Dokumen ini menjelaskan contoh pipeline yang diimplementasikan di Google Cloud yang melakukan pemodelan kecenderungan. Aplikasi ini ditujukan untuk data engineer, engineer machine learning, atau tim ilmu pemasaran yang membuat dan men-deploy model machine learning. Dokumen ini mengasumsikan bahwa Anda mengetahui konsep machine learning dan sudah terbiasa dengan Google Cloud, BigQuery, Vertex AI Pipelines, Python, dan notebook Jupyter. Dokumen ini juga mengasumsikan bahwa Anda memiliki pemahaman tentang Google Analytics 4 dan fitur ekspor mentah di BigQuery.
Pipeline yang Anda gunakan menggunakan data contoh Google Analytics. Pipeline ini membangun beberapa model menggunakan BigQuery ML dan XGBoost, dan Anda menjalankan pipeline menggunakan Vertex AI Pipelines. Dokumen ini menjelaskan proses melatih model, mengevaluasi, dan men-deploy model tersebut. Panduan ini juga menjelaskan cara mengotomatiskan seluruh proses.
Kode pipeline yang lengkap tersedia dalam notebook Jupyter di repositori GitHub.
Apa itu pemodelan kecenderungan?
Pemodelan kecenderungan memprediksi tindakan yang mungkin diambil konsumen. Contoh pemodelan kecenderungan mencakup prediksi konsumen mana yang cenderung membeli suatu produk, mendaftar ke layanan, atau bahkan melakukan churn dan tidak lagi menjadi pelanggan aktif untuk suatu merek.
Output model kecenderungan adalah skor antara 0 dan 1 untuk setiap konsumen, dimana skor ini menunjukkan seberapa besar kemungkinan konsumen melakukan tindakan tersebut. Salah satu pendorong utama yang membuat organisasi melakukan pemodelan kecenderungan adalah kebutuhan untuk melakukan lebih banyak hal dengan data pihak pertama. Untuk kasus penggunaan pemasaran, model kecenderungan terbaik menyertakan sinyal dari sumber online dan offline, seperti analisis situs dan data CRM.
Demo ini menggunakan contoh data GA4 yang ada di BigQuery. Untuk kasus penggunaan Anda, sebaiknya pertimbangkan sinyal offline tambahan.
Cara MLOps menyederhanakan pipeline ML Anda
Sebagian besar model ML tidak digunakan dalam produksi. Hasil model menghasilkan insight, dan setelah tim data science menyelesaikan suatu model, tim engineering ML atau software engineering perlu menggabungkannya ke dalam kode untuk produksi menggunakan framework seperti Flask atau FastAPI. Proses ini sering kali mengharuskan model di-build dalam framework baru, yang berarti data harus ditransformasikan ulang. Pekerjaan ini dapat memakan waktu berminggu-minggu atau berbulan-bulan, hingga bahkan banyak model yang tidak sampai ke tahap produksi.
Operasi machine learning (MLOps) telah menjadi hal penting untuk mendapatkan nilai dari project ML, serta MLOps, dan sekarang menjadi keahlian yang terus berkembang untuk organisasi data science. Untuk membantu organisasi memahami nilai ini, Google Cloud telah memublikasikan Panduan Praktisi untuk MLOps yang memberikan ringkasan MLOps.
Dengan menggunakan prinsip-prinsip MLOps dan Google Cloud, Anda dapat mengirim model ke endpoint menggunakan proses otomatis yang menghapus sebagian besar kerumitan proses manual. Alat dan proses yang dijelaskan dalam dokumen ini membahas pendekatan untuk memiliki pipeline secara menyeluruh, yang membantu Anda memasukkan model Anda ke dalam produksi. Dokumen panduan praktisi yang disebutkan sebelumnya memberikan solusi horizontal dan garis besar tentang kemungkinan penggunaan MLOps dan Google Cloud.
Apa yang dimaksud dengan Vertex AI Pipelines?
Vertex AI Pipelines memungkinkan Anda menjalankan pipeline ML yang dibuat menggunakan Kubeflow Pipelines SDK atau TensorFlow Extended (TFX). Tanpa Vertex AI, menjalankan salah satu framework open source ini dalam skala besar mengharuskan Anda menyiapkan dan mengelola cluster Kubernetes sendiri. Vertex AI Pipelines dapat mengatasi tantangan ini. Karena merupakan layanan terkelola, layanan ini dapat meningkatkan atau menurunkan skala sesuai kebutuhan, dan tidak memerlukan pemeliharaan yang berkelanjutan.
Setiap langkah dalam proses Vertex AI Pipelines terdiri dari penampung independen yang dapat mengambil input atau menghasilkan output dalam bentuk artefak. Misalnya, jika suatu langkah dalam proses membangun set data Anda, output-nya adalah artefak set data. Artefak set data ini dapat digunakan sebagai input untuk langkah berikutnya. Karena setiap komponen adalah penampung terpisah, Anda harus memberikan informasi untuk setiap komponen pipeline, seperti nama image dasar dan daftar dependensi apa pun.
Proses build pipeline
Contoh yang dijelaskan dalam dokumen ini menggunakan notebook Jupyter untuk membuat komponen pipeline serta mengompilasi, menjalankan, dan mengotomatiskannya. Seperti disebutkan sebelumnya, notebook ini tersedia di repositori GitHub.
Anda dapat menjalankan kode notebook menggunakan instance notebook yang dikelola pengguna Vertex AI Workbench, yang menangani autentikasi untuk Anda. Vertex AI Workbench memungkinkan Anda bekerja dengan notebook untuk membuat mesin, membangun notebook, dan terhubung ke Git. (Vertex AI Workbench menyertakan banyak fitur lainnya, tetapi fitur tersebut tidak dibahas dalam dokumen ini.)
Setelah operasi pipeline selesai, diagram serupa seperti diagram berikut akan dibuat di Vertex AI Pipelines:
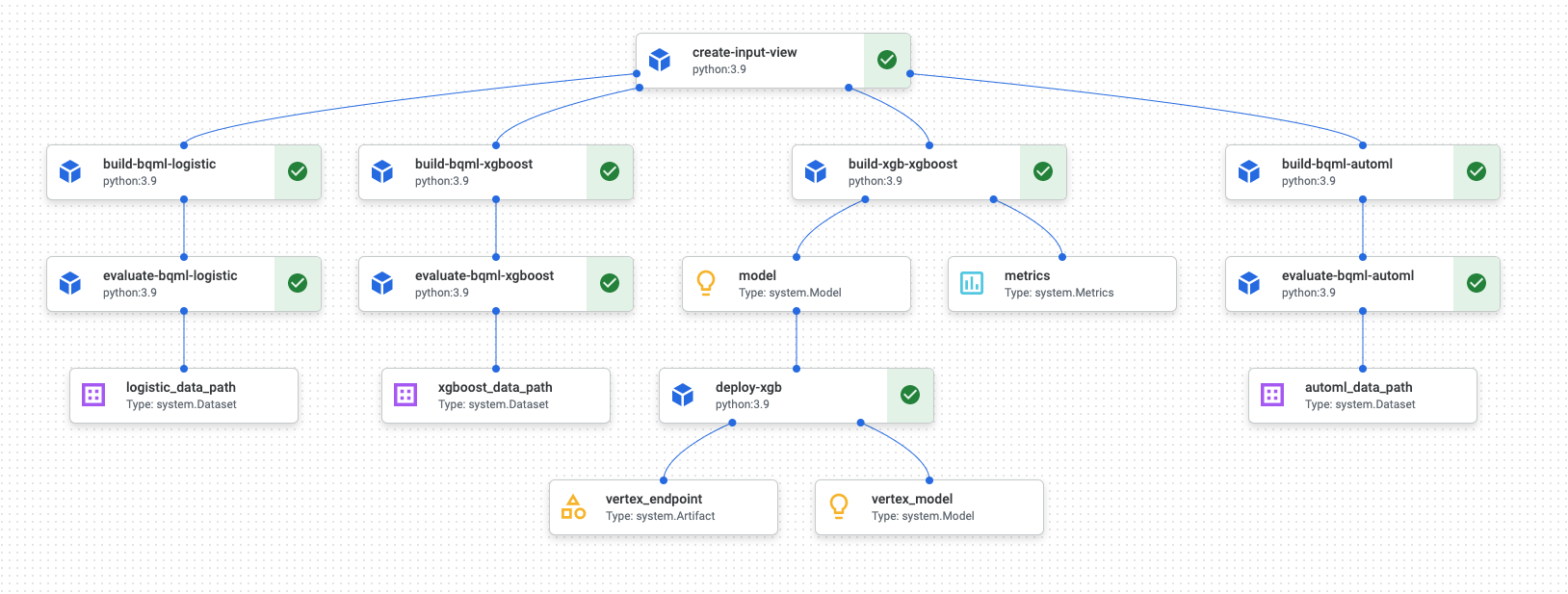
Diagram sebelumnya merupakan directed acyclic graph (DAG). Membuat dan meninjau DAG adalah langkah terpusat untuk memahami pipeline data atau ML Anda. Atribut utama DAG adalah komponen mengalir dalam satu arah (dalam hal ini, dari atas ke bawah) dan tidak ada siklus yang terjadi, yaitu komponen induk tidak bergantung pada komponen turunan. Beberapa komponen dapat muncul secara paralel, sementara komponen lainnya memiliki dependensi sehingga muncul secara berurutan.
Kotak centang hijau di setiap komponen menandakan bahwa kode berjalan dengan benar. Jika terjadi error, Anda akan melihat tanda seru berwarna merah. Anda dapat mengklik setiap komponen dalam diagram untuk melihat detail tugas selengkapnya.
Diagram DAG disertakan dalam bagian dokumen ini dan berfungsi sebagai cetak biru untuk setiap komponen yang dibangun oleh pipeline. Daftar berikut memberikan deskripsi setiap komponen.
Pipeline yang lengkap melakukan langkah-langkah berikut, seperti yang ditunjukkan pada diagram DAG:
create-input-view: Komponen ini membuat tampilan BigQuery. Komponen ini menyalin SQL dari bucket Cloud Storage dan mengisi parameter value yang Anda berikan. Tampilan BigQuery ini adalah set data input yang digunakan untuk semua model nanti di pipeline.build-bqml-logistic: Pipeline menggunakan BigQuery ML untuk membuat model regresi logistik. Setelah komponen ini selesai, model baru dapat dilihat di konsol BigQuery. Anda dapat menggunakan objek model ini untuk melihat performa model dan untuk membuat prediksi nantinya.evaluate-bqml-logistic: Pipeline menggunakan komponen ini untuk membuat kurva presisi/perolehan (logistic_data_pathpada diagram DAG) untuk regresi logistik. Artefak ini disimpan dalam bucket Cloud Storage.build-bqml-xgboost: Komponen ini membuat model XGBoost menggunakan BigQuery ML. Setelah komponen ini selesai, Anda dapat melihat objek model baru (system.Model) di konsol BigQuery. Anda dapat menggunakan objek ini untuk melihat performa model dan untuk membuat prediksi nantinya.evaluate-bqml-xgboost: Komponen ini membuat kurva presisi/perolehan bernamaxgboost_data_pathuntuk model XGBoost. Artefak ini disimpan dalam bucket Cloud Storage.build-xgb-xgboost: Pipeline membuat model XGBoost. Komponen ini menggunakan Python, bukan BigQuery ML, sehingga Anda dapat melihat berbagai pendekatan untuk membuat model ini. Setelah selesai, komponen ini akan menyimpan objek model dan metrik performa di bucket Cloud Storage.deploy-xgb: Komponen ini men-deploy model XGBoost. Fungsi ini membuat endpoint yang memungkinkan prediksi batch atau online. Anda dapat menjelajahi endpoint di tab Models pada halaman konsol Vertex AI. Endpoint melakukan penskalaan otomatis agar cocok dengan traffic.build-bqml-automl: Pipeline membuat model AutoML menggunakan BigQuery ML. Setelah komponen ini selesai, objek model baru dapat dilihat di konsol BigQuery. Anda dapat menggunakan objek ini untuk melihat performa model dan untuk membangun prediksi nantinya.evaluate-bqml-automl: Pipeline membuat kurva presisi/perolehan untuk model AutoML. Artefak ini disimpan di bucket Cloud Storage.
Perhatikan bahwa proses tersebut tidak mengirim model ML BigQuery ke endpoint. Hal ini karena Anda dapat menghasilkan prediksi langsung dari objek model yang ada di BigQuery. Saat Anda memutuskan antara menggunakan BigQuery ML dan menggunakan library lain untuk solusi Anda, pertimbangkan cara menghasilkan prediksi. Jika prediksi batch harian memenuhi kebutuhan Anda, maka tetap berada di lingkungan BigQuery dapat menyederhanakan alur kerja Anda. Namun, jika Anda memerlukan prediksi real-time, atau jika skenario Anda memerlukan fungsionalitas yang ada di library lain, ikuti langkah-langkah dalam dokumen ini untuk mengirim model tersimpan Anda ke endpoint.
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
Notebook Jupyter untuk skenario ini
Tugas untuk membuat dan membangun pipeline di-build ke notebook Jupyter yang ada di repositori GitHub.
Untuk menjalankan tugas ini, dapatkan notebook lalu jalankan sel kode di notebook secara berurutan. Alur yang dijelaskan dalam dokumen ini mengasumsikan bahwa Anda menjalankan notebook di Vertex AI Workbench.
Membuka lingkungan Vertex AI Workbench
Anda dapat memulai dengan meng-clone repositori GitHub ke lingkungan Vertex AI Workbench.
- Di konsol Google Cloud, pilih project tempat Anda ingin membuat notebook.
Buka halaman Vertex AI Workbench.
Pada tab Notebook yang dikelola pengguna, klik Notebook baru.
Dalam daftar jenis notebook, pilih notebook Python 3.
Pada dialog Notebook baru, klik Opsi lanjutan, lalu di bagian Jenis mesin, pilih jenis mesin yang ingin Anda gunakan. Jika Anda tidak yakin, pilih n1-standard-1 (1 cVPU, 3,75 GB RAM).
Klik Buat.
Proses pembuatan lingkungan notebook memerlukan waktu beberapa saat.
Setelah notebook dibuat, pilih notebook, lalu klik Buka Jupyterlab.
Lingkungan JupyterLab akan terbuka di browser Anda.
Untuk meluncurkan tab terminal, pilih File > Baru > Peluncur.
Klik ikon Terminal pada tab Peluncur.
Di terminal, clone repositori GitHub
mlops-on-gcp:git clone https://github.com/GoogleCloudPlatform/cloud-for-marketing/
Setelah perintah selesai, Anda akan melihat folder
cloud-for-marketingdi file browser.
Mengonfigurasi setelan notebook
Sebelum menjalankan notebook, Anda harus mengonfigurasinya. Notebook ini memerlukan bucket Cloud Storage untuk menyimpan artefak pipeline, jadi, untuk memulai Anda harus membuat bucket tersebut.
- Buat bucket Cloud Storage tempat notebook dapat menyimpan artefak pipeline. Nama bucket harus unik secara global.
- Pada
folder
cloud-for-marketing/marketing-analytics/predicting/kfp_pipeline/, buka notebookPropensity_Pipeline.ipynb. - Di notebook, tetapkan nilai variabel
PROJECT_IDke ID project Google Cloud tempat Anda ingin menjalankan pipeline. - Tetapkan nilai variabel
BUCKET_NAMEke nama bucket yang baru saja Anda buat.
Bagian selanjutnya dari dokumen ini menjelaskan cuplikan kode yang penting untuk memahami cara kerja pipeline. Untuk mengetahui implementasi yang lengkap, lihat repositori GitHub.
Membangun tampilan BigQuery
Langkah pertama dalam pipeline menghasilkan data input, yang akan digunakan untuk membangun setiap model. Komponen Vertex AI Pipelines ini menghasilkan tampilan BigQuery. Untuk menyederhanakan proses pembuatan tampilan, beberapa SQL telah dibuat dan disimpan dalam file teks di GitHub.
Kode untuk setiap komponen dimulai dengan mendekorasi (mengubah class induk atau
fungsi melalui atribut) class komponen Vertex AI Pipelines. Kode tersebut
kemudian menentukan fungsi create_input_view, yang merupakan langkah dalam pipeline.
Fungsi ini memerlukan beberapa input. Beberapa nilai tersebut saat ini
di-hardcode ke dalam kode, seperti tanggal mulai dan tanggal akhir. Saat mengotomatiskan
pipeline, Anda dapat mengubah kode untuk menggunakan nilai yang sesuai (misalnya,
menggunakan fungsi
CURRENT_DATE
untuk suatu tanggal), atau Anda dapat mengupdate komponen untuk menggunakan nilai ini sebagai
parameter, bukan menyimpannya secara hard code. Anda juga harus mengubah nilai
ga_data_ref menjadi nama tabel GA4, dan menetapkan nilai
variabel conversion ke konversi Anda. (Contoh ini menggunakan data sampel GA4 publik.)
Listingan berikut menunjukkan kode untuk komponen create-input-view.
@component( # this component builds a BigQuery view, which will be the underlying source for model packages_to_install=["google-cloud-bigquery", "google-cloud-storage"], base_image="python:3.9", output_component_file="output_component/create_input_view.yaml", ) def create_input_view(view_name: str, data_set_id: str, project_id: str, bucket_name: str, blob_path: str ): from google.cloud import bigquery from google.cloud import storage client = bigquery.Client(project=project_id) dataset = client.dataset(data_set_id) table_ref = dataset.table(view_name) ga_data_ref = 'bigquery-public-data.google_analytics_sample.ga_sessions_*' conversion = "hits.page.pageTitle like '%Shopping Cart%'" start_date = '20170101' end_date = '20170131' def get_sql(bucket_name, blob_path): from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket(bucket_name) blob = bucket.get_blob(blob_path) content = blob.download_as_string() return content def if_tbl_exists(client, table_ref): ... else: content = get_sql() content = str(content, 'utf-8') create_base_feature_set_query = content. format(start_date = start_date, end_date = end_date, ga_data_ref = ga_data_ref, conversion = conversion) shared_dataset_ref = client.dataset(data_set_id) base_feature_set_view_ref = shared_dataset_ref.table(view_name) base_feature_set_view = bigquery.Table(base_feature_set_view_ref) base_feature_set_view.view_query = create_base_feature_set_query.format(project_id) base_feature_set_view = client.create_table(base_feature_set_view)
Membangun model BigQuery ML
Setelah tampilan dibuat, jalankan komponen bernama build_bqml_logistic untuk
membangun model BigQuery ML. Blok notebook ini adalah komponen
inti. Dengan menggunakan tampilan pelatihan yang Anda buat di blok pertama,
model ini akan membangun model BigQuery ML. Dalam contoh ini, notebook menggunakan
regresi logistik.
Untuk mendapatkan informasi tentang jenis model dan hyperparameter yang tersedia, baca Dokumentasi referensi ML BigQuery.
Listingan berikut menunjukkan kode untuk komponen ini.
@component( # this component builds a logistic regression with BigQuery ML packages_to_install=["google-cloud-bigquery"], base_image="python:3.9", output_component_file="output_component/create_bqml_model_logistic.yaml" ) def build_bqml_logistic(project_id: str, data_set_id: str, model_name: str, training_view: str ): from google.cloud import bigquery client = bigquery.Client(project=project_id) model_name = f"{project_id}.{data_set_id}.{model_name}" training_set = f"{project_id}.{data_set_id}.{training_view}" build_model_query_bqml_logistic = ''' CREATE OR REPLACE MODEL `{model_name}` OPTIONS(model_type='logistic_reg' , INPUT_LABEL_COLS = ['label'] , L1_REG = 1 , DATA_SPLIT_METHOD = 'RANDOM' , DATA_SPLIT_EVAL_FRACTION = 0.20 ) AS SELECT * EXCEPT (fullVisitorId, label), CASE WHEN label is null then 0 ELSE label end as label FROM `{training_set}` '''.format(model_name = model_name, training_set = training_set) job_config = bigquery.QueryJobConfig() client.query(build_model_query_bqml_logistic, job_config=job_config)
Menggunakan XGBoost, bukan BigQuery ML
Komponen yang diilustrasikan di bagian sebelumnya menggunakan BigQuery ML. Bagian notebook berikut ini menunjukkan cara menggunakan XGBoost di Python secara langsung, bukan menggunakan BigQuery ML.
Anda menjalankan komponen bernama build_bqml_xgboost untuk membuat komponen sehingga dapat menjalankan
model klasifikasi XGBoost standar dengan penelusuran petak. Kode tersebut kemudian
menyimpan model sebagai artefak di bucket Cloud Storage yang Anda buat.
Fungsi ini mendukung parameter tambahan (metrics dan model) untuk artefak
output; parameter-parameter ini diperlukan oleh Vertex AI Pipelines.
@component( # this component builds an xgboost classifier with xgboost packages_to_install=["google-cloud-bigquery", "xgboost", "pandas", "sklearn", "joblib", "pyarrow"], base_image="python:3.9", output_component_file="output_component/create_xgb_model_xgboost.yaml" ) def build_xgb_xgboost(project_id: str, data_set_id: str, training_view: str, metrics: Output[Metrics], model: Output[Model] ): ... data_set = f"{project_id}.{data_set_id}.{training_view}" build_df_for_xgboost = ''' SELECT * FROM `{data_set}` '''.format(data_set = data_set) ... xgb_model = XGBClassifier(n_estimators=50, objective='binary:hinge', silent=True, nthread=1, eval_metric="auc") random_search = RandomizedSearchCV(xgb_model, param_distributions=params, n_iter=param_comb, scoring='precision', n_jobs=4, cv=skf.split(X_train,y_train), verbose=3, random_state=1001 ) random_search.fit(X_train, y_train) xgb_model_best = random_search.best_estimator_ predictions = xgb_model_best.predict(X_test) score = accuracy_score(y_test, predictions) auc = roc_auc_score(y_test, predictions) precision_recall = precision_recall_curve(y_test, predictions) metrics.log_metric("accuracy",(score * 100.0)) metrics.log_metric("framework", "xgboost") metrics.log_metric("dataset_size", len(df)) metrics.log_metric("AUC", auc) dump(xgb_model_best, model.path + ".joblib")
Membangun endpoint
Anda menjalankan komponen bernama deploy_xgb untuk membangun endpoint menggunakan
model XGBoost dari bagian sebelumnya. Komponen ini mengambil artefak model
XGBoost sebelumnya, membangun container, lalu men-deploy endpoint, sekaligus
menyediakan URL endpoint sebagai artefak agar Anda dapat melihatnya. Setelah
langkah ini selesai, endpoint Vertex AI telah dibuat dan
Anda dapat melihat endpoint tersebut di halaman konsol untuk Vertex AI.
@component( # Deploys xgboost model packages_to_install=["google-cloud-aiplatform", "joblib", "sklearn", "xgboost"], base_image="python:3.9", output_component_file="output_component/xgboost_deploy_component.yaml", ) def deploy_xgb( model: Input[Model], project_id: str, vertex_endpoint: Output[Artifact], vertex_model: Output[Model] ): from google.cloud import aiplatform aiplatform.init(project=project_id) deployed_model = aiplatform.Model.upload( display_name="tai-propensity-test-pipeline", artifact_uri = model.uri.replace("model", ""), serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-4:latest" ) endpoint = deployed_model.deploy(machine_type="n1-standard-4") # Save data to the output params vertex_endpoint.uri = endpoint.resource_name vertex_model.uri = deployed_model.resource_name
Menentukan pipeline
Untuk menentukan pipeline, tentukan setiap operasi berdasarkan komponen yang Anda buat sebelumnya. Kemudian, Anda dapat menentukan urutan elemen pipeline jika tidak dipanggil secara eksplisit dalam komponen.
Misalnya, kode di notebook berikut ini mendefinisikan pipeline. Dalam hal
ini, kode memerlukan komponen build_bqml_logistic_op untuk dijalankan setelah
komponen create_input_view_op.
@dsl.pipeline( # Default pipeline root. You can override it when submitting the pipeline. pipeline_root=PIPELINE_ROOT, # A name for the pipeline. name="pipeline-test", description='Propensity BigQuery ML Test' ) def pipeline(): create_input_view_op = create_input_view( view_name = VIEW_NAME, data_set_id = DATA_SET_ID, project_id = PROJECT_ID, bucket_name = BUCKET_NAME, blob_path = BLOB_PATH ) build_bqml_logistic_op = build_bqml_logistic( project_id = PROJECT_ID, data_set_id = DATA_SET_ID, model_name = 'bqml_logistic_model', training_view = VIEW_NAME ) # several components have been deleted for brevity build_bqml_logistic_op.after(create_input_view_op) build_bqml_xgboost_op.after(create_input_view_op) build_bqml_automl_op.after(create_input_view_op) build_xgb_xgboost_op.after(create_input_view_op) evaluate_bqml_logistic_op.after(build_bqml_logistic_op) evaluate_bqml_xgboost_op.after(build_bqml_xgboost_op) evaluate_bqml_automl_op.after(build_bqml_automl_op)
Mengompilasi dan menjalankan pipeline
Sekarang Anda dapat mengompilasi dan menjalankan pipeline.
Kode berikut di notebook menetapkan nilai enable_caching ke benar (true) untuk
mengaktifkan cache. Ketika caching diaktifkan, setiap operasi sebelumnya saat
komponen berhasil diselesaikan tidak akan dijalankan ulang. Flag ini berguna
terutama saat Anda menguji pipeline karena saat caching diaktifkan, operasi akan selesai
lebih cepat dan menggunakan lebih sedikit resource.
compiler.Compiler().compile( pipeline_func=pipeline, package_path="pipeline.json" ) TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S") run = pipeline_jobs.PipelineJob( display_name="test-pipeine", template_path="pipeline.json", job_id="test-{0}".format(TIMESTAMP), enable_caching=True ) run.run()
Mengotomatiskan pipeline
Pada tahap ini, Anda telah meluncurkan pipeline pertama. Anda dapat memeriksa halaman Vertex AI Pipelines di konsol untuk melihat status tugas ini. Anda dapat melihat setiap container dibuat dan dijalankan. Anda juga dapat melacak error untuk komponen tertentu pada bagian ini dengan mengklik setiap komponen.
Untuk menjadwalkan pipeline, build fungsi Cloud Run dan gunakan penjadwal yang mirip dengan cron job.
Kode di bagian terakhir notebook menjadwalkan pipeline untuk dijalankan sekali sehari, seperti yang ditunjukkan dalam cuplikan kode berikut:
from kfp.v2.google.client import AIPlatformClient api_client = AIPlatformClient(project_id=PROJECT_ID, region='us-central1' ) api_client.create_schedule_from_job_spec( job_spec_path='pipeline.json', schedule='0 * * * *', enable_caching=False )
Menggunakan pipeline yang sudah selesai dalam produksi
Pipeline yang telah selesai telah melakukan tugas-tugas berikut:
- Membuat set data input.
- Melatih beberapa model menggunakan BigQuery ML serta XGBoost Python.
- Menganalisis hasil model.
- Men-deploy model XGBoost.
Anda juga telah mengotomatiskan pipeline dengan menggunakan fungsi Cloud Run dan Cloud Scheduler untuk berjalan setiap hari.
Pipeline yang ditentukan di notebook dibuat untuk mengilustrasikan cara pembuatan berbagai model. Anda tidak akan menjalankan pipeline karena pipeline saat ini dibangun dalam skenario produksi. Namun, Anda dapat menggunakan pipeline ini sebagai panduan dan memodifikasi komponen sesuai kebutuhan. Misalnya, Anda dapat mengedit proses pembuatan fitur untuk memanfaatkan data Anda, mengubah rentang tanggal, dan mungkin membangun model alternatif. Anda juga akan memilih model dari beberapa ilustrasi yang paling sesuai dengan persyaratan produksi Anda.
Saat pipeline siap untuk produksi, Anda dapat mengimplementasikan tugas tambahan. Misalnya, Anda dapat menerapkan model pemenang/penantang, yang setiap hari membuat model baru dan model baru (penantang) dan yang sudah ada (juara) diberi skor berdasarkan data baru. Anda dapat memasukkan model baru ke dalam produksi hanya jika performanya lebih baik daripada performa model saat ini. Untuk memantau progres sistem, Anda juga dapat menyimpan catatan performa model setiap hari dan memvisualisasikan performa yang sedang tren.
Pembersihan
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Langkah berikutnya
- Untuk mempelajari cara menggunakan MLOps guna membuat sistem ML yang siap produksi, lihat Panduan Praktisi untuk MLOps.
- Untuk mempelajari Vertex AI, lihat Dokumentasi Vertex AI.
- Untuk mempelajari Kubeflow Pipelines, lihat Dokumentasi KFP.
- Untuk mempelajari TensorFlow Extended, lihat Panduan Pengguna TFX.
- Untuk ringkasan prinsip dan rekomendasi arsitektur yang khusus untuk beban kerja AI dan ML di Google Cloud, lihat perspektif AI dan ML di Framework Arsitektur.
- Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.
Kontributor
Penulis: Tai Conley | Cloud Customer Engineer
Kontributor lainnya: Lars Ahlfors | Cloud Customer Engineer