本文档介绍如何部署导出机制以将日志从 Google Cloud 资源流式传输到 Splunk。本文档假定您已阅读此应用场景的相应参考架构。
以下说明适用于希望将日志从 Google Cloud 流式传输到 Splunk 的运营和安全管理员。在使用 IT 运营或安全应用场景的说明时,您必须熟悉 Splunk 和 Splunk HTTP Event Collector (HEC)。熟悉 Dataflow 流水线、Pub/Sub、Cloud Logging、Identity and Access Management 和 Cloud Storage 并非必需,但这对于此部署很有用。
如需使用基础架构即代码 (IaC) 自动执行此参考架构中的部署步骤,请参阅 terraform-splunk-log-export GitHub 代码库。
架构
下图展示了参考架构,并演示了日志数据如何从 Google Cloud 流向 Splunk。

如图所示,Cloud Logging 将日志收集到组织级层的日志接收器中,并将日志发送到 Pub/Sub。Pub/Sub 服务会为日志创建单个主题和订阅,并将日志转发到 Dataflow 主流水线。主 Dataflow 流水线是一种 Pub/Sub to Splunk 流式流水线,该流水线从 Pub/Sub 订阅中提取日志并将其传送至 Splunk。次要 Dataflow 流水线与 Dataflow 主流水线并行,是 Pub/Sub 到 Pub/Sub 流式传输流水线,用于在传送失败时重放消息。该流程结束时,Splunk Enterprise 或 Splunk Cloud Platform 将充当 HEC 端点,并接收日志以供进一步分析。如需了解详情,请参阅参考架构的架构部分。
如需部署此参考架构,请执行以下任务:
- 执行设置任务。
- 在专用项目中创建聚合日志接收器。
- 创建死信主题。
- 设置 Splunk HEC 端点。
- 配置 Dataflow 流水线容量。
- 将日志导出到 Splunk。
- 在 Splunk Dataflow 流水线中使用用户定义的函数 (UDF) 来转换运行的日志或事件。
- 处理传送失败以避免可能出现的配置错误或暂时性的网络问题。
准备工作
完成以下步骤,为 Google Cloud to Splunk 参考架构设置环境:
启动项目、启用结算功能并激活 API
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Monitoring API, Secret Manager, Compute Engine, Pub/Sub, and Dataflow APIs.
授予 IAM 角色
在 Google Cloud 控制台中,确保您对组织和项目资源具有以下 Identity and Access Management (IAM) 权限。如需了解详情,请参阅授予、更改和撤消对资源的访问权限。
| 权限 | 预定义角色 | 资源 |
|---|---|---|
|
|
组织 |
|
|
项目 |
|
|
项目 |
如果预定义的 IAM 角色没有足够的权限来执行任务,请创建自定义角色。自定义角色可为您提供所需的访问权限,还有助于您符合最小权限原则。
设置您的环境
In the Google Cloud console, activate Cloud Shell.
为您的活跃 Cloud Shell 会话设置项目:
gcloud config set project PROJECT_ID
将
PROJECT_ID替换为您的项目 ID。
设置安全网络
在此步骤中,在处理日志并将其导出到 Splunk Enterprise 之前,请先设置安全网络。
创建 VPC 网络和子网:
gcloud compute networks create NETWORK_NAME --subnet-mode=custom gcloud compute networks subnets create SUBNET_NAME \ --network=NETWORK_NAME \ --region=REGION \ --range=192.168.1.0/24
请替换以下内容:
NETWORK_NAME:您的网络的名称。SUBNET_NAME:您的子网的名称REGION:您要用于此网络的区域
为 Dataflow 工作器虚拟机 (VM) 创建防火墙规则,以便相互通信:
gcloud compute firewall-rules create allow-internal-dataflow \ --network=NETWORK_NAME \ --action=allow \ --direction=ingress \ --target-tags=dataflow \ --source-tags=dataflow \ --priority=0 \ --rules=tcp:12345-12346
此规则允许使用 TCP 端口 12345-12346 的 Dataflow 虚拟机之间的内部流量。此外,Dataflow 服务会设置
dataflow标签。创建 Cloud NAT 网关:
gcloud compute routers create nat-router \ --network=NETWORK_NAME \ --region=REGION gcloud compute routers nats create nat-config \ --router=nat-router \ --nat-custom-subnet-ip-ranges=SUBNET_NAME \ --auto-allocate-nat-external-ips \ --region=REGION
在子网上启用专用 Google 访问通道:
gcloud compute networks subnets update SUBNET_NAME \ --enable-private-ip-google-access \ --region=REGION
创建日志接收器
在本部分中,您将创建组织级日志接收器及其 Pub/Sub 目标位置以及必要的权限。
在 Cloud Shell 中,创建一个 Pub/Sub 主题和关联的订阅作为新的日志接收器目的地:
gcloud pubsub topics create INPUT_TOPIC_NAME gcloud pubsub subscriptions create \ --topic INPUT_TOPIC_NAME INPUT_SUBSCRIPTION_NAME
请替换以下内容:
INPUT_TOPIC_NAME:要用作日志接收器目标位置的 Pub/Sub 主题的名称INPUT_SUBSCRIPTION_NAME:日志接收器目标位置的 Pub/Sub 订阅的名称
创建组织日志接收器:
gcloud logging sinks create ORGANIZATION_SINK_NAME \ pubsub.googleapis.com/projects/PROJECT_ID/topics/INPUT_TOPIC_NAME \ --organization=ORGANIZATION_ID \ --include-children \ --log-filter='NOT logName:projects/PROJECT_ID/logs/dataflow.googleapis.com'
替换以下内容:
ORGANIZATION_SINK_NAME:组织中接收器的名称ORGANIZATION_ID:您的组织 ID。
该命令包含以下标志:
--organization标志指定这是组织级的日志接收器。--include-children标志是必需的,可确保组织级的日志接收器包含所有子文件夹和项目中的所有日志。--log-filter标志指定要路由的日志。在此示例中,您将拥有专门用于项目PROJECT_ID的 Dataflow 操作日志,因为日志导出 Dataflow 流水线时处理日志会生成更多日志。此过滤条件可阻止流水线导出自己的日志,从而避免潜在的指数循环。输出包括o#####-####@gcp-sa-logging.iam.gserviceaccount.com形式的服务账号。
将 Pub/Sub Publisher IAM 角色授予 Pub/Sub 主题
INPUT_TOPIC_NAME中的日志接收器服务账号。 此角色使日志接收器服务账号能够发布有关该主题的消息。gcloud pubsub topics add-iam-policy-binding INPUT_TOPIC_NAME \ --member=serviceAccount:LOG_SINK_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/pubsub.publisher
将
LOG_SINK_SERVICE_ACCOUNT替换为日志接收器的服务账号名称。
创建死信主题
为防止在消息传送失败时丢失数据,您应该创建一个 Pub/Sub 死信主题和相应的订阅。失败的消息会存储在死信主题中,直到操作员或站点可靠性工程师可以调查并纠正失败。如需了解详情,请参阅参考架构的重放失败消息部分。
在 Cloud Shell 中,创建 Pub/Sub 死信主题和订阅,以防止通过存储任何无法传送的消息来丢失数据:
gcloud pubsub topics create DEAD_LETTER_TOPIC_NAME gcloud pubsub subscriptions create --topic DEAD_LETTER_TOPIC_NAME DEAD_LETTER_SUBSCRIPTION_NAME
请替换以下内容:
DEAD_LETTER_TOPIC_NAME:将作为死信主题的 Pub/Sub 主题的名称DEAD_LETTER_SUBSCRIPTION_NAME:死信主题的 Pub/Sub 订阅的名称
设置 Splunk HEC 端点
在以下步骤中,您将设置 Splunk HEC 端点并将新创建的 HEC 令牌作为 Secret 存储在 Secret Manager 中。部署 Splunk Dataflow 流水线时,您需要提供端点网址和令牌。
配置 Splunk HEC
- 如果您还没有 Splunk HEC 端点,请参阅 Splunk 文档,了解如何配置 Splunk HEC。 Splunk HEC 在 Splunk Cloud Platform 服务或您自己的 Splunk Enterprise 实例上运行。
- 在 Splunk 中,创建 Splunk HEC 令牌后,复制令牌值。
- 在 Cloud Shell 中,将 Splunk HEC 令牌值保存在名为
splunk-hec-token-plaintext.txt的临时文件中。
将 Splunk HEC 令牌存储在 Secret Manager 中
在本步骤中,您将创建 Secret 和一个底层 Secret 版本,该版本用于存储 Splunk HEC 令牌值。
在 Cloud Shell 中,创建一个 Secret,使其包含 Splunk HEC 令牌:
gcloud secrets create hec-token \ --replication-policy="automatic"
如需详细了解 Secret 的复制政策,请参阅选择复制政策。
使用文件
splunk-hec-token-plaintext.txt的内容添加令牌作为 Secret 版本:gcloud secrets versions add hec-token \ --data-file="./splunk-hec-token-plaintext.txt"
删除
splunk-hec-token-plaintext.txt文件,因为我们已不再需要它。
配置 Dataflow 流水线容量
下表总结了配置 Dataflow 流水线容量设置的建议一般最佳做法:
| 设置 | 一般最佳做法 |
|---|---|
|
设为基准机器类型大小 |
|
设置为根据计算得出的处理预期峰值 EPS 所需的工作器数量上限 |
|
设置为 2 x vCPU/工作器 x 工作器数量上限,以最大限度地提高并行 Splunk HEC 连接数 |
|
设置为面向日志的 10-50 个事件/请求,前提是可接受最大缓冲延迟时间为两秒 |
在您的环境中部署此参考架构时,请务必使用您自己的唯一值和计算。
设置机器类型和机器数量的值。如需计算适合您的云环境的值,请参阅参考架构的机器类型和机器数量部分。
DATAFLOW_MACHINE_TYPE DATAFLOW_MACHINE_COUNT
设置 Dataflow 并行处理和批次数量的值。如需计算适合您的云环境的值,请参阅参考架构的并行处理和批处理计数部分。
JOB_PARALLELISM JOB_BATCH_COUNT
如需详细了解如何计算 Dataflow 流水线容量参数,请参阅此参考架构的性能和费用优化设计注意事项部分。
使用 Dataflow 流水线导出日志
在本部分中,您将按照以下步骤部署 Dataflow 流水线:
- 创建 Cloud Storage 存储桶和 Dataflow 工作器服务账号。
- 向 Dataflow 工作器服务账号授予角色和访问权限。
- 部署 Dataflow 流水线。
- 查看 Splunk 中的日志。
该流水线将 Google Cloud 日志消息发送到 Splunk HEC。
创建 Cloud Storage 存储桶和 Dataflow 工作器服务账号
在 Cloud Shell 中,创建一个统一的存储桶级访问权限设置的新 Cloud Storage 存储桶:
gsutil mb -b on gs://PROJECT_ID-dataflow/
您刚刚创建的 Cloud Storage 存储桶是 Dataflow 作业暂存临时文件的位置。
在 Cloud Shell 中,为您的 Dataflow 工作器创建服务账号:
gcloud iam service-accounts create WORKER_SERVICE_ACCOUNT \ --description="Worker service account to run Splunk Dataflow jobs" \ --display-name="Splunk Dataflow Worker SA"
将
WORKER_SERVICE_ACCOUNT替换为您要用于 Dataflow 工作器服务账号的名称。
向 Dataflow 工作器服务账号授予角色和访问权限
在本部分中,您将向 Dataflow 工作器服务账号授予所需角色,如下表所示。
| 角色 | 路径 | 用途 |
|---|---|---|
| Dataflow Admin |
|
使服务账号能够充当 Dataflow 管理员。 |
| Dataflow Worker |
|
使服务账号能够充当 Dataflow 工作器。 |
| Storage Object Admin |
|
使服务账号能够访问 Dataflow 用于暂存文件的 Cloud Storage 存储桶。 |
| Pub/Sub Publisher |
|
使服务账号能够将失败消息发布到 Pub/Sub 死信主题。 |
| Pub/Sub Subscriber |
|
使服务账号能够访问输入订阅。 |
| Pub/Sub Viewer |
|
使服务账号能够查看订阅。 |
| Secret Manager Secret Accessor |
|
使服务账号能够访问包含 Splunk HEC 令牌的 Secret。 |
在 Cloud Shell 中,向 Dataflow 工作器服务账号授予此账号执行 Dataflow 作业操作和管理任务所需的 Dataflow Admin 和 Dataflow Worker 角色:
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/dataflow.worker"
授予 Dataflow 工作器服务账号查看和使用 Pub/Sub 输入订阅中的消息的权限:
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.subscriber"
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.viewer"
向 Dataflow 工作器服务账号授予将任何失败消息发布到 Pub/Sub 未处理主题的访问权限:
gcloud pubsub topics add-iam-policy-binding DEAD_LETTER_TOPIC_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.publisher"
向 Dataflow 工作器服务账号授予对 Secret Manager 中的 Splunk HEC 令牌 Secret 的访问权限:
gcloud secrets add-iam-policy-binding hec-token \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/secretmanager.secretAccessor"
向 Dataflow 工作器服务账号授予对 Dataflow 作业将用于暂存文件的 Cloud Storage 存储桶的读写权限:
gcloud storage buckets add-iam-policy-binding gs://PROJECT_ID-dataflow/ \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" --role=”roles/storage.objectAdmin”
部署 Dataflow 流水线
在 Cloud Shell 中,为您的 Splunk HEC 网址设置以下环境变量:
export SPLUNK_HEC_URL=SPLUNK_HEC_URL
使用
protocol://host[:port] 格式替换SPLUNK_HEC_URL变量,其中:protocol是http或https。host是您的 Splunk HEC 实例的完全限定域名 (FQDN) 或 IP 地址,或者,如果您有多个 HEC 实例,则是关联 HTTP(S)(或基于 DNS 的)负载均衡器的 FQDN 或 IP 地址。port是 HEC 端口号。它是可选项,具体取决于您的 Splunk HEC 端点配置。
有效的 Splunk HEC 网址输入示例为
https://splunk-hec.example.com:8088。如果您要将数据发送到 Splunk Cloud Platform 上的 HEC,请参阅将数据发送到 Splunk Cloud 上的 HEC,以确定特定 Splunk HEC 网址的上述host和port部分。Splunk HEC 网址不得包含 HEC 端点路径,例如
/services/collector。Pub/Sub to Splunk Dataflow 模板目前仅支持 JSON 格式事件的/services/collector端点,并且会自动将该路径附加到您的 Splunk HEC 网址输入。如需详细了解该 HEC 端点,请参阅 services/collector 端点的 Splunk 文档。使用 Pub/Sub to Splunk Dataflow 模板部署 Dataflow 流水线:
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --staging-location=gs://PROJECT_ID-dataflow/temp/ \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://splk-public/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
将
JOB_NAME替换为名称格式pubsub-to-splunk-date+"%Y%m%d-%H%M%S"可选参数
javascriptTextTransformGcsPath和javascriptTextTransformFunctionName指定公开提供的示例 UDF:gs://splk-public/js/dataflow_udf_messages_replay.js。示例 UDF 包括可用于重放失败递送的事件转换和解码逻辑的代码示例。如需详细了解 UDF,请参阅使用 UDF 转换运行中的事件。流水线作业完成后,在输出中找到新作业 ID,复制并保存作业 ID。您可以在后续步骤中输入此作业 ID。
查看 Splunk 中的日志
Dataflow 流水线工作器需要几分钟时间完成预配并准备好将日志传送到 Splunk HEC。您可以确认是否已在 Splunk Enterprise 或 Splunk Cloud Platform 搜索界面中正确接收日志并将其编入索引。如需查看每种受监控资源的日志数,请执行以下操作:
在 Splunk 中,打开 Splunk 搜索和报告。
运行搜索
index=[MY_INDEX] | stats count by resource.type,其中为您的 Splunk HEC 令牌配置了MY_INDEX索引: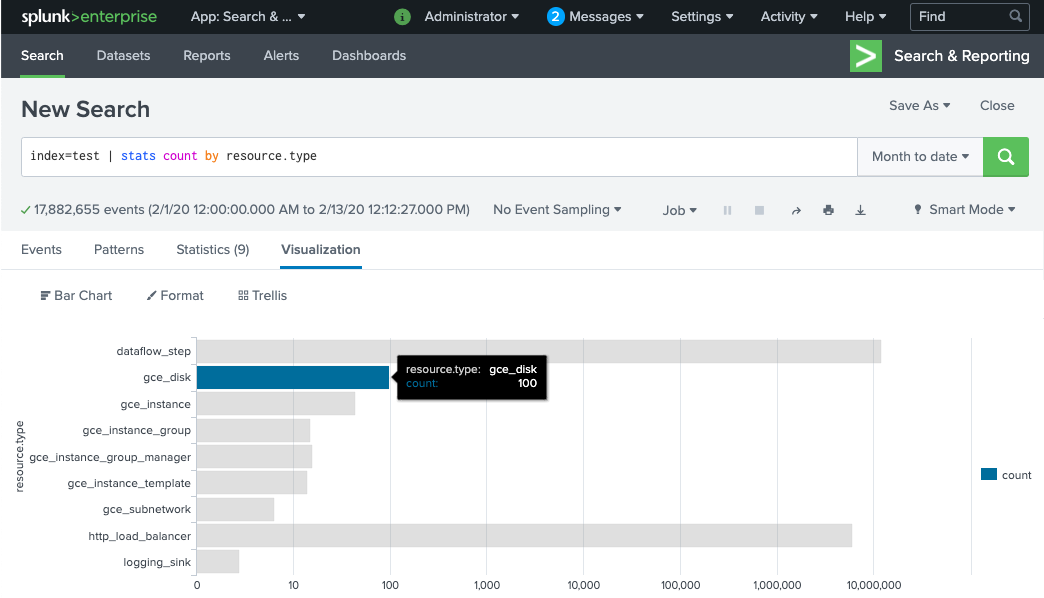
如果您没有看到任何事件,请参阅处理递送失败。
使用 UDF 转换运行中的事件
Pub/Sub to Splunk Dataflow 模板支持用于自定义事件转换的 JavaScript UDF,例如按照事件添加新字段或设置 Splunk HEC 元数据。您部署的流水线使用此示例 UDF。
在本部分中,您首先将修改示例 UDF 函数以添加新的事件字段。这个新字段将原创 Pub/Sub 订阅的值指定为额外的上下文信息。然后,使用修改后的 UDF 更新 Dataflow 流水线。
修改示例 UDF
在 Cloud Shell 中,下载包含示例 UDF 函数的 JavaScript 文件:
wget https://storage.googleapis.com/splk-public/js/dataflow_udf_messages_replay.js
在您选择的文本编辑器中,打开 JavaScript 文件,找到
event.inputSubscription字段,取消备注该行并将splunk-dataflow-pipeline替换为INPUT_SUBSCRIPTION_NAME:event.inputSubscription = "INPUT_SUBSCRIPTION_NAME";
保存文件。
将文件上传到 Cloud Storage 存储桶:
gsutil cp ./dataflow_udf_messages_replay.js gs://PROJECT_ID-dataflow/js/
使用新的 UDF 更新 Dataflow 流水线
在 Cloud Shell 中,使用排空选项停止流水线,以确保从 Pub/Sub 中拉取的日志不会丢失。
gcloud dataflow jobs drain JOB_ID --region=REGION
使用更新后的 UDF 运行 Dataflow 流水线作业。
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://PROJECT_ID-dataflow/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
将
JOB_NAME替换为名称格式pubsub-to-splunk-date+"%Y%m%d-%H%M%S"
处理递送失败
处理失败可能是因为处理事件或连接到 Splunk HEC 出错。在本部分中,您将引入一个递送失败,以演示错误处理工作流。此外,您还将了解如何查看和触发失败的消息传递到 Splunk。
触发递送失败
如需在 Splunk 中手动引入传送失败,请执行以下操作之一:
- 如果您运行单个实例,请停止 Splunk 服务器以导致连接错误。
- 通过 Splunk 输入配置停用相关的 HEC 令牌。
问题排查失败消息
如需调查失败消息,您可以使用 Google Cloud 控制台:
在 Google Cloud 控制台中,转到 Pub/Sub 订阅页面。
点击您创建的未处理的订阅。如果您使用前面的示例,订阅名称为:
projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME。要打开消息查看器,请点击 View Messages。
要查看消息,请点击 Pull,确保已清除 启用确认消息。
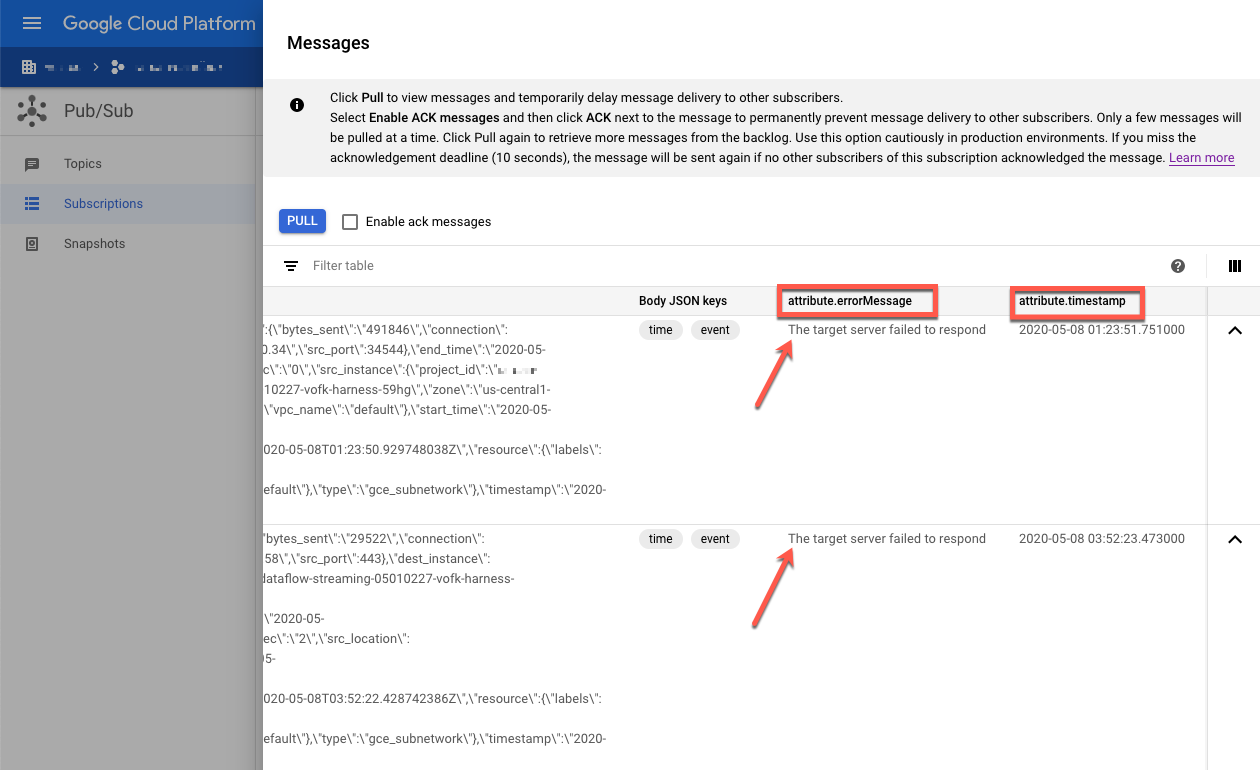
检查失败的消息。请注意以下几点:
Message body列下的 Splunk 事件载荷。attribute.errorMessage列下的错误消息。attribute.timestamp列下的错误时间戳。
以下屏幕截图显示了 Splunk HEC 端点暂时关闭或无法访问时收到的失败消息的示例。请注意,errorMessage 属性的文本显示为 The target server failed to respond。
该消息还会显示与每次失败关联的时间戳。您可以使用此时间戳来排查失败的根本原因。
重放失败消息
在本部分中,您需要重启 Splunk 服务器或启用 Splunk HEC 端点以修复传送错误。然后,您可以重放未处理的消息。
在 Splunk 中,使用以下任一方法恢复与 Google Cloud 的连接:
- 如果您停止了 Splunk 服务器,请重启服务器。
- 如果您在触发递送失败部分中停用了 Splunk HEC 端点,请检查 Splunk HEC 端点现已运行。
在 Cloud Shell 中,先截取未处理订阅的快照,然后再重新处理此订阅中的消息。如果发生意外配置错误,快照可防止消息丢失。
gcloud pubsub snapshots create SNAPSHOT_NAME \ --subscription=DEAD_LETTER_SUBSCRIPTION_NAME
将
SNAPSHOT_NAME替换为可帮助您识别快照的名称,例如dead-letter-snapshot-date+"%Y%m%d-%H%M%S。使用 Pub/Sub to Splunk Dataflow 模板创建 Pub/Sub to Pub/Sub 流水线。流水线使用另一个 Dataflow 作业将消息从未处理的订阅传输回输入主题。
DATAFLOW_INPUT_TOPIC="INPUT_TOPIC_NAME" DATAFLOW_DEADLETTER_SUB="DEAD_LETTER_SUBSCRIPTION_NAME" JOB_NAME=splunk-dataflow-replay-date +"%Y%m%d-%H%M%S" gcloud dataflow jobs run JOB_NAME \ --gcs-location= gs://dataflow-templates/latest/Cloud_PubSub_to_Cloud_PubSub \ --worker-machine-type=n1-standard-2 \ --max-workers=1 \ --region=REGION \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME,\ outputTopic=projects/PROJECT_ID/topics/INPUT_TOPIC_NAME
从命令输出中复制 Dataflow 作业 ID,并保存以备后用。在排空 Dataflow 作业时,您需要输入此作业 ID 作为
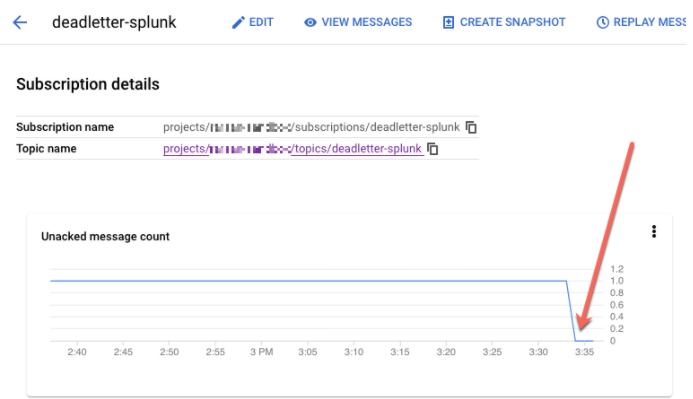
REPLAY_JOB_ID。在 Google Cloud 控制台中,转到 Pub/Sub 订阅页面。
选择未处理的订阅。确认未确认的消息数图表小于 0,如以下屏幕截图所示。
在 Cloud Shell 中,排空您创建的 Dataflow 作业:
gcloud dataflow jobs drain REPLAY_JOB_ID --region=REGION
将
REPLAY_JOB_ID替换为您之前保存的 Dataflow 作业 ID。
当消息迁移回原始输入主题时,主 Dataflow 流水线会自动选取失败的消息并将它们重新递送给 Splunk。
确认 Splunk 中的消息
要确认消息是否已重新递送,请在 Splunk 中打开 Splunk 搜索和报告。
运行搜索
delivery_attempts > 1。该特殊字段中,示例 UDF 会添加到每个事件中以跟踪传送尝试的次数。请务必扩大搜索时间范围,使其包含可能发生的事件,因为事件时间戳是原始创建时间,而不是编入索引时间。
在以下屏幕截图中,最初失败的两条消息现在已成功传递至 Splunk,并具有正确的时间戳。
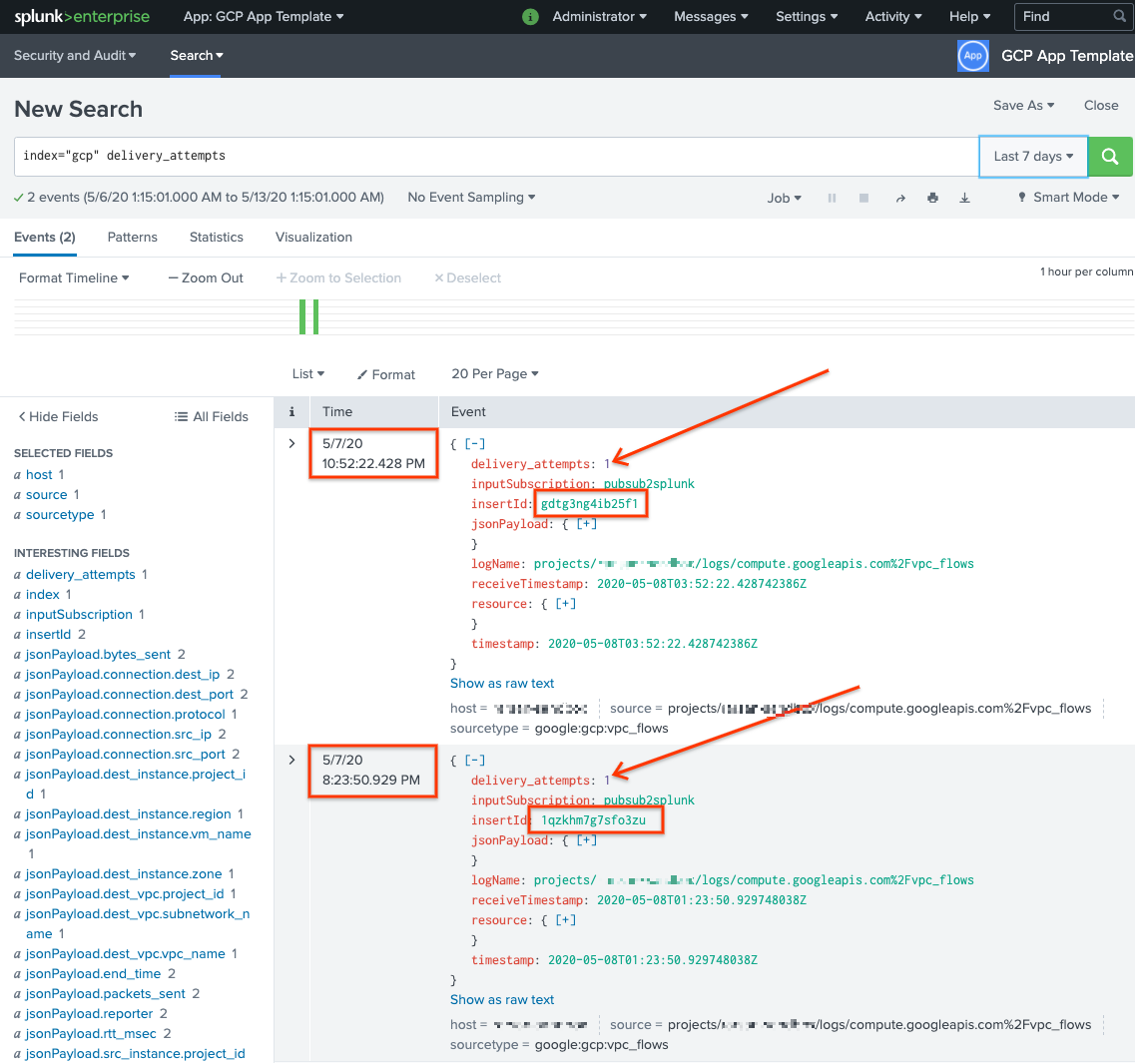
请注意,insertId 字段值与查看未处理的订阅时失败消息中显示的值相同。insertId 字段是 Cloud Logging 分配给原始日志条目的唯一标识符。insertId 也会显示在 Pub/Sub 消息正文中。
清理
为避免因本参考架构中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
删除组织级层的接收器
- 使用以下命令删除组织级层的日志接收器:
gcloud logging sinks delete ORGANIZATION_SINK_NAME --organization=ORGANIZATION_ID
删除项目
删除日志接收器后,您可以继续删除为了接收和导出日志而创建的资源。最简单的方法是删除为参考架构创建的项目。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 如需查看 Pub/Sub to Splunk Dataflow 模板参数的完整列表,请参阅 Pub/Sub to Splunk Dataflow 文档。
- 如需了解可帮助您部署此参考架构的相应 Terraform 模板,请参阅
terraform-splunk-log-exportGitHub 代码库。它包含一个预建的 Cloud Monitoring 信息中心,用于监控 Splunk Dataflow 流水线。 - 如需详细了解 Splunk Dataflow 自定义指标和日志记录(以帮助您监控和排查 Splunk Dataflow 流水线并排查问题),请参阅此博客 Splunk Dataflow 流处理流水线的新可观测性功能。
- 如需查看更多参考架构、图表和最佳实践,请浏览云架构中心。