本文档向研究人员,数据科学家和业务分析师解释了在 BigQuery 中分析快速医疗保健互操作性资源 (FHIR) 的过程和注意事项。
具体来说,本文档聚焦于从 Cloud Healthcare API 中的 FHIR 存储区 导出的患者资源数据。本文档还详细演示了一系列查询,它们演示了 FHIR 架构数据以关系型格式工作,并介绍如何访问这些查询以通过视图重复使用。
使用 BigQuery 分析 FHIR 数据
Cloud Healthcare API 的 FHIR 专属 API 旨在与单个 FHIR 资源级层或 FHIR 资源的集合进行实时实务交互。但是,FHIR API 并不用于分析用例。对于这些用例,我们建议您 将数据从 FHIR API 导出到 BigQuery。BigQuery 是一个无服务器,可扩容的数据仓库,可让您快速或大规模分析大量数据。
此外,BigQuery 符合 ANSI:2011 SQL,它允许数据科学家和业务分析师通过常用工具(例如 Tableau、Looker 或 Vertex AI Workbench)去访问数据。
在某些应用(例如 Vertex AI Workbench)中,您可以使用内置的客户端(如 适用于 BigQuery 的 Python 客户端库)进行访问。在这些情况下,返回的数据可通过内置的语言数据结构提供。
访问 BigQuery
您可以通过 Google Cloud 控制台中的 BigQuery 网页界面 以及以下工具访问 BigQuery:
- BigQuery 命令行工具
- BigQuery REST API 或 客户端库
- ODBC 和 JDBC 驱动程序。
通过使用这些工具,您几乎可以将 BigQuery 集成到任何应用中。
使用 FHIR 数据结构
内置 FHIR 标准数据结构很复杂,通过任何 FHIR 资源嵌套和嵌入 FHIR 数据类型。这些可嵌入的 FHIR 数据类型称为 复杂数据类型。数组和结构在关系型数据库中也称为复杂数据类型。内置 FHIR 标准数据结构可在面向文档的系统中序列化为 XML 或 JSON 文件,但在转换为关系数据库时,该结构可能难以实现。
以下屏幕截图显示了 FHIR patient resource 数据类型的部分视图,其中说明了内置 FHIR 标准数据结构的复杂性。
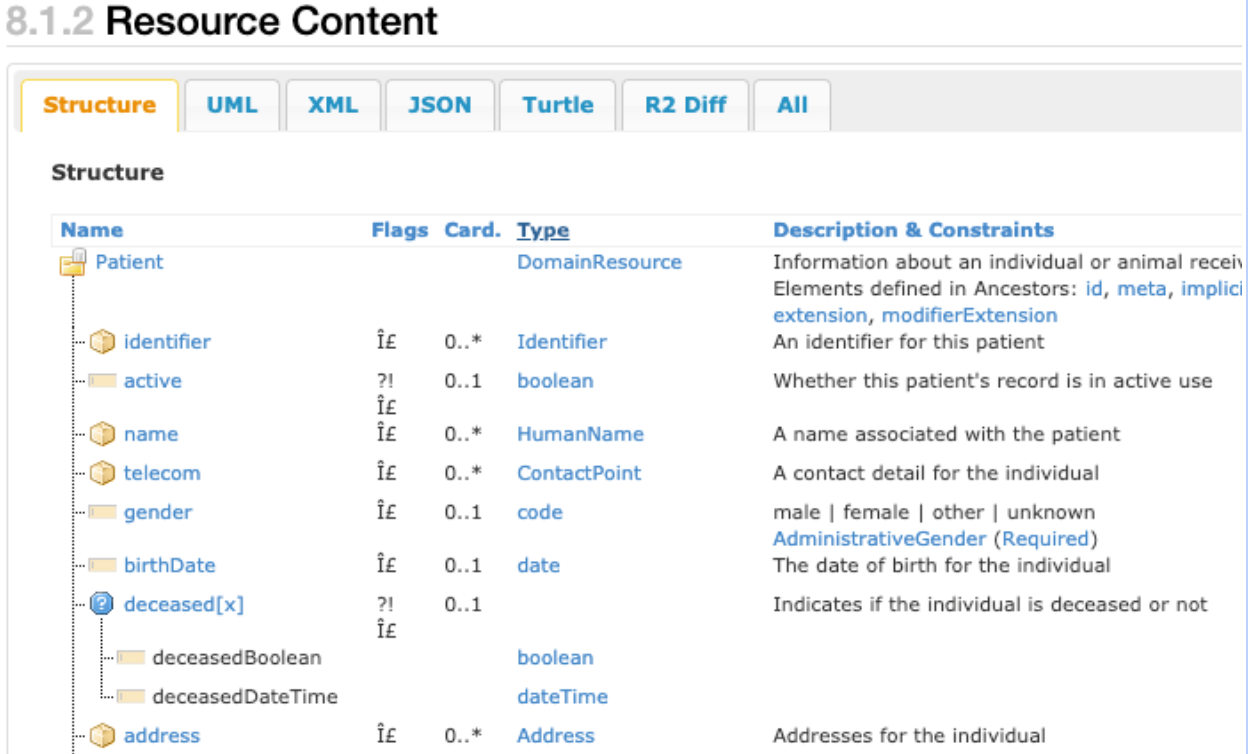
上面的屏幕截图显示了 FHIR patient
resource 数据类型的主要组件。例如,基数 列(在表中表示为 Card.)显示若干项,这些项可包含零个、一个或多个条目。类型列显示了标识符、HumanName 和 Address 数据类型,即构成 patient
resource 数据类型的复杂数据类型的示例。每行都可以作为结构数组记录多次。
使用数组和结构
BigQuery 支持数组和 STRUCT 数据类型(嵌套的重复数据结构),因为它们在 FHIR 资源中表示,这使得从 FHIR 到 BigQuery 的数据转换成为可能。
在 BigQuery 中,数组是由零个或多个相同数据类型的值组成的有序列表。您可以构建简单数据类型(如 INT64 数据类型)和复杂数据类型(如 STRUCT 数据类型)的数组。ARRAY 数据类型例外,因为目前不支持数组的数组。在 BigQuery 中,结构数组显示为可重复记录。
您可以在 BigQuery 界面或 JSON 架构文件中指定嵌套数据,或嵌套并重复的数据。要指定嵌套列或嵌套并重复的列,请使用 RECORD (STRUCT) 数据类型。
Cloud Healthcare API 支持 BigQuery 中 FHIR 架构上的 SQL。此分析架构是 ExportResources() 方法的默认架构,并且受 FHIR 社区的支持。
BigQuery 支持反规范化的数据。这意味着在存储数据时,您可以对数据进行反规范化并使用嵌套和重复的列,而不用创建关系型架构(如星型或雪花型架构)。嵌套并重复的列不但可以保持数据元素之间的关系,而且也不会因保留关系(规范化)架构对性能产生影响。
通过 UNNEST 运算符访问您的数据
FHIR API 中的每个 FHIR 资源都会作为一行数据导出到 BigQuery 中。您可以将任何行中的数组或结构视为嵌入式表。您可以通过 使用 UNNEST 运算符将数组或结构展平 来访问 SELECT 子句或查询中的 WHERE 子句去访问“表”中的数据。UNNEST 运算符接受一个数组,然后返回一个表,该数组中的每个元素占一行。如需了解详情,请参阅 使用标准 SQL 中的数组。
UNNEST 操作不会保留数组元素的顺序,但您可以使用可选的 WITH OFFSET 子句对表进行重新排序。这会返回一个额外的列,其中包含每个数组元素的 OFFSET 子句。然后,您可以使用 ORDER BY 子句按偏移量对行进行排序。
联接非嵌套数据时,BigQuery 会使用关联的 CROSS JOIN 操作,该操作使用源表从数组中的每个项引用数组的列,即直接在 FROM 子句中调用 UNNEST。对于来源表中的每一行,UNNEST 操作会将来自该行的数组展平为一组包含数组元素的行。相关 CROSS JOIN 操作会将此新行与来源表的单行联接。
使用查询调查架构
如需在 BigQuery 中查询 FHIR 数据,请务必了解通过导出过程创建的架构。借助 BigQuery,您可以通过 INFORMATION_SCHEMA 功能(显示一系列元数据的视图)检查数据集中每个表的列结构。本文档的其余部分提及 FHIR 架构上的SQL,该架构设计可用于检索数据。
以下示例查询在 FHIR 架构上的 SQL 中探索患者表的列详细信息。该查询引用 FHIR 中生成的合成数据 公共数据集,该数据集托管了在 Synthea 和 FHIR 中生成的超过 100 万个合成患者记录。
查询 INFORMATION_SCHEMA.COLUMNS 视图时,查询为表中的每一列(字段)返回一行结果。以下查询可返回患者表中的所有列:
SELECT * FROM `bigquery-public-data.fhir_synthea.INFORMATION_SCHEMA.COLUMNS` WHERE table_name='patient'
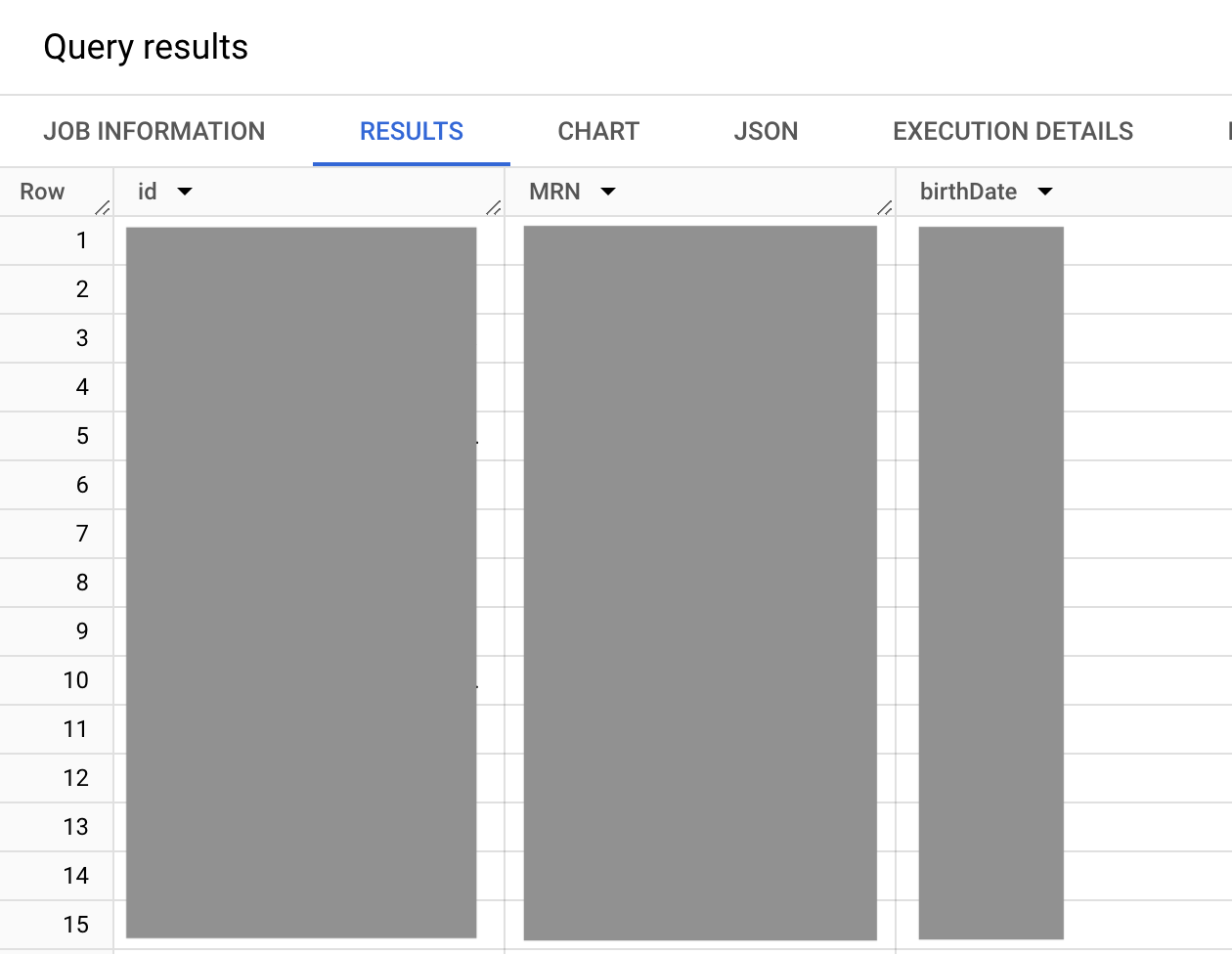
以下查询结果的屏幕截图显示了 identifier 数据类型,以及该数据类型中包含 STRUCT 数据类型的数组。

在 BigQuery 中使用 FHIR 患者资源
患者医疗记录编号 (MRN) 是 FHIR 数据中存储的一个关键信息,用于组织的所有患者的临床和运营数据系统。访问个别患者或一组患者的数据的任何方法都必须过滤或返回 MRN,或者两者都做出。
以下示例查询会将内部 FHIR 服务器标识符返回给患者资源本身,包括 MRN 和所有患者的出生日期。查询特定 MRN 的过滤条件也包括在内,但在本示例中被注释掉。
在此查询中,您两次解除了 identifier 复杂数据类型的嵌套。您还可以使用相关的 CROSS JOIN 操作将未嵌套的数据与来源表联接起来。查询中的 bigquery-public-data.fhir_synthea.patient 表是使用 FHIR 的 FHIR 架构版本上的 SQL 导出到 BigQuery 创建的。
SELECT id, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b"
输出类似于以下内容:
在前面的查询中,identifier.type.coding.code 值集是 FHIR identifier 值集,枚举的可用身份数据类型,如 MRN (MR 身份数据类型)、驾驶执照(DL 身份数据类型)和护照号码(PPN 身份数据类型)。由于 identifier.type.coding 值集是数组,因此针对患者列出的任意数量的标识符。但在本例中,您需要 MRN(MR 身份数据类型)。
将患者表与其他表联接起来
基于患者表查询,您可以将患者表与此数据集中的其他表(例如条件表)联接。条件表是患者诊断数据的记录位置。
以下示例查询会检索血压的医疗条件的所有条目。
SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003'
输出类似于以下内容:
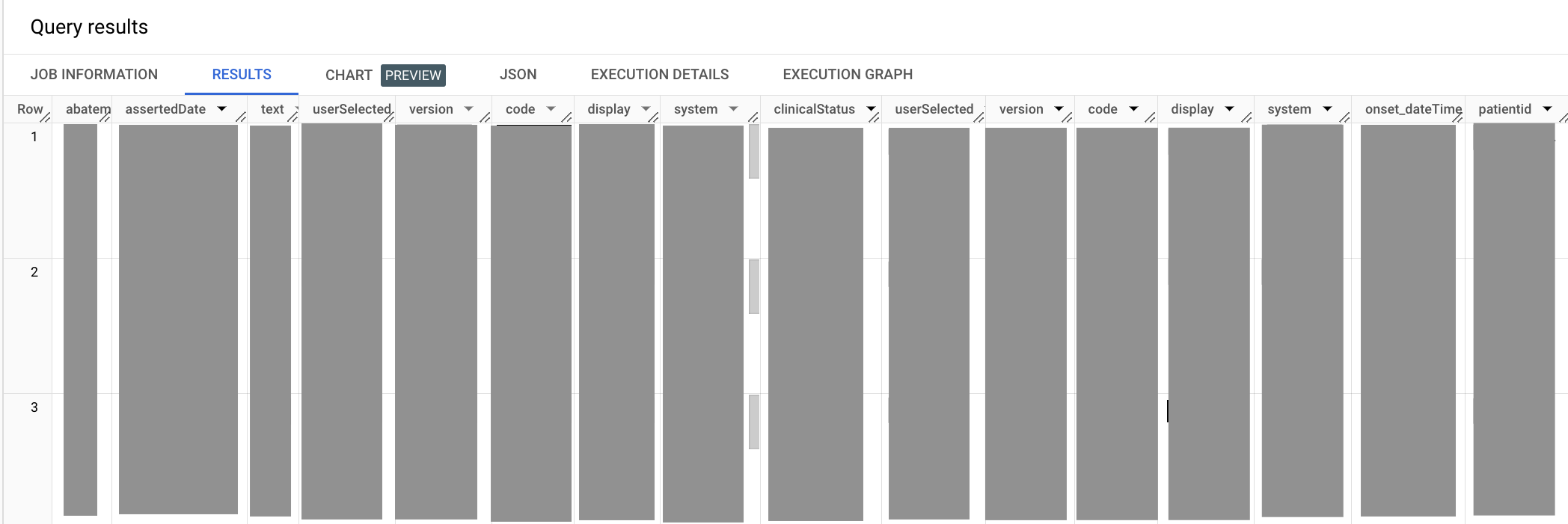
在上述查询中,您将重复使用 UNNEST 方法来展平 code.coding 字段。在 SELECT 状态中的 abatement.dateTime 与 onset.dateTime 代码元素是有别名的,因为它们都以 dateTime结 尾,这将导致 SELECT 状输出中的列名称不明确。当您选择 Hypertension 代码时,还需要声明代码的术语系统,在本例中为 SNOMED CT 临床术语系统。
最后,使用 subject.patientid 键将条件表与患者表联接起来。此键指向 FHIR 服务器中患者资源本身的标识符。
整合查询
在以下示例中,您将使用前两个部分中的查询,并使用 WITH 子句联接这些查询,同时执行一些简单的计算。
WITH patient AS ( SELECT id as patientid, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b" ), condition AS ( SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003' ) SELECT patient.patientid, patient.MRN, patient.birthDate as birthDate_string, #current patient age. now - birthdate CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH)/12 AS INT) as patient_current_age_years, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH) AS INT) as patient_current_age_months, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),DAY) AS INT) as patient_current_age_days, #age at onset. onset date - birthdate DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset, condition.onset_dateTime, condition.code.code, condition.code.display, condition.code.system FROM patient JOIN condition ON patient.patientid = condition.patientid
输出类似于以下内容:
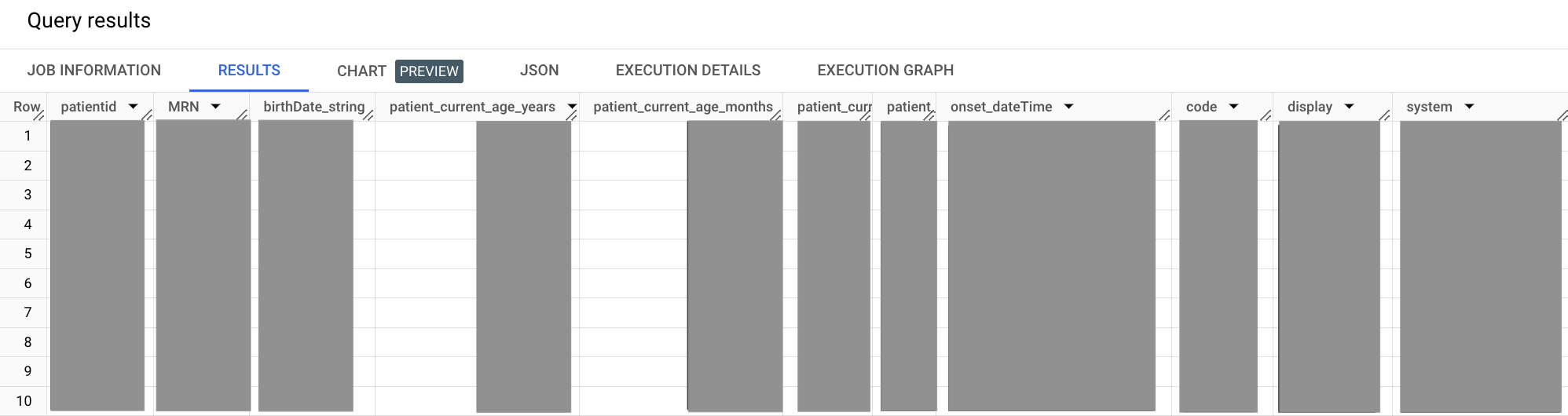
在上述查询中,WITH 子句允许您将子查询隔离为其定义的细分。这种方法有助于提高易读性,而随着查询规模的扩大,此指标会变得越来越重要。在此查询中,将患者和条件的子查询隔离到各自的 WITH 细分中,然后将它们联接在主 SELECT 细分中。
您还可以将计算应用于原始数据。以下示例代码(即 SELECT 语句)展示了如何计算患者在疾病开始时的年龄。
DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset
如前面的代码示例所示,您可以对提供的 dateTime 字符串 condition.onset_dateTime 执行多项操作。首先,使用 SUBSTR 值选择字符串的日期部分。然后,使用 CAST 语法将字符串转换为 DATE 数据类型。您还可以将 patient.birthDate 字段转换为 DATE 字段。最后,使用 DATE_DIFF 函数来计算两个日期之间的差值。
后续步骤
- 使用 BigQuery 和 AI Platform Notebooks 分析临床数据。
- 在 Jupyter 笔记本中直观呈现 BigQuery 数据。
- Cloud Healthcare API 安全。
- BigQuery access control。
- Google Cloud Marketplace 中的医疗保健和生命科学解决方案。
- 探索有关 Google Cloud 的参考架构、图表和最佳做法。查看我们的 Cloud 架构中心。