Dokumen deployment ini menjelaskan cara men-deploy pipeline Dataflow untuk memproses file gambar dalam skala besar dengan Cloud Vision API. Pipeline ini menyimpan hasil file yang diproses di BigQuery. Anda dapat menggunakan file tersebut untuk tujuan analisis atau untuk melatih model BigQuery ML.
Pipeline Dataflow yang Anda buat dalam deployment ini dapat memproses jutaan gambar per hari. Satu-satunya batasan adalah kuota Vision API Anda. Anda dapat meningkatkan kuota Vision API berdasarkan persyaratan skala.
Petunjuk ini ditujukan untuk data engineer dan data scientist. Dokumen ini mengasumsikan bahwa Anda memiliki pengetahuan dasar tentang cara membuat pipeline Dataflow menggunakan Java SDK Apache Beam, GoogleSQL untuk BigQuery, dan skrip shell dasar. Tutorial ini juga mengasumsikan bahwa Anda sudah memahami Vision API.
Arsitektur
Diagram berikut mengilustrasikan alur sistem untuk membuat solusi analisis visi ML.

Pada diagram sebelumnya, informasi mengalir melalui arsitektur sebagai berikut:
- Klien mengupload file gambar ke bucket Cloud Storage.
- Cloud Storage mengirimkan pesan tentang upload data ke Pub/Sub.
- Pub/Sub akan memberi tahu Dataflow tentang upload.
- Pipeline Dataflow mengirimkan gambar ke Vision API.
- Vision API memproses gambar, lalu menampilkan anotasi.
- Pipeline mengirimkan file yang dianotasi ke BigQuery untuk Anda analisis.
Tujuan
- Buat pipeline Apache Beam untuk analisis gambar dari gambar yang dimuat di Cloud Storage.
- Gunakan Dataflow Runner v2 untuk menjalankan pipeline Apache Beam dalam mode streaming guna menganalisis gambar segera setelah diupload.
- Menggunakan Vision API untuk menganalisis gambar dari serangkaian jenis fitur.
- Menganalisis anotasi dengan BigQuery.
Biaya
Dalam dokumen ini, Anda menggunakan komponen Google Cloud yang dapat ditagih berikut:
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Setelah selesai mem-build aplikasi contoh, Anda dapat menghindari penagihan berkelanjutan dengan menghapus resource yang Anda buat. Untuk mengetahui informasi selengkapnya, lihat Pembersihan.
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
-
Make sure that billing is enabled for your Google Cloud project.
-
Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
-
Make sure that billing is enabled for your Google Cloud project.
-
Di konsol Google Cloud, aktifkan Cloud Shell.
Di bagian bawah Google Cloud Console, Cloud Shell sesi akan terbuka dan menampilkan perintah command line. Cloud Shell adalah lingkungan shell dengan Google Cloud CLI yang sudah terinstal, dan dengan nilai yang sudah ditetapkan untuk project Anda saat ini. Diperlukan waktu beberapa detik untuk melakukan inisialisasi sesi.
- Clone repositori GitHub yang berisi kode sumber
pipeline Dataflow:
git clone https://github.com/GoogleCloudPlatform/dataflow-vision-analytics.git - Buka folder root repositori:
cd dataflow-vision-analytics - Ikuti petunjuk di bagian Memulai repositori dataflow-vision-analytics di GitHub untuk menyelesaikan tugas berikut:
- Aktifkan beberapa API.
- Membuat bucket Cloud Storage.
- Buat topik dan langganan Pub/Sub.
- Membuat set data BigQuery.
- Siapkan beberapa variabel lingkungan untuk deployment ini.
Menjalankan pipeline Dataflow untuk semua fitur Vision API yang diterapkan
Pipeline Dataflow meminta dan memproses kumpulan fitur dan atribut Vision API tertentu dalam file yang dianotasi.
Parameter yang tercantum dalam tabel berikut bersifat khusus untuk pipeline Dataflow dalam deployment ini. Untuk mengetahui daftar lengkap parameter eksekusi Dataflow standar, lihat Menetapkan opsi pipeline Dataflow.
| Nama parameter | Deskripsi |
|---|---|
|
Jumlah gambar yang akan disertakan dalam permintaan ke Vision API. Nilai defaultnya adalah 1. Anda dapat meningkatkan nilai ini ke maksimum 16. |
|
Nama set data BigQuery output. |
|
Daftar fitur pemrosesan gambar. Pipeline ini mendukung fitur label, penanda, logo, wajah, petunjuk pemangkasan, dan properti gambar. |
|
Parameter yang menentukan jumlah maksimum panggilan paralel ke Vision API. Nilai defaultnya adalah 1. |
|
Parameter string dengan menggunakan nama tabel untuk berbagai anotasi. Nilai
default diberikan untuk setiap tabel—misalnya,
label_annotation. |
|
Durasi waktu tunggu sebelum memproses gambar jika ada batch gambar yang tidak lengkap. Defaultnya adalah 30 detik. |
|
ID langganan Pub/Sub yang menerima notifikasi Cloud Storage input. |
|
Project ID yang akan digunakan untuk Vision API. |
Di Cloud Shell, jalankan perintah berikut untuk memproses gambar untuk semua jenis fitur yang didukung oleh pipeline Dataflow:
./gradlew run --args=" \ --jobName=test-vision-analytics \ --streaming \ --runner=DataflowRunner \ --enableStreamingEngine \ --diskSizeGb=30 \ --project=${PROJECT} \ --datasetName=${BIGQUERY_DATASET} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=IMAGE_PROPERTIES,LABEL_DETECTION,LANDMARK_DETECTION,LOGO_DETECTION,CROP_HINTS,FACE_DETECTION"Akun layanan khusus harus memiliki akses baca ke bucket yang berisi image. Dengan kata lain, akun tersebut harus memiliki peran
roles/storage.objectVieweryang diberikan di bucket tersebut.Untuk mengetahui informasi selengkapnya tentang cara menggunakan akun layanan khusus, lihat Keamanan dan izin Dataflow.
Buka URL yang ditampilkan di tab browser baru, atau buka halaman Dataflow Jobs dan pilih pipeline test-vision-analytics.
Setelah beberapa detik, grafik untuk tugas Dataflow akan muncul:
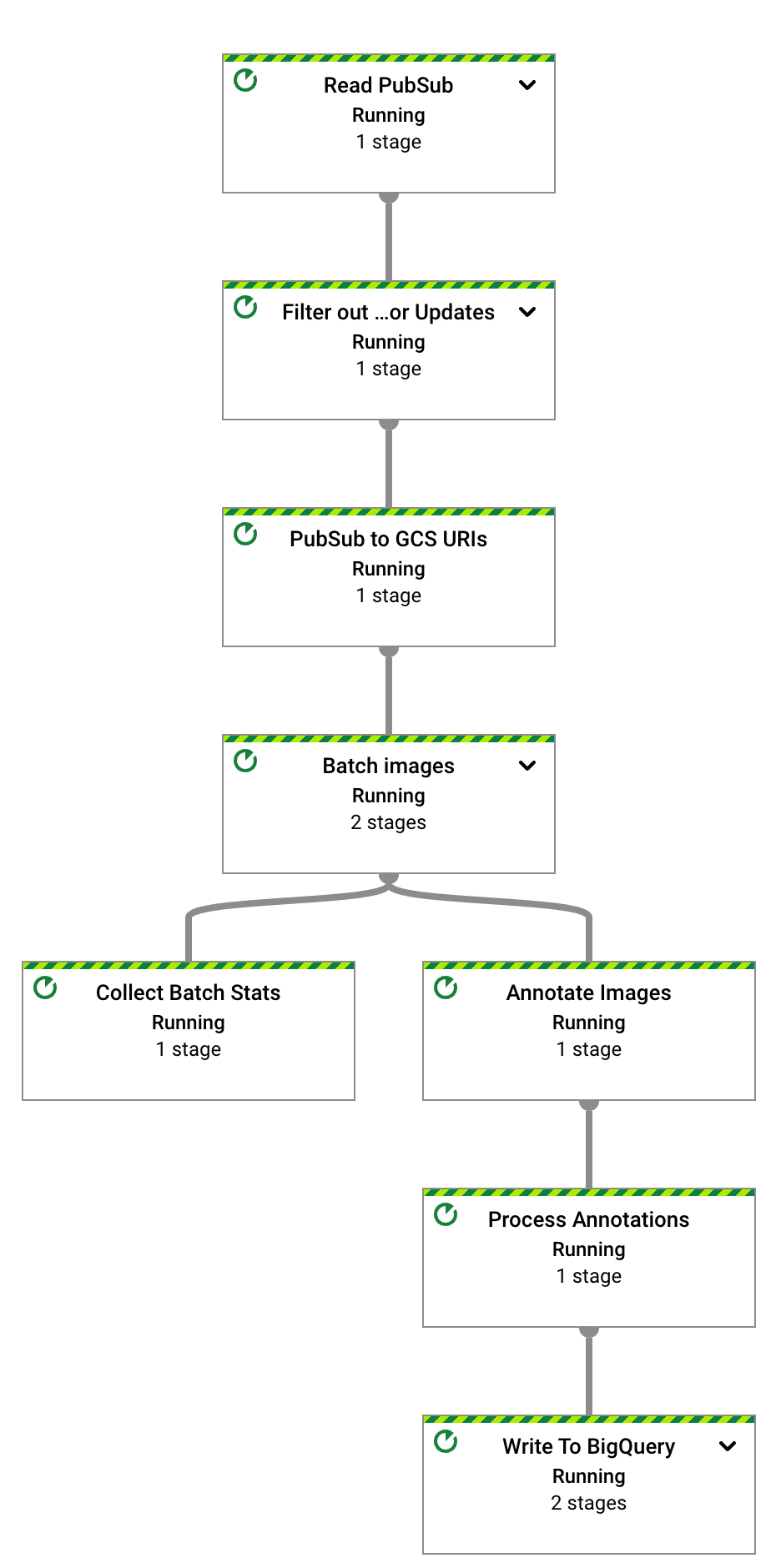
Pipeline Dataflow sekarang sedang berjalan dan menunggu untuk menerima notifikasi input dari langganan Pub/Sub.
Picu pemrosesan gambar Dataflow dengan mengupload enam file contoh ke dalam bucket input:
gcloud storage cp data-sample/* gs://${IMAGE_BUCKET}Di konsol Google Cloud, temukan panel Penghitung Kustom dan gunakan untuk meninjau penghitung kustom di Dataflow dan memverifikasi bahwa Dataflow telah memproses keenam gambar. Anda dapat menggunakan fungsi filter panel untuk membuka metrik yang benar. Untuk hanya menampilkan penghitung yang dimulai dengan awalan
numberOf, ketiknumberOfdi filter.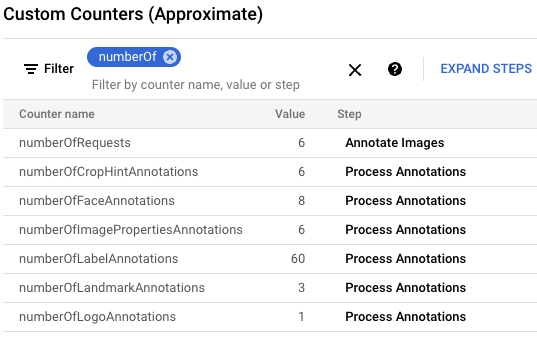
Di Cloud Shell, validasikan bahwa tabel tersebut dibuat secara otomatis:
bq query --nouse_legacy_sql "SELECT table_name FROM ${BIGQUERY_DATASET}.INFORMATION_SCHEMA.TABLES ORDER BY table_name"Outputnya adalah sebagai berikut:
+----------------------+ | table_name | +----------------------+ | crop_hint_annotation | | face_annotation | | image_properties | | label_annotation | | landmark_annotation | | logo_annotation | +----------------------+
Lihat skema untuk tabel
landmark_annotation. FiturLANDMARK_DETECTIONini akan menangkap atribut yang ditampilkan dari panggilan API.bq show --schema --format=prettyjson ${BIGQUERY_DATASET}.landmark_annotationOutputnya adalah sebagai berikut:
[ { "name":"gcs_uri", "type":"STRING" }, { "name":"feature_type", "type":"STRING" }, { "name":"transaction_timestamp", "type":"STRING" }, { "name":"mid", "type":"STRING" }, { "name":"description", "type":"STRING" }, { "name":"score", "type":"FLOAT" }, { "fields":[ { "fields":[ { "name":"x", "type":"INTEGER" }, { "name":"y", "type":"INTEGER" } ], "mode":"REPEATED", "name":"vertices", "type":"RECORD" } ], "name":"boundingPoly", "type":"RECORD" }, { "fields":[ { "fields":[ { "name":"latitude", "type":"FLOAT" }, { "name":"longitude", "type":"FLOAT" } ], "name":"latLon", "type":"RECORD" } ], "mode":"REPEATED", "name":"locations", "type":"RECORD" } ]Lihat data anotasi yang dihasilkan oleh API dengan menjalankan perintah
bq queryberikut untuk melihat semua penanda yang ditemukan dalam enam gambar ini yang diurutkan berdasarkan skor yang paling mungkin:bq query --nouse_legacy_sql "SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score, locations FROM ${BIGQUERY_DATASET}.landmark_annotation ORDER BY score DESC"Outputnya mirip dengan hal berikut ini:
+------------------+-------------------+------------+---------------------------------+ | file_name | description | score | locations | +------------------+-------------------+------------+---------------------------------+ | eiffel_tower.jpg | Eiffel Tower | 0.7251996 | ["POINT(2.2944813 48.8583701)"] | | eiffel_tower.jpg | Trocadéro Gardens | 0.69601923 | ["POINT(2.2892823 48.8615963)"] | | eiffel_tower.jpg | Champ De Mars | 0.6800974 | ["POINT(2.2986304 48.8556475)"] | +------------------+-------------------+------------+---------------------------------+
Untuk deskripsi mendetail tentang semua kolom yang khusus untuk anotasi, lihat
AnnotateImageResponse.Untuk menghentikan pipeline streaming, jalankan perintah berikut. Pipeline akan terus berjalan meskipun tidak ada lagi notifikasi Pub/Sub yang harus diproses.
gcloud dataflow jobs cancel --region ${REGION} $(gcloud dataflow jobs list --region ${REGION} --filter="NAME:test-vision-analytics AND STATE:Running" --format="get(JOB_ID)")Bagian berikut berisi lebih banyak contoh kueri yang menganalisis berbagai fitur gambar.
Menganalisis set data Flickr30K
Di bagian ini, Anda akan mendeteksi label dan landmark di set data gambar Flickr30k publik yang dihosting di Kaggle.
Di Cloud Shell, ubah parameter pipeline Dataflow sehingga dapat dioptimalkan untuk set data besar. Untuk memungkinkan throughput yang lebih tinggi, tingkatkan juga nilai
batchSizedankeyRange. Dataflow menskalakan jumlah pekerja sesuai kebutuhan:./gradlew run --args=" \ --runner=DataflowRunner \ --jobName=vision-analytics-flickr \ --streaming \ --enableStreamingEngine \ --diskSizeGb=30 \ --autoscalingAlgorithm=THROUGHPUT_BASED \ --maxNumWorkers=5 \ --project=${PROJECT} \ --region=${REGION} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=LABEL_DETECTION,LANDMARK_DETECTION \ --datasetName=${BIGQUERY_DATASET} \ --batchSize=16 \ --keyRange=5"Karena set data berukuran besar, Anda tidak dapat menggunakan Cloud Shell untuk mengambil gambar dari Kaggle dan mengirimkannya ke bucket Cloud Storage. Anda harus menggunakan VM dengan ukuran disk yang lebih besar untuk melakukannya.
Untuk mengambil gambar berbasis Kaggle dan mengirimkannya ke bucket Cloud Storage, ikuti petunjuk di bagian Mensimulasikan gambar yang diupload ke bucket penyimpanan di repositori GitHub.
Untuk mengamati progres proses penyalinan dengan melihat metrik kustom yang tersedia di UI Dataflow, buka halaman Dataflow Jobs dan pilih pipeline
vision-analytics-flickr. Penghitung pelanggan akan berubah secara berkala hingga pipeline Dataflow memproses semua file.Outputnya mirip dengan screenshot panel Penghitung Kustom berikut. Salah satu file dalam set data adalah jenis yang salah, dan penghitung
rejectedFilesmencerminkannya. Nilai penghitung ini merupakan perkiraan. Anda mungkin melihat angka yang lebih tinggi. Selain itu, jumlah anotasi kemungkinan besar akan berubah karena peningkatan akurasi pemrosesan oleh Vision API.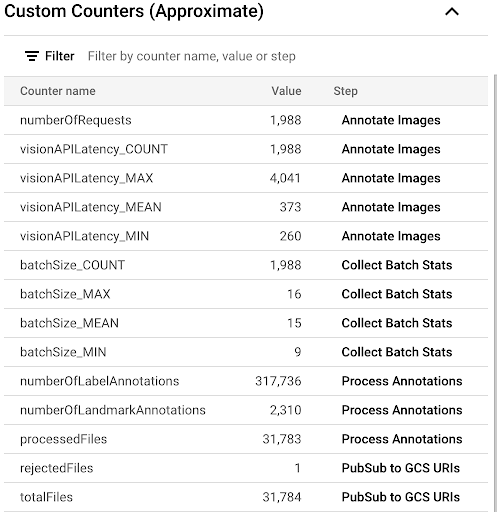
Untuk menentukan apakah Anda mendekati atau melampaui resource yang tersedia, lihat halaman kuota Vision API.
Dalam contoh kita, pipeline Dataflow hanya menggunakan kurang lebih 50% kuotanya. Berdasarkan persentase kuota yang Anda gunakan, Anda dapat memutuskan untuk meningkatkan paralelisme pipeline dengan meningkatkan nilai parameter
keyRange.Menghentikan pipeline:
gcloud dataflow jobs list --region $REGION --filter="NAME:vision-analytics-flickr AND STATE:Running" --format="get(JOB_ID)"
Menganalisis anotasi di BigQuery
Dalam deployment ini, Anda telah memproses lebih dari 30.000 gambar untuk anotasi label dan penanda. Di bagian ini, Anda akan mengumpulkan statistik tentang file tersebut. Anda dapat menjalankan kueri ini di ruang kerja GoogleSQL untuk BigQuery atau menggunakan alat command line bq.
Perhatikan bahwa angka yang Anda lihat dapat bervariasi dari contoh hasil kueri dalam deployment ini. Vision API terus meningkatkan akurasi analisisnya; API ini dapat menghasilkan hasil yang lebih kaya dengan menganalisis gambar yang sama setelah Anda awalnya menguji solusi.
Di konsol Google Cloud, buka halaman Editor kueri BigQuery dan jalankan perintah berikut untuk melihat 20 label teratas dalam set data:
SELECT description, count(*)ascount \ FROM vision_analytics.label_annotation GROUP BY description ORDER BY count DESC LIMIT 20Outputnya mirip dengan hal berikut ini:
+------------------+-------+ | description | count | +------------------+-------+ | Leisure | 7663 | | Plant | 6858 | | Event | 6044 | | Sky | 6016 | | Tree | 5610 | | Fun | 5008 | | Grass | 4279 | | Recreation | 4176 | | Shorts | 3765 | | Happy | 3494 | | Wheel | 3372 | | Tire | 3371 | | Water | 3344 | | Vehicle | 3068 | | People in nature | 2962 | | Gesture | 2909 | | Sports equipment | 2861 | | Building | 2824 | | T-shirt | 2728 | | Wood | 2606 | +------------------+-------+
Menentukan label lain yang ada pada gambar dengan label tertentu, yang diberi peringkat berdasarkan frekuensi:
DECLARE label STRING DEFAULT 'Plucked string instruments'; WITH other_labels AS ( SELECT description, COUNT(*) count FROM vision_analytics.label_annotation WHERE gcs_uri IN ( SELECT gcs_uri FROM vision_analytics.label_annotation WHERE description = label ) AND description != label GROUP BY description) SELECT description, count, RANK() OVER (ORDER BY count DESC) rank FROM other_labels ORDER BY rank LIMIT 20;Outputnya adalah sebagai berikut. Untuk label Plucked string instruments yang digunakan dalam perintah sebelumnya, Anda akan melihat:
+------------------------------+-------+------+ | description | count | rank | +------------------------------+-------+------+ | String instrument | 397 | 1 | | Musical instrument | 236 | 2 | | Musician | 207 | 3 | | Guitar | 168 | 4 | | Guitar accessory | 135 | 5 | | String instrument accessory | 99 | 6 | | Music | 88 | 7 | | Musical instrument accessory | 72 | 8 | | Guitarist | 72 | 8 | | Microphone | 52 | 10 | | Folk instrument | 44 | 11 | | Violin family | 28 | 12 | | Hat | 23 | 13 | | Entertainment | 22 | 14 | | Band plays | 21 | 15 | | Jeans | 17 | 16 | | Plant | 16 | 17 | | Public address system | 16 | 17 | | Artist | 16 | 17 | | Leisure | 14 | 20 | +------------------------------+-------+------+
Lihat 10 landmark teratas yang terdeteksi:
SELECT description, COUNT(description) AS count FROM vision_analytics.landmark_annotation GROUP BY description ORDER BY count DESC LIMIT 10Outputnya adalah sebagai berikut:
+--------------------+-------+ | description | count | +--------------------+-------+ | Times Square | 55 | | Rockefeller Center | 21 | | St. Mark's Square | 16 | | Bryant Park | 13 | | Millennium Park | 13 | | Ponte Vecchio | 13 | | Tuileries Garden | 13 | | Central Park | 12 | | Starbucks | 12 | | National Mall | 11 | +--------------------+-------+
Tentukan gambar yang kemungkinan besar berisi air terjun:
SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score FROM vision_analytics.landmark_annotation WHERE LOWER(description) LIKE '%fall%' ORDER BY score DESC LIMIT 10Outputnya adalah sebagai berikut:
+----------------+----------------------------+-----------+ | file_name | description | score | +----------------+----------------------------+-----------+ | 895502702.jpg | Waterfall Carispaccha | 0.6181358 | | 3639105305.jpg | Sahalie Falls Viewpoint | 0.44379658 | | 3672309620.jpg | Gullfoss Falls | 0.41680416 | | 2452686995.jpg | Wahclella Falls | 0.39005348 | | 2452686995.jpg | Wahclella Falls | 0.3792498 | | 3484649669.jpg | Kodiveri Waterfalls | 0.35024035 | | 539801139.jpg | Mallela Thirtham Waterfall | 0.29260656 | | 3639105305.jpg | Sahalie Falls | 0.2807213 | | 3050114829.jpg | Kawasan Falls | 0.27511594 | | 4707103760.jpg | Niagara Falls | 0.18691841 | +----------------+----------------------------+-----------+
Temukan gambar landmark dalam jarak 3 kilometer dari Colosseum di Roma (fungsi
ST_GEOPOINTini menggunakan garis bujur dan lintang Colosseum):WITH landmarksWithDistances AS ( SELECT gcs_uri, description, location, ST_DISTANCE(location, ST_GEOGPOINT(12.492231, 41.890222)) distance_in_meters, FROM `vision_analytics.landmark_annotation` landmarks CROSS JOIN UNNEST(landmarks.locations) AS location ) SELECT SPLIT(gcs_uri,"/")[OFFSET(3)] file, description, ROUND(distance_in_meters) distance_in_meters, location, CONCAT("https://storage.cloud.google.com/", SUBSTR(gcs_uri, 6)) AS image_url FROM landmarksWithDistances WHERE distance_in_meters < 3000 ORDER BY distance_in_meters LIMIT 100Saat menjalankan kueri, Anda akan melihat bahwa ada beberapa gambar Colosseum, tetapi juga gambar Arch Of Constantine, Palatine Hill, dan sejumlah tempat lain yang sering difoto.
Anda dapat memvisualisasikan data di BigQuery Geo Viz dengan menempelkan kueri sebelumnya. Pilih titik pada peta, untuk melihat detailnya. Atribut
Image_urlberisi link ke file gambar.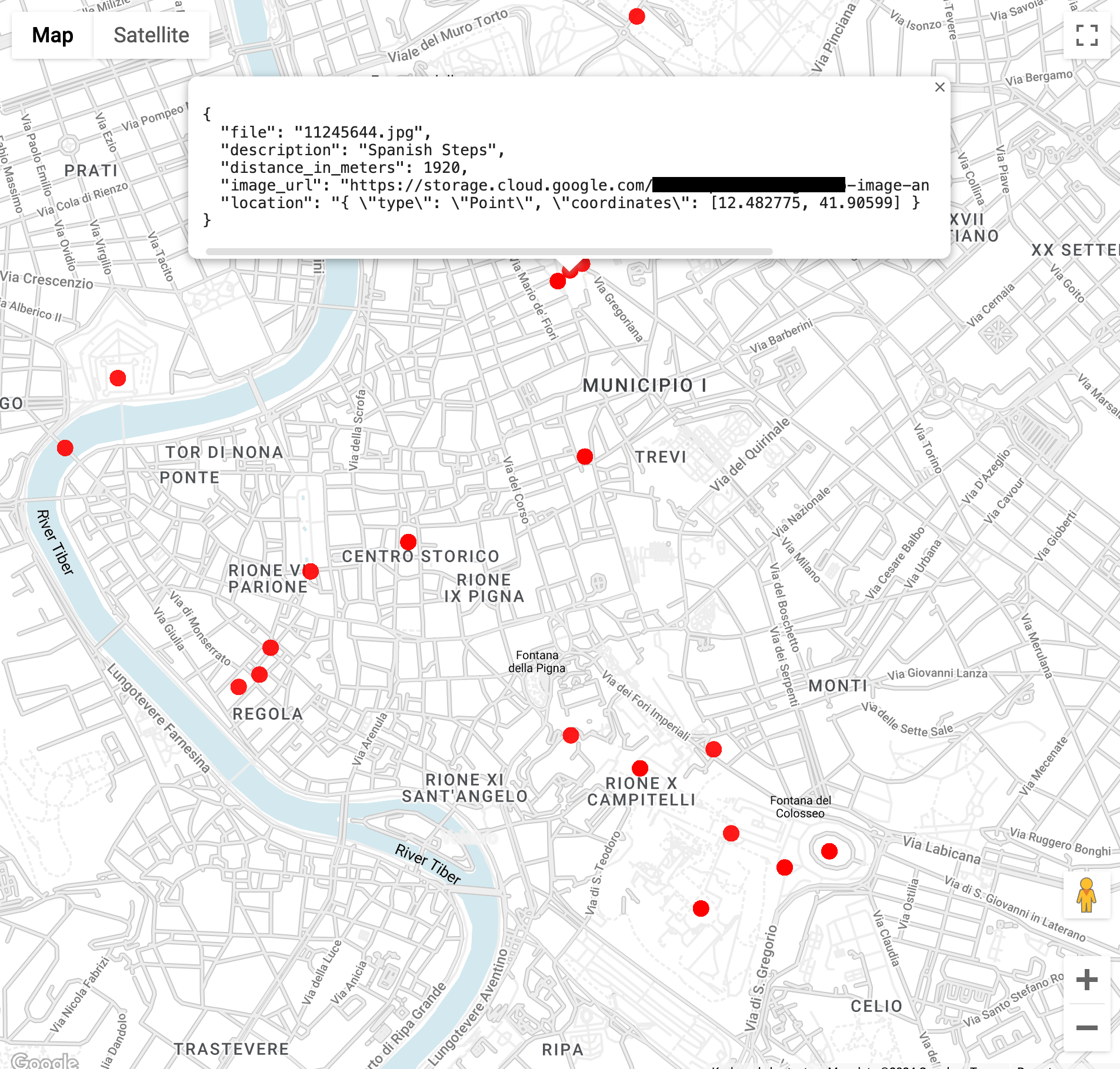
Satu catatan tentang hasil kueri. Informasi lokasi biasanya tersedia untuk
tempat terkenal. Gambar yang sama dapat berisi beberapa lokasi untuk landmark yang sama.
Fungsi ini dijelaskan dalam jenis
AnnotateImageResponse.
Karena satu lokasi dapat menunjukkan lokasi kejadian dalam gambar,
beberapa elemen
LocationInfo
dapat muncul. Lokasi lain dapat menunjukkan tempat
gambar diambil.
Pembersihan
Agar tidak dikenai biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam panduan ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus setiap resource.
Menghapus project Google Cloud
Cara termudah untuk menghilangkan penagihan adalah dengan menghapus project Google Cloud yang Anda buat untuk tutorial.
- Di konsol Google Cloud, buka halaman Manage resource.
- Pada daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
Jika Anda memutuskan untuk menghapus resource satu per satu, ikuti langkah-langkah di bagian Clean up di repositori GitHub.
Langkah selanjutnya
- Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.
Kontributor
Penulis:
- Masud Hasan | Site Reliability Engineering Manager
- Sergei Lilichenko | Solutions Architect
- Lakshmanan Sethu | Technical Account Manager
Kontributor lainnya:
- Jiyeon Kang | Customer Engineer
- Sunil Kumar Jang Bahadur | Customer Engineer