이 배포 문서에서는 Cloud Vision API로 이미지 파일을 대규모로 처리하기 위해 Dataflow 파이프라인을 배포하는 방법을 설명합니다. 이 파이프라인은 처리된 파일의 결과를 BigQuery에 저장합니다. 이 파일을 분석 목적 또는 BigQuery ML 모델을 학습시키는 데 사용할 수 있습니다.
이 배포에서 만든 Dataflow 파이프라인은 하루에 수백만 개의 이미지를 처리할 수 있습니다. 유일한 한도는 Vision API 할당량입니다. 확장 요구사항에 따라 Vision API 할당량을 늘릴 수 있습니다.
이 안내는 데이터 엔지니어와 데이터 과학자를 대상으로 합니다. 이 문서에서는 Apache Beam의 Java SDK, BigQuery용 GoogleSQL, 기본 셸 스크립팅을 사용한 Dataflow 파이프라인 빌드에 대한 기본 지식이 있다고 가정합니다. 또한 Vision API에 익숙하다고 가정합니다.
아키텍처
다음 다이어그램은 ML 비전 분석 솔루션을 빌드하는 시스템 흐름을 보여줍니다.

위의 다이어그램에서 정보는 다음과 같이 아키텍처를 통해 이동합니다.
- 클라이언트가 이미지 파일을 Cloud Storage 버킷에 업로드합니다.
- Cloud Storage가 Pub/Sub에 데이터 업로드에 대한 메시지를 보냅니다.
- Pub/Sub가 Dataflow에 업로드를 알립니다.
- Dataflow 파이프라인은 Vision API로 이미지를 보냅니다.
- Vision API가 이미지를 처리한 다음 주석을 반환합니다.
- 파이프라인은 분석할 수 있도록 주석 처리된 파일을 BigQuery로 보냅니다.
목표
- Cloud Storage에 로드된 이미지의 이미지 분석을 위한 Apache Beam 파이프라인을 만듭니다.
- Dataflow Runner v2를 사용하여 스트리밍 모드에서 Apache Beam 파이프라인을 실행하여 업로드되는 즉시 이미지를 분석합니다.
- Vision API를 사용하여 기능 유형 집합에 대해 이미지를 분석합니다.
- BigQuery로 주석을 분석합니다.
비용
이 문서에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud 구성요소를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
예시 애플리케이션 빌드를 마치면 만든 리소스를 삭제하여 비용이 계속 청구되지 않도록 할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- Dataflow 파이프라인의 소스 코드가 포함된 GitHub 저장소를 클론합니다.
git clone https://github.com/GoogleCloudPlatform/dataflow-vision-analytics.git - 저장소의 루트 폴더로 이동합니다.
cd dataflow-vision-analytics - GitHub의 dataflow-vision-analytics 저장소에서 시작하기 섹션의 안내에 따라 다음 작업을 수행합니다.
- 여러 API를 사용 설정합니다.
- Cloud Storage 버킷 만들기
- Pub/Sub 주제 및 구독을 만듭니다.
- BigQuery 데이터 세트를 만듭니다.
- 이 배포의 여러 환경 변수를 설정합니다.
구현된 모든 Vision API 기능에 대한 Dataflow 파이프라인 실행
Dataflow 파이프라인은 주석 처리된 파일 내에서 Vision API 기능 및 속성 집합을 요청 및 처리합니다.
다음 표에 나열된 매개변수는 이 배포의 Dataflow 파이프라인에 해당됩니다. 표준 Dataflow 실행 매개변수의 전체 목록은 Dataflow 파이프라인 옵션 설정을 참조하세요.
| 매개변수 이름 | 설명 |
|---|---|
|
Vision API에 대한 요청에 포함할 이미지 수입니다. 기본값은 1입니다. 이 값을 최대 16으로 늘릴 수 있습니다. |
|
출력 BigQuery 데이터 세트의 이름입니다. |
|
이미지 처리 기능의 목록입니다. 이 파이프라인은 라벨, 랜드마크, 로고, 얼굴, 자르기 힌트, 이미지 속성 기능을 지원합니다. |
|
Vision API에 대한 최대 동시 호출 수를 정의하는 매개변수입니다. 기본값은 1입니다. |
|
다양한 주석을 위한 테이블 이름이 있는 문자열 매개변수 각 테이블에 기본값이 제공됩니다(예: label_annotation). |
|
불완전한 이미지 배치가 있는 경우 이미지를 처리하기 전에 대기하는 시간입니다. 기본값은 30초입니다. |
|
입력 Cloud Storage 알림을 수신하는 Pub/Sub 구독의 ID입니다. |
|
Vision API에 사용할 프로젝트 ID입니다. |
Cloud Shell에서 다음 명령어를 실행하여 Dataflow 파이프라인에서 지원하는 모든 기능 유형의 이미지를 처리합니다.
./gradlew run --args=" \ --jobName=test-vision-analytics \ --streaming \ --runner=DataflowRunner \ --enableStreamingEngine \ --diskSizeGb=30 \ --project=${PROJECT} \ --datasetName=${BIGQUERY_DATASET} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=IMAGE_PROPERTIES,LABEL_DETECTION,LANDMARK_DETECTION,LOGO_DETECTION,CROP_HINTS,FACE_DETECTION"전용 서비스 계정에는 이미지가 포함된 버킷에 대한 읽기 액세스 권한이 있어야 합니다. 즉, 해당 계정은 해당 버킷에 부여된
roles/storage.objectViewer역할이 있어야 합니다.전용 서비스 계정 사용에 대한 자세한 내용은 Dataflow 보안 및 권한을 참조하세요.
새 브라우저 탭에서 표시된 URL을 열거나 Dataflow 작업 페이지로 이동하여 test-vision-analytics 파이프라인을 선택합니다.
몇 초 후 Dataflow 작업의 그래프가 표시됩니다.
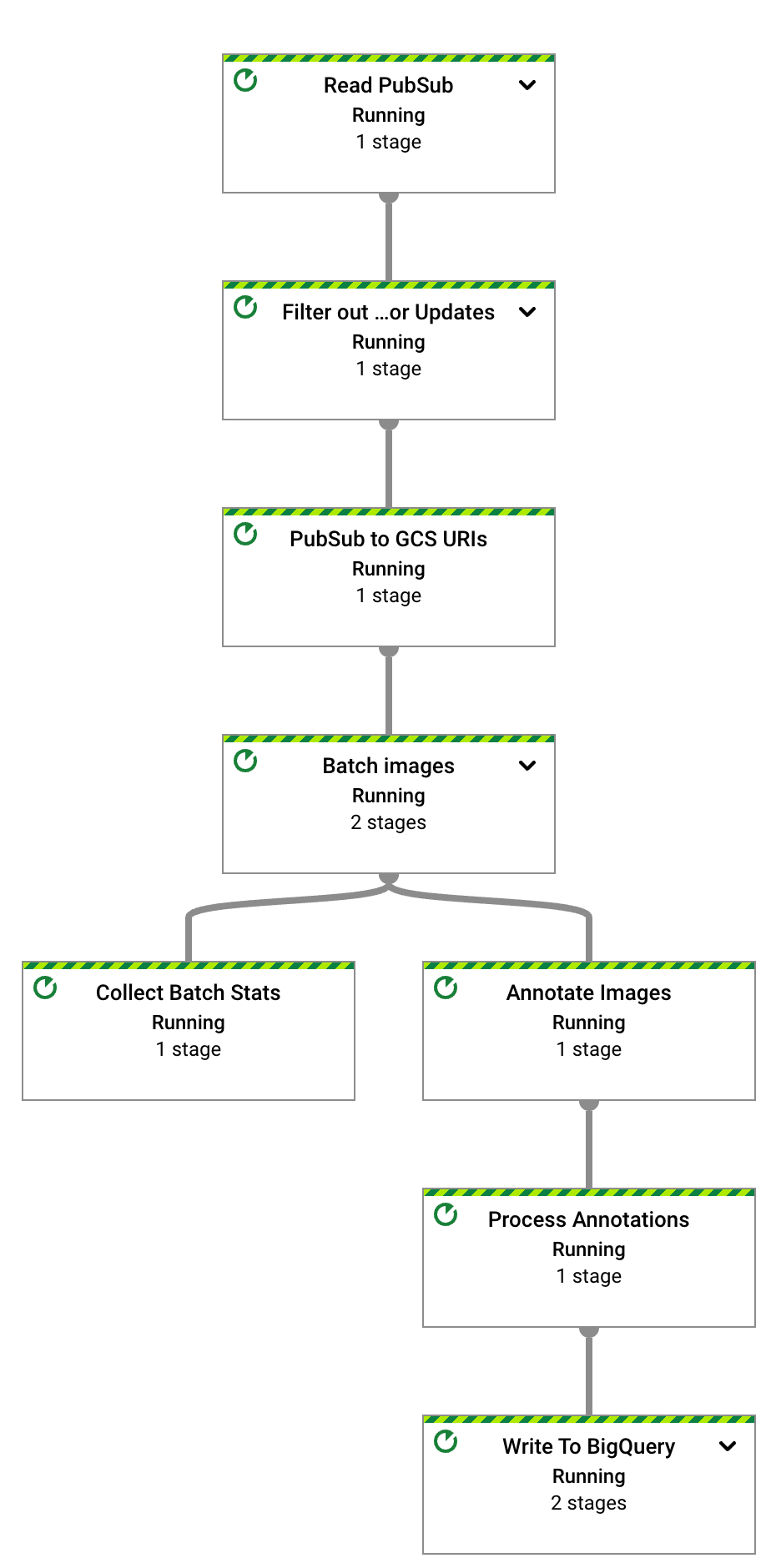
이제 Dataflow 파이프라인이 실행되며 Pub/Sub 구독에서 입력 알림 수신을 기다리는 중입니다.
샘플 파일 6개를 입력 버킷에 업로드하여 Dataflow 이미지 처리를 트리거합니다.
gcloud storage cp data-sample/* gs://${IMAGE_BUCKET}Google Cloud 콘솔에서 커스텀 카운터 패널을 찾아 사용하여 Dataflow의 커스텀 카운터를 검토하고 Dataflow가 6개 이미지를 모두 처리했는지 확인합니다. 패널의 필터 기능을 사용하여 올바른 측정항목으로 이동할 수 있습니다.
numberOf프리픽스로 시작하는 카운터만 표시하려면 필터에numberOf를 입력합니다.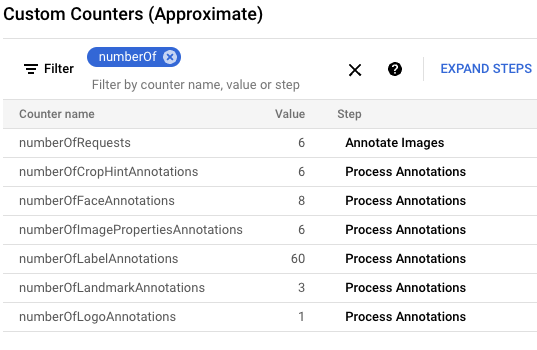
Cloud Shell에서 테이블이 자동으로 생성되었는지 확인합니다.
bq query --nouse_legacy_sql "SELECT table_name FROM ${BIGQUERY_DATASET}.INFORMATION_SCHEMA.TABLES ORDER BY table_name"출력은 다음과 같습니다.
+----------------------+ | table_name | +----------------------+ | crop_hint_annotation | | face_annotation | | image_properties | | label_annotation | | landmark_annotation | | logo_annotation | +----------------------+
landmark_annotation테이블의 스키마를 봅니다.LANDMARK_DETECTION기능은 API 호출에서 반환된 속성을 캡처합니다.bq show --schema --format=prettyjson ${BIGQUERY_DATASET}.landmark_annotation출력은 다음과 같습니다.
[ { "name":"gcs_uri", "type":"STRING" }, { "name":"feature_type", "type":"STRING" }, { "name":"transaction_timestamp", "type":"STRING" }, { "name":"mid", "type":"STRING" }, { "name":"description", "type":"STRING" }, { "name":"score", "type":"FLOAT" }, { "fields":[ { "fields":[ { "name":"x", "type":"INTEGER" }, { "name":"y", "type":"INTEGER" } ], "mode":"REPEATED", "name":"vertices", "type":"RECORD" } ], "name":"boundingPoly", "type":"RECORD" }, { "fields":[ { "fields":[ { "name":"latitude", "type":"FLOAT" }, { "name":"longitude", "type":"FLOAT" } ], "name":"latLon", "type":"RECORD" } ], "mode":"REPEATED", "name":"locations", "type":"RECORD" } ]다음
bq query명령어를 실행하여 API에서 생성된 주석 데이터를 보고 이 6개 이미지에 있는 모든 랜드마크를 가능성이 가장 높은 점수순으로 정렬하여 확인합니다.bq query --nouse_legacy_sql "SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score, locations FROM ${BIGQUERY_DATASET}.landmark_annotation ORDER BY score DESC"출력은 다음과 비슷합니다.
+------------------+-------------------+------------+---------------------------------+ | file_name | description | score | locations | +------------------+-------------------+------------+---------------------------------+ | eiffel_tower.jpg | Eiffel Tower | 0.7251996 | ["POINT(2.2944813 48.8583701)"] | | eiffel_tower.jpg | Trocadéro Gardens | 0.69601923 | ["POINT(2.2892823 48.8615963)"] | | eiffel_tower.jpg | Champ De Mars | 0.6800974 | ["POINT(2.2986304 48.8556475)"] | +------------------+-------------------+------------+---------------------------------+
주석과 관련된 모든 열에 대한 자세한 설명은
AnnotateImageResponse를 참조하세요.스트리밍 파이프라인을 중지하려면 다음 명령어를 실행합니다. 더 이상 처리할 Pub/Sub 알림이 없더라도 파이프라인은 계속 실행됩니다.
gcloud dataflow jobs cancel --region ${REGION} $(gcloud dataflow jobs list --region ${REGION} --filter="NAME:test-vision-analytics AND STATE:Running" --format="get(JOB_ID)")다음 섹션에는 이미지의 여러 이미지 특성을 분석하는 추가 샘플 쿼리가 포함되어 있습니다.
Flickr30K 데이터 세트 분석
이 섹션에서는 Kaggle에서 호스팅되는 공개 Flickr30k 이미지 데이터 세트에서 라벨과 랜드마크를 감지합니다.
Cloud Shell에서 큰 데이터 세트에 대해 최적화되도록 Dataflow 파이프라인 매개변수를 변경합니다. 높은 처리량을 허용하려면
batchSize및keyRange값도 늘립니다. Dataflow는 필요에 따라 작업자 수를 조정합니다../gradlew run --args=" \ --runner=DataflowRunner \ --jobName=vision-analytics-flickr \ --streaming \ --enableStreamingEngine \ --diskSizeGb=30 \ --autoscalingAlgorithm=THROUGHPUT_BASED \ --maxNumWorkers=5 \ --project=${PROJECT} \ --region=${REGION} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=LABEL_DETECTION,LANDMARK_DETECTION \ --datasetName=${BIGQUERY_DATASET} \ --batchSize=16 \ --keyRange=5"데이터 세트가 크기 때문에 Cloud Shell을 사용하여 Kaggle에서 이미지를 검색하고 이를 Cloud Storage 버킷으로 전송할 수 없습니다. 이렇게 하려면 디스크 크기가 더 큰 VM을 사용해야 합니다.
Kaggle 기반 이미지를 검색하여 Cloud Storage 버킷으로 전송하려면 GitHub 저장소에서 스토리지 버킷에 업로드되는 이미지 시뮬레이션 섹션의 안내를 따르세요.
Dataflow UI에서 사용할 수 있는 커스텀 측정항목을 확인하여 복사 프로세스의 진행 상황을 관찰하려면 Dataflow 작업 페이지로 이동하여
vision-analytics-flickr파이프라인을 선택합니다. 커스텀 카운터는 Dataflow 파이프라인이 모든 파일을 처리할 때까지 주기적으로 변경되어야 합니다.출력은 커스텀 카운터 패널의 다음 스크린샷과 비슷합니다. 데이터 세트의 파일 중 하나가 잘못된 유형이고,
rejectedFiles카운터가 이를 반영합니다. 이러한 카운터 값은 근사치입니다. 더 큰 수치가 표시될 수 있습니다. 또한 Vision API의 처리 정확도가 높아져 주석 수가 변경될 가능성이 높습니다.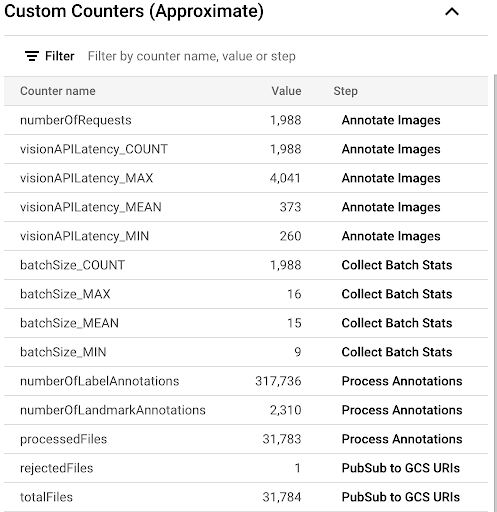
사용 가능한 리소스에 근접하거나 초과하는지 확인하려면 Vision API 할당량 페이지를 참조하세요.
이 예시에서 Dataflow 파이프라인은 할당량의 약 50%만 사용했습니다. 사용하는 할당량의 비율에 따라
keyRange매개변수의 값을 늘려 파이프라인의 동시 로드를 늘릴 수 있습니다.파이프라인을 종료합니다.
gcloud dataflow jobs list --region $REGION --filter="NAME:vision-analytics-flickr AND STATE:Running" --format="get(JOB_ID)"
BigQuery에서 주석 분석
이 배포에서 라벨 및 랜드마크 주석에 대해 30,000개가 넘는 이미지를 처리했습니다. 이 섹션에서는 이러한 파일에 대한 통계를 수집합니다. BigQuery용 GoogleSQL 작업공간에서 이러한 쿼리를 실행하거나 bq 명령줄 도구를 사용할 수 있습니다.
표시되는 숫자는 이 배포의 샘플 쿼리 결과와 다를 수 있습니다. Vision API는 분석 정확성을 지속적으로 향상시켜 줍니다. 솔루션을 처음 테스트한 후 동일한 이미지를 분석하여 보다 풍부한 결과를 얻을 수 있습니다.
Google Cloud 콘솔에서 BigQuery 쿼리 편집기 페이지로 이동하고 다음 명령어를 실행하여 데이터 세트의 상위 20개 라벨을 확인합니다.
SELECT description, count(*)ascount \ FROM vision_analytics.label_annotation GROUP BY description ORDER BY count DESC LIMIT 20출력은 다음과 비슷합니다.
+------------------+-------+ | description | count | +------------------+-------+ | Leisure | 7663 | | Plant | 6858 | | Event | 6044 | | Sky | 6016 | | Tree | 5610 | | Fun | 5008 | | Grass | 4279 | | Recreation | 4176 | | Shorts | 3765 | | Happy | 3494 | | Wheel | 3372 | | Tire | 3371 | | Water | 3344 | | Vehicle | 3068 | | People in nature | 2962 | | Gesture | 2909 | | Sports equipment | 2861 | | Building | 2824 | | T-shirt | 2728 | | Wood | 2606 | +------------------+-------+
빈도에 따라 순위가 지정된 특정 라벨이 있는 이미지에 있는 다른 라벨을 확인합니다.
DECLARE label STRING DEFAULT 'Plucked string instruments'; WITH other_labels AS ( SELECT description, COUNT(*) count FROM vision_analytics.label_annotation WHERE gcs_uri IN ( SELECT gcs_uri FROM vision_analytics.label_annotation WHERE description = label ) AND description != label GROUP BY description) SELECT description, count, RANK() OVER (ORDER BY count DESC) rank FROM other_labels ORDER BY rank LIMIT 20;출력은 다음과 같습니다. 앞의 명령어에 사용된 발현악기 라벨은 다음과 같습니다.
+------------------------------+-------+------+ | description | count | rank | +------------------------------+-------+------+ | String instrument | 397 | 1 | | Musical instrument | 236 | 2 | | Musician | 207 | 3 | | Guitar | 168 | 4 | | Guitar accessory | 135 | 5 | | String instrument accessory | 99 | 6 | | Music | 88 | 7 | | Musical instrument accessory | 72 | 8 | | Guitarist | 72 | 8 | | Microphone | 52 | 10 | | Folk instrument | 44 | 11 | | Violin family | 28 | 12 | | Hat | 23 | 13 | | Entertainment | 22 | 14 | | Band plays | 21 | 15 | | Jeans | 17 | 16 | | Plant | 16 | 17 | | Public address system | 16 | 17 | | Artist | 16 | 17 | | Leisure | 14 | 20 | +------------------------------+-------+------+
감지된 상위 10개의 랜드마크를 확인합니다.
SELECT description, COUNT(description) AS count FROM vision_analytics.landmark_annotation GROUP BY description ORDER BY count DESC LIMIT 10출력은 다음과 같습니다.
+--------------------+-------+ | description | count | +--------------------+-------+ | Times Square | 55 | | Rockefeller Center | 21 | | St. Mark's Square | 16 | | Bryant Park | 13 | | Millennium Park | 13 | | Ponte Vecchio | 13 | | Tuileries Garden | 13 | | Central Park | 12 | | Starbucks | 12 | | National Mall | 11 | +--------------------+-------+
폭포가 있을 가능성이 가장 높은 이미지를 확인합니다.
SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score FROM vision_analytics.landmark_annotation WHERE LOWER(description) LIKE '%fall%' ORDER BY score DESC LIMIT 10출력은 다음과 같습니다.
+----------------+----------------------------+-----------+ | file_name | description | score | +----------------+----------------------------+-----------+ | 895502702.jpg | Waterfall Carispaccha | 0.6181358 | | 3639105305.jpg | Sahalie Falls Viewpoint | 0.44379658 | | 3672309620.jpg | Gullfoss Falls | 0.41680416 | | 2452686995.jpg | Wahclella Falls | 0.39005348 | | 2452686995.jpg | Wahclella Falls | 0.3792498 | | 3484649669.jpg | Kodiveri Waterfalls | 0.35024035 | | 539801139.jpg | Mallela Thirtham Waterfall | 0.29260656 | | 3639105305.jpg | Sahalie Falls | 0.2807213 | | 3050114829.jpg | Kawasan Falls | 0.27511594 | | 4707103760.jpg | Niagara Falls | 0.18691841 | +----------------+----------------------------+-----------+
로마의 콜로세움에서 3km 이내에 있는 랜드마크의 이미지를 찾습니다(
ST_GEOPOINT함수는 콜로세움의 경도와 위도를 사용).WITH landmarksWithDistances AS ( SELECT gcs_uri, description, location, ST_DISTANCE(location, ST_GEOGPOINT(12.492231, 41.890222)) distance_in_meters, FROM `vision_analytics.landmark_annotation` landmarks CROSS JOIN UNNEST(landmarks.locations) AS location ) SELECT SPLIT(gcs_uri,"/")[OFFSET(3)] file, description, ROUND(distance_in_meters) distance_in_meters, location, CONCAT("https://storage.cloud.google.com/", SUBSTR(gcs_uri, 6)) AS image_url FROM landmarksWithDistances WHERE distance_in_meters < 3000 ORDER BY distance_in_meters LIMIT 100쿼리를 실행하면 콜로세움의 이미지가 여러 개 있을 뿐만 아니라 콘스타티누스 개선문, 팔라티노 언덕, 자주 사진이 찍히는 여러 장소의 이미지도 표시됩니다.
이전 쿼리에 붙여넣어 BigQuery Geo Viz의 데이터를 시각화할 수 있습니다. 지도에서 한 지점을 선택하여 세부정보를 확인합니다.
Image_url속성에는 이미지 파일의 링크가 포함됩니다.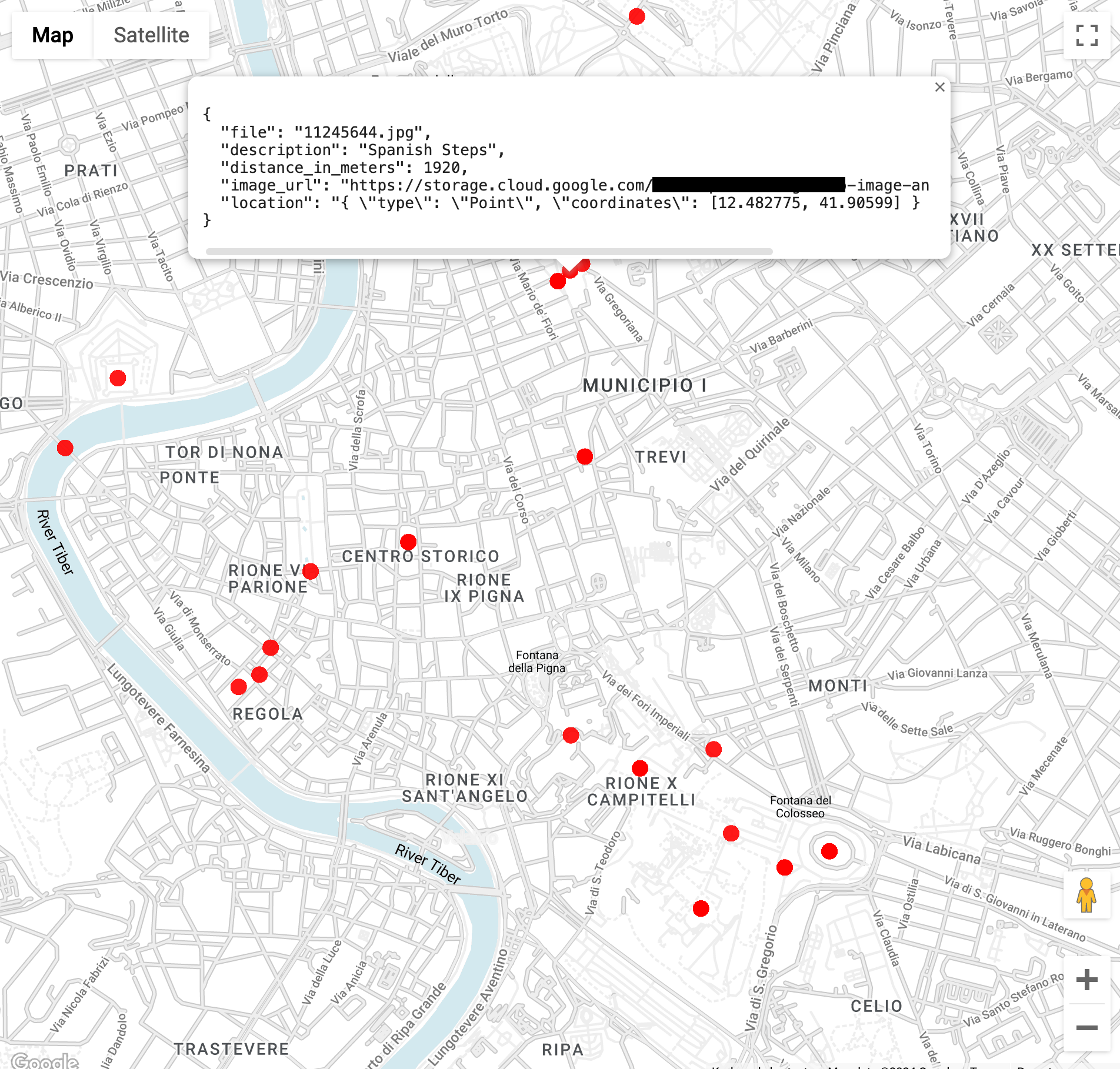
쿼리 결과에 대한 한 가지 참고사항이 있습니다. 일반적으로 랜드마크의 경우 위치 정보가 표시됩니다. 같은 이미지에 같은 랜드마크의 여러 위치가 포함될 수 있습니다.
이 기능은 AnnotateImageResponse 유형으로 설명되어 있습니다.
하나의 위치가 이미지에 나온 현장의 위치를 나타내므로 여러 LocationInfo 요소가 표시될 수 있습니다. 다른 위치는 이미지를 찍은 위치를 나타낼 수 있습니다.
삭제
이 가이드에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트는 유지하되 개별 리소스를 삭제하세요.
Google Cloud 프로젝트 삭제
비용이 청구되지 않도록 하는 가장 쉬운 방법은 튜토리얼에서 만든 Google Cloud 프로젝트를 삭제하는 것입니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
리소스를 개별적으로 삭제하려면 GitHub 저장소의 삭제 섹션에 있는 단계를 따릅니다.
다음 단계
- 그 밖의 참조 아키텍처, 다이어그램, 튜토리얼, 권장사항을 알아보려면 클라우드 아키텍처 센터를 확인하세요.
참여자
저자:
- 마수드 하산 | 사이트 안정성 엔지니어링 관리자
- Sergei Lilichenko | 솔루션 설계자
- 락쉬마난 세투 | 기술계정 관리자
기타 참여자:
- 강지연 | 고객 엔지니어
- 수닐 쿠마르 장 바하두르 | 고객 엔지니어
비공개 LinkedIn 프로필을 보려면 LinkedIn에 로그인하세요.