Dataproc et Google Cloud contiennent plusieurs fonctionnalités de sécurisation des données. Ce guide explique le fonctionnement de la sécurité Hadoop et sa traduction dans Google Cloud. Il explique également comment concevoir la sécurité lors du déploiement sur Google Cloud.
Présentation
Le modèle et les mécanismes de sécurité lors d'un déploiement Hadoop sur site sont différents de ceux de la procédure cloud. Comprendre la sécurité sur Hadoop peut vous aider à mieux concevoir la sécurité lors du déploiement sur Google Cloud.
Vous pouvez déployer Hadoop sur Google Cloud de deux manières: en tant que clusters gérés par Google (Dataproc) ou en tant que clusters gérés par l'utilisateur (Hadoop sur Compute Engine). Les contenus et les conseils techniques fournis dans ce guide s'appliquent principalement aux deux formes de déploiement. Ainsi, Dataproc/Hadoop fait référence à des concepts ou procédures applicables à l'un ou l'autre de ces modèles. Les quelques différences de procédure entre Dataproc et Hadoop sur Compute Engine sont indiquées dans le présent guide.
Caractéristiques de la sécurité Hadoop sur site
Le schéma ci-dessous montre une infrastructure Hadoop sur site classique et la manière dont elle est sécurisée. Notez comment les composants Hadoop de base interagissent les uns avec les autres comme avec les systèmes de gestion des utilisateurs.
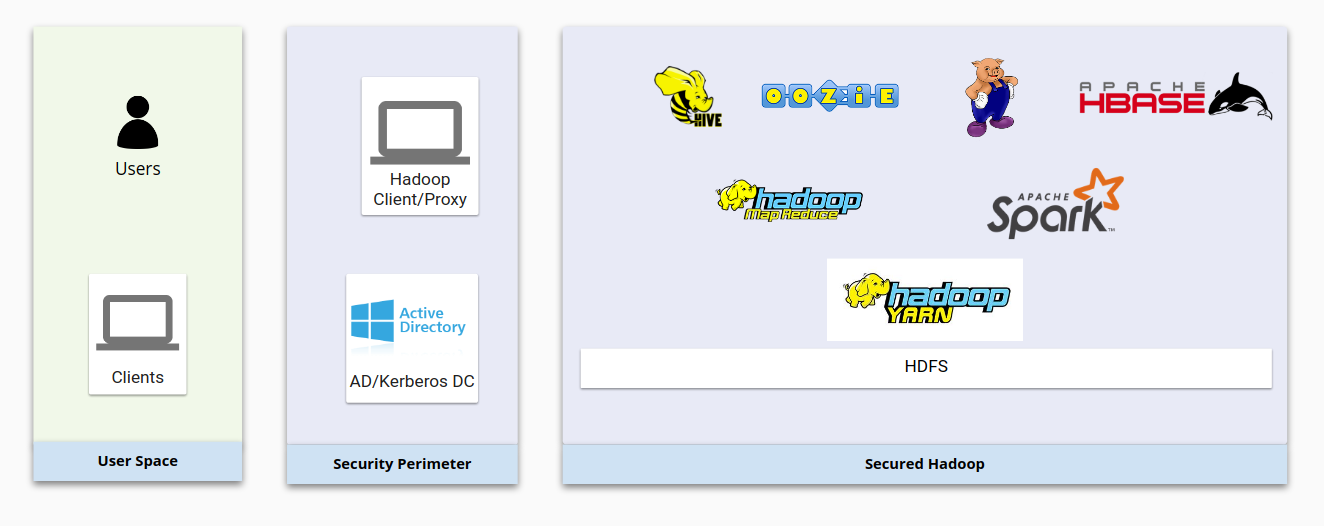
D'une manière générale, la sécurité Hadoop est construite sur ces quatre piliers :
- L'authentification fournie via Kerberos intégré à un schéma LDAP ou Active Directory
- L'autorisation fournie via HDFS et des produits de sécurité comme Apache Sentry ou Apache Ranger, qui garantissent la validité des accès utilisateur aux ressources Hadoop
- Le chiffrement fourni via les chiffrements réseau et HDFS, qui garantissent la sécurité des données en transit et au repos
- Les audits fournis par les produits tiers comme Cloudera Navigator
Du point de vue du compte utilisateur, Hadoop dispose de sa propre structure d'utilisateurs et de groupe pour gérer les identités et exécuter les daemons. Les daemons Hadoop HDFS et YARN s'exécutent par exemple comme des utilisateurs Unix hdfs et yarn, comme expliqué sur la page Hadoop en mode sécurisé.
Les utilisateurs Hadoop sont généralement mappés à partir d'utilisateurs Linux ou Active Directory/LDAP. Les utilisateurs et les groupes Active Directory sont synchronisés au moyen d'outils comme Centrify ou RedHat SSSD.
Authentification Hadoop sur site
Dans le cas d'un système sécurisé, les utilisateurs et les services doivent s'authentifier auprès du système. À cette fin, le mode sécurisé Hadoop utilise Kerberos. La plupart des composants Hadoop sont conçus pour utiliser l'authentification Kerberos. Kerberos est généralement mis en œuvre dans les systèmes d'authentification d'entreprise tels qu'Active Directory ou les systèmes compatibles LDAP.
Principals Kerberos
Dans Kerberos, un utilisateur est appelé un principal (ou "nom principal"). Dans un déploiement Hadoop, il y a les principaux d'utilisateur et les principaux de service. Les principaux d'utilisateur sont généralement synchronisés depuis Active Directory ou d'autres systèmes de gestion d'utilisateurs vers un centre de distribution de clés (KDC). Un principal d'utilisateur correspond à un utilisateur humain. Un principal de service est un nom unique attribué à un service par serveur. Ainsi, chaque service sur chaque serveur dispose d'un principal unique pour le représenter.
Fichiers Keytab
Un fichier keytab (ou "table clé") contient les principaux Kerberos et leurs clés. Les keytabs permettent aux utilisateurs et aux services de s'authentifier auprès des services Hadoop sans passer par des outils interactifs ni saisir des mots de passe. Hadoop crée des principaux de service pour chaque service sur chaque nœud. Ces principaux sont stockés dans des fichiers keytabs sur des nœuds Hadoop.
SPNEGO
Si vous accédez à un cluster kerberisé à l'aide d'un navigateur Web, ce dernier doit savoir comment transférer des clés Kerberos. C'est là qu'intervient le "mécanisme de négociation GSS-API simple et protégé" (SPNEGO, Simple and Protected GSS-API Negotiation Mechanism), qui permet d'utiliser Kerberos dans des applications Web.
Intégration
Hadoop s'intègre à Kerberos non seulement pour l'authentification de l'utilisateur, mais également pour l'authentification du service. Un service Hadoop sur un nœud, quel qu'il soit, a toujours son propre principal Kerberos qu'il utilise pour s'authentifier. Les services utilisent généralement des fichiers de clés stockés sur le serveur contenant un mot de passe aléatoire.
Pour être en mesure d'interagir avec les services, les utilisateurs humains doivent habituellement obtenir un ticket Kerberos à l'aide de la commande kinit, ou via Centrify ou SSSD.
Autorisation Hadoop sur site
Une fois l'identité validée, le système d'autorisation vérifie le type d'accès de l'utilisateur ou du service. Sur Hadoop, certains projets open source tels qu'Apache Sentry et Apache Ranger permettent d'obtenir cette autorisation.
Apache Sentry et Apache Ranger
Apache Sentry et Apache Ranger sont des mécanismes d'autorisation courants utilisés sur les clusters Hadoop. Les composants Hadoop implémentent leurs propres plug-in dans Sentry ou Ranger pour spécifier le comportement à adopter lorsque Sentry ou Ranger valide ou refuse l'accès à une identité. Sentry et Ranger s'appuient sur des systèmes d'authentification tels que Kerberos, LDAP ou AD. Le mécanisme de mappage de groupe Hadoop s'assure que le mappage de groupe dans Sentry ou Ranger est le même que dans les autres composants de l'écosystème Hadoop.
Autorisations HDFS et LCA
HDFS utilise un système d'autorisation de type POSIX avec une liste de contrôle d'accès (LCA) pour déterminer si les utilisateurs ont accès aux fichiers. Chaque fichier et chaque répertoire est associé à un propriétaire et à un groupe. La structure est dotée d'un dossier racine qui appartient à un super-utilisateur. Les différents niveaux de la structure peuvent être chiffrés différemment et présenter des droits de propriété, des autorisations ainsi que des LCA étendues (facl) différents.
Comme indiqué dans le schéma suivant, les autorisations sont généralement accordées au niveau répertoire à des groupes spécifiques en fonction de leurs besoins d'accès. Les modèles d'accès sont identifiés en tant que rôles différents et mappés aux groupes Active Directory. Les objets appartenant à un seul ensemble de données résident généralement au niveau de la couche qui dispose des autorisations pour un groupe spécifique, avec des répertoires différents pour différentes catégories de données.
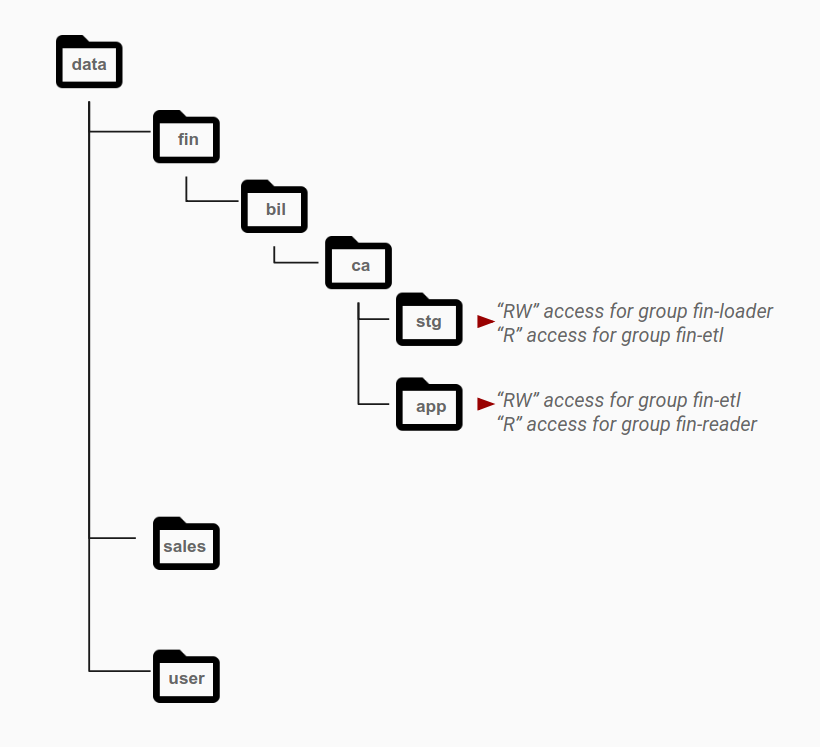
Par exemple, le répertoire stg correspond à la zone de stockage intermédiaire pour les données financières. Le dossier stg dispose d'autorisations de lecture et d'écriture pour le groupe fin-loader. À partir de cette zone intermédiaire, un autre groupe de comptes d'application, fin-etl, qui représente les pipelines ETL, dispose d'un accès en lecture seule à ce répertoire. Les pipelines ETL traitent les données et les enregistrent dans le répertoire app pour diffusion. Pour activer ce modèle d'accès, le répertoire app dispose d'un accès en lecture/écriture pour le groupe fin-etl, lequel représente l'identité utilisée pour écrire les données ETL, et d'un accès en lecture seule pour le groupe fin-reader, lequel utilise les données obtenues.
Chiffrement Hadoop sur site
Hadoop contient des outils de chiffrement pour les données au repos et les données en transit. Le chiffrement des données au repos s'effectue via HDFS à l'aide de clés de chiffrement écrites en Java ou de solutions de chiffrement fournisseurs. HDFS accepte le chiffrement par zones qui permet de chiffrer différents fichiers à l'aide de clés différentes. Chaque zone de chiffrement est associée à une clé de zone de chiffrement unique spécifiée lors de la création de la zone.
Chaque fichier dans une zone de chiffrement possède une clé de chiffrement de données unique (DEK). Les DEK ne sont jamais gérées directement par HDFS. En effet, HDFS ne gère que les clés de chiffrement des données elles-mêmes chiffrées (EDEK, Encrypted Data Encryption Key). Le client déchiffre une EDEK, puis utilise la DEK qui suit pour lire et écrire les données. Seul un flux d'octets chiffrés est visible sur les nœuds de données HDFS.
Le transit de données entre les nœuds Hadoop peut être chiffré par protocole TLS (Transport Layer Security). TLS assure le chiffrement et l'authentification lors des communications entre deux composants Hadoop. Des certificats internes signés par une autorité de certification sont généralement utilisés par Hadoop pour ce type de chiffrement.
Audits Hadoop sur site
Les audits constituent une part importante des procédures de sécurité. Un audit permet de détecter une activité suspecte et fournit un enregistrement des personnes ayant accès aux ressources. Cloudera Navigator est généralement utilisé pour la gestion des données, de même que d'autres outils tiers comme le suivi d'audit dans Hadoop. Ces outils offrent un contrôle et une visibilité sur les données dans les datastores Hadoop, ainsi que sur les calculs effectués sur ces données. Les audits de données permettent de capturer un enregistrement complet et non modifiable de toutes les activités au sein d'un système.
Hadoop sur Google Cloud
Dans un environnement Hadoop classique sur site, les quatre piliers de la sécurité Hadoop (authentification, autorisation, chiffrement et audit) sont intégrés et gérés par différents composants. Sur Google Cloud, ils sont gérés par différents Google Cloud composants externes à Dataproc et à Hadoop sur Compute Engine.
Vous pouvez gérer les ressources Google Cloud à l'aide de la consoleGoogle Cloud , qui est une interface Web. Vous pouvez également utiliser Google Cloud CLI, une solution plus rapide et pratique si vous êtes familiarisé avec la ligne de commande. Pour exécuter les commandes gcloud, vous devez installer gcloud CLI sur votre ordinateur local ou utiliser une instance de Cloud Shell.
Authentification Hadoop Google Cloud
Il existe deux types d'identités Google dans Google Cloud: les comptes de service et les comptes utilisateur. La plupart des API Google nécessitent une authentification avec une identité Google. Un nombre limité d' Google Cloud API fonctionne sans authentification (à l'aide de clés API), mais nous vous recommandons d'utiliser toutes les API avec l'authentification par compte de service.
Les comptes de service emploient des clés privées pour établir l'identité. Les comptes utilisateur utilisent le protocole OAUTH 2.0 pour authentifier les utilisateurs finaux. Pour en savoir plus, consultez la section Aperçu de l'authentification.
Autorisation Hadoop Google Cloud
Google Cloud fournit différents moyens de spécifier les autorisations dont dispose une identité authentifiée pour un ensemble de ressources.
IAM
Google Cloud propose la gestion de l'authentification et des accès (Identity and Access Management, IAM), qui vous permet de gérer le contrôle des accès en définissant quels utilisateurs (entités principales) disposent de quel type d'accès (rôle) pour chaque ressource.
Avec IAM, vous pouvez accorder l'accès aux ressources Google Cloud et empêcher tout accès indésirable à d'autres ressources. IAM vous permet d'implémenter le principe de sécurité du moindre privilège afin de n'accorder que l'accès nécessaire à vos ressources.
Comptes de service
Un compte de service est un type particulier de compte Google qui appartient à votre application ou à une machine virtuelle (VM), et non à un utilisateur final individuel. Les applications peuvent utiliser les identifiants du compte de service pour s'authentifier auprès d'autres API Cloud. En outre, vous pouvez créer des règles de pare-feu autorisant ou interdisant le trafic vers et depuis des instances en fonction du compte de service attribué à chaque instance.
Les clusters Dataproc s'appuient sur les VM Compute Engine. L'attribution d'un compte de service personnalisé lors de la création d'un cluster Dataproc attribue ce compte de service à toutes les VM de votre cluster. Le cluster dispose ainsi de droits d'accès et d'un contrôle précis sur les ressources Google Cloud . Si vous ne spécifiez pas de compte de service, les VM Dataproc utilisent le compte de service Compute Engine géré par Google par défaut. Par défaut, ce compte est doté du rôle étendu d'éditeur de projet qui lui attribue un large éventail d'autorisations. Pour les environnements de production, nous recommandons de ne pas utiliser le compte de service par défaut pour créer un cluster Dataproc.
Autorisations de compte de service
Lorsque vous attribuez un compte de service personnalisé à un cluster Dataproc/Hadoop, le niveau d'accès de ce compte de service est déterminé par la combinaison des niveaux d'accès accordés aux instances de VM du cluster et des rôles IAM attribués à votre compte de service. Pour configurer une instance à l'aide de votre compte de service personnalisé, vous devez configurer les niveaux d'accès et les rôles IAM. Ces mécanismes interagissent principalement de la manière suivante :
- Les niveaux d'accès autorisent l'accès d'une instance.
- IAM limite cet accès aux rôles attribués au compte de service utilisé par l'instance.
- Les autorisations à l'intersection des niveaux d'accès et des rôles IAM constituent les autorisations finales de l'instance.
Lorsque vous créez un cluster Dataproc ou une instance Compute Engine dans la console Google Cloud , vous sélectionnez le niveau d'accès d'application d'accès de l'instance:
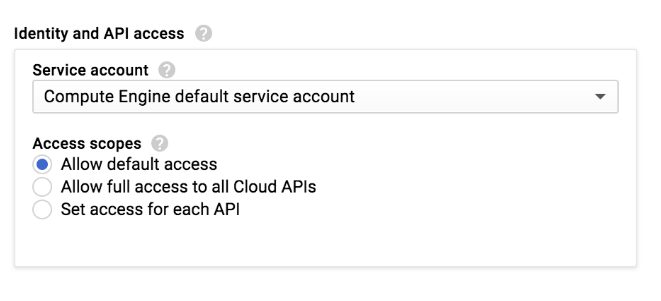
Un cluster Dataproc ou une instance Compute Engine dispose d'un ensemble de niveaux d'accès définis pour être utilisés avec le paramètre Allow default access (Autoriser l'accès par défaut) :
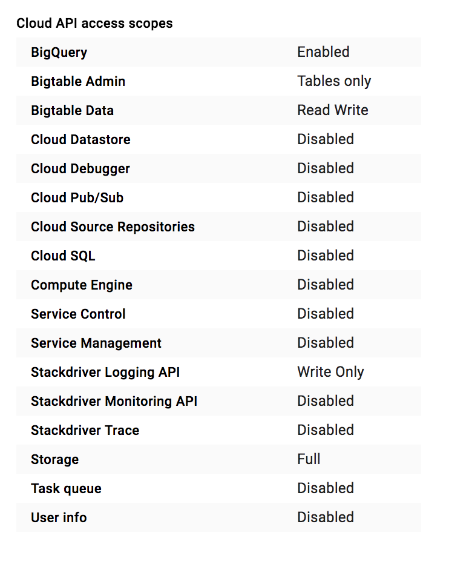
Vous pouvez choisir parmi de nombreux niveaux d'accès. Lors de la création d'une instance de VM ou d'un cluster, nous vous recommandons de définir le paramètre Autoriser l'accès complet à l'ensemble des API Cloud si vous utilisez la console ou le niveau d'accès https://www.googleapis.com/auth/cloud-platform si vous utilisez Google Cloud CLI. Ils autorisent l'accès à tous les servicesGoogle Cloud . Une fois que vous avez défini le champ d'application, nous vous recommandons de limiter cet accès en attribuant des rôles IAM au compte de service du cluster.
Le compte ne peut effectuer aucune action en dehors de ces rôles, malgré le niveau d'accèsGoogle Cloud . Pour en savoir plus, consultez la documentation sur les autorisations de compte de service.
Comparer IAM avec Apache Sentry et Apache Ranger
IAM joue un rôle semblable à Apache Sentry et Apache Ranger. IAM définit l'accès via des rôles. L'accès à d'autres composantsGoogle Cloud est défini dans ces rôles et est associé aux comptes de service. Cela signifie que toutes les instances qui utilisent le même compte de service disposent du même accès aux autres Google Cloud ressources. Toute personne ayant accès à ces instances dispose également du même accès à ces ressourcesGoogle Cloud que le compte de service.
Les clusters Dataproc et les instances Compute Engine ne sont pas dotés d'un mécanisme permettant de mapper les utilisateurs et les groupes Google avec les utilisateurs et les groupes Linux. Vous pouvez toutefois créer des utilisateurs et des groupes Linux. Dans le cluster Dataproc ou dans les VM Compute Engine, les autorisations HDFS et le mappage des utilisateurs et des groupes Hadoop continuent à fonctionner. Ce mappage peut être utilisé pour limiter l'accès à HDFS ou pour forcer l'attribution de ressources à l'aide d'une file d'attente YARN.
Lorsque les applications d'un cluster Dataproc ou d'une VM Compute Engine doivent accéder à des ressources externes telles que Cloud Storage ou BigQuery, ces applications sont authentifiées en tant qu'identité du compte de service que vous avez attribué aux VM du cluster. Vous utilisez ensuite IAM pour accorder au compte de service personnalisé de votre cluster le niveau d'accès minimal requis par votre application.
Autorisations Cloud Storage
Dataproc utilise Cloud Storage comme système de stockage. Dataproc fournit également un système HDFS local, mais HDFS ne sera pas disponible en cas de suppression du cluster Dataproc. Si l'application ne dépend pas strictement de HDFS, il est préférable d'utiliser Cloud Storage pour exploiter pleinement Google Cloud.
Cloud Storage n'a pas d'arborescence de stockage. La structure de répertoire simule la structure d'un système de fichiers. Il n'existe pas non plus d'autorisations de type POSIX. Le contrôle des accès par les comptes de service et les comptes utilisateur IAM peut être défini au niveau du bucket. Les autorisations établies sur les utilisateurs Linux ne sont pas appliquées.
Chiffrement Hadoop Google Cloud
À quelques exceptions près,les services Google Cloud chiffrent les données du client au repos et en transit à l'aide de diverses méthodes. Le chiffrement est automatique et ne requiert aucune action de la part du client.
Par exemple, les nouvelles données stockées sur les disques persistants sont chiffrées selon la norme AES (Advanced Encryption Standard) 256 bits, et chaque clé de chiffrement est elle-même chiffrée avec un ensemble de clés racines (maîtres) régulièrement alternées. Google Cloud utilise les mêmes règles de chiffrement et de gestion des clés, bibliothèques de cryptographie et racine de confiance que pour de nombreux services de production de Google, y compris Gmail et ses propres données d'entreprise.
Le chiffrement étant une fonctionnalité par défaut de Google Cloud (contrairement à la plupart des implémentations Hadoop sur site), vous n'avez pas à vous soucier de sa mise en œuvre, sauf si vous souhaitez utiliser votre propre clé de chiffrement.Google Cloud fournit également une solution de clés de chiffrement gérées par le client et une solution de clés de chiffrement fournies par le client. Si vous devez gérer vous-même les clés de chiffrement ou stocker vos clés sur site, vous pouvez le faire.
Pour en savoir plus, consultez Chiffrement au repos et Chiffrement en transit.
Audits Hadoop Google Cloud
Les journaux d'audit Cloud peuvent gérer certains types de journaux pour chaque projet et organisation.Les services Google Cloud génèrent des entrées dans ces journaux d'audit pour vous aider à répondre à la question "qui a fait quoi, où et quand ?" dans vos projetsGoogle Cloud .
Pour en savoir plus sur les journaux d'audit et les services qui génèrent des entrées dans ces journaux, consultez la documentation sur Cloud Audit Logs.
Processus de migration
Pour garantir un fonctionnement sécurisé et efficace de Hadoop sur Google Cloud, suivez la procédure décrite dans cette section.
Dans cette section, nous partons du principe que vous avez configuré votre environnement Google Cloud. Vous avez donc créé des utilisateurs et des groupes dans Google Workspace. Ces utilisateurs et ces groupes sont soit gérés manuellement, soit synchronisés avec Active Directory. Vous avez tout configuré pour que Google Cloud soit pleinement opérationnel pour l'authentification des utilisateurs.
Déterminer qui gérera les identités
La plupart des clients Google utilisent Cloud Identity pour gérer leurs identités. Cependant, certains gèrent leurs identités d'entreprise indépendamment des identités Google Cloud . Dans ce cas, leurs autorisations POSIX et SSH déterminent l'accès des utilisateurs finaux aux ressources du cloud.
Si vous disposez d'un système d'identité indépendant, commencez par créer des clés de compte de service Google Cloud , puis téléchargez-les. Vous pouvez ensuite relier votre modèle de sécurité POSIX et SSH sur site au modèle Google Cloud en attribuant les autorisations d'accès de type POSIX appropriées aux fichiers de clé de compte de service téléchargés. Vous autorisez ou refusez à vos identités sur site l'accès à ces fichiers de clés.
Si vous procédez ainsi, la possibilité de réaliser des audits dépend de vos propres systèmes de gestion des identités. Comme outil d'audit, vous pouvez utiliser les journaux SSH des connexions utilisateurs sur les nœuds périphériques (qui contiennent les fichiers de clés du compte de service). Vous pouvez également opter pour un mécanisme de magasin de clés plus lourd et explicite afin d'extraire les identifiants du compte de service des utilisateurs. Dans ce cas, "l'emprunt d'identité du compte de service" est enregistré dans la couche de magasin de clés.
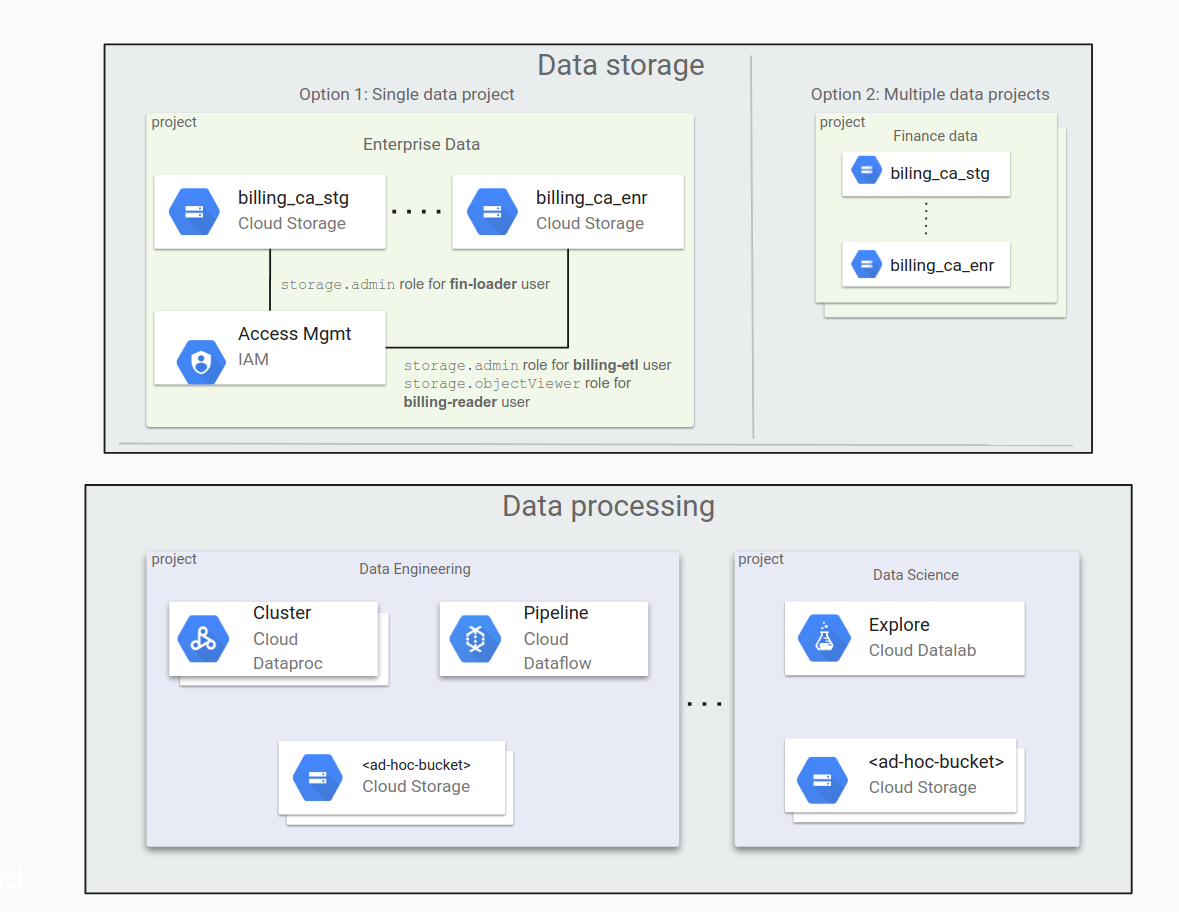
Déterminer s'il faut utiliser un projet de données unique ou plusieurs projets de données
Si votre organisation traite un volume important de données, vous devez distribuer ces données dans plusieurs buckets Cloud Storage. Vous devez également réfléchir à la manière de répartir ces buckets entre vos projets. Lors de la mise en route de Google Cloud, il peut être tentant de ne transférer qu'une petite quantité de données, puis d'augmenter le volume à mesure que les charges de travail et les applications sont transférées.
Il peut aussi sembler pratique de placer tous vos buckets de données dans un même projet, mais cette approche est rarement la bonne. Pour gérer l'accès aux données, vous utilisez une structure de répertoires aplatie avec des rôles IAM attribués aux buckets. Ce mode de gestion peut devenir problématique à mesure que le nombre de buckets augmente.
La solution consiste à stocker les données dans plusieurs projets, chacun étant dédié à différentes organisations : un projet pour le service financier, un autre pour le groupe juridique, etc. Dans ce cas, chaque groupe gère ses propres autorisations de manière indépendante.
Pendant le traitement des données, il peut être nécessaire d'accéder aux buckets ou de créer des buckets ad hoc. Le traitement peut être réparti entre plusieurs limites de confiance, par exemple lorsque des data scientists accèdent à des données générées par un processus dont ils ne sont pas propriétaires.
Le schéma suivant présente une répartition classique des données dans Cloud Storage selon deux modèles : dans un projet de données unique ou entre plusieurs projets de données.
Voici les principaux points à considérer au moment de décider quelle approche convient le mieux à votre organisation.
Un seul projet de données :
- La gestion de tous les buckets est simple, à condition que leur nombre soit limité.
- L'attribution des autorisations est principalement effectuée par les membres du groupe administrateur.
Plusieurs projets de données :
- La délégation des responsabilités de gestion aux propriétaires des projets est plus facile à effectuer.
- Cette approche est intéressante pour les entreprises qui disposent de différents processus d'attribution des autorisations. Par exemple, le processus d'attribution des autorisations n'est pas le même pour les projets du service marketing et les projets du service juridique.
Identifier les applications et créer des comptes de service
Lorsque les clusters Dataproc/Hadoop interagissent avec d'autres ressourcesGoogle Cloud , par exemple Cloud Storage, vous devez identifier toutes les applications qui s'exécutent sur Dataproc/Hadoop, ainsi que les accès nécessaires. Par exemple, imaginons qu'une tâche ETL distribue les données financières en Californie dans le bucket financial-ca. Cette tâche ETL doit disposer de l'accès en lecture et écriture au bucket. Après avoir identifié les applications utilisatrices d'Hadoop, vous pourrez créer des comptes de service pour chacune de ces applications.
N'oubliez pas que cet accès n'a pas d'incidence sur les utilisateurs Linux du cluster Dataproc ou de Hadoop sur Compute Engine.
Pour en savoir plus sur les comptes de service, consultez la section Créer et gérer les comptes de service.
Attribuer des autorisations aux comptes de service
Une fois que vous avez déterminé l'accès de chaque application aux différents buckets Cloud Storage, il vous reste à définir ces autorisations sur les comptes de service d'applications appropriés. Si vos applications doivent également accéder à d'autres composantsGoogle Cloud , tels que BigQuery ou Bigtable, vous pouvez également accorder des autorisations à ces composants à l'aide de comptes de service.
Par exemple, vous pouvez spécifier operation-ca-etl en tant qu'application ETL pour générer des rapports sur les opérations. Pour ce faire, assemblez les données marketing et de ventes pour la Californie, et accordez-lui un accès en lecture/écriture sur le bucket de données du service financier. Définissez ensuite les applications marketing-report-ca et sales-report-ca de sorte que chacune dispose d'un accès en lecture et en écriture à ses propres services. Cette configuration est expliquée dans le schéma suivant.
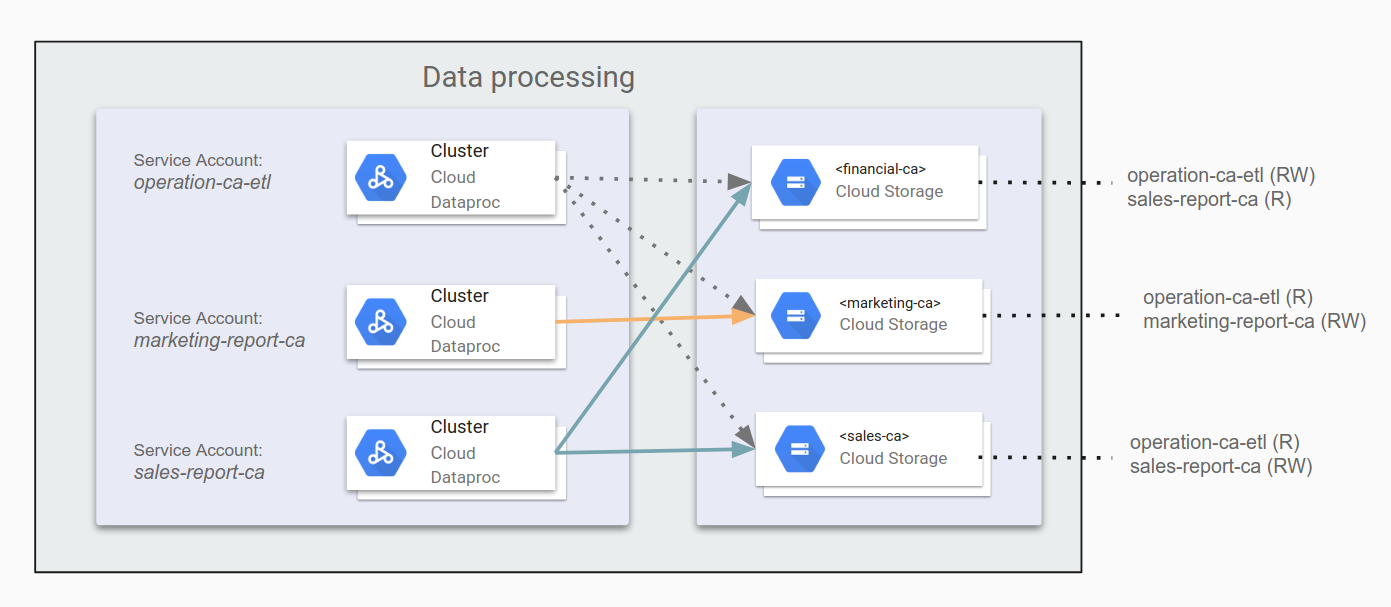
Nous conseillons d'appliquer le principe du moindre privilège. Selon ce principe, vous n'attribuez à chaque utilisateur ou compte de service que les autorisations minimales dont il a besoin pour exécuter les tâches qui lui sont attribuées. Les autorisations par défaut dansGoogle Cloud sont optimisées pour faciliter l'utilisation et réduire le temps de configuration. Pour créer des infrastructures Hadoop susceptibles de passer avec succès les contrôles de sécurité et de conformité, vous devez concevoir des autorisations plus restrictives. Le fait d'établir ces règles au préalable et de les documenter permet non seulement d'obtenir un pipeline conforme et sécurisé, mais également de revoir au besoin l'architecture avec les équipes de sécurité et de conformité.
Créer des clusters
Une fois que vous avez planifié et configuré l'accès, vous pouvez créer des clusters Dataproc ou Hadoop sur Compute Engine avec les comptes de service que vous avez créés. Chaque cluster aura accès aux autres composantsGoogle Cloud en fonction des autorisations que vous avez attribuées à ce compte de service. Veillez à spécifier les niveaux d'accès corrects à Google Cloud , puis ajustez en conséquence l'accès du compte de service. Si un problème d'accès survient, en particulier pour Hadoop sur Compute Engine, vérifiez ces autorisations.
Pour créer un cluster Dataproc avec un compte de service spécifique, exécutez la commande gcloud suivante :
gcloud dataproc clusters create [CLUSTER_NAME] \
--service-account=[SERVICE_ACCOUNT_NAME]@[PROJECT+_ID].iam.gserviceaccount.com \
--scopes=scope[, ...]
Nous conseillons d'éviter d'utiliser le compte de service Compute Engine par défaut pour les raisons suivantes :
- Les audits sont difficiles à effectuer lorsque plusieurs clusters et VM de Compute Engine utilisent le compte de service Compute Engine par défaut.
- La configuration par défaut du compte de service Compute Engine peut varier. En effet, il a peut-être accès à des privilèges supérieurs aux besoins de votre cluster.
- Les modifications du compte de service Compute Engine par défaut peuvent affecter, voire détruire les clusters et les applications qui y sont exécutés.
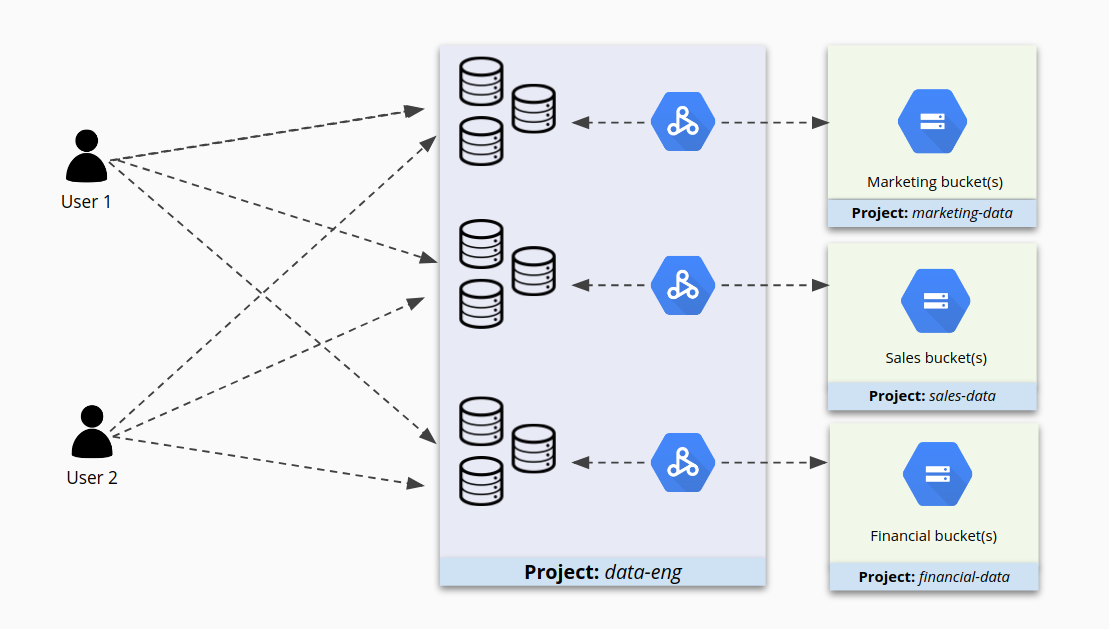
Envisager de définir des autorisations IAM pour chaque cluster
Si le placement de plusieurs clusters dans un seul projet facilite la gestion, ce n'est pas forcément le meilleur moyen de sécuriser leur accès. Par exemple, pour les clusters 1 et 2 dans le projet A, certains utilisateurs peuvent disposer des privilèges appropriés pour travailler sur le groupe 1, mais détenir aussi des autorisations trop étendues pour le cluster 2. Pire encore, ils peuvent avoir accès au cluster 2 simplement parce qu'il se trouve dans ce projet alors qu'ils ne devraient pas avoir accès à ce cluster.
Lorsque les projets contiennent plusieurs clusters, leur accès peut vite s'enchevêtrer, comme le montre l'illustration suivante.
À la place, si vous regroupez des clusters qui se ressemblent dans des projets plus petits et que vous configurez IAM séparément pour chaque cluster, vous obtiendrez un contrôle d'accès plus précis. Les utilisateurs auront ainsi accès aux clusters qui leur sont destinés et leur accès aux autres clusters sera limité.
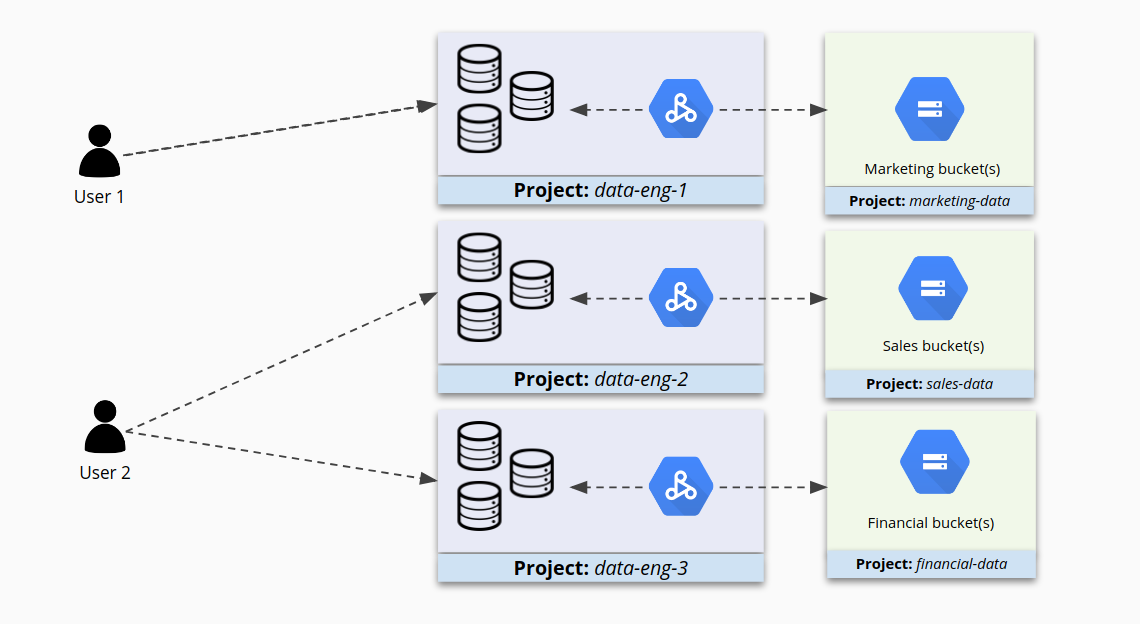
Limiter l'accès aux clusters
Configurer des accès à l'aide de comptes de service sécurise les interactions entre Dataproc/Hadoop et les autres Google Cloud composants. Cependant, cela ne permet pas de contrôler pleinement qui peut accéder à Dataproc/Hadoop. Par exemple, un utilisateur du cluster détenteur de l'adresse IP des nœuds de cluster Dataproc/Hadoop peut toujours utiliser SSH pour s'y connecter (dans certains cas) ou pour envoyer des tâches. Dans l'environnement sur site, l'administrateur système dispose généralement de sous-réseaux, de règles de pare-feu, d'une authentification Linux et d'autres règles permettant de limiter l'accès aux clusters Hadoop.
Lorsque vous exécutez Dataproc/Hadoop sur Compute Engine, vous pouvez restreindre l'accès au niveau de l'authentification Google Workspace ouGoogle Cloud de différentes manières. Toutefois, ce guide est principalement consacré à l'accès au niveau des composants Google Cloud .
Limiter la connexion SSH via la connexion au système d'exploitation
Dans l'environnement sur site, pour limiter les connexions utilisateurs à un nœud Hadoop, vous devez configurer le contrôle d'accès de périmètre, l'accès SSH au niveau Linux et les fichiers sudoer.
Sur Google Cloud, vous pouvez configurer des restrictions SSH au niveau de l'utilisateur pour la connexion aux instances Compute Engine en procédant comme suit:
- Activez la fonctionnalité OS Login sur votre projet ou sur des instances individuelles.
- Accordez les rôles IAM pertinents à vous-même et aux autres entités principales.
- Vous pouvez également ajouter des clés SSH personnalisées aux comptes utilisateur pour vous-même et pour d'autres entités principales. Sinon, Compute Engine génère automatiquement ces clés lorsque vous vous connectez à des instances.
Une fois que vous avez activé OS Login sur une ou plusieurs instances de votre projet, ces instances n'acceptent les connexions qu'à partir de comptes utilisateur disposant des rôles IAM nécessaires pour accéder à votre projet ou à votre organisation.
Par exemple, vous pouvez attribuer à vos utilisateurs l'accès à une instance en procédant comme suit :
Attribuez les rôles d'accès aux instances nécessaires à l'utilisateur. Celui-ci doit disposer des rôles suivants :
- Le rôle
iam.serviceAccountUser L'un des rôles de connexion suivants :
- Le rôle
compute.osLogin, qui n'accorde pas d'autorisations d'administrateur - Le rôle
compute.osAdminLogin, qui accorde des autorisations d'administrateur
- Le rôle
- Le rôle
Si, en tant qu'administrateur d'organisation, vous souhaitez autoriser des identités Google extérieures à votre organisation à accéder à vos instances, attribuez-leur le rôle
compute.osLoginExternalUserau niveau de l'organisation. Vous devez ensuite accorder à ces identités extérieures le rôlecompute.osLoginoucompute.osAdminLoginau niveau du projet ou de l'organisation.
Après avoir configuré les rôles nécessaires, connectez-vous à une instance à l'aide des outils Compute Engine. Compute Engine génère automatiquement des clés SSH et les associe à votre compte utilisateur.
Pour en savoir plus sur la fonctionnalité de connexion au système d'exploitation, consultez la section Gérer l'accès à une instance à l'aide de la connexion au système d'exploitation.
Limiter l'accès au réseau à l'aide de règles de pare-feu
Sur Google Cloud, vous pouvez également créer des règles de pare-feu qui utilisent des comptes de service pour filtrer le trafic entrant ou sortant. Cette approche s'avère particulièrement efficace dans les cas suivants :
- Le nombre d'utilisateurs ou d'applications qui ont besoin d'accéder à Hadoop est important, ce qui pose problème pour créer des règles basées sur l'IP.
- Vous exécutez des clusters Hadoop ou des VM clientes éphémères, par conséquent les adresses IP changent fréquemment.
Les règles de pare-feu combinées à des comptes de service permettent de définir l'accès à un cluster Dataproc/Hadoop spécifique pour n'autoriser qu'un compte de service donné. Ainsi, seules les VM exécutées sur ce compte de service auront accès au cluster, et ce au niveau spécifié.
Le schéma suivant illustre le processus d'utilisation des comptes de service pour restreindre l'accès. dataproc-app-1, dataproc-1, dataproc-2 et app-1-client sont tous des comptes de service. Les règles de pare-feu autorisent dataproc-app-1 à accéder à dataproc-1 et dataproc-2, et permettent aux clients utilisant le compte app-1-client d'accéder à dataproc-1. Concernant le stockage, Cloud Storage limite l'accès et les autorisations aux comptes de service plutôt qu'aux règles de pare-feu.
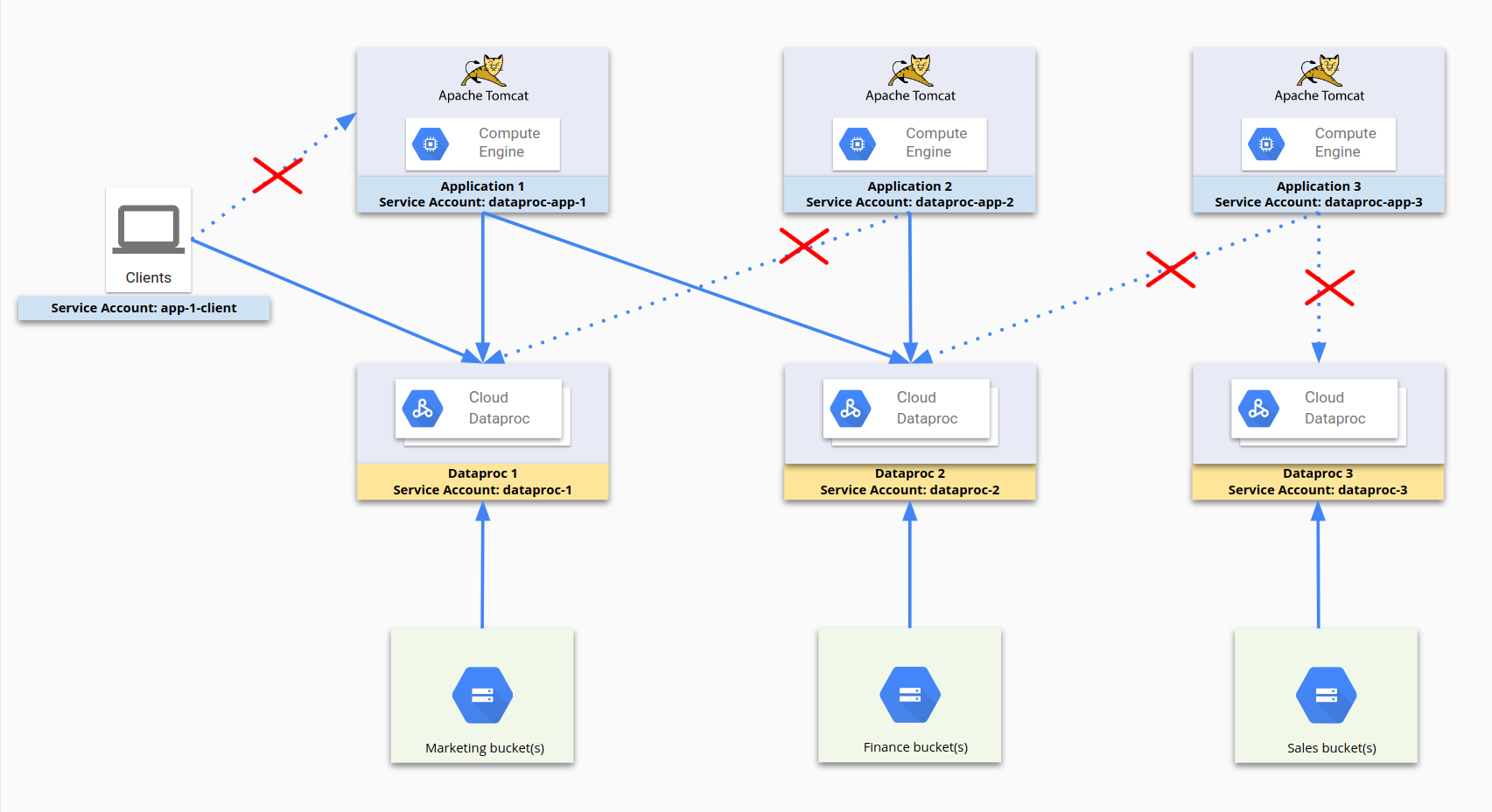
Pour cette configuration, les règles de pare-feu suivantes ont été définies :
| Nom de la règle | Paramètres |
|---|---|
dp1 |
Cible : dataproc-1Source : [Plage d'adresses IP] Autorité de contrôle source : dataproc-app-1Autoriser [ports] |
dp2 |
Cible : dataproc-2Source : [Plage d'adresses IP] Autorité de contrôle source : dataproc-app-2Autoriser [ports] |
dp2-2 |
Cible : dataproc-2Source : [Plage d'adresses IP] Autorité de contrôle source : dataproc-app-1Autoriser [ports] |
app-1-client |
Cible : dataproc-1Source : [Plage d'adresses IP] Autorité de contrôle source : app-1-clientAutoriser [ports] |
Pour en savoir plus sur l'utilisation des règles de pare-feu avec les comptes de service, consultez la section Filtrage source et cible par compte de service.
Rechercher les ports de pare-feu ouverts par mégarde
L'application de règles de pare-feu appropriées est également importante pour exposer les interfaces utilisateur Web qui s'exécutent sur le cluster. Vérifiez qu'aucun port de pare-feu ouvert sur Internet ne se connecte à ces interfaces. Les ports ouverts et les règles de pare-feu mal configurées peuvent permettre à des utilisateurs non autorisés d'exécuter du code arbitraire.
Par exemple, Apache Hadoop YARN fournit des API REST qui partagent les mêmes ports que les interfaces Web YARN. Par défaut, les utilisateurs autorisés à accéder à l'interface Web YARN peuvent créer des applications, envoyer des tâches, voire effectuer des opérations sur Cloud Storage.
Consultez les pages Configurations de réseau Dataproc et Créer un tunnel SSH pour établir une connexion sécurisée avec le contrôleur de votre cluster. Pour en savoir plus sur l'utilisation des règles de pare-feu avec les comptes de service, consultez la section Filtrage source et cible par compte de service.
Qu'en est-il des clusters mutualisés ?
D'une manière générale, il est recommandé d'exécuter des clusters Dataproc/Hadoop distincts pour différentes applications. Toutefois, si vous devez utiliser un cluster mutualisé tout en respectant les exigences de sécurité, vous pouvez créer des utilisateurs et des groupes Linux dans des clusters Dataproc/Hadoop afin de fournir une autorisation et une attribution de ressources via une file d'attente YARN. Vous devez mettre en place cette autorisation vous-même car il n'existe pas de mappage direct entre les utilisateurs Google et les utilisateurs Linux. L'activation de Kerberos sur le cluster permet de renforcer le niveau d'authentification dans le champ d'application du cluster.
Il arrive parfois que des utilisateurs, tels qu'un groupe de data scientists, utilisent un cluster Hadoop pour explorer les données et créer des modèles. Dans ces circonstances, il est préférable de regrouper les utilisateurs qui partagent le même accès aux données et de créer un cluster Dataproc/Hadoop dédié. De cette façon, vous pouvez ajouter des utilisateurs au groupe qui détient l'autorisation d'accès aux données. Les ressources du cluster peuvent également être attribuées en fonction de leurs utilisateurs Linux.