Questo documento descrive diverse architetture che forniscono alta disponibilità (HA) per i deployment PostgreSQL su Google Cloud. L'alta disponibilità è la misura della resilienza del sistema in risposta a un errore dell'infrastruttura sottostante. In questo documento, HA si riferisce alla disponibilità dei cluster PostgreSQL all'interno di una singola regione cloud o tra più regioni, a seconda dell'architettura HA.
Questo documento è rivolto ad amministratori di database, architetti cloud e ingegneri DevOps che vogliono imparare ad aumentare l'affidabilità del livello dati di PostgreSQL migliorando il tempo di attività complessivo del sistema. Questo documento illustra i concetti pertinenti all'esecuzione di PostgreSQL su Compute Engine. Il documento non descrive l'utilizzo di database gestiti come Cloud SQL per PostgreSQL e AlloyDB per PostgreSQL.
Se un sistema o un'applicazione richiede uno stato persistente per gestire richieste o transazioni, il livello di persistenza dei dati (il livello dei dati) deve essere disponibile per gestire correttamente le richieste di query o mutazioni dei dati. Il tempo di inattività nel livello di dati impedisce al sistema o all'applicazione di eseguire le attività necessarie.
A seconda degli obiettivi del livello di servizio (SLO) del tuo sistema, potresti richiedere un'architettura che fornisca un livello di disponibilità più elevato. Esiste più di un modo per ottenere l'alta disponibilità, ma in generale si esegue il provisioning di un'infrastruttura ridondante a cui l'applicazione può accedere rapidamente.
Questo documento tratta i seguenti argomenti:
- Definizione dei termini relativi ai concetti di database ad alta disponibilità.
- Opzioni per le topologie PostgreSQL ad alta disponibilità.
- Informazioni contestuali da prendere in considerazione per ogni opzione di architettura.
Terminologia
I seguenti termini e concetti sono standard del settore e sono utili da comprendere per scopi che vanno oltre l'ambito di questo documento.
- replica
-
Il processo mediante il quale le transazioni di scrittura (
INSERT,UPDATEoDELETE) e le modifiche allo schema (Data Definition Language (DDL)) vengono acquisite, registrate e poi applicate in serie a tutti i nodi di replica del database downstream nell'architettura. - nodo principale
- Il nodo che fornisce una lettura con lo stato più aggiornato dei dati persistenti. Tutte le scritture del database devono essere indirizzate a un nodo primario.
- nodo di replica (secondario)
- Una copia online del nodo del database principale. Le modifiche vengono replicate in modo sincrono o asincrono nei nodi di replica dal nodo primario. Puoi leggere dai nodi di replica sapendo che i dati potrebbero essere leggermente ritardati a causa del ritardo della replica.
- ritardo della replica
- Una misurazione, in numero di sequenza di log (LSN), ID transazione o tempo. Il ritardo della replica esprime la differenza tra il momento in cui le operazioni di modifica vengono applicate alla replica rispetto al momento in cui vengono applicate al nodo primario.
- archiviazione continua
- Un backup incrementale in cui il database salva continuamente le transazioni sequenziali in un file.
- log write-ahead (WAL)
- Un log write-ahead (WAL) è un file di log che registra le modifiche ai file di dati prima che vengano effettivamente apportate ai file. In caso di arresto anomalo del server, il WAL è un modo standard per garantire l'integrità e la durabilità dei dati delle tue scritture.
- Record WAL
- Un record di una transazione applicata al database. Un record WAL viene formattato e archiviato come una serie di record che descrivono le modifiche a livello di pagina del file di dati.
- Numero di sequenza di log (LSN)
- Le transazioni creano record WAL che vengono aggiunti al file WAL. La posizione in cui si verifica l'inserimento è chiamata numero di sequenza di log (LSN). Si tratta di un numero intero a 64 bit, rappresentato da due numeri esadecimali separati da una barra (XXXXXXXX/YYZZZZZZ). "Z" rappresenta la posizione di offset nel file WAL.
- file di segmenti
- File che contengono il maggior numero possibile di record WAL, a seconda delle dimensioni del file che configuri. I file di segmento hanno nomi di file che aumentano monotonicamente e una dimensione predefinita di 16 MB.
- replica sincrona
-
Una forma di replica in cui il server primario attende che la replica
confermi che i dati sono stati scritti nel log delle transazioni della replica prima di
confermare un commit al client. Quando esegui la replica in streaming, puoi utilizzare l'opzione
synchronous_commitdi PostgreSQL, che contribuisce a garantire la coerenza tra il server primario e la replica. - replica asincrona
- Una forma di replica in cui il server primario non attende che la replica confermi la ricezione della transazione prima di confermare un commit al client. La replica asincrona ha una latenza inferiore rispetto alla replica sincrona. Tuttavia, se il database principale si arresta in modo anomalo e le transazioni di cui è stato eseguito il commit non vengono trasferite alla replica, esiste la possibilità di perdita di dati. La replica asincrona è la modalità di replica predefinita su PostgreSQL, utilizzando la spedizione dei log basata su file o la replica in streaming.
- trasferimento dei log basato su file
- Un metodo di replica in PostgreSQL che trasferisce i file di segmento WAL dal server di database principale alla replica. Il servizio primario opera in modalità di archiviazione continua, mentre ogni servizio di standby opera in modalità di recupero continuo per leggere i file WAL. Questo tipo di replica è asincrono.
- replica dello streaming
- Un metodo di replica in cui la replica si connette all'istanza principale e riceve continuamente una sequenza continua di modifiche. Poiché gli aggiornamenti arrivano tramite un flusso, questo metodo mantiene la replica più aggiornata rispetto all'istanza primaria rispetto alla replica log shipping. Sebbene la replica sia asincrona per impostazione predefinita, puoi configurare in alternativa la replica sincrona.
- replica dello streaming fisico
- Un metodo di replica che trasferisce le modifiche alla replica. Questo metodo utilizza i record WAL che contengono le modifiche fisiche ai dati sotto forma di indirizzi dei blocchi del disco e modifiche byte per byte.
- replica logica dello streaming
- Un metodo di replica che acquisisce le modifiche in base alla loro identità di replica (chiave primaria), il che consente un maggiore controllo sulla modalità di replica dei dati rispetto alla replica fisica. A causa delle limitazioni nella replica logica di PostgreSQL, la replica logica in streaming richiede una configurazione speciale per una configurazione HA. Questa guida illustra la replica fisica standard e non la replica logica.
- uptime
- La percentuale di tempo in cui una risorsa funziona ed è in grado di fornire una risposta a una richiesta.
- failure detection
- Il processo di identificazione del verificarsi di un errore dell'infrastruttura.
- failover
- Il processo di promozione dell'infrastruttura di backup o in standby (in questo caso, il nodo di replica) per diventare l'infrastruttura principale. Durante il failover, il nodo di replica diventa il nodo principale.
- switchover
- Il processo di esecuzione di un failover manuale su un sistema di produzione. Uno switchover verifica che il sistema funzioni correttamente o rimuove il nodo primario corrente dal cluster per la manutenzione.
- Recovery Time Objective (RTO)
- La durata in tempo reale trascorsa per il completamento del processo di failover del livello di dati. L'RTO dipende dalla quantità di tempo accettabile dal punto di vista aziendale.
- Recovery Point Objective (RPO)
- La quantità di perdita di dati (in tempo reale trascorso) che il livello di dati deve sostenere a seguito del failover. L'RPO dipende dalla quantità di perdita di dati accettabile dal punto di vista aziendale.
- di riserva
- Il processo di reintegro del nodo primario precedente dopo che la condizione che ha causato un failover è stata risolta.
- autoriparazione
- La capacità di un sistema di risolvere i problemi senza azioni esterne da parte di un operatore umano.
- partizione di rete
- Una condizione in cui due nodi di un'architettura, ad esempio i nodi principale e replica, non possono comunicare tra loro tramite la rete.
- split brain
- Una condizione che si verifica quando due nodi ritengono contemporaneamente di essere il nodo principale.
- gruppo di nodi
- Un insieme di risorse di calcolo che forniscono un servizio. In questo documento, questo servizio è il livello di persistenza dei dati.
- nodo testimone o quorum
- Una risorsa di calcolo separata che aiuta un gruppo di nodi a determinare cosa fare quando si verifica una condizione di split-brain.
- elezioni primarie o per la scelta del leader
- Il processo mediante il quale un gruppo di nodi peer-aware, inclusi i nodi di controllo, determina quale nodo deve essere il nodo primario.
Quando prendere in considerazione un'architettura ad alta affidabilità
Le architetture ad alta disponibilità offrono una maggiore protezione contro i tempi di inattività del livello dati rispetto alle configurazioni di database a singolo nodo. Per selezionare l'opzione migliore per il tuo caso d'uso aziendale, devi comprendere la tua tolleranza ai tempi di inattività e i compromessi rispettivi delle varie architetture.
Utilizza un'architettura HA quando vuoi aumentare l'uptime del livello dati per soddisfare i requisiti di affidabilità per i tuoi carichi di lavoro e servizi. Se il tuo ambiente tollera un certo tempo di inattività, un'architettura HA potrebbe introdurre costi e complessità non necessari. Ad esempio, gli ambienti di sviluppo o test raramente richiedono un'alta disponibilità del livello di database.
Considera i tuoi requisiti per l'alta disponibilità
Di seguito sono riportate diverse domande per aiutarti a decidere quale opzione di alta disponibilità di PostgreSQL è più adatta alla tua attività:
- Quale livello di disponibilità speri di raggiungere? Hai bisogno di un'opzione che consenta al tuo servizio di continuare a funzionare solo durante un singolo errore di zona o regionale completo? Alcune opzioni di HA sono limitate a una regione, mentre altre possono essere multiregionali.
- Quali servizi o clienti si basano sul tuo livello di dati e qual è il costo per la tua attività in caso di tempi di inattività nel livello di persistenza dei dati? Se un servizio si rivolge solo a clienti interni che richiedono un uso occasionale del sistema, probabilmente ha requisiti di disponibilità inferiori rispetto a un servizio rivolto ai clienti finali che serve i clienti in modo continuo.
- Qual è il tuo budget operativo? Il costo è un aspetto importante da considerare: per fornire l'alta disponibilità, i costi dell'infrastruttura e dello spazio di archiviazione aumenteranno probabilmente.
- Quanto deve essere automatizzato il processo e con quale rapidità devi eseguire il failover? (Qual è il tuo RTO?) Le opzioni di HA variano in base alla rapidità con cui il sistema può eseguire il failover ed essere disponibile per i clienti.
- Puoi permetterti di perdere dati a seguito del failover? (Qual è il tuo RPO?) A causa della natura distribuita delle topologie HA, esiste un compromesso tra la latenza di commit e il rischio di perdita di dati a causa di un errore.
Come funziona HA
Questa sezione descrive la replica in streaming e in streaming sincrona che sono alla base delle architetture HA di PostgreSQL.
Replica di flussi di dati
La replica in streaming è un approccio di replica in cui la replica si connette all'istanza principale e riceve continuamente un flusso di record WAL. Rispetto alla replica log shipping, la replica in streaming consente alla replica di rimanere più aggiornata rispetto all'istanza principale. PostgreSQL offre la replica in streaming integrata a partire dalla versione 9. Molte soluzioni HA PostgreSQL utilizzano la replica di streaming integrata per fornire il meccanismo per mantenere sincronizzati più nodi di replica PostgreSQL con il nodo primario. Molte di queste opzioni sono descritte nella sezione Architetture HA di PostgreSQL più avanti in questo documento.
Ogni nodo di replica richiede risorse di calcolo e archiviazione dedicate. L'infrastruttura dei nodi di replica è indipendente da quella del nodo principale. Puoi utilizzare i nodi replica come hot standby per gestire le query client di sola lettura. Questo approccio consente il bilanciamento del carico delle query di sola lettura tra il database primario e una o più repliche.
La replica in streaming è asincrona per impostazione predefinita; il server primario non attende una conferma da una replica prima di confermare il commit di una transazione al client. Se un'istanza primaria subisce un errore dopo aver confermato la transazione, ma prima che una replica riceva la transazione, la replica asincrona può comportare una perdita di dati. Se la replica viene promossa a nuova primaria, questa transazione non sarà presente.
Replica sincrona dello streaming
Puoi configurare la replica in streaming come sincrona scegliendo una o più repliche da utilizzare come standby sincrono. Se configuri l'architettura per la replica sincrona, il database primario non conferma il commit di una transazione finché la replica non riconosce la persistenza della transazione. La replica in streaming sincrona offre una maggiore durabilità in cambio di una latenza delle transazioni più elevata.
L'opzione di configurazione
synchronous_commit ti consente anche di configurare i seguenti livelli di durabilità delle repliche progressive per la transazione:
local: le repliche di standby sincrone non sono coinvolte nella conferma del commit. Il primario riconosce i commit delle transazioni dopo che i record WAL vengono scritti e scaricati sul disco locale. I commit delle transazioni sull'istanza principale non coinvolgono le repliche di standby. Le transazioni possono andare perse se si verifica un errore sul server primario.on[impostazione predefinita]: le repliche di standby sincrone scrivono le transazioni di cui è stato eseguito il commit nel proprio WAL prima di inviare la conferma alla replica primaria. L'utilizzo della configurazioneongarantisce che la transazione possa essere persa solo se l'archivio primario e tutte le repliche di standby sincrone subiscono errori di archiviazione simultanei. Poiché le repliche inviano un riconoscimento solo dopo aver scritto i record WAL, i client che eseguono query sulla replica non vedranno le modifiche finché i rispettivi record WAL non vengono applicati al database della replica.remote_write: le repliche di standby sincrone confermano la ricezione del record WAL a livello di sistema operativo, ma non garantiscono che il record WAL sia stato scritto sul disco. Poichéremote_writenon garantisce che il WAL sia stato scritto, la transazione può andare persa in caso di errore sia nell'istanza primaria che in quella secondaria prima che i record vengano scritti.remote_writeha una durata inferiore rispetto all'opzioneon.remote_apply: le repliche di standby sincrone confermano la ricezione della transazione e l'applicazione riuscita al database prima di confermare il commit della transazione al client. L'utilizzo della configurazioneremote_applygarantisce che la transazione venga salvata nella replica e che i risultati della query client includano immediatamente gli effetti della transazione.remote_applyoffre maggiore durabilità e coerenza rispetto aoneremote_write.
L'opzione di configurazione synchronous_commit funziona con l'opzione di configurazione synchronous_standby_names che specifica l'elenco dei server di standby che partecipano al processo di replica sincrona. Se non vengono specificati nomi di standby sincroni, i commit delle transazioni non attendono la replica.
Architetture HA di PostgreSQL
Al livello più elementare, l'HA del livello di dati consiste in quanto segue:
- Un meccanismo per identificare se si verifica un errore del nodo primario.
- Un processo per eseguire un failover in cui il nodo di replica viene promosso a nodo principale.
- Un processo per modificare il routing delle query in modo che le richieste dell'applicazione raggiungano il nuovo nodo primario.
- (Facoltativo) Un metodo per eseguire il failback all'architettura originale utilizzando i nodi principali e di replica pre-failover nelle loro capacità originali.
Le sezioni seguenti forniscono una panoramica delle seguenti architetture HA:
- Il modello Patroni
- Estensione e servizio pg_auto_failover
- MIG stateful e disco permanente regionale
Queste soluzioni HA riducono al minimo i tempi di inattività in caso di interruzione dell'infrastruttura o della zona. Quando scegli tra queste opzioni, bilancia la latenza di commit e la durabilità in base alle esigenze della tua attività.
Un aspetto fondamentale di un'architettura di alta affidabilità è il tempo e lo sforzo manuale necessari per preparare un nuovo ambiente di standby per il successivo failover o fallback. In caso contrario, il sistema può resistere a un solo guasto e il servizio non è protetto da una violazione dell'SLA. Ti consigliamo di selezionare un'architettura HA in grado di eseguire failover manuali o switchover con l'infrastruttura di produzione.
HA using the Patroni template
Patroni è un modello di software open source (con licenza MIT) maturo e sottoposto a manutenzione attiva che fornisce gli strumenti per configurare, eseguire il deployment e gestire un'architettura HA PostgreSQL. Patroni fornisce uno stato del cluster condiviso e una configurazione dell'architettura che viene mantenuta in un archivio di configurazione distribuito (DCS). Le opzioni per implementare un DCS includono: etcd, Consul, Apache ZooKeeper, o Kubernetes. Il seguente diagramma mostra i componenti principali di un cluster Patroni.
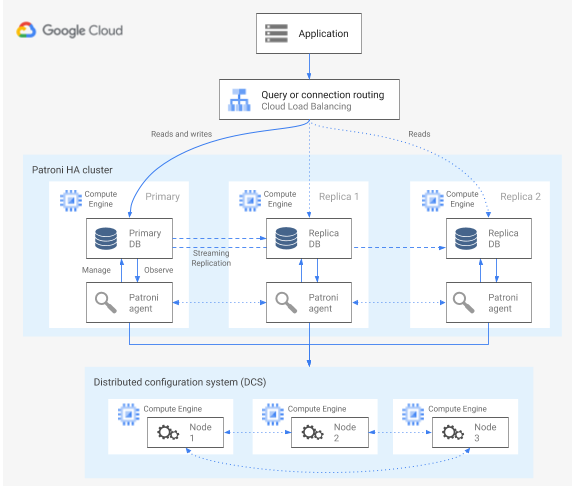
Figura 1. Diagramma dei componenti principali di un cluster Patroni.
Nella figura 1, i bilanciatori del carico si trovano davanti ai nodi PostgreSQL e gli agenti DCS e Patroni operano sui nodi PostgreSQL.
Patroni esegue un processo agente su ogni nodo PostgreSQL. Il processo dell'agente gestisce la configurazione del processo PostgreSQL e del nodo di dati. L'agente Patroni coordina gli altri nodi tramite DCS. Il processo dell'agente Patroni espone anche un'API REST che puoi interrogare per determinare l'integrità e la configurazione del servizio PostgreSQL per ogni nodo.
Per affermare il proprio ruolo di appartenenza al cluster, il nodo primario aggiorna regolarmente la chiave leader nel DCS. La chiave leader include una durata (TTL). Se il TTL scade senza un aggiornamento, la chiave leader viene rimossa dal DCS e inizia l'elezione del leader per selezionare un nuovo primario dal pool di candidati.
Il seguente diagramma mostra un cluster integro in cui il nodo A aggiorna correttamente il blocco leader.
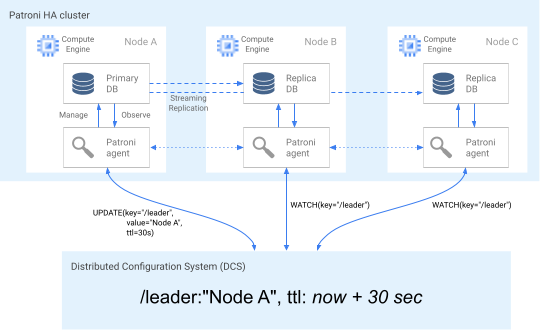
Figura 2. Diagramma di un cluster integro.
La Figura 2 mostra un cluster integro: i nodi B e C osservano mentre il nodo A aggiorna correttamente la chiave leader.
Rilevamento errori
L'agente Patroni segnala continuamente il suo stato aggiornando la chiave nel DCS. Allo stesso tempo, l'agente convalida l'integrità di PostgreSQL. Se l'agente rileva un problema, esegue l'isolamento automatico del nodo arrestandosi o declassa il nodo a replica. Come mostrato nel seguente diagramma, se il nodo danneggiato è il nodo principale, la relativa chiave leader nel DCS scade e viene eseguita una nuova elezione del leader.
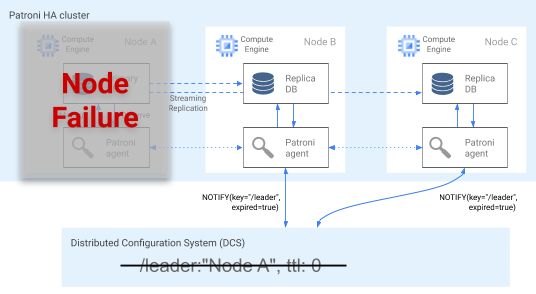
Figura 3. Diagramma di un cluster compromesso.
La figura 3 mostra un cluster compromesso: un nodo principale inattivo non ha aggiornato di recente la chiave leader nel DCS e le repliche non leader ricevono una notifica che indica che la chiave leader è scaduta.
Sugli host Linux, Patroni esegue anche un watchdog a livello di sistema operativo sui nodi primari. Questo watchdog è in ascolto dei messaggi keep-alive del processo dell'agente Patroni. Se il processo non risponde e il segnale di mantenimento in vita non viene inviato, il watchdog riavvia l'host. Il watchdog aiuta a prevenire una condizione di split brain in cui il nodo PostgreSQL continua a fungere da primario, ma la chiave leader nel DCS è scaduta a causa di un errore dell'agente ed è stato eletto un altro primario (leader).
Processo di failover
Se il blocco del leader scade in DCS, i nodi di replica candidati iniziano una selezione del leader. Quando una replica rileva un blocco leader mancante, controlla la sua posizione di replica rispetto alle altre repliche. Ogni replica utilizza l'API REST per ottenere le posizioni dei log WAL degli altri nodi di replica, come mostrato nel seguente diagramma.
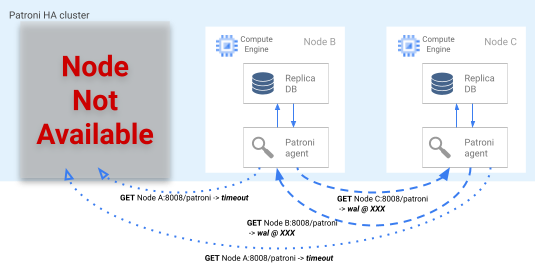
Immagine 4. Diagramma del processo di failover di Patroni.
La figura 4 mostra le query sulla posizione del log WAL e i rispettivi risultati dei nodi replica attivi. Il nodo A non è disponibile e i nodi integri B e C restituiscono la stessa posizione WAL.
Il nodo (o i nodi se si trovano nella stessa posizione) più aggiornato tenta contemporaneamente di acquisire il blocco leader nel DCS. Tuttavia, solo un
nodo può creare la chiave leader nel DCS. Il primo nodo a creare correttamente
la chiave leader è il vincitore della corsa al leader, come mostrato nel seguente
diagramma. In alternativa, puoi designare i candidati di failover preferiti
impostando il tag
failover_priority
nei file di configurazione.
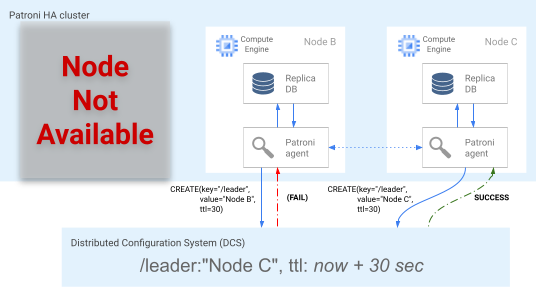
Figura 5. Diagramma della classifica dei leader.
La figura 5 mostra una competizione per la leadership: due candidati leader tentano di ottenere il blocco del leader, ma solo uno dei due nodi, il nodo C, imposta correttamente la chiave del leader e vince la competizione.
Dopo aver vinto l'elezione del leader, la replica viene promossa a nuova istanza principale. A partire dal momento in cui la replica si promuove, la nuova istanza principale aggiorna la chiave leader nel DCS per mantenere il blocco leader e gli altri nodi fungono da repliche.
Patroni fornisce anche lo
strumento di controllo patronictl
che consente di eseguire i cambi di ruolo per testare la procedura di failover dei nodi.
Questo strumento aiuta gli operatori a testare le configurazioni HA in produzione.
Routing delle query
Il processo dell'agente Patroni in esecuzione su ogni nodo espone endpoint API REST che rivelano il ruolo attuale del nodo: principale o replica.
| Endpoint REST | Codice restituito HTTP se primario | Codice restituito HTTP se la replica |
|---|---|---|
/primary |
200 |
503 |
/replica |
503 |
200 |
Poiché i controlli di integrità pertinenti modificano le proprie risposte se un determinato nodo cambia ruolo, un controllo di integrità del bilanciatore del carico può utilizzare questi endpoint per informare il routing del traffico dei nodi primari e di replica. Il progetto Patroni fornisce configurazioni modello per un bilanciatore del carico come HAProxy. Il bilanciatore del carico di rete passthrough interno può utilizzare questi stessi controlli di integrità per fornire funzionalità simili.
Procedura di riserva
Se si verifica un errore del nodo, il cluster rimane in stato di funzionamento ridotto. La procedura di failback di Patroni consente di ripristinare un cluster ad alta disponibilità in uno stato integro dopo un failover. Il processo di fallback gestisce il ripristino dello stato originale del cluster inizializzando automaticamente il nodo interessato come replica del cluster.
Ad esempio, un nodo potrebbe riavviarsi a causa di un errore nel sistema operativo o nell'infrastruttura sottostante. Se il nodo è il nodo principale e il riavvio richiede più tempo del TTL della chiave leader, viene attivata una selezione del leader e viene selezionato e promosso un nuovo nodo principale. Quando viene avviato il processo Patroni primario obsoleto, rileva di non avere il blocco leader, si declassa automaticamente a replica e si unisce al cluster in questa veste.
Se si verifica un errore del nodo non recuperabile, ad esempio un errore di zona improbabile, devi avviare un nuovo nodo. Un operatore di database può avviare manualmente un nuovo nodo oppure puoi utilizzare un gruppo di istanze gestite (MIG) stateful a livello di regione con un numero minimo di nodi per automatizzare il processo. Una volta creato il nuovo nodo, Patroni rileva che fa parte di un cluster esistente e lo inizializza automaticamente come replica.
HA utilizzando l'estensione e il servizio pg_auto_failover
pg_auto_failover è un'estensione PostgreSQL open source (licenza PostgreSQL) in fase di sviluppo attivo. pg_auto_failover configura un'architettura HA estendendo le funzionalità PostgreSQL esistenti. pg_auto_failover non ha dipendenze diverse da PostgreSQL.
Per utilizzare l'estensione pg_auto_failover con un'architettura HA, devi avere almeno tre nodi, ognuno dei quali esegue PostgreSQL con l'estensione abilitata. Uno qualsiasi dei nodi può non funzionare senza influire sull'uptime del gruppo di database. Una
raccolta di nodi gestiti da pg_auto_failover è chiamata formazione. Il
seguente diagramma mostra un'architettura pg_auto_failover.
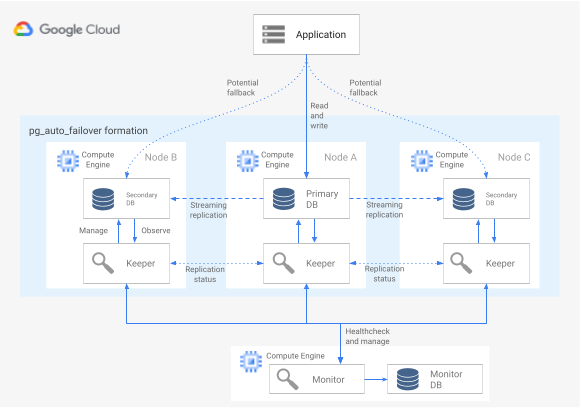
Immagine 6. Diagramma di un'architettura pg_auto_failover.
La Figura 6 mostra un'architettura pg_auto_failover composta da due componenti principali: il servizio Monitor e l'agente Keeper. Sia Keeper che Monitor sono contenuti nell'estensione pg_auto_failover.
Monitorare il servizio
Il servizio di monitoraggio pg_auto_failover è implementato come estensione PostgreSQL. Quando il servizio crea un nodo di monitoraggio, avvia un'istanza PostgreSQL con l'estensione pg_auto_failover abilitata. Il monitor mantiene lo stato globale per la formazione, ottiene lo stato del controllo di integrità dai nodi di dati PostgreSQL membri e orchestra il gruppo utilizzando le regole stabilite da una macchina a stati finiti (FSM). In base alle regole FSM per le transizioni di stato, il monitor comunica le istruzioni ai nodi del gruppo per azioni come la promozione, il declassamento e le modifiche alla configurazione.
Agente di Keeper
Su ogni nodo di dati pg_auto_failover, l'estensione avvia un processo dell'agente Keeper. Questo processo Keeper osserva e gestisce il servizio PostgreSQL. Il Keeper invia aggiornamenti di stato al nodo Monitor e riceve ed esegue le azioni che Monitor invia in risposta.
Per impostazione predefinita, pg_auto_failover configura tutti i nodi di dati secondari del gruppo come
repliche sincrone. Il numero di repliche sincrone richieste per un commit
si basa sulla configurazione number_sync_standby impostata sul
monitor.
Rilevamento errori
Gli agenti Keeper sui nodi di dati principali e secondari si connettono periodicamente al nodo Monitor per comunicare il loro stato attuale e verificare se ci sono azioni da eseguire. Il nodo di monitoraggio si connette anche ai nodi di dati per eseguire un controllo di integrità eseguendo le chiamate API del protocollo PostgreSQL (libpq), imitando l'applicazione client PostgreSQL pg_isready(). Se nessuna di queste azioni va a buon fine dopo un periodo di tempo (30 secondi per impostazione predefinita), il nodo Monitor determina che si è verificato un errore del nodo di dati. Puoi modificare le impostazioni di configurazione di PostgreSQL per personalizzare la tempistica del monitoraggio e il numero di tentativi. Per ulteriori informazioni, consulta Failover e tolleranza agli errori.
Se si verifica un errore di un singolo nodo, si verifica una delle seguenti condizioni:
- Se il nodo di dati non integro è un nodo primario, il monitoraggio avvia un failover.
- Se il nodo di dati non integro è secondario, il monitoraggio disattiva la replica sincrona per il nodo non integro.
- Se il nodo non riuscito è il nodo di monitoraggio, il failover automatico non è possibile. Per evitare questo single point of failure, devi assicurarti che siano in atto il monitoraggio e il ripristino di emergenza corretti.
Il seguente diagramma mostra gli scenari di errore e gli stati del risultato della formazione descritti nell'elenco precedente.
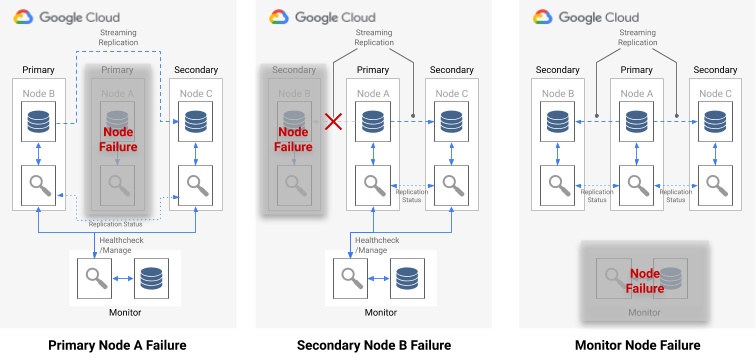
Immagine 7. Diagramma degli scenari di errore di pg_auto_failover.
Processo di failover
Ogni nodo del database nel gruppo ha le seguenti opzioni di configurazione che determinano il processo di failover:
replication_quorum: un'opzione booleana. Sereplication_quorumè impostato sutrue, il nodo viene considerato un potenziale candidato per il failovercandidate_priority: un valore intero compreso tra 0 e 100.candidate_priorityha un valore predefinito di 50 che puoi modificare per influire sulla priorità di failover. I nodi vengono classificati in ordine di priorità come potenziali candidati di failover in base al valorecandidate_priority. I nodi con un valorecandidate_prioritypiù alto hanno una priorità maggiore. Il processo di failover richiede che almeno due nodi abbiano una priorità candidata diversa da zero in qualsiasi formazione di pg_auto_failover.
Se si verifica un errore del nodo primario, i nodi secondari vengono presi in considerazione per la
promozione a primario se hanno una replica sincrona attiva e se sono
membri di replication_quorum.
I nodi secondari vengono presi in considerazione per la promozione in base ai seguenti criteri progressivi:
- Nodi con la priorità del candidato più alta
- Standby con la posizione del log WAL più avanzata pubblicata nel monitor
- Selezione casuale come spareggio finale
Un candidato di failover è un candidato in ritardo quando non ha pubblicato la posizione LSN più avanzata nel WAL. In questo scenario, pg_auto_failover orchestra un passaggio intermedio nel meccanismo di failover: il candidato in ritardo recupera i byte WAL mancanti da un nodo di standby con la posizione LSN più avanzata. Il nodo di riserva viene quindi promosso. PostgreSQL consente questa operazione perché la replica a cascata consente a qualsiasi standby di fungere da nodo upstream per un altro standby.
Routing delle query
pg_auto_failover non fornisce funzionalità di routing delle query lato server.
pg_auto_failover si basa invece sul routing delle query lato client che utilizza il driver client PostgreSQL ufficiale libpq.
Quando definisci l'URI di connessione, il driver può accettare più host nella parola chiave
host.
La libreria client utilizzata dall'applicazione deve eseguire il wrapping di libpq o implementare la possibilità di fornire più host per l'architettura per supportare un failover completamente automatizzato.
Procedure di fallback e switchover
Quando il processo Keeper riavvia un nodo non riuscito o avvia un nuovo nodo di sostituzione, controlla il nodo Monitor per determinare l'azione successiva da eseguire. Se un nodo riavviato e in errore era in precedenza il nodo primario e il monitor ha già scelto un nuovo nodo primario in base al processo di failover, Keeper reinizializza questo nodo primario obsoleto come replica secondaria.
pg_auto_failover fornisce lo strumento pg_autoctl, che consente di eseguire switchover per testare il processo di failover dei nodi. Oltre a consentire agli operatori di testare le configurazioni HA in produzione, lo strumento ti aiuta a ripristinare un cluster HA in uno stato integro dopo un failover.
Alta affidabilità utilizzando i gruppi di istanze gestite stateful e il disco permanente regionale
Questa sezione descrive un approccio HA che utilizza i seguenti componenti Google Cloud:
- disco permanente a livello di regione. Quando utilizzi dischi permanenti a livello di regione, i dati vengono replicati in modo sincrono tra due zone di una regione, quindi non è necessario utilizzare la replica in streaming. Tuttavia, l'alta disponibilità è limitata a esattamente due zone in una regione.
- Gruppi di istanze gestite stateful. Una coppia di MIG stateful viene utilizzata come parte di un control plane per mantenere in esecuzione un nodo PostgreSQL primario. Quando il MIG stateful avvia una nuova istanza, può collegare il disco permanente regionale esistente. In un determinato momento, solo uno dei due MIG avrà un'istanza in esecuzione.
- Cloud Storage. Un oggetto in un bucket Cloud Storage contiene una configurazione che indica quale dei due MIG esegue il nodo del database principale e in quale MIG deve essere creata un'istanza di failover.
- Controlli di integrità e riparazione automatica dei MIG. Il controllo di integrità monitora l'integrità dell'istanza. Se il nodo in esecuzione non è integro, il controllo di integrità avvia il processo di riparazione automatica.
- Logging. Quando la riparazione automatica arresta il nodo primario, viene registrata una voce in Logging. Le voci di log pertinenti vengono esportate in un argomento sink Pub/Sub utilizzando un filtro.
- Funzioni Cloud Run basate su eventi. Il messaggio Pub/Sub attiva Cloud Run Functions. Cloud Run Functions utilizza la configurazione in Cloud Storage per determinare le azioni da intraprendere per ogni MIG stateful.
- Bilanciatore del carico di rete passthrough interno. Il bilanciatore del carico fornisce il routing all'istanza in esecuzione nel gruppo. In questo modo, la modifica dell'indirizzo IP di un'istanza causata dalla ricreazione dell'istanza viene astratta dal client.
Il seguente diagramma mostra un esempio di HA che utilizza i MIG stateful e i dischi permanenti regionali:

Immagine 8. Diagramma di un'architettura ad alta affidabilità che utilizza MIG stateful e dischi permanenti regionali.
La Figura 8 mostra un nodo primario integro che gestisce il traffico client. I client si connettono all'indirizzo IP statico del bilanciatore del carico di rete passthrough interno. Il bilanciatore del carico instrada le richieste dei client alla VM in esecuzione come parte del gruppo di istanze gestite. I volumi di dati vengono memorizzati su dischi permanenti regionali montati.
Per implementare questo approccio, crea un'immagine VM con PostgreSQL che si avvii all'inizializzazione da utilizzare come modello di istanza del MIG. Devi anche configurare un controllo di integrità basato su HTTP (ad esempio HAProxy o pgDoctor) sul nodo. Un controllo di integrità basato su HTTP contribuisce a garantire che sia il bilanciatore del carico sia il gruppo di istanze possano determinare l'integrità del nodo PostgreSQL.
Disco permanente regionale
Per eseguire il provisioning di un dispositivo di archiviazione a blocchi che fornisce la replica sincrona dei dati tra due zone in una regione, puoi utilizzare l'opzione di archiviazione disco permanente regionale di Compute Engine. Un disco permanente regionale può fornire un blocco di base per implementare un'opzione HA di PostgreSQL che non si basa sulla replica di streaming integrata di PostgreSQL.
Se la tua istanza VM del nodo primario non è disponibile a causa di un errore dell'infrastruttura o di un'interruzione a livello di zona, puoi forzare il collegamento del disco permanente regionale a un'istanza VM nella zona di backup della stessa regione.
Per collegare il disco permanente regionale a un'istanza VM nella zona di backup, puoi eseguire una delle seguenti operazioni:
- Mantieni un'istanza VM cold standby nella zona di backup. Un'istanza VM di standby a freddo è un'istanza VM arrestata a cui non è montato unPersistent Diskte regionale, ma è un'istanza VM identica all'istanza VM del nodo primario. In caso di errore, la VM di standby a freddo viene avviata e il disco permanente regionale viene montato. L'istanza di standby a freddo e l'istanza del nodo primario hanno gli stessi dati.
- Crea una coppia di MIG stateful utilizzando lo stesso modello di istanza. I MIG forniscono controlli di integrità e fanno parte del control plane. Se il nodo principale non funziona, viene creata un'istanza di failover nel MIG di destinazione in modo dichiarativo. Il MIG di destinazione è definito nell'oggetto Cloud Storage. Per collegare il disco permanente regionale viene utilizzata una configurazione per istanza.
Se l'interruzione del servizio dati viene identificata tempestivamente, l'operazione di forzatura dell'allegato viene in genere completata in meno di un minuto, quindi è possibile ottenere un RTO misurato in minuti.
Se la tua attività può tollerare i tempi di inattività aggiuntivi necessari per rilevare e comunicare un'interruzione e per eseguire il failover manualmente, allora non è necessario automatizzare la procedura di forzatura dell'attacco. Se la tolleranza RTO è inferiore, puoi automatizzare il processo di rilevamento e failover. In alternativa, Cloud SQL per PostgreSQL fornisce anche un'implementazione completamente gestita di questo approccio HA.
Processo di rilevamento degli errori e di failover
L'approccio HA utilizza le funzionalità di riparazione automatica dei gruppi di istanze per monitorare l'integrità dei nodi utilizzando un controllo di integrità. Se un controllo di integrità non riesce, l'istanza esistente viene considerata non integra e viene arrestata. Questo arresto avvia la procedura di failover utilizzando Logging, Pub/Sub e la funzione Cloud Run Functions attivata.
Per soddisfare il requisito che questa VM abbia sempre montato il disco regionale, uno dei due MIG verrà configurato dalle funzioni Cloud Run per creare un'istanza in una delle due zone in cui è disponibile il disco permanente regionale. In caso di errore del nodo, l'istanza di sostituzione viene avviata, in base allo stato persistente in Cloud Storage, nella zona alternativa.

Figura 9. Diagramma di un errore a livello di zona in un gruppo di istanze gestite.
Nella figura 9, il precedente nodo primario nella zona A ha subito un errore e le funzioni Cloud Run hanno configurato il MIG B per avviare una nuova istanza primaria nella zona B. Il meccanismo di rilevamento degli errori viene configurato automaticamente per monitorare l'integrità del nuovo nodo primario.
Routing delle query
Il bilanciatore del carico di rete passthrough interno instrada i client all'istanza che esegue il servizio PostgreSQL. Il bilanciatore del carico utilizza lo stesso controllo di integrità del gruppo di istanze per determinare se l'istanza è disponibile per gestire le query. Se il nodo non è disponibile perché è in fase di ricreazione, le connessioni non vanno a buon fine. Una volta ripristinata l'istanza, i controlli di integrità iniziano a essere superati e le nuove connessioni vengono indirizzate al nodo disponibile. In questa configurazione non sono presenti nodi di sola lettura perché è presente un solo nodo in esecuzione.
Procedura di riserva
Se il nodo del database non supera un controllo di integrità a causa di un problema hardware sottostante, il nodo viene ricreato su un'altra istanza sottostante. A questo punto, l'architettura viene ripristinata allo stato originale senza ulteriori passaggi. Tuttavia, in caso di errore a livello di zona, la configurazione continua a essere eseguita in uno stato degradato finché la prima zona non viene ripristinata. Anche se è molto improbabile, se si verificano errori simultanei in entrambe le zone configurate per la replica di Persistent Disk a livello regionale e per il gruppo di istanze gestite stateful, l'istanza PostgreSQL non può essere ripristinata e il database non è disponibile per gestire le richieste durante l'interruzione.
Confronto tra le opzioni HA
Le tabelle seguenti forniscono un confronto tra le opzioni di alta disponibilità disponibili da Patroni, pg_auto_failover e MIG stateful con dischi permanenti regionali.
Configurazione e architettura
| Patroni | pg_auto_failover | Gruppi di istanze gestite stateful con dischi permanenti a livello di regione |
|---|---|---|
|
Richiede un'architettura HA, la configurazione DCS e il monitoraggio e gli avvisi. La configurazione dell'agente sui nodi di dati è relativamente semplice. |
Non richiede dipendenze esterne diverse da PostgreSQL. Richiede un nodo dedicato come monitor. Il nodo di monitoraggio richiede HA e RE per garantire che non sia un singolo punto di errore (SPOF). | Architettura costituita esclusivamente da Google Cloud servizi. Esegui un solo nodo di database attivo alla volta. |
Configurabilità dell'alta disponibilità
| Patroni | pg_auto_failover | Gruppi di istanze gestite stateful con dischi permanenti a livello di regione |
|---|---|---|
| Estremamente configurabile: supporta la replica sincrona e asincrona e consente di specificare quali nodi devono essere sincroni e asincroni. Include la gestione automatica dei nodi sincroni. Consente configurazioni HA multizona e multiregione. Il DCS deve essere accessibile. | Simile a Patroni: molto configurabile. Tuttavia, poiché il monitor è disponibile solo come singola istanza, qualsiasi tipo di configurazione deve considerare l'accesso a questo nodo. | Limitato a due zone in una singola regione con replica sincrona. |
Capacità di gestire la partizione di rete
| Patroni | pg_auto_failover | Gruppi di istanze gestite stateful con dischi permanenti a livello di regione |
|---|---|---|
| L'autoisolamento insieme a un monitor a livello di sistema operativo offre protezione contro lo split brain. Qualsiasi errore di connessione al DCS comporta la retrocessione del server primario a replica e l'attivazione di un failover per garantire la durabilità rispetto alla disponibilità. | Utilizza una combinazione di controlli di integrità dalla primaria al monitor e alla replica per rilevare una partizione di rete e si esegue il declassamento, se necessario. | Non applicabile: è presente un solo nodo PostgreSQL attivo alla volta, quindi non esiste una partizione di rete. |
Costo
| Patroni | pg_auto_failover | Gruppi di istanze gestite stateful con dischi permanenti a livello di regione |
|---|---|---|
| Costo elevato perché dipende dal DCS che scegli e dal numero di repliche PostgreSQL. L'architettura Patroni non comporta costi significativi. Tuttavia, la spesa complessiva è influenzata dall'infrastruttura sottostante, che utilizza più istanze di calcolo per PostgreSQL e DCS. Poiché utilizza più repliche e un cluster DCS separato, questa opzione può essere la più costosa. | Costo medio perché comporta l'esecuzione di un nodo di monitoraggio e di almeno tre nodi PostgreSQL (uno primario e due repliche). | Costo ridotto perché in un dato momento è in esecuzione attivamente un solo nodo PostgreSQL. Paghi solo per una singola istanza di computing. |
Configurazione client
| Patroni | pg_auto_failover | Gruppi di istanze gestite stateful con dischi permanenti a livello di regione |
|---|---|---|
| Trasparente per il client perché si connette a un bilanciatore del carico. | Richiede che la libreria client supporti più definizioni di host nella configurazione perché non è facilmente front-end con un bilanciatore del carico. | Trasparente per il client perché si connette a un bilanciatore del carico. |
Scalabilità
| Patroni | pg_auto_failover | Gruppi di istanze gestite stateful con dischi permanenti a livello di regione |
|---|---|---|
| Elevata flessibilità nella configurazione per i compromessi tra scalabilità e disponibilità. Lo scaling di lettura è possibile aggiungendo altre repliche. | Simile a Patroni: la scalabilità della lettura è possibile aggiungendo altre repliche. | Scalabilità limitata a causa della presenza di un solo nodo PostgreSQL attivo alla volta. |
Automation dell'inizializzazione dei nodi PostgreSQL, gestione della configurazione
| Patroni | pg_auto_failover | Gruppi di istanze gestite stateful con dischi permanenti a livello di regione |
|---|---|---|
Fornisce strumenti per gestire la configurazione di PostgreSQL (patronictl
edit-config) e inizializza automaticamente i nuovi nodi o i nodi riavviati nel cluster. Puoi inizializzare i nodi utilizzando
pg_basebackup o altri strumenti come Barman.
|
Inizializza automaticamente i nodi, ma è limitato all'utilizzo di
pg_basebackup durante l'inizializzazione di un nuovo nodo di replica.
La gestione della configurazione è limitata alle configurazioni
relative a pg_auto_failover.
|
Il gruppo di istanze con stato con disco condiviso elimina la necessità di inizializzare il nodo PostgreSQL. Poiché è in esecuzione un solo nodo, la gestione delle configurazioni avviene su un singolo nodo. |
Personalizzazione e ricchezza di funzionalità
| Patroni | pg_auto_failover | Gruppi di istanze gestite stateful con dischi permanenti a livello di regione |
|---|---|---|
|
Fornisce un'interfaccia di hook per consentire la chiamata di azioni definibili dall'utente in passaggi chiave, ad esempio in caso di declassamento o promozione. Configurabilità avanzata, ad esempio supporto di diversi tipi di DCS, diversi modi per inizializzare le repliche e diversi modi per fornire la configurazione di PostgreSQL. Consente di configurare cluster di standby che consentono di eseguire cluster di repliche in cascata per semplificare la migrazione tra cluster. |
Limitato perché è un progetto relativamente nuovo. | Non applicabile. |
Maturità
| Patroni | pg_auto_failover | Gruppi di istanze gestite stateful con dischi permanenti a livello di regione |
|---|---|---|
| Project è disponibile dal 2015 e viene utilizzato in produzione da grandi aziende come Zalando e GitLab. | Progetto relativamente nuovo annunciato all'inizio del 2019. | Composto interamente da prodotti Google Cloud generalmente disponibili. |
Best practice per la manutenzione e il monitoraggio
La manutenzione e il monitoraggio del cluster PostgreSQL HA sono fondamentali per garantire alta disponibilità, integrità dei dati e prestazioni ottimali. Le sezioni seguenti forniscono alcune best practice per il monitoraggio e la manutenzione di un cluster PostgreSQL HA.
Esegui test regolari di backup e ripristino
Esegui regolarmente il backup dei database PostgreSQL e testa la procedura di ripristino. In questo modo, puoi garantire l'integrità dei dati e ridurre al minimo i tempi di inattività in caso di interruzione. Testa la procedura di recupero per convalidare i backup e identificare potenziali problemi prima che si verifichi un'interruzione.
Monitora i server PostgreSQL e il ritardo di replica
Monitora i server PostgreSQL per verificare che siano in esecuzione. Monitora il
ritardo della replica tra i nodi principali e di replica. Un ritardo eccessivo può causare
incoerenza dei dati e un aumento della perdita di dati in caso di failover. Configura
avvisi per aumenti significativi del ritardo e indaga rapidamente sulla causa principale.
L'utilizzo di visualizzazioni come pg_stat_replication e pg_replication_slots può aiutarti
a monitorare il ritardo della replica.
Implementare il pool di connessioni
Il pool di connessioni può aiutarti a gestire in modo efficiente le connessioni al database. Il pool di connessioni contribuisce a ridurre l'overhead della creazione di nuove connessioni, il che migliora le prestazioni dell'applicazione e la stabilità del server di database. Strumenti come PGBouncer e Pgpool-II possono fornire il pooling delle connessioni per PostgreSQL.
Implementa un monitoraggio completo
Per ottenere informazioni dettagliate sui cluster PostgreSQL HA, crea sistemi di monitoraggio robusti come segue:
- Monitora le metriche chiave di PostgreSQL e del sistema, come l'utilizzo della CPU, l'utilizzo della memoria, l'I/O del disco, l'attività di rete e le connessioni attive.
- Raccogli i log PostgreSQL, inclusi i log del server, i log WAL e i log autovacuum, per analisi approfondite e risoluzione dei problemi.
- Utilizza gli strumenti di monitoraggio e le dashboard per visualizzare le metriche e i log per identificare rapidamente i problemi.
- Integra le metriche e i log con i sistemi di avviso per la notifica proattiva di potenziali problemi.
Per ulteriori informazioni sul monitoraggio di un'istanza Compute Engine, consulta la panoramica di Cloud Monitoring.
Passaggi successivi
- Scopri di più sulla configurazione dell'alta disponibilità di Cloud SQL.
- Scopri di più sulle opzioni di alta disponibilità utilizzando Persistent Disk regionale.
- Scopri di più su Patroni.
- Scopri di più su pg_auto_failover.
- Per ulteriori architetture di riferimento, diagrammi e best practice, esplora il Cloud Architecture Center.
Collaboratori
Autore: Alex Cârciu | Solutions Architect