이 문서에서는 Google Cloud 지리정보 기능을 이해하고 지리정보 분석 애플리케이션에서 이러한 기능을 사용하는 방법을 이해하는 데 도움이 됩니다. 이 문서는 Google Cloud 에서 제공되는 제품과 서비스를 사용하여 비즈니스 이해관계자에게 지리정보 통계를 제공하고자 하는 지리정보 시스템 (GIS) 전문가, 데이터 과학자, 애플리케이션 개발자를 대상으로 합니다.
개요
Google Cloud 는 세계, 환경, 비즈니스에 대한 유용한 정보를 개발하는 데 도움이 되는 종합적인 지리정보 분석 및 머신러닝 기능을 제공합니다. 이러한 기능에서 얻을 수 있는 지리정보 통계는 기존 GIS 인프라를 관리하는 데 따르는 복잡성과 비용을 지불하지 않고도 더욱 정확하고 지속 가능한 비즈니스 의사 결정을 내릴 수 있도록 도와줍니다. Google Cloud
지리정보 분석 사용 사례
중요한 비즈니스 의사 결정의 상당수가 위치 데이터를 중심으로 고려됩니다. 지리정보 분석으로 얻은 유용한 정보는 다음 예시에 설명된 대로 여러 산업, 비즈니스, 시장에 적용할 수 있습니다.
- 환경 위험 평가. 홍수 및 산불과 같은 자연재해를 예측하여 환경 조건으로 인한 위험을 이해하여 위험을 더 효과적으로 예측하고 위험에 대한 계획을 수립할 수 있습니다.
- 사이트 선택 최적화. 독점 사이트 측정항목을 교통 패턴 및 지리적 이동성과 같은 공개적으로 제공되는 데이터와 결합한 후 지리정보 분석을 사용하여 비즈니스에 가장 적합한 위치를 찾고 재무 결과를 예측할 수 있습니다.
- 물류 및 운송 계획. 지리정보 데이터를 비즈니스 의사 결정에 통합하면 보다 효과적으로 라스트 마일 물류와 같은 차량 운영을 관리하고 자율 차량의 데이터를 분석하고 정밀 철도 사업을 관리하고, 이동성 계획을 개선할 수 있습니다.
- 토양 건강과 수확량 이해 및 개선. 토지의 수백만 에이커를 분석하여 토양 특성을 이해하고 농가에서 농사에 영향을 미치는 변수 간의 상호작용을 분석하도록 돕습니다.
- 지속 가능한 개발 관리. 경제, 환경, 사회적 조건을 매핑하여 환경을 보호 및 보존하는 중점 분야를 파악합니다.
지리정보 클라우드 구성 요소
지리정보 분석 아키텍처는 사용 사례 및 요구사항에 따라 하나 이상의 지리정보 클라우드 구성요소로 구성될 수 있습니다. 각 구성요소는 다양한 기능을 제공하며, 이들 구성요소는 함께 작동하여 확장 가능한 통합 지리정보 클라우드 분석 아키텍처를 형성합니다.
데이터는 지리정보 통계를 제공하는 원시 자료입니다. 고품질의 지리정보 데이터는 여러 공개 및 독점 소스에서 제공됩니다. 공개 데이터 소스에는 BigQuery 공개 데이터 세트, Earth Engine 카탈로그, 미국 지질조사국(USGS)가 포함됩니다. 독점 데이터 소스에는 SAP 및 Oracle과 같은 내부 시스템과 Esri ArcGIS Server, Carto, QGIS와 같은 내부 GIS 도구가 있습니다. 재고 관리, 마케팅 분석, 공급망 물류와 같은 여러 비즈니스 시스템의 데이터를 집계한 후 이 데이터를 지리정보 소스 데이터와 결합하여 결과를 지리정보 데이터 웨어하우스에 전송할 수 있습니다.
소스의 데이터 유형과 대상에 따라 지리정보 데이터 소스를 직접 분석 데이터 웨어하우스로 로드할 수도 있습니다. 예를 들어 BigQuery에서는 줄 바꿈으로 구분된 GeoJSON 파일 로드를 기본 지원하며 Earth Engine에는 포괄적인 분석 가능한 데이터 세트 모음과 통합된 데이터 카탈로그가 있습니다. 지리정보 데이터를 사전 처리하여Google Cloud의 엔터프라이즈 데이터 웨어하우스로 로드하는 지리정보 데이터 파이프라인을 통해 기타 데이터를 다른 형식으로 로드할 수 있습니다. Dataflow를 사용하여 프로덕션에 즉시 사용 가능한 데이터 파이프라인을 빌드할 수 있습니다. 또는 FME Spatial ETL과 같은 파트너 솔루션을 사용할 수 있습니다.
엔터프라이즈 데이터 웨어하우스는 지리정보 분석 플랫폼의 핵심입니다. 지리정보 데이터가 데이터 웨어하우스로 로드되면 다음 기능 중 일부를 사용하여 지리정보 애플리케이션과 통계를 빌드할 수 있습니다.
- BigQuery ML 및 Vertex AI에서 사용할 수 있는 머신러닝 기능
- BigQuery GeoViz, Looker Studio, Looker와 같은 보고 및 비즈니스 인텔리전스 도구
- Apigee와 같이 Google Cloud 에서 사용할 수 있는 API 서비스
- BigQuery에서 사용할 수 있는 지리정보 쿼리 및 분석 기능
- 지리정보 계산 및 쿼리를 수행할 수 있게 해주는 BigQuery의 SQL 지역 함수
- Earth Engine에 기본 제공되는 머신러닝 기능
그러면 이 아키텍처는 대규모 데이터를 저장, 처리, 관리하는 데 사용할 수 있는 단일 시스템 역할을 합니다. 또한 이 아키텍처를 사용하면 이러한 기능이 포함되지 않은 시스템에서 실행할 수 없는 통계를 생성할 수 있는 고급 분석 솔루션을 빌드하고 배포할 수 있습니다.
지리정보 데이터 유형, 형식, 좌표계
지리정보 데이터를 BigQuery와 같은 데이터 웨어하우스로 집계하려면 내부 시스템과 공개 소스에서 발생할 수 있는 지리정보 데이터 형식을 이해해야 합니다.
데이터 유형
지리정보 데이터 유형은 벡터와 래스터라는 두 가지 카테고리로 분류됩니다.
벡터 데이터는 다음 다이어그램과 같이 꼭짓점과 선 세그먼트로 구성됩니다.
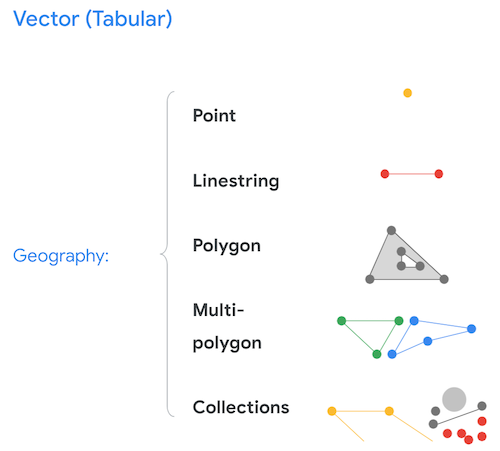
벡터 데이터의 예시로는 필지 경계, 공공 통행로(도로), 자산 위치가 있습니다. 벡터 데이터는 테이블 형식(행 및 열) 형식으로 저장할 수 있으므로 BigQuery, Cloud SQL의 PostGIS와 같은 지리정보 데이터베이스는 저장, 색인 생성, 벡터 데이터 분석에 탁월합니다.
래스터 데이터는 픽셀 그리드로 구성됩니다. 래스터 데이터의 예로는 다음 예시와 같이 대기 측정과 위성 이미지가 있습니다.

Earth Engine은 행성 규모의 래스터 데이터를 저장하고 분석할 수 있도록 설계되었습니다. Earth Engine에는 래스터를 벡터화하는 기능이 포함되어 있으므로 리전을 분류하고 래스터 데이터의 패턴을 파악할 수 있습니다. 예를 들어 시간에 따른 대기 래스터 데이터를 분석하여 풍류를 나타내는 벡터를 추출할 수 있습니다. 각 픽셀을 직접 벡터 형태로 변환하는 다각형화라고 하는 프로세스를 사용하여 각 개별 래스터 픽셀을 BigQuery로 로드할 수 있습니다.
지리정보 클라우드 애플리케이션은 두 가지 유형의 데이터를 결합해 각 카테고리의 데이터 소스의 강점을 활용하는 종합적인 통계를 생성합니다. 예를 들어 새로운 개발 사이트를 식별하는 데 도움이 되는 부동산 애플리케이션은 필지 경계와 같은 벡터 데이터를 고도 데이터와 같은 래스터 데이터와 결합하여 홍수 위험과 보험 비용을 최소화할 수 있습니다.
데이터 형식
다음 표에는 널리 사용되는 지리정보 데이터 형식과 이를 분석 플랫폼에서 사용하는 방법이 나와 있습니다.
| 데이터 소스 형식 | 설명 | 예시 |
|---|---|---|
| Shapefile | Esri에서 개발한 벡터 데이터 형식입니다. 이 형식을 사용하면 기하학적 위치를 저장하고 속성을 연결할 수 있습니다. | 인구조사 지역 지형, 건물 차지 공간 |
| WKT | OGC에서 게시한 사람이 읽을 수 있는 벡터 데이터 형식입니다. 이 형식은 BigQuery에서 기본 지원됩니다. | CSV 파일에서 지형 표현 |
| WKB | WKT에 상응하는 스토리지 효율적인 바이너리입니다. 이 형식은 BigQuery에서 기본 지원됩니다. | CSV 파일 및 데이터베이스의 지형 표현 |
| KML | Google 어스 및 기타 데스크톱 도구에서 사용하는 XML 호환 벡터 형식입니다. OGC에서 형식을 게시합니다. | 3D 빌딩 모양, 도로, 토지 특징 |
| Geojson | JSON 기반의 개방형 벡터 데이터 형식입니다. | 웹브라우저 및 모바일 애플리케이션의 기능 |
| GeoTIFF | 널리 사용되는 래스터 데이터 형식입니다. 이 형식을 사용하면 TIFF 이미지의 픽셀을 지리 좌표에 매핑할 수 있습니다. | 디지털 고도 모델인 Landsat입니다. |
좌표 참조 시스템
유형 및 형식에 관계없이 모든 지리 공간 데이터에는 좌표 참조 시스템이 포함되어 있습니다. 이 시스템을 사용하면 BigQuery 및 Earth Engine과 같은 지리정보 분석 도구가 지구 표면의 물리적 위치 좌표에 연결될 수 있습니다. 좌표 기준 시스템 유형에는 측지 및 평면 등 두 가지 유형이 있습니다.
측지 데이터는 지구의 곡선을 고려하고 지리 좌표(경도 및 위도)를 기반으로 하는 좌표계를 사용합니다. 측지 모양을 일반적으로 지역이라고 합니다. BigQuery에서 사용하는 WGS 84 좌표 참조 시스템은 측지 좌표계입니다.
평면 데이터는 Mercator와 같은 지도 투영을 기반으로 하며 지리 좌표를 2차원 평면에 매핑합니다. 평면 데이터를 BigQuery로 로드하려면 평면 데이터를 WGS 84 좌표계로 다시 투영해야 합니다. 기존 GIS 도구를 사용하거나 지리정보 클라우드 데이터 파이프라인을 사용하여 수동으로 다시 투영할 수 있습니다(다음 섹션 참조).
지리정보 클라우드 데이터 파이프라인 빌드 고려사항
앞에서 설명한 것처럼 데이터 유형에 따라 일부 지리정보 데이터를 BigQuery 및 Earth Engine에 직접 로드할 수 있습니다. 데이터에서 WGS 84 참조 시스템을 사용하는 경우 BigQuery를 통해 WKT, WKB, GeoJSON 파일 형식으로 벡터 데이터를 로드할 수 있습니다. Earth Engine은 Earth Engine 카탈로그에서 제공되는 데이터와 직접 통합되며 GeoTIFF 파일 형식으로 래스터 이미지를 직접 로드할 수 있습니다.
다른 형식으로 저장되고 BigQuery로 직접 로드할 수 없는 지리정보 데이터가 표시될 수 있습니다. 또는 데이터가 먼저 WGS 84 기준 시스템으로 다시 투영해야 하는 좌표 기준 시스템에 있을 수 있습니다. 마찬가지로 오류를 사전 처리, 단순화, 수정해야 하는 데이터가 표시될 수도 있습니다.
Dataflow로 지리정보 데이터 파이프라인을 빌드하여 사전 처리된 지리정보 데이터를 BigQuery로 로드할 수 있습니다. Dataflow는 대규모 데이터의 스트리밍 및 일괄 처리를 지원하는 관리형 분석 서비스입니다.
Apache Beam을 확장하고 Dataflow에 지리정보 처리 기능을 추가하는 geobeam Python 라이브러리를 사용할 수 있습니다. 이 라이브러리를 사용하면 다양한 소스에서 지리정보 데이터를 읽을 수 있습니다. 또한 라이브러리는 데이터를 처리 및 변환하고 BigQuery로 로드하여 지리정보 클라우드 데이터 웨어하우스로 사용하는 데 도움이 됩니다. geobeam 라이브러리는 오픈소스이므로 추가 형식과 사전 처리 태스크를 지원하도록 라이브러리를 수정하고 확장할 수 있습니다.
Dataflow 및 geobeam 라이브러리를 사용하여 대량의 지리정보 데이터를 병렬로 수집하고 분석할 수 있습니다. geobeam 라이브러리는 커스텀 I/O 커넥터를 구현하면 작동합니다. geobeam 라이브러리에는 GDAL, PROJ, 기타 관련 라이브러리가 포함되어 있으므로 지리정보 데이터를 간편하게 처리할 수 있습니다. 예를 들어 geobeam은 모든 입력 도형을 자동으로 BigQuery에서 사용하는 WGS84 좌표계로 다시 투영하여 공간 데이터를 저장, 클러스터링, 처리합니다.
geobeam 라이브러리는 Apache Beam 설계 패턴을 따르므로 공간 파이프라인은 비공간 파이프라인과 유사하게 작동합니다. 차이점은 geobeam 커스텀 FileBasedSource 클래스를 사용하여 공간 소스 파일에서 읽는다는 점입니다. 기본 제공되는 geobeam 변환 함수를 사용하여 공간 데이터를 처리하고 자체 함수를 구현할 수도 있습니다.
다음 예시에서는 래스터 파일을 읽고 래스터를 다각형화하여 WGS 84로 다시 투영하고 BigQuery에 다각형을 쓰는 파이프라인을 보여줍니다.
with beam.Pipeline(options=pipeline_options) as p:
(p
| beam.io.Read(GeotiffSource(known_args.gcs_url))
| 'MakeValid' >> beam.Map(geobeam.fn.make_valid)
| 'FilterInvalid' >> beam.Filter(geobeam.fn.filter_invalid)
| 'FormatRecords' >> beam.Map(geobeam.fn.format_record,
known_args.band_column, known_args.band_type)
| 'WriteToBigQuery' >> beam.io.WriteToBigQuery('DATASET.TABLE'))
BigQuery에서 지리정보 데이터 분석
데이터가 BigQuery에 있으면 데이터를 변환, 분석, 모델링할 수 있습니다. 예를 들어 해당 지역의 교차로를 계산하고 표준 SQL을 사용하여 테이블을 조인하면 토지 구획의 평균 고도를 쿼리할 수 있습니다. BigQuery는 새로운 지역 값 구성, 지역 측정값 계산, 두 지역 간의 관계 살펴보기 등을 수행할 수 있게 해주는 다양한 함수를 제공합니다. BigQuery S2 함수를 사용하여 S2 그리드 셀로 계층적 지리정보 색인을 생성할 수 있습니다. 또한 BigQuery ML의 머신러닝 기능을 사용하여 지리정보 데이터를 클러스터링하도록 k-평균 머신러닝 모델을 만들기와 같이 데이터의 패턴을 식별할 수 있습니다.
지리정보 시각화, 보고서, 배포
Google Cloud 는 공간 데이터와 통계를 시각화하고 보고하여 사용자와 애플리케이션에 제공하는 몇 가지 옵션을 제공합니다. 공간 정보를 나타내는 방법은 비즈니스 요구사항과 목표에 따라 다릅니다. 모든 공간 정보가 그래픽으로 표현되지는 않습니다. 많은 정보가 사용자 대상 애플리케이션의 기능을 강화할 수 있도록 Apigee와 같은 API 서비스를 통해 제공되거나 Firestore와 같은 애플리케이션 데이터베이스에 저장하여 제공되는 것이 좋습니다.
지리정보 분석에 대해 테스트하고 프로토타입을 제작하면서 BigQuery GeoViz를 사용하여 쿼리를 검증하고 BigQuery에서 시각적 출력을 생성할 수 있습니다. 비즈니스 인텔리전스 보고를 위해 Looker Studio 또는 Looker를 사용하여 BigQuery에 연결하고 지리정보 시각화를 다양한 보고 유형에 결합할 수 있으며 이를 통해 필요한 정보에 대한 통합 뷰를 제시할 수 있습니다.
사용자가 지리정보 데이터 및 통계 정보와 상호작용하고 해당 정보를 비즈니스 애플리케이션에 통합할 수 있는 애플리케이션을 빌드할 수도 있습니다. 예를 들어 Google Maps Platform을 사용하면 지리정보 분석, 머신러닝, 지도 API의 데이터를 단일 지도 기반 애플리케이션으로 결합할 수 있습니다. deck.gl과 같은 오픈소스 라이브러리를 사용하면 고성능 시각화 및 애니메이션을 포함시켜 지도 기반 스토리를 얘기하고 데이터를 보다 효과적으로 표현할 수 있습니다.
Google은 또한 지리정보를 최대한 활용할 수 있는 강력하고 성장 중인 파트너 제품 생태계를 갖추고 있습니다. Carto, NGIS, Climate Engine을 비롯하여 각각의 전문 기능과 제품을 제공하여 업계 및 비즈니스에 따라 맞춤 설정할 수 있습니다.
참조 아키텍처
다음 다이어그램에서는 지리정보 클라우드 구성요소 상호작용 방식을 보여주는 참조 아키텍처를 보여줍니다. 이 아키텍처에는 지리정보 데이터 파이프라인과 지리정보 분석 플랫폼이라는 두 가지 핵심 구성요소가 있습니다.

다이어그램에 표시된 것처럼 지리정보 소스 데이터가 Cloud Storage 및 Earth Engine에 로드됩니다. 이러한 제품 중 하나에서 geobeam을 사용하는 Dataflow 파이프라인을 통해 데이터를 로드하여 특성 유효성 검사 및 도형 다시 투영과 같은 일반적인 사전 처리 작업을 수행할 수 있습니다. Dataflow에서 파이프라인 출력을 BigQuery에 씁니다. 데이터가 BigQuery에 있으면 BigQuery 분석과 머신러닝을 사용하여 데이터를 그대로 분석하거나 Looker Studio, Looker, Vertex AI, Apigee와 같은 다른 서비스에서 데이터에 액세스할 수 있습니다.
다음 단계
- 지리정보 분석 시작하기
- BigQuery 지리정보 튜토리얼
- Earth Engine 튜토리얼
- 지리정보 분석 및 AI
- Google Cloud의 AI 및 ML 워크로드와 관련된 아키텍처 원칙 및 권장사항에 관한 개요는 아키텍처 프레임워크의 AI 및 ML 관점을 참고하세요.