Questo documento descrive un esempio di pipeline implementata in Google Cloud che esegue la definizione del modello di propensione. È destinata a data engineer, esperti di machine learning o team di scienza del marketing che creano e implementano modelli di machine learning. Il documento presuppone che tu conosca i concetti di machine learning e che tu abbia dimestichezza con Google Cloud, BigQuery, Vertex AI Pipelines, Python e Jupyter Notebook. Inoltre, assume che tu abbia familiarità con Google Analytics 4 e con la funzionalità di esportazione non elaborata in BigQuery.
La pipeline con cui lavori utilizza i dati di esempio di Google Analytics. La pipeline genera diversi modelli utilizzando BigQuery ML e XGBoost e puoi eseguirla utilizzando Vertex AI Pipelines. Questo documento descrive le procedure di addestramento, valutazione e deployment dei modelli. Descrive inoltre come automatizzare l'intero processo.
Il codice completo della pipeline si trova in un Jupyter Notebook in un repository GitHub.
Che cos'è la definizione del modello di propensione?
La definizione del modello di propensione prevede le azioni che un consumatore potrebbe intraprendere. Alcuni esempi di modelli di propensione sono la previsione dei consumatori che potrebbero acquistare un prodotto, registrarsi a un servizio o addirittura abbandonare il brand e non essere più clienti attivi.
L'output di un modello di propensione è un punteggio compreso tra 0 e 1 per ogni consumatore, in cui questo punteggio rappresenta la probabilità che il consumatore effettui l'azione. Uno tra i fattori chiave che spingono le organizzazioni verso la creazione di modelli di propensione è la necessità di fare di più con i dati proprietari. Per i casi d'uso di marketing, i migliori modelli di propensione includono indicatori sia da origini online che offline, come i dati di analisi dei siti e del CRM.
Questa demo utilizza i dati di esempio di GA4 in BigQuery. Per il tuo caso d'uso, ti consigliamo di prendere in considerazione ulteriori indicatori offline.
In che modo MLOps semplifica le pipeline di ML
La maggior parte dei modelli ML non viene utilizzata in produzione. I risultati del modello generano approfondimenti e spesso, dopo che i team di data science hanno completato un modello, un team di ML engineering o di software engineering deve inserirlo in un codice per la produzione utilizzando un framework come Flask o FastAPI. Spesso questa procedura richiede la creazione del modello in un nuovo framework, il che significa che i dati devono essere trasformati di nuovo. Questo lavoro può richiedere settimane o mesi, pertanto molti modelli non vengono prodotti.
Le operazioni di machine learning (MLOps) sono diventate importanti per ottenere valore dai progetti di ML e MLOps e ora sono un insieme di competenze in evoluzione per le organizzazioni di data science. Per aiutare le organizzazioni a comprendere questo valore, Google Cloud ha pubblicato una guida alle MLOps per professionisti che fornisce una panoramica delle MLOps.
Se utilizzi i principi di MLOps e Google Cloud, puoi inviare i modelli a un endpoint utilizzando un processo automatico che rimuove gran parte della complessità del processo manuale. Gli strumenti e la procedura descritti in questo documento illustrano un approccio per acquisire la proprietà della pipeline end-to-end, che ti aiuta a mettere in produzione i modelli. Il documento della guida per professionisti citato in precedenza fornisce una soluzione orizzontale e una panoramica di ciò che è possibile utilizzando le MLOps e Google Cloud.
Che cos'è Vertex AI Pipelines?
Vertex AI Pipelines ti consente di eseguire pipeline ML create utilizzando l'SDK Kubeflow Pipelines o TensorFlow Extended (TFX). Senza Vertex AI, per eseguire uno di questi framework open source su larga scala devi configurare e gestire i tuoi cluster Kubernetes. Vertex AI Pipelines risolve questo problema. Poiché si tratta di un servizio gestito, viene eseguito lo scaling up o lo scaling down in base alle esigenze e non richiede manutenzione continua.
Ogni passaggio del processo Vertex AI Pipelines è costituito da un contenitore indipendente che può ricevere input o produrre output sotto forma di elementi. Ad esempio, se un passaggio della procedura genera il set di dati, l'output è l'elemento del set di dati. Questo artefatto del set di dati può essere utilizzato come input per il passaggio successivo. Poiché ogni componente è un contenitore separato, devi fornire informazioni per ogni componente della pipeline, ad esempio il nome dell'immagine di base e un elenco di eventuali dipendenze.
Il processo di compilazione della pipeline
L'esempio descritto in questo documento utilizza un notebook Jupyter per creare i componenti della pipeline e per compilarli, eseguirli e automatizzarli. Come notato in precedenza, il notebook si trova in un repository GitHub.
Puoi eseguire il codice del notebook utilizzando un'istanza di notebook gestiti dall'utente di Vertex AI Workbench, che gestisce l'autenticazione per te. Vertex AI Workbench consente di lavorare con i blocchi note per creare macchine, compilare blocchi note e collegarti a Git. Vertex AI Workbench include molte altre funzionalità, ma non sono trattate in questo documento.
Al termine dell'esecuzione della pipeline, in Vertex AI Pipelines viene generato un diagramma simile al seguente:
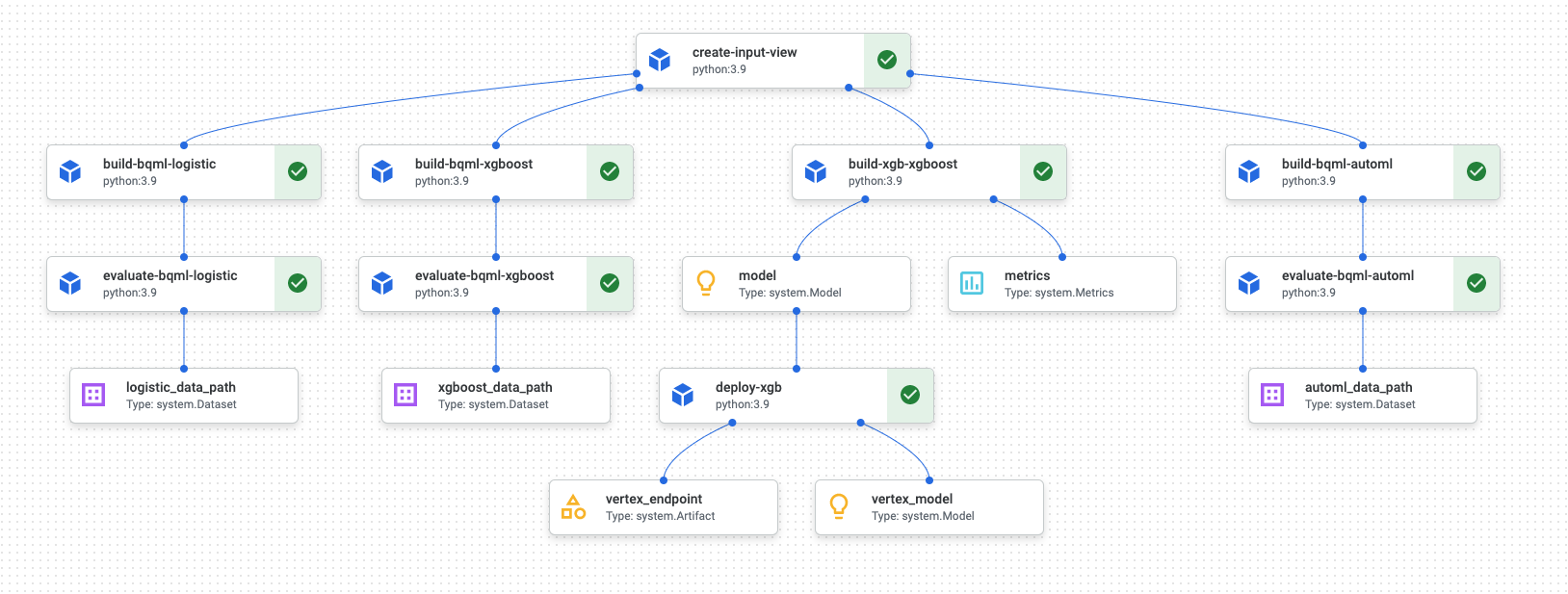
Il diagramma precedente è un grafo diretto aciclico (DAG). La creazione e la revisione del DAG è un passaggio fondamentale per comprendere la pipeline di dati o ML. Gli attributi chiave dei DAG sono che i componenti scorrono in un'unica direzione (in questo caso, dall'alto verso il basso) e che non si verificano cicli, ovvero un componente principale non si basa sul componente secondario. Alcuni componenti possono verificarsi in parallelo, mentre altri hanno dipendenze e quindi si verificano in serie.
La casella di controllo verde in ogni componente indica che il codice è stato eseguito correttamente. Se si sono verificati errori, viene visualizzato un punto esclamativo rosso. Puoi fare clic su ogni componente nel diagramma per visualizzare ulteriori dettagli del job.
Il diagramma DAG è incluso in questa sezione del documento per fungere da blueprint per ogni componente creato dalla pipeline. L'elenco seguente fornisce una descrizione di ciascun componente.
La pipeline completa esegue i seguenti passaggi, come mostrato nel diagramma DAG:
create-input-view: questo componente crea una visualizzazione BigQuery. Il componente copia SQL da un bucket Cloud Storage e compila i valori dei parametri che fornisci. Questa vista BigQuery è il set di dati di input utilizzato per tutti i modelli più avanti nella pipeline.build-bqml-logistic: la pipeline utilizza BigQuery ML per creare un modello di regressione logistica. Al termine di questo componente, un nuovo modello sarà visibile nella console BigQuery. Puoi utilizzare questo oggetto modello per visualizzare il rendimento del modello e in un secondo momento per creare previsioni.evaluate-bqml-logistic: la pipeline utilizza questo componente per creare una curva di precisione/richiamo (logistic_data_pathnel diagramma DAG) per la regressione logistica. Questo artefatto è archiviato in un bucket Cloud Storage.build-bqml-xgboost: questo componente crea un modello XGBoost utilizzando BigQuery ML. Al termine di questo componente, puoi visualizzare un nuovo oggetto modello (system.Model) nella console BigQuery. Puoi utilizzare questo oggetto per visualizzare il rendimento del modello e in un secondo momento per creare predizioni.evaluate-bqml-xgboost: questo componente crea una curva di precisione/richiamo denominataxgboost_data_pathper il modello XGBoost. Questo artefatto è archiviato in un bucket Cloud Storage.build-xgb-xgboost: la pipeline crea un modello XGBoost. Questo componente utilizza Python anziché BigQuery ML per consentirti di osservare approcci diversi per la creazione del modello. Al termine di questo componente, viene archiviato un oggetto modello e le metriche relative alle prestazioni in un bucket Cloud Storage.deploy-xgb: questo componente esegue il deployment del modello XGBoost. Crea un endpoint che consente previsioni batch o online. Puoi esplorare l'endpoint nella scheda Modelli della pagina console di Vertex AI. L'endpoint viene scalato automaticamente in base al traffico.build-bqml-automl: la pipeline crea un modello AutoML utilizzando BigQuery ML. Al termine di questo componente, nella console BigQuery è visibile un nuovo oggetto modello. Puoi utilizzare questo oggetto per visualizzare il rendimento del modello e successivamente per elaborare le previsioni.evaluate-bqml-automl: la pipeline crea una curva di precisione/richiamo per il modello AutoML. L'artefatto è archiviato in un bucket Cloud Storage.
Tieni presente che il processo non spinge i modelli BigQuery ML a un endpoint. Questo perché puoi generare le previsioni direttamente dall'oggetto modello in BigQuery. Quando scegli tra l'utilizzo di BigQuery ML e di altre librerie per la tua soluzione, considera come devono essere generate le previsioni. Se una previsione batch giornaliera soddisfa le tue esigenze, rimanere nell'ambiente BigQuery può semplificare il tuo flusso di lavoro. Tuttavia, se hai bisogno di previsioni in tempo reale o se il tuo scenario richiede funzionalità presenti in un'altra libreria, segui i passaggi descritti in questo documento per inviare il modello salvato a un endpoint.
Costi
In questo documento utilizzi i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il Calcolatore prezzi.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
Il notebook Jupyter per questo scenario
Le attività per la creazione e la compilazione della pipeline sono integrate in un notebook Jupyter che si trova in un repository GitHub.
Per eseguire le attività, ottieni il notebook ed esegui le celle di codice in ordine. Il flusso descritto in questo documento presuppone che tu stia eseguendo i blocchi note in Vertex AI Workbench.
Apri l'ambiente Vertex AI Workbench
Per iniziare, clona il repository GitHub in un ambiente Vertex AI Workbench.
- Nella console Google Cloud, seleziona il progetto in cui vuoi creare il notebook.
Vai alla pagina Vertex AI Workbench.
Nella scheda Blocchi note gestiti dall'utente, fai clic su Nuovo blocco note.
Nell'elenco dei tipi di notebook, scegli un notebook Python 3.
Nella finestra di dialogo Nuovo notebook, fai clic su Opzioni avanzate e poi in Tipo di macchina, seleziona il tipo di macchina che vuoi utilizzare. In caso di dubbi, scegli n1-standard-1 (1 cVPU, 3,75 GB di RAM).
Fai clic su Crea.
La creazione dell'ambiente del notebook richiede alcuni istanti.
Dopo aver creato il blocco note, selezionalo e fai clic su Apri JupyterLab.
L'ambiente JupyterLab si apre nel browser.
Per avviare una scheda del terminale, seleziona File > Nuovo > Avvio.
Fai clic sull'icona Terminale nella scheda Avvio app.
Nel terminale, clona il
mlops-on-gcprepository GitHub:git clone https://github.com/GoogleCloudPlatform/cloud-for-marketing/
Al termine del comando, vedrai la cartella
cloud-for-marketingnel browser di file.
Configurare le impostazioni dei notebook
Prima di eseguire il notebook, devi configurarlo. Il blocco note richiede un bucket Cloud Storage per archiviare gli artefatti della pipeline, quindi devi innanzitutto creare questo bucket.
- Crea un bucket Cloud Storage in cui il notebook può archiviare gli artefatti della pipeline. Il nome del bucket deve essere univoco a livello globale.
- Nella
cloud-for-marketing/marketing-analytics/predicting/kfp_pipeline/cartella, apri il notebookPropensity_Pipeline.ipynb. - Nel notebook, imposta il valore della variabile
PROJECT_IDsull'ID del progetto Google Cloud in cui vuoi eseguire la pipeline. - Imposta il valore della variabile
BUCKET_NAMEsul nome del bucket appena creato.
La parte rimanente di questo documento descrive gli snippet di codice importanti per comprendere il funzionamento della pipeline. Per l'implementazione completa, consulta il repository GitHub.
Crea la vista BigQuery
Il primo passaggio della pipeline genera i dati di input, che verranno utilizzati per creare ogni modello. Questo componente di Vertex AI Pipelines genera una vista BigQuery. Per semplificare la procedura di creazione della vista, alcune query SQL sono già state generate e salvate in un file di testo su GitHub.
Il codice di ogni componente inizia decorando (modificando una classe o funzione di base tramite attributi) la classe del componente Vertex AI Pipelines. Il codice
quindi definisce la funzione create_input_view, che è un passaggio della pipeline.
La funzione richiede diversi input. Alcuni di questi valori sono attualmente codificati nel codice, ad esempio la data di inizio e la data di fine. Quando automatizzi la pipeline, puoi modificare il codice in modo da utilizzare valori appropriati (ad esempio, la funzione CURRENT_DATE per una data) oppure puoi aggiornare il componente in modo che accetti questi valori come parametri anziché mantenerli codificati. Devi anche modificare il valore di ga_data_ref in base al nome della tabella GA4 e impostare il valore della variabile conversion sulla conversione. (Questo esempio utilizza i dati di esempio GA4 pubblici).
La seguente voce mostra il codice del componente create-input-view.
@component( # this component builds a BigQuery view, which will be the underlying source for model packages_to_install=["google-cloud-bigquery", "google-cloud-storage"], base_image="python:3.9", output_component_file="output_component/create_input_view.yaml", ) def create_input_view(view_name: str, data_set_id: str, project_id: str, bucket_name: str, blob_path: str ): from google.cloud import bigquery from google.cloud import storage client = bigquery.Client(project=project_id) dataset = client.dataset(data_set_id) table_ref = dataset.table(view_name) ga_data_ref = 'bigquery-public-data.google_analytics_sample.ga_sessions_*' conversion = "hits.page.pageTitle like '%Shopping Cart%'" start_date = '20170101' end_date = '20170131' def get_sql(bucket_name, blob_path): from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket(bucket_name) blob = bucket.get_blob(blob_path) content = blob.download_as_string() return content def if_tbl_exists(client, table_ref): ... else: content = get_sql() content = str(content, 'utf-8') create_base_feature_set_query = content. format(start_date = start_date, end_date = end_date, ga_data_ref = ga_data_ref, conversion = conversion) shared_dataset_ref = client.dataset(data_set_id) base_feature_set_view_ref = shared_dataset_ref.table(view_name) base_feature_set_view = bigquery.Table(base_feature_set_view_ref) base_feature_set_view.view_query = create_base_feature_set_query.format(project_id) base_feature_set_view = client.create_table(base_feature_set_view)
Crea il modello BigQuery ML
Dopo aver creato la vista, esegui il componente denominato build_bqml_logistic per
costruire un modello BigQuery ML. Questo blocco del notebook è un componente di base. Utilizza la vista di addestramento creata nel primo blocco per
costruire un modello BigQuery ML. In questo esempio, il notebook utilizza la regressione logistica.
Per informazioni sui tipi di modelli e sugli iperparametri disponibili, consulta la documentazione di riferimento di BigQuery ML.
La seguente voce mostra il codice di questo componente.
@component( # this component builds a logistic regression with BigQuery ML packages_to_install=["google-cloud-bigquery"], base_image="python:3.9", output_component_file="output_component/create_bqml_model_logistic.yaml" ) def build_bqml_logistic(project_id: str, data_set_id: str, model_name: str, training_view: str ): from google.cloud import bigquery client = bigquery.Client(project=project_id) model_name = f"{project_id}.{data_set_id}.{model_name}" training_set = f"{project_id}.{data_set_id}.{training_view}" build_model_query_bqml_logistic = ''' CREATE OR REPLACE MODEL `{model_name}` OPTIONS(model_type='logistic_reg' , INPUT_LABEL_COLS = ['label'] , L1_REG = 1 , DATA_SPLIT_METHOD = 'RANDOM' , DATA_SPLIT_EVAL_FRACTION = 0.20 ) AS SELECT * EXCEPT (fullVisitorId, label), CASE WHEN label is null then 0 ELSE label end as label FROM `{training_set}` '''.format(model_name = model_name, training_set = training_set) job_config = bigquery.QueryJobConfig() client.query(build_model_query_bqml_logistic, job_config=job_config)
Utilizza XGBoost anziché BigQuery ML
Il componente illustrato nella sezione precedente utilizza BigQuery ML. La sezione successiva dei notebook mostra come utilizzare XGBoost direttamente in Python anziché utilizzare BigQuery ML.
Esegui il componente denominato build_bqml_xgboost per eseguire un
modello di classificazione XGBoost standard con una ricerca in rete. Il codice salva quindi il modello come artefatto nel bucket Cloud Storage che hai creato.
La funzione supporta parametri aggiuntivi (metrics e model) per gli elementi di output. Questi parametri sono obbligatori per Vertex AI Pipelines.
@component( # this component builds an xgboost classifier with xgboost packages_to_install=["google-cloud-bigquery", "xgboost", "pandas", "sklearn", "joblib", "pyarrow"], base_image="python:3.9", output_component_file="output_component/create_xgb_model_xgboost.yaml" ) def build_xgb_xgboost(project_id: str, data_set_id: str, training_view: str, metrics: Output[Metrics], model: Output[Model] ): ... data_set = f"{project_id}.{data_set_id}.{training_view}" build_df_for_xgboost = ''' SELECT * FROM `{data_set}` '''.format(data_set = data_set) ... xgb_model = XGBClassifier(n_estimators=50, objective='binary:hinge', silent=True, nthread=1, eval_metric="auc") random_search = RandomizedSearchCV(xgb_model, param_distributions=params, n_iter=param_comb, scoring='precision', n_jobs=4, cv=skf.split(X_train,y_train), verbose=3, random_state=1001 ) random_search.fit(X_train, y_train) xgb_model_best = random_search.best_estimator_ predictions = xgb_model_best.predict(X_test) score = accuracy_score(y_test, predictions) auc = roc_auc_score(y_test, predictions) precision_recall = precision_recall_curve(y_test, predictions) metrics.log_metric("accuracy",(score * 100.0)) metrics.log_metric("framework", "xgboost") metrics.log_metric("dataset_size", len(df)) metrics.log_metric("AUC", auc) dump(xgb_model_best, model.path + ".joblib")
Creare un endpoint
Esegui il componente denominato deploy_xgb per creare un endpoint utilizzando il
modello XGBoost della sezione precedente. Il componente prende l'elemento precedente
del modello XGBoost, crea un contenitore e poi esegue il deployment dell'endpoint, fornendo anche l'URL dell'endpoint come elemento in modo da poterlo visualizzare. Al termine di questo passaggio, viene creato un endpoint Vertex AI che puoi visualizzare nella pagina della console di Vertex AI.
@component( # Deploys xgboost model packages_to_install=["google-cloud-aiplatform", "joblib", "sklearn", "xgboost"], base_image="python:3.9", output_component_file="output_component/xgboost_deploy_component.yaml", ) def deploy_xgb( model: Input[Model], project_id: str, vertex_endpoint: Output[Artifact], vertex_model: Output[Model] ): from google.cloud import aiplatform aiplatform.init(project=project_id) deployed_model = aiplatform.Model.upload( display_name="tai-propensity-test-pipeline", artifact_uri = model.uri.replace("model", ""), serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-4:latest" ) endpoint = deployed_model.deploy(machine_type="n1-standard-4") # Save data to the output params vertex_endpoint.uri = endpoint.resource_name vertex_model.uri = deployed_model.resource_name
Definisci la pipeline
Per definire la pipeline, definisci ogni operazione in base ai componenti che hai creato in precedenza. Puoi quindi specificare l'ordine degli elementi della pipeline se non vengono richiamati esplicitamente nel componente.
Ad esempio, il seguente codice nel notebook definisce una pipeline. In questo
caso, il codice richiede l'esecuzione del componente build_bqml_logistic_op dopo il componente
create_input_view_op.
@dsl.pipeline( # Default pipeline root. You can override it when submitting the pipeline. pipeline_root=PIPELINE_ROOT, # A name for the pipeline. name="pipeline-test", description='Propensity BigQuery ML Test' ) def pipeline(): create_input_view_op = create_input_view( view_name = VIEW_NAME, data_set_id = DATA_SET_ID, project_id = PROJECT_ID, bucket_name = BUCKET_NAME, blob_path = BLOB_PATH ) build_bqml_logistic_op = build_bqml_logistic( project_id = PROJECT_ID, data_set_id = DATA_SET_ID, model_name = 'bqml_logistic_model', training_view = VIEW_NAME ) # several components have been deleted for brevity build_bqml_logistic_op.after(create_input_view_op) build_bqml_xgboost_op.after(create_input_view_op) build_bqml_automl_op.after(create_input_view_op) build_xgb_xgboost_op.after(create_input_view_op) evaluate_bqml_logistic_op.after(build_bqml_logistic_op) evaluate_bqml_xgboost_op.after(build_bqml_xgboost_op) evaluate_bqml_automl_op.after(build_bqml_automl_op)
Compila ed esegui la pipeline
Ora puoi compilare ed eseguire la pipeline.
Il seguente codice nel notebook imposta il valore enable_caching su true per attivare la memorizzazione nella cache. Quando la memorizzazione nella cache è attivata, le eventuali esecuzioni precedenti in cui un componente è stato completato correttamente non verranno eseguite di nuovo. Questo flag è utile soprattutto quando testi la pipeline perché, quando la memorizzazione nella cache è attivata, l'esecuzione viene completata più velocemente e vengono utilizzate meno risorse.
compiler.Compiler().compile( pipeline_func=pipeline, package_path="pipeline.json" ) TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S") run = pipeline_jobs.PipelineJob( display_name="test-pipeine", template_path="pipeline.json", job_id="test-{0}".format(TIMESTAMP), enable_caching=True ) run.run()
Automatizzare la pipeline
A questo punto hai lanciato la prima pipeline. Puoi controllare la pagina Vertex AI Pipelines nella console per visualizzare lo stato di questo job. Puoi osservare la compilazione e l'esecuzione di ciascun container. Puoi anche monitorare gli errori relativi a componenti specifici in questa sezione facendo clic su ciascuno.
Per pianificare la pipeline, crei una funzione Cloud Run e utilizzi un programmatore simile a un cron job.
Il codice nell'ultima sezione del notebook pianifica l'esecuzione della pipeline una volta al giorno, come mostrato nel seguente snippet di codice:
from kfp.v2.google.client import AIPlatformClient api_client = AIPlatformClient(project_id=PROJECT_ID, region='us-central1' ) api_client.create_schedule_from_job_spec( job_spec_path='pipeline.json', schedule='0 * * * *', enable_caching=False )
Utilizzare la pipeline completata in produzione
La pipeline completata ha eseguito le seguenti attività:
- È stato creato un set di dati di input.
- Ho addestrato diversi modelli utilizzando sia BigQuery ML sia XGBoost di Python.
- Risultati del modello analizzato.
- È stato eseguito il deployment del modello XGBoost.
Hai anche automatizzato la pipeline utilizzando le funzioni Cloud Run e Cloud Scheduler per l'esecuzione giornaliera.
La pipeline definita nel notebook è stata creata per illustrare i modi per creare vari modelli. Non eseguirai la pipeline così com'è attualmente creata in un ambiente di produzione. Tuttavia, puoi utilizzare questa pipeline come guida e modificare i componenti in base alle tue esigenze. Ad esempio, puoi modificare la procedura di creazione delle funzionalità per sfruttare i tuoi dati, modificare gli intervalli di date e persino creare modelli alternativi. Dovresti anche scegliere il modello tra quelli illustrati che soddisfa meglio i tuoi requisiti di produzione.
Quando la pipeline è pronta per la produzione, puoi implementare altre attività. Ad esempio, puoi implementare un modello di tipo campione/rivale, in cui ogni giorno viene creato un nuovo modello e sia il nuovo modello (il rivale) sia quello esistente (il campione) vengono valutati in base ai nuovi dati. Il nuovo modello viene messo in produzione solo se il suo rendimento è migliore rispetto a quello del modello corrente. Per monitorare l'avanzamento del sistema, puoi anche tenere traccia delle prestazioni del modello di ogni giorno e visualizzare le tendenze.
Esegui la pulizia
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Per scoprire come utilizzare MLOps per creare sistemi ML pronti per la produzione, consulta la Guida alle MLOps per professionisti.
- Per scoprire di più su Vertex AI, consulta la documentazione di Vertex AI.
- Per scoprire di più su Kubeflow Pipelines, consulta la documentazione di KFP.
- Per scoprire di più su TensorFlow Extended, consulta la Guida utente di TFX.
- Per una panoramica dei principi e dei consigli di architettura specifici per i workload di IA e ML in Google Cloud, consulta la prospettiva IA e ML nel framework di architettura.
- Per altre architetture di riferimento, diagrammi e best practice, visita il Centro architetture di Google Cloud.
Collaboratori
Autore: Tai Conley | Cloud Customer Engineer
Altro collaboratore: Lars Ahlfors | Cloud Customer Engineer