이 튜토리얼에서는 Google Cloud에서 R을 사용하여 대규모 데이터 과학을 시작하는 방법을 보여줍니다. 이 튜토리얼은 R 및 Jupyter 노트북 사용 경험이 있고 SQL에 익숙한 사용자를 대상으로 작성되었습니다.
이 튜토리얼에서는 Vertex AI Workbench 사용자 관리 노트북과 BigQuery를 사용하여 탐색 데이터 분석을 수행하는 방법을 중점적으로 설명합니다. GitHub의 Jupyter 노트북에서 이 튜토리얼의 코드를 찾을 수 있습니다.
개요
R은 통계 모델링에 가장 널리 사용되는 프로그래밍 언어 중 하나이며 데이터 과학자와 머신러닝(ML) 전문가를 아우르는 대규모 커뮤니티입니다. Comprehensive R Archive Network(CRAN) 오픈소스 저장소에 패키지가 15,000개 이상 있는 R에는 모든 통계 데이터 분석 애플리케이션, ML, 시각화용 도구가 있습니다. R은 문법 표현 및 포괄적인 데이터와 ML 라이브러리의 양으로 인해 지난 20년 동안 꾸준하게 성장하고 있습니다.
데이터 과학자로서 여러분은 R을 사용하여 역량을 어떻게 활용할 수 있는지, 그리고 ML을 위한 확장 가능한 완전 관리형 클라우드 서비스의 이점도 어떻게 활용할 수 있는지를 알아볼 수 있습니다.
아키텍처
이 튜토리얼에서는 사용자 관리 노트북을 데이터 과학 환경으로 사용하여 탐색적 데이터 분석(EDA)을 수행합니다. 확장성과 경제성이 뛰어난 Google의 서버리스 클라우드 데이터 웨어하우스인 BigQuery에서 이 튜토리얼의 일부로서 추출하는 데이터에 R을 사용합니다. 데이터를 분석하고 처리하면, 변환된 데이터가 추가 ML 작업을 위해 Cloud Storage에 저장됩니다. 이 흐름은 다음 다이어그램에 나와 있습니다.
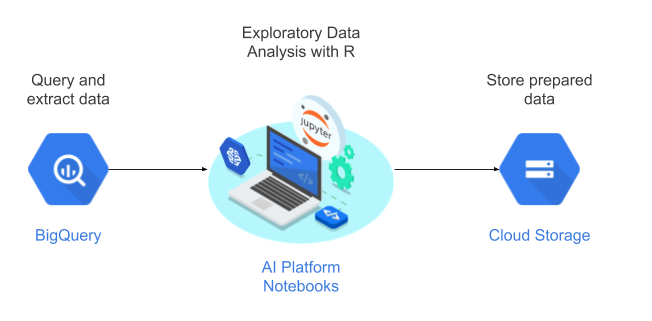
튜토리얼용 데이터
이 튜토리얼에서 사용되는 데이터 세트는 BigQuery 출생률 데이터 세트입니다. 이 공개 데이터 세트에는 1969년부터 2008년까지 미국에 등록된 1억 3천 7백만 명 이상의 출생 정보가 포함되어 있습니다.
이 튜토리얼에서는 EDA 및 R과 BigQuery를 사용한 시각화에 중점을 둡니다. 이 튜토리얼에서는 임신 및 산모와 관련된 여러 가지 요소를 바탕으로 아기 체중을 예측하는 머신러닝 목표를 설정합니다. 하지만 태스크를 취급하지 않습니다.
사용자 관리 노트북
Vertex AI Workbench 사용자 관리 노트북은 다음과 같은 기능을 포함한 통합 JupyterLab 환경을 제공하는 서비스입니다.
- 클릭 한 번으로 배포. 클릭 한 번으로 최신 머신러닝 및 데이터 과학 프레임워크로 사전 구성된 JupyterLab 인스턴스를 시작할 수 있습니다.
- 필요에 따라 규모 조정. 작은 머신 구성(예: 이 튜토리얼에서와 같이 vCPU 4개, RAM 15GB)으로 시작할 수 있으며, 데이터가 한 머신에 비해 너무 커지면 CPU, RAM, GPU를 추가하여 규모를 확장할 수 있습니다.
- Google Cloud 통합. Vertex AI Workbench 사용자 관리 노트북 인스턴스는 BigQuery와 같은 Google Cloud 서비스와 통합됩니다. 이 통합으로 인해 데이터 수집부터 사전 처리와 탐색까지 간편하게 진행할 수 있습니다.
- 사용량에 따른 청구. 최소 수수료나 선불 약정이 없이 Vertex AI Workbench 사용자 관리 노트북 가격 책정을 참조하세요. 사용자 관리 노트북 인스턴스와 함께 사용하는 Google Cloud 리소스에도 요금이 부과됩니다.
사용자 관리 노트북은 Deep Learning VM Image에서 실행됩니다. 이러한 이미지는 PyTorch 및 TensorFlow와 같은 ML 프레임워크를 지원하도록 최적화되어 있습니다. 이 튜토리얼에서는 R 3.6을 사용하는 사용자 관리 노트북 인스턴스 만들기를 지원합니다.
R을 사용하여 BigQuery로 작업
BigQuery는 인프라 관리가 필요하지 않으므로 의미 있는 정보를 찾는 데 집중할 수 있습니다. BigQuery를 사용하면 익숙한 SQL로 데이터를 작업할 수 있으므로 데이터베이스 관리자가 필요하지 않습니다. BigQuery를 사용하여 대량의 데이터를 대규모로 분석하고 BigQuery의 풍부한 SQL 분석 기능을 사용하여 ML용 데이터 세트를 준비할 수 있습니다.
R을 사용하여 BigQuery 데이터를 쿼리하려면 오픈소스 R 라이브러리인 bigrquery를 사용하면 됩니다. bigrquery 패키지는 BigQuery를 기반으로 다음과 같은 추상화 수준을 제공합니다.
하위 수준 API는 기본 BigQuery REST API를 통해 씬 래퍼를 제공합니다.
DBI 인터페이스는 하위 수준의 API를 래핑하며 이 인터페이스를 사용하면 다른 데이터베이스 시스템으로 작업과 비슷하게 BigQuery로 작업할 수 있습니다. 이 방식은 BigQuery에서 SQL 쿼리를 실행하거나 100MB 미만을 업로드하려는 경우에 가장 편리한 레이어입니다.
dbplir 인터페이스를 사용하면 BigQuery 테이블을 메모리 내 데이터 프레임처럼 취급할 수 있습니다. SQL을 작성하는 대신 dbplir이 작성하게 하려는 경우 가장 편리한 레이어입니다.
이 튜토리얼은 DBI 또는 dbplyr을 요구하지 않고 bigrquery의 하위 수준 API를 사용합니다.
목표
- R을 지원하는 사용자 관리 노트북 인스턴스를 만들기
- bigrquery R 라이브러리를 사용하여 BigQuery에서 데이터를 쿼리하고 분석하기
- Cloud Storage에서 ML용 데이터를 준비하고 저장하기
비용
이 문서에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud 구성요소를 사용합니다.
- BigQuery
- Vertex AI Workbench user-managed notebooks instance. You are also charged for resources used within notebooks, including compute resources, BigQuery, and API requests.
- Cloud Storage
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
R로 사용자 관리 노트북 인스턴스 만들기
첫 번째 단계는 이 튜토리얼에서 사용할 수 있는 사용자 관리 노트북 인스턴스를 만드는 것입니다.
Google Cloud Console에서 Notebooks 페이지로 이동합니다.
사용자 관리 노트북 탭에서 새 노트북을 클릭합니다.
R 3.6을 선택합니다.
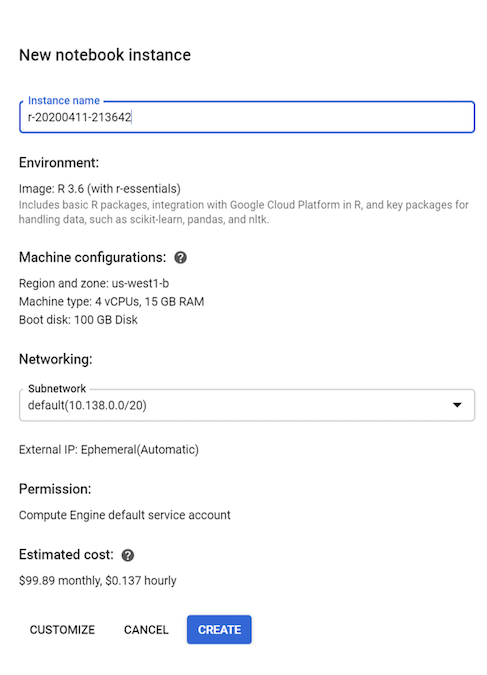
이 튜토리얼에서는 모든 기본값을 그대로 두고 만들기를 클릭합니다.
사용자 관리 노트북 인스턴스를 시작하는 데 최대 90초가 걸릴 수 있습니다. 준비가 되면 메모장 인스턴스 창의 인스턴스 이름 옆에 JupyterLab 열기 링크가 표시됩니다.
JupyterLab 열기
노트북에서 튜토리얼을 진행하려면 JupyterLab 환경을 열고 ml-on-gcp GitHub 저장소를 복제한 다음 노트북을 열어야 합니다.
인스턴스 목록에서 Jupyterlab 열기를 클릭합니다. 그러면 브라우저에서 JupyterLab 환경이 열립니다.
터미널 탭을 실행하려면 런처에서 터미널을 클릭합니다.
터미널에서
ml-on-gcpGitHub 저장소를 클론합니다.git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git명령어가 완료되면 파일 브라우저에
ml-on-gcp폴더가 표시됩니다.파일 브라우저에서
ml-on-gcp,tutorials,R.을 차례로 엽니다.클론 결과는 다음과 같습니다.
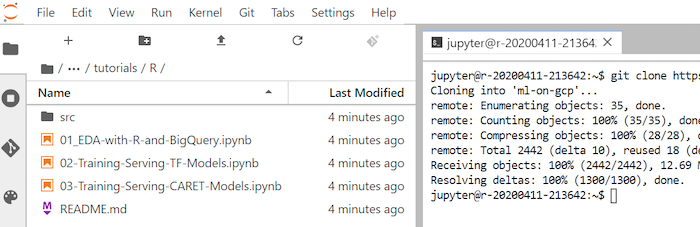
노트북 열기 및 R 설정
bigrquery를 포함하여 이 튜토리얼에 필요한 R 라이브러리는 기본적으로 R 노트북에 설치됩니다. 이 절차의 일부로서 라이브러리를 가져와 노트북에서 사용할 수 있도록 합니다.
파일 브라우저에서
01-EDA-with-R-and-BigQuery.ipynb노트북을 엽니다.이 노트북은 R 및 BigQuery를 사용한 탐색적 데이터 분석 튜토리얼을 다룹니다. 튜토리얼의 이 시점에서 노트북에서 작업하고 Jupyter 노트북 자체에 표시되는 코드를 실행합니다.
이 튜토리얼에 필요한 R 라이브러리를 가져옵니다.
library(bigrquery) # used for querying BigQuery library(ggplot2) # used for visualization library(dplyr) # used for data wrangling대역 외 인증을 사용하여
bigrquery를 인증합니다.bq_auth(use_oob = True)변수를 이 튜토리얼에 사용할 프로젝트의 이름으로 설정합니다.
# Set the project ID PROJECT_ID <- "gcp-data-science-demo"변수를 Cloud Storage 버킷 이름으로 설정합니다.
BUCKET_NAME <- "bucket-name"
bucket-name을 전역적으로 고유한 이름으로 바꿉니다.
나중에 버킷을 사용하여 출력 데이터를 저장합니다.
BigQuery에서 데이터 쿼리
이 튜토리얼 섹션에서는 BigQuery SQL 문을 R로 실행한 결과를 읽고 데이터를 미리 살펴봅니다.
2000년 이후 출생 샘플에 대한 몇 가지 가능한 예측 변수와 타겟 예측 변수를 추출하는 BigQuery SQL 문을 만듭니다.
sql_query <- " SELECT ROUND(weight_pounds, 2) AS weight_pounds, is_male, mother_age, plurality, gestation_weeks, cigarette_use, alcohol_use, CAST(ABS(FARM_FINGERPRINT(CONCAT( CAST(YEAR AS STRING), CAST(month AS STRING), CAST(weight_pounds AS STRING))) ) AS STRING) AS key FROM publicdata.samples.natality WHERE year > 2000 AND weight_pounds > 0 AND mother_age > 0 AND plurality > 0 AND gestation_weeks > 0 AND month > 0 LIMIT %s "key열은year,month,weight_pounds열의 연결된 값을 기반으로 생성된 행 식별자입니다.쿼리를 실행하고 데이터를 인메모리
data frame객체로 검색합니다.sample_size <- 10000 sql_query <- sprintf(sql_query, sample_size) natality_data <- bq_table_download( bq_project_query( PROJECT_ID, query=sql_query ) )검색된 결과 보기:
head(natality_data)출력은 다음과 비슷합니다.
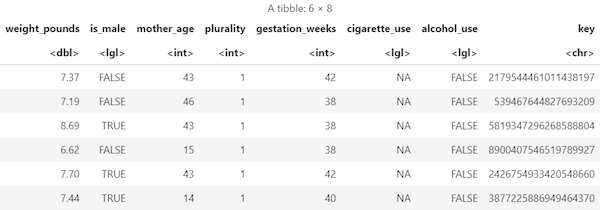
각 열의 행 수와 데이터 유형을 봅니다.
str(natality_data)출력은 다음과 비슷합니다.
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 10000 obs. of 8 variables: $ weight_pounds : num 7.75 7.4 6.88 9.38 6.98 7.87 6.69 8.05 5.69 9.22 ... $ is_male : logi FALSE TRUE TRUE TRUE FALSE TRUE ... $ mother_age : int 47 44 42 43 42 43 42 43 45 44 ... $ plurality : int 1 1 1 1 1 1 1 1 1 1 ... $ gestation_weeks: int 41 39 38 39 38 40 35 40 38 39 ... $ cigarette_use : logi NA NA NA NA NA NA ... $ alcohol_use : logi FALSE FALSE FALSE FALSE FALSE FALSE ... $ key : chr "3579741977144949713" "8004866792019451772" "7407363968024554640" "3354974946785669169" ...
검색된 데이터의 요약 보기:
summary(natality_data)출력은 다음과 비슷합니다.
weight_pounds is_male mother_age plurality Min. : 0.620 Mode :logical Min. :13.0 Min. :1.000 1st Qu.: 6.620 FALSE:4825 1st Qu.:22.0 1st Qu.:1.000 Median : 7.370 TRUE :5175 Median :27.0 Median :1.000 Mean : 7.274 Mean :27.3 Mean :1.038 3rd Qu.: 8.110 3rd Qu.:32.0 3rd Qu.:1.000 Max. :11.440 Max. :51.0 Max. :4.000 gestation_weeks cigarette_use alcohol_use key Min. :18.00 Mode :logical Mode :logical Length:10000 1st Qu.:38.00 FALSE:580 FALSE:8284 Class :character Median :39.00 TRUE :83 TRUE :144 Mode :character Mean :38.68 NA's :9337 NA's :1572 3rd Qu.:40.00 Max. :47.00
ggplot2를 사용하여 데이터 시각화
이 섹션에서는 R의 ggplot2 라이브러리를 사용하여 natality 데이터 세트의 일부 변수를 살펴봅니다.
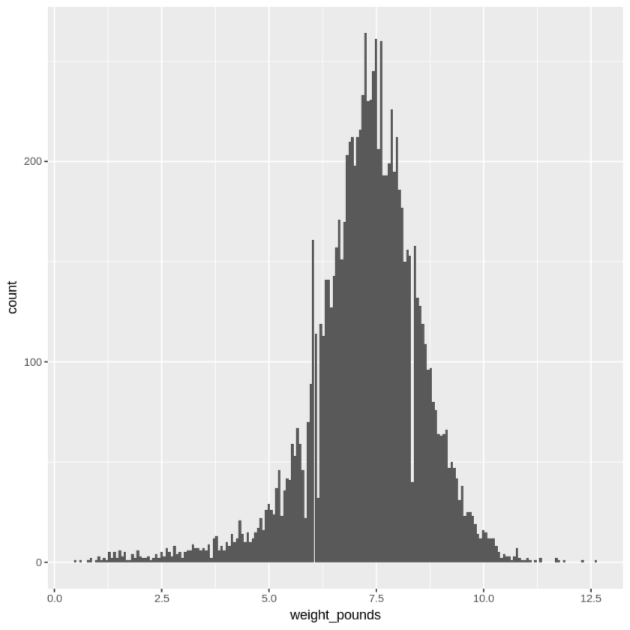
히스토그램을 사용하여
weight_pounds값의 분포를 표시합니다.ggplot( data = natality_data, aes(x = weight_pounds) ) + geom_histogram(bins = 200)결과 그래프는 다음과 유사합니다.
분산형 그래프를 사용하여
gestation_weeks와weight_pounds의 관계를 표시합니다.ggplot( data = natality_data, aes(x = gestation_weeks, y = weight_pounds) ) + geom_point() + geom_smooth(method = "lm")결과 그래프는 다음과 유사합니다.
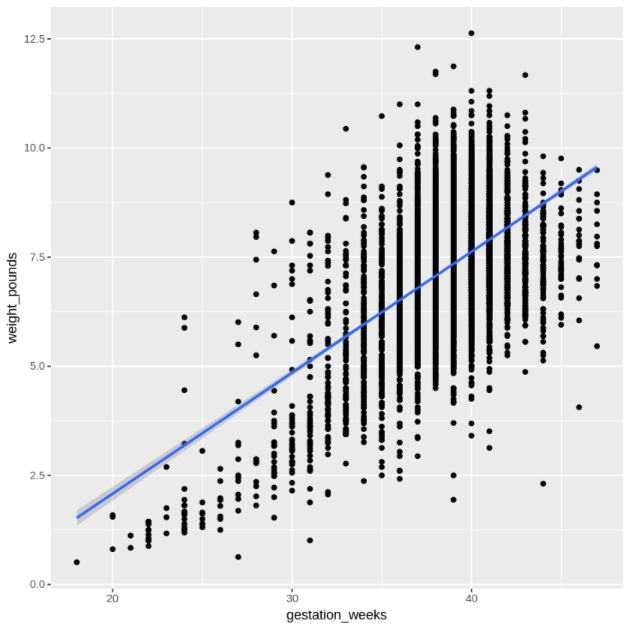
R에서 BigQuery의 데이터 처리
대규모 데이터세트로 작업하는 경우 BigQuery에서 최대한 많은 분석(집계, 필터링, 조인, 열 계산 등)을 수행한 후 결과를 검색하는 것이 좋습니다. R에서 이러한 태스크를 수행하는 것은 보다 비효율적입니다. 분석에 BigQuery를 사용하면 BigQuery의 확장성과 성능을 활용할 수 있고 반환된 결과가 R의 메모리에 적합한지 확인할 수 있습니다.
선택한 열의 각 값에 대한 레코드 수와 평균 몸무게를 찾는 함수를 만듭니다.
get_distinct_values <- function(column_name) { query <- paste0( 'SELECT ', column_name, ', COUNT(1) AS num_babies, AVG(weight_pounds) AS avg_wt FROM publicdata.samples.natality WHERE year > 2000 GROUP BY ', column_name) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }mother_age열을 사용하여 이 함수를 호출한 다음 산모 연령별 아기 수 및 평균 몸무게를 확인합니다.df <- get_distinct_values('mother_age') ggplot(data = df, aes(x = mother_age, y = num_babies)) + geom_line() ggplot(data = df, aes(x = mother_age, y = avg_wt)) + geom_line()첫 번째
ggplot명령어의 출력은 다음과 같으며, 산모 연령별 출생 아기의 수를 보여줍니다.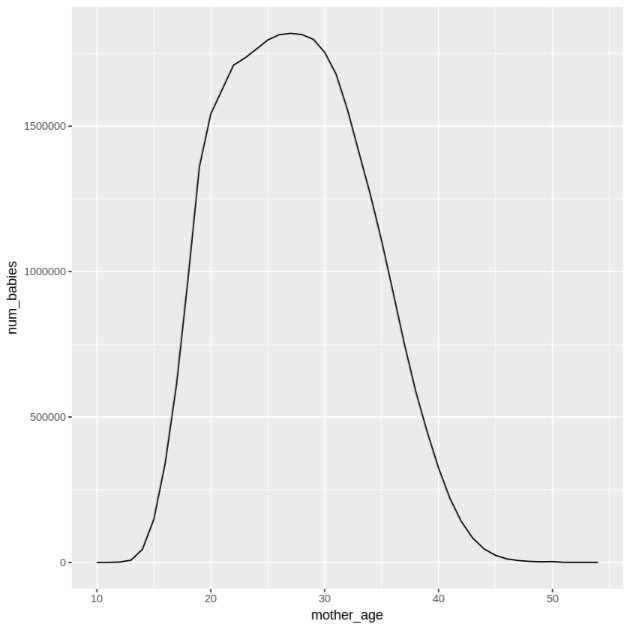
두 번째
ggplot명령어의 출력은 다음과 같으며, 산모 연령별 아기의 평균 몸무게를 보여줍니다.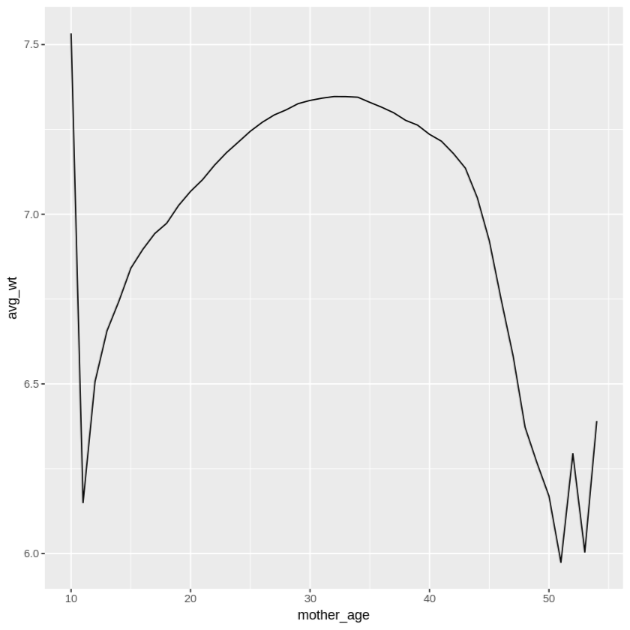
더 많은 시각화 예시를 보려면 Notebooks를 참조하세요.
데이터를 CSV 파일로 저장
다음 작업은 BigQuery에서 추출된 데이터를 추가 ML 작업에 사용할 수 있도록 Cloud Storage에 CSV 파일로 저장하는 것입니다.
학습 및 평가 데이터를 BigQuery에서 R로 로드합니다.
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query, sample_size) train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )데이터를 로컬 CSV 파일에 씁니다.
# Write data frames to local CSV files, without headers or row names dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = FALSE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = FALSE, sep = ",")시스템에 전달되는
gsutil명령어를 래핑하여 CSV 파일을 Cloud Storage에 업로드합니다.# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)이 단계의 또 다른 옵션은 Cloud Storage JSON API를 사용하여 이 작업에 googleCloudStorageR 라이브러리를 사용하는 것입니다.
삭제
이 튜토리얼에서 사용한 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 관련 리소스를 삭제해야 합니다.
프로젝트 삭제
청구되지 않도록 하는 가장 쉬운 방법은 튜토리얼에서 만든 프로젝트를 삭제하는 것입니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
- bigrquery 문서에서 R 노트북의 BigQuery 데이터를 사용하는 방법 알아보기
- ML 규칙에서 ML 엔지니어링 권장사항 알아보기
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항을 살펴보기 Cloud 아키텍처 센터 살펴보기