Dokumen ini menjelaskan kepada para peneliti, data scientist, dan analis bisnis mengenai proses dan pertimbangan untuk menganalisis data Fast Healthcare Interoperability Resources (FHIR) di BigQuery.
Secara khusus, dokumen ini berfokus pada data resource pasien yang diekspor dari penyimpanan FHIR di Cloud Healthcare API. Dokumen ini juga memandu serangkaian kueri yang menunjukkan cara kerja data skema FHIR dalam format relasional, dan menunjukkan cara mengakses kueri ini untuk digunakan kembali melalui tampilan.
Menggunakan BigQuery untuk menganalisis data FHIR
API khusus FHIR Cloud Healthcare API dirancang untuk interaksi transaksional real-time dengan data FHIR di tingkat satu resource FHIR atau kumpulan resource FHIR. Namun, FHIR API tidak dirancang untuk kasus penggunaan analisis. Untuk kasus penggunaan ini, sebaiknya mengekspor data Anda dari FHIR API ke BigQuery. BigQuery adalah data warehouse skalabel tanpa server yang memungkinkan Anda menganalisis data dalam jumlah besar secara retrospektif atau prospektif.
Selain itu, BigQuery sesuai dengan ANSI:2011 SQL, yang menjadikan data dapat diakses oleh data scientist dan analis bisnis melalui alat yang biasa mereka gunakan, seperti Tableau, Looker, atau Vertex AI Workbench.
Di beberapa aplikasi, seperti Vertex AI Workbench, Anda mendapatkan akses melalui klien bawaan, seperti library Klien Python untuk BigQuery. Dalam hal ini, data yang ditampilkan ke aplikasi tersedia melalui struktur data bahasa bawaan.
Mengakses BigQuery
Anda dapat mengakses BigQuery melalui UI web BigQuery dengan konsol Google Cloud, dan juga dengan alat berikut:
- Alat command line BigQuery
- REST API atau library klien BigQuery
- Driver ODBC dan JDBC
Dengan menggunakan alat ini, Anda dapat mengintegrasi BigQuery ke hampir semua aplikasi.
Bekerja dengan struktur data FHIR
Struktur data standar FHIR bawaan bersifat kompleks, dengan jenis dataFHIR
bertingkat dan tersemat
di seluruh resource FHIR. Jenis data FHIR yang dapat disematkan ini disebut sebagai jenis data kompleks.
Array dan struktur juga disebut sebagai jenis data kompleks dalam database relasional. Struktur data standar FHIR bawaan berfungsi dengan baik diserialisasi sebagai file XML atau JSON dalam sistem yang berorientasi dokumen, tetapi strukturnya kemungkinan sulit untuk digunakan saat diterjemahkan ke dalam database relasional.
Screenshot berikut menunjukkan sebagian tampilan jenis data FHIR
patient resource
yang menggambarkan sifat kompleks struktur data standar FHIR
bawaan.
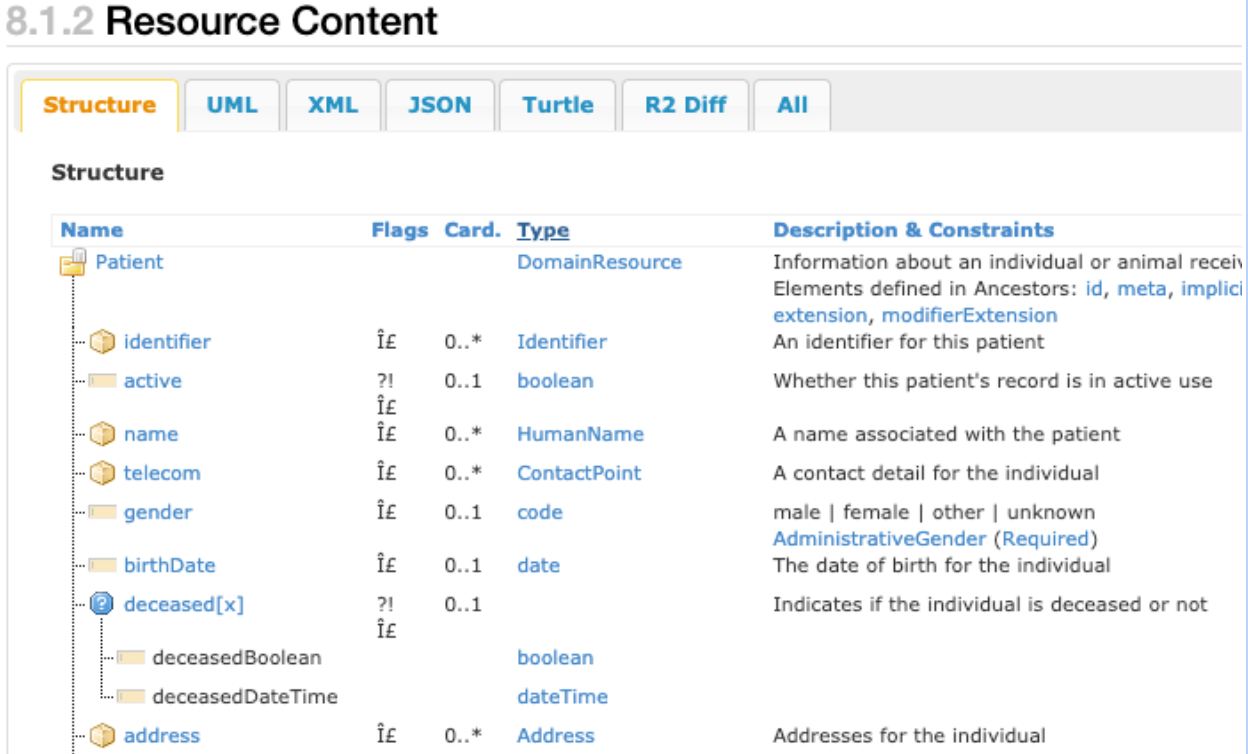
Screenshot sebelumnya menunjukkan komponen utama jenis data patient
resource FHIR. Misalnya, kolom kardinalitas (ditunjukkan dalam tabel sebagai Kartu.) yang menunjukkan beberapa item yang dapat memiliki nol, satu, atau lebih dari satu entri. Kolom Jenis menampilkan
Identifier,
HumanName,
dan
Address, jenis data yang merupakan contoh jenis data kompleks yang membentuk jenis data patient
resource. Setiap baris dapat direkam beberapa kali, sebagai sebuah struktur array.
Menggunakan array dan struktur
BigQuery mendukung array dan
STRUCT jenis data—struktur data bertingkat
dan berulang—seperti yang direpresentasikan dalam resource FHIR, yang memungkinkan
konversi data dari FHIR ke BigQuery.
Dalam BigQuery, sebuah array adalah daftar berurutan yang terdiri dari nol atau beberapa nilai dari jenis data yang sama. Anda dapat membuat array jenis data sederhana, seperti INT64 jenis data ,dan jenis data kompleks, seperti STRUCT jenis data . Pengecualian untuk jenis data ARRAY ,karena array dari array saat ini tidak didukung. Dalam BigQuery, struktur array muncul sebagai kumpulan data yang dapat diulang.
Anda dapat menentukan data bertingkat, ataupun data bertingkat dan berulang, pada UI BigQuery atau dalam file skema JSON. Untuk menentukan kolom bertingkat, ataupun kolom bertingkat dan berulang, gunakan jenis data RECORD (STRUCT).
Cloud Healthcare API mendukung SQL pada skema FHIR di BigQuery. Skema analisis ini adalah skema default pada metode ExportResources() dan didukung oleh komunitas FHIR.
BigQuery mendukung data yang didenormalisasi. Artinya, saat Anda menyimpan data, Anda dapat melakukan denormalisasi data dan menggunakan kolom bertingkat dan berulang, bukan membuat skema relasional seperti skema bintang atau kepingan salju. Kolom bertingkat dan berulang mempertahankan hubungan antar-elemen data tanpa dampak performa dari mempertahankan skema relasional (dinormalisasi).
Mengakses data Anda melalui operator UNNEST
Setiap resource FHIR di FHIR API diekspor ke BigQuery berupa
satu baris data. Anda dapat menganggap bahwa array atau struktur di dalam baris mana pun sebagai tabel tersemat. Anda dapat mengakses data dalam "tabel" tersebut dalam klausa SELECT
atau klausa WHERE dari kueri Anda dengan
meratakan array atau struktur menggunakan UNNEST operator.
Operator UNNEST mengambil array dan menampilkan tabel dengan satu baris
untuk setiap elemen dalam array. Untuk mengetahui informasi selengkapnya, baca
bekerja menggunakan array dalam SQL standar.
Operasi UNNEST tidak mempertahankan urutan elemen array, tetapi Anda dapat mengurutkan ulang tabel menggunakan klausa WITH OFFSET secara opsional. Tindakan ini
menampilkan kolom tambahan dengan klausa OFFSET untuk setiap elemen array.
Kemudian, Anda dapat menggunakan klausa ORDER BY untuk mengurutkan baris berdasarkan selisihnya.
Saat menggabungkan data tidak bertingkat, BigQuery menggunakan operasi
CROSS JOIN
berkorelasi yang mereferensikan kolom array dari setiap item dalam array dengan
tabel sumber, yaitu tabel yang tepat mendahului panggilan keUNNEST
dalam klausa FROM. Untuk setiap baris dalam tabel sumber, operasi UNNEST
meratakan array dari baris tersebut menjadi kumpulan baris yang berisi elemen
array. Operasi CROSS JOIN yang berkorelasi menggabungkan kumpulan baris baru ini dengan
satu baris dari tabel sumber.
Menyelidiki skema menggunakan kueri
Untuk membuat kueri data FHIR di BigQuery, Anda harus memahami skema yang dibuat melalui proses ekspor. BigQuery memungkinkan Anda memeriksa struktur kolom setiap tabel dalam set data melalui fitur INFORMATION_SCHEMA, serangkaian tampilan yang menampilkan metadata. Bagian selanjutnya dari dokumen ini
mengacu pada
SQL skema FHIR,
yang didesain agar dapat diakses untuk mengambil data.
Contoh kueri berikut mengeksplorasi detail kolom untuk tabel pasien dalam skema SQL di FHIR. Kueri mereferensi ke set data publik Data Sintetis yang Dihasilkan Sintea di FHIR, yang menghosting lebih dari 1 juta catatan pasien sintetis yang dihasilkan dalam format Synthea dan FHIR.
Saat Anda membuat kueri tampilan INFORMATION_SCHEMA.COLUMNS, hasil kueri akan berisi satu baris untuk setiap kolom dalam tabel. Kueri berikutnya menampilkan semua kolom di tabel pasien:
SELECT * FROM `bigquery-public-data.fhir_synthea.INFORMATION_SCHEMA.COLUMNS` WHERE table_name='patient'
Screenshot hasil kueri berikut ini menunjukkan jenis data identifier,
dan array dalam jenis data yang berisi jenis data STRUCT.

Menggunakan resource pasien FHIR pada BigQuery
Nomor rekam medis pasien (MRN), bagian penting dari informasi yang disimpan dalam data FHIR Anda, digunakan di seluruh sistem data organisasi klinis dan operasional untuk semua pasien. Metode apa pun yang akan mengakses data untuk pasien secara individual atau sekumpulan pasien harus memfilter atau menampilkan MRN, atau melakukan keduanya.
Contoh kueri berikut menampilkan ID server FHIR internal ke resource pasien itu sendiri, termasuk MRN dan tanggal lahir untuk semua pasien. Filter untuk membuat kueri MRN tertentu juga disertakan, tetapi diberi komentar dalam contoh ini.
Dalam kueri ini, Anda membatalkan jenis data kompleks identifier dua kali. Anda juga menggunakan
operasi CROSS JOIN yang berkorelasi untuk menggabungkan data tidak bertingkat dengan tabel sumbernya.
Tabel bigquery-public-data.fhir_synthea.patient dalam kueri dibuat menggunakan
SQL di versi skema FHIR dari FHIR ke BigQuery Export.
SELECT id, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b"
Outputnya mirip dengan hal berikut ini:
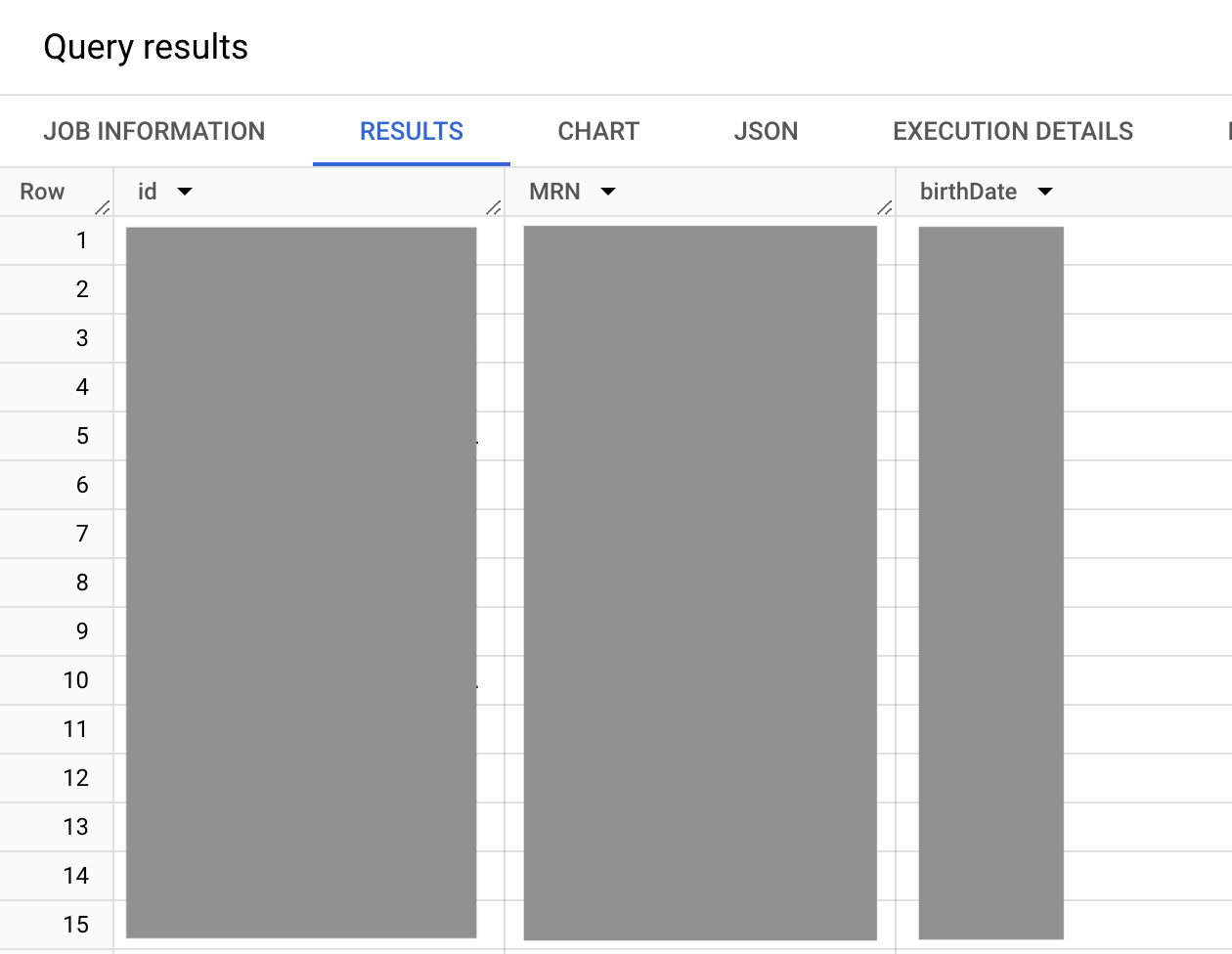
Dalam kueri sebelumnya, kumpulan nilai identifier.type.coding.code adalah
kumpulan nilai identifier FHIR
yang menghitung jenis data identitas yang tersedia, seperti MRN (MR jenis
data identitas), surat izin mengemudi (jenis data identitas DL), dan nomor paspor
(jenis data identitas PPN). Karena identifier.type.coding kumpulan nilai adalah sebuah
array, kemungkinan terdapat sejumlah ID yang tercantum untuk pasien. Namun, dalam
hal ini, Anda perlu menggunakan MRN (jenis data identitas MR).
Menggabungkan tabel pasien dengan tabel lain
Berpijak pada kueri tabel pasien, Anda dapat menggabungkan tabel pasien dengan tabel lain dalam set data ini, seperti tabel kondisi. Tabel kondisi adalah tempat diagnosa pasien direkam.
Contoh kueri berikut mengambil semua entri untuk kondisi medis hipertensi.
SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003'
Outputnya mirip dengan hal berikut ini:
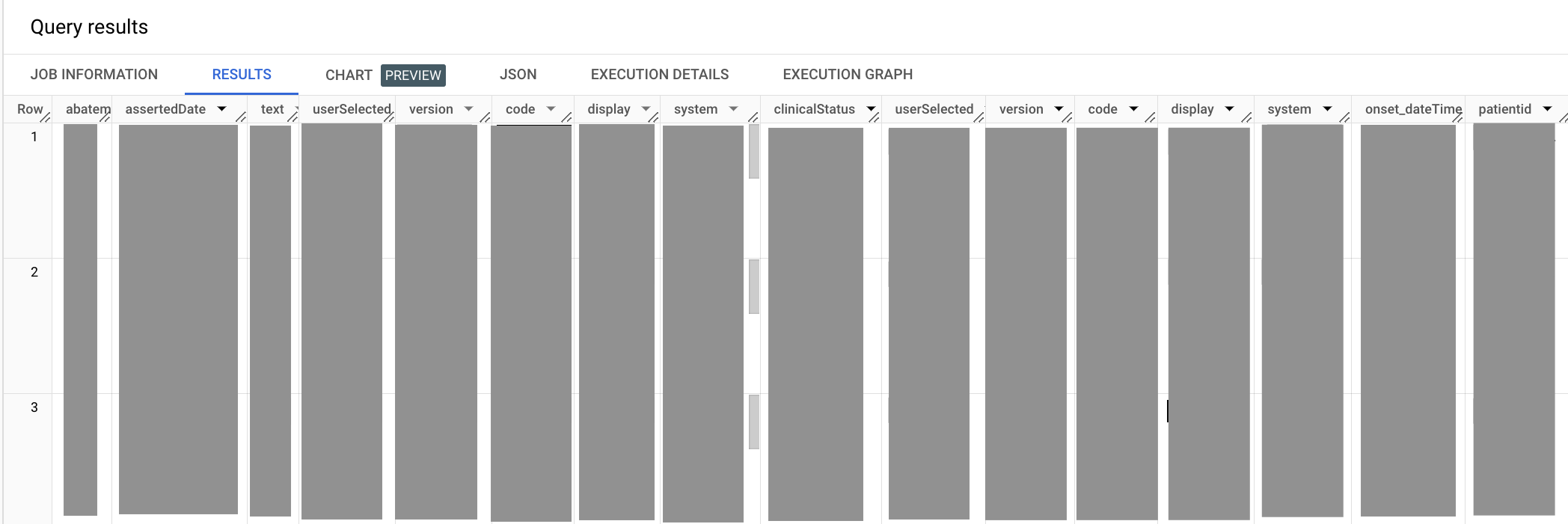
Pada kueri sebelumnya, Anda menggunakan kembali metode UNNEST untuk meratakan
kolom code.coding. Aplikasi abatement.dateTime dan padaonset.dateTime elemen
kode diSELECT pernyataan tersebut diberi alias karena keduanya berakhir dengan
dateTime, yang akan mengakibatkan nama kolom ambigu dalam output
SELECT pernyataan pribadi Anda. Saat memilih kode Hypertension, Anda juga harus
mendeklarasikan sistem terminologi asal kode—dalam hal ini, sistem terminologi klinis
SNOMED CT.
Sebagai langkah terakhir, gunakan kunci subject.patientid untuk menggabungkan tabel kondisi
dengan tabel pasien. Kunci ini mengarah pada ID resource
pasien itu sendiri di dalam server FHIR.
Menyatukan kueri
Pada contoh kueri berikut, Anda menggunakan kueri dari dua bagian
sebelumnya dan menggabungkannya menggunakan klausa
WITH, sembari melakukan beberapa penghitungan sederhana.
WITH patient AS ( SELECT id as patientid, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b" ), condition AS ( SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003' ) SELECT patient.patientid, patient.MRN, patient.birthDate as birthDate_string, #current patient age. now - birthdate CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH)/12 AS INT) as patient_current_age_years, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH) AS INT) as patient_current_age_months, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),DAY) AS INT) as patient_current_age_days, #age at onset. onset date - birthdate DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset, condition.onset_dateTime, condition.code.code, condition.code.display, condition.code.system FROM patient JOIN condition ON patient.patientid = condition.patientid
Outputnya mirip dengan hal berikut ini:
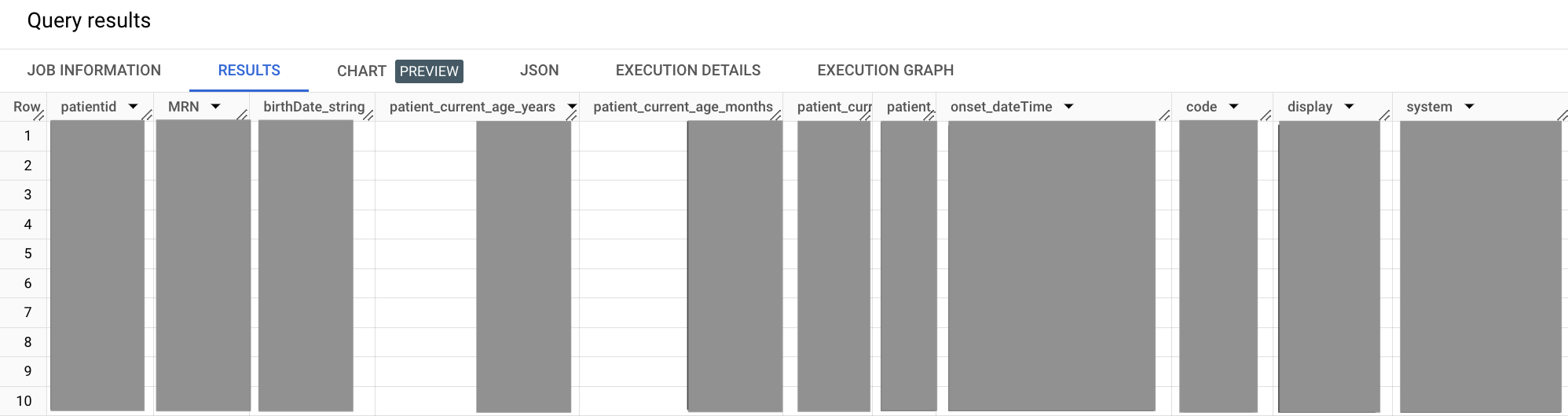
Dalam contoh kueri sebelumnya, klausa WITH memungkinkan Anda mengisolasi subkueri
ke dalam segmen yang ditentukan sendiri. Pendekatan ini dapat membantu kejelasan, yang
menjadi lebih penting saat kueri Anda bertambah besar. Dalam kueri ini, Anda mengisolasi
subkueri untuk pasien dan kondisi ke dalam segmen WITH mereka sendiri, lalu
menggabungkannya ke segmen SELECT utama.
Anda juga dapat menerapkan kalkulasi pada data mentah. Kode contoh berikut
pernyataan SELECT, menunjukkan cara menghitung usia pasien saat awal pasien mengidap penyakit.
DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset
Sebagaimana yang ditunjukkan dalam contoh kode sebelumnya, Anda dapat menjalankan sejumlah
operasi pada string dateTime yang disediakan, condition.onset_dateTime. Pertama,
pilih komponen tanggal string dengan
nilai
SUBSTR. Kemudian, konversikan string menjadi jenis data DATE dengan menggunakan sintaksis
CAST. Anda juga akan mengonversi kolom patient.birthDate menjadi kolom DATE.
Terakhir, hitung perbedaan antara dua tanggal tersebut menggunakan fungsi
DATE_DIFF.
Langkah berikutnya
- Menganalisis data klinis menggunakan BigQuery dan Notebooks AI Platform.
- Tutorial: Memvisualisasikan Data BigQuery di Notebook Jupyter
- Keamanan Cloud Healthcare API.
- Kontrol akses BigQuery.
- Solusi layanan kesehatan dan ilmu hayati di Google Cloud Marketplace.
- Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.