Ti consigliamo di progettare il tuo data mesh in modo che supporti un'ampia gamma di casi d'uso per il consumo di dati. In questo documento vengono descritti i casi d'uso più comuni per il consumo di dati in un'organizzazione. Il documento illustra anche quali informazioni devono essere prese in considerazione dai consumatori di dati quando determinano il prodotto di dati giusto per il loro caso d'uso e come scoprono e utilizzano i prodotti di dati. Comprendere questi fattori può aiutare le organizzazioni a garantire di disporre delle indicazioni e degli strumenti giusti per supportare i consumatori di dati.
Questo documento fa parte di una serie che descrive come implementare un data mesh su Google Cloud. Si presuppone che tu abbia letto e conosca i concetti descritti in Architettura e funzioni in un data mesh e Crea un data mesh moderno e distribuito con Google Cloud.
La serie è composta dalle seguenti parti:
- Architettura e funzioni in un mesh di dati
- Progettare una piattaforma di dati self-service per una mesh di dati
- Creare prodotti di dati in un data mesh
- Individuare e utilizzare i prodotti di dati in un data mesh (questo documento)
La progettazione di un livello di consumo dei dati, in particolare il modo in cui i consumatori basati sul dominio dei dati utilizzano i prodotti di dati, dipende dai requisiti dei consumatori di dati. Come prerequisito, si presume che i consumatori abbiano in mente un caso d'uso. Si presume che abbiano identificato i dati di cui hanno bisogno e che possano cercarli nel catalogo centrale dei prodotti dati. Se i dati non sono presenti nel catalogo o non si trovano nello stato preferito (ad esempio, se l'interfaccia non è appropriata o gli SLA sono insufficienti), il consumatore deve contattare il produttore dei dati.
In alternativa, il consumatore può contattare il centro di eccellenza (COE) per il data mesh per ricevere consigli su quale dominio è il più adatto a produrre quel prodotto dati. I consumatori di dati possono anche chiedere come presentare la richiesta. Se la tua organizzazione è di grandi dimensioni, dovrebbe esistere una procedura per effettuare richieste di prodotti di dati in modalità self-service.
I consumatori di dati utilizzano i prodotti di dati tramite le applicazioni che eseguono. Il tipo di approfondimenti richiesti determina la scelta del design dell'applicazione che utilizza i dati. Quando sviluppa il design dell'applicazione, il consumatore di dati identifica anche l'utilizzo preferito dei prodotti di dati nell'applicazione. stabiliscono la fiducia necessaria nell'affidabilità e nella sicurezza di questi dati. I consumatori di dati possono quindi stabilire una visualizzazione delle interfacce e degli SLA del prodotto di dati richiesti dall'applicazione.
Casi d'uso del consumo di dati
Affinché i consumatori di dati possano creare applicazioni di dati, le origini potrebbero essere uno o più prodotti di dati e, forse, i dati del dominio del consumatore di dati. Come descritto in Creare prodotti di dati in una data mesh, i prodotti di dati analitici potrebbero essere creati da prodotti di dati basati su vari repository di dati fisici.
Sebbene il consumo di dati possa avvenire all'interno dello stesso dominio, i pattern di consumo più comuni sono quelli che cercano il prodotto di dati giusto, indipendentemente dal dominio, come origine per l'applicazione. Quando il prodotto giusto esiste in un altro dominio, il pattern di consumo richiede di configurare il meccanismo successivo per l'accesso e l'utilizzo dei dati nei vari domini. Il consumo di prodotti di dati creati in domini diversi da quello di consumo è descritto in Passaggi per il consumo dei dati.
Architettura
Il seguente diagramma mostra uno scenario di esempio in cui i consumatori utilizzano i prodotti di dati tramite una serie di interfacce, tra cui set di dati autorizzati e API.
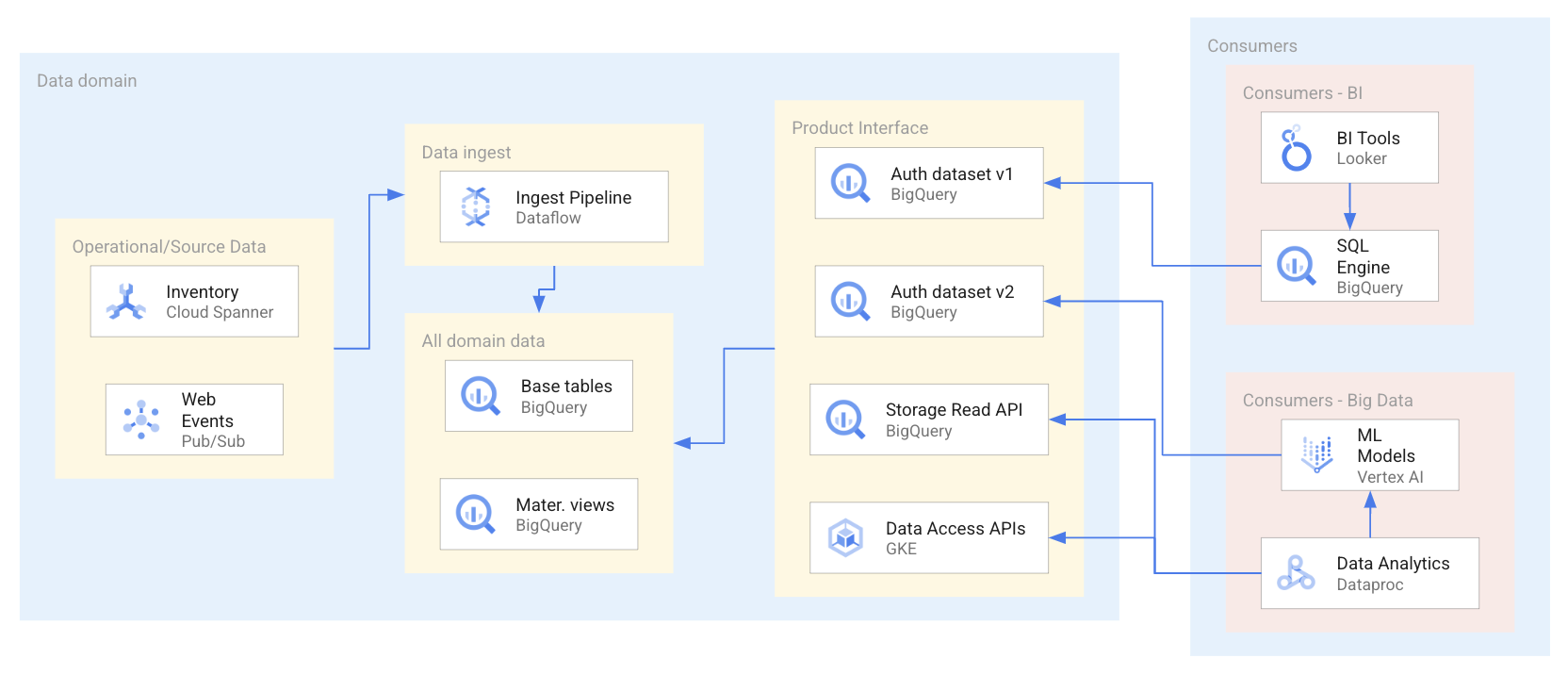
Come mostrato nel diagramma precedente, il produttore di dati ha esposto quattro interfacce di prodotti di dati: due set di dati BigQuery autorizzati, un set di dati BigQuery esposto dall'API BigQuery Storage Read e API di accesso ai dati ospitate su Google Kubernetes Engine. Quando utilizzano i prodotti di dati, i consumatori di dati utilizzano una serie di applicazioni che eseguono query o accedono direttamente alle risorse di dati all'interno dei prodotti di dati. Per questo scenario, i consumatori di dati accedono alle risorse di dati in due modi diversi in base ai loro requisiti specifici di accesso ai dati. Nel primo modo, Looker utilizza BigQuery SQL per eseguire query su un set di dati autorizzato. Nel secondo modo, Dataproc accede direttamente a un set di dati tramite l'API BigQuery e poi elabora i dati inseriti per addestrare un modello di machine learning (ML).
L'utilizzo di un'applicazione di consumo dei dati potrebbe non sempre generare un report di business intelligence (BI) o una dashboard BI. Il consumo di dati di un dominio può anche comportare modelli ML che arricchiscono ulteriormente i prodotti di analisi, vengono utilizzati nell'analisi dei dati o fanno parte di processi operativi, ad esempio il rilevamento delle frodi.
Di seguito sono riportati alcuni casi d'uso tipici del consumo di prodotti di dati:
- Report BI e analisi dei dati:in questo caso, le applicazioni di dati sono create per utilizzare i dati di più prodotti di dati. Ad esempio, i consumatori di dati del team di gestione dei rapporti con i clienti (CRM) devono accedere ai dati di più domini, come vendite, clienti e finanza. L'applicazione CRM sviluppata da questi consumatori di dati potrebbe dover eseguire query su una vista autorizzata BigQuery in un dominio ed estrarre dati da un'API Cloud Storage Read in un altro dominio. Per i consumatori di dati, i fattori di ottimizzazione che influenzano l'interfaccia di consumo preferita sono i costi di calcolo e l'eventuale elaborazione aggiuntiva dei dati necessaria dopo aver eseguito una query sul prodotto di dati. Nei casi d'uso di BI e analisi dei dati, le viste autorizzate di BigQuery sono probabilmente le più utilizzate.
- Casi d'uso di data science e addestramento dei modelli: in questo caso, il team che utilizza i dati utilizza i prodotti di dati di altri domini per arricchire il proprio prodotto di dati analitici, ad esempio un modello ML. Utilizzando Google Cloud Serverless per Apache Spark per Spark, Google Cloud fornisce funzionalità di pre-elaborazione dei dati e di feature engineering per consentire l'arricchimento dei dati prima di eseguire attività di machine learning. Le considerazioni chiave sono la disponibilità di quantità sufficienti di dati di addestramento a un costo ragionevole e la certezza che i dati di addestramento siano quelli appropriati. Per contenere i costi, le interfacce di consumo preferite sono probabilmente le API di lettura diretta. È possibile che un team che utilizza i dati crei un modello ML come prodotto di dati e, a sua volta, diventi un nuovo team di produzione di dati.
- Processi dell'operatore: il consumo fa parte del processo operativo all'interno del dominio di utilizzo dei dati. Ad esempio, un consumatore di dati in un team che si occupa di frodi potrebbe utilizzare i dati delle transazioni provenienti da origini dati operative nel dominio del commerciante. Utilizzando un metodo di integrazione dei dati come Change Data Capture, questi dati sulle transazioni vengono intercettati quasi in tempo reale. Puoi quindi utilizzare Pub/Sub per definire uno schema per questi dati ed esporre queste informazioni come eventi. In questo caso, le interfacce appropriate sarebbero i dati esposti come argomenti Pub/Sub.
Passaggi per il consumo dei dati
I produttori di dati documentano il proprio prodotto di dati nel catalogo centrale, incluse le indicazioni su come utilizzare i dati. Per un'organizzazione con più domini, questo approccio alla documentazione crea un'architettura diversa dalla pipeline ELT/ETL tradizionale creata centralmente, in cui i processori creano output senza il limite dei domini aziendali. I consumatori di dati in un data mesh devono disporre di un livello di scoperta e consumo ben progettato per creare un ciclo di vita di consumo dei dati. Il livello deve includere quanto segue:
Passaggio 1: scopri i prodotti di dati tramite la ricerca dichiarativa e l'esplorazione delle specifiche dei prodotti di dati: i consumatori di dati sono liberi di cercare qualsiasi prodotto di dati che i produttori di dati hanno registrato nel catalogo centrale. Per tutti i prodotti di dati, il tag del prodotto di dati specifica come effettuare le richieste di accesso ai dati e la modalità di utilizzo dei dati dall'interfaccia del prodotto di dati richiesta. I campi nei tag del prodotto di dati sono ricercabili utilizzando un'applicazione di ricerca. Le interfacce dei prodotti di dati implementano gli URI di dati, il che significa che i dati non devono essere spostati in una zona di consumo separata per servire i consumatori. Nelle situazioni in cui non sono necessari dati in tempo reale, i consumatori eseguono query sui prodotti di dati e creano report con i risultati generati.
Passaggio 2: esplorazione dei dati tramite l'accesso interattivo ai dati e la prototipazione:i consumatori di dati utilizzano strumenti interattivi come BigQuery Studio e Jupyter Notebook per interpretare e sperimentare i dati al fine di perfezionare le query necessarie per l'utilizzo in produzione. Le query interattive consentono ai consumatori di dati di esplorare nuove dimensioni dei dati e migliorare la correttezza degli approfondimenti generati negli scenari di produzione.
Passaggio 3: utilizza il prodotto di dati tramite un'applicazione, con accesso programmatico e produzione:
- Report BI. I report e le dashboard batch e quasi in tempo reale sono il gruppo più comune di casi d'uso di analisi richiesti dai consumatori di dati. I report potrebbero richiedere l'accesso a più prodotti di dati per facilitare il processo decisionale. Ad esempio, una piattaforma di dati dei clienti richiede l'interrogazione programmatica sia degli ordini sia dei prodotti di dati CRM in modo pianificato. I risultati di un approccio di questo tipo forniscono una visione olistica del cliente agli utenti aziendali che consumano i dati.
- Modello AI/ML per la previsione batch e in tempo reale. I data scientist utilizzano principi MLOps comuni per creare e gestire modelli ML che utilizzano prodotti di dati resi disponibili dai team di prodotti di dati. I modelli ML forniscono funzionalità di inferenza in tempo reale per casi d'uso transazionali come il rilevamento di attività fraudolente. Analogamente, con l'analisi esplorativa dei dati, i consumer di dati possono arricchire i dati di origine. Ad esempio, l'analisi esplorativa dei dati sulle vendite e sulle campagne di marketing mostra i segmenti demografici dei clienti in cui si prevede che le vendite siano più elevate e quindi dove devono essere pubblicate le campagne.
Passaggi successivi
- Consulta un'implementazione di riferimento dell'architettura di mesh di dati.
- Scopri di più su BigQuery.
- Scopri di più su Vertex AI.
- Scopri di più sulla data science su Dataproc.
- Per ulteriori architetture di riferimento, diagrammi e best practice, esplora il Cloud Architecture Center.