Questo documento descrive due architetture di riferimento che consentono di creare apprendimento federato su Google Cloud utilizzando Google Kubernetes Engine (GKE). Il riferimento le architetture e le risorse associate descritte in questo documento supportano quanto segue:
- Apprendimento federato tra silos
- Apprendimento federato cross-device, basato su un'architettura multi-silo
I destinatari di questo documento sono Cloud Architect, AI e ML che desiderano implementare casi d'uso dell'apprendimento federato su in Google Cloud. È inoltre rivolto ai responsabili delle decisioni che stanno valutando se implementare il learning federato su Google Cloud.
Architettura
I diagrammi in questa sezione mostrano un'architettura multi-silo e un modello per l'apprendimento federato. Per conoscere le diverse applicazioni per queste architetture, consulta i Casi d'uso.
Architettura cross-silo
Il seguente diagramma mostra un'architettura che supporta l'apprendimento federato tra silos:

Il diagramma precedente mostra un esempio semplicistico di architettura a più silos. Nel diagramma, tutte le risorse si trovano nello stesso progetto in un Google Cloud dell'organizzazione. Queste risorse includono il modello client locale, il modello client globale e i relativi carichi di lavoro di apprendimento federato.
Questa architettura di riferimento può essere modificata per supportare diverse configurazioni per i silos di dati. I membri del consorzio possono ospitare i propri silos di dati nei seguenti modi:
- Su Google Cloud, nella stessa organizzazione Google Cloud e nella stessa organizzazione progetto.
- In Google Cloud, nella stessa organizzazione Google Cloud, in diversi progetti Google Cloud.
- Su Google Cloud, in diverse organizzazioni Google Cloud.
- In ambienti privati on-premise o in altri cloud pubblici.
Affinché i membri partecipanti possano collaborare, devono creare norme di sicurezza canali di comunicazione tra i loro ambienti. Per saperne di più sul ruolo dei membri partecipanti nell'iniziativa di apprendimento federato, su come collaborano e su cosa condividono tra loro, consulta la sezione Casi d'uso.
L'architettura include i seguenti componenti:
- Una rete Virtual Private Cloud (VPC) e una subnet.
- Un
cluster GKE privato che ti consente di svolgere le seguenti operazioni:
- Isola i nodi del cluster da internet.
- Limita l'esposizione a internet dei nodi e del piano di controllo del cluster creando un cluster GKE privato con reti autorizzate.
- Utilizza nodi dei cluster schermati che utilizzano un'immagine del sistema operativo con protezione avanzata.
- Attiva Dataplane V2 per ottimizzare il networking di Kubernetes.
- GKE dedicato pool di nodi: Creerai un pool di nodi dedicato per ospitare esclusivamente app tenant e Google Cloud. I nodi presentano incompatibilità per garantire che vengano eseguiti solo i carichi di lavoro tenant e pianificato nei nodi tenant. Le altre risorse del cluster sono ospitate nel pool di nodi principale.
Crittografia dei dati (attivata per impostazione predefinita):
- Dati at-rest.
- Dati in transito.
- Secret dei cluster a livello dell'applicazione.
Crittografia dei dati in uso, attivando facoltativamente i nodi Google Kubernetes Engine riservati.
Regole firewall VPC che applicano quanto segue:
- Regole di base di riferimento che si applicano a tutti i nodi nel cluster.
- Regole aggiuntive che si applicano solo ai nodi nel pool di nodi del tenant. Queste regole firewall limitano l'accesso in entrata e in uscita ai nodi del tenant.
Cloud NAT per consentire il traffico in uscita verso internet.
Cloud DNS record per abilitare Accesso privato Google in modo che le app nel cluster possano accedere alle API di Google senza dover su internet.
Account di servizio che sono le seguenti:
- Un account di servizio dedicato per i nodi nel pool di nodi tenant.
- Un account di servizio dedicato per le app tenant da utilizzare con la federazione delle identità per i carichi di lavoro.
Supporto per l'utilizzo di Google Gruppi per il controllo degli accessi basato sui ruoli (RBAC) di Kubernetes.
Un repository Git per archiviare i descrittori di configurazione.
Un repository Artifact Registry per archiviare le immagini container.
Configurazione Sync e Policy Controller per il deployment della configurazione e dei criteri.
Gateway Cloud Service Mesh per consentire selettivamente il traffico in entrata e in uscita del cluster.
Bucket Cloud Storage per archiviare i pesi dei modelli globali e locali.
Accesso ad altre API Google e Google Cloud. Ad esempio, un carico di lavoro di addestramento potrebbe dover accedere ai dati di addestramento archiviati in Cloud Storage, BigQuery o Cloud SQL.
Architettura cross-device
Il seguente diagramma mostra un'architettura che supporta cross-device apprendimento federato:
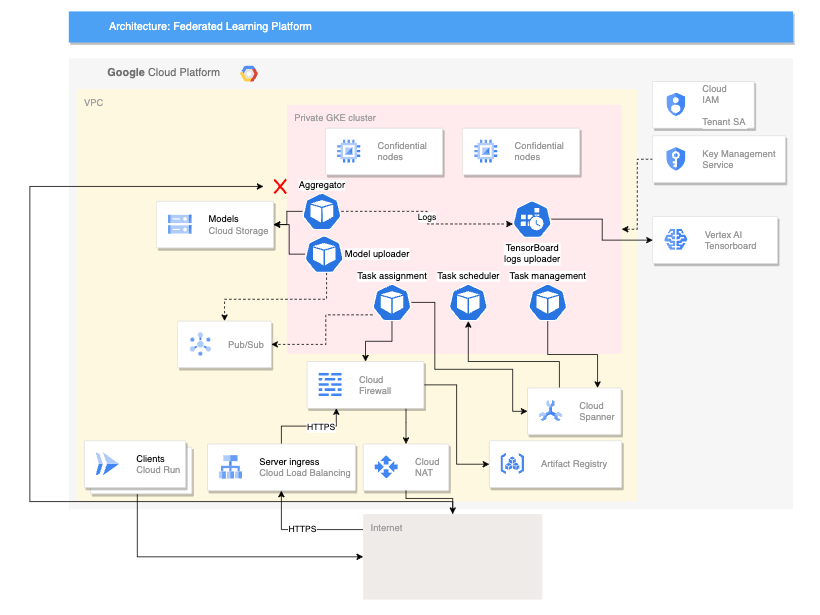
L'architettura cross-device precedente si basa sull'architettura cross-silo con l'aggiunta dei seguenti componenti:
- Un servizio Cloud Run che simula i dispositivi che si connettono al server
- Un Certificate Authority Service che crea certificati privati per il server e client per eseguire
- Un Vertex AI TensorBoard per visualizzare il risultato dell'addestramento
- Un bucket Cloud Storage per archiviare il modello consolidato
- Il cluster GKE privato che utilizza nodi riservati come pool principale per contribuire a proteggere i dati in uso
L'architettura cross-device utilizza componenti del progetto open source Federated Compute Platform (FCP). Questo progetto include:
- Codice client per comunicare con un server ed eseguire attività sul dispositivi
- Un protocollo per la comunicazione client-server
- Punti di connessione con TensorFlow Federated per semplificare la definizione dei calcoli federati
Il deployment dei componenti FCP mostrati nel diagramma precedente può essere eseguito come un insieme di microservizi. Questi componenti svolgono le seguenti funzioni:
- Aggregatore: questo job legge i gradienti del dispositivo e calcola il risultato aggregato con la privacy differenziale.
- Collector: questo job viene eseguito periodicamente per eseguire query sulle attività attive e su gradienti criptati. Queste informazioni determinano quando inizia l'aggregazione.
- Model uploader: questo job ascolta gli eventi e pubblica i risultati in modo che i dispositivi possano scaricare i modelli aggiornati.
- Assegnazione di attività: questo servizio frontend distribuisce le attività di addestramento ai dispositivi.
- Gestione delle attività: questo job gestisce le attività.
- Task-scheduler: questo job viene eseguito periodicamente o viene attivato dal per eventi specifici.
Prodotti utilizzati
Le architetture di riferimento per entrambi i casi d'uso dell'apprendimento federato utilizzano i seguenti componenti di Google Cloud:
- Google Cloud Kubernetes Engine (GKE): GKE fornisce la piattaforma di base per l'apprendimento federato.
- TensorFlow Federated (TFF): Il TFF fornisce un framework open source per il machine learning e altri su dati decentralizzati.
GKE fornisce inoltre le seguenti funzionalità alla tua piattaforma di machine learning federata:
- Hosting del coordinatore dell'apprendimento federato: il coordinatore dell'apprendimento federato è responsabile della gestione del processo di apprendimento federato. Questa gestione include attività come la distribuzione del modello globale partecipanti, aggregando gli aggiornamenti dei partecipanti e aggiornando i globale. GKE può essere utilizzato per ospitare il coordinatore dell'apprendimento federato in modo altamente disponibile e scalabile.
- Hosting dei partecipanti all'apprendimento federato: partecipanti dell'apprendimento federato sono responsabili dell'addestramento del modello globale sulla base dei dati locali. GKE può essere utilizzato per ospitare i partecipanti all'apprendimento federato in modo sicuro e isolato. Questo approccio può contribuire ad assicurare che i dati dei partecipanti vengano conservati localmente.
- Fornire un canale di comunicazione sicuro e scalabile: Federated i partecipanti devono essere in grado di comunicare con di machine learning in modo sicuro e scalabile. GKE può essere utilizzato per fornire un canale di comunicazione sicuro e scalabile tra i partecipanti e il coordinatore.
- Gestione del ciclo di vita dei deployment di apprendimento federato: GKE può essere utilizzato per gestire il ciclo di vita dei deployment di apprendimento federato. Questa gestione include attività come il provisioning delle risorse, il deployment della piattaforma di machine learning federato e il monitoraggio delle prestazioni della piattaforma di machine learning federato.
Oltre a questi vantaggi, GKE offre anche una serie di funzionalità che possono essere utili per gli implementazioni di apprendimento federato, ad esempio:
- Cluster regionali: GKE ti consente di creare cluster regionali, aiutandoti a migliorare le prestazioni dei deployment di apprendimento federato riducendo la latenza tra i partecipanti e il coordinatore.
- Norme di rete: GKE ti consente di creare norme di rete, contribuendo a migliorare la sicurezza degli implementazioni di apprendimento federato controllando il flusso di traffico tra i partecipanti e il coordinatore.
- Bilanciamento del carico: GKE fornisce una serie di carichi di bilanciamento del carico, contribuendo a migliorare la scalabilità dell'apprendimento federato distribuendo il traffico tra i partecipanti e il coordinatore.
Il TFF fornisce le seguenti funzionalità per facilitare l'implementazione casi d'uso dell'apprendimento federato:
- La possibilità di esprimere in modo dichiarativo i calcoli federati, che sono un insieme di passaggi di elaborazione eseguiti su un server e un insieme di client. Questi di computing può essere implementato in diversi ambienti di runtime.
- Gli aggregatori personalizzati possono essere creati utilizzando TFF open source.
- Supporto di una serie di algoritmi di apprendimento federato, tra cui
i seguenti algoritmi:
- Media federata:
Un algoritmo che calcola la media dei parametri del modello
clienti. È particolarmente adatto per i casi d'uso in cui i dati sono relativamente omogenei e il modello non è troppo complesso. I casi d'uso tipici sono:
- Consigli personalizzati: un'azienda può utilizzare la media federata per addestrare un modello che consiglia prodotti utenti in base alla loro cronologia acquisti.
- Rilevamento di frodi: un consorzio di banche può utilizzare per addestrare un modello che rileva transazioni fraudolente.
- Diagnosi medica: un gruppo di ospedali può utilizzare la media federata per addestrare un modello che diagnostica il cancro.
- Discesa stocastica federata del gradiente (FedSGD): un algoritmo che utilizza la discesa stocastica del gradiente per aggiornare i parametri del modello. È adatta per casi d'uso in cui i dati sono eterogenei
e il modello è complesso. Di seguito sono riportati i casi d'uso tipici:
- Elaborazione del linguaggio naturale: un'azienda può utilizzare FedSGD per addestrare un modello che migliora la precisione del riconoscimento vocale.
- Riconoscimento delle immagini: un'azienda può utilizzare FedSGD per addestrare un modello in grado di identificare gli oggetti nelle immagini.
- Manutenzione predittiva: un'azienda può utilizzare FedSGD per addestrare un modello che prevede quando è probabile che una macchina si guasti.
- Adamo federato:
Un algoritmo che utilizza l'ottimizzatore Adam per aggiornare i parametri del modello.
Di seguito sono riportati i casi d'uso tipici:
- Sistemi del motore per suggerimenti: un'azienda può utilizzare Adam federato per addestrare un modello che consiglia i prodotti agli utenti in base alla loro cronologia acquisti.
- Ranking: un'azienda può utilizzare Adam federato per addestrare un modello che classifica risultati di ricerca.
- Previsione della percentuale di clic: un'azienda può utilizzare Adam federato per addestrare un modello che preveda la probabilità che un utente faccia clic su un annuncio.
- Media federata:
Un algoritmo che calcola la media dei parametri del modello
clienti. È particolarmente adatto per i casi d'uso in cui i dati sono relativamente omogenei e il modello non è troppo complesso. I casi d'uso tipici sono:
Casi d'uso
Questa sezione descrive i casi d'uso in cui le funzionalità cross-silo e cross-device sono le scelte giuste per la tua piattaforma di apprendimento federata.
L'apprendimento federato è un ambiente di machine learning in cui molti client per addestrare un modello in modo collaborativo. Questo processo è guidato da un coordinatore centrale e i dati di addestramento rimangono decentralizzati.
Nel paradigma di apprendimento federato, i clienti scaricano un modello globale e migliorano addestrando il modello localmente in base ai suoi dati. Quindi, ciascun client invia i propri gli aggiornamenti del modello calcolati di nuovo al server centrale, dove vengono e viene generata una nuova iterazione del modello globale. In queste architetture di riferimento, i carichi di lavoro di addestramento con GKE.
L'apprendimento federato incarna il principio di privacy della minimizzazione dei dati, limitando i dati raccolti in ogni fase del calcolo, limita l'accesso ai dati ed elabora e poi elimina i dati il prima possibile. Inoltre, l'impostazione dei problemi dell'apprendimento federato è compatibile Ulteriori tecniche di tutela della privacy, come l'uso della privacy differenziale (DP) per migliorare l'anonimizzazione del modello per garantire che il modello finale non memorizzi i dati del singolo utente.
A seconda del caso d'uso, l'addestramento dei modelli con l'apprendimento federato può avere vantaggi aggiuntivi:
- Conformità: in alcuni casi, le normative potrebbero limitare il modo in cui i dati possono o condivise. L'apprendimento federato potrebbe essere utilizzato per rispettare queste normative.
- Efficienza della comunicazione: in alcuni casi, è più efficiente addestrare un un modello basato su dati distribuiti, anziché centralizzare i dati. Ad esempio, i set di dati su cui deve essere addestrato il modello sono troppo grandi per essere spostati in modo centralizzato.
- Rendere accessibili i dati: l'apprendimento federato consente alle organizzazioni di mantenere i dati di addestramento decentralizzati in silos di dati per utente o per organizzazione.
- Maggiore accuratezza del modello: mediante l'addestramento su dati di utenti reali (assicurando al contempo che privacy) anziché dati sintetici (a volte indicati come dati proxy), spesso si traduce in una maggiore accuratezza del modello.
Esistono diversi tipi di apprendimento federato, che si distinguono in base alla provenienza dei dati e al luogo in cui vengono eseguiti i calcoli locali. La di questo documento si concentrano su due tipi di apprendimento federato: cross-silo e cross-device. Altri tipi di apprendimento federato non rientrano nell'ambito per questo documento.
L'apprendimento federato è ulteriormente classificato in base alla modalità di partizione dei set di dati, che può essere la seguente:
- Apprendimento federato orizzontale (HFL): set di dati con le stesse caratteristiche (colonne), ma diversi campioni (righe). Ad esempio, più ospedali potrebbero avere cartelle cliniche con gli stessi parametri medici ma diversi popolazioni di pazienti.
- Apprendimento federato verticale (VFL): set di dati con gli stessi campioni (righe) ma caratteristiche diverse (colonne). Ad esempio, una banca e un negozio l'azienda potrebbe avere dati dei clienti con persone che si sovrappongono ma informazioni finanziarie e sugli acquisti.
- Federated Transfer Learning (FTL): sovrapposizione parziale in entrambi i campioni e le caratteristiche tra i set di dati. Ad esempio, due ospedali potrebbero avere documenti con alcuni individui sovrapposti e alcuni medici condivisi ma anche caratteristiche uniche in ogni set di dati.
Il calcolo federato tra silos si verifica quando i membri partecipanti sono organizzazioni o aziende. In pratica, il numero di abbonati è solitamente ridotto (ad esempio, entro un centinaio di membri). Il calcolo cross-silo è in genere utilizzati in scenari in cui le organizzazioni partecipanti dispongono di diversi set di dati, ma vuole addestrare un modello condiviso o analizzare risultati aggregati senza condividere tra loro i dati non elaborati. Ad esempio, la partecipazione possono avere i propri ambienti in diverse organizzazioni Google Cloud, ad esempio quando rappresentano persone giuridiche diverse o nello stesso dell'organizzazione Google Cloud, ad esempio quando rappresentano reparti diversi di la stessa persona giuridica.
I membri partecipanti potrebbero non essere in grado di considerare i carichi di lavoro reciproci come entità attendibili. Ad esempio, un membro partecipante potrebbe non avere accesso a il codice sorgente di un carico di lavoro di addestramento come il coordinatore. Poiché non può accedere a questo codice sorgente, il membro partecipante non può garantire che il carico di lavoro sia completamente attendibile.
Per aiutarti a impedire a un carico di lavoro non attendibile di accedere ai tuoi dati o alle tue risorse senza autorizzazione, ti consigliamo di procedere come segue:
- Esegui il deployment di carichi di lavoro non attendibili in un ambiente isolato.
- Concedi ai carichi di lavoro non attendibili solo i diritti di accesso e le autorizzazioni strettamente necessari per completare i round di addestramento assegnati al carico di lavoro.
Per aiutarti a isolare i carichi di lavoro potenzialmente non attendibili, queste architetture di riferimento implementano controlli di sicurezza, come la configurazione di spazi dei nomi Kubernetes isolati, in cui ogni spazio dei nomi ha un pool di nodi GKE dedicato. Comunicazione e cluster tra spazio dei nomi il traffico in entrata e in uscita è vietato per impostazione predefinita, a meno che non questa impostazione.
Ecco alcuni casi d'uso di esempio per l'apprendimento federato tra silos:
- Rilevamento di frodi: l'apprendimento federato può essere utilizzato per addestrare un modello di rilevamento di frodi su dati distribuiti in più organizzazioni. Ad esempio, un consorzio di banche potrebbe utilizzare l'apprendimento federato per addestrare un modello che rileva le transazioni fraudolente.
- Diagnosi medica: l'apprendimento federato può essere utilizzato per addestrare un modello di diagnosi medica su dati distribuiti su più ospedali. Per Ad esempio, un gruppo di ospedali potrebbe utilizzare l'apprendimento federato per addestrare un modello che diagnostica il cancro.
L'apprendimento federato cross-device è un tipo di calcolo federato in cui i membri partecipanti sono dispositivi di utenti finali come cellulari, veicoli o dispositivi IoT. Il numero di membri può raggiungere una scala di milioni o addirittura decine di milioni.
Il processo per l'apprendimento federato cross-device è simile a quello dell'apprendimento l'apprendimento federato tra silos. Tuttavia, richiede anche di adattare l'architettura di riferimento per tenere conto di alcuni fattori aggiuntivi che devi considerare quando hai a che fare con migliaia o milioni di dispositivi. Devi implementare i carichi di lavoro amministrativi per gestire gli scenari riscontrati nei casi d'uso dell'apprendimento federato cross-device. Ad esempio, la necessità coordinare un sottoinsieme di clienti che si svolgeranno nel corso dell'addestramento. L'architettura cross-device offre questa possibilità consentendoti di eseguire il deployment dei servizi FCP. Questi servizi hanno carichi di lavoro con punti di connessione con TFF. TFF viene utilizzato per scrivere codice che gestisce questo coordinamento.
Di seguito sono riportati alcuni casi d'uso di esempio per l'apprendimento federato cross-device:
- Consigli personalizzati: puoi usare federata tra dispositivi ad addestrare un modello di suggerimenti personalizzato sui dati distribuiti su più dispositivi. Ad esempio, un'azienda potrebbe utilizzare l'apprendimento federato per addestrare un modello che consiglia prodotti agli utenti in base nella loro cronologia acquisti.
- Elaborazione del linguaggio naturale: l'apprendimento federato può essere utilizzato per addestrare un modello di elaborazione del linguaggio naturale su dati distribuiti su più dispositivi. Ad esempio, un'azienda potrebbe utilizzare l'apprendimento federato per addestrare un modello che migliora la precisione del riconoscimento vocale.
- Prevedere le esigenze di manutenzione dei veicoli: l'apprendimento federato può essere utilizzato addestrare un modello che prevede quando è probabile che un veicolo richieda manutenzione. Questo modello può essere addestrato su dati raccolti da più veicoli. Questo approccio consente al modello di apprendere dalle esperienze di tutti i veicoli, senza compromettere la privacy di nessun singolo veicolo.
La tabella seguente riassume le funzionalità delle architetture cross-silo e cross-device e mostra come classificare il tipo di scenario di apprendimento federato applicabile al tuo caso d'uso.
| Funzionalità | Calcoli federati tra silos | Calcoli federati cross-device |
|---|---|---|
| Dimensione della popolazione | Di solito è ridotto (ad esempio, entro un centinaio di dispositivi) | Scalabile fino a migliaia, milioni o centinaia di milioni di dispositivi |
| Membri partecipanti | Organizzazioni o aziende | Dispositivi mobili, dispositivi periferici, veicoli |
| Partizione dei dati più comune | HFL, VFL, FTL | HFL |
| Sensibilità dei dati | Dati sensibili che i partecipanti non vogliono condividere tra loro in formato non elaborato | Dati troppo sensibili per essere condivisi con un server centrale |
| Disponibilità dei dati | I partecipanti sono quasi sempre disponibili | In qualsiasi momento è disponibile solo una parte dei partecipanti |
| Esempi di casi d'uso | Rilevamento di frodi, diagnosi mediche, previsioni finanziarie | Monitoraggio dell'attività fisica, riconoscimento vocale, classificazione delle immagini |
Note sul layout
Questa sezione fornisce indicazioni per aiutarti a utilizzare questa architettura di riferimento per: sviluppare una o più architetture che soddisfino i tuoi requisiti specifici sicurezza, affidabilità, efficienza operativa, costi e prestazioni.
Considerazioni sulla progettazione dell'architettura multi-silo
Per implementare un'architettura di apprendimento federato multi-silo in Google Cloud, devi implementare i seguenti prerequisiti minimi: descritti più dettagliatamente nelle seguenti sezioni:
- Istituisci un consorzio per l'apprendimento federato.
- Determina il modello di collaborazione da implementare per il consorzio di apprendimento federato.
- Determina le responsabilità delle organizzazioni partecipanti.
Oltre a questi prerequisiti, esistono altre azioni che la federazione che non rientrano nell'ambito di questo documento, ad esempio le seguenti:
- Gestisci il Consorzio per l'apprendimento federato.
- Progettare e implementare un modello di collaborazione.
- Prepara, gestisci e utilizza i dati di addestramento del modello e il modello che che il proprietario della federazione intende addestrare.
- Crea, esegui il containerizzazione e orchestra i flussi di lavoro di apprendimento federato.
- Esegui il deployment e gestisci i carichi di lavoro di apprendimento federato.
- Configura i canali di comunicazione per le organizzazioni partecipanti trasferire i dati in modo sicuro.
Creare un consorzio di apprendimento federato
Un consorzio per l'apprendimento federato è il gruppo di organizzazioni che partecipano in un'attività di apprendimento federato in più silos. Le organizzazioni del consorzio condividono solo i parametri dei modelli di ML e puoi criptarli per aumentare la privacy. Se il Consorzio per l'apprendimento federato consente questa pratica, le organizzazioni possono anche aggregare dati che non contengono informazioni di informazioni (PII).
Determina un modello di collaborazione per il consorzio di apprendimento federato
Il consorzio di apprendimento federato può implementare diversi modelli di collaborazione, come ad esempio:
- Un modello centralizzato composto da un unico coordinamento dell'organizzazione, denominato proprietario della federazione o agente di orchestrazione, e un insieme di organizzazioni partecipanti o proprietari di dati.
- Un modello decentralizzato composto da organizzazioni che coordinano come gruppo.
- Un modello eterogeneo costituito da un consorzio di diverse organizzazioni partecipanti, che apportano tutte risorse diverse al consorzio.
In questo documento si presuppone che il modello di collaborazione sia centralizzato.
Determinare le responsabilità delle organizzazioni partecipanti
Dopo aver scelto un modello di collaborazione per il consorzio di apprendimento federato, il proprietario della federazione deve determinare le responsabilità delle organizzazioni partecipanti.
Il proprietario della federazione deve inoltre effettuare le seguenti operazioni quando inizia a creare consorzio per l'apprendimento federato:
- Coordina l'impegno di apprendimento federato.
- Progettare e implementare il modello ML globale e i modelli ML da condividere le organizzazioni partecipanti.
- Definire i cicli di apprendimento federati, ovvero l'approccio per l'iterazione delle il processo di addestramento ML.
- Seleziona le organizzazioni partecipanti che contribuiscono a un determinato di apprendimento federato. Questa selezione viene chiamata coorte.
- Progettare e implementare una procedura di verifica dell'iscrizione a consorzio per le organizzazioni partecipanti.
- Aggiorna il modello ML globale e i modelli ML da condividere con le organizzazioni partecipanti.
- Fornisci alle organizzazioni partecipanti gli strumenti per verificare che ciò avvenga il consorzio per l'apprendimento federato soddisfa le loro esigenze in termini di requisiti normativi.
- Offri alle organizzazioni partecipanti informazioni canali di comunicazione.
- Fornire alle organizzazioni partecipanti tutti i dati aggregati non riservati necessari per completare ogni ciclo di apprendimento federato.
Le organizzazioni partecipanti hanno le seguenti responsabilità:
- Fornire e gestire un ambiente sicuro e isolato (un silo). Il silo è il luogo in cui le organizzazioni partecipanti archiviano i propri dati e in cui viene implementato l'addestramento dei modelli di ML. Le organizzazioni partecipanti non condividono i propri dati con altre organizzazioni.
- Addestra i modelli forniti dal proprietario della federazione utilizzando la propria infrastruttura di calcolo e i propri dati locali.
- Condividi i risultati dell'addestramento del modello con il proprietario della federazione sotto forma di e aggregati dopo aver rimosso eventuali PII.
Il proprietario della federazione e le organizzazioni partecipanti possono utilizzare Cloud Storage per condividere modelli aggiornati e risultati di addestramento.
Il proprietario della federazione e le organizzazioni partecipanti perfezionano il modello ML fino a quando il modello non soddisfa i requisiti.
Implementazione dell'apprendimento federato su Google Cloud
Dopo la creazione del consorzio per l'apprendimento federato e una volta stabilito in che modo consorzio per l'apprendimento federato, consigliamo a quel partecipante le organizzazioni:
- Esegui il provisioning e configura l'infrastruttura necessaria per il consorzio di apprendimento federato.
- Implementa il modello di collaborazione.
- Inizia l'attività di apprendimento federato.
Esegui il provisioning e la configurazione dell'infrastruttura per il consorzio di apprendimento federato
Durante il provisioning e la configurazione dell'infrastruttura per il consorzio di apprendimento federato, è responsabilità del proprietario della federazione creare e distribuire i carichi di lavoro che addestrano i modelli ML federati alle organizzazioni partecipanti. Poiché una terza parte (il proprietario della federazione) ha creato e fornito i carichi di lavoro, le organizzazioni partecipanti devono adottare precauzioni durante il loro dispiegamento negli ambienti di runtime.
Le organizzazioni partecipanti devono configurare i propri ambienti in base alle proprie le best practice per la sicurezza individuali e applicare controlli che limitano l'ambito le autorizzazioni concesse a ogni carico di lavoro. Oltre a seguire le proprie singole best practice per la sicurezza, consigliamo al proprietario della federazione e alle organizzazioni partecipanti di prendere in considerazione i vettori di minaccia specifici per l'apprendimento federato.
Implementare il modello di collaborazione
Dopo aver preparato l'infrastruttura del consorzio di apprendimento federato, il proprietario della federazione progetta e implementa i meccanismi che consentono alle organizzazioni partecipanti di interagire tra loro. L'approccio segue la collaborazione scelto dal proprietario della federazione per il Consorzio per l'apprendimento federato.
Inizia l'impegno di apprendimento federato
Dopo aver implementato il modello di collaborazione, il proprietario della federazione implementa un modello ML globale da addestrare e i modelli ML da condividere con il partecipante. dell'organizzazione. Una volta pronti, il proprietario della federazione avvia il primo round dell'iniziativa di apprendimento federato.
Durante ogni ciclo dell'iniziativa di apprendimento federato, il proprietario della federazione svolge quanto segue:
- Distribuisce i modelli di ML da condividere con le organizzazioni partecipanti.
- Attende che le organizzazioni partecipanti consegnino i risultati del dei modelli ML condivisi dal proprietario della federazione.
- Raccoglie ed elabora i risultati della formazione che il partecipante le organizzazioni produttive.
- Aggiorna il modello ML globale quando riceve risultati di addestramento appropriati dalle organizzazioni partecipanti.
- Aggiorna i modelli di ML da condividere con gli altri membri del consorzio laddove applicabile.
- Prepara i dati di addestramento per il prossimo ciclo di apprendimento federato.
- Avvia il prossimo ciclo di apprendimento federato.
Sicurezza, privacy e conformità
Questa sezione descrive i fattori da prendere in considerazione quando utilizzi questo di riferimento per progettare e creare una piattaforma di apprendimento federata in Google Cloud. Queste indicazioni si applicano a entrambe le architetture descritte in questo documento.
I carichi di lavoro di apprendimento federato di cui esegui il deployment nei tuoi ambienti esporre te, i tuoi dati, i tuoi modelli di apprendimento federato e la tua infrastruttura alle minacce che potrebbero avere un impatto sulla tua attività.
Per aiutarti ad aumentare la sicurezza dei tuoi ambienti di apprendimento federato, queste architetture di riferimento configurano Controlli di sicurezza di GKE incentrati sull'infrastruttura dei tuoi ambienti. Questi controlli potrebbero non essere sufficienti per proteggerti dalle minacce specifiche per i tuoi carichi di lavoro e casi d'uso di apprendimento federato. Data la specificità di ogni carico di lavoro e caso d'uso di apprendimento federato, i controlli di sicurezza volti a proteggere l'implementazione dell'apprendimento federato non rientrano nell'ambito di questo documento. Per ulteriori informazioni ed esempi su queste minacce, consulta Considerazioni sulla sicurezza per l'apprendimento federato.
Controlli di sicurezza di GKE
Questa sezione illustra i controlli che puoi applicare con queste architetture per aiutarti a proteggere il tuo cluster GKE.
Sicurezza avanzata dei cluster GKE
Queste architetture di riferimento ti aiutano a creare un cluster GKE che implementa le seguenti impostazioni di sicurezza:
- Limita l'esposizione a internet dei nodi e del piano di controllo del cluster creando un cluster GKE privato con reti autorizzate.
- Utilizza le funzionalità di
nodi schermati
che utilizzano un'immagine del nodo protetta
containerdruntime. - Maggiore isolamento dei carichi di lavoro dei tenant tramite GKE Sandbox.
- Crittografa i dati at-rest per impostazione predefinita.
- Cripta i dati in transito per impostazione predefinita.
- Crittografa i secret del cluster a livello di applicazione.
- Facoltativamente, cripta i dati in uso abilitando Confidential Google Kubernetes Engine Nodes.
Per ulteriori informazioni sulle impostazioni di sicurezza di GKE, consulta Rafforza la sicurezza del tuo cluster e Dashboard della postura di sicurezza.
Regole firewall VPC
Regole firewall Virtual Private Cloud (VPC) e disciplinare quale traffico è consentito da o verso le VM di Compute Engine. Le regole consentono il traffico viene filtrato con granularità delle VM, a seconda Attributi di livello 4.
Creazione di un cluster GKE con le regole firewall predefinite del cluster GKE. Queste regole firewall consentono la comunicazione tra i nodi del cluster dal piano di controllo GKE, e tra nodi e pod in un cluster Kubernetes.
Applicano regole firewall aggiuntive ai nodi del pool di nodi del tenant. Queste regole firewall limitano il traffico in uscita dai nodi del tenant. Questo approccio può Aumentare l'isolamento dei nodi tenant. Per impostazione predefinita, tutto il traffico in uscita di nodi tenant. Eventuali uscite richieste devono essere configurate esplicitamente. Per Ad esempio, crei regole firewall per consentire il traffico in uscita dai nodi tenant dal piano di controllo GKE e alle API di Google utilizzando Accesso privato Google. Le regole firewall vengono indirizzate ai nodi tenant utilizzando account di servizio per il pool di nodi tenant.
Spazi dei nomi
Gli spazi dei nomi consentono di fornire un ambito per le risorse correlate all'interno di un cluster, ad esempio pod, servizi e controller di replica. Utilizzando gli spazi dei nomi, può delegare la responsabilità dell'amministrazione delle risorse correlate come unità. Pertanto, gli spazi dei nomi sono parte integrante della maggior parte dei pattern di sicurezza.
Gli spazi dei nomi sono una funzionalità importante per l'isolamento del piano di controllo. Tuttavia, non forniscono isolamento dei nodi, isolamento del piano dati o isolamento della rete.
Un approccio comune consiste nel creare spazi dei nomi per singole applicazioni. Ad esempio, potresti creare lo spazio dei nomi myapp-frontend per il componente dell'interfaccia utente di un'applicazione.
Queste architetture di riferimento ti aiutano a creare uno spazio dei nomi dedicato per ospitare le app di terze parti. Lo spazio dei nomi e le relative risorse vengono trattati come un tenant all'interno nel tuo cluster. Applichi criteri e controlli allo spazio dei nomi per limitare delle risorse nello spazio dei nomi.
Criteri di rete
Criteri di rete applicare i flussi di traffico di rete di livello 4 utilizzando regole firewall a livello di pod. I criteri di rete sono limitati a uno spazio dei nomi.
Nelle architetture di riferimento descritte in questo documento, applichi le norme di rete allo spazio dei nomi del tenant che ospita le app di terze parti. Per impostazione predefinita, il criterio di rete nega tutto il traffico verso e da i pod nello spazio dei nomi. Qualsiasi trafico richiesto deve essere aggiunto esplicitamente a una lista consentita. Ad esempio, i criteri di rete in queste architetture di riferimento consentono esplicitamente al traffico servizi cluster richiesti, come il DNS interno del cluster e Cloud Service Mesh dal piano di controllo.
Config Sync
Configurazione Sync mantiene sincronizzati i cluster GKE con le configurazioni archiviate in un repository. Il repository Git funge da unica fonte attendibile per la configurazione e i criteri del cluster. Config Sync è dichiarativo. È continuamente controlla lo stato del cluster e applica lo stato dichiarato nel file di configurazione a applicare criteri, il che aiuta a prevenire deviazione della configurazione.
Installa Config Sync nel tuo cluster GKE. Configura Config Sync per sincronizzare le configurazioni e i criteri dei cluster da un Repository di codice sorgente Cloud. Le risorse sincronizzate includono:
- Configurazione di Cloud Service Mesh a livello di cluster
- Criteri di sicurezza a livello di cluster
- Configurazione e criterio a livello di spazio dei nomi tenant, inclusa la rete criteri, account di servizio, regole RBAC e configurazione di Cloud Service Mesh
Policy Controller
Policy Controller della versione Google Kubernetes Engine (GKE) Enterprise è un controller di ammissione dinamico per Kubernetes che applica In base a CustomResourceDefinition (basato su CRD) i criteri che vengono attuati Apri Policy Agent (OPA).
I controller di ammissione sono plug-in Kubernetes che intercettano le richieste al server dell'API Kubernetes prima che un oggetto venga reso persistente, ma dopo che la richiesta è stata autenticata e autorizzata. Puoi utilizzare i controller di ammissione per limitare il modo in cui viene utilizzato un cluster.
Installerai Policy Controller nel tuo cluster GKE. Queste architetture di riferimento includono criteri di esempio per aiutarti a proteggere il tuo cluster. Applicherai automaticamente i criteri al cluster utilizzando Config Sync. Tu e applicare le seguenti norme:
- Criteri selezionati utili per applicare la sicurezza dei pod. Ad esempio, applichi criteri che impediscono ai pod in esecuzione di container con privilegi e che richiedono principale di sola lettura.
- Norme della libreria di modelli di Policy Controller. Ad esempio, applichi un criterio non consente i servizi di tipo NodePort.
Cloud Service Mesh
Cloud Service Mesh è un mesh di servizi che aiuta a semplificare la gestione delle le comunicazioni tra i servizi. Queste architetture di riferimento configurano Cloud Service Mesh in modo che:
- Inserisce automaticamente i proxy sidecar.
- Applica comunicazione mTLS tra i servizi nel mesh.
- Limita il traffico mesh in uscita solo agli host noti.
- Limita il traffico in entrata solo da determinati client.
- Consente di configurare criteri di sicurezza di rete in base all'identità del servizio anziché in base all'indirizzo IP dei peer sulla rete.
- Limita la comunicazione autorizzata tra i servizi nel mesh. Ad esempio, le app nello spazio dei nomi tenant Possono comunicare solo con app nello stesso spazio dei nomi o con un insieme degli host esterni noti.
- Instrada tutto il traffico in entrata e in uscita tramite gateway mesh dove puoi applicare ulteriori controlli del traffico.
- Supporta la comunicazione sicura tra i cluster.
Incompatibilità e affinità dei nodi
Incompatibilità dei nodi e affinità nodo sono meccanismi Kubernetes che ti consentono di influire sulla pianificazione dei pod. nodi del cluster.
I nodi infetti respingono i pod. Kubernetes non pianificherà un pod su un nodo incompatibile a meno che il pod non abbia una tolleranza per l'incompatibilità. Puoi utilizzare le incompatibilità dei nodi per prenotare i nodi per l'utilizzo solo da parte di determinati carichi di lavoro o tenant. I taint e le tolleranze vengono spesso utilizzati nei cluster multi-tenant. Per ulteriori informazioni, consulta nodi dedicati con incompatibilità e tolleranze documentazione.
L'affinità nodo ti consente di limitare i pod a nodi con etichette specifiche. Se un pod ha un requisito di affinità del nodo, Kubernetes non lo pianifica su un nodo a meno che il nodo non abbia un'etichetta corrispondente al requisito di affinità. Puoi utilizzare l'affinità dei nodi per assicurarti che i pod vengano pianificati sui nodi appropriati.
Puoi utilizzare insieme le incompatibilità dei nodi e l'affinità dei nodi per garantire il carico di lavoro del tenant i pod sono pianificati esclusivamente su nodi riservati al tenant.
Queste architetture di riferimento consentono di controllare la pianificazione delle app tenant nei seguenti modi:
- Creazione di un pool di nodi GKE dedicato al tenant. Ogni nodo nel pool ha un'alterazione correlata al nome del tenant.
- Applicazione automatica della tolleranza e dell'affinità nodo appropriate a qualsiasi pod che abbia come target lo spazio dei nomi tenant. Applichi la tolleranza e affinità con Cambiamenti di PolicyController.
Principio del privilegio minimo
Una best practice per la sicurezza consiste nell'adottare un principio del privilegio minimo a progetti e risorse Google Cloud come i cluster GKE. Utilizzando questo approccio, le app eseguite all'interno del cluster e gli sviluppatori e gli operatori che utilizzano dispongono solo dell'insieme minimo di autorizzazioni richiesto.
Queste architetture di riferimento ti aiutano a utilizzare gli account di servizio con privilegi minimi nel seguente modo:
- Ogni pool di nodi GKE riceve il proprio account di servizio. Ad esempio, i nodi nel pool di nodi del tenant utilizzano un account di servizio dedicato a questi nodi. Gli account di servizio dei nodi sono configurati con autorizzazioni minime richieste.
- Il cluster utilizza la federazione delle identità per i carichi di lavoro per GKE per associare gli account di servizio Kubernetes agli account di servizio Google. In questo modo, alle app del tenant può essere concesso l'accesso limitato a qualsiasi API Google richiesta senza scaricare e memorizzare una chiave dell'account di servizio. Ad esempio: puoi concedere all'account di servizio le autorizzazioni per leggere i dati nel bucket Cloud Storage.
Queste architetture di riferimento ti aiutano a limitare l'accesso alle risorse del cluster nei seguenti modi:
- Puoi creare un ruolo RBAC in Kubernetes di esempio con autorizzazioni limitate per gestire le app. Puoi concedere questo ruolo agli utenti e ai gruppi che operano le app nello spazio dei nomi tenant. Se applichi questo ruolo limitato a utenti e gruppi, questi utenti avranno le autorizzazioni per modificare solo le risorse dell'app nello spazio dei nomi del tenant. Non dispongono delle autorizzazioni per modificare risorse a livello di cluster o e sensibili, come i criteri di Cloud Service Mesh.
Autorizzazione binaria
Autorizzazione binaria consente di applicare in modo forzato i criteri che definisci per le immagini container il deployment nel tuo ambiente GKE. Autorizzazione binaria consente di cui eseguire il deployment solo per le immagini container conformi ai criteri che hai definito. it non consente il deployment di altre immagini container.
In questa architettura di riferimento, Autorizzazione binaria è abilitata con il suo configurazione. Per ispezionare l'impostazione predefinita di Autorizzazione binaria configurazione, consulta Esportare il file YAML dei criteri.
Per ulteriori informazioni su come configurare i criteri, consulta le seguenti indicazioni specifiche:
- Google Cloud CLI
- Console Google Cloud
- L'API REST
- La risorsa Terraform
google_binary_authorization_policy
Verifica attestazione tra organizzazioni
Puoi utilizzare l'autorizzazione binaria per verificare le attestazioni generate da un firmatario di terze parti. Ad esempio, in un apprendimento federato tra più silos caso d'uso, puoi verificare le attestazioni che un'altra organizzazione partecipante è stato creato.
Per verificare le attestazioni create da una terza parte:
- Ricevi le chiavi pubbliche utilizzate dalla terza parte per creare le attestazioni che devi verificare.
- Crea gli attestatori per verificare le attestazioni.
- Aggiungi le chiavi pubbliche che hai ricevuto dalla terza parte agli attestatori che hai creato.
Per ulteriori informazioni sulla creazione di attestatori, consulta le seguenti guida:
- Google Cloud CLI
- Console Google Cloud
- l'API REST
- la risorsa Terraform
google_binary_authorization_attestor
Dashboard GKE Compliance
La dashboard Conformità di GKE fornisce insight strategici per a rafforzare il livello di sicurezza e ad automatizzare i report di conformità per benchmark e standard di settore. Puoi registrare i tuoi cluster GKE per attivare la generazione automatica di report sulla conformità.
Per ulteriori informazioni, vedi Informazioni sulla dashboard di conformità GKE.
Considerazioni sulla sicurezza dell'apprendimento federato
Nonostante il suo modello di condivisione dei dati rigoroso, l'apprendimento federato non è intrinsecamente sicuro contro tutti gli attacchi mirati e devi prendere in considerazione questi rischi quando implementi una delle architetture descritte in questo documento. Esiste anche il rischio di fughe di informazioni non intenzionali sui modelli di ML o sui dati di addestramento dei modelli. Ad esempio, un malintenzionato potrebbe compromettere intenzionalmente il modello di ML globale o i round dell'iniziativa di apprendimento federato oppure eseguire un attacco di temporizzazione (un tipo di attacco lato canale) per raccogliere informazioni sulle dimensioni dei set di dati di addestramento.
Le minacce più comuni nei confronti di un'implementazione dell'apprendimento federato sono i seguenti: che segue:
- Memorizzazione intenzionale o non intenzionale dei dati di addestramento. Il tuo account federato dell’apprendimento dell’implementazione o che un aggressore potrebbe archiviare involontariamente dati in modi con cui potrebbe essere difficile lavorare. Un aggressore potrebbe essere in grado di raccogliere informazioni sul modello ML globale o sugli ultimi round dell'iniziativa di apprendimento federato tramite il reverse engineering dei dati archiviati.
- Estrai informazioni dagli aggiornamenti del modello ML globale. Durante la sessione di apprendimento, un aggressore potrebbe effettuare il reverse engineering degli aggiornamenti Modello ML che il proprietario della federazione raccoglie dalle organizzazioni partecipanti e dispositivi.
- Il proprietario della federazione potrebbe compromettere i round. Una federazione compromessa il proprietario potrebbe controllare un silo o un dispositivo disonesti e avviare un round impegno di apprendimento federato. Alla fine del round, il compromesso proprietario della federazione potrebbe essere in grado di raccogliere informazioni sugli aggiornamenti raccoglie da organizzazioni e dispositivi partecipanti legittimi confrontando questi aggiornamenti con quello prodotto dal silo rogue.
- Le organizzazioni e i dispositivi dei partecipanti potrebbero compromettere il modello di ML globale. Durante l'apprendimento federato, un malintenzionato potrebbe tentare di influire deliberatamente sul rendimento, sulla qualità o sull'integrità del modello di ML globale producendo aggiornamenti non validi o irrilevanti.
Per contribuire a mitigare l'impatto delle minacce descritte in questa sezione, consigliamo di seguire le seguenti best practice:
- Ottimizza il modello per ridurre al minimo la memorizzazione dei dati di addestramento.
- Implementare meccanismi che tutelano la privacy.
- Controlla regolarmente il modello ML globale, i modelli ML che intendi condividere, i dati di addestramento e l'infrastruttura che hai implementato per raggiungere i tuoi obiettivi di apprendimento federato.
- Implementa un algoritmo di aggregazione sicura per elaborare i risultati dell'addestramento prodotti dalle organizzazioni partecipanti.
- Genera e distribuisci in modo sicuro le chiavi di crittografia dei dati utilizzando un'infrastruttura a chiave pubblica.
- Esegui il deployment dell'infrastruttura piattaforma di computing riservata.
I proprietari della federazione devono anche svolgere i seguenti passaggi aggiuntivi:
- Verifica l'identità di ogni organizzazione partecipante e l'integrità di ogni silo in caso di architetture cross-silo, nonché l'identità e l'integrità di ogni dispositivo in caso di architetture cross-device.
- Limitare l'ambito degli aggiornamenti al modello ML globale che possono produrre le organizzazioni e i dispositivi dei partecipanti.
Affidabilità
Questa sezione descrive i fattori di progettazione da prendere in considerazione quando utilizzi una delle architetture di riferimento presenti in questo documento per progettare e creare una piattaforma di apprendimento federata su Google Cloud.
Quando progetti l'architettura di apprendimento federato su Google Cloud, ti consigliamo di seguire le indicazioni riportate in questa sezione per migliorare la disponibilità e la scalabilità del carico di lavoro e contribuire a rendere l'architettura resiliente a interruzioni e disastri.
GKE: GKE supporta diversi tipi di cluster che puoi personalizzare in base ai requisiti di disponibilità dei tuoi carichi di lavoro e al tuo budget. Ad esempio, puoi creare cluster a livello di regione che distribuiscono il piano di controllo e i nodi tra diverse zone all'interno di un a livello di regione o di zona che hanno il piano di controllo e i nodi in un zona di destinazione. Sia le architetture di riferimento cross-silo che cross-device si basano cluster GKE. Per ulteriori informazioni sugli aspetti da considerare durante la creazione per i cluster GKE, consulta scelte di configurazione del cluster.
A seconda del tipo di cluster e di come sono i nodi del piano di controllo e del cluster distribuiti tra regioni e zone, GKE offre diverse di ripristino di emergenza per proteggere i carichi di lavoro a livello di regione. Per ulteriori informazioni sull'emergenza di GKE di ripristino, vedi Architecting ripristino di emergenza in caso di interruzioni dell'infrastruttura cloud: Google Kubernetes Engine.
Google Cloud Load Balancing: GKE supporta diversi modi per bilanciare il carico del traffico verso i carichi di lavoro. Lo strumento GKE delle implementazioni Gateway Kubernetes e Servizio Kubernetes Le API consentono di eseguire automaticamente il provisioning Cloud Load Balancing per esporre in modo sicuro e affidabile i carichi di lavoro in esecuzione cluster GKE.
In queste architetture di riferimento, tutto il traffico in entrata e in uscita passa attraverso i gateway Cloud Service Mesh. Questi gateway ti consentono di controllare in modo rigoroso il flusso di traffico all'interno e all'esterno dei tuoi cluster GKE.
Problemi di affidabilità per l'apprendimento federato cross-device
L'apprendimento federato cross-device presenta una serie di sfide di affidabilità che non riscontrati in scenari multi-silo. Di seguito sono elencati alcuni esempi:
- Connettività del dispositivo inaffidabile o intermittente
- Spazio di archiviazione del dispositivo limitato
- Computing e memoria limitati
Una connettività inaffidabile può causare problemi quali:
- Aggiornamenti obsoleti e divergenza dei modelli: in caso di problemi con i dispositivi la connettività è intermittente, gli aggiornamenti del modello locale potrebbero diventare inattivi, che rappresentano informazioni obsolete rispetto allo stato attuale dei globale. L'aggregazione degli aggiornamenti inattivi può portare a differenze nel modello, dove il modello globale si discosta dalla soluzione ottimale a causa di incoerenze nel processo di addestramento.
- Contributi sbilanciati e modelli distorti: la comunicazione intermittente può comportare una distribuzione non uniforme dei contributi dei dispositivi partecipanti. I dispositivi con connettività scadente potrebbero contribuire a un numero inferiore di aggiornamenti. generando una rappresentazione sbilanciata dei dati sottostanti distribuzione dei contenuti. Questo squilibrio può portare a un pregiudizio del modello globale nei confronti dei dati provenienti da dispositivi con connessioni più affidabili.
- Aumento del sovraccarico di rete e del consumo energetico: la comunicazione intermittente può comportare un aumento del sovraccarico di rete, poiché i dispositivi potrebbero dover inviare nuovamente gli aggiornamenti persi o danneggiati. Questo problema può anche aumentare il consumo energetico dei dispositivi, soprattutto per quelli con una durata limitata della batteria, potrebbero dover mantenere le connessioni attive per periodi più lunghi la corretta trasmissione degli aggiornamenti.
Per ridurre alcuni degli effetti causati da una comunicazione intermittente, architetture di riferimento di questo documento possono essere utilizzate con il FCP.
Un'architettura di sistema che esegue il protocollo FCP può essere progettata per soddisfare i seguenti requisiti:
- Gestisci i round a lunga esecuzione.
- Attiva l'esecuzione speculativa (i round possono iniziare prima che il numero richiesto di client sia assemblato in previsione di un numero maggiore di check-in a breve).
- Consenti ai dispositivi di scegliere a quali attività partecipare. Questo approccio puoi attivare funzionalità come il campionamento senza sostituzione, una strategia di campionamento in cui ogni unità campione di una popolazione ha una sola possibilità da selezionare. Questo approccio aiuta a mitigare lo squilibrio contributi e modelli parziali
- Estensibile per tecniche di anonimizzazione come la privacy differenziale (DP) e l'aggregazione attendibile (TAG).
Per contribuire a mitigare le limitate capacità di calcolo e di archiviazione dei dispositivi, possono essere utili le seguenti tecniche:
- Scopri qual è la capacità massima disponibile per eseguire il calcolo dell'apprendimento federato
- Comprendere quanti dati possono essere conservati in un determinato momento
- Progetta il codice di apprendimento federato lato client in modo che funzioni entro le risorse di calcolo e RAM disponibili sui client
- Comprendere le implicazioni dell'esaurimento dello spazio di archiviazione e dell'implementazione per la gestione
Ottimizzazione dei costi
Questa sezione fornisce indicazioni per ottimizzare i costi di creazione ed esecuzione piattaforma di apprendimento federata su Google Cloud che stabilisci utilizzando per questa architettura di riferimento. Queste indicazioni valgono per entrambe le architetture descritte in questo documento.
L'esecuzione di carichi di lavoro su GKE può aiutarti a ottimizzare i costi del tuo ambiente eseguendo il provisioning e la configurazione dei cluster in base ai requisiti delle risorse dei carichi di lavoro. Inoltre, abilita funzionalità che riconfigurano dinamicamente i cluster e i nodi del cluster, ad esempio la scalabilità automatica dei nodi e dei pod del cluster e la dimensione corretta dei cluster.
Per saperne di più sull'ottimizzazione dei costi degli ambienti GKE, consulta Best practice per l'esecuzione di applicazioni Kubernetes con ottimizzazione dei costi su GKE.
Efficienza operativa
Questa sezione descrive i fattori da considerare per ottimizzare l'efficienza quando utilizzi questa architettura di riferimento per creare ed eseguire una piattaforma di machine learning federata su Google Cloud. Queste linee guida si applicano entrambe le architetture descritte in questo documento.
Per aumentare l'automazione e il monitoraggio dell'apprendimento federato ti consigliamo di adottare i principi MLOps, ossia DevOps nel contesto dei sistemi di machine learning. Praticare le MLOps significa promuovere l'automazione e il monitoraggio di tutte le fasi della creazione di un sistema ML, tra cui integrazione, test, rilascio, deployment e gestione dell'infrastruttura. Per saperne di più sulle MLOps, consulta MLOps: pipeline di distribuzione continua e automazione nel machine learning.
Ottimizzazione delle prestazioni
Questa sezione descrive i fattori da prendere in considerazione per ottimizzare il rendimento dei tuoi carichi di lavoro quando utilizzi questa architettura di riferimento per creare ed eseguire la piattaforma di apprendimento federata su Google Cloud. Queste linee guida si applicano entrambe le architetture descritte in questo documento.
GKE supporta diverse funzionalità per ridimensionare e scalare automaticamente e manualmente l'ambiente GKE in base alle esigenze dei carichi di lavoro e per aiutarti a evitare il provisioning eccessivo delle risorse. Ad esempio, puoi utilizzare Recommender per generare approfondimenti e consigli per ottimizzare l'utilizzo delle risorse GKE.
Per quanto riguarda la scalabilità del tuo ambiente GKE, ti consigliamo di elaborare piani a breve, medio e lungo termine in base alle tue intenzioni per scalare ambienti e carichi di lavoro. Ad esempio, come intendi far crescere il tuo impatto GKE in alcune settimane, mesi e anni? Avere un piano pronto ti aiuta a sfruttare al meglio la scalabilità fornite da GKE, ottimizzano ambienti GKE e ridurre i costi. Per ulteriori informazioni sulla pianificazione della scalabilità del cluster e del carico di lavoro, vedi Informazioni sulla scalabilità di GKE.
Per aumentare le prestazioni dei tuoi carichi di lavoro ML, puoi adottare Unità di elaborazione Cloud Tensor (Cloud TPU), acceleratori AI progettati da Google e ottimizzati per l'addestramento e l'inferenza dei modelli AI di grandi dimensioni.
Deployment
Per eseguire il deployment delle architetture di riferimento cross-silo e cross-device che descrive il documento, consulta Apprendimento federato su Google Cloud GitHub di ASL.
Passaggi successivi
- Scopri come implementare gli algoritmi di apprendimento federato sulla piattaforma TensorFlow Federated.
- Scopri di più su progressi e problemi aperti nell'apprendimento federato.
- Scopri di più sull'apprendimento federato nel blog di Google AI.
- Guarda come Google mantiene intatta la privacy quando si utilizza l'apprendimento federato con informazioni aggregate anonimizzate per migliorare i modelli di ML.
- Leggi l'articolo Verso l'apprendimento federato su larga scala.
- Scopri come implementare una pipeline MLOps per gestire il ciclo di vita dei modelli di machine learning.
- Per altre architetture di riferimento, diagrammi e best practice, visita il Centro architetture di Google Cloud.
Collaboratori
Autori:
- Giulia Martini | Responsabile soluzioni
- Marco Ferrari | Cloud Solutions Architect
Altri collaboratori:
- Chloé Kiddon | Ingegnere e responsabile del personale informatico
- Laurent Grangeau | Solutions Architect
- Lilian Felix | Cloud engineer