Dokumen ini menjelaskan arsitektur referensi yang membantu Anda membuat mekanisme ekspor log yang siap produksi, skalabel, fault-tolerant, dan dapat mengalirkan log serta peristiwa dari resource Anda di Google Cloud ke Splunk. Splunk adalah alat analisis populer yang menawarkan platform keamanan dan kemampuan observasi terpadu. Bahkan, Anda memiliki pilihan untuk mengekspor data logging ke Splunk Enterprise atau Splunk Cloud Platform. Jika Anda seorang administrator, Anda juga dapat menggunakan arsitektur ini untuk operasi IT atau kasus penggunaan keamanan.
Arsitektur referensi ini mengasumsikan hierarki resource yang mirip dengan diagram berikut. Semua Google Cloud log resource dari level organisasi, folder, dan project dikumpulkan ke dalam sink gabungan. Kemudian, sink gabungan mengirimkan log ini ke pipeline ekspor log, yang memproses log dan mengekspornya ke Splunk.

Arsitektur
Diagram berikut menunjukkan arsitektur referensi yang Anda gunakan saat men-deploy solusi ini. Diagram ini menunjukkan cara data log mengalir dariGoogle Cloud ke Splunk.

Arsitektur ini mencakup komponen berikut:
- Cloud Logging: Untuk memulai prosesnya, Cloud Logging mengumpulkan log ke dalam sink log gabungan tingkat organisasi dan mengirimkan log tersebut ke Pub/Sub.
- Pub/Sub: Layanan Pub/Sub kemudian membuat satu topik dan langganan untuk log dan meneruskan log ke pipeline Dataflow utama.
- Dataflow: Ada dua
pipeline Dataflow dalam arsitektur referensi ini:
- Pipeline Dataflow utama: Di pusat proses, pipeline Dataflow utama adalah pipeline streaming Pub/Sub ke Splunk yang mengambil log dari langganan Pub/Sub dan mengirimkannya ke Splunk.
- Pipeline Dataflow sekunder: Paralel dengan pipeline Dataflow utama, pipeline Dataflow sekunder adalah pipeline streaming Pub/Sub ke Pub/Sub untuk memutar ulang pesan jika pengiriman gagal.
- Splunk: Pada akhir proses, Splunk Enterprise atau Splunk Cloud Platform bertindak sebagai HTTP Event Collector (HEC) dan menerima log untuk analisis lebih lanjut. Anda dapat men-deploy Splunk secara lokal, di Google Cloud sebagai SaaS, atau melalui pendekatan hybrid.
Kasus penggunaan
Arsitektur referensi ini menggunakan pendekatan berbasis cloud dan push. Dalam metode berbasis push ini, Anda menggunakan template Pub/Sub ke Splunk Dataflow untuk streaming log ke HTTP Event Collector (HEC) Splunk. Arsitektur referensi juga membahas perencanaan kapasitas pipeline Dataflow dan cara menangani potensi kegagalan pengiriman saat ada masalah server atau jaringan sementara.
Meskipun arsitektur referensi ini berfokus pada log Google Cloud , arsitektur yang sama dapat digunakan untuk mengekspor data Google Cloud lainnya, seperti perubahan aset real-time dan temuan keamanan. Dengan mengintegrasikan log dari Cloud Logging, Anda dapat terus menggunakan layanan partner yang ada, seperti Splunk sebagai solusi analisis log terpadu.
Metode berbasis push untuk melakukan streaming data Google Cloud ke Splunk memiliki keunggulan berikut:
- Layanan terkelola. Sebagai layanan terkelola, Dataflow mengelola resource yang diperlukan di Google Cloud untuk tugas pemrosesan data seperti ekspor log.
- Workload terdistribusi. Metode ini memungkinkan Anda mendistribusikan workload ke beberapa worker wuntuk pemrosesan paralel sehingga tidak ada titik tunggal kegagalan.
- Keamanan. Karena Google Cloud mengirim data Anda ke Splunk HEC, maka tidak ada beban pemeliharaan dan keamanan yang terkait dengan pembuatan dan pengelolaan kunci akun layanan.
- Penskalaan otomatis. Layanan Dataflow menskalakan otomatis jumlah worker sebagai respons terhadap variasi dalam volume log dan backlog yang masuk.
- Fault-tolerance. Jika ada masalah server atau jaringan sementara, metode berbasis push akan otomatis mencoba mengirim ulang data ke HEC Splunk. Fitur ini juga mendukung topik yang belum diproses (juga dikenal sebagai topik yang dihentikan pengirimannya) untuk pesan log yang tidak terkirim agar tidak kehilangan data.
- Kemudahan. Anda menghindari overhead pengelolaan dan biaya untuk menjalankan satu atau beberapa forwarder berat di Splunk.
Arsitektur referensi ini berlaku untuk bisnis di berbagai vertical industri, termasuk yang diatur seperti jasa farmasi dan keuangan. Jika memilih untuk mengekspor data Google Cloud ke Splunk, Anda dapat melakukannya karena alasan berikut:
- Analisis bisnis
- Operasi TI
- Pemantauan performa aplikasi
- Operasi keamanan
- Kepatuhan
Alternatif desain
Metode alternatif untuk ekspor log ke Splunk adalah metode pengambilan log dari Google Cloud. Dalam metode berbasis pull ini, Anda menggunakan Google Cloud API untuk mengambil data melalui Add-on Splunk untuk Google Cloud. Anda dapat memilih untuk menggunakan metode berbasis pull dalam situasi berikut:
- Deployment Splunk Anda tidak menawarkan endpoint Splunk HEC.
- Volume log Anda rendah.
- Anda ingin mengekspor dan menganalisis metrik Cloud Monitoring, objek Cloud Storage, metadata Cloud Resource Manager API, data Penagihan Cloud, atau log bervolume rendah.
- Anda sudah mengelola satu atau beberapa forwarder di Splunk.
- Anda menggunakan Inputs Data Manager untuk Splunk Cloud yang dihosting.
Selain itu, perhatikan pertimbangan tambahan yang muncul saat Anda menggunakan metode berbasis pull ini:
- Satu worker menangani beban kerja penyerapan data, yang tidak menawarkan kemampuan penskalaan otomatis.
- Di Splunk, penggunaan heavy forwarder untuk menarik data dapat menyebabkan satu titik kegagalan.
- Metode berbasis pull mengharuskan Anda membuat dan mengelola kunci akun layanan yang digunakan untuk mengonfigurasi Add-on Splunk untuk Google Cloud.
Sebelum menggunakan Add-on Splunk, entri log harus dirutekan terlebih dahulu ke
Pub/Sub menggunakan sink log. Untuk membuat sink log dengan
topik Pub/Sub sebagai tujuan, lihat
membuat sink.
Pastikan untuk memberikan peran Pub/Sub Publisher
(roles/pubsub.publisher) ke identitas penulis sink melalui
tujuan topik Pub/Sub tersebut. Untuk informasi
selengkapnya tentang mengonfigurasi izin tujuan sink, lihat
Menetapkan izin tujuan.
Untuk mengaktifkan Add-on Splunk, lakukan langkah-langkah berikut:
- Di Splunk, ikuti petunjuk Splunk untuk menginstal Add-on Splunk untuk Google Cloud.
- Buat langganan pull Pub/Sub untuk topik Pub/Sub tempat log dirutekan, jika Anda belum memilikinya.
- Membuat akun layanan
- Buat kunci akun layanan untuk akun layanan yang baru saja Anda buat.
- Berikan peran Pub/Sub Viewer (
roles/pubsub.viewer) dan Pub/Sub Subscriber (roles/pubsub.subscriber) ke akun layanan agar akun tersebut dapat menerima pesan dari langganan Pub/Sub. Di Splunk, ikuti petunjuk Splunk untuk mengonfigurasi input Pub/Sub baru di Add-on Splunk untuk Google Cloud.
Pesan Pub/Sub dari ekspor log muncul di Splunk.
Untuk memastikan bahwa add-on berfungsi, lakukan langkah-langkah berikut:
- Di Cloud Monitoring, buka Metrics Explorer.
- Di menu Resources, pilih
pubsub_subscription. - Di kategori Metric, pilih
pubsub/subscription/pull_message_operation_count. - Pantau jumlah operasi pesan pull selama satu hingga dua menit.
Pertimbangan desain
Panduan berikut dapat membantu Anda mengembangkan arsitektur yang memenuhi persyaratan organisasi Anda dalam hal keamanan, privasi, kepatuhan, efisiensi operasional, keandalan, toleransi error, performa, dan pengoptimalan biaya.
Keamanan, privasi, dan kepatuhan
Bagian berikut menjelaskan pertimbangan keamanan untuk arsitektur referensi ini:
- Menggunakan alamat IP pribadi untuk mengamankan VM yang mendukung pipeline Dataflow
- Mengaktifkan Akses Google Pribadi
- Batasi traffic masuk Splunk HEC ke alamat IP yang diketahui yang digunakan oleh Cloud NAT
- Menyimpan token Splunk HEC di Secret Manager
- Buat akun layanan worker Dataflow khusus untuk mengikuti praktik terbaik dengan hak istimewa terendah
- Mengonfigurasi validasi SSL untuk sertifikat CA root internal jika Anda menggunakan CA pribadi
Menggunakan alamat IP pribadi untuk mengamankan VM yang mendukung pipeline Dataflow
Anda harus membatasi akses ke VM worker yang digunakan di pipeline Dataflow. Untuk membatasi akses, deploy VM ini dengan alamat IP pribadi. Namun, VM ini juga harus dapat menggunakan HTTPS untuk menstreaming log yang diekspor ke Splunk dan mengakses internet. Untuk memberikan akses HTTPS ini, Anda memerlukan gateway Cloud NAT yang secara otomatis mengalokasikan alamat IP Cloud NAT ke VM yang membutuhkannya. Pastikan untuk memetakan subnet yang berisi VM ke gateway Cloud NAT.
Mengaktifkan Akses Google Pribadi
Saat Anda membuat gateway Cloud NAT, Akses Google Pribadi akan otomatis diaktifkan. Namun, untuk mengizinkan worker Dataflow dengan alamat IP pribadi mengakses alamat IP eksternal yang digunakan oleh layanan dan Google Cloud API, Anda juga harus mengaktifkan Akses Google Pribadi untuk subnet secara manual.
Batasi traffic masuk Splunk HEC ke alamat IP yang diketahui yang digunakan oleh Cloud NAT
Jika ingin membatasi traffic ke Splunk HEC ke sebagian alamat IP yang diketahui, Anda dapat mencadangkan alamat IP statis dan menetapkannya secara manual ke gateway Cloud NAT. Bergantung pada deployment Splunk, Anda dapat mengonfigurasi aturan firewall masuk Splunk HEC menggunakan alamat IP statis ini. Untuk mengetahui informasi selengkapnya tentang Cloud NAT, lihat Menyiapkan dan mengelola penafsiran alamat jaringan (NAT) dengan Cloud NAT.
Simpan token Splunk HEC di Secret Manager
Saat men-deploy pipeline Dataflow, Anda dapat meneruskan nilai token dengan salah satu cara berikut:
- Teks biasa
- Ciphertext yang dienkripsi dengan kunci Cloud Key Management Service
- Versi rahasia yang dienkripsi dan dikelola oleh Secret Manager
Dalam arsitektur referensi ini, Anda menggunakan opsi Secret Manager karena opsi ini menawarkan cara yang paling tidak kompleks dan efisien untuk melindungi token Splunk HEC Anda. Opsi ini juga mencegah kebocoran token Splunk HEC dari konsol Dataflow atau detail tugas.
Rahasia di Secret Manager berisi kumpulan versi rahasia. Setiap versi rahasia menyimpan data rahasia yang sebenarnya, seperti token HEC Splunk. Jika nantinya Anda memilih untuk merotasi token HEC Splunk sebagai tindakan keamanan tambahan, Anda dapat menambahkan token baru tersebut sebagai versi rahasia baru ke rahasia ini. Untuk mengetahui informasi umum tentang rotasi rahasia, lihat Tentang jadwal rotasi.
Buat akun layanan worker Dataflow khusus untuk mengikuti praktik terbaik dengan hak istimewa terendah
Pekerja di pipeline Dataflow menggunakan akun layanan pekerja Dataflow untuk mengakses resource dan menjalankan operasi. Secara default, pekerja menggunakan akun layanan default Compute Engine project Anda sebagai akun layanan pekerja, yang memberi mereka izin luas ke semua resource dalam project Anda. Namun, untuk menjalankan tugas Dataflow dalam produksi, sebaiknya Anda membuat akun layanan kustom dengan kumpulan peran dan izin minimum. Kemudian, Anda dapat menetapkan akun layanan kustom ini ke worker pipeline Dataflow.
Diagram berikut mencantumkan peran wajib yang harus Anda tetapkan ke akun layanan agar worker Dataflow dapat menjalankan tugas Dataflow dengan sukses.
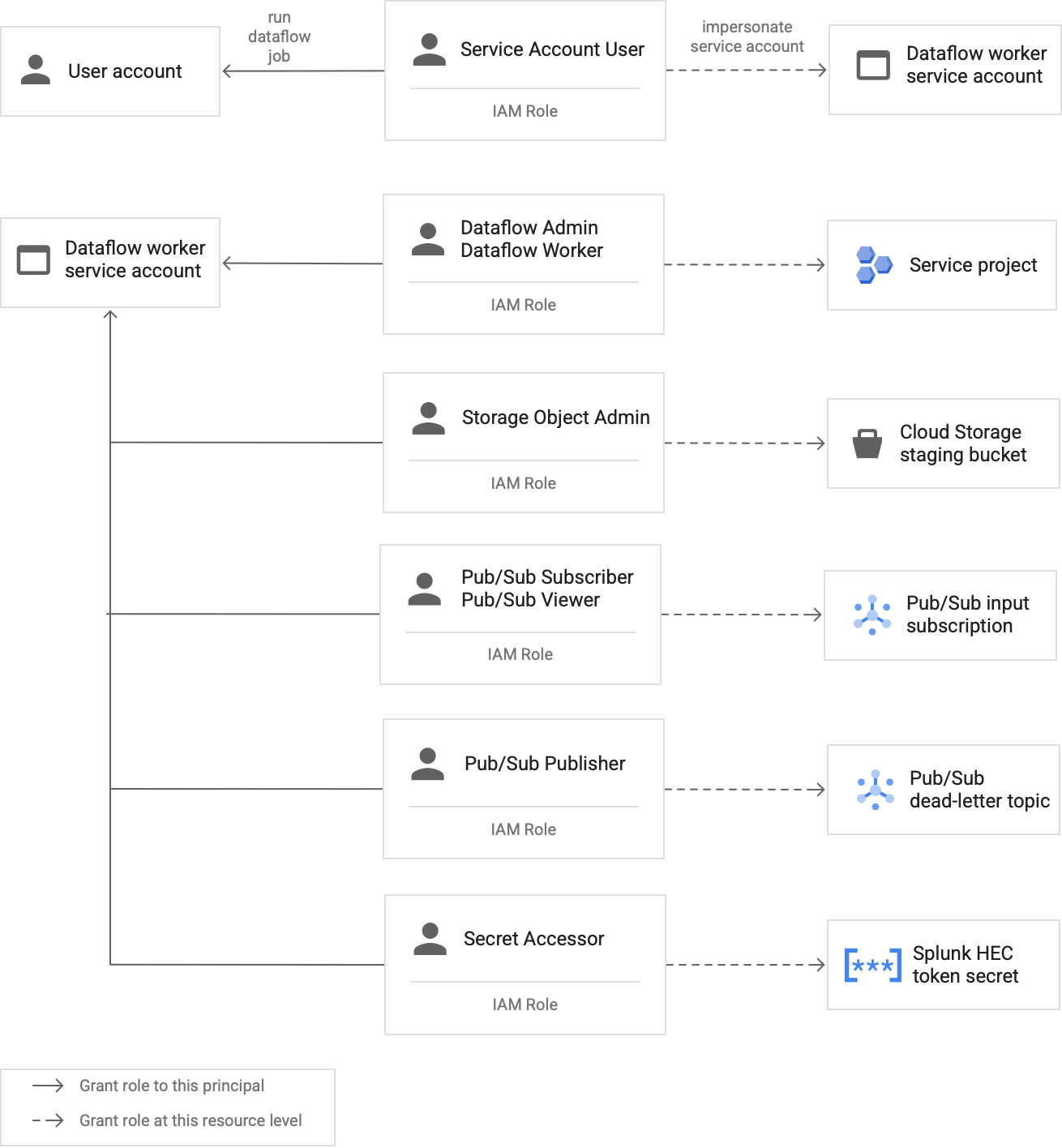
Seperti yang ditunjukkan pada diagram, Anda perlu menetapkan peran berikut ke akun layanan untuk worker Dataflow Anda:
- Dataflow Admin
- Dataflow Worker
- Storage Object Admin
- Pub/Sub Subscriber
- Pub/Sub Viewer
- Pub/Sub Publisher
- Secret Accessor
Mengonfigurasi validasi SSL dengan sertifikat CA root internal jika Anda menggunakan CA pribadi
Secara default, pipeline Dataflow menggunakan trust store default worker Dataflow untuk memvalidasi sertifikat SSL untuk endpoint Splunk HEC Anda. Jika menggunakan certificate authority (CA) pribadi untuk menandatangani sertifikat SSL yang digunakan oleh endpoint Splunk HEC, Anda dapat mengimpor sertifikat root CA internal ke trust store. Worker Dataflow kemudian dapat menggunakan sertifikat yang diimpor untuk validasi sertifikat SSL.
Anda dapat menggunakan dan mengimpor sertifikat root CA internal Anda sendiri untuk deployment Splunk dengan sertifikat yang ditandatangani sendiri atau ditandatangani secara pribadi. Anda juga dapat menonaktifkan validasi SSL sepenuhnya untuk tujuan pengembangan dan pengujian internal saja. Metode CA root internal ini paling cocok untuk deployment Splunk internal yang tidak terhubung ke internet.
Untuk mengetahui informasi selengkapnya, lihat
parameter template Dataflow Pub/Sub ke Splunk
rootCaCertificatePath dan disableCertificateValidation.
Efisiensi operasional
Bagian berikut menjelaskan pertimbangan efisiensi operasional untuk arsitektur referensi ini:
- Gunakan UDF untuk mengubah log atau peristiwa yang sedang berlangsung
- Memutar ulang pesan yang belum diproses
Gunakan UDF untuk mengubah log atau peristiwa yang sedang berlangsung
Template Pub/Sub ke Splunk Dataflow mendukung fungsi yang ditentukan pengguna (UDF) untuk transformasi peristiwa kustom. Contoh kasus penggunaan mencakup memperkaya data dengan kolom tambahan, menyamarkan beberapa kolom sensitif, atau memfilter data yang tidak diinginkan. Dengan UDF, Anda dapat mengubah format output pipeline Dataflow tanpa harus mengompilasi ulang atau mempertahankan kode template itu sendiri. Arsitektur referensi ini menggunakan UDF untuk menangani pesan yang tidak dapat dikirimkan oleh pipeline ke Splunk.
Memutar ulang pesan yang belum diproses
Terkadang, pipeline menerima error pengiriman dan tidak mencoba mengirimkan pesan lagi. Dalam hal ini, Dataflow mengirim pesan yang belum diproses ini ke topik yang belum diproses seperti yang ditunjukkan pada diagram berikut. Setelah memperbaiki akar masalah kegagalan pengiriman, Anda dapat memutar ulang pesan yang belum diproses.
Langkah-langkah berikut menguraikan proses yang ditunjukkan dalam diagram sebelumnya:
- Pipeline pengiriman utama dari Pub/Sub ke Splunk secara otomatis meneruskan pesan yang tidak terkirim ke topik yang belum diproses untuk diselidiki oleh pengguna.
Operator atau site reliability engineer (SRE) menyelidiki pesan yang gagal dalam langganan yang belum diproses. Operator memecahkan masalah dan memperbaiki akar masalah kegagalan pengiriman. Misalnya, memperbaiki kesalahan konfigurasi token HEC mungkin memungkinkan pesan dikirim.
Operator memicu pipeline pesan yang gagal diputar ulang. Pipeline Pub/Sub ke Pub/Sub ini (disorot di bagian titik-titik pada diagram sebelumnya) adalah pipeline sementara yang memindahkan pesan yang gagal dari langganan yang belum diproses kembali ke log asli menghilangkan topik.
Pipeline pengiriman utama memproses ulang pesan yang sebelumnya gagal. Langkah ini mengharuskan pipeline menggunakan UDF untuk mendeteksi dan mendekode payload pesan yang gagal dengan benar. Kode berikut adalah contoh fungsi yang menerapkan logika decoding bersyarat ini, termasuk penghitungan upaya pengiriman untuk tujuan pelacakan:
// If the message has already been converted to a Splunk HEC object // with a stringified obj.event JSON payload, then it's a replay of // a previously failed delivery. // Unnest and parse the obj.event. Drop the previously injected // obj.attributes such as errorMessage and timestamp if (obj.event) { try { event = JSON.parse(obj.event); redelivery = true; } catch(e) { event = obj; } } else { event = obj; } // Keep a tally of delivery attempts event.delivery_attempt = event.delivery_attempt || 1; if (redelivery) { event.delivery_attempt += 1; }
Keandalan dan fault tolerance
Sehubungan dengan keandalan dan fault tolerance, tabel berikut, Tabel 1,
mencantumkan beberapa kemungkinan error pengiriman Splunk. Tabel tersebut juga mencantumkan
atribut errorMessage terkait yang dicatat oleh pipeline pada setiap pesan sebelum
meneruskan pesan ini ke topik yang belum diproses.
Tabel 1: Jenis error pengiriman Splunk
| Jenis error pengiriman | Otomatis dicoba lagi dengan pipeline? | Atribut Ccontoh errorMessage |
|---|---|---|
Error jaringan sementara |
Ya |
atau
|
Error 5xx server Splunk |
Ya |
|
Error 4xx server Splunk |
Tidak |
|
Server Splunk mati |
Tidak |
|
Sertifikat SSL Splunk tidak valid |
Tidak |
|
Terjadi error sintaksis JavaScript dalam fungsi yang ditentukan pengguna (UDF) |
Tidak |
|
Dalam beberapa kasus, pipeline menerapkan
backoff eksponensial dan
secara otomatis mencoba mengirimkan pesan lagi. Misalnya, saat server Splunk
menghasilkan kode error 5xx, pipeline harus mengirim ulang
pesan. Kode error ini terjadi saat endpoint HEC Splunk kelebihan beban.
Atau, mungkin ada masalah terus-menerus yang mencegah pesan dikirim ke endpoint HEC. Untuk masalah yang terus-menerus terjadi, pipeline tidak akan mencoba mengirim pesan lagi. Berikut adalah contoh masalah persisten:
- Terjadi error sintaksis dalam fungsi UDF.
- Token HEC tidak valid yang menyebabkan server Splunk membuat respons
server "Forbidden"
4xx.
Pengoptimalan performa dan biaya
Sehubungan dengan pengoptimalan performa dan biaya, Anda perlu menentukan ukuran dan throughput maksimum untuk pipeline Dataflow. Anda harus menghitung ukuran dan nilai throughput yang benar agar pipeline dapat menangani volume log harian puncak (GB/hari) dan frekuensi pesan log (peristiwa per detik, atau EPS) dari langganan Pub/Sub upstream.
Anda harus memilih nilai ukuran dan throughput agar sistem tidak mengalami salah satu masalah berikut:
- Penundaan yang disebabkan oleh backlogging pesan atau throttling pesan.
- Biaya tambahan karena penyediaan pipeline yang berlebihan.
Setelah melakukan penghitungan ukuran dan throughput, Anda dapat menggunakan hasilnya untuk mengonfigurasi pipeline optimal yang menyeimbangkan performa dan biaya. Untuk mengonfigurasi kapasitas pipeline, gunakan setelan berikut:
- Flag Jenis mesin dan Jumlah mesin adalah bagian dari perintah gcloud yang men-deploy tugas Dataflow. Flag ini memungkinkan Anda menentukan jenis dan jumlah VM yang akan digunakan.
- Parameter Paralelisme dan Jumlah batch adalah bagian dari template Dataflow Pub/Sub ke Splunk. Parameter ini penting untuk meningkatkan EPS sekaligus menghindari membanjiri endpoint HEC Splunk.
Bagian berikut memberikan penjelasan tentang setelan ini. Jika berlaku, bagian ini juga menyediakan formula dan contoh penghitungan yang menggunakan setiap formula. Contoh penghitungan dan nilai yang dihasilkan ini mengasumsikan organisasi dengan karakteristik berikut:
- Menghasilkan 1 TB log setiap hari.
- Memiliki ukuran pesan rata-rata 1 KB.
- Memiliki rasio pesan puncak berkelanjutan yang besarnya dua kali lipat rasio rata-rata.
Karena lingkungan Dataflow Anda unik, ganti nilai contoh dengan nilai dari organisasi Anda sendiri saat Anda mengerjakan langkah-langkah ini.
Machine type
Praktik terbaik: Setel flag
--worker-machine-type ke n2-standard-4 untuk
memilih ukuran mesin yang memberikan rasio performa terhadap biaya terbaik.
Karena jenis mesin n2-standard-4 dapat menangani 12 ribu EPS, sebaiknya gunakan jenis
mesin ini sebagai dasar pengukuran untuk semua worker
Dataflow.
Untuk arsitektur referensi ini, tetapkan flag --worker-machine-type ke nilai
n2-standard-4.
Machine count
Praktik terbaik: Tetapkan
flag --max-workers untuk mengontrol jumlah maksimum
worker yang diperlukan untuk menangani EPS puncak yang diharapkan.
Dengan penskalaan otomatis Dataflow, layanan dapat secara adaptif
mengubah jumlah worker yang digunakan untuk menjalankan pipeline streaming Anda
saat terjadi perubahan pada penggunaan dan beban resource. Untuk menghindari penyediaan yang berlebihan saat
penskalaan otomatis, sebaiknya selalu tetapkan jumlah maksimum virtual machine yang
digunakan sebagai pekerja Dataflow. Anda menentukan jumlah maksimum
virtual machine dengan flag --max-workers saat men-deploy
pipeline Dataflow.
Dataflow secara statis menyediakan komponen penyimpanan sebagai berikut:
Pipeline penskalaan otomatis men-deploy satu persistent disk data untuk setiap calon worker streaming. Ukuran persistent disk default adalah 400 GB, dan Anda dapat menetapkan jumlah maksimum worker dengan flag
--max-workers. Disk akan dipasang ke worker yang sedang berjalan kapan saja, termasuk saat startup.Karena setiap instance worker dibatasi hingga 15 persistent disk, jumlah minimum worker awal adalah
⌈--max-workers/15⌉. Jadi, jika nilai defaultnya adalah--max-workers=20, penggunaan (dan biaya) pipeline adalah sebagai berikut:- Penyimpanan: statis dengan 20 persistent disk.
- Komputasi: dinamis dengan minimum 2 instance worker (⌈20/15⌉ = 2), dan maksimum 20.
Nilai ini setara dengan 8 TB Persistent Disk. Persistent Disk ukuran ini dapat menimbulkan biaya yang tidak perlu jika disk tidak sepenuhnya digunakan, terutama jika sebagian besar waktu hanya dijalankan oleh satu atau dua worker.
Untuk menentukan jumlah maksimum worker yang diperlukan untuk pipeline, gunakan formula berikut secara berurutan:
Tentukan rata-rata peristiwa per detik (EPS) menggunakan rumus berikut:
\( {AverageEventsPerSecond}\simeq\frac{TotalDailyLogsInTB}{AverageMessageSizeInKB}\times\frac{10^9}{24\times3600} \)Contoh penghitungan: Dengan contoh nilai 1 TB log per hari dengan ukuran pesan rata-rata 1 KB, formula ini menghasilkan nilai EPS rata-rata sebesar 11,5k EPS.
Tentukan EPS puncak yang berkelanjutan menggunakan formula berikut, dengan pengganda N mewakili sifat bursty logging:
\( {PeakEventsPerSecond = N \times\ AverageEventsPerSecond} \)Contoh penghitungan: Dengan contoh nilai N=2 dan nilai EPS rata-rata 11,5k yang Anda hitung di langkah sebelumnya, formula ini akan menghasilkan nilai puncak EPS yang berkelanjutan sebesar 23 ribu EPS.
Tentukan jumlah maksimum vCPU yang diperlukan menggunakan formula berikut:
\( {maxCPUs = ⌈PeakEventsPerSecond / 3k ⌉} \)Contoh penghitungan: Dengan menggunakan nilai EPS puncak berkelanjutan sebesar 23k yang Anda hitung di langkah sebelumnya, formula ini akan menghasilkan maksimum ⌈23 / 3⌉ = 8 core vCPU.
Tentukan jumlah maksimum worker Dataflow menggunakan formula berikut:
\( maxNumWorkers = ⌈maxCPUs / 4 ⌉ \)Contoh penghitungan: Dengan menggunakan contoh nilai vCPU maksimum 8 yang dihitung di langkah sebelumnya, formula [8/4] ini menghasilkan angka maksimum 2 untuk jenis mesin
n2-standard-4.
Untuk contoh ini, Anda akan menetapkan flag --max-workers ke nilai 2 berdasarkan
kumpulan contoh perhitungan sebelumnya. Namun, ingatlah untuk menggunakan
nilai dan perhitungan unik Anda sendiri saat men-deploy arsitektur referensi ini
di lingkungan Anda.
Keparalelan
Praktik terbaik: Setel
parameter parallelism
di template Pub/Sub ke Splunk Dataflow menjadi dua kali
jumlah vCPU yang digunakan oleh jumlah maksimum worker
Dataflow.
Parameter parallelism membantu memaksimalkan jumlah koneksi Splunk HEC paralel,
yang kemudian akan memaksimalkan laju EPS untuk pipeline Anda.
Nilai parallelism default dari 1 menonaktifkan paralelisme dan membatasi
kecepatan output. Anda perlu mengganti setelan default ini untuk memperhitungkan
2 hingga 4 koneksi paralel per vCPU, dengan jumlah maksimum worker yang di-deploy. Sebagai
aturan, Anda menghitung nilai penggantian untuk setelan ini dengan mengalikan
jumlah maksimum worker Dataflow dengan jumlah vCPU per worker,
lalu menggandakan nilai ini.
Untuk menentukan jumlah total koneksi paralel ke Splunk HEC di seluruh worker Dataflow, gunakan rumus berikut:
Contoh penghitungan: Dengan menggunakan contoh vCPU maksimum 8 yang sebelumnya dihitung untuk jumlah mesin, formula ini menghasilkan jumlah koneksi paralel menjadi 8 x 2 = 16.
Untuk contoh ini, Anda akan menetapkan parameter parallelism ke nilai 16
berdasarkan contoh penghitungan sebelumnya. Namun, ingatlah untuk menggunakan
nilai dan perhitungan unik Anda sendiri saat men-deploy arsitektur referensi ini
di lingkungan Anda.
Jumlah batch
Praktik terbaik: Agar Splunk HEC
dapat memproses peristiwa dalam batch, bukan satu per satu, tetapkan
parameter batchCount ke suatu nilai antara 10 hingga 50 peristiwa/permintaan untuk log.
Mengonfigurasi jumlah batch membantu meningkatkan EPS dan mengurangi beban pada
endpoint Splunk HEC. Setelan ini menggabungkan beberapa peristiwa menjadi satu
batch untuk pemrosesan yang lebih efisien. Sebaiknya tetapkan parameter batchCount
ke nilai antara 10 hingga 50 peristiwa/permintaan untuk log, asalkan penundaan
buffering maksimum dua detik masih dapat diterima.
Karena rata-rata ukuran pesan log dalam contoh ini adalah 1 KB, sebaiknya Anda
mengelompokkan setidaknya 10 peristiwa per permintaan. Untuk contoh ini, Anda akan menetapkan
parameter batchCount ke nilai 10. Namun, ingatlah untuk menggunakan
nilai dan perhitungan unik Anda sendiri saat men-deploy arsitektur referensi ini
di lingkungan Anda.
Untuk mengetahui informasi selengkapnya tentang rekomendasi performa dan pengoptimalan biaya ini, lihat Merencanakan pipeline Dataflow Anda.
Langkah berikutnya
- Untuk mengetahui daftar lengkap parameter template Pub/Sub ke Dataflow Splunk, baca dokumentasi Pub/Sub ke Dataflow Splunk.
- Untuk mengetahui template Terraform yang sesuai guna membantu Anda
men-deploy arsitektur referensi ini,
lihat repositori GitHub
terraform-splunk-log-export. Rilis ini mencakup dasbor Cloud Monitoring bawaan untuk memantau pipeline Splunk Dataflow Anda. - Untuk mengetahui detail selengkapnya tentang logging dan metrik kustom Splunk Dataflow untuk membantu Anda memantau dan memecahkan masalah pipeline Dataflow Splunk, lihat blog ini Fitur kemampuan observasi baru untuk pipeline streaming Splunk Dataflow Anda.
- Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.