Questa guida descrive l'architettura di riferimento utilizzata per eseguire il deployment di Google Distributed Cloud (solo software) su bare metal. Questa guida è rivolta agli amministratori della piattaforma che vogliono utilizzare GKE Enterprise su una piattaforma bare metal in una configurazione geograficamente ridondante e ad alta disponibilità. Per comprendere al meglio questa guida, è necessario conoscere i concetti di base di GKE Enterprise, come descritto in Panoramica tecnica di GKE Enterprise. Inoltre, dovresti avere una conoscenza di base dei concetti di base di Kubernetes Google Kubernetes Engine (GKE), come descritto in Nozioni di base di Kubernetes e ai Documentazione di GKE.
Questa guida presenta Repository di codice sorgente GitHub che includa script che puoi usare per eseguire il deployment dell'architettura descritta. Questa guida descrive anche i componenti dell'architettura che accompagnano gli script e i moduli utilizzati per crearli. Ti consigliamo di utilizzare questi file come modelli per creare moduli che utilizzino le best practice e le norme della tua organizzazione.
Modello di architettura
Nella guida alle nozioni di base dell'architettura di GKE Enterprise, la piattaforma è descritta in livelli. Le risorse a ogni livello forniscono un insieme specifico di funzioni. Queste risorse sono di proprietà e gestite da una o più utenti tipo. Come mostrato nel seguente diagramma, l'architettura della piattaforma GKE Enterprise per l'hardware bare metal è composta dai seguenti livelli e risorse:
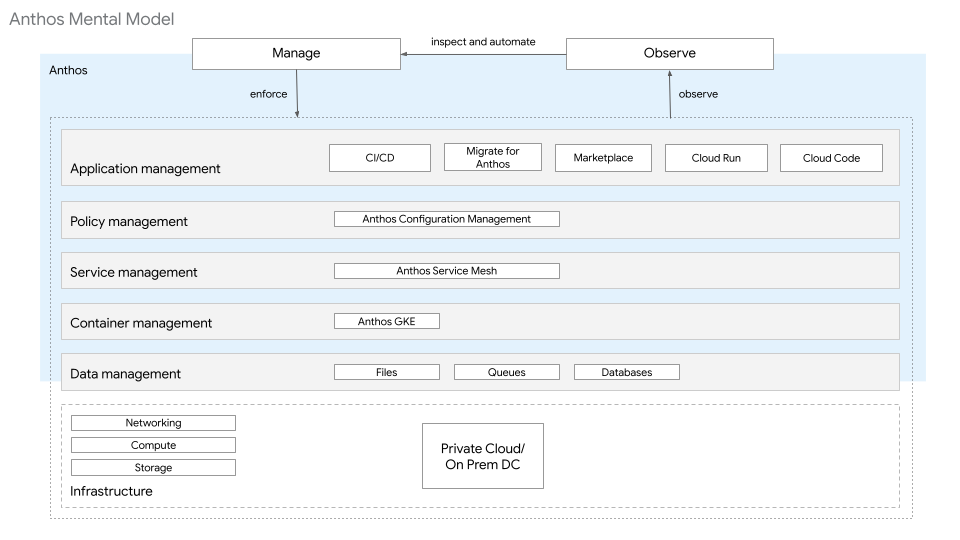
- Infrastruttura: questo livello include archiviazione, calcolo e networking, gestiti con elementi on-premise.
- Gestione dei dati: ai fini di questa guida, la gestione dei dati richiede un database SQL gestito al di fuori di Kubernetes di cluster in fase di deployment.
- Livello di gestione dei container: questo livello utilizza cluster GKE.
- Livello di gestione dei servizi: questo livello utilizza Cloud Service Mesh.
- Livello di gestione dei criteri: questo livello utilizza Config Sync e Policy Controller.
- Livello di gestione delle applicazioni: questo livello utilizza Cloud Build e Cloud Source Repositories.
- Livello di osservabilità: questo livello utilizza le dashboard di Google Cloud Observability e Cloud Service Mesh.
Ciascuno di questi livelli viene ripetuto nello stack per diversi ambienti del ciclo di vita, come sviluppo, gestione temporanea e produzione.
Le seguenti sezioni includono solo informazioni aggiuntive specifiche per deployment bare metal. Si basano sulle rispettive sezioni della Guida alle basi dell'architettura di GKE Enterprise. Ti consigliamo di consulta la guida mentre leggi questo articolo.
Networking
Per ulteriori informazioni sui requisiti di rete, vedi Requisiti di rete.
Per i bilanciatori del carico Google Distributed Cloud sono disponibili due opzioni: in bundle e manuale.
In modalità integrata, il software di bilanciamento del carico L4 viene implementato durante la creazione del cluster. I processi del bilanciatore del carico possono essere eseguiti su un pool dedicato di nodi worker o sugli stessi nodi del piano di controllo. Per pubblicizzare gli indirizzi IP virtuali (VIP), questo bilanciatore del carico ha due opzioni:
- Address Resolution Protocol (ARP): richiede connettività di livello 2 tra i nodi che eseguono il bilanciatore del carico.
- Border Gateway Protocol (BGP): Utilizza il peering per interconnettere la rete del cluster, che è un sistema autonomo, con un altro sistema autonomo, come una rete esterna.
In modalità manuale, configuri le tue soluzioni di bilanciamento del carico per il controllo e il traffico del piano dati. Sono disponibili molte opzioni hardware e software per i bilanciatori del carico esterni. Devi configurare il bilanciatore del carico esterno per il piano di controllo prima di creare un cluster bare metal. Il bilanciatore del carico del piano di controllo esterno può essere utilizzato anche per il piano dati di rete o puoi configurare un bilanciatore del carico separato per il piano dati. Per determinare la disponibilità, il bilanciatore del carico deve essere in grado di distribuire il traffico in un pool di nodi in base a un controllo di idoneità configurabile.
Per ulteriori informazioni sui bilanciatori del carico i deployment bare metal, vedi Panoramica dei bilanciatori del carico.
Architettura dei cluster
Google Distributed Cloud supporta più modelli di deployment su bare metal, soddisfacendo diverse esigenze di disponibilità, isolamento e utilizzo delle risorse. Questi modelli di deployment sono descritti in Scelta di un modello di deployment.
Gestione delle identità
Google Distributed Cloud utilizza GKE Identity Service per integrarsi con i provider di identità. Supporta OpenID Connect (OIDC) e LDAP (Lightweight Directory Access Protocol). Per le applicazioni e i servizi, Cloud Service Mesh può essere utilizzato con varie soluzioni di identità.
Per ulteriori informazioni sulla gestione delle identità, consulta Gestione delle identità con OIDC in Google Distributed Cloud e Autenticazione con OIDC o Configurare il servizio GKE Identity con LDAP.
Sicurezza e gestione delle norme
Per la gestione della sicurezza e delle policy di Google Distributed Cloud, consigliamo di utilizzare Config Sync e Policy Controller. Policy Controller consente di creare e applicare criteri in tutti i cluster. Configurazione Sync valuta le modifiche e le applica a tutti i cluster per ottenere lo stato appropriato.
Servizi
Quando utilizzi la modalità in bundle di Google Distributed Cloud per il bilanciamento del carico nei deployment bare metal, puoi creare servizi di tipo LoadBalancer. Quando crei questi servizi, Google Distributed Cloud
assegna un indirizzo IP dal pool di indirizzi IP del bilanciatore del carico configurato al
completamente gestito di Google Cloud. Il tipo di servizio LoadBalancer viene utilizzato per esporre Kubernetes
esterno al cluster
traffico da nord a sud.
Quando utilizzi Google Distributed Cloud, nel cluster viene creato anche un
IngressGateway
per impostazione predefinita. Non puoi creare elementi di tipo LoadBalancer
per Google Distributed Cloud in modalità manuale. Invece,
puoi creare un
Ingress
che utilizza IngressGateway o crea
NodePort-type
e configurare manualmente il bilanciatore del carico esterno per usare
servizio Kubernetes come backend.
Per la gestione del servizio, noto anche come traffico est-ovest, consigliamo di utilizzare Cloud Service Mesh. Cloud Service Mesh si basa sulle API aperte di Istio e fornisce osservabilità, autenticazione, crittografia, controlli granulari del traffico e altre funzionalità in modo uniforme. Per maggiori informazioni informazioni su Service Management, consulta Cloud Service Mesh.
Persistenza e gestione dello stato
Google Distributed Cloud on bare metal dipende in gran parte dall'infrastruttura esistente per l'archiviazione temporanea, l'archiviazione dei volumi e l'archiviazione dei volumi permanenti. I dati temporanei utilizzano le risorse del disco locale sul nodo in cui è pianificato il pod Kubernetes. Per i dati permanenti, GKE Enterprise compatibili con Container Storage Interface (CSI) un'API a standard aperto supportata da molti fornitori di servizi di archiviazione. Per l'archiviazione in produzione, consigliamo di installare un driver CSI da uno spazio di archiviazione GKE Enterprise Ready partner. Per l'elenco completo dei partner di archiviazione GKE Enterprise Ready, vedi Partner di archiviazione GKE Enterprise Ready
Per ulteriori informazioni sullo spazio di archiviazione, vedi Configurazione dello spazio di archiviazione.
Database
Google Distributed Cloud non fornisce ulteriori specifiche per i database, oltre a quelle standard la piattaforma GKE Enterprise. La maggior parte dei database viene eseguita su un di gestione dei dati. Anche i carichi di lavoro sulla piattaforma GKE Enterprise deve essere configurata per connettersi a eventuali database esterni accessibili.
Osservabilità
Google Cloud Observability raccoglie log e metriche di monitoraggio per
dei cluster Google Distributed Cloud in modo simile
di raccolta e monitoraggio dei cluster GKE. Per impostazione predefinita, i log del cluster e le metriche dei componenti di sistema vengono inviati a Cloud Monitoring.
Per fare in modo che Google Cloud Observability raccolga i log delle applicazioni
abilita l'opzione clusterOperations.enableApplication nel cluster
YAML della configurazione.
Per ulteriori informazioni sull'osservabilità, consulta Configurare il logging e il monitoraggio.
Caso d'uso: deployment di Cymbal Bank
In questa guida, il Cymbal Bank/Bank of Anthos viene utilizzata per simulare la pianificazione, il deployment della piattaforma di deployment delle applicazioni per Google Distributed Cloud on bare metal.
La parte restante del documento è costituita da tre sezioni. La Pianificazione che descrive le decisioni prese in base alle opzioni discusse nei del modello di architettura. La Implementazione della piattaforma tratta gli script e i moduli forniti da un'origine per eseguire il deployment della piattaforma GKE Enterprise. Infine, nella sezione Deployment dell'applicazione, l'applicazione Cymbal Bank viene dispiattata sulla piattaforma.
Questa guida di Google Distributed Cloud può essere utilizzata per eseguire il deployment o gli host autogestiti Istanze di Compute Engine di Compute Engine. Chiunque può completare questo processo utilizzando le risorse Google Cloud senza dover accedere a hardware fisico. L'utilizzo di Compute Engine è a solo scopo dimostrativo. NON utilizzare queste istanze per carichi di lavoro di produzione. Quando è disponibile l'accesso all'hardware fisico e Vengono utilizzati intervalli di indirizzi IP; puoi utilizzare il repository di origine fornito così com'è. Se ambiente differisce da quanto delineato Pianificazione puoi modificare gli script e i moduli per adattarli alle differenze. Il repository di origine associato contiene istruzioni sia per l'hardware fisico sia per gli scenari di istanza Compute Engine.
Pianificazione
La sezione seguente illustra nel dettaglio le decisioni di architettura prese durante la pianificazione e la progettazione della piattaforma per il deployment dell'applicazione GKE Enterprise della Banca di in Google Distributed Cloud. Queste sezioni si concentrano su un ambiente di produzione. Per creare ambienti inferiori, di sviluppo o gestione temporanea, puoi usare passaggi simili.
Progetti Google Cloud
Quando crei progetti in Google Cloud per Google Distributed Cloud, è necessario un progetto host del parco risorse. Si consiglia di creare progetti aggiuntivi per ogni ambiente o funzione aziendale. Questa configurazione di progetto consente di organizzare le risorse in base sull'utente tipo che interagisce con la risorsa.
Le seguenti sottosezioni illustrano i tipi di progetti consigliati e le persone associate.
Progetto Hub
Il progetto hub hub-prod è per la persona dell'amministratore di rete. Questo progetto è il luogo in cui è collegato il data center on-premise
Google Cloud utilizzando la forma di connettività ibrida che hai selezionato. Per maggiori informazioni
per informazioni sulle opzioni di connettività ibrida vedi
Connettività Google Cloud
Progetto host del parco risorse
Il progetto host del parco risorse fleet-prodè destinato alla persona dell'amministratore della piattaforma. Il progetto è il luogo in cui vengono registrati i cluster Google Distributed Cloud. In questo progetto si trovano anche le risorse Google Cloud correlate alla piattaforma. Queste
risorse includono l'osservabilità di Google Cloud, Cloud Source Repositories e altre ancora. Un determinato progetto Google Cloud può avere solo
un'unica flotta (o nessuna flotta) associata. Questa limitazione rafforza l'utilizzo dei progetti Google Cloud per fornire un isolamento più efficace tra le risorse che non sono gestite o utilizzate insieme.
Progetto di gruppo o dell'applicazione
L'applicazione o il progetto di gruppo app-banking-prod è per la persona sviluppatore. In questo progetto si trovano le risorse Google Cloud specifiche per l'applicazione o per il team. Il progetto include tutto tranne i cluster GKE. A seconda del numero di team o applicazioni, potrebbero essere presenti più istanze di questo tipo di progetto. Creazione in corso...
progetti distinti per team diversi ti consente di gestire
IAM, fatturazione e quota per ogni team.
Networking
Ogni cluster Google Distributed Cloud richiede le seguenti subnet di indirizzi IP:
- Indirizzi IP dei nodi
- Indirizzi IP dei pod Kubernetes
- Indirizzi IP di cluster/servizi Kubernetes
- Indirizzi IP del bilanciatore del carico (modalità in bundle)
Usare gli stessi intervalli di indirizzi IP non instradabili per il pod Kubernetes di servizio in ogni cluster, seleziona modello di rete in modalità isola. In questa configurazione, i pod possono comunicare direttamente tra loro all'interno di un cluster, ma non è raggiungibile direttamente dall'esterno di un cluster (utilizzando gli indirizzi IP dei pod). Questa configurazione forma un'isola all'interno della rete che non è collegata alla rete esterna. I cluster formano una mesh completa da nodo a nodo tra i nodi del cluster all'interno dell'isola, consentendo al pod di raggiungere direttamente altri pod all'interno del cluster.
Allocazione degli indirizzi IP
| Cluster | Nodo | Pod | Servizi | Bilanciatore del carico |
|---|---|---|---|---|
| metal-admin-dc1-000-prod | 10.185.0.0/24 | 192.168.0.0/16 | 10.96.0.0/12 | N/D |
| metal-user-dc1a-000-prod | 10.185.1.0/24 | 192.168.0.0/16 | 10.96.0.0/12 | 10.185.1.3-10.185.1.10 |
| metal-user-dc1b-000-prod | 10.185.2.0/24 | 192.168.0.0/16 | 10.96.0.0/12 | 10.185.2.3-10.185.2.10 |
| metal-admin-dc2-000-prod | 10.195.0.0/24 | 192.168.0.0/16 | 10.96.0.0/12 | N/D |
| metal-user-dc2a-000-prod | 10.195.1.0/24 | 192.168.0.0/16 | 10.96.0.0/12 | 10.195.1.3-10.195.1.10 |
| metal-user-dc2b-000-prod | 10.195.2.0/24 | 192.168.0.0/16 | 10.96.0.0/12 | 10.195.2.3-10.195.2.10 |
In modalità isola, è importante assicurarsi che le sottoreti di indirizzi IP scelte per i pod e i servizi Kubernetes non siano in uso o non siano instradabili dalla rete del nodo.
Requisiti di rete
a fornire un bilanciatore del carico integrato
Google Distributed Cloud che non richiede configurazione, utilizza
in bundle con la modalità bilanciatore
del carico in ogni cluster. Quando i carichi di lavoro vengono eseguiti LoadBalancer
viene assegnato un indirizzo IP dal pool del bilanciatore del carico.
Per leggere informazioni dettagliate sui requisiti del bilanciatore del carico in bundle per la configurazione, consulta Panoramica dei bilanciatori del carico e Configurazione del bilanciamento del carico in bundle.
Architettura dei cluster
Per un ambiente di produzione, consigliamo di utilizzare una modello di deployment dei cluster di amministrazione e utenti con un cluster di amministrazione e due cluster utente in ciascuna posizione geografica raggiungere la massima ridondanza e tolleranza di errore Google Distributed Cloud.
Ti consigliamo di utilizzare almeno quattro cluster di utenti per ogni ambiente di produzione. Utilizza due località geograficamente ridondanti, ciascuna contenente due cluster fault-tolerant. Ogni cluster a tolleranza di errore dispone di hardware ridondante e connessioni di rete ridondanti. La riduzione del numero di cluster riduce la ridondanza o la tolleranza di errore dell'architettura.
Per garantire un'elevata disponibilità, il piano di controllo di ogni cluster utilizza tre nodi. Con un minimo di tre nodi worker per cluster utente, puoi distribuire i carichi di lavoro su questi nodi per ridurre l'impatto se un nodo diventa offline. La il numero e il dimensionamento dei nodi worker dipendono in gran parte dal tipo e dal numero carichi di lavoro in esecuzione nel cluster. Il dimensionamento consigliato per ciascuno dei nodi è discusso in Configurazione dell'hardware per Google Distributed Cloud.
La tabella seguente descrive le dimensioni consigliate dei nodi per core CPU, memoria e spazio di archiviazione su disco locale in questo caso d'uso.
| Tipo di nodo | CPU/vCPU | Memoria | Archiviazione |
|---|---|---|---|
| Piano di controllo | 8 core | 32 GiB | 256 GiB |
| Worker | 8 core | 64 GiB | 512 GiB |
Per ulteriori informazioni sui prerequisiti della macchina e sul dimensionamento, vedi Prerequisiti delle macchine dei nodi cluster.
Gestione delle identità
Per la gestione delle identità, consigliamo un'integrazione con OIDC tramite GKE Identity Service. Negli esempi forniti nella fonte repository di codice, l'autenticazione locale viene utilizzata per semplificare i requisiti. Se OIDC , puoi modificare l'esempio per utilizzarlo. Per ulteriori informazioni, consulta Gestione delle identità con OIDC in Google Distributed Cloud.
Sicurezza e gestione delle norme
Nel caso d'uso di Cymbal Bank, Config Sync e Policy Controller
per la gestione dei criteri. Viene creato un repository di origine Cloud per archiviare i dati di configurazione utilizzati da Config Sync. L'operatore ConfigManagement, utilizzato per installare e gestire Config Sync e Policy Controller, deve disporre dell'accesso in sola lettura al repository di codice sorgente della configurazione. Per concedere l'accesso, utilizza una forma di
autenticazione. In questo esempio, viene utilizzato un account di servizio Google.
Servizi
Per Service Management in questo caso d'uso, Cloud Service Mesh viene utilizzato per
forniscono una base su cui
creare servizi distribuiti. Per impostazione predefinita, nel cluster viene creato anche un IngressGateway che gestisce gli oggetti Ingress Kubernetes standard.
Persistenza e gestione degli stati
Poiché l'archiviazione permanente dipende in gran parte dall'infrastruttura esistente, questo caso d'uso non lo richiede. In altri casi, tuttavia, ti consigliamo di utilizzare le opzioni di archiviazione dei partner di archiviazione GKE Enterprise Ready. Se è disponibile un'opzione di archiviazione CSI, può essere installata sul cluster utilizzando le istruzioni fornite dal fornitore. Per proof of concept e casi d'uso avanzati, puoi utilizzare volumi locali. Tuttavia, nella maggior parte dei casi d'uso, sconsigliamo di utilizzare volumi locali in ambienti di produzione.
Database
Molte applicazioni stateful su Google Distributed Cloud utilizzano come archivio di persistenza. Un'applicazione di database stateful deve avere accesso a un database per fornire la propria logica di business ai client. Non sono previste limitazioni sul tipo di Datastore utilizzato da Google Distributed Cloud. Le decisioni in materia di archiviazione dei dati, di conseguenza, dallo sviluppatore o dai team di gestione dei dati associati. Poiché applicazioni diverse potrebbero richiedere datastore diversi, questi possono essere utilizzati anche senza limitazioni. I database possono essere gestiti nel cluster, on-premise anche nel cloud.
Cymbal Bank è un'applicazione stateful che accede a due database PostgreSQL. L'accesso al database viene configurato tramite le variabili di ambiente. Il database PostgreSQL deve essere accessibile nodi che eseguono i carichi di lavoro, anche se il database è gestito esternamente in un cluster Kubernetes. In questo esempio, l'applicazione accede a un database PostgreSQL esterno esistente. Mentre l'applicazione viene eseguita sulla piattaforma, il database viene gestiti esternamente. Di conseguenza, il database non fa parte della piattaforma GKE Enterprise. Se è disponibile un database PostgreSQL, utilizzalo. In caso contrario, crea e utilizza un database Cloud SQL per l'applicazione Cymbal Bank.
Osservabilità
Ogni cluster nel caso d'uso di Cymbal Bank è configurato in modo che Google Cloud Observability raccolga i log e le metriche sia per i componenti di sistema sia per le applicazioni. Esistono diverse dashboard di Cloud Monitoring create dal programma di installazione della console Google Cloud, che possono essere visualizzate il Dashboard di monitoraggio . Per ulteriori informazioni sull'osservabilità, consulta Configurare il logging e il monitoraggio e Come funzionano il logging e il monitoraggio per Google Distributed Cloud.
Deployment della piattaforma
Per ulteriori informazioni, consulta Deployment della piattaforma della documentazione nel repository di codice sorgente GitHub.
Deployment dell'applicazione
Per maggiori informazioni, consulta la sezione Esegui il deployment dell'applicazione della documentazione nel repository di origine GitHub.
Passaggi successivi
- Scopri di più su Cloud Service Mesh Config Sync, e Policy Controller.
- Dai un'occhiata ad alcune delle altre architetture di riferimento di GKE Enterprise.
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.