Dokumen ini menjelaskan cara men-deploy mekanisme ekspor untuk melakukan streaming log dari resourceGoogle Cloud ke Splunk. Hal ini mengasumsikan bahwa Anda telah membaca arsitektur referensi yang sesuai untuk kasus penggunaan ini.
Petunjuk ini ditujukan untuk administrator operasi dan keamanan yang ingin melakukan streaming log dari Google Cloud ke Splunk. Anda harus memahami Splunk dan HTTP Event Collector (HEC) Splunk saat menggunakan petunjuk ini untuk operasi IT atau kasus penggunaan keamanan. Meskipun tidak diwajibkan, pemahaman tentang pipeline Dataflow, Pub/Sub, Cloud Logging, Identity and Access Management, dan Cloud Storage berguna untuk deployment ini.
Untuk mengotomatiskan langkah-langkah deployment dalam arsitektur referensi ini menggunakan
infrastruktur sebagai kode (IaC), lihat
repositori GitHub
terraform-splunk-log-export.
Arsitektur
Diagram berikut menunjukkan arsitektur referensi dan menunjukkan cara data log mengalir dari Google Cloud ke Splunk.

Seperti yang ditunjukkan pada diagram, Cloud Logging mengumpulkan log ke dalam sink log tingkat organisasi dan mengirimkan log tersebut ke Pub/Sub. Layanan Pub/Sub membuat satu topik dan langganan untuk log serta meneruskan log ke pipeline Dataflow utama. Pipeline Dataflow utama adalah pipeline streaming Pub/Sub ke Splunk yang mengambil log dari langganan Pub/Sub dan mengirimkannya ke Splunk. Paralel dengan pipeline Dataflow utama, pipeline Dataflow sekunder adalah pipeline streaming Pub/Sub ke Pub/Sub untuk memutar ulang pesan jika pengiriman gagal. Di akhir proses, Splunk Enterprise atau Splunk Cloud Platform bertindak sebagai endpoint HEC dan menerima log untuk dianalisis lebih lanjut. Untuk detail selengkapnya, lihat bagian Arsitektur dari arsitektur referensi.
Untuk men-deploy arsitektur referensi ini, Anda harus melakukan tugas-tugas berikut:
- Melakukan tugas penyiapan.
- Buat sink log gabungan dalam project khusus.
- Membuat topik yang dihentikan pengirimannya.
- Siapkan endpoint HEC Splunk.
- Konfigurasi kapasitas pipeline Dataflow.
- Ekspor log ke Splunk.
- Transformasikan log atau peristiwa yang sedang berlangsung menggunakan fungsi yang ditentukan pengguna (UDF) dalam pipeline Splunk Dataflow.
- Menangani kegagalan pengiriman untuk menghindari kehilangan data akibat potensi kesalahan konfigurasi atau masalah jaringan yang bersifat sementara.
Sebelum memulai
Selesaikan langkah-langkah berikut guna menyiapkan lingkungan untuk arsitektur referensiGoogle Cloud ke Splunk:
- Siapkan project, aktifkan penagihan, dan aktifkan API.
- Memberikan peran IAM.
- Menyiapkan lingkungan Anda.
- Siapkan jaringan aman.
Memunculkan project, mengaktifkan penagihan, dan mengaktifkan API
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Monitoring API, Secret Manager, Compute Engine, Pub/Sub, and Dataflow APIs.
Memberikan peran IAM
Di konsol Google Cloud, pastikan Anda memiliki izin Identity and Access Management (IAM) berikut untuk resource organisasi dan project. Untuk mengetahui informasi selengkapnya, baca Memberikan, mengubah, dan mencabut akses ke resource.
| Izin | Peran yang telah ditetapkan | Resource |
|---|---|---|
|
|
Organisasi |
|
|
Project |
|
|
Project |
Jika peran IAM yang telah ditetapkan tidak menyertakan izin yang memadai bagi Anda untuk melakukan tugas, buat peran khusus. Peran khusus memberi Anda akses yang dibutuhkan, sekaligus membantu Anda mengikuti prinsip hak istimewa terendah.
Menyiapkan lingkungan Anda
In the Google Cloud console, activate Cloud Shell.
Tetapkan project untuk sesi Cloud Shell Anda yang aktif:
gcloud config set project PROJECT_ID
Ganti
PROJECT_IDdengan project ID Anda.
Menyiapkan jaringan aman
Pada langkah ini, Anda akan menyiapkan jaringan aman sebelum memproses dan mengekspor log ke Splunk Enterprise.
Buat jaringan VPC dan subnet:
gcloud compute networks create NETWORK_NAME --subnet-mode=custom gcloud compute networks subnets create SUBNET_NAME \ --network=NETWORK_NAME \ --region=REGION \ --range=192.168.1.0/24
Ganti kode berikut:
NETWORK_NAME: nama untuk jaringan AndaSUBNET_NAME: nama untuk subnet AndaREGION: region yang ingin Anda gunakan untuk jaringan ini
Buat aturan firewall untuk virtual machine (VM) pekerja Dataflow untuk saling berkomunikasi:
gcloud compute firewall-rules create allow-internal-dataflow \ --network=NETWORK_NAME \ --action=allow \ --direction=ingress \ --target-tags=dataflow \ --source-tags=dataflow \ --priority=0 \ --rules=tcp:12345-12346
Aturan ini memungkinkan traffic internal antara VM Dataflow yang menggunakan port TCP 12345-12346. Selain itu, layanan Dataflow menetapkan tag
dataflow.Buat gateway Cloud NAT:
gcloud compute routers create nat-router \ --network=NETWORK_NAME \ --region=REGION gcloud compute routers nats create nat-config \ --router=nat-router \ --nat-custom-subnet-ip-ranges=SUBNET_NAME \ --auto-allocate-nat-external-ips \ --region=REGION
Mengaktifkan Akses Google Pribadi di subnet
gcloud compute networks subnets update SUBNET_NAME \ --enable-private-ip-google-access \ --region=REGION
Membuat log sink
Di bagian ini, Anda akan membuat sink log di seluruh organisasi dan tujuan Pub/Sub-nya, beserta izin yang diperlukan.
Di Cloud Shell, buat topik Pub/Sub dan langganan terkait sebagai tujuan sink log baru Anda:
gcloud pubsub topics create INPUT_TOPIC_NAME gcloud pubsub subscriptions create \ --topic INPUT_TOPIC_NAME INPUT_SUBSCRIPTION_NAME
Ganti kode berikut:
INPUT_TOPIC_NAME: nama untuk topik Pub/Sub yang akan digunakan sebagai tujuan sink logINPUT_SUBSCRIPTION_NAME: nama untuk langganan Pub/Sub ke tujuan sink log
Buat sink log organisasi:
gcloud logging sinks create ORGANIZATION_SINK_NAME \ pubsub.googleapis.com/projects/PROJECT_ID/topics/INPUT_TOPIC_NAME \ --organization=ORGANIZATION_ID \ --include-children \ --log-filter='NOT logName:projects/PROJECT_ID/logs/dataflow.googleapis.com'
Ganti kode berikut:
ORGANIZATION_SINK_NAME: nama sink Anda di organisasiORGANIZATION_ID: ID organisasi Anda
Perintah ini terdiri dari flag berikut:
- Flag
--organizationmenentukan bahwa ini adalah sink log tingkat organisasi. - Flag
--include-childrendiperlukan dan memastikan bahwa sink log tingkat organisasi menyertakan semua log di semua subfolder dan project. - Flag
--log-filtermenentukan log yang akan dirutekan. Dalam contoh ini, Anda mengecualikan log operasi Dataflow secara khusus untuk projectPROJECT_ID, karena pipeline Dataflow ekspor log menghasilkan lebih banyak log sendiri saat memproses log. Filter mencegah pipeline mengekspor log-nya sendiri, sehingga menghindari siklus yang berpotensi eksponensial. Output-nya mencakup akun layanan dalam bentuko#####-####@gcp-sa-logging..
Berikan peran IAM Pub/Sub Publisher ke akun layanan sink log pada topik Pub/Sub
INPUT_TOPIC_NAME. Peran ini memungkinkan akun layanan sink log memublikasikan pesan pada topik tersebut.gcloud pubsub topics add-iam-policy-binding INPUT_TOPIC_NAME \ --member=serviceAccount:LOG_SINK_SERVICE_ACCOUNT@PROJECT_ID. \ --role=roles/pubsub.publisher
Ganti
LOG_SINK_SERVICE_ACCOUNTdengan nama akun layanan untuk sink log Anda.
Membuat topik yang dihentikan peng irimannya
Untuk mencegah potensi kehilangan data yang terjadi saat pesan gagal dikirim, Anda harus membuat topik yang dihentikan pengirimannya dan langganan yang sesuai untuk Pub/Sub. Pesan yang gagal akan disimpan dalam topik yang dihentikan pengirimannya hingga operator atau engineer keandalan situs dapat menyelidiki dan memperbaiki kegagalan tersebut. Untuk informasi selengkapnya, lihat bagian Mengulang pesan yang gagal dalam arsitektur referensi.
Di Cloud Shell, buat topik dan langganan Pub/Sub yang dihentikan pengirimannya untuk mencegah kehilangan data dengan menyimpan pesan yang tidak terkirim:
gcloud pubsub topics create DEAD_LETTER_TOPIC_NAME gcloud pubsub subscriptions create --topic DEAD_LETTER_TOPIC_NAME DEAD_LETTER_SUBSCRIPTION_NAME
Ganti kode berikut:
DEAD_LETTER_TOPIC_NAME: nama untuk topik Pub/Sub yang akan menjadi topik yang dihentikan pengirimannyaDEAD_LETTER_SUBSCRIPTION_NAME: nama langganan Pub/Sub untuk topik yang dihentikan pengirimannya
Menyiapkan endpoint Splunk HEC
Dalam prosedur berikut, Anda akan menyiapkan endpoint Splunk HEC dan menyimpan token HEC yang baru dibuat sebagai rahasia di Secret Manager. Saat men-deploy pipeline Dataflow Splunk, Anda harus menyediakan URL endpoint dan token.
Mengonfigurasi HEC Splunk
- Jika Anda belum memiliki endpoint Splunk HEC, lihat dokumentasi Splunk untuk mempelajari cara mengonfigurasi HEC Splunk. HEC Splunk berjalan di layanan Cloud Platform Splunk atau di instance Splunk Enterprise Anda sendiri. Tetap nonaktifkan opsi Konfirmasi Pengindeksan HEC Splunk, karena tidak didukung oleh Splunk Dataflow.
- Di Splunk, setelah Anda membuat token Splunk HEC, salin nilai token.
- Di Cloud Shell, simpan nilai token HEC Splunk dalam file sementara yang bernama
splunk-hec-token-plaintext.txt.
Simpan token Splunk HEC di Secret Manager
Pada langkah ini, Anda akan membuat rahasia dan satu versi rahasia yang mendasarinya untuk menyimpan nilai token Splunk HEC.
Di Cloud Shell, buat rahasia untuk memuat token Splunk HEC Anda:
gcloud secrets create hec-token \ --replication-policy="automatic"
Untuk mengetahui informasi selengkapnya tentang kebijakan replikasi untuk secret, lihat Memilih kebijakan replikasi.
Tambahkan token sebagai versi secret menggunakan konten file
splunk-hec-token-plaintext.txt:gcloud secrets versions add hec-token \ --data-file="./splunk-hec-token-plaintext.txt"
Hapus file
splunk-hec-token-plaintext.txt, karena tidak diperlukan lagi.
Mengonfigurasi kapasitas pipeline Dataflow
Tabel berikut merangkum praktik terbaik umum yang direkomendasikan untuk mengonfigurasi setelan kapasitas pipeline Dataflow:
| Setelan | Praktik terbaik umum |
|---|---|
Flag |
Tetapkan ke ukuran mesin dasar |
Flag |
Tetapkan ke jumlah maksimum pekerja yang diperlukan untuk menangani perkiraan EPS puncak per penghitungan Anda |
Parameter |
Tetapkan ke 2 x vCPU/pekerja x jumlah maksimum pekerja untuk memaksimalkan jumlah koneksi HEC Splunk paralel |
|
Tetapkan ke 10-50 peristiwa/permintaan untuk log, asalkan penundaan buffering maksimum dua detik dapat diterima |
Ingatlah untuk menggunakan nilai dan perhitungan unik Anda sendiri saat men-deploy arsitektur referensi ini di lingkungan Anda.
Tetapkan nilai untuk jenis mesin dan jumlah mesin. Untuk menghitung nilai yang sesuai dengan lingkungan cloud Anda, lihat bagian Jenis mesin dan Jumlah mesin dalam arsitektur referensi.
DATAFLOW_MACHINE_TYPE DATAFLOW_MACHINE_COUNT
Tetapkan nilai untuk paralelisme dan jumlah batch Dataflow. Untuk menghitung nilai yang sesuai dengan lingkungan cloud Anda, lihat bagian Paralelisme dan Jumlah batch dari arsitektur referensi.
JOB_PARALLELISM JOB_BATCH_COUNT
Untuk mengetahui informasi selengkapnya tentang cara menghitung parameter kapasitas pipeline Dataflow, lihat bagian Pertimbangan desain pengoptimalan biaya dan performa dalam arsitektur referensi.
Mengekspor log dengan menggunakan pipeline Dataflow
Di bagian ini, Anda akan men-deploy pipeline Dataflow dengan langkah-langkah berikut:
- Buat bucket Cloud Storage dan akun layanan pekerja Dataflow.
- Memberikan peran dan akses ke akun layanan pekerja Dataflow.
- Deploy pipeline Dataflow.
- Lihat log di Splunk.
Pipeline ini mengirimkan Google Cloud pesan log ke Splunk HEC.
Membuat bucket Cloud Storage dan akun layanan pekerja Dataflow
Di Cloud Shell, buat bucket Cloud Storage baru dengan setelan akse s lvel bucket seragam:
gcloud storage buckets create gs://PROJECT_ID-dataflow/ --uniform-bucket-level-access
Bucket Cloud Storage yang baru saja Anda buat adalah tempat tugas Dataflow membuat file sementara.
Di Cloud Shell, buat akun layanan untuk pekerja Dataflow:
gcloud iam service-accounts create WORKER_SERVICE_ACCOUNT \ --description="Worker service account to run Splunk Dataflow jobs" \ --display-name="Splunk Dataflow Worker SA"
Ganti
WORKER_SERVICE_ACCOUNTdengan nama yang ingin Anda gunakan untuk akun layanan pekerja Dataflow.
Memberikan peran dan akses ke akun layanan pekerja Dataflow
Di bagian ini, berikan peran yang diperlukan ke akun layanan pekerja Dataflow seperti yang ditunjukkan pada tabel berikut.
| Peran | Jalur | Tujuan |
|---|---|---|
| Dataflow Admin |
|
Aktifkan akun layanan untuk bertindak sebagai admin Dataflow. |
| Dataflow Worker |
|
Aktifkan akun layanan untuk bertindak sebagai pekerja Dataflow. |
| Storage Object Admin |
|
Aktifkan akun layanan untuk mengakses bucket Cloud Storage yang digunakan oleh Dataflow untuk file staging. |
| Pub/Sub Publisher |
|
Aktifkan akun layanan untuk memublikasikan pesan yang gagal ke topik Pub/Sub yang dihentikan pengirimannya. |
| Pub/Sub Subscriber |
|
Aktifkan akun layanan untuk mengakses langganan input. |
| Pub/Sub Viewer |
|
Aktifkan akun layanan untuk melihat langganan. |
| Secret Manager Secret Accessor. |
|
Aktifkan akun layanan untuk mengakses secret yang berisi token HEC Splunk. |
Di Cloud Shell, berikan peran Admin Dataflow dan Pekerja Dataflow ke akun layanan pekerja Dataflow yang diperlukan akun ini untuk menyetujui operasi tugas dan tugas administrasi Dataflow:
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID." \ --role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID." \ --role="roles/dataflow.worker"
Beri akun layanan pekerja Dataflow untuk melihat dan menggunakan pesan dari langganan input Pub/Sub:
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID." \ --role="roles/pubsub.subscriber"
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID." \ --role="roles/pubsub.viewer"
Beri akun layanan pekerja Dataflow untuk memublikasikan pesan yang gagal ke topik Pub/Sub yang belum diproses:
gcloud pubsub topics add-iam-policy-binding DEAD_LETTER_TOPIC_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID." \ --role="roles/pubsub.publisher"
Beri akun layanan pekerja Dataflow akses ke rahasia token Splunk HEC di Secret Manager:
gcloud secrets add-iam-policy-binding hec-token \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID." \ --role="roles/secretmanager.secretAccessor"
Beri akun layanan pekerja Dataflow akses baca dan tulis ke bucket Cloud Storage untuk digunakan oleh tugas Dataflow untuk file staging:
gcloud storage buckets add-iam-policy-binding gs://PROJECT_ID-dataflow/ \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID." --role=”roles/storage.objectAdmin”
Men-deploy pipeline Dataflow
Di Cloud Shell, tetapkan variabel lingkungan berikut untuk URL Splunk HEC Anda:
export SPLUNK_HEC_URL=SPLUNK_HEC_URL
Ganti variabel
SPLUNK_HEC_URLmenggunakan bentukprotocol://host[:port], dengan:protocoladalahhttpatauhttps.hostadalah nama domain yang sepenuhnya memenuhi syarat (FQDN) atau alamat IP dari instance Splunk HEC Anda, atau, jika Anda memiliki beberapa instance HEC, instance Load Balancer HTTP(S) (atau berbasis DNS).portadalah nomor port HEC. Hal ini bersifat opsional, dan bergantung pada konfigurasi endpoint HEC Splunk Anda.
Contoh input URL HEC Splunk yang valid adalah
https://splunk-hec.example.com:8088. Jika Anda mengirim data ke HEC di Cloud Platform Splunk, lihat Mengirim data ke HEC di Cloud Splunk untuk menentukan bagianhostdanportdi atas URL spesifik Splunk HEC Anda.URL HEC Splunk tidak boleh menyertakan jalur endpoint HEC, misalnya,
/services/collector. Template Pub/Sub ke Dataflow Splunk saat ini hanya mendukung endpoint/services/collectoruntuk peristiwa berformat JSON, dan otomatis menambahkan jalur tersebut ke input URL Splunk HEC Anda. Untuk mempelajari endpoint HEC lebih lanjut, lihat dokumentasi Splunk untuk endpoint layanan/kolektor.Deploy pipeline Dataflow menggunakan template Pub/Sub ke Splunk Dataflow:
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --staging-location=gs://PROJECT_ID-dataflow/temp/ \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://splk-public/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
Ganti
JOB_NAMEdengan format namapubsub-to-splunk-date+"%Y%m%d-%H%M%S"Parameter opsional
javascriptTextTransformGcsPathdanjavascriptTextTransformFunctionNamemenentukan contoh UDF yang tersedia untuk publik:gs://splk-public/js/dataflow_udf_messages_replay.js. Contoh UDF menyertakan contoh kode untuk logika decoding dan transformasi peristiwa yang Anda gunakan untuk memutar ulang pengiriman yang gagal. Untuk mengetahui informasi selengkapnya tentang UDF, lihat Mentransformasi peristiwa yang berlangsung dengan UDF.Setelah tugas pipeline selesai, temukan ID tugas baru di output, salin ID tugas, lalu simpan. Anda memasukkan ID pekerjaan ini di langkah berikutnya.
Lihat log di Splunk
Pekerja pipeline Dataflow memerlukan waktu beberapa menit untuk disediakan dan siap mengirim log ke Splunk HEC. Anda dapat mengonfirmasi bahwa log diterima dan diindeks dengan benar di antarmuka penelusuran Splunk Enterprise atau Splunk Cloud Platform. Untuk melihat jumlah log per jenis resource yang dimonitor:
Di Splunk, buka Splunk Search & Reporting.
Jalankan penelusuran
index=[MY_INDEX] | stats count by resource.typetempat indeksMY_INDEXdikonfigurasi untuk token Splunk HEC Anda: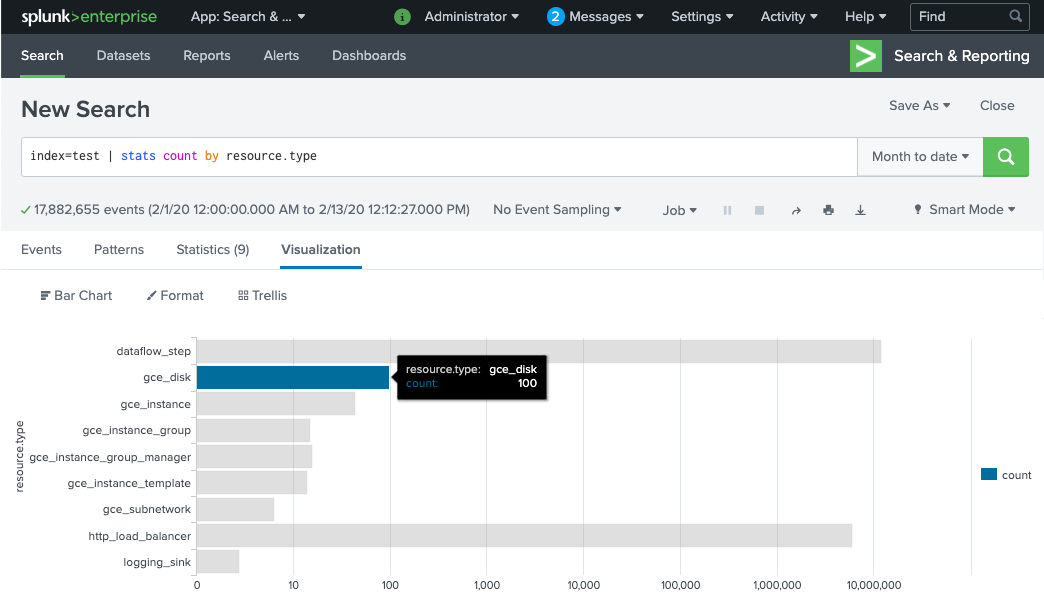
Jika Anda tidak melihat peristiwa apa pun, lihat Menangani kegagalan pengiriman.
Mengubah peristiwa yang sedang berlangsung dengan UDF
Template Pub/Sub ke Splunk Dataflow mendukung UDF JavaScript untuk transformasi peristiwa kustom, seperti menambahkan kolom baru atau menetapkan metadata Splunk HEC berdasarkan peristiwa. Pipeline yang Anda deploy menggunakan UDF contoh ini.
Di bagian ini, Anda akan mengedit contoh fungsi UDF terlebih dahulu untuk menambahkan kolom peristiwa baru. Kolom baru ini menentukan nilai langganan Pub/Sub asal sebagai informasi kontekstual tambahan. Kemudian, Anda memperbarui pipeline Dataflow dengan UDF yang dimodifikasi.
Mengubah contoh UDF
Di Cloud Shell, download file JavaScript yang berisi contoh fungsi UDF:
wget https://storage.googleapis.com/splk-public/js/dataflow_udf_messages_replay.js
Di editor teks pilihan Anda, buka file JavaScript, temukan kolom
event.inputSubscription, hapus tanda komentar di baris tersebut, lalu gantisplunk-dataflow-pipelinedenganINPUT_SUBSCRIPTION_NAME:event.inputSubscription = "INPUT_SUBSCRIPTION_NAME";
Simpan file.
upload file ke bucket Cloud Storage.
gcloud storage cp ./dataflow_udf_messages_replay.js gs://PROJECT_ID-dataflow/js/
Mengupdate pipeline Dataflow dengan UDF baru
Di Cloud Shell, hentikan pipeline menggunakan opsi Drain untuk memastikan bahwa log yang telah diambil dari Pub/Sub tidak hilang:
gcloud dataflow jobs drain JOB_ID --region=REGION
Jalankan tugas pipeline Dataflow dengan UDF yang telah diperbarui.
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://PROJECT_ID-dataflow/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
Ganti
JOB_NAMEdengan format namapubsub-to-splunk-date+"%Y%m%d-%H%M%S"
Menangani kegagalan pengiriman
Kegagalan pengiriman dapat terjadi karena terjadi error saat memproses peristiwa atau menghubungkan ke HEC Splunk. Di bagian ini, Anda memperkenalkan kegagalan pengiriman untuk menunjukkan alur kerja penanganan error. Anda juga akan mempelajari cara melihat dan memicu pengiriman ulang pesan yang gagal ke Splunk.
Memicu kegagalan pengiriman
Untuk menyebabkan kegagalan pengiriman secara manual di Splunk, lakukan salah satu hal berikut:
- Jika Anda menjalankan satu instance, hentikan server Splunk agar error koneksi.
- Nonaktifkan token HEC yang relevan dari konfigurasi input Splunk Anda.
Memecahkan masalah pesan yang gagal
Untuk menyelidiki pesan yang gagal, Anda dapat menggunakan Google Cloud Console:
Di Google Cloud Console, buka halaman Pub/Sub Subscriptions.
Klik langganan yang belum diproses dan Anda buat. Jika Anda menggunakan contoh sebelumnya, nama langganan adalah:
projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME.Untuk membuka penampil pesan, klik Lihat Pesan.
Untuk melihat pesan, klik Pull. Pastikan opsi Enable ack messages tetap dihapus.
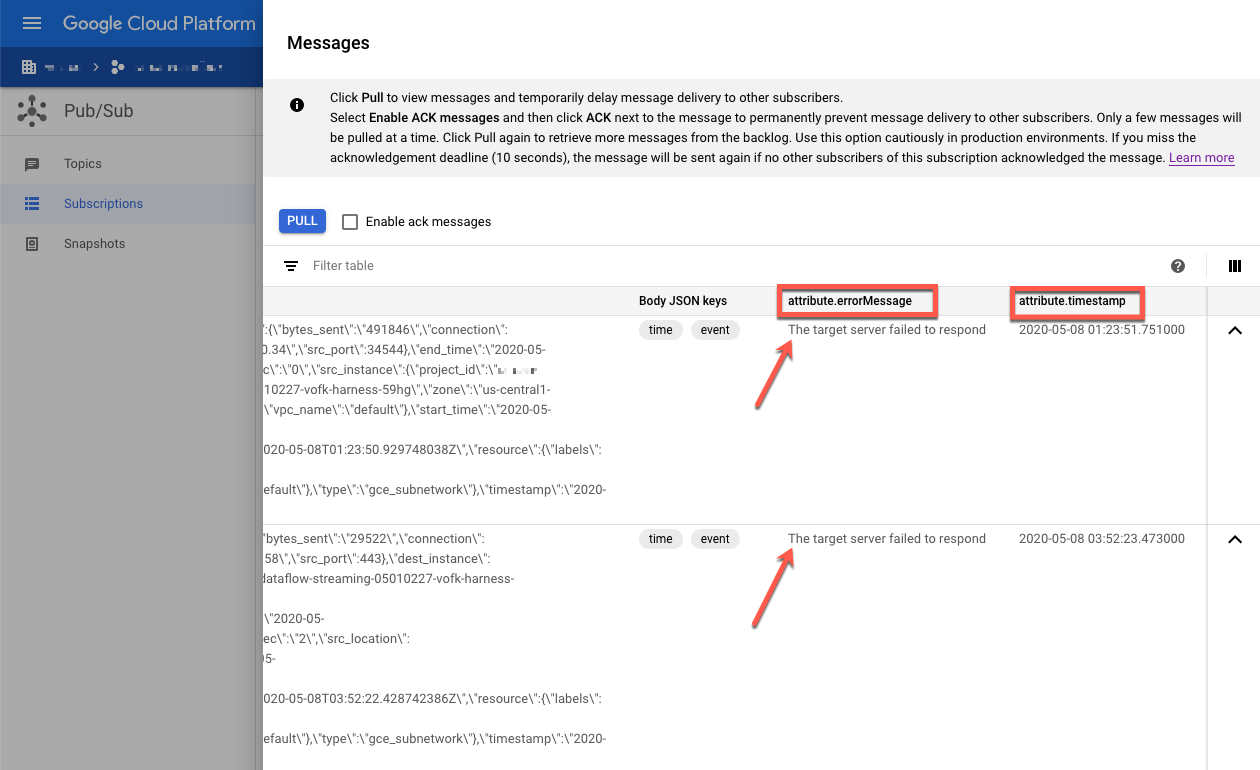
Periksa pesan yang gagal. Perhatikan hal-hal berikut:
- Payload peristiwa Splunk di bagian kolom
Message body. - Pesan error pada kolom
attribute.errorMessage. - Stempel waktu error di bagian kolom
attribute.timestamp.
- Payload peristiwa Splunk di bagian kolom
Screenshot berikut menunjukkan contoh pesan kegagalan yang Anda terima
jika endpoint Splunk HEC sedang tidak aktif untuk sementara atau tidak dapat dijangkau. Perhatikan bahwa
teks atribut errorMessage membaca The target server failed to respond.
Pesan ini juga menunjukkan stempel waktu yang terkait dengan setiap kegagalan. Anda
dapat menggunakan stempel waktu ini untuk memecahkan masalah utama kegagalan.
Putar ulang pesan yang gagal
Di bagian ini, Anda harus memulai ulang server Splunk atau mengaktifkan endpoint HEC Splunk untuk memperbaiki error pengiriman. Anda kemudian dapat memutar ulang pesan yang belum diproses.
Di Splunk, gunakan salah satu metode berikut untuk memulihkan koneksi keGoogle Cloud:
- Jika Anda menghentikan server Splunk, mulai ulang server.
- Jika Anda menonaktifkan endpoint Splunk HEC di bagian Memicu kegagalan pengiriman, pastikan endpoint Splunk HEC saat ini telah beroperasi.
Di Cloud Shell, ambil snapshot langganan yang belum diproses sebelum memproses ulang pesan dalam langganan ini. Snapshot mencegah hilangnya pesan jika terjadi error konfigurasi yang tidak terduga.
gcloud pubsub snapshots create SNAPSHOT_NAME \ --subscription=DEAD_LETTER_SUBSCRIPTION_NAME
Ganti
SNAPSHOT_NAMEdengan nama yang memudahkan Anda mengidentifikasi snapshot, sepertidead-letter-snapshot-date+"%Y%m%d-%H%M%S.Gunakan template Pub/Sub ke Dataflow Splunk untuk membuat pipeline Pub/Sub ke Pub/Sub. Pipeline menggunakan tugas Dataflow lain untuk mentransfer pesan dari langganan yang belum diproses kembali ke topik input.
DATAFLOW_INPUT_TOPIC="INPUT_TOPIC_NAME" DATAFLOW_DEADLETTER_SUB="DEAD_LETTER_SUBSCRIPTION_NAME" JOB_NAME=splunk-dataflow-replay-date +"%Y%m%d-%H%M%S" gcloud dataflow jobs run JOB_NAME \ --gcs-location= gs://dataflow-templates/latest/Cloud_PubSub_to_Cloud_PubSub \ --worker-machine-type=n2-standard-2 \ --max-workers=1 \ --region=REGION \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME,\ outputTopic=projects/PROJECT_ID/topics/INPUT_TOPIC_NAME
Salin ID tugas Dataflow dari output perintah dan simpan untuk nanti. Anda akan memasukkan ID tugas ini sebagai
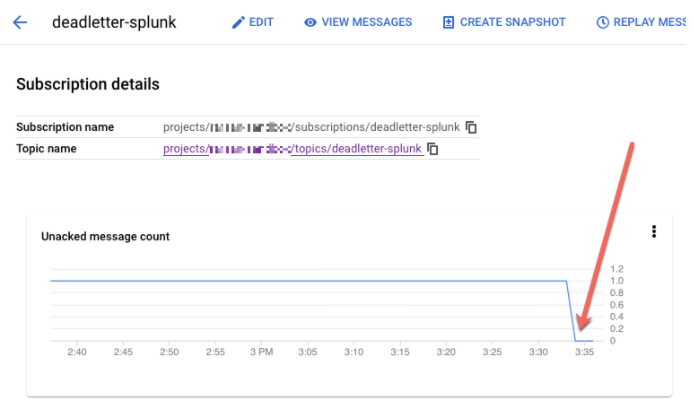
REPLAY_JOB_IDsaat menghabiskan tugas Dataflow.Di Google Cloud Console, buka halaman Pub/Sub Subscriptions.
Pilih langganan yang belum diproses. Pastikan grafik Jumlah pesan yang tidak dikonfirmasi diturunkan ke 0, seperti yang ditunjukkan pada screenshot berikut.
Di Cloud Shell, selesaikan tugas Dataflow yang Anda buat:
gcloud dataflow jobs drain REPLAY_JOB_ID --region=REGION
Ganti
REPLAY_JOB_IDdengan ID tugas Dataflow yang Anda simpan sebelumnya.
Saat pesan ditransfer kembali ke topik input asli, pipeline Dataflow utama akan otomatis mengambil pesan yang gagal dan mengirimkannya kembali ke Splunk.
Mengonfirmasi pesan di Splunk
Untuk mengonfirmasi bahwa pesan telah dikirim ulang, di Splunk, buka Splunk Search & Reporting.
Jalankan penelusuran untuk
delivery_attempts > 1. Ini adalah kolom khusus yang ditambahkan oleh contoh UDF ke setiap peristiwa untuk melacak jumlah upaya pengiriman. Pastikan untuk memperluas rentang waktu penelusuran untuk menyertakan peristiwa yang mungkin telah terjadi di masa lalu, karena stempel waktu peristiwa adalah waktu asli pembuatan, bukan waktu pengindeksan.
Dalam screenshot berikut, dua pesan yang awalnya gagal kini berhasil dikirim dan diindeks di Splunk dengan stempel waktu yang benar.
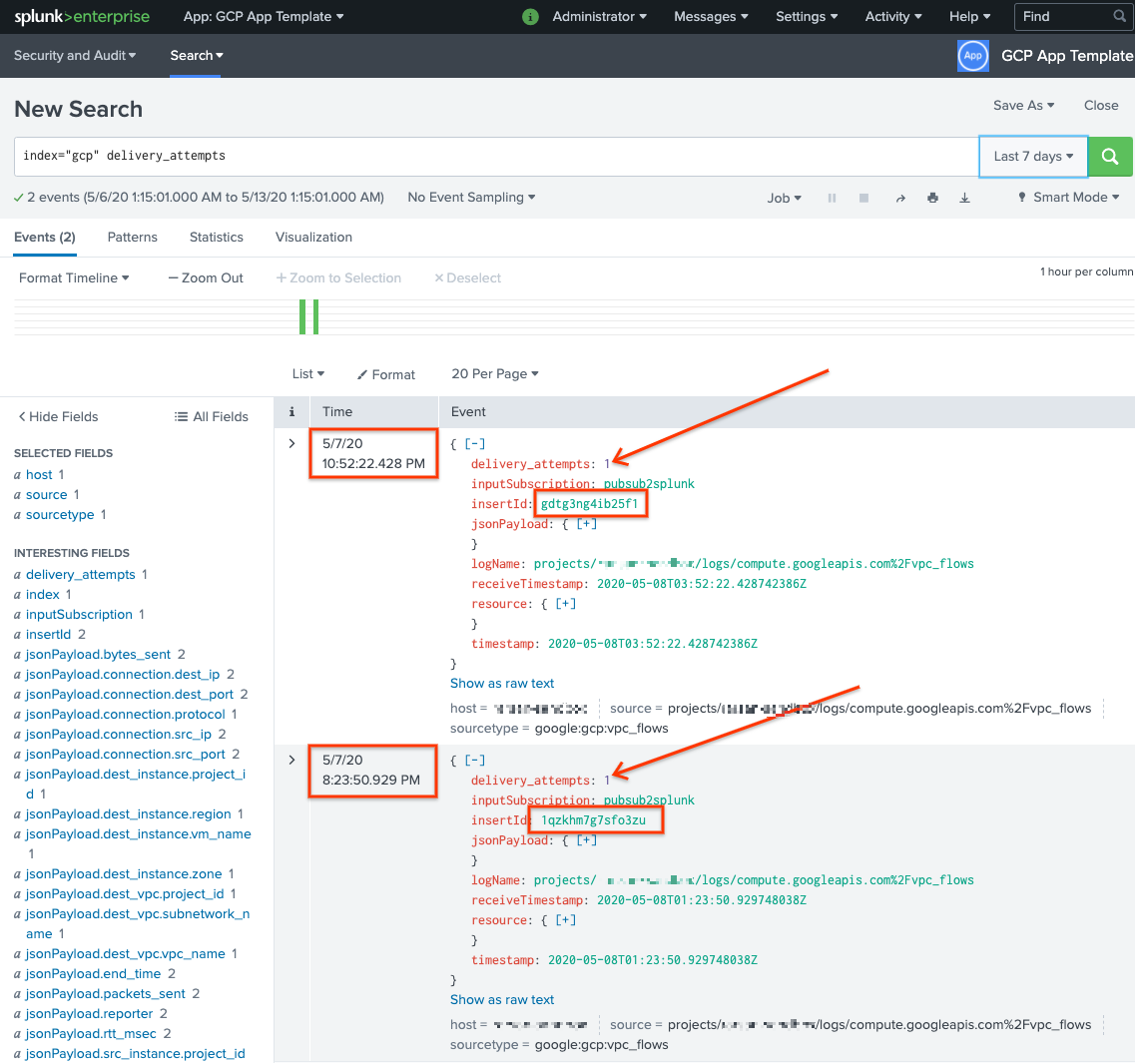
Perhatikan bahwa nilai kolom insertId sama dengan nilai yang muncul dalam pesan yang gagal saat Anda melihat langganan yang belum diproses.
Kolom insertId adalah ID unik yang ditetapkan Cloud Logging ke entri log asli. insertId juga muncul dalam isi pesan
Pub/Sub.
Pembersihan
Agar tidak dikenai biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam arsitektur referensi ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus setiap resource.
Menghapus sink tingkat organisasi
- Gunakan perintah berikut untuk menghapus sink log tingkat organisasi:
gcloud logging sinks delete ORGANIZATION_SINK_NAME --organization=ORGANIZATION_ID
Menghapus project
Setelah sink log dihapus, Anda dapat melanjutkan penghapusan resource yang dibuat untuk menerima dan mengekspor log. Cara termudah adalah menghapus project yang Anda buat untuk arsitektur referensi.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Langkah selanjutnya
- Untuk mengetahui daftar lengkap parameter template Pub/Sub ke Dataflow Splunk, baca dokumentasi Pub/Sub ke Dataflow Splunk.
- Untuk mengetahui template Terraform yang sesuai guna membantu Anda men-deploy arsitektur referensi ini, lihat repositori GitHub
terraform-splunk-log-export. Rilis ini mencakup dasbor Cloud Monitoring bawaan untuk memantau pipeline Splunk Dataflow Anda. - Untuk mengetahui detail selengkapnya tentang logging dan metrik kustom Splunk Dataflow untuk membantu Anda memantau dan memecahkan masalah pipeline Dataflow Splunk, lihat blog iniFitur kemampuan observasi baru untuk pipeline streaming Splunk Dataflow Anda singkat ini.
- Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.