Tutorial ini menunjukkan cara memulai data science dalam skala besar menggunakan R di Google Cloud. Tutorial ini ditujukan bagi mereka yang memiliki pengalaman menggunakan R dan netbook Jupyter, serta terbiasa menggunakan SQL.
Tutorial ini berfokus pada menjalankan analisis data eksploratif menggunakan notebook Vertex AI Workbench yang dikelola pengguna dan BigQuery. Anda dapat menemukan kode untuk tutorial ini di Jupyter notebook yang ada di GitHub.
Ringkasan
R merupakan salah satu bahasa pemrograman yang paling banyak digunakan untuk pemodelan statistik. Bahasa pemrograman ini memiliki komunitas data scientist dan tenaga profesional machine learning (ML). Dengan lebih dari 15.000 paket di repositori open source Comprehensive R Archive Network (CRAN), R memiliki alat untuk semua aplikasi analisis data statistik, ML, dan visualisasi. R telah mengalami pertumbuhan yang stabil dalam dua dekade terakhir karena sintaksisnya yang ekspresif serta data dan library ML yang komprehensif.
Sebagai data scientist, Anda mungkin ingin mengetahui cara memanfaatkan keahlian Anda dengan menggunakan R serta cara memanfaatkan keunggulan layanan cloud yang skalabel dan terkelola sepenuhnya untuk ML.
Arsitektur
Dalam tutorial ini, Anda akan menggunakan notebook yang dikelola pengguna sebagai lingkungan data science untuk melakukan analisis data eksploratif (EDA). Anda akan menggunakan R untuk menganalisis data yang diekstrak sebagai bagian dari tutorial ini dari BigQuery, yang merupakan cloud data warehouse (CDW) Google yang serverless, sangat skalabel, dan hemat biaya. Setelah Anda menganalisis dan memproses data, data yang ditransformasi disimpan di Cloud Storage untuk tugas ML lebih lanjut. Alur ini ditunjukkan dalam diagram berikut:
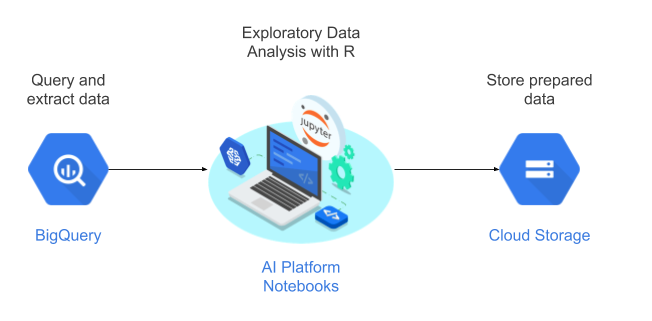
Data untuk tutorial
Set data yang digunakan dalam tutorial ini adalah set data kelahiran BigQuery. Data set publik ini mencakup informasi tentang 137 juta lebih kelahiran yang terdaftar di Amerika Serikat dari tahun 1969 hingga 2008.
Tutorial ini berfokus pada EDA dan visualisasi yang menggunakan R dan BigQuery. Tutorial ini membantu Anda untuk mencapai tujuan pembelajaran machine-learning guna memprediksi berat bayi dengan mempertimbangkan sejumlah faktor tentang kehamilan dan ibu bayi, meskipun tugas tersebut tidak dibahas dalam tutorial ini.
Notebook yang dikelola pengguna
Notebook Vertex AI Workbench yang dikelola pengguna merupakan layanan yang menawarkan lingkungan JupyterLab terintegrasi, dengan fitur berikut:
- Deployment sekali klik. Anda dapat menggunakan satu klik untuk memulai JupyterLab instance yang sebelumnya telah dikonfigurasi dengan framework terbaru machine-learning dan data-science.
- Skala sesuai permintaan. Anda dapat memulainya dengan konfigurasi mesin kecil (misalnya, 4 vCPU dan 15 GB RAM, seperti dalam tutorial ini), dan saat data menjadi terlalu besar, Anda bisa meningkatkan skalanya dengan menambah CPU, RAM, and GPU.
- Integrasi Google Cloud. Instance notebook Vertex AI Workbench yang dikelola pengguna diintegrasikan dengan layanan Google Cloud seperti BigQuery. Integrasi ini memudahkan Anda beralih dari penyerapan data ke prapemrosesan dan eksplorasi.
- Harga sesuai penggunaan. Tidak ada biaya minimum atau komitmen di awal. Lihat harga untuk notebook Vertex AI Workbench yang dikelola pengguna. Anda juga membayar resource Google Cloud yang digunakan instance notebook yang dikelola pengguna.
Notebook yang dikelola pengguna berjalan di Deep Learning VM Image. Image ini dioptimalkan untuk mendukung framework ML seperti PyTorch dan TensorFlow. Tutorial ini mendukung pembuatan instance notebook yang dikelola pengguna dengan instalasi R versi 3.6.
Menggunakan BigQuery dengan R
BigQuery tidak memerlukan pengelolaan infrastruktur, sehingga Anda bisa fokus untuk menemukan insight yang bermakna. BigQuery memungkinkan Anda menggunakan SQL yang familier untuk menangani data, sehingga Anda tidak memerlukan administrator database. Anda dapat menggunakan BigQuery untuk menganalisis data dalam jumlah dan skala besar, serta menyiapkan set data untuk ML menggunakan kemampuan analitik SQL yang kuat dari BigQuery.
Untuk membuat kueri data BigQuery menggunakan R, Anda dapat menggunakan library open source R bigrquery. Paket bigrquery menyediakan tingkat abstraksi berikut di atas BigQuery:
API tingkat rendah menyediakan wrapper tipis di atas BigQuery REST API yang mendasarinya.
Antarmuka DBI menggabungkan API tingkat rendah dan membuat penggunaan BigQuery terasa seperti bekerja dengan sistem database lainnya. Ini adalah lapisan yang paling praktis jika Anda ingin menjalankan kueri SQL di BigQuery atau mengupload kurang dari 100 MB.
Dengan antarmuka dbplyr Anda dapat memperlakukan tabel BigQuery seperti bingkai data dalam memori. Ini adalah lapisan yang paling praktis jika Anda tidak ingin menulis SQL, tetapi ingin dbplyr menulisnya untuk Anda.
Tutorial ini menggunakan API level rendah dari bigrquery, tanpa memerlukan DBI atau dbplyr.
Tujuan
- Membuat instance notebook yang dikelola pengguna yang memiliki dukungan R.
- Membuat kueri dan menganalisis data dari BigQuery menggunakan library R bigrquery.
- Menyiapkan dan menyimpan data untuk ML di Cloud Storage.
Biaya
Dalam dokumen ini, Anda menggunakan komponen Google Cloud yang dapat ditagih berikut:
- BigQuery
- Instance notebook Vertex AI Workbench yang dikelola pengguna. Anda juga akan dikenai biaya untuk resource yang digunakan dalam notebook, termasuk resource komputasi, BigQuery, dan permintaan API.
- Cloud Storage
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Sebelum memulai
- Login ke akun Google Cloud Anda. Jika Anda baru menggunakan Google Cloud, buat akun untuk mengevaluasi performa produk kami dalam skenario dunia nyata. Pelanggan baru juga mendapatkan kredit gratis senilai $300 untuk menjalankan, menguji, dan men-deploy workload.
-
Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
-
Pastikan penagihan telah diaktifkan untuk project Google Cloud Anda.
-
Aktifkan API Compute Engine.
-
Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
-
Pastikan penagihan telah diaktifkan untuk project Google Cloud Anda.
-
Aktifkan API Compute Engine.
Membuat instance notebook yang dikelola pengguna dengan R
Langkah pertama adalah membuat instance notebook yang dikelola pengguna yang dapat Anda gunakan untuk tutorial ini.
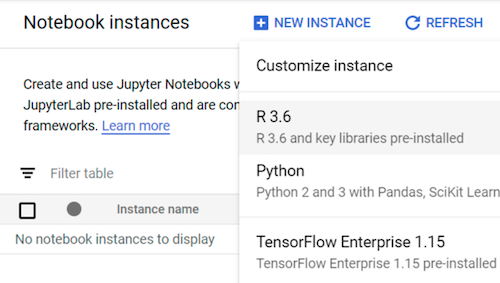
Di konsol Google Cloud, buka halaman Notebooks.
Pada tab Notebook yang dikelola pengguna, klik Notebook baru.
Pilih R 3.6.
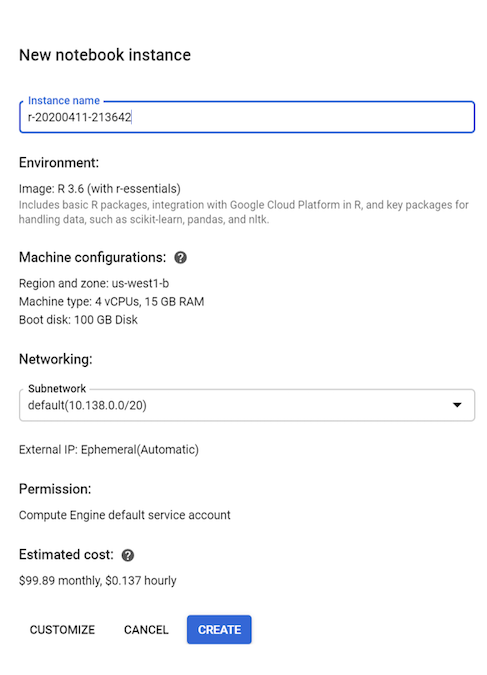
Untuk tutorial ini, biarkan semua nilai default dan klik Create:
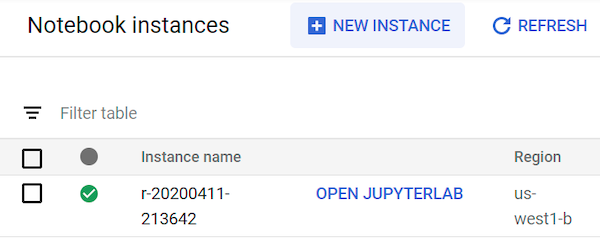
Memulai instance notebook yang dikelola pengguna memerlukan waktu hingga 90 detik. Jika sudah siap, Anda akan melihatnya tercantum di panel Instance notebook dengan link Buka JupyterLab di samping nama instance:
Membuka JupyterLab
Untuk menjalankan tutorial di notebook, Anda harus membuka lingkungan JupyterLab, clone repositori GitHub ml-on-gcp, lalu buka notebook.
Pada daftar instance, klik Buka Jupyterlab. Tindakan ini akan membuka lingkungan JupyterLab di browser Anda.
Untuk meluncurkan tab terminal, klik Terminal di Peluncur.
Di terminal, clone repositori GitHub
ml-on-gcp:git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.gitSetelah perintah selesai, Anda akan melihat folder
ml-on-gcpdi file browser.Di file browser, buka
ml-on-gcp, lalututorials, laluR.Hasil clone akan terlihat seperti berikut:
Membuka notebook dan menyiapkan R
Library R yang Anda perlukan untuk tutorial ini, termasuk BigQuery, diinstal di notebook R secara default. Sebagai bagian dari prosedur ini, Anda perlu mengimpornya agar tersedia untuk notebook.
Di file browser, buka notebook
01-EDA-with-R-and-BigQuery.ipynb.Notebook ini membahas tutorial analisis data eksploratif tentang R dan BigQuery. Dari sini, Anda akan bekerja di notebook dan menjalankan kode yang terlihat di dalam notebook Jupyter itu sendiri.
Impor library R yang Anda perlukan untuk tutorial ini:
library(bigrquery) # used for querying BigQuery library(ggplot2) # used for visualization library(dplyr) # used for data wranglingAutentikasi
bigrquerymenggunakan autentikasi out-of-band:bq_auth(use_oob = True)Tetapkan variabel ke nama project yang Anda gunakan untuk tutorial ini:
# Set the project ID PROJECT_ID <- "gcp-data-science-demo"Tetapkan variabel ke nama bucket Cloud Storage:
BUCKET_NAME <- "bucket-name"
Ganti bucket-name dengan nama yang unik secara global.
Anda akan menggunakan bucket untuk menyimpan data output nanti.
Membuat kueri data dari BigQuery
Di bagian ini, Anda akan membaca hasil eksekusi pernyataan SQL BigQuery ke dalam R dan meninjau data lebih awal.
Buat pernyataan SQL BigQuery yang mengekstrak beberapa prediktor yang memungkinkan dan variabel prediksi target untuk sampel data kelahiran sejak tahun 2000:
sql_query <- " SELECT ROUND(weight_pounds, 2) AS weight_pounds, is_male, mother_age, plurality, gestation_weeks, cigarette_use, alcohol_use, CAST(ABS(FARM_FINGERPRINT(CONCAT( CAST(YEAR AS STRING), CAST(month AS STRING), CAST(weight_pounds AS STRING))) ) AS STRING) AS key FROM publicdata.samples.natality WHERE year > 2000 AND weight_pounds > 0 AND mother_age > 0 AND plurality > 0 AND gestation_weeks > 0 AND month > 0 LIMIT %s "Kolom
keyadalah baris ID yang dihasilkan berdasarkan nilai yang digabungkan dari kolomyear,month, danweight_pounds.Jalankan kueri dan ambil data sebagai objek
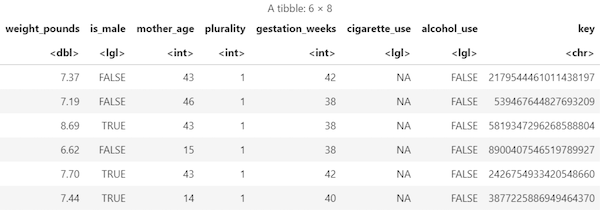
data framedalam memori:sample_size <- 10000 sql_query <- sprintf(sql_query, sample_size) natality_data <- bq_table_download( bq_project_query( PROJECT_ID, query=sql_query ) )Lihat hasil yang diambil:
head(natality_data)Outputnya mirip dengan hal berikut ini:
Lihat jumlah baris dan jenis data setiap kolom:
str(natality_data)Outputnya mirip dengan hal berikut ini:
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 10000 obs. of 8 variables: $ weight_pounds : num 7.75 7.4 6.88 9.38 6.98 7.87 6.69 8.05 5.69 9.22 ... $ is_male : logi FALSE TRUE TRUE TRUE FALSE TRUE ... $ mother_age : int 47 44 42 43 42 43 42 43 45 44 ... $ plurality : int 1 1 1 1 1 1 1 1 1 1 ... $ gestation_weeks: int 41 39 38 39 38 40 35 40 38 39 ... $ cigarette_use : logi NA NA NA NA NA NA ... $ alcohol_use : logi FALSE FALSE FALSE FALSE FALSE FALSE ... $ key : chr "3579741977144949713" "8004866792019451772" "7407363968024554640" "3354974946785669169" ...
Lihat ringkasan data yang diambil:
summary(natality_data)Outputnya mirip dengan yang berikut ini:
weight_pounds is_male mother_age plurality Min. : 0.620 Mode :logical Min. :13.0 Min. :1.000 1st Qu.: 6.620 FALSE:4825 1st Qu.:22.0 1st Qu.:1.000 Median : 7.370 TRUE :5175 Median :27.0 Median :1.000 Mean : 7.274 Mean :27.3 Mean :1.038 3rd Qu.: 8.110 3rd Qu.:32.0 3rd Qu.:1.000 Max. :11.440 Max. :51.0 Max. :4.000 gestation_weeks cigarette_use alcohol_use key Min. :18.00 Mode :logical Mode :logical Length:10000 1st Qu.:38.00 FALSE:580 FALSE:8284 Class :character Median :39.00 TRUE :83 TRUE :144 Mode :character Mean :38.68 NA's :9337 NA's :1572 3rd Qu.:40.00 Max. :47.00
Memvisualisasikan data menggunakan ggplot2
Di bagian ini, Anda akan menggunakan library ggplot2 di R untuk mempelajari beberapa variabel dari set data kelahiran.
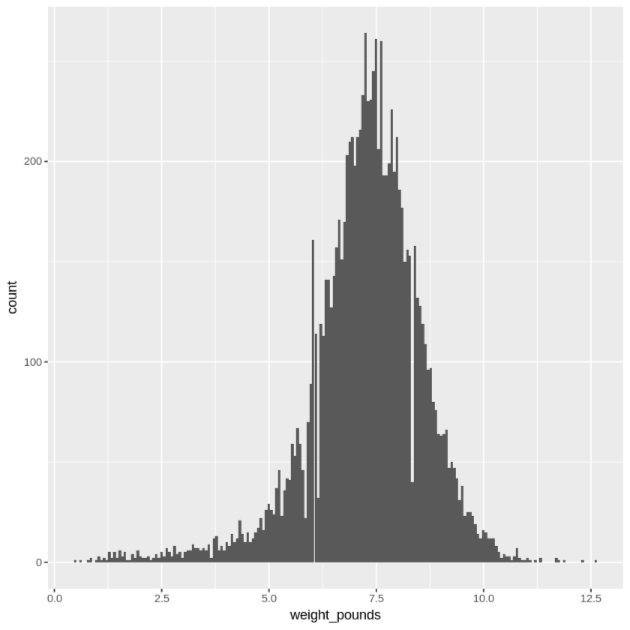
Tampilkan distribusi nilai
weight_poundsmenggunakan histogram:ggplot( data = natality_data, aes(x = weight_pounds) ) + geom_histogram(bins = 200)Plot yang dihasilkan mirip dengan berikut ini:
Tampilkan hubungan antara
gestation_weeksdanweight_poundsmenggunakan diagram sebar:ggplot( data = natality_data, aes(x = gestation_weeks, y = weight_pounds) ) + geom_point() + geom_smooth(method = "lm")Plot yang dihasilkan mirip dengan berikut ini:
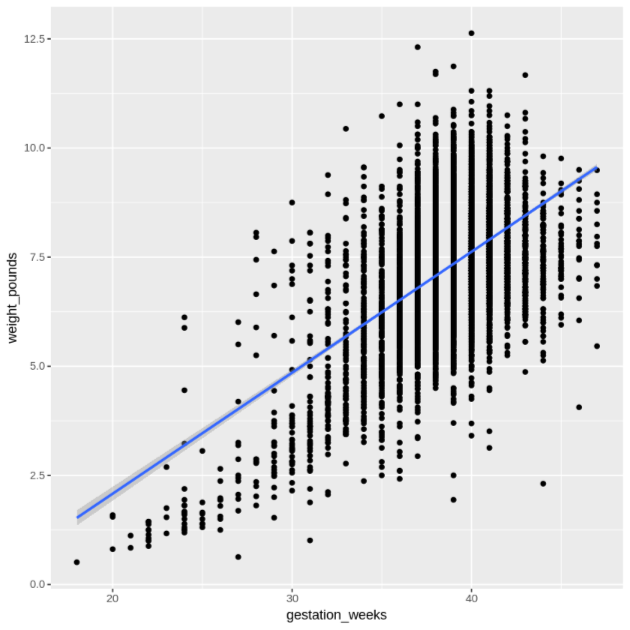
Memproses data dari R di BigQuery
Saat Anda bekerja dengan set data besar, sebaiknya lakukan analisis sebanyak mungkin di BigQuery (seperti agregasi, pemfilteran, penggabungan, komputasi kolom, dan sebagainya), lalu ambil hasilnya. Kurang efisien jika melakukan tugas-tugas ini di R. Menggunakan BigQuery untuk analisis data memanfaatkan skalabilitas dan performa BigQuery, serta memastikan hasil yang diperoleh dapat masuk ke dalam memori R.
Buat fungsi yang menemukan jumlah kumpulan data dan berat rata-rata bayi untuk setiap nilai kolom yang terpilih:
get_distinct_values <- function(column_name) { query <- paste0( 'SELECT ', column_name, ', COUNT(1) AS num_babies, AVG(weight_pounds) AS avg_wt FROM publicdata.samples.natality WHERE year > 2000 GROUP BY ', column_name) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }Panggil fungsi ini menggunakan kolom
mother_age, lalu lihat jumlah bayi dan berat rata-rata berdasarkan usia ibu:df <- get_distinct_values('mother_age') ggplot(data = df, aes(x = mother_age, y = num_babies)) + geom_line() ggplot(data = df, aes(x = mother_age, y = avg_wt)) + geom_line()Output perintah
ggplotpertama adalah sebagai berikut, yang menampilkan jumlah bayi yang lahir berdasarkan usia ibu.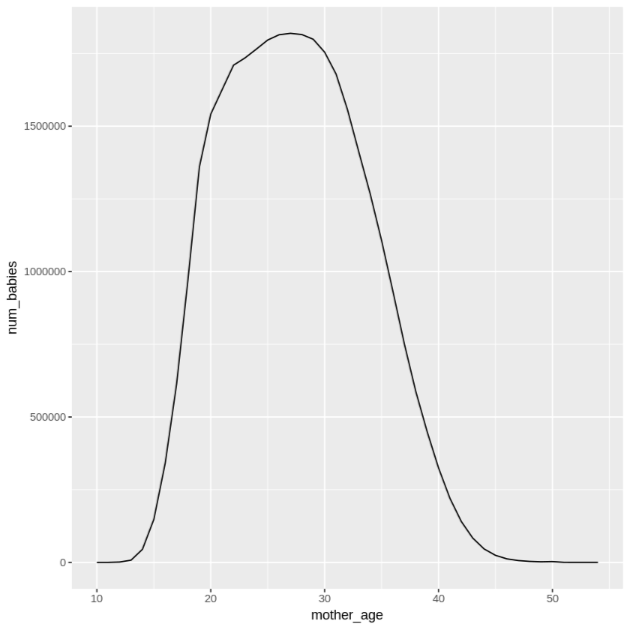
Output perintah
ggplotkedua adalah sebagai berikut, yang menampilkan berat rata-rata bayi berdasarkan usia ibu.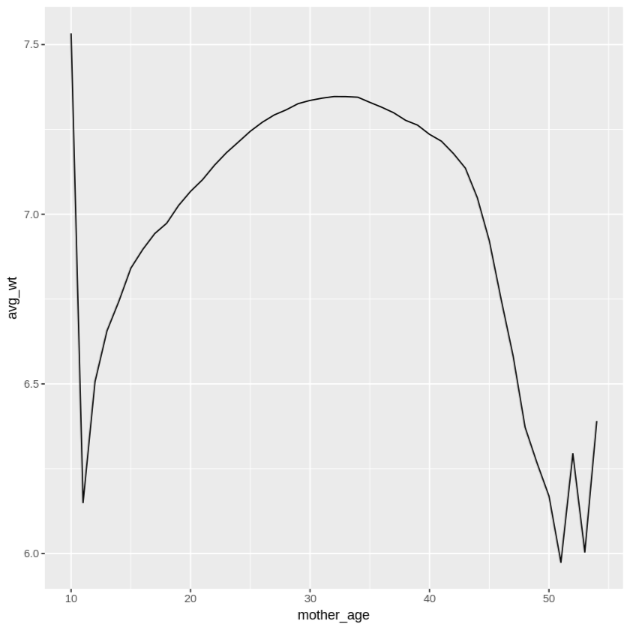
Lihat notebook untuk melihat contoh visualisasi lainnya.
Menyimpan data sebagai file CSV
Tugas berikutnya adalah menyimpan data yang diekstrak dari BigQuery sebagai file CSV di Cloud Storage sehingga Anda dapat menggunakannya untuk tugas ML lebih lanjut.
Muat data pelatihan dan evaluasi dari BigQuery ke R:
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query, sample_size) train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )Tulis data ke file CSV lokal:
# Write data frames to local CSV files, without headers or row names dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = FALSE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = FALSE, sep = ",")Upload file CSV ke Cloud Storage dengan menggabungkan perintah
gsutilyang diteruskan ke sistem:# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)Opsi lain untuk langkah ini adalah menggunakan library googleCloudStorageR untuk mengupload file CVS ke Cloud Storage menggunakan Cloud Storage JSON API.
Pembersihan
Agar resource yang digunakan dalam tutorial ini tidak menimbulkan biaya pada akun Google Cloud Anda, Anda harus menghapusnya.
Menghapus project
Cara termudah untuk menghilangkan penagihan adalah dengan menghapus project yang Anda buat untuk tutorial.
- Di konsol Google Cloud, buka halaman Manage resource.
- Pada daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
Langkah selanjutnya
- Pelajari lebih lanjut cara menggunakan data BigQuery di notebook R di dokumentasi bigrquery.
- Pelajari praktik terbaik untuk ML engineering di Aturan ML.
- Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.