Questo documento spiega a ricercatori, data scientist e analisti aziendali le procedure e le considerazioni per analizzare i dati di Fast Healthcare Interoperability Resources (FHIR) in BigQuery.
Nello specifico, questo documento si concentra sui dati delle risorse dei pazienti esportati dall'archivio FHIR nell'API Cloud Healthcare. Questo documento illustra anche una serie di query che dimostrano il funzionamento dei dati dello schema FHIR in un formato relazionale e mostra come accedere a queste query per il riutilizzo tramite le visualizzazioni.
Utilizzo di BigQuery per l'analisi dei dati FHIR
L'API specifica per FHIR dell'API Cloud Healthcare è progettata per l'interazione transazionale in tempo reale con i dati FHIR a livello di una singola risorsa FHIR o di una raccolta di risorse FHIR. Tuttavia, l'API FHIR non è progettata per i casi d'uso di analisi. Per questi casi d'uso, ti consigliamo di esportare i dati dall'API FHIR in BigQuery. BigQuery è un data warehouse serverless e scalabile che consente di analizzare grandi quantità di dati in modo retrospettivo o prospettico.
Inoltre, BigQuery è conforme allo standard ANSI:2011 SQL, che rende i dati accessibili a data scientist e analisti aziendali tramite strumenti che in genere utilizzano, come Tableau, Looker o Vertex AI Workbench.
In alcune applicazioni, come Vertex AI Workbench, puoi accedere tramite client integrati, come la libreria client Python per BigQuery. In questi casi, i dati restituiti all'applicazione sono disponibili tramite le strutture di dati linguistici integrate.
Accesso a BigQuery
Puoi accedere a BigQuery tramite l'UI web di BigQuery nella console Google Cloud e anche con i seguenti strumenti:
- Lo strumento a riga di comando BigQuery
- L'API REST o le librerie client di BigQuery
- Driver ODBC e JDBC
Utilizzando questi strumenti, puoi integrare BigQuery in quasi qualsiasi applicazione.
Utilizzo della struttura di dati FHIR
La struttura di dati standard FHIR integrata è complessa, con tipi di dati FHIR nidificati e incorporati in qualsiasi risorsa FHIR. Questi tipi di dati FHIR incorporabili sono indicati come
tipi di dati complessi.
Gli array e le strutture sono noti anche come tipi di dati complessi nei database
relazionali. La struttura di dati standard FHIR integrata funziona bene se serializzata come file XML o JSON in un sistema orientato ai documenti, ma può essere difficile da gestire se tradotta in database relazionali.
Lo screenshot seguente mostra una visualizzazione parziale di un tipo di dato FHIR
patient resource
che illustra la natura complessa della struttura dei dati standard FHIR integrata.
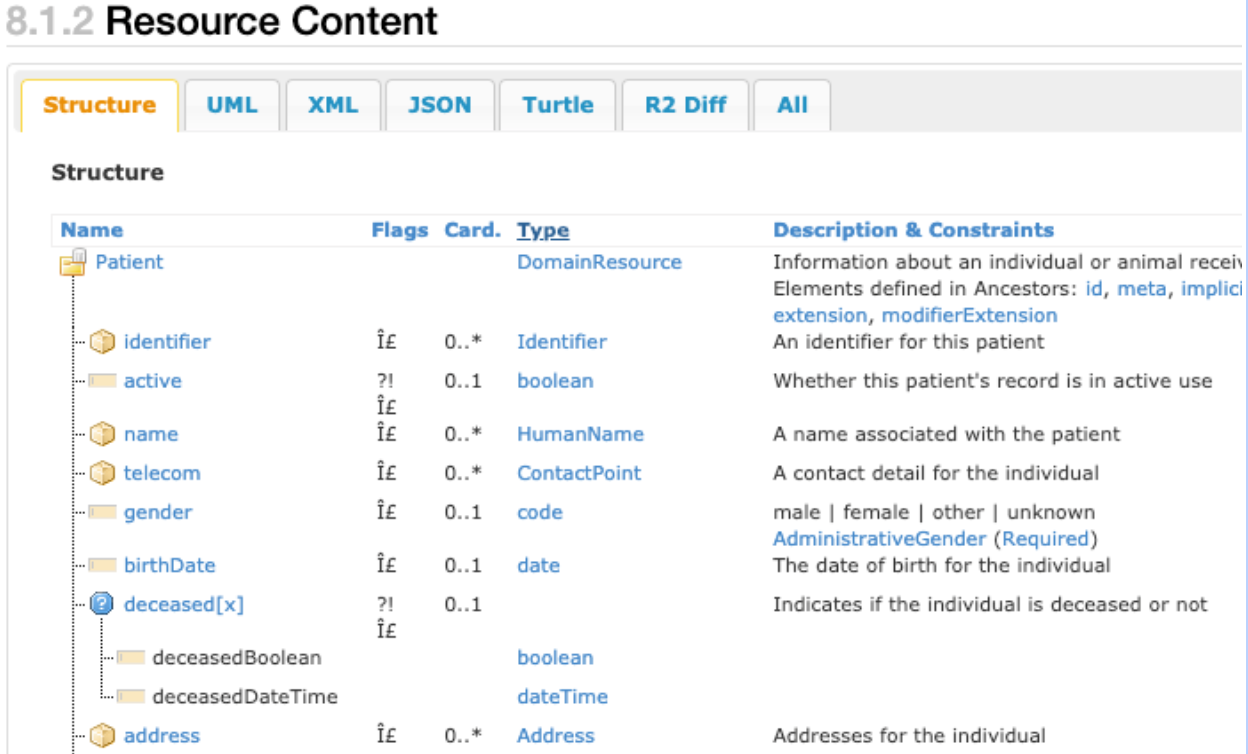
Lo screenshot precedente mostra i componenti principali di un tipo di dati FHIR patient
resource. Ad esempio, la colonna Cardinalità (indicata nella tabella come Card) mostra diversi elementi che possono avere zero, una o più voci. La colonna Tipo mostra i tipi di dati Identificatore, HumanName e Address, che sono esempi di tipi di dati complessi che comprendono il tipo di dati patient
resource. Ognuna di queste righe può essere registrata più volte, come array di strutture.
Utilizzo di array e strutture
BigQuery supporta gli array e i tipi di dati STRUCT, ovvero strutture di dati ripetute e nidificate, così come sono rappresentati nelle risorse FHIR, il che rende possibile la conversione dei dati da FHIR a BigQuery.
In BigQuery, un array è un elenco ordinato costituito da zero o più valori dello stesso tipo di dati. Puoi creare array di tipi di dati semplici, come il tipo di dati INT64, e tipi di dati complessi, come il tipo di dati STRUCT. L'eccezione è il tipo di dati ARRAY, perché gli array di
array non sono attualmente supportati. In BigQuery, un array di strutture viene visualizzato come un record ripetibile.
Puoi specificare dati nidificati o nidificati e ripetuti nell'interfaccia utente di BigQuery o in un file di schema JSON. Per specificare colonne nidificate o colonne nidificate e ripetute, utilizza il tipo di dati RECORD (STRUCT).
L'API Cloud Healthcare supporta lo schema SQL su FHIR in BigQuery. Questo schema di analisi è lo schema predefinito per il metodo ExportResources() ed è supportato dalla community FHIR.
BigQuery supporta i dati denormalizzati. Ciò significa che quando memorizzi i dati, anziché creare uno schema relazionale come uno schema a stella o a fiocco di neve, puoi denormalizzarli e utilizzare colonne nidificate e ripetute. Le colonne nidificate e ripetute mantengono le relazioni tra gli elementi di dati senza l'impatto sulle prestazioni della conservazione di uno schema relazionale (normalizzato).
Accedere ai dati tramite l'operatore UNNEST
Ogni risorsa FHIR nell'API FHIR viene esportata in BigQuery come
una riga di dati. Puoi considerare un array o una struttura all'interno di una riga come una tabella incorporata. Puoi accedere ai dati in questa "tabella" nella clausola SELECT
o nella clausola WHERE della query
appiattando l'array o la struttura utilizzando l'operatore UNNEST.
L'operatore UNNEST prende un array e restituisce una tabella con una singola riga per ogni elemento dell'array. Per ulteriori informazioni, consulta
Utilizzo degli array in SQL standard.
L'operazione UNNEST non conserva l'ordine degli elementi dell'array, ma puoi riordinare la tabella utilizzando la clausola facoltativa WITH OFFSET. Questo
restituisce un'altra colonna con la clausola OFFSET per ogni elemento dell'array.
Puoi quindi utilizzare la clausola ORDER BY per ordinare le righe in base all'offset.
Quando unisci i dati non nidificati, BigQuery utilizza un'operazione CROSS JOIN correlata che fa riferimento alla colonna degli array di ogni elemento dell'array con la tabella di origine, ovvero la tabella che precede direttamente la chiamata a UNNEST nella clausola FROM. Per ogni riga della tabella di origine, l'operazione UNNEST
appiattisce l'array della riga in un insieme di righe contenenti gli elementi
dell'array. L'operazione CROSS JOIN correlata unisce questo nuovo insieme di righe alla singola riga della tabella di origine.
Esaminare lo schema con le query
Per eseguire query sui dati FHIR in BigQuery, è importante comprendere lo schema creato durante il processo di esportazione. BigQuery ti consente di esaminare la struttura delle colonne di ogni tabella del set di dati tramite la funzionalità INFORMATION_SCHEMA, una serie di viste che mostrano i metadati. Il resto di questo documento fa riferimento allo schema SQL on FHIR, progettato per essere accessibile per il recupero dei dati.
La seguente query di esempio esplora i dettagli delle colonne per la tabella paziente nel schema SQL on FHIR. La query fa riferimento al set di dati pubblico Synthea Generated Synthetic Data in FHIR, che ospita oltre 1 milione di record dei pazienti sintetici generati nei formati Synthea e FHIR.
Quando esegui una query sulla vista
INFORMATION_SCHEMA.COLUMNS, i risultati della query contengono una riga per ogni colonna (campo) di una tabella. La
seguente query restituisce tutte le colonne della tabella paziente:
SELECT * FROM `bigquery-public-data.fhir_synthea.INFORMATION_SCHEMA.COLUMNS` WHERE table_name='patient'
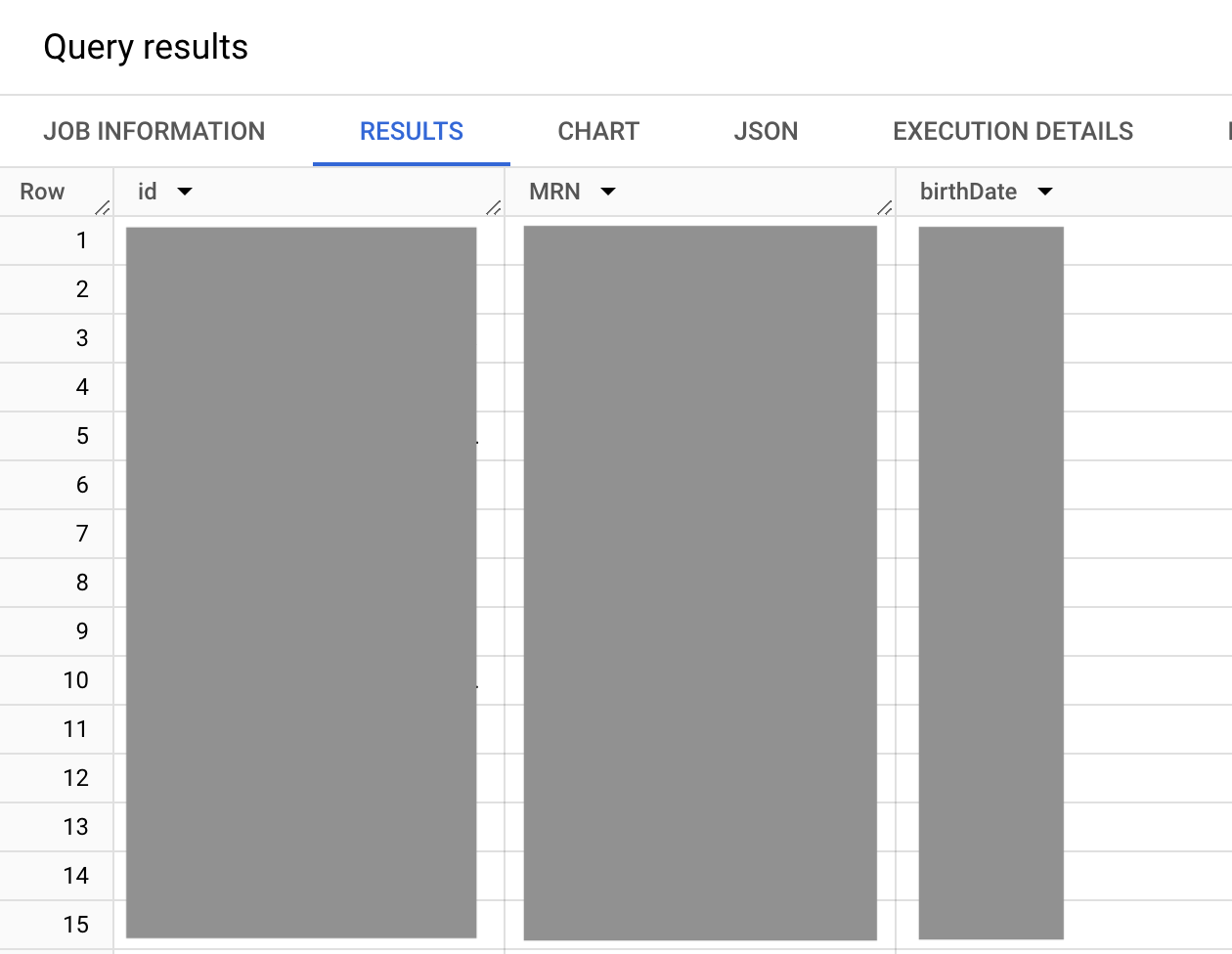
Lo screenshot seguente del risultato della query mostra il tipo di dati identifier e l'array all'interno del tipo di dati che contiene i tipi di dati STRUCT.

Utilizzo della risorsa paziente FHIR in BigQuery
Il numero del record sanitario del paziente (MRN), un'informazione fondamentale memorizzata nei dati FHIR, viene utilizzato in tutti i sistemi di dati clinici e operativi di un'organizzazione per tutti i pazienti. Qualsiasi metodo di accesso ai dati di un singolo paziente o di un insieme di pazienti deve filtrare per o restituire il codice MRN oppure eseguire entrambe le operazioni.
La seguente query di esempio restituisce l'identificatore del server FHIR interno alla stessa risorsa paziente, inclusi l'MRN e la data di nascita di tutti i pazienti. È incluso anche il filtro per eseguire query su un MRN specifico, ma è commentato in questo esempio.
In questa query, estrai due volte il tipo di dati complessi identifier. Utilizzi anche le operazioni CROSS JOIN correlate per unire i dati non nidificati con la relativa tabella di origine.
La tabella bigquery-public-data.fhir_synthea.patient nella query è stata creata utilizzando la versione dello schema SQL su FHIR dell'esportazione da FHIR a BigQuery.
SELECT id, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b"
L'output è simile al seguente:
Nella query precedente, il set di valori identifier.type.coding.code è il
set di valori identifier FHIR
che enumera i tipi di dati di identità disponibili, ad esempio il codice identificativo del paziente (MR tipo di dato di identità), la patente di guida (DL tipo di dato di identità) e il numero di passaporto
(PPN tipo di dato di identità). Poiché il set di valori identifier.type.coding è un array, è possibile elencare un numero qualsiasi di identificatori per un paziente. In questo caso, però, devi utilizzare il codice MRN (MR tipo di dati di identità).
Unisci la tabella dei pazienti ad altre tabelle
Sulla base della query della tabella dei pazienti, puoi unire la tabella dei pazienti ad altre tabelle di questo set di dati, ad esempio la tabella delle condizioni. La tabella delle condizioni è dove vengono registrate le diagnosi dei pazienti.
La seguente query di esempio recupera tutte le voci relative alla condizione medica dell'ipertensione.
SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003'
L'output è simile al seguente:
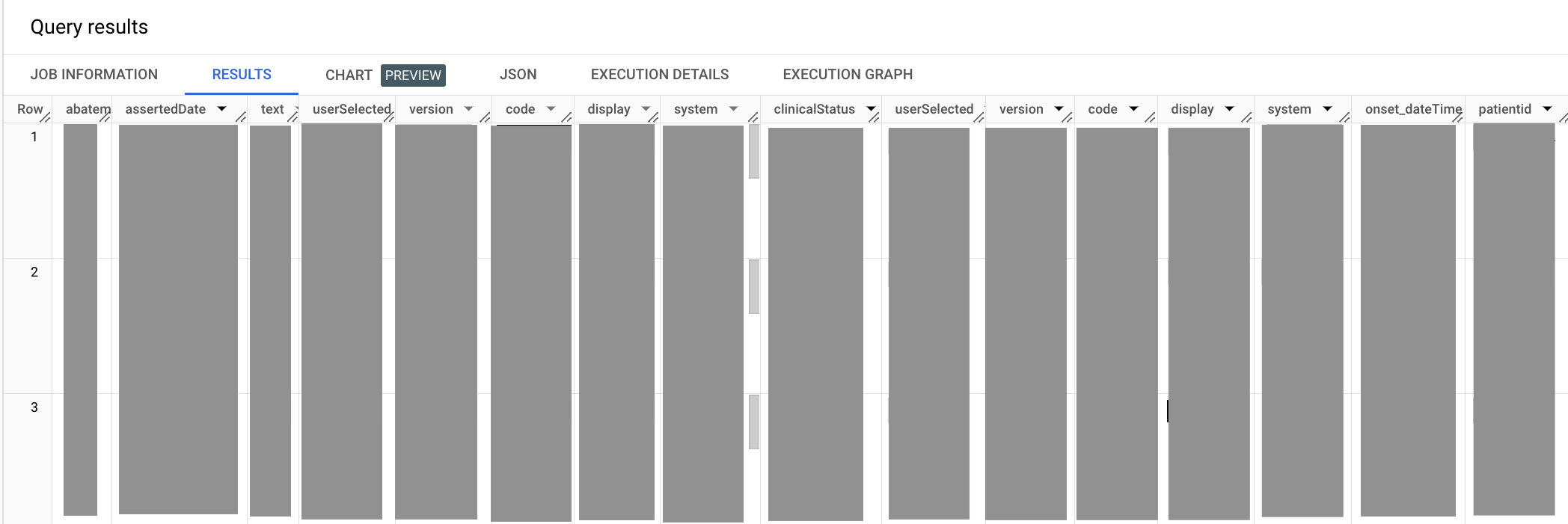
Nella query precedente, riutilizzi il metodo UNNEST per appianare il
code.coding campo. Gli elementi di codice abatement.dateTime e onset.dateTime nell'istruzione SELECT sono associati a un alias perché entrambi terminano con dateTime, il che potrebbe comportare nomi di colonne ambigui nell'output di un'istruzione SELECT. Quando selezioni il codice Hypertension, devi anche dichiarare il sistema di terminologia da cui proviene il codice, in questo caso il sistema di terminologia clinica SNOMED CT.
Come passaggio finale, utilizza la chiave subject.patientid per unire la tabella delle condizioni alla tabella dei pazienti. Questa chiave rimanda all'identificatore della risorsa
del paziente all'interno del server FHIR.
Raggruppare le query
Nella seguente query di esempio, utilizzi le query delle due sezioni precedenti e le unisci utilizzando la clausola WITH, mentre esegui alcuni semplici calcoli.
WITH patient AS ( SELECT id as patientid, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b" ), condition AS ( SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003' ) SELECT patient.patientid, patient.MRN, patient.birthDate as birthDate_string, #current patient age. now - birthdate CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH)/12 AS INT) as patient_current_age_years, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH) AS INT) as patient_current_age_months, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),DAY) AS INT) as patient_current_age_days, #age at onset. onset date - birthdate DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset, condition.onset_dateTime, condition.code.code, condition.code.display, condition.code.system FROM patient JOIN condition ON patient.patientid = condition.patientid
L'output è simile al seguente:
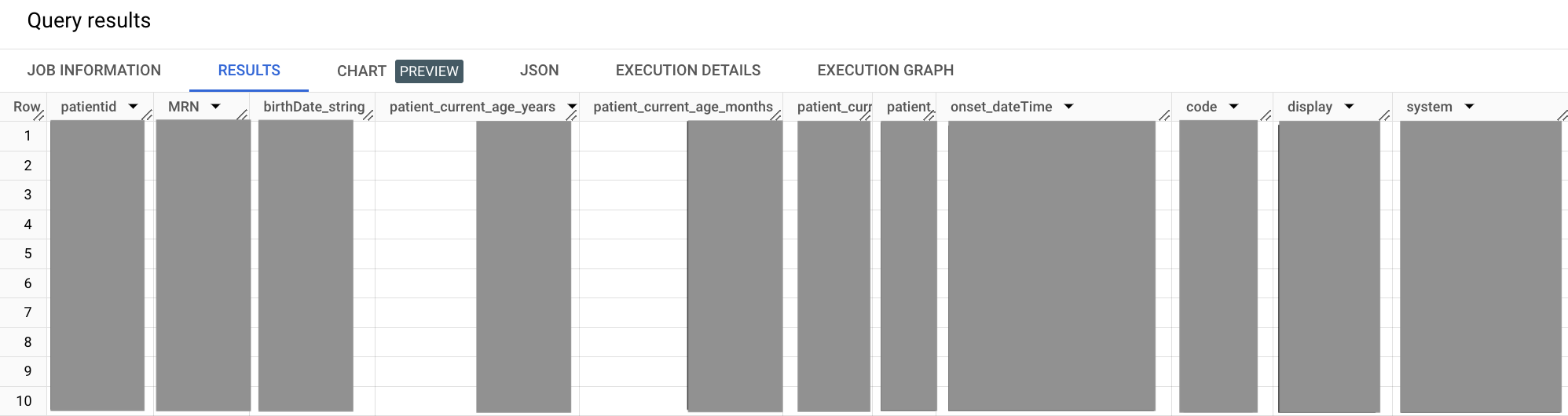
Nella query di esempio precedente, la clausola WITH consente di isolare le sottoquery
nei rispettivi segmenti definiti. Questo approccio può contribuire alla leggibilità, che diventa più importante man mano che la query aumenta di dimensioni. In questa query, isoli la sottoquery per i pazienti e le condizioni nei rispettivi segmenti WITH e poi li unisci nel segmento WITH principale.SELECT
Puoi anche applicare i calcoli ai dati non elaborati. Il seguente codice campione, un
statement SELECT, mostra come calcolare l'età del paziente all'insorgenza della malattia.
DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset
Come indicato nell'esempio di codice precedente, puoi eseguire una serie di operazioni sulla stringa dateTime fornita, condition.onset_dateTime. Innanzitutto,
seleziona il componente della data della stringa con il valore
SUBSTR. Poi converti la stringa in un tipo di dati DATE utilizzando la sintassi
CAST. Inoltre, converti il campo patient.birthDate nel campo DATE.
Infine, calcola la differenza tra le due date utilizzando la funzione
DATE_DIFF.
Passaggi successivi
- Analizza i dati clinici utilizzando BigQuery e AI Platform Notebooks.
- Visualizzazione dei dati di BigQuery in un blocco note Jupyter.
- Sicurezza dell'API Cloud Healthcare.
- Controllo dell'accesso a BigQuery.
- Soluzioni per la sanità e le scienze biologiche in Google Cloud Marketplace.
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.