejecución de varias réplicas en varias ubicaciones en todo el planeta y la replicación de datos en distintos lugares. Estas mismas capacidades están disponibles para los clientes de Google Cloud a través de productos como Cloud Load Balancing, Google Kubernetes Engine y Cloud Spanner.
En general, Google Cloud diseña productos a fin de entregar los siguientes niveles de disponibilidad para zonas y regiones:
| Recurso | Ejemplos | Objetivo del diseño de disponibilidad | Tiempo de inactividad implícito |
|---|---|---|---|
| Zonal | Compute Engine, Persistent Disk | 99.9% | 8.75 horas al año |
| Regional | Cloud Storage regional, Persistent Disk replicado, Google Kubernetes Engine regional | 99.99% | 52 minutos al año |
Compara los objetivos del diseño de disponibilidad de Google Cloud con el nivel aceptable de tiempo de inactividad para identificar los recursos apropiados de Google Cloud. Si bien los diseños tradicionales se enfocan en mejorar la disponibilidad a nivel del componente para mejorar la disponibilidad resultante de la aplicación, los modelos de la nube se enfocan en la composición de los componentes a fin de lograr este objetivo. Muchos productos dentro de Google Cloud usan esta técnica. Por ejemplo, Cloud Spanner ofrece una base de datos multirregional que compone varias regiones para entregar una disponibilidad del 99.999%.
La composición es importante porque, sin ella, la disponibilidad de la aplicación no puede superar la de los productos de Google Cloud que usas. De hecho, a menos que la aplicación nunca falle, tendrá una disponibilidad menor que los productos de Google Cloud subyacentes. En el resto de esta sección, se muestra cómo puedes usar una composición de productos zonales y regionales para lograr una mayor disponibilidad de la aplicación que la que proporcionan una sola zona o región. En la próxima sección, se proporciona una guía práctica para aplicar estos principios a tus aplicaciones.
Planifica los alcances de interrupción de zonas
Por lo general, las fallas de infraestructura generan interrupciones del servicio en una sola zona. Dentro de una región, las zonas están diseñadas para minimizar el riesgo de fallas correlacionadas con otras zonas, y una interrupción del servicio en una zona no suele afectar el servicio de otra zona en la misma región. Una interrupción con alcance a una zona no siempre implica que toda la zona no esté disponible; solo define el límite del incidente. Es posible que una interrupción zonal no tenga ningún efecto tangible en los recursos específicos de esa zona.
Es un caso menos frecuente, pero también es importante tener en cuenta que varias zonas, en algún momento, experimentarán una interrupción correlacionada en una sola región. Cuando dos o más zonas experimentan una interrupción, se aplica la estrategia de alcance de la interrupción regional que aparece a continuación.
Los recursos regionales están diseñados para ser resistentes a las interrupciones zonales mediante la entrega del servicio desde una composición de varias zonas. Si se interrumpe una de las zonas que respaldan un recurso regional, el recurso queda disponible de manera automática desde otra zona. Revisa con cuidado la descripción de la capacidad del producto en el apéndice para obtener más detalles.
Google Cloud solo ofrece algunos recursos zonales, como las máquinas virtuales (VM) de Compute Engine y Persistent Disk. Si planeas usar recursos zonales, tendrás que realizar tu propia composición de recursos mediante el diseño, la compilación y la prueba de la conmutación por error y la recuperación entre recursos zonales ubicados en varias zonas. Estas son algunas de las estrategias:
- Enrutar con rapidez el tráfico a máquinas virtuales en otra zona mediante Cloud Load Balancing cuando una verificación de estado determina que una zona tiene problemas
- Usar plantillas de instancias o grupos de instancias administrados de Compute Engine para ejecutar y escalar instancias de VM idénticas en varias zonas
- Usar Persistent Disk regional para replicar de forma síncrona los datos en otra zona de una región. Consulta Opciones de alta disponibilidad mediante PD regionales para obtener más detalles
Planifica los alcances de interrupción regional
Una interrupción regional es una interrupción del servicio que afecta a más de una zona en una sola región. Estas son interrupciones más grandes y menos frecuentes, y pueden ser consecuencia de desastres naturales o fallas en la infraestructura a gran escala.
Si un producto regional está diseñado para proporcionar una disponibilidad del 99.99%, una interrupción puede traducirse a casi una hora de inactividad para un producto específico cada año. Por lo tanto, es posible que tus aplicaciones esenciales necesiten contar con un plan de DR multirregional si no esta duración de interrupción es inaceptable.
Los recursos multirregionales están diseñados para ser resistentes a las interrupciones regionales mediante la entrega del servicio en varias regiones. Como se describió antes, los productos multirregionales compensan la latencia, la coherencia y el costo. La compensación más común se da entre la replicación de datos síncrona y la replicación asíncrona. La replicación asíncrona ofrece menos latencia al costo de riesgo de pérdida de datos durante una interrupción. Por lo tanto, es importante verificar la descripción de la capacidad del producto en el apéndice para obtener más detalles.
Si quieres usar recursos regionales y seguir siendo resiliente ante las interrupciones regionales, debes diseñar tu propia composición de recursos. Para ello, diseña, compila y prueba la conmutación por error y la recuperación entre los recursos regionales ubicados en varias regiones. Además de las estrategias zonales anteriores, que también puedes aplicar a otras regiones, ten en cuenta lo siguiente:
- Los recursos regionales deben replicar los datos en una región secundaria, en una opción de almacenamiento multirregional, como Cloud Storage, o en una opción de nube híbrida, como Anthos.
- Una vez que tengas una mitigación regional ante interrupciones, pruébala con frecuencia. Si hay algo peor que pensar que eres resistente a una interrupción de una sola región, es descubrir que ese no es el caso cuando ocurre de verdad.
Enfoque de disponibilidad y resiliencia de Google Cloud
Google Cloud supera con regularidad sus objetivos de diseño de disponibilidad, pero no debes suponer que este rendimiento anterior sólido es la disponibilidad mínima que puedes diseñar. En cambio, debes seleccionar dependencias de Google Cloud cuyos objetivos para los que se diseñaron superan la confiabilidad prevista de la aplicación, de modo que el tiempo de inactividad de la aplicación más el tiempo de inactividad de Google Cloud entreguen el resultado que buscas.
Un sistema bien diseñado puede responder la pregunta “¿Qué sucede cuando una zona o región tiene una interrupción de 1, 5, 10 o 30 minutos?” Esto se debe tener en cuenta en muchas capas, incluidas las siguientes:
- ¿Qué experimentarán mis clientes durante una interrupción?
- ¿Cómo detecto que hay una interrupción en curso?
- ¿Qué sucede con mi solicitud durante una interrupción?
- ¿Qué sucede con mis datos durante una interrupción?
- ¿Qué le sucede a mis otras aplicaciones como consecuencia de una interrupción (debido a las dependencias cruzadas)?
- ¿Qué debo hacer para recuperarme después de que se resuelve una interrupción? ¿Quién lo hace?
- ¿A quién debo notificar sobre una interrupción? ¿En qué período?
Guía paso a paso a fin de diseñar la recuperación ante desastres para aplicaciones en Google Cloud
En las secciones anteriores, se explicó cómo Google compila la infraestructura de nube y algunos enfoques para abordar las interrupciones zonales y regionales.
En esta sección, te ayudamos a desarrollar un framework para aplicar el principio de composición a tus aplicaciones en función de los resultados de confiabilidad deseados.
Paso 1: Reúne los requisitos existentes
El primer paso es definir los requisitos de disponibilidad para tus aplicaciones. La mayoría de las empresas ya tienen algún nivel de orientación de diseño en este espacio, que se puede desarrollar de forma interna o derivar de leyes u otros requisitos legales. En general, esta guía de diseño se codifica en dos métricas clave: el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO). En términos comerciales, el RTO se traduce como “cuánto tiempo transcurre después de un desastre hasta que vuelvo a estar activo y listo para ejecutar”. El RPO se traduce como “cuántos datos puedo perder si ocurre un desastre”.

A lo largo de la historia, las empresas definieron los requisitos de RTO y RPO para un rango amplio de eventos de desastres, desde fallas de componentes hasta terremotos. Esto tenía sentido en el mundo local en el que los planificadores debían asignar los requisitos de RTO y RPO a través de toda la pila de software y hardware. En la nube, ya no necesitas definir tus requisitos con tanto detalles porque el proveedor se encarga de eso. En cambio, puedes definir tus requisitos de RTO y RPO en términos del alcance de la pérdida (zonas o regiones completas) sin especificar los motivos subyacentes. Para Google Cloud, esto simplifica la recopilación de requisitos a 3 situaciones: una interrupción zonal, una interrupción regional o la interrupción de varias regiones, que es muy poco probable.
Ya que se reconoce que no todas las aplicaciones tienen la misma importancia, la mayoría de los clientes clasifican sus aplicaciones en niveles de importancia, en los que se puede aplicar un requisito específico de RTO y RPO. Cuando se combinan, el RTO, el RPO y la importancia de la aplicación optimizan el proceso de diseñar la arquitectura de una aplicación determinada y dan respuesta a las siguientes preguntas:
- ¿La aplicación debe ejecutarse en varias zonas en la misma región o en varias zonas en varias regiones?
- ¿De qué productos de Google Cloud puede depender la aplicación?
Este es un ejemplo del resultado del ejercicio de recopilación de requisitos:
El RTO y el RPO por importancia de la aplicación para la organización de ejemplo:
| Importancia de la aplicación | % de apps | Apps de ejemplo | Interrupción zonal | Interrupción regional |
|---|---|---|---|---|
| Nivel 1
(más importante) |
5% | Por lo general, las aplicaciones globales y externas orientadas al cliente, como los pagos en tiempo real y las vidrieras de comercio electrónico. | RTO de cero
RPO de cero |
RTO de 4 horas RPO de 1 hora |
| Nivel 2 | 35% | Por lo general, las aplicaciones regionales o las aplicaciones internas importantes como CRM o ERP. | RTO de 4 horas RPO de cero |
RTO de 24 horas
RPO de 4 horas |
| Nivel 3
(menos importante) |
60% | Por lo general, las aplicaciones de equipos o departamentos, como la oficina administrativa, las reservas, los viajes internos, la contabilidad y el departamento de RR.HH. | RTO de 12 horas
RPO de 24 horas |
RTO de 28 días
RPO de 24 horas |
Paso 2: Asignación de capacidades a los productos disponibles
El segundo paso es comprender las capacidades de resiliencia de los productos de Google Cloud que usarán tus aplicaciones. La mayoría de las empresas revisan la información relevante de los productos y, luego, agregan orientación sobre cómo modificar las arquitecturas a fin de adaptarse a las brechas entre las capacidades de los productos y los requisitos de resiliencia. En esta sección, se abarcan algunas áreas comunes y recomendaciones sobre las limitaciones de datos y aplicaciones en este espacio.
Como se mencionó antes, los productos habilitados para DR de Google están pensados, a grandes rasgos, para dos tipos de alcances de interrupción: regional y zonal. Cuando se trata de DR, se debe planificar de la misma manera para las interrupciones parciales y las interrupciones totales. Esto brinda una matriz inicial de alto nivel de qué productos son adecuados para cada situación de forma predeterminada:
Funciones generales de los productos de Google Cloud
(consulta el Apéndice para conocer las funciones específicas de productos)
| Todos los productos de Google Cloud | Productos regionales de Google Cloud con replicación automática entre zonas | Productos multirregionales o globales de Google Cloud con replicación automática en todas las regiones | |
|---|---|---|---|
| Error de un componente dentro de una zona | Cubierto* | Cubierto | Cubierto |
| Interrupción zonal | No cubierto | Cubierto | Cubierto |
| Interrupción regional | No cubierto | No cubierto | Cubierto |
* Todos los productos de Google Cloud son resilientes a la falla de componentes, excepto en los casos específicos que se indican en la documentación del producto. Por lo general, son situaciones en las que el producto ofrece acceso directo o asignación estática a un hardware de especialidad, como la memoria o los discos de estado sólido (SSD).
Cómo el RPO limita las opciones de producto
En la mayoría de las implementaciones de nube, la integridad de los datos es el aspecto más significativo desde el punto de vista arquitectónico para un servicio. Al menos algunas aplicaciones tienen un requisito de RPO de cero, lo que significa que no se deberían perder datos en caso de que ocurra una interrupción. Por lo general, esto requiere que los datos se repliquen de forma síncrona en otra zona o región. La replicación síncrona tiene compensaciones de costo y latencia, por lo que, si bien muchos productos de Google Cloud proporcionan replicación síncrona entre zonas, solo unos pocos la proporcionan en regiones. Esta compensación entre el costo y la complejidad significa que no es inusual que diferentes tipos de datos dentro de una aplicación tengan diferentes valores de RPO.
En los datos con un RPO mayor que cero, las aplicaciones pueden aprovechar la replicación asíncrona. La replicación asíncrona es aceptable cuando los datos perdidos se pueden volver a crear con facilidad o se pueden recuperar de una fuente de datos dorada si es necesario. También puede ser una opción razonable cuando una pequeña pérdida de datos es una compensación aceptable en el contexto de las duraciones previstas para las interrupciones zonales y regionales. También es relevante que, durante una interrupción transitoria, los datos escritos en la ubicación afectada, pero que aún no se replicaron en otra ubicación, por lo general estén disponibles después de que se resuelva la interrupción. Esto significa que el riesgo de pérdida permanente de los datos es menor que el riesgo de perder el acceso a los datos durante una interrupción.
Acciones clave: Determina si realmente necesitas un RPO de cero y, si es así, si puedes hacerlo para un subconjunto de datos; esto aumenta de forma notable el rango de servicios habilitados para DR disponibles. En Google Cloud, alcanzar un RPO de cero implica usar, en su mayoría, productos regionales para la aplicación, que, en la configuración predeterminada, son resilientes a las interrupciones a escala zonal, pero no a escala regional.
Cómo el RTO limita las opciones del producto
Uno de los principales beneficios de la computación en la nube es la capacidad de implementar la infraestructura a pedido. Sin embargo, no es lo mismo que la implementación instantánea. El valor de RTO de tu aplicación debe adaptarse al RTO combinado de los productos de Google Cloud que usa la aplicación y a las acciones que deban realizar los ingenieros o SRE para reiniciar las VM o los componentes de la aplicación. Un RTO medido en minutos significa diseñar una aplicación que se recupere de forma automática de un desastre sin intervención humana o con pasos mínimos, como presionar un botón para una conmutación por error. El costo y la complejidad de este tipo de sistema siempre han sido muy altos, pero los productos de Google Cloud, como los balanceadores de cargas y los grupos de instancias, hacen que este diseño sea mucho más accesible y sencillo. Por lo tanto, debes tener en cuenta la conmutación por error y la recuperación automatizadas para la mayoría de las aplicaciones. Ten en cuenta que diseñar un sistema para este tipo de conmutación por error en caliente en todas las regiones es complicado y costoso; solo una fracción muy pequeña de los servicios importantes justifican esta capacidad.
La mayoría de las aplicaciones tendrá un RTO de entre una hora y un día, lo que permite una conmutación por error cálida en una situación de desastre, con algunos componentes de la aplicación que se ejecutan todo el tiempo en modo de espera, como las bases de datos, mientras que otros se escalan horizontalmente durante un desastre real, como los servidores web. En el caso de estas aplicaciones, debes considerar la automatización para los eventos de escalamiento horizontal. Los servicios con un RTO de más de un día son los de menor importancia y a menudo se pueden recuperarse desde una copia de seguridad o volver a crearse desde cero.
Acciones clave: Determina si en verdad necesitas un RTO de (alrededor de) cero para la conmutación por error regional y, de ser así, si puedes hacerlo para un subconjunto de los servicios. Esto cambia el costo de ejecutar y mantener tu servicio.
Paso 3: Desarrolla tus propias arquitecturas y guías de referencia
El último paso recomendado es compilar tus propios patrones de arquitectura específicos de la empresa para ayudar a tus equipos a estandarizar su enfoque sobre la recuperación ante desastres. La mayoría de los clientes de Google Cloud producen una guía destinada a sus equipos de desarrollo que hace coincidir sus expectativas individuales de resiliencia empresarial con las dos categorías principales de interrupciones en Google Cloud. Esto permite que los equipos clasifiquen con facilidad qué productos habilitados para DR son adecuados en cada nivel de importancia.
Crea lineamientos para productos
La tabla de RTO y RPO de ejemplo anterior es una guía hipotética que detalla qué productos se permitirían de forma predeterminada para cada nivel de importancia. Ten en cuenta que, de forma predeterminada, ciertos productos se identificaron como no adecuados. Siempre puedes agregar tus propios mecanismos de replicación y conmutación por error para habilitar la sincronización entre zonas o regiones, pero este ejercicio está más allá del alcance de este artículo. En las tablas, también encontrarás vínculos a más información sobre cada producto para ayudarte a comprender sus capacidades en relación con la administración de las interrupciones zonales y regionales.
Patrones de arquitectura de muestra para la organización de ejemplo: Resiliencia para las interrupciones zonales:
| Producto de Google Cloud | ¿El producto cumple con los requisitos de interrupción zonal para la organización de ejemplo (con la configuración adecuada del producto)? | ||
|---|---|---|---|
| Nivel 1 | Nivel 2 | Nivel 3 | |
| Compute Engine | Sí | Sí | Sí |
| Dataflow | No | No | No |
| BigQuery | No | No | Sí |
| Google Kubernetes Engine | Sí | Sí | Sí |
| Cloud Storage | Sí | Sí | Sí |
| Cloud SQL | No | Sí | Sí |
| Cloud Spanner | Sí | Sí | Sí |
| Cloud Load Balancing | Sí | Sí | Sí |
Esta tabla es un ejemplo basado solo en los niveles hipotéticos descritos con anterioridad.
Patrones de arquitectura de muestra para la organización de ejemplo: Resiliencia para las interrupciones regionales:
| Producto de Google Cloud | ¿El producto cumple con los requisitos de interrupción regional para la organización de ejemplo (con la configuración adecuada del producto)? | ||
|---|---|---|---|
| Nivel 1 | Nivel 2 | Nivel 3 | |
| Compute Engine | Sí | Sí | Sí |
| Dataflow | No | No | No |
| BigQuery | No | No | Sí |
| Google Kubernetes Engine | Sí | Sí | Sí |
| Cloud Storage | No | No | No |
| Cloud SQL | Sí | Sí | Sí |
| Cloud Spanner | Sí | Sí | Sí |
| Cloud Load Balancing | Sí | Sí | Sí |
Esta tabla es un ejemplo basado solo en los niveles hipotéticos descritos con anterioridad.
A fin de mostrar cómo se usarían estos productos, en las siguientes secciones, se explican algunas arquitecturas de referencia para cada uno de los niveles hipotéticos de importancia de la aplicación. Estas son descripciones de alto nivel hechas de manera deliberada para explicar las decisiones clave de la arquitectura y no representan un diseño de solución completo.
Arquitectura de ejemplo de nivel 3
| Importancia de la aplicación | Interrupción zonal | Interrupción regional |
|---|---|---|
| Nivel 3 (menos importante) |
RTO de 12 horas RPO de 24 horas |
RTO de 28 días RPO de 24 horas |
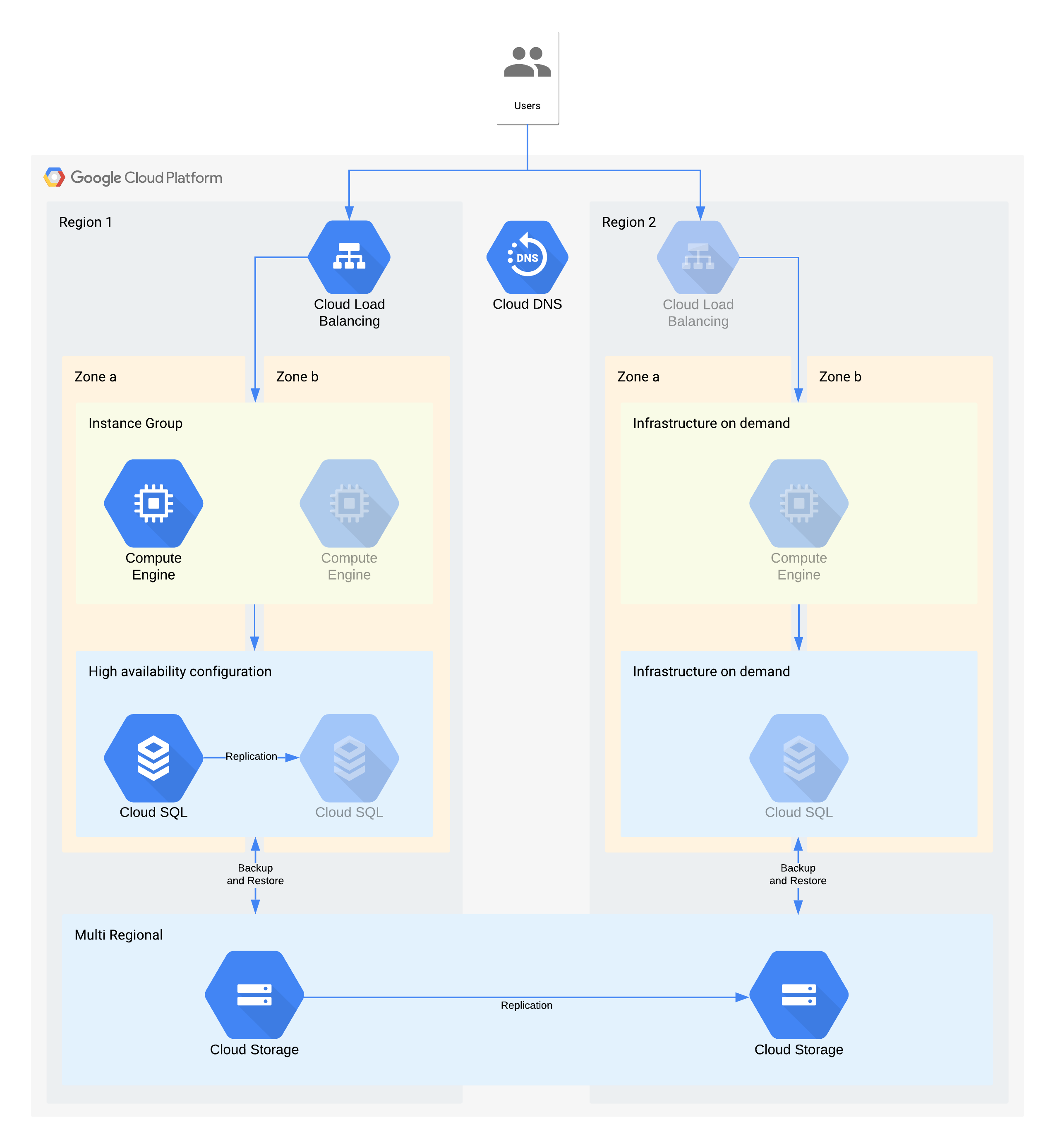
(Los íconos en gris muestran la infraestructura que se habilitará para permitir la recuperación)
En esta arquitectura, se describe una aplicación tradicional de cliente y servidor: los usuarios internos se conectan a una aplicación que se ejecuta en una instancia de procesamiento respaldada por una base de datos para el almacenamiento continuo.
Es importante tener en cuenta que esta arquitectura admite valores de RTO y RPO superiores a los necesarios. Sin embargo, también debes considerar quitar pasos manuales adicionales cuando podrían resultar costosos o poco confiables. Por ejemplo, recuperar una base de datos a partir de una copia de seguridad nocturna podría admitir el RPO de 24 horas, pero esto suele requerir una persona capacitada, como un administrador de la base de datos que podría no estar disponible, en especial si varios servicios se vieron afectados al mismo tiempo. Con la infraestructura a pedido de Google Cloud, puedes compilar esta capacidad sin hacer una compensación de costo mayor, por lo que esta arquitectura usa la alta disponibilidad de Cloud SQL en lugar de una copia de seguridad o el restablecimiento manual para interrupciones zonales.
Decisiones clave de arquitectura para la interrupción zonal: RTO de 12 horas y RPO de 24 horas:
- Un balanceador de cargas interno se usa a fin de proporcionar un punto de acceso escalable para los usuarios, lo que permite la conmutación por error automática a otra zona. Aunque el RTO es de 12 horas, los cambios manuales en las direcciones IP o incluso las actualizaciones del DNS pueden tardar más tiempo del esperado.
- Un grupo de instancias administrado regional se configura con varias zonas, pero con recursos mínimos. Esto optimiza el costo, pero permite que las máquinas virtuales se escalen horizontalmente con rapidez en la zona de la copia de seguridad.
- Una configuración de Cloud SQL de alta disponibilidad proporciona conmutación por error automática a otra zona. Las bases de datos son mucho más difíciles de volver a crear y restablecer en comparación con las máquinas virtuales de Compute Engine.
Decisiones clave de arquitectura para la interrupción regional: RTO de 28 días y RPO de 24 horas:
- Un balanceador de cargas se construiría en la región 2 solo en caso de que se produzca una interrupción regional. Se usa Cloud DNS para proporcionar una capacidad de conmutación por error regional, organizada y manual, ya que la infraestructura en la región 2 solo estará disponible en caso de que se produzca una interrupción regional.
- Un grupo de instancias administrado nuevo se construiría solo en caso de que se produzca una interrupción regional. Esto optimiza el costo y es poco probable que se invoque debido a la corta duración de la mayoría de las interrupciones regionales. Ten en cuenta que, a fin de simplificar el diagrama, no se muestran ni las herramientas asociadas necesarias para volver a implementar ni la copia de las imágenes de Compute Engine necesarias.
- Se volvería a crear una instancia de Cloud SQL nueva y se restablecerían los datos desde una copia de seguridad. Una vez más, el riesgo de una interrupción prolongada en una región es muy baja, por lo que esta es otra compensación de optimización de costos.
- Se usa Cloud Storage multirregional para almacenar estas copias de seguridad. Esto brinda resiliencia zonal y regional automática dentro de RTO y RPO.
Arquitectura de ejemplo de nivel 2
| Importancia de la aplicación | Interrupción zonal | Interrupción regional |
|---|---|---|
| Nivel 2 | RTO de 4 horas RPO de cero |
RTO de 24 horas RPO de 4 horas |
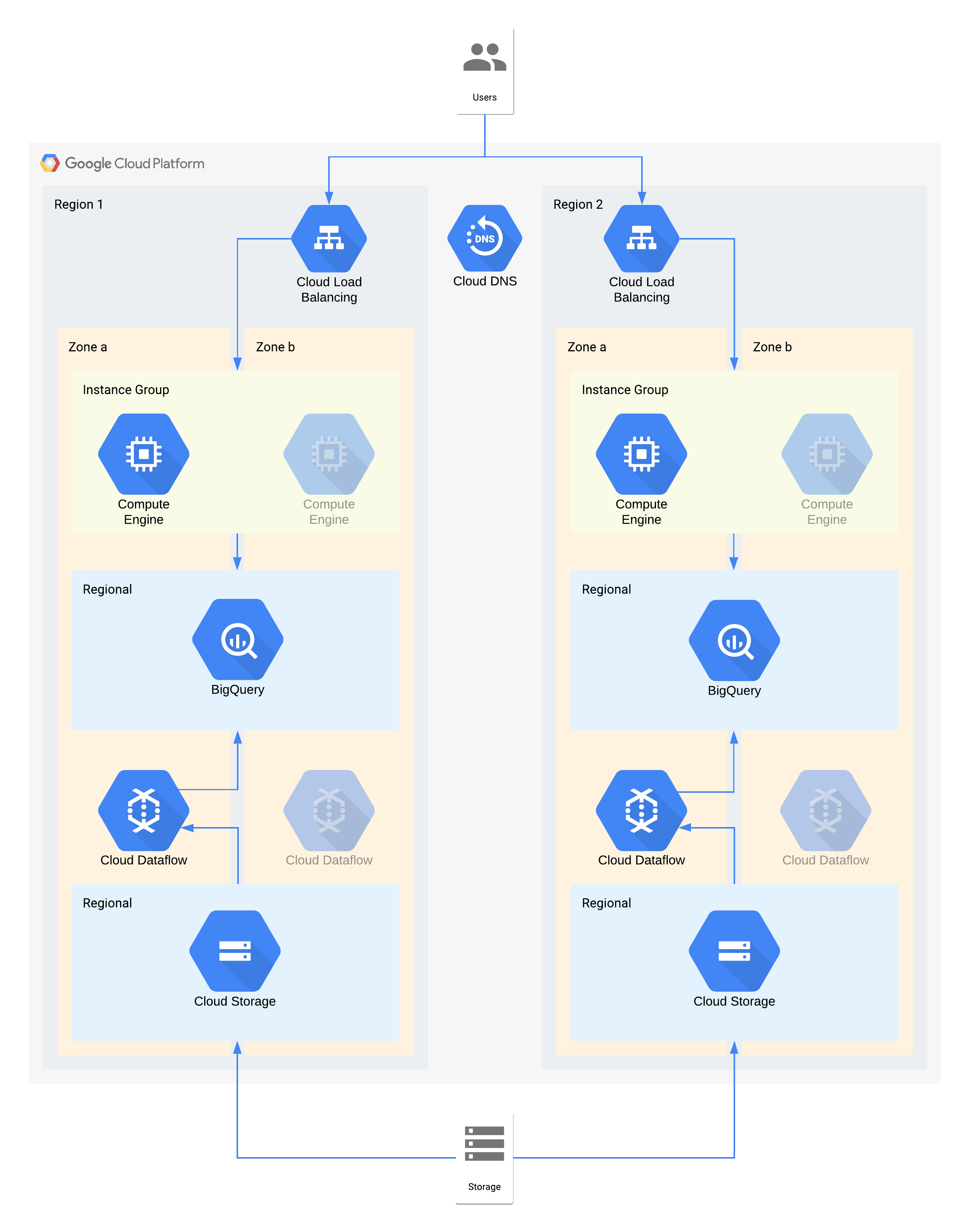
En esta arquitectura, se describe un almacén de datos con usuarios internos que se conectan a una capa de visualización de instancias de procesamiento, y una capa de transformación y transferencia de datos que propaga el almacén de datos de backend.
Algunos componentes individuales de esta arquitectura directamente no admiten el RPO requerido para su nivel. Sin embargo, debido a cómo se usan en conjunto, el servicio general cumple con el RPO. En este caso, como Dataflow es un producto zonal, se deben seguir las recomendaciones para el diseño de alta disponibilidad a fin de evitar la pérdida de datos durante una interrupción zonal. Sin embargo, la capa de Cloud Storage es la fuente dorada de estos datos y admite un RPO de cero. Esto significa que cualquier dato perdido puede volver a transferirse a BigQuery a través de la zona B (Zone B) en caso de una interrupción en la zona A (Zone A).
Decisiones clave de arquitectura para la interrupción zonal: RTO de 4 horas y RPO de cero:
- Se usa un balanceador de cargas a fin de proporcionar un punto de acceso escalable para los usuarios, lo que permite la conmutación por error automática a otra zona. Aunque el RTO es de 4 horas, los cambios manuales en las direcciones IP o incluso las actualizaciones del DNS pueden tardar más tiempo del esperado.
- Se configura un grupo de instancias administrado regional para la capa de procesamiento de visualización de datos con varias zonas, pero con recursos mínimos. Esto optimiza el costo, pero permite que las máquinas virtuales se escalen horizontalmente con rapidez.
- Se usa Cloud Storage regional como capa de etapa de pruebas para la transferencia inicial de datos, lo que proporciona resiliencia zonal automática.
- Se usa Dataflow para extraer datos de Cloud Storage y transformarlos antes de cargarlos en BigQuery. En caso de que ocurra una interrupción zonal, este es un proceso sin estado que se puede reiniciar en otra zona.
- BigQuery proporciona el backend del almacén de datos para el frontend de visualización de datos. Si se produce una interrupción zonal, se volverán a transferir los datos que se hayan perdido desde Cloud Storage.
Decisiones clave de arquitectura para la interrupción regional: RTO de 24 horas y RPO de 4 horas:
- Se usa un balanceador de cargas en cada región a fin de proporcionar un punto de acceso escalable para los usuarios. Se usa Cloud DNS para proporcionar capacidad de conmutación por error regional, organizada y manual, ya que la infraestructura en la región 2 solo estará disponible en caso de que se produzca una interrupción regional.
- Se configura un grupo de instancias administrado regional para la capa de procesamiento de visualización de datos con varias zonas, pero con recursos mínimos. No será accesible hasta que se vuelva a configurar el balanceador de cargas. Sin embargo, no se requiere una intervención manual.
- Se usa Cloud Storage regional como capa de etapa de pruebas para la transferencia inicial de datos. Se carga al mismo tiempo en ambas regiones para cumplir con los requisitos de RPO.
- Se usa Dataflow para extraer datos de Cloud Storage y transformarlos antes de cargarlos en BigQuery. Si se produce una interrupción regional, BigQuery se propagaría con los datos más recientes de Cloud Storage.
- BigQuery proporciona el backend del almacén de datos. En las operaciones normales, esto se actualiza de manera intermitente. Si se produce una interrupción regional, se vuelven a transferir los datos más recientes desde Cloud Storage mediante Dataflow.
Arquitectura de ejemplo de nivel 1
| Importancia de la aplicación | Interrupción zonal | Interrupción regional |
|---|---|---|
| Nivel 1 (más importante) |
RTO de cero RPO de cero |
RTO de 4 horas RPO de 1 hora |
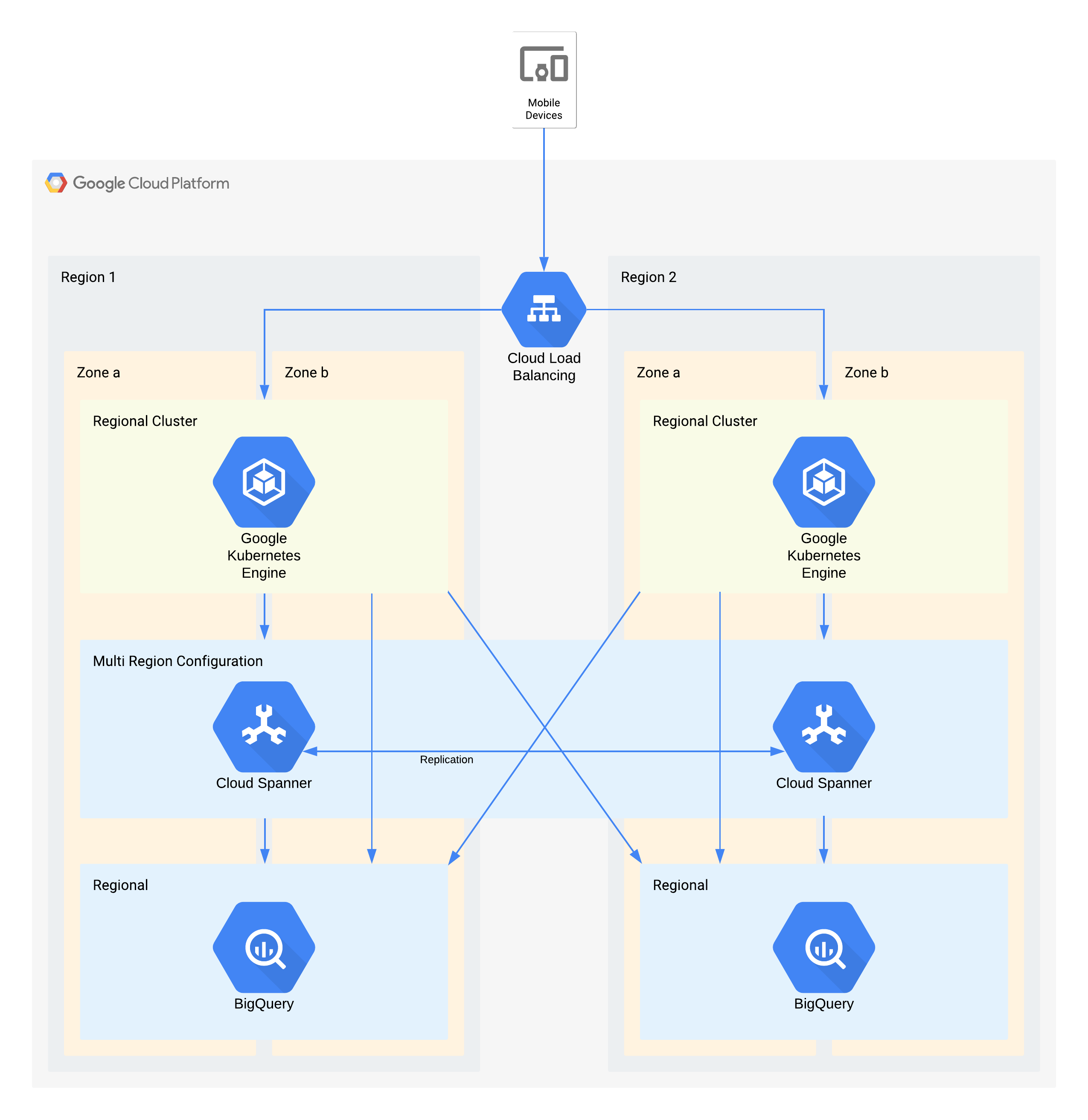
En esta arquitectura, se describe una infraestructura de backend de apps para dispositivos móviles con usuarios externos que se conectan a un conjunto de microservicios que se ejecutan en Google Kubernetes Engine. Cloud Spanner proporciona la capa de almacenamiento de datos de backend para los datos en tiempo real, y los datos históricos se transmiten a un data lake de BigQuery en cada región.
Otra vez, algunos componentes individuales de esta arquitectura no admiten directamente el RPO requerido para su nivel. Sin embargo, debido a cómo se usan en conjunto, el servicio general sí lo admite. En este caso, BigQuery se usa para consultas analíticas. Cada región recibe datos de forma simultánea desde Cloud Spanner.
Decisiones clave de arquitectura para la interrupción zonal: RTO de cero y RPO de cero:
- Se usa un balanceador de cargas a fin de proporcionar un punto de acceso escalable para los usuarios, lo que permite la conmutación por error automática a otra zona.
- Se usa un clúster regional de Google Kubernetes Engine para la capa de la aplicación que está configurada con varias zonas. Esto logra el RTO de cero dentro de cada región.
- Cloud Spanner multirregional se usa como capa de persistencia de datos y proporciona resiliencia automática de los datos de la zona y coherencia en la transacción.
- BigQuery proporciona la capacidad de crear estadísticas para la aplicación. Cada región recibe datos provenientes de Cloud Spanner de manera independiente y la aplicación accede a ellos de la misma forma.
Decisiones clave de arquitectura para la interrupción regional: RTO de 4 horas y RPO de 1 hora:
- Se usa un balanceador de cargas a fin de proporcionar un punto de acceso escalable para los usuarios, lo que permite la conmutación por error automática a otra región.
- Se usa un clúster regional de Google Kubernetes Engine para la capa de la aplicación que está configurada con varias zonas. Si se produce una interrupción regional, el clúster en la región alternativa se escala de manera automática para tomar la carga de procesamiento adicional.
- Se usa Cloud Spanner multirregional como capa de persistencia de datos, lo que proporciona resiliencia automática de los datos de la región y coherencia en la transacción. Este es el componente clave para lograr la RPO entre varias horas.
- BigQuery proporciona la capacidad de crear estadísticas para la aplicación. Cada región recibe datos provenientes de Cloud Spanner de manera independiente y la aplicación accede a ellos de la misma forma. Esta arquitectura compensa el componente de BigQuery, lo que le permite cumplir con los requisitos generales de la aplicación.
Apéndice: Referencia del producto
En esta sección, se describen la arquitectura y las capacidades de DR de los productos de Google Cloud que más se usan en las aplicaciones del cliente y que se pueden aprovechar con facilidad para cumplir con tus requisitos de DR.
Temas comunes
Muchos productos de Google Cloud ofrecen opciones de configuración regionales o multirregionales. Los productos regionales son resilientes a las interrupciones zonales, mientras que los productos globales y multirregionales son resilientes a las interrupciones regionales. En general, esto significa que, durante una interrupción, la aplicación experimenta interrupciones mínimas. Google logra estos resultados a través de algunos enfoques arquitectónicos comunes, que reflejan la guía de arquitectura anterior.
- Implementación redundante: Los backends de la aplicación y el almacenamiento de datos se implementan en varias zonas dentro de una región y en varias regiones dentro de una ubicación multirregional.
Replicación de datos: Los productos usan la replicación síncrona o asíncrona en las ubicaciones redundantes.
La replicación síncrona significa que, cuando tu aplicación realiza una llamada a la API para crear o modificar los datos que almacenó el producto, recibe una respuesta correcta solo una vez que el producto escribió los datos en varias ubicaciones. La replicación síncrona garantiza que no pierdas el acceso a ninguno de tus datos durante una interrupción en la infraestructura de Google Cloud porque todos están disponibles en una de las ubicaciones de backend disponibles.
Aunque esta técnica proporciona la máxima protección de los datos, puede tener compensaciones en términos de latencia y rendimiento. Los productos multirregionales que usan la replicación síncrona experimentan esta compensación de manera más significativa, por lo general, en décimas o centésimas de milisegundos de latencia adicional.
La replicación asíncrona significa que, cuando tu aplicación realiza una llamada a la API para crear o modificar los datos que almacenó el producto, recibe una respuesta correcta una vez que el producto escribió los datos en una sola ubicación. Luego de la solicitud de escritura, el producto replica los datos en ubicaciones adicionales.
Esta técnica proporciona una latencia menor y una capacidad de procesamiento más alta en la API que la replicación síncrona, pero a expensas de la protección de los datos. Si la ubicación en la que escribiste los datos sufre una interrupción antes de que se complete la replicación, perderás el acceso a esos datos hasta que la interrupción en la ubicación se resuelva.
Controla las interrupciones con el balanceo de cargas: Google Cloud usa el balanceo de cargas de software para enrutar las solicitudes a los backends de aplicaciones adecuados. En comparación con otros enfoques como el balanceo de cargas de DNS, este enfoque reduce el tiempo de respuesta del sistema a una interrupción. Cuando se produce una interrupción en una ubicación de Google Cloud, el balanceador de cargas detecta con rapidez que el backend implementado en esa ubicación se encuentra “en mal estado” y dirige todas las solicitudes a un backend en una ubicación alternativa. Esto permite que el producto siga entregando las solicitudes de tu aplicación durante una interrupción en la ubicación. Cuando se resuelve la interrupción en la ubicación, el balanceador de cargas detecta la disponibilidad de los backends del producto en esa ubicación y reanuda el envío de tráfico hacia allí.
Compute Engine
Compute Engine es la infraestructura como servicio de Google Cloud. Usa la infraestructura mundial de Google para ofrecer máquinas virtuales (y servicios relacionados) a los clientes.
Las instancias de Compute Engine son recursos zonales, por lo que, en caso de que se produzca una interrupción zonal, las instancias no están disponibles de forma predeterminada. Compute Engine ofrece grupos de instancias administrados (MIG) que, de forma automática, pueden escalar verticalmente VM adicionales desde plantillas de instancias preconfiguradas, tanto dentro de una sola zona como en varias zonas dentro de una región. Los MIG son ideales para las aplicaciones sin estado y que requieren resiliencia ante la pérdida zonal, pero que necesitan configuración y planificación de recursos. Se pueden usar varios MIG regionales a fin de lograr resiliencia ante interrupciones regionales para las aplicaciones sin estado.
Las aplicaciones que tienen cargas de trabajo con estado aún pueden usar MIG con estado (Beta), pero necesitan atención adicional en la planificación de la capacidad, ya que no se escalan horizontalmente. En ambos casos, es importante configurar y probar de manera correcta las plantillas de instancias y los MIG de Compute Engine con anticipación para garantizar que las funciones de conmutación por error funcionen en otras zonas. Consulta la sección anterior Patrones de arquitectura para obtener más información.
Dataproc
Dataproc proporciona capacidades de transmisión y procesamiento de datos por lotes. Dataproc se diseñó como un plano de control regional que permite a los usuarios administrar clústeres de Dataproc. El plano de control no depende de una zona individual en una región determinada. Por lo tanto, durante una interrupción zonal, conservas el acceso a las API de Dataproc, incluida la capacidad de crear clústeres nuevos.
Los clústeres se ejecutan en Compute Engine. Debido a que el clúster es un recurso zonal, una interrupción zonal hace que el clúster deje de estar disponible o lo destruye. Dataproc no realiza instantáneas del estado del clúster de forma automática, por lo que una interrupción zonal podría provocar la pérdida de datos que se están procesando. Dataproc no conserva datos del usuario dentro del servicio. Los usuarios pueden configurar sus canalizaciones para que escriban resultados en muchos almacenes de datos. Debes considerar la arquitectura del almacén de datos y elegir un producto que ofrezca la resiliencia ante desastres necesaria.
Si una zona sufre una interrupción, puedes volver a crear una instancia nueva del clúster en otra zona, ya sea si seleccionas una zona diferente o usas la función de posición automática en Dataproc para seleccionar de forma automática una zona disponible. Una vez que el clúster está disponible, se puede reanudar el procesamiento de datos. También puedes ejecutar un clúster con el modo de alta disponibilidad habilitado, lo que reduce la probabilidad de que una interrupción zonal parcial afecte un nodo principal y, por lo tanto, a todo el clúster.
Dataflow
Dataflow es el servicio de procesamiento de datos completamente administrado y sin servidores de Google Cloud para canalizaciones de transmisión y por lotes. Los trabajos de Dataflow son zonales por naturaleza y, en la configuración predeterminada, no conservan los resultados de los cálculos intermedios durante una interrupción zonal. Un enfoque de recuperación típico para esas canalizaciones predeterminadas de Dataflow es reiniciar el trabajo en una zona o una región diferente y volver a procesar los datos de entrada.
Diseña las canalizaciones de Dataflow para alta disponibilidad
En el caso de una interrupción zonal o regional, puedes evitar la pérdida de datos si vuelves a usar la misma suscripción en el tema de Pub/Sub. Como parte de la garantía exacta de Dataflow, Dataflow solo confirma los mensajes en Pub/Sub si se mantuvieron en el destino o si un mensaje pasó por una operación de agrupación o de sistema de ventanas de tiempo y se guardó en el estado de canalización duradero de Dataflow. Si no hay operaciones de agrupación o de sistema de ventanas de tiempo, una conmutación por error a otro trabajo de Dataflow en otra zona o región mediante el reúso de la suscripción no genera pérdida de datos en los datos de salida de la canalización.
Si la canalización usa la agrupación o el sistema de ventanas de tiempo, puedes usar la funcionalidad Búsqueda de Pub/Sub o Volver a reproducir de Kafka después de una interrupción zonal o regional para volver a procesar los elementos de datos a fin de llegar al mismo resultado de cálculo. La pérdida de datos de los resultados de la canalización se puede minimizar hasta 0 elementos si la lógica empresarial que usa la canalización se basa en los datos antes de la interrupción. Si la lógica empresarial de la canalización se basa en datos que se procesaron antes de la interrupción (por ejemplo, si se usan ventanas variables de larga duración o si un período global almacena contadores en aumento), Dataflow ofrece una función de captura de instantánea (por el momento en modo de vista previa) que proporciona una copia de seguridad de la instantánea del estado de una canalización.
BigQuery
BigQuery es un almacén de datos en la nube sin servidores, rentable y altamente escalable, diseñado para lograr agilidad empresarial. BigQuery admite dos opciones diferentes de configuración relacionadas con la disponibilidad para conjuntos de datos del usuario.
Configuración de una región única
En una configuración de una región única, los datos se almacenan de forma redundante en dos zonas dentro de una sola región. Los datos escritos en BigQuery primero se escriben en la zona principal y, luego, se replican de forma asíncrona en una zona secundaria. Esto protege contra la falta de disponibilidad de una zona única dentro de la región. Los datos que se escribieron en la zona principal, pero que no se replicaron en la zona secundaria en el momento en que se produjo una interrupción zonal, no están disponibles hasta que se resuelva la interrupción. En el caso poco probable de que se destruya una zona, es posible que los datos se pierdan de forma permanente.
Configuración multiregión (EE.UU. y UE)
Al igual que con la configuración de una región única, en la configuración multirregional de EE.UU y UE, los datos se almacenan de manera redundante en dos zonas dentro de una región. Además, BigQuery conserva una copia de seguridad adicional de los datos en una segunda región. Si la región principal experimenta una interrupción, los datos se entregan desde la región secundaria. Los datos que no se replicaron no estarán disponibles hasta que se restablezca la región principal.
Google Kubernetes Engine
Google Kubernetes Engine (GKE) ofrece el servicio administrado de Kubernetes mediante la optimización de la implementación de aplicaciones en contenedores en Google Cloud. Puedes elegir entre topologías de clústeres regionales o zonales.
- Cuando creas un clúster zonal, GKE aprovisiona una máquina de plano de control en la zona elegida, así como máquinas de trabajador (nodos) dentro de la misma zona.
- Para los clústeres regionales, GKE aprovisiona tres máquinas de plano de control en tres zonas diferentes dentro de la región elegida. De forma predeterminada, los nodos también están incluidos en tres zonas, aunque puedes elegir crear un clúster regional con nodos que se aprovisionan solo en una zona.
- Los clústeres multizonales son similares a los clústeres zonales, ya que incluyen una máquina principal y ofrecen la capacidad de incluir nodos de varias zonas.
Interrupción zonal: Para evitar interrupciones zonales, usa clústeres regionales. El plano de control y los nodos se distribuyen en tres zonas diferentes dentro de una región. Una interrupción zonal no afecta al plano de control y los nodos trabajadores que se implementan en las otras dos zonas.
Interrupción regional: La mitigación de una interrupción regional requiere la implementación en varias regiones. Aunque por el momento no se ofrece como una capacidad integrada de los productos, la topología multirregional es un enfoque que hoy en día usan muchos clientes de GKE y que se puede implementar de forma manual. Puedes crear varios clústeres regionales para replicar las cargas de trabajo en varias regiones y controlar el tráfico a estos clústeres mediante la entrada de varios clústeres.
Cloud Key Management Service
Cloud Key Management Service (Cloud KMS) proporciona la administración de recursos de claves criptográficas escalables y de alta durabilidad. Cloud KMS almacena todos sus datos y metadatos en las bases de datos de Cloud Spanner, que proporcionan alta durabilidad y disponibilidad de datos con replicación síncrona.
Los recursos de Cloud KMS pueden crearse en una sola región, en varias regiones o de forma global.
En el caso de una interrupción zonal, Cloud KMS continúa entregando solicitudes desde otra zona en la misma región o en otra sin interrupciones. Debido a que los datos se replican de forma síncrona, no hay pérdida ni corrupción de datos. Cuando se resuelve la interrupción zonal, se restablece la redundancia total.
Si se produce una interrupción regional, los recursos regionales de esa región se encuentran sin conexión hasta que esta vuelve a estar disponible. Ten en cuenta que, incluso dentro de una región, se mantienen al menos 3 réplicas en zonas diferentes. Cuando se requiere una mayor disponibilidad, los recursos deben almacenarse en una configuración multirregional o global. Las configuraciones globales y multirregionales están diseñadas para permanecer disponibles durante una interrupción regional mediante el almacenamiento y la entrega de datos con redundancia geográfica en más de una región.
Cloud Identity
Los servicios de Cloud Identity se distribuyen en varias regiones y usan el balanceo de cargas dinámico. Cloud Identity no permite que los usuarios seleccionen un alcance de recurso. Si una zona o una región en particular experimenta una interrupción, el tráfico se distribuye de manera automática a otras zonas o regiones.
En la mayoría de los casos, los datos persistentes se duplican en varias regiones con replicación síncrona. Por motivos de rendimiento, algunos sistemas, como las caché o los cambios que afectan a una gran cantidad de entidades, se replican de manera asíncrona en todas las regiones. Si la región principal en la que se almacenan los datos más recientes experimenta una interrupción, Cloud Identity entrega datos obsoletos desde otra ubicación hasta que la región principal esté disponible.
Persistent Disk
Los discos persistentes están disponibles en las configuraciones zonales y regionales.
Los discos persistentes zonales se alojan en una sola zona. Si la zona del disco no está disponible, Persistent Disk tampoco estará disponible hasta que se resuelva la interrupción zonal.
Los discos persistentes regionales proporcionan replicación síncrona de datos entre dos zonas de una región. Si se produce una interrupción en la zona de la máquina virtual, puedes forzar la conexión de un disco persistente regional a una instancia de VM en la zona secundaria del disco. Para ello, debes iniciar otra instancia de VM o mantener una instancia de VM en espera activa en esa zona.
Cloud Storage
Cloud Storage proporciona almacenamiento de objetos unificado, escalable y con alta durabilidad a nivel global. Los depósitos de Cloud Storage pueden crearse en una sola región, en regiones dobles o en varias regiones dentro de un continente.
Si una zona experimenta una interrupción, los datos en la zona no disponible se entregan de forma automática y transparente desde cualquier otro lugar de la región. Los datos y los metadatos se almacenan de manera redundante en todas las zonas, a partir de la escritura inicial. Las escrituras no se pierden cuando una zona deja de estar disponible.
En el caso de una interrupción regional, los depósitos regionales de esa región permanecen sin conexión hasta que la región vuelve a estar disponible. Cuando se requiere una mayor disponibilidad, debes considerar almacenar los datos en una configuración de región doble o múltiple. Las regiones dobles y múltiples están diseñadas para permanecer disponibles durante una interrupción regional mediante el almacenamiento de datos con redundancia geográfica en más de una región mediante la replicación asíncrona.
Cloud Storage usa Cloud Load Balancing para entregar depósitos de regiones dobles y múltiples desde varias regiones. Si se produce una interrupción regional, la entrega no se interrumpe. Debido a que la redundancia geográfica se logra de forma asíncrona, es posible que algunos datos escritos de manera reciente no sean accesibles durante la interrupción y podrían perderse si se produce una destrucción física de los datos en la región afectada.
Container Registry
Container Registry proporciona una implementación escalable y alojada de Docker Registry que almacena de forma segura y privada las imágenes de contenedor de Docker. Container Registry implementa la API de Docker Registry de HTTP.
Container Registry es un servicio global que almacena de forma síncrona los metadatos de imágenes de manera redundante en varias zonas y regiones según la configuración predeterminada. Las imágenes de contenedor se almacenan en depósitos multirregionales de Cloud Storage. Con esta estrategia de almacenamiento, Container Registry proporciona resiliencia ante interrupciones zonales en todos los casos y ante interrupciones regionales para cualquier dato que Cloud Storage haya replicado de manera asíncrona en varias regiones.
Pub/Sub
Pub/Sub es un servicio de mensajería para la integración de aplicaciones y las estadísticas de transmisiones. Los temas de Pub/Sub son globales, lo que significa que son visibles y accesibles desde cualquier ubicación de Google Cloud. Sin embargo, todos los mensajes se almacenan en una sola región de Google Cloud, la más cercana al publicador y la que permita la política de ubicación de recursos. Por lo tanto, un tema puede tener mensajes almacenados en diferentes regiones en Google Cloud. La política de almacenamiento de mensajes de Pub/Sub puede restringir las regiones en las que se almacenan los mensajes.
Interrupción zonal: Cuando se publica un mensaje de Pub/Sub, se escribe de forma síncrona en el almacenamiento en al menos dos zonas dentro de la región. Por lo tanto, si una sola zona deja de estar disponible, no se produce un impacto visible para el cliente.
Interrupción regional: Durante una interrupción regional, no se puede acceder a los mensajes almacenados dentro de la región afectada. Las operaciones administrativas, como la creación y la eliminación de temas y suscripciones, son multirregionales y resilientes ante la interrupción de cualquier región única de Google Cloud. Las operaciones de publicación también son resilientes ante las interrupciones regionales, siempre que esté disponible al menos una región permitida por la política de almacenamiento de mensajes y tu aplicación use el extremo global (pubsub.googleapis.com) o varios extremos regionales.
De forma predeterminada, Pub/Sub no restringe la ubicación de almacenamiento de mensajes.
Si tu aplicación se basa en el ordenamiento de los mensajes, revisa las recomendaciones detalladas del equipo de Pub/Sub. Las garantías de ordenamiento de mensajes se proporcionan por región y pueden interrumpirse si usas un extremo global.
Cloud Composer
Cloud Composer es la implementación administrada de Apache Airflow de Google Cloud. Cloud Composer está diseñado como un plano de control regional que permite a los usuarios administrar clústeres de Cloud Composer. El plano de control no depende de una zona individual en una región determinada. Por lo tanto, durante una interrupción zonal, conservas el acceso a las API de Cloud Composer, incluida la capacidad de crear clústeres nuevos.
Los clústeres se ejecutan en Google Kubernetes Engine. Debido a que el clúster es un recurso zonal, una interrupción zonal hace que el clúster deje de estar disponible o lo destruye. Es posible que los flujos de trabajo que se están ejecutando al momento de la interrupción se interrumpan antes de completarse. Esto significa que la interrupción provoca la pérdida del estado de los flujos de trabajo ejecutados de manera parcial, incluidas las acciones externas que el usuario configuró para completar el flujo de trabajo. Según el flujo de trabajo, esto puede causar inconsistencias externas, por ejemplo, si el flujo de trabajo se detiene en la mitad de una ejecución de varios pasos para modificar los almacenes de datos externos. Por lo tanto, debes considerar el proceso de recuperación cuando diseñes tu flujo de trabajo de Airflow, incluidos cómo detectar estados de flujos de trabajo ejecutados de manera parcial, cómo reparar cambios de datos parciales, etcétera.
Durante una interrupción zonal, puedes elegir usar Cloud Composer para iniciar una instancia nueva del clúster en otra zona. Una vez que el clúster está disponible, se puede reanudar el flujo de trabajo. Según tus preferencias, es posible que quieras ejecutar un clúster de réplica inactivo en otra zona y cambiar a esa réplica en caso de que ocurra una interrupción zonal.
Cloud SQL
Cloud SQL es un servicio de base de datos relacional completamente administrado para MySQL, PostgreSQL y SQL Server. Cloud SQL usa máquinas virtuales administradas de Compute Engine para ejecutar el software de base de datos. Ofrece una configuración de alta disponibilidad para la redundancia regional, lo que protege la base de datos ante una interrupción zonal. Las réplicas entre regiones pueden aprovisionarse para proteger la base de datos ante una interrupción regional. Debido a que el producto también ofrece una opción zonal, que no es resiliente ante una interrupción zonal o regional, debes tener cuidado cuando seleccionas la configuración de alta disponibilidad, las réplicas entre regiones o ambas.
Interrupción zonal: La opción de alta disponibilidad crea una instancia de VM principal y en espera en dos zonas distintas dentro de una región. Durante el funcionamiento normal, la instancia de VM principal entrega todas las solicitudes y escribe los archivos de la base de datos en un disco persistente regional, que se replica de forma síncrona en las zonas principal y de espera. Si una interrupción zonal afecta a la instancia principal, Cloud SQL inicia una conmutación por error durante la cual el disco persistente se conecta a la VM en espera y el tráfico se redirige.
Durante este proceso, se debe inicializar la base de datos, lo que incluye el procesamiento de cualquier transacción escrita en el registro de transacciones, pero que no está aplicada a la base de datos. La cantidad y el tipo de transacciones sin procesar pueden aumentar el tiempo de RTO. Las operaciones de escritura recientes pueden provocar una acumulación de transacciones sin procesar. El tiempo de RTO se ve muy afectado por (a) la actividad de escritura reciente y (b) los cambios recientes en los esquemas de base de datos.
Por último, cuando se resuelve la interrupción zonal, puedes activar de forma manual una operación de recuperación para reanudar la entrega en la zona principal.
Para obtener más detalles sobre la opción de alta disponibilidad, consulta la documentación de alta disponibilidad de Cloud SQL.
Interrupción regional: La opción de réplica entre regiones protege tu base de datos ante las interrupciones regionales mediante la creación de réplicas de lectura de la instancia principal en otras regiones. La replicación entre regiones usa la replicación asíncrona, que permite que la instancia principal confirme las transacciones antes de que se confirmen en las réplicas. La diferencia de tiempo entre el momento en que una transacción se confirma en la instancia principal y en que se confirma en la réplica se conoce como “demora de replicación” (que se puede supervisar). Esta métrica refleja las transacciones que no se enviaron desde la instancia principal a las réplicas y las que se recibieron, pero que aún la réplica no procesó. Las transacciones que no se envíen a la réplica no estarán disponibles durante una interrupción regional. Las transacciones recibidas que la réplica aún no procesó afectan el tiempo de recuperación, como se describe a continuación.
Cloud SQL recomienda probar la carga de trabajo con una configuración que incluya una réplica para establecer un límite de “seguro de transacciones por segundo(TPS)”, que es el TPS continuo más alto que no acumula demora de replicación. Si la carga de trabajo excede el límite seguro de TPS, la demora de replicación se acumula, lo que afecta de manera negativa los valores de RPO y RTO. Como regla general, evita usar configuraciones de instancias pequeñas (<2 núcleos de CPU virtual, <100 GB de disco o HDD de PD), que son susceptibles a las demoras de replicación.
Si se produce una interrupción regional, debes decidir si promueves una réplica de lectura de forma manual. Esta es una operación manual, ya que la promoción puede causar una situación de cerebro dividido en la que la réplica promocionada acepta transacciones nuevas a pesar de que haber demorado la instancia principal en el momento de la promoción. Esto puede causar problemas cuando se resuelve la interrupción regional y deberás conciliar las transacciones que nunca se propagaron de la instancia principal a las réplicas. Si esto resulta problemático para tus necesidades, puedes considerar usar un producto de base de datos de replicación síncrona entre regiones como Cloud Spanner.
Una vez que el usuario lo activa, el proceso de promoción sigue pasos similares a la de una instancia en espera en la configuración de alta disponibilidad: la réplica de lectura debe procesar el registro de transacciones y el balanceador de cargas debe redireccionar el tráfico. El procesamiento del registro de transacciones controla el tiempo total de recuperación.
Para obtener más detalles sobre la opción de réplica entre regiones, consulta la documentación de réplica entre regiones de Cloud SQL.
Cloud Logging
Cloud Logging consta de dos partes principales: el enrutador de registros y el almacenamiento de Cloud Logging.
El enrutador de registros controla los eventos de registros de transmisión y dirige los registros a Cloud Storage, Pub/Sub, BigQuery o al almacenamiento de Cloud Logging.
El almacenamiento de Cloud Logging es un servicio para almacenar, consultar y administrar el cumplimiento de los registros. Es compatible con muchos usuarios y flujos de trabajo, incluidos el desarrollo, el cumplimiento, la solución de problemas y las alertas proactivas.
Enrutador de registros y registros entrantes: Durante una interrupción zonal, la API de Cloud Logging enruta los registros a otras zonas de la región. Por lo general, los registros que enruta el enrutador de registros a Cloud Logging, BigQuery o Pub/Sub se escriben en su destino final lo antes posible, mientras que los registros enviados a Cloud Storage se almacenan en el búfer y se escriben en lotes por hora.
Entradas de registro: Si se produce una interrupción zonal o regional, las entradas de registro que se almacenaron en el búfer de la zona o la región afectada y que no se escribieron en el destino de exportación se vuelven inaccesibles. Las métricas basadas en registros también se calculan en el enrutador de registros y están sujetas a las mismas restricciones. Una vez que se entregan a la ubicación de exportación de registros seleccionada, los registros se replican según el servicio de destino. Los registros que se exportan al almacenamiento de Cloud Logging se replican de forma síncrona en dos zonas de una región. Para obtener información sobre el comportamiento de replicación de otros tipos de destino, consulta la sección relevante en este artículo. Ten en cuenta que los registros exportados a Cloud Storage se agrupan por lotes y se escriben cada hora. Por lo tanto, recomendamos usar el almacenamiento de Cloud Logging, BigQuery o Pub/Sub para minimizar la cantidad de datos afectados por una interrupción.
Metadatos de registro: Los metadatos como la configuración de receptores y de la exclusión se almacenan a nivel global, pero en caché a nivel regional. Si se produce una interrupción, las instancias regionales del enrutador de registros operarían. Las interrupciones en una sola región no tienen impacto fuera de la región.
Cloud Spanner
Cloud Spanner es una base de datos escalable, con alta disponibilidad, de varias versiones, replicada de forma síncrona y muy coherente con semánticas relacionales.
Las instancias regionales de Cloud Spanner replican los datos de forma síncrona en tres zonas de una sola región. Una operación de escritura a una instancia regional de Cloud Spanner se envía de forma síncrona a las 3 réplicas y se confirma en el cliente después de que al menos 2 réplicas (quórum de mayoría de 2 de 3) confirman la escritura. Esto hace que Cloud Spanner sea resistente a una falla de zona, ya que proporciona acceso a todos los datos, ya que las escrituras más recientes persisten y se puede obtener un quórum mayor para las escrituras con 2 réplicas.
Las instancias multirregionales de Cloud Spanner incluyen un quórum de escritura que replica datos de forma síncrona en 5 zonas ubicadas en 3 regiones (2 réplicas de lectura y escritura cada una en la región líder predeterminada y otra región; y una réplica en la región testigo). Una operación de escritura en una instancia multirregional de Cloud Spanner se confirma después de que al menos 3 réplicas (quórum de mayoría de 3 de 5) hayan confirmado la escritura. En el caso de una falla de zona o región, Cloud Spanner tiene acceso a todos los datos (incluidas las escrituras más recientes) y entrega solicitudes de lectura y escritura, ya que los datos se conservan en al menos 3 zonas en 2 regiones en el momento en que la escritura se confirma al cliente.
Consulta la documentación de las instancias de Cloud Spanner para obtener más información sobre estas configuraciones y la documentación de replicación a fin de obtener más información sobre cómo funciona la replicación.