Ce tutoriel constitue la deuxième partie d'une série qui explique comment créer une solution de bout en bout pour permettre aux analystes de données d'accéder de manière sécurisée aux données lors de l'utilisation d'outils d'informatique décisionnelle.
Ce tutoriel s'adresse aux opérateurs et aux administrateurs informatiques qui configurent des environnements qui fournissent des fonctionnalités de données et de traitement aux outils d'informatique décisionnelle utilisés par les analystes de données.
Tableau est utilisé comme outil d'informatique décisionnelle dans ce tutoriel. Pour suivre ce tutoriel, Tableau Desktop doit être installé sur votre poste de travail.
La série se compose des parties suivantes :
- La première partie de la série, Architecture permettant de connecter un logiciel de visualisation à Hadoop sur Google Cloud, définit l'architecture de la solution, ses composants et la manière dont les composants interagissent.
- Cette deuxième partie de la série vous explique comment configurer les composants de l'architecture qui composent la topologie Hive de bout en bout sur Google Cloud. Le tutoriel utilise des outils Open Source issus de l'écosystème Hadoop, avec Tableau comme outil d'informatique décisionnelle.
Les extraits de code de ce tutoriel sont disponibles dans un dépôt GitHub. Le dépôt GitHub inclut également des fichiers de configuration Terraform pour vous aider à configurer un prototype opérationnel.
Tout au long de ce tutoriel, vous utiliserez le nom sara comme l'identité d'utilisateur fictive d'un analyste de données. Cette identité d'utilisateur se trouve dans l'annuaire LDAP utilisé par Apache Knox et Apache Ranger. Vous pouvez également choisir de configurer des groupes LDAP, mais cette procédure n'entre pas dans le cadre de ce tutoriel.
Objectifs
- Créer une configuration de bout en bout permettant à un outil d'informatique décisionnelle d'utiliser les données d'un environnement Hadoop.
- Authentifier et autoriser les requêtes des utilisateurs.
- Configurer et utiliser des canaux de communication sécurisés entre l'outil d'informatique décisionnelle et le cluster.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS) APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS) APIs.
Initialiser l'environnement
-
In the Google Cloud console, activate Cloud Shell.
Dans Cloud Shell, définissez des variables d'environnement avec votre ID de projet, ainsi que la région et les zones des clusters Dataproc:
export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bVous pouvez choisir n'importe quelle région et zone, mais vous devez rester cohérent tout au long de ce tutoriel.
Configurer un compte de service
Dans Cloud Shell, créez un compte de service.
gcloud iam service-accounts create cluster-service-account \ --description="The service account for the cluster to be authenticated as." \ --display-name="Cluster service account"Le cluster utilise ce compte pour accéder aux ressources Google Cloud .
Ajoutez les rôles suivants au compte de service :
- Nœud de calcul Dataproc : pour créer et gérer des clusters Dataproc
- Éditeur Cloud SQL : pour que Ranger se connecte à sa base de données à l'aide du proxy Cloud SQL.
Déchiffreur de CryptoKey Cloud KMS : pour déchiffrer les mots de passe chiffrés avec Cloud KMS.
bash -c 'array=( dataproc.worker cloudsql.editor cloudkms.cryptoKeyDecrypter ) for i in "${array[@]}" do gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "serviceAccount:cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com" \ --role roles/$i done'
Créer le cluster de backend
Dans cette section, vous allez créer le cluster de backend dans lequel se trouve Ranger. Vous allez également créer la base de données Ranger pour stocker les règles de stratégie, ainsi qu'un exemple de table dans Hive pour appliquer les stratégies Ranger.
Créer l'instance de base de données Ranger
Créez une instance MySQL pour stocker les stratégies Apache Ranger :
export CLOUD_SQL_NAME=cloudsql-mysql gcloud sql instances create ${CLOUD_SQL_NAME} \ --tier=db-n1-standard-1 --region=${REGION}Cette commande crée une instance appelée
cloudsql-mysqlavec le type de machinedb-n1-standard-1situé dans la région spécifiée par la variable${REGION}. Pour en savoir plus, consultez la documentation Cloud SQL.Définissez le mot de passe de l'instance pour l'utilisateur
rootse connectant depuis n'importe quel hôte. Vous pouvez utiliser l'exemple de mot de passe à des fins de démonstration ou créer le vôtre. Si vous créez votre propre mot de passe, utilisez au moins huit caractères, y compris au moins une lettre et un chiffre.gcloud sql users set-password root \ --host=% --instance ${CLOUD_SQL_NAME} --password mysql-root-password-99
Chiffrer les mots de passe
Dans cette section, vous allez créer une clé cryptographique afin de chiffrer les mots de passe pour Ranger et MySQL. Pour éviter l'exfiltration, vous pouvez stocker la clé cryptographique dans Cloud KMS. Pour des raisons de sécurité, vous ne pouvez pas afficher, extraire ni exporter les bits de clé.
Vous utilisez la clé cryptographique pour chiffrer les mots de passe et les écrire dans des fichiers.
Vous importez ensuite ces fichiers dans un bucket Cloud Storage pour qu'ils soient accessibles au compte de service agissant pour le compte des clusters.
Le compte de service peut déchiffrer ces fichiers, car il dispose du rôle cloudkms.cryptoKeyDecrypter et de l'accès aux fichiers et à la clé cryptographique. Même si un fichier est exfiltré, il ne peut pas être déchiffré sans le rôle et la clé.
Par mesure de sécurité supplémentaire, vous créez des fichiers de mot de passe distincts pour chaque service. Cette action réduit la zone concernée potentielle si un mot de passe est exfiltré.
Pour en savoir plus sur la gestion des clés, consultez la documentation de Cloud KMS.
Dans Cloud Shell, créez un trousseau de clés Cloud KMS pour conserver vos clés :
gcloud kms keyrings create my-keyring --location globalPour chiffrer vos mots de passe, créez une clé cryptographique Cloud KMS :
gcloud kms keys create my-key \ --location global \ --keyring my-keyring \ --purpose encryptionChiffrez le mot de passe administrateur Ranger à l'aide de la clé. Vous pouvez utiliser l'exemple de mot de passe ou créer le vôtre. Votre mot de passe doit comporter au moins huit caractères, y compris au moins une lettre et un chiffre.
echo "ranger-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-admin-password.encryptedChiffrez le mot de passe administrateur de la base de données Ranger à l'aide de la clé suivante :
echo "ranger-db-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-db-admin-password.encryptedChiffrez votre mot de passe racine MySQL à l'aide de la clé suivante :
echo "mysql-root-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=mysql-root-password.encryptedCréez un bucket Cloud Storage pour stocker les fichiers de mot de passe chiffrés :
gcloud storage buckets create gs://${PROJECT_ID}-ranger --location=${REGION}Importez les fichiers de mot de passe chiffrés dans le bucket Cloud Storage :
gcloud storage cp *.encrypted gs://${PROJECT_ID}-ranger
Créer le cluster
Dans cette section, vous allez créer un cluster de backend compatible avec Ranger. Pour en savoir plus sur le composant facultatif Ranger dans Dataproc, consultez la page de documentation du composant Dataproc Ranger.
Dans Cloud Shell, créez un bucket Cloud Storage pour stocker les journaux d'audit Apache Solr :
gcloud storage buckets create gs://${PROJECT_ID}-solr --location=${REGION}Exportez toutes les variables requises pour créer le cluster :
export BACKEND_CLUSTER=backend-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-b export CLOUD_SQL_NAME=cloudsql-mysql export RANGER_KMS_KEY_URI=\ projects/${PROJECT_ID}/locations/global/keyRings/my-keyring/cryptoKeys/my-key export RANGER_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-admin-password.encrypted export RANGER_DB_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-db-admin-password.encrypted export MYSQL_ROOT_PWD_URI=\ gs://${PROJECT_ID}-ranger/mysql-root-password.encryptedPour plus de commodité, certaines des variables que vous avez définies précédemment sont répétées dans cette commande afin que vous puissiez les modifier en fonction de vos besoins.
Les nouvelles variables contiennent les éléments suivants :
- Nom du cluster de backend.
- URI de la clé cryptographique, qui permet au compte de service de déchiffrer les mots de passe.
- URI des fichiers contenant les mots de passe chiffrés.
Si vous avez utilisé un trousseau de clés ou une clé différents, ou des noms de fichiers différents, utilisez les valeurs correspondantes dans votre commande.
Créez le cluster de backend Dataproc :
gcloud beta dataproc clusters create ${BACKEND_CLUSTER} \ --optional-components=SOLR,RANGER \ --region ${REGION} \ --zone ${ZONE} \ --enable-component-gateway \ --scopes=default,sql-admin \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --properties="\ dataproc:ranger.kms.key.uri=${RANGER_KMS_KEY_URI},\ dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PWD_URI},\ dataproc:ranger.db.admin.password.uri=${RANGER_DB_ADMIN_PWD_URI},\ dataproc:ranger.cloud-sql.instance.connection.name=${PROJECT_ID}:${REGION}:${CLOUD_SQL_NAME},\ dataproc:ranger.cloud-sql.root.password.uri=${MYSQL_ROOT_PWD_URI},\ dataproc:solr.gcs.path=gs://${PROJECT_ID}-solr,\ hive:hive.server2.thrift.http.port=10000,\ hive:hive.server2.thrift.http.path=cliservice,\ hive:hive.server2.transport.mode=http"Cette commande a les propriétés suivantes :
- Les trois dernières lignes de la commande sont les propriétés Hive permettant de configurer HiveServer2 en mode HTTP, de sorte qu'Apache Knox puisse appeler Apache Hive via HTTP.
- Les autres paramètres de la commande fonctionnent comme suit :
- Le paramètre
--optional-components=SOLR,RANGERactive Apache Ranger et sa dépendance Solr. - Le paramètre
--enable-component-gatewaypermet à la passerelle des composants Dataproc de rendre la Ranger et d'autres interfaces utilisateur Hadoop directement disponibles à partir de la page du cluster dans la console Google Cloud. Lorsque vous définissez ce paramètre, il n'est pas nécessaire de créer un tunnel SSH pour le nœud maître du backend. - Le paramètre
--scopes=default,sql-adminautorise Apache Ranger à accéder à sa base de données Cloud SQL.
- Le paramètre
Si vous devez créer un metastore externe Hive qui persiste au-delà de la durée de vie d'un cluster et qui puisse être utilisé sur plusieurs clusters, consultez la page Utiliser Apache Hive sur Dataproc.
Pour exécuter la procédure, vous devez exécuter les exemples de création de table directement sur Beeline. Bien que les commandes gcloud dataproc jobs submit hive utilisent le transport binaire Hive, elles ne sont pas compatibles avec HiveServer2 lorsqu'il est configuré en mode HTTP.
Créer un exemple de table Hive
Dans Cloud Shell, créez un bucket Cloud Storage pour stocker un exemple de fichier Apache Parquet :
gcloud buckets create gs://${PROJECT_ID}-hive --location=${REGION}Copiez un exemple de fichier Parquet accessible au public dans votre bucket :
gcloud storage cp gs://hive-solution/part-00000.parquet \ gs://${PROJECT_ID}-hive/dataset/transactions/part-00000.parquetConnectez-vous au nœud maître du cluster de backend que vous avez créé dans la section précédente à l'aide de SSH :
gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mLe nom du nœud maître du cluster correspond au nom du cluster suivi de
-m.. Les noms des nœuds maîtres des clusters HA ont un suffixe supplémentaire.Si vous vous connectez à votre nœud maître pour la première fois à partir de Cloud Shell, vous êtes invité à générer des clés SSH.
Dans le terminal que vous avez ouvert avec SSH, connectez-vous au HiveServer2 local à l'aide d'Apache Beeline, qui est préinstallé sur le nœud maître :
beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice admin admin-password"\ --hivevar PROJECT_ID=$(gcloud info --format='value(config.project)')Cette commande démarre l'outil de ligne de commande Beeline et transmet le nom de votre projet Google Cloud dans une variable d'environnement.
Hive n'effectue aucune authentification des utilisateurs, mais pour effectuer la plupart des tâches, il requiert une identité utilisateur. L'utilisateur
admincorrespond à un utilisateur par défaut configuré dans Hive. Le fournisseur d'identité que vous configurez avec Apache Knox plus loin dans ce tutoriel gère l'authentification des utilisateurs pour les requêtes provenant des outils d'informatique décisionnelle.Dans l'invite Beeline, créez une table à l'aide du fichier Parquet que vous avez précédemment copié dans votre bucket Hive :
CREATE EXTERNAL TABLE transactions (SubmissionDate DATE, TransactionAmount DOUBLE, TransactionType STRING) STORED AS PARQUET LOCATION 'gs://${PROJECT_ID}-hive/dataset/transactions';Vérifiez que la table a été créée :
SELECT * FROM transactions LIMIT 10; SELECT TransactionType, AVG(TransactionAmount) AS AverageAmount FROM transactions WHERE SubmissionDate = '2017-12-22' GROUP BY TransactionType;Les résultats des deux requêtes s'affichent dans l'invite Beeline.
Quittez l'outil de ligne de commande Beeline :
!quitCopiez le nom DNS interne de l'instance maître du backend :
hostname -A | tr -d '[:space:]'; echoVous utiliserez ce nom dans la section suivante en tant que
backend-master-internal-dns-namepour configurer la topologie Apache Knox. Vous l'utiliserez également pour configurer un service dans Ranger.Quittez le terminal sur le nœud :
exit
Créer le cluster proxy
Dans cette section, vous allez créer le cluster proxy avec l'action d'initialisation Apache Knox.
Créer une topologie
Dans Cloud Shell, clonez le dépôt GitHub "initialization-actions" Dataproc :
git clone https://github.com/GoogleCloudDataproc/initialization-actions.gitCréez une topologie pour le cluster de backend :
export KNOX_INIT_FOLDER=`pwd`/initialization-actions/knox cd ${KNOX_INIT_FOLDER}/topologies/ mv example-hive-nonpii.xml hive-us-transactions.xmlApache Knox utilise le nom du fichier comme chemin d'URL pour la topologie. Au cours de cette étape, vous allez modifier le nom pour représenter une topologie appelée
hive-us-transactions. Vous pouvez ensuite accéder aux données de transaction fictives que vous avez chargées dans Hive dans la section Créer un exemple de table Hive.Modifiez le fichier de topologie :
vi hive-us-transactions.xmlPour savoir comment les services de backend sont configurés, consultez le fichier descripteur de topologie. Ce fichier définit une topologie qui pointe vers un ou plusieurs services de backend. Deux services sont configurés avec des exemples de valeurs : WebHDFS et HIVE. Ce fichier définit également le fournisseur d'authentification pour les services de cette topologie et des LCA d'autorisation.
Ajoutez l'exemple d'identité d'utilisateur LDAP d'analyste de données
sara.<param> <name>hive.acl</name> <value>admin,sara;*;*</value> </param>Ajouter l'exemple d'identité permet à l'utilisateur d'accéder au service de backend Hive via Apache Knox.
Modifiez l'URL HIVE de sorte qu'elle pointe vers le service Hive du cluster de backend. Vous trouverez la définition du service HIVE en bas du fichier, sous WebHDFS.
<service> <role>HIVE</role> <url>http://<backend-master-internal-dns-name>:10000/cliservice</url> </service>Remplacez l'espace réservé
<backend-master-internal-dns-name>par le nom DNS interne du cluster de backend obtenu à la section Créer un exemple de table Hive.Enregistrez le fichier et fermez l'éditeur.
Pour créer d'autres topologies, répétez les étapes de cette section. Créez un descripteur XML indépendant pour chaque topologie.
Dans la section Créer le cluster proxy, vous copiez ces fichiers dans un bucket Cloud Storage. Pour créer des topologies ou les modifier après avoir créé le cluster proxy, modifiez les fichiers, puis importez-les à nouveau dans le bucket. L'action d'initialisation Apache Knox crée un job Cron qui copie régulièrement les modifications apportées au bucket dans le cluster proxy.
Configurer le certificat SSL/TLS
Un client utilise un certificat SSL/TLS lorsqu'il communique avec Apache Knox. L'action d'initialisation peut générer un certificat autosigné ou vous pouvez fournir votre certificat signé par une autorité de certification.
Dans Cloud Shell, modifiez le fichier de configuration général Apache Knox :
vi ${KNOX_INIT_FOLDER}/knox-config.yamlRemplacez
HOSTNAMEpar le nom DNS externe du nœud maître du proxy en tant que valeur pour l'attributcertificate_hostname. Pour ce tutoriel, utilisezlocalhost.certificate_hostname: localhostPlus loin dans ce tutoriel, vous créerez un tunnel SSH et le cluster proxy pour la valeur
localhost.Le fichier de configuration général Apache Knox contient également la clé
master_keyqui chiffre les certificats utilisés par les outils d'informatique décisionnelle pour communiquer avec le cluster proxy. Par défaut, cette clé correspond au motsecret.Si vous fournissez votre propre certificat, modifiez les deux propriétés suivantes :
generate_cert: false custom_cert_name: <filename-of-your-custom-certificate>Enregistrez le fichier et fermez l'éditeur.
Si vous fournissez votre propre certificat, vous pouvez le spécifier dans la propriété
custom_cert_name.
Créer le cluster proxy
Dans Cloud Shell, créez un bucket Cloud Storage.
gcloud storage buckets create gs://${PROJECT_ID}-knox --location=${REGION}Ce bucket fournit à l'action d'initialisation Apache Knox les configurations que vous avez créées dans la section précédente.
Copiez dans le bucket tous les fichiers du dossier d'action d'initialisation Apache Knox :
gcloud storage cp ${KNOX_INIT_FOLDER}/* gs://${PROJECT_ID}-knox --recursiveExportez toutes les variables requises pour créer le cluster :
export PROXY_CLUSTER=proxy-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bAu cours de cette étape, certaines des variables que vous avez définies sont répétées afin que vous puissiez apporter les modifications nécessaires.
Créez le cluster proxy :
gcloud dataproc clusters create ${PROXY_CLUSTER} \ --region ${REGION} \ --zone ${ZONE} \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --initialization-actions gs://goog-dataproc-initialization-actions-${REGION}/knox/knox.sh \ --metadata knox-gw-config=gs://${PROJECT_ID}-knox
Vérifier la connexion via le proxy
Une fois le cluster proxy créé, connectez-vous à son nœud maître depuis Cloud Shell à l'aide de SSH :
gcloud compute ssh --zone ${ZONE} ${PROXY_CLUSTER}-mÀ partir du terminal du nœud maître du cluster proxy, exécutez la requête suivante :
beeline -u "jdbc:hive2://localhost:8443/;\ ssl=true;sslTrustStore=/usr/lib/knox/data/security/keystores/gateway-client.jks;trustStorePassword=secret;\ transportMode=http;httpPath=gateway/hive-us-transactions/hive"\ -e "SELECT SubmissionDate, TransactionType FROM transactions LIMIT 10;"\ -n admin -p admin-password
Cette commande a les propriétés suivantes :
- La commande
beelineutiliselocalhostau lieu du nom interne DNS, car le certificat que vous avez généré lors de la configuration d'Apache Knox spécifielocalhostcomme nom d'hôte. Si vous utilisez votre propre certificat ou nom DNS, utilisez le nom d'hôte correspondant. - Le port est
8443, ce qui correspond au port SSL par défaut d'Apache Knox. - La ligne qui commence par
ssl=trueactive SSL et fournit le chemin d'accès et le mot de passe du SSL Trust Store à utiliser par les applications clientes telles que Beeline. - La ligne
transportModeindique que la requête doit être envoyée via HTTP et fournit le chemin du service HiveServer2. Le chemin comprend le mot clégateway, le nom de topologie que vous avez défini dans une section précédente et le nom du service configuré dans la même topologie, dans ce cashive. - Le paramètre
-efournit la requête à exécuter sur Hive. Si vous omettez ce paramètre, vous allez ouvrir une session interactive dans l'outil de ligne de commande Beeline. - Le paramètre
-nfournit une identité et un mot de passe d'utilisateur. Dans cette étape, vous utilisez l'utilisateuradminHive par défaut. Dans les sections suivantes, vous allez créer une identité d'utilisateur analyste et configurer des identifiants et des règles d'autorisation pour cet utilisateur.
Ajouter un utilisateur au magasin d'authentification
Par défaut, Apache Knox inclut un fournisseur d'authentification basé sur Apache Shiro.
Ce fournisseur d'authentification est configuré avec l'authentification BASIC sur un magasin LDAP ApacheDS. Dans cette section, vous allez ajouter un exemple d'identité d'utilisateur d'analyste de données sara au magasin d'authentification.
À partir du terminal du nœud maître du proxy, installez les utilitaires LDAP :
sudo apt-get install ldap-utilsCréez un fichier LDIF (LDAP Data Interchange Format) pour le nouvel utilisateur
sara:export USER_ID=sara printf '%s\n'\ "# entry for user ${USER_ID}"\ "dn: uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org"\ "objectclass:top"\ "objectclass:person"\ "objectclass:organizationalPerson"\ "objectclass:inetOrgPerson"\ "cn: ${USER_ID}"\ "sn: ${USER_ID}"\ "uid: ${USER_ID}"\ "userPassword:${USER_ID}-password"\ > new-user.ldifAjoutez l'ID utilisateur à l'annuaire LDAP :
ldapadd -f new-user.ldif \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389Le paramètre
-Dspécifie le nom distinctif (DN, distinguished name) à lier lorsque l'utilisateur représenté parldapaddaccède à l'annuaire. Le nom distinctif doit être une identité d'utilisateur qui se trouve déjà dans l'annuaire, dans ce cas l'utilisateuradmin.Vérifiez que le nouvel utilisateur se trouve dans le magasin d'authentification :
ldapsearch -b "uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org" \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389Les informations sur l'utilisateur s'affichent dans votre terminal.
Copiez et enregistrez le nom DNS interne du nœud maître du proxy :
hostname -A | tr -d '[:space:]'; echoUtilisez-le dans la section suivante en tant que
<proxy-master-internal-dns-name>pour configurer la synchronisation LDAP.Quittez le terminal sur le nœud :
exit
Configurer l'autorisation
Dans cette section, vous allez configurer la synchronisation des identités entre le service LDAP et Ranger.
Synchroniser les identités des utilisateurs dans Ranger
Pour vous assurer que les stratégies Ranger s'appliquent aux mêmes identités d'utilisateur qu'Apache Knox, vous devez configurer le daemon Ranger UserSync pour synchroniser les identités du même annuaire.
Dans cet exemple, vous vous connectez à l'annuaire LDAP local qui est disponible par défaut avec Apache Knox. Toutefois, dans un environnement de production, nous vous recommandons de configurer un annuaire d'identité externe. Pour en savoir plus, consultez le guide de l'utilisateur Apache Knox et la documentation sur Google Cloud Cloud Identity, Managed Active Directory et Federated AD.
À l'aide de SSH, connectez-vous au nœud maître du cluster de backend que vous avez créé :
export BACKEND_CLUSTER=backend-cluster gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mDans le terminal, modifiez le fichier de configuration
UserSync:sudo vi /etc/ranger/usersync/conf/ranger-ugsync-site.xmlDéfinissez les valeurs des propriétés LDAP suivantes. Veillez à modifier les propriétés
useret non les propriétésgroup, qui portent des noms similaires.<property> <name>ranger.usersync.sync.source</name> <value>ldap</value> </property> <property> <name>ranger.usersync.ldap.url</name> <value>ldap://<proxy-master-internal-dns-name>:33389</value> </property> <property> <name>ranger.usersync.ldap.binddn</name> <value>uid=admin,ou=people,dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.ldap.ldapbindpassword</name> <value>admin-password</value> </property> <property> <name>ranger.usersync.ldap.user.searchbase</name> <value>dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.source.impl.class</name> <value>org.apache.ranger.ldapusersync.process.LdapUserGroupBuilder</value> </property>Remplacez l'espace réservé
<proxy-master-internal-dns-name>par le nom DNS interne du serveur proxy, que vous avez récupéré à la section précédente.Ces propriétés constituent un sous-ensemble d'une configuration LDAP complète qui synchronise à la fois les utilisateurs et les groupes. Pour en savoir plus, consultez la page concernant l'intégration de Ranger à LDAP.
Enregistrez le fichier et fermez l'éditeur.
Redémarrez le daemon
ranger-usersync:sudo service ranger-usersync restartExécutez la commande suivante :
grep sara /var/log/ranger-usersync/*Si les identités sont synchronisées, vous verrez au moins une ligne de journal pour l'utilisateur
sara.
Créer des stratégies Ranger
Dans cette section, vous allez configurer un nouveau service Hive dans Ranger. Vous allez également configurer et tester une stratégie Ranger pour limiter l'accès aux données Hive pour une identité spécifique.
Configurer le service Ranger
À partir du terminal du nœud maître, modifiez la configuration Hive Ranger :
sudo vi /etc/hive/conf/ranger-hive-security.xmlModifiez la propriété
<value>de la propriétéranger.plugin.hive.service.name:<property> <name>ranger.plugin.hive.service.name</name> <value>ranger-hive-service-01</value> <description> Name of the Ranger service containing policies for this YARN instance </description> </property>Enregistrez le fichier et fermez l'éditeur.
Redémarrez le service d'administration HiveServer2 :
sudo service hive-server2 restartVous êtes prêt à créer des stratégies Ranger.
Configurer le service dans la console d'administration Ranger
Dans la console Google Cloud, accédez à la page Dataproc.
Cliquez sur le nom de votre cluster de backend, puis sur Interfaces Web.
Comme vous avez créé votre cluster avec la passerelle des composants, vous voyez la liste des composants Hadoop installés sur votre cluster.
Cliquez sur le lien Ranger pour ouvrir la console Ranger.
Connectez-vous à Ranger avec l'utilisateur
adminet votre mot de passe administrateur Ranger. La console Ranger affiche la page "Service Manager" (Gestionnaire de services) avec une liste de services.Cliquez sur le signe "+" du groupe "HiVE" pour créer un service Hive.

Dans le formulaire, définissez les valeurs suivantes :
- Nom du service :
ranger-hive-service-01. Vous avez précédemment défini ce nom dans le fichier de configurationranger-hive-security.xml. - Nom d'utilisateur :
admin - Mot de passe :
admin-password jdbc.driverClassName: conservez le nom par défautorg.apache.hive.jdbc.HiveDriverjdbc.url:jdbc:hive2:<backend-master-internal-dns-name>:10000/;transportMode=http;httpPath=cliservice- Remplacez l'espace réservé
<backend-master-internal-dns-name>par le nom récupéré dans une section précédente.
- Nom du service :
Cliquez sur Ajouter.
Chaque installation de plug-in Ranger accepte un seul service Hive. Pour configurer facilement des services Hive supplémentaires, vous pouvez démarrer des clusters de backend supplémentaires. Chaque cluster possède son propre plug-in Ranger. Ces clusters peuvent partager la même base de données Ranger, afin que vous disposiez d'une vue unifiée de tous les services chaque fois que vous accédez à la console d'administration Ranger depuis l'un de ces clusters.
Configurer une stratégie Ranger avec des autorisations limitées
La stratégie autorise l'utilisateur LDAP analyste sara à accéder à des colonnes spécifiques de la table Hive.
Dans la fenêtre "Gestionnaire de services", cliquez sur le nom du service que vous avez créé.
La console d'administration Ranger affiche la fenêtre Stratégies.
Cliquez sur Ajouter une stratégie.
Avec cette stratégie, vous accordez à
saral'autorisation de n'afficher que les colonnessubmissionDateettransactionTypedes transactions de table.Dans le formulaire, définissez les valeurs suivantes :
- Nom de la stratégie : n'importe quel nom, par exemple
allow-tx-columns - Base de données :
default - Table :
transactions - Colonne Hive :
submissionDate, transactionType - Conditions d'autorisation :
- Sélectionner l'utilisateur :
sara - Autorisations :
select
- Sélectionner l'utilisateur :
- Nom de la stratégie : n'importe quel nom, par exemple
Au bas de l'écran, cliquez sur Ajouter.
Tester la stratégie avec Beeline
Dans le terminal du nœud maître, démarrez l'outil de ligne de commande Beeline avec l'utilisateur
sara.beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice sara user-password"Bien que l'outil de ligne de commande Beeline n'applique pas le mot de passe, vous devez fournir un mot de passe pour exécuter la commande précédente.
Exécutez la requête suivante pour vérifier que Ranger la bloque.
SELECT * FROM transactions LIMIT 10;La requête inclut la colonne
transactionAmount, quesaran'a pas le droit de sélectionner.Une erreur
Permission denieds'affiche.Vérifiez que Ranger autorise la requête suivante :
SELECT submissionDate, transactionType FROM transactions LIMIT 10;Quittez l'outil de ligne de commande Beeline :
!quitQuittez le terminal :
exitDans la console Ranger, cliquez sur l'onglet Audit. Les événements refusés et autorisés s'affichent. Vous pouvez filtrer les événements selon le nom du service que vous avez défini précédemment, par exemple
ranger-hive-service-01.
Se connecter depuis un outil d'informatique décisionnelle
La dernière étape de ce tutoriel consiste à interroger les données Hive à partir de Tableau Desktop.
Créer une règle de pare-feu
- Copiez et enregistrez votre adresse IP publique.
Dans Cloud Shell, créez une règle de pare-feu qui ouvre le port TCP
8443pour l'entrée depuis votre poste de travail :gcloud compute firewall-rules create allow-knox\ --project=${PROJECT_ID} --direction=INGRESS --priority=1000 \ --network=default --action=ALLOW --rules=tcp:8443 \ --target-tags=knox-gateway \ --source-ranges=<your-public-ip>/32Remplacez l'espace réservé
<your-public-ip>par votre adresse IP publique.Appliquez le tag réseau de la règle de pare-feu au nœud maître du cluster proxy :
gcloud compute instances add-tags ${PROXY_CLUSTER}-m --zone=${ZONE} \ --tags=knox-gateway
Créer un tunnel SSH
Cette procédure n'est nécessaire que si vous utilisez un certificat autosigné valide pour localhost. Si vous utilisez votre propre certificat ou que votre nœud maître du proxy possède son propre nom DNS externe, vous pouvez passer directement à la section Se connecter à Hive.
Dans Cloud Shell, générez la commande pour créer le tunnel :
echo "gcloud compute ssh ${PROXY_CLUSTER}-m \ --project ${PROJECT_ID} \ --zone ${ZONE} \ -- -L 8443:localhost:8443"Exécutez
gcloud initpour authentifier votre compte utilisateur et accorder les autorisations d'accès.Ouvrez un terminal dans votre poste de travail.
Créez un tunnel SSH pour transférer le port
8443. Copiez la commande générée à la première étape et collez-la dans le terminal de poste de travail, puis exécutez-la.Laissez le terminal ouvert pour que le tunnel reste actif.
Se connecter à Hive
- Sur votre poste de travail, installez le pilote ODBC Hive.
- Ouvrez Tableau Desktop ou redémarrez-le s'il était ouvert.
- Sur la page d'accueil, sous Se connecter/À un serveur, sélectionnez Plus.
- Recherchez puis sélectionnez Cloudera Hadoop.
En utilisant l'exemple d'utilisateur LDAP d'analyste de données
saracomme identité d'utilisateur, renseignez les champs comme suit :- Server (serveur) : si vous avez créé un tunnel, utilisez
localhost. Si vous n'avez pas créé de tunnel, utilisez le nom DNS externe de votre nœud maître de proxy. - Port :
8443 - Type :
HiveServer2 - Authentification :
UsernameetPassword - Nom d'utilisateur :
sara - Mot de passe :
sara-password - HTTP Path (chemin HTTP) :
gateway/hive-us-transactions/hive - Require SSL (SSL obligatoire) :
yes
- Server (serveur) : si vous avez créé un tunnel, utilisez
Cliquez sur Sign In (se connecter).

Interroger les données Hive
- Sur l'écran Source de données, cliquez sur Sélectionner un schéma et recherchez
default. Double-cliquez sur le nom du schéma
default.Le panneau Table s'affiche.
Dans le panneau Table, double-cliquez sur Nouveau SQL personnalisé.
La fenêtre Modifier le SQL personnalisé s'ouvre.
Saisissez la requête suivante, qui sélectionne la date et le type de transaction dans la table des transactions :
SELECT `submissiondate`, `transactiontype` FROM `default`.`transactions`Cliquez sur OK.
Les métadonnées de la requête sont extraites de Hive.
Sélectionnez Mettre à jour maintenant.
Tableau récupère les données depuis Hive, car
saraest autorisé à lire ces deux colonnes à partir de la tabletransactions.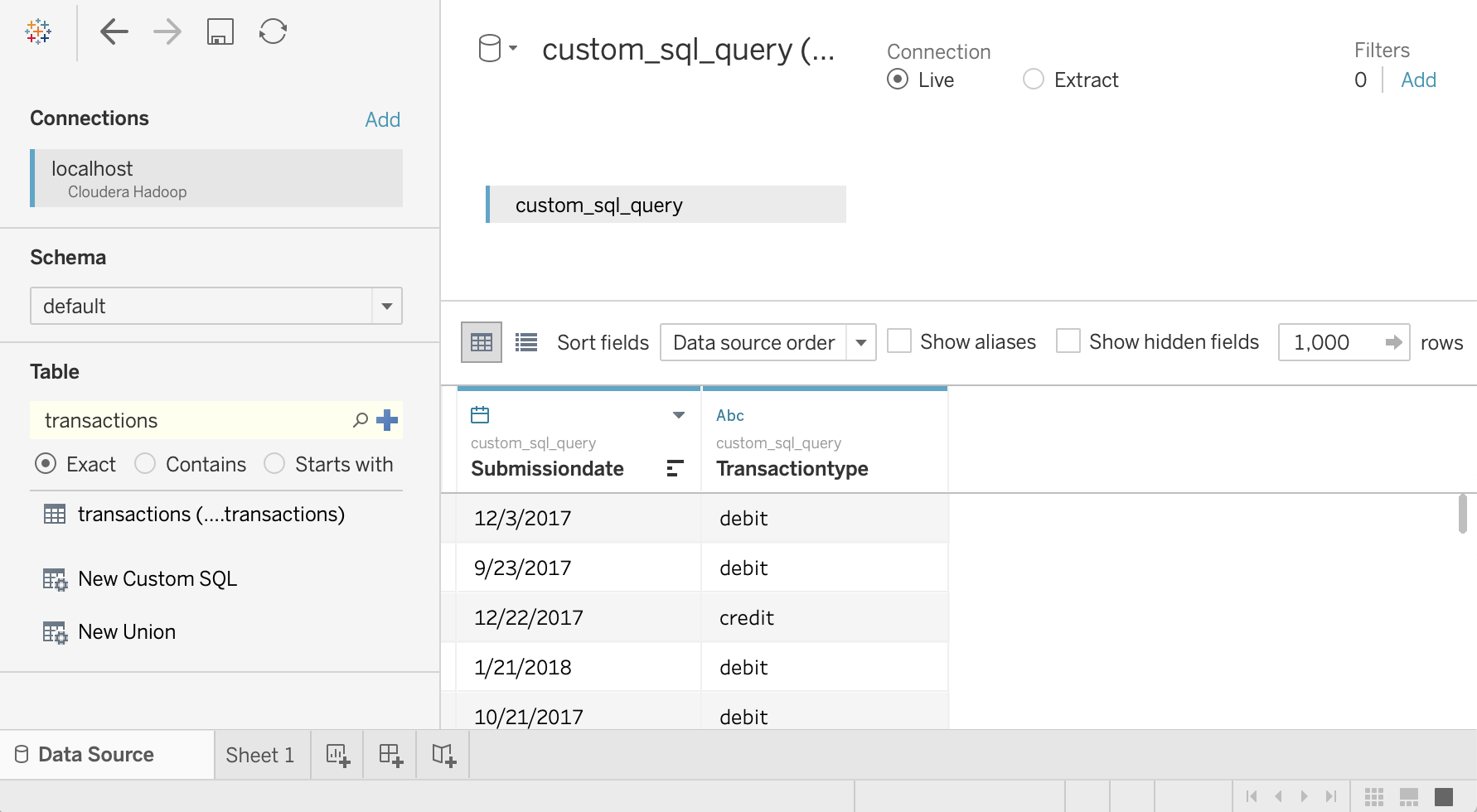
Pour essayer de sélectionner toutes les colonnes de la table
transactions, dans le panneau Table, double-cliquez à nouveau sur New Custom SQL (Nouveau SQL personnalisé). La fenêtre Modifier le SQL personnalisé s'ouvre.Saisissez la requête suivante :
SELECT * FROM `default`.`transactions`Cliquez sur OK. Le message d'erreur suivant s'affiche :
Permission denied: user [sara] does not have [SELECT] privilege on [default/transactions/*].Comme
sarane dispose pas de l'autorisation de Ranger pour lire la colonnetransactionAmount, ce message est attendu. Cet exemple montre comment limiter les données auxquelles les utilisateurs de Tableau peuvent accéder.Pour afficher toutes les colonnes, répétez la procédure avec l'utilisateur
admin.Fermez Tableau et votre fenêtre de terminal.
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer le projet
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étape suivante
- Consultez la première partie de cette série: Architecture permettant de connecter un logiciel de visualisation à Hadoop sur Google Cloud.
- Consultez le guide de sécurité sur la migration Hadoop.
- Découvrez comment migrer l'infrastructure Hadoop sur site vers Google Cloud.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.