Dokumen ini menunjukkan cara memulai data science dalam skala besar dengan R di Google Cloud. Tutorial ini ditujukan bagi mereka yang memiliki pengalaman menggunakan notebook R dan Jupyter, serta terbiasa menggunakan SQL.
Dokumen ini berfokus pada menjalankan analisis data eksploratif menggunakan instance Vertex AI Workbench dan BigQuery. Anda dapat menemukan kode yang menyertainya di Jupyter notebook yang ada di GitHub.
Ringkasan
R merupakan salah satu bahasa pemrograman yang paling banyak digunakan untuk pemodelan statistik. Bahasa pemrograman ini memiliki komunitas data scientist dan tenaga profesional machine learning (ML). Dengan lebih dari 20.000 paket di repositori open source Comprehensive R Archive Network (CRAN), R memiliki alat untuk semua aplikasi analisis data statistik, ML, dan visualisasi. R telah mengalami pertumbuhan yang stabil dalam dua dekade terakhir karena sintaksisnya yang ekspresif serta data dan library ML yang komprehensif.
Sebagai data scientist, Anda mungkin ingin mengetahui cara memanfaatkan keahlian Anda dengan menggunakan R serta cara memanfaatkan keunggulan layanan cloud yang skalabel dan terkelola sepenuhnya untuk data science.
Arsitektur
Dalam panduan ini, Anda akan menggunakan instance Vertex AI Workbench sebagai lingkungan data science untuk melakukan analisis data eksploratif (EDA). Anda akan menggunakan R untuk menganalisis data yang diekstrak dalam panduan ini dari BigQuery, cloud data warehouse (CDW) Google yang serverless, sangat skalabel, dan hemat biaya. Setelah Anda menganalisis dan memproses data, data yang ditransformasi akan disimpan di Cloud Storage untuk potensi tugas ML lebih lanjut. Alur ini ditunjukkan dalam diagram berikut:

Data contoh
Contoh data untuk dokumen ini adalah
set data perjalanan taksi New York City BigQuery.
Set data publik ini mencakup informasi tentang jutaan perjalanan taksi yang
terjadi di New York City setiap tahun. Dalam dokumen ini, Anda menggunakan data dari tahun 2022, yang ada di tabel bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022 di BigQuery.
Dokumen ini berfokus pada EDA dan visualisasi yang menggunakan R dan BigQuery. Langkah-langkah dalam dokumen ini menyiapkan Anda untuk sasaran ML memprediksi jumlah tarif taksi (jumlah sebelum pajak, biaya, dan tambahan lainnya), dengan mempertimbangkan sejumlah faktor tentang perjalanan. Pembuatan model yang sebenarnya tidak dibahas dalam dokumen ini.
Vertex AI Workbench
Vertex AI Workbench adalah layanan yang menawarkan lingkungan JupyterLab terintegrasi, dengan fitur berikut:
- Deployment sekali klik. Anda dapat menggunakan satu klik untuk memulai JupyterLab instance yang sebelumnya telah dikonfigurasi dengan framework terbaru machine-learning dan data-science.
- Skala sesuai permintaan. Anda dapat memulainya dengan konfigurasi mesin kecil (misalnya, 4 vCPU dan 16 GB RAM, seperti dalam dokumen ini), dan saat data menjadi terlalu besar untuk satu mesin, Anda dapat meningkatkan skalanya dengan menambahkan CPU, RAM, dan GPU.
- IntegrasiGoogle Cloud . Instance Vertex AI Workbench diintegrasikan dengan layanan Google Cloud seperti BigQuery. Integrasi ini memudahkan Anda beralih dari penyerapan data ke prapemrosesan dan eksplorasi.
- Harga sesuai penggunaan. Tidak ada biaya minimum atau komitmen di awal. Untuk mengetahui informasinya, lihat harga untuk Vertex AI Workbench. Anda juga membayar Google Cloud resource yang digunakan dalam notebook (seperti BigQuery dan Cloud Storage).
Notebook instance Vertex AI Workbench berjalan di Deep Learning VM Image. Dokumen ini mendukung pembuatan instance Vertex AI Workbench yang memiliki R 4.3.
Bekerja dengan BigQuery menggunakan R
BigQuery tidak memerlukan pengelolaan infrastruktur, sehingga Anda dapat berfokus untuk menemukan insight yang bermakna. Anda dapat menganalisis data dalam jumlah dan skala besar serta menyiapkan set data untuk ML menggunakan kemampuan analisis SQL yang kaya dari BigQuery.
Untuk membuat kueri data BigQuery menggunakan R, Anda dapat menggunakan library open source R bigrquery. Paket bigrquery menyediakan tingkat abstraksi berikut di atas BigQuery:
- API tingkat rendah menyediakan wrapper tipis di atas BigQuery REST API yang mendasarinya.
- Antarmuka DBI menggabungkan API tingkat rendah dan membuat penggunaan BigQuery terasa seperti bekerja dengan sistem database lainnya. Ini adalah lapisan yang paling praktis jika Anda ingin menjalankan kueri SQL di BigQuery atau mengupload kurang dari 100 MB.
- Dengan antarmuka dbplyr, Anda dapat memperlakukan tabel BigQuery seperti bingkai data dalam memori. Ini adalah lapisan yang paling praktis jika Anda tidak ingin menulis SQL, tetapi ingin dbplyr menulisnya untuk Anda.
Dokumen ini menggunakan API level rendah dari bigrquery, tanpa memerlukan DBI atau dbplyr.
Tujuan
- Buat instance Vertex AI Workbench yang memiliki dukungan R.
- Membuat kueri dan menganalisis data dari BigQuery menggunakan library R bigrquery.
- Menyiapkan dan menyimpan data untuk ML di Cloud Storage.
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
- BigQuery
- Vertex AI Workbench instances. You are also charged for resources used within notebooks, including compute resources, BigQuery, and API requests.
- Cloud Storage
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Membuat instance Vertex AI Workbench
Langkah pertama adalah membuat instance Vertex AI Workbench yang dapat Anda gunakan untuk panduan ini.
Di konsol Google Cloud, buka halaman Workbench.
Di tab Instances, klik Create New.
Di jendela New instance, klik Create. Untuk panduan ini, pertahankan semua nilai default.
Instance Vertex AI Workbench dapat memerlukan waktu 2-3 menit untuk dimulai. Jika sudah siap, instance akan otomatis tercantum di panel Instance notebook, dan link Buka JupyterLab akan muncul di samping nama instance. Jika link untuk membuka JupyterLab tidak muncul dalam daftar setelah beberapa menit, muat ulang halaman.
Membuka JupyterLab dan menginstal R
Untuk menyelesaikan panduan di notebook, Anda harus membuka lingkungan JupyterLab, menginstal R, meng-clone repositori GitHub vertex-ai-samples, lalu membuka notebook.
Pada daftar instance, klik Buka Jupyterlab. Tindakan ini akan membuka lingkungan JupyterLab di tab lain di browser Anda.
Di lingkungan JupyterLab, klik New Launcher, lalu di tab Launcher, klik Terminal.
Di panel terminal, instal R:
conda create -n r conda activate r conda install -c r r-essentials r-base=4.3.2Selama penginstalan, setiap kali Anda diminta untuk melanjutkan, ketik
y. Mungkin perlu waktu beberapa menit untuk menyelesaikan penginstalan. Setelah penginstalan selesai, output-nya akan terlihat seperti berikut:done Executing transaction: done ® jupyter@instance-INSTANCE_NUMBER:~$Dengan INSTANCE_NUMBER adalah angka unik yang ditetapkan ke instance Vertex AI Workbench Anda.
Setelah perintah selesai dieksekusi di terminal, muat ulang halaman browser, lalu buka Peluncur dengan mengklik New Launcher.
Tab Launcher menampilkan opsi untuk meluncurkan R di notebook atau di konsol, dan untuk membuat file R.
Klik tab Terminal, lalu clone repositori GitHub vertex-ai-samples:
git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.gitSetelah perintah selesai, Anda akan melihat folder
vertex-ai-samplesdi panel file browser lingkungan JupyterLab.Di file browser, buka
vertex-ai-samples>notebooks>community>exploratory_data_analysis. Anda akan melihat notebookeda_with_r_and_bigquery.ipynb.
Membuka notebook dan menyiapkan R
Di file browser, buka notebook
eda_with_r_and_bigquery.ipynb.Notebook ini membahas analisis data eksploratif dengan R dan BigQuery. Di seluruh dokumen ini, Anda akan bekerja di notebook dan menjalankan kode yang terlihat di dalam notebook Jupyter.
Periksa versi R yang digunakan notebook:
versionKolom
version.stringdalam output akan menampilkanR version 4.3.2, yang Anda instal di bagian sebelumnya.Periksa dan instal paket R yang diperlukan jika belum tersedia dalam sesi saat ini:
# List the necessary packages needed_packages <- c("dplyr", "ggplot2", "bigrquery") # Check if packages are installed installed_packages <- .packages(all.available = TRUE) missing_packages <- needed_packages[!(needed_packages %in% installed_packages)] # If any packages are missing, install them if (length(missing_packages) > 0) { install.packages(missing_packages) }Muat paket yang diperlukan:
# Load the required packages lapply(needed_packages, library, character.only = TRUE)Autentikasi
bigrquerymenggunakan autentikasi out-of-band:bq_auth(use_oob = True)Tetapkan nama project yang ingin Anda gunakan untuk notebook ini dengan mengganti
[YOUR-PROJECT-ID]dengan nama:# Set the project ID PROJECT_ID <- "[YOUR-PROJECT-ID]"Tetapkan nama bucket Cloud Storage tempat data output akan disimpan dengan mengganti
[YOUR-BUCKET-NAME]dengan nama yang unik secara global:BUCKET_NAME <- "[YOUR-BUCKET-NAME]"Tetapkan tinggi dan lebar default untuk plot yang akan dibuat nanti di notebook:
options(repr.plot.height = 9, repr.plot.width = 16)
Membuat kueri data dari BigQuery
Di bagian notebook ini, Anda akan membaca hasil eksekusi pernyataan SQL BigQuery ke dalam R dan meninjau data lebih awal.
Buat pernyataan SQL BigQuery yang mengekstrak beberapa prediktor yang memungkinkan dan variabel prediksi target untuk sampel perjalanan. Kueri berikut memfilter beberapa nilai outlier atau tidak masuk akal di kolom yang sedang dibaca untuk analisis.
sql_query_template <- " SELECT TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes, passenger_count, ROUND(trip_distance, 1) AS trip_distance_miles, rate_code, /* Mapping from rate code to type from description column in BigQuery table schema */ (CASE WHEN rate_code = '1.0' THEN 'Standard rate' WHEN rate_code = '2.0' THEN 'JFK' WHEN rate_code = '3.0' THEN 'Newark' WHEN rate_code = '4.0' THEN 'Nassau or Westchester' WHEN rate_code = '5.0' THEN 'Negotiated fare' WHEN rate_code = '6.0' THEN 'Group ride' /* Several NULL AND some '99.0' values go here */ ELSE 'Unknown' END) AS rate_type, fare_amount, CAST(ABS(FARM_FINGERPRINT( CONCAT( CAST(trip_distance AS STRING), CAST(fare_amount AS STRING) ) )) AS STRING) AS key FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` /* Filter out some outlier or hard to understand values */ WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) LIMIT %s "Kolom
keyadalah ID baris yang dihasilkan berdasarkan nilai yang digabungkan dari kolomtrip_distancedanfare_amount.Jalankan kueri dan ambil data yang sama sebagai tibble dalam memori, yang mirip dengan frame data.
sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) taxi_trip_data <- bq_table_download( bq_project_query( PROJECT_ID, query = sql_query ) )Lihat hasil yang diambil:
head(taxi_trip_data)Outputnya adalah tabel yang mirip dengan gambar berikut:
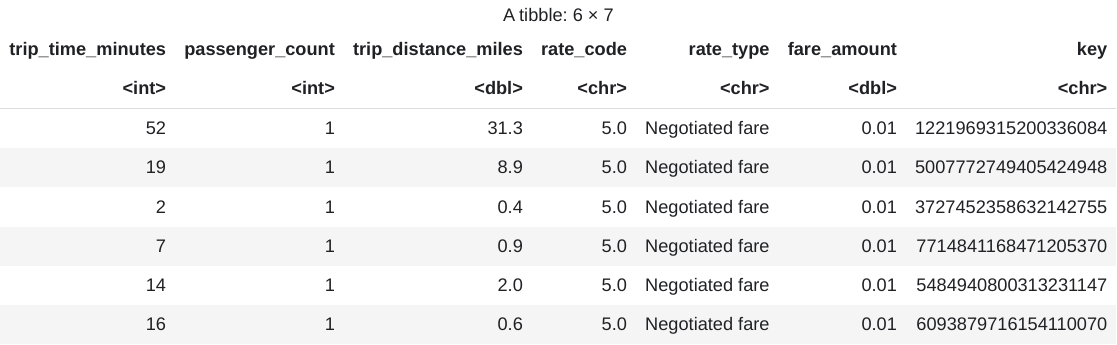
Hasilnya menampilkan kolom data perjalanan berikut:
- Bilangan bulat
trip_time_minutes - Bilangan bulat
passenger_count trip_distance_milesgandarate_codekarakterrate_typekarakterfare_amountgandakeykarakter
- Bilangan bulat
Lihat jumlah baris dan jenis data setiap kolom:
str(taxi_trip_data)Outputnya mirip dengan yang berikut ini:
tibble [10,000 x 7] (S3: tbl_df/tbl/data.frame) $ trip_time_minutes : int [1:10000] 52 19 2 7 14 16 1 2 2 6 ... $ passenger_count : int [1:10000] 1 1 1 1 1 1 1 1 3 1 ... $ trip_distance_miles: num [1:10000] 31.3 8.9 0.4 0.9 2 0.6 1.7 0.4 0.5 0.2 ... $ rate_code : chr [1:10000] "5.0" "5.0" "5.0" "5.0" ... $ rate_type : chr [1:10000] "Negotiated fare" "Negotiated fare" "Negotiated fare" "Negotiated fare" ... $ fare_amount : num [1:10000] 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 ... $ key : chr [1:10000] "1221969315200336084" 5007772749405424948" "3727452358632142755" "77714841168471205370" ...Lihat ringkasan data yang diambil:
summary(taxi_trip_data)Outputnya mirip dengan hal berikut ini:
trip_time_minutes passenger_count trip_distance_miles rate_code Min. : 1.00 Min. :1.000 Min. : 0.000 Length:10000 1st Qu.: 20.00 1st Qu.:1.000 1st Qu.: 3.700 Class :character Median : 24.00 Median :1.000 Median : 4.800 Mode :character Mean : 30.32 Mean :1.465 Mean : 9.639 3rd Qu.: 39.00 3rd Qu.:2.000 3rd Qu.:17.600 Max. :120.00 Max. :9.000 Max. :43.700 rate_type fare_amount key Length:10000 Min. : 0.01 Length:10000 Class :character 1st Qu.: 16.50 Class :character Mode :character Median : 16.50 Mode :character Mean : 31.22 3rd Qu.: 52.00 Max. :182.50
Memvisualisasikan data menggunakan ggplot2
Di bagian notebook ini, Anda akan menggunakan library ggplot2 di R untuk mempelajari beberapa variabel dari contoh set data.
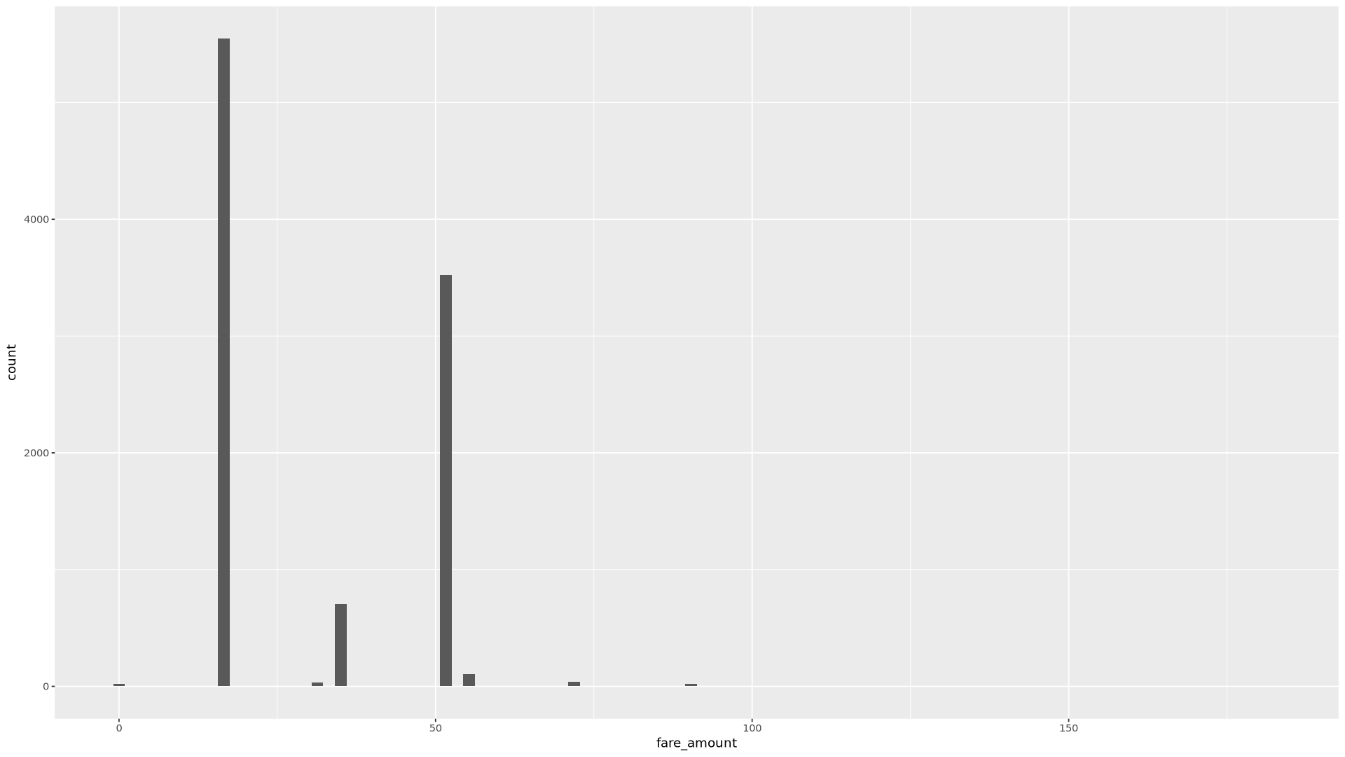
Tampilkan distribusi nilai
fare_amountmenggunakan histogram:ggplot( data = taxi_trip_data, aes(x = fare_amount) ) + geom_histogram(bins = 100)Plot yang dihasilkan mirip dengan grafik pada gambar berikut:
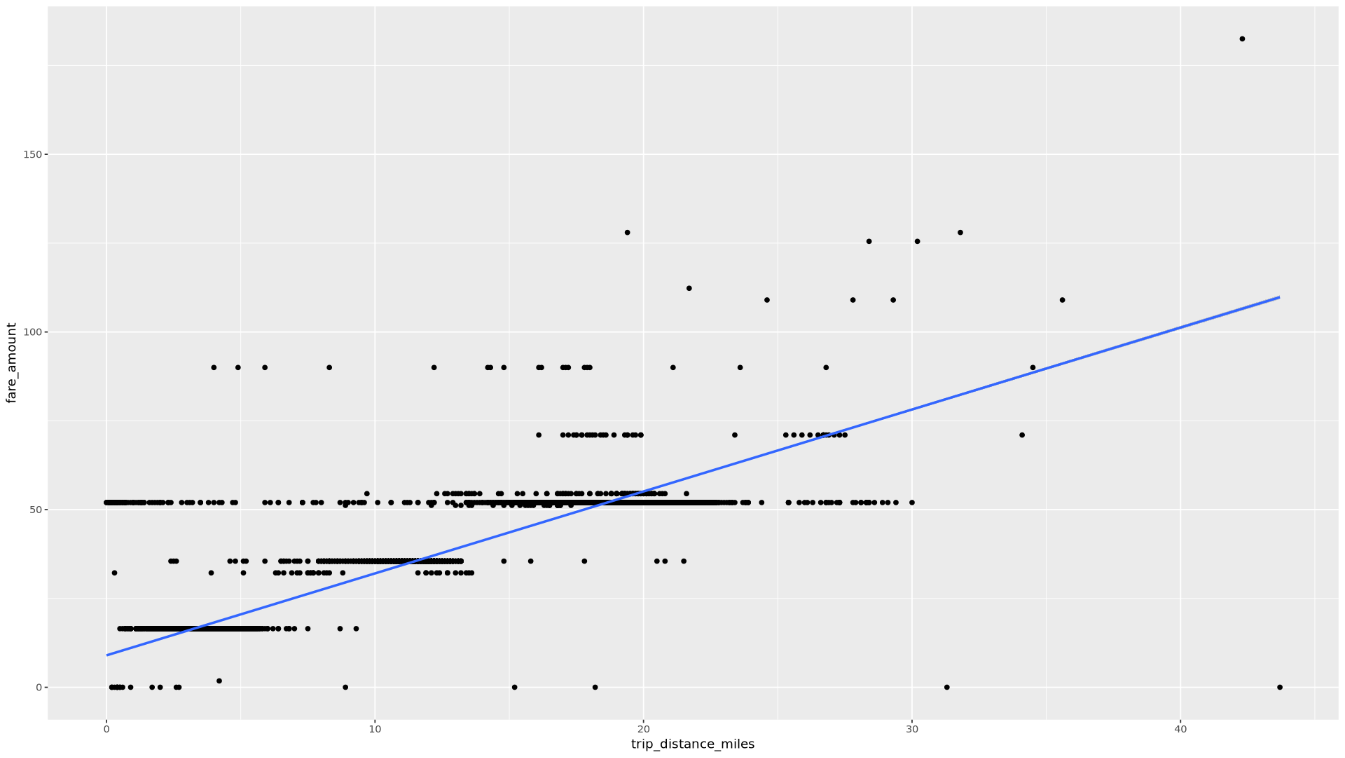
Tampilkan hubungan antara
trip_distancedanfare_amountmenggunakan diagram sebar:ggplot( data = taxi_trip_data, aes(x = trip_distance_miles, y = fare_amount) ) + geom_point() + geom_smooth(method = "lm")Plot yang dihasilkan mirip dengan grafik pada gambar berikut:
Memproses data di BigQuery dari R
Saat Anda bekerja dengan set data besar, sebaiknya lakukan analisis sebanyak mungkin di BigQuery (seperti agregasi, pemfilteran, penggabungan, komputasi kolom, dan sebagainya), lalu ambil hasilnya. Melakukan tugas-tugas ini di R kurang efisien. Menggunakan BigQuery untuk analisis data memanfaatkan skalabilitas dan performa BigQuery, serta memastikan hasil yang diperoleh dapat masuk ke dalam memori R.
Di notebook, buat fungsi yang menemukan jumlah perjalanan dan jumlah tarif rata-rata untuk setiap nilai kolom yang dipilih:
get_distinct_value_aggregates <- function(column) { query <- paste0( 'SELECT ', column, ', COUNT(1) AS num_trips, AVG(fare_amount) AS avg_fare_amount FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) GROUP BY 1 ' ) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }Panggil fungsi menggunakan kolom
trip_time_minutesyang ditentukan menggunakan fungsi stempel waktu di BigQuery:df <- get_distinct_value_aggregates( 'TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes') ggplot( data = df, aes(x = trip_time_minutes, y = num_trips) ) + geom_line() ggplot( data = df, aes(x = trip_time_minutes, y = avg_fare_amount) ) + geom_line()Notebook menampilkan dua grafik. Grafik pertama menunjukkan jumlah perjalanan menurut durasi perjalanan dalam menit. Grafik kedua menunjukkan jumlah tarif rata-rata perjalanan menurut waktu perjalanan.
Output perintah
ggplotpertama adalah sebagai berikut, yang menampilkan jumlah perjalanan berdasarkan durasi perjalanan (dalam menit):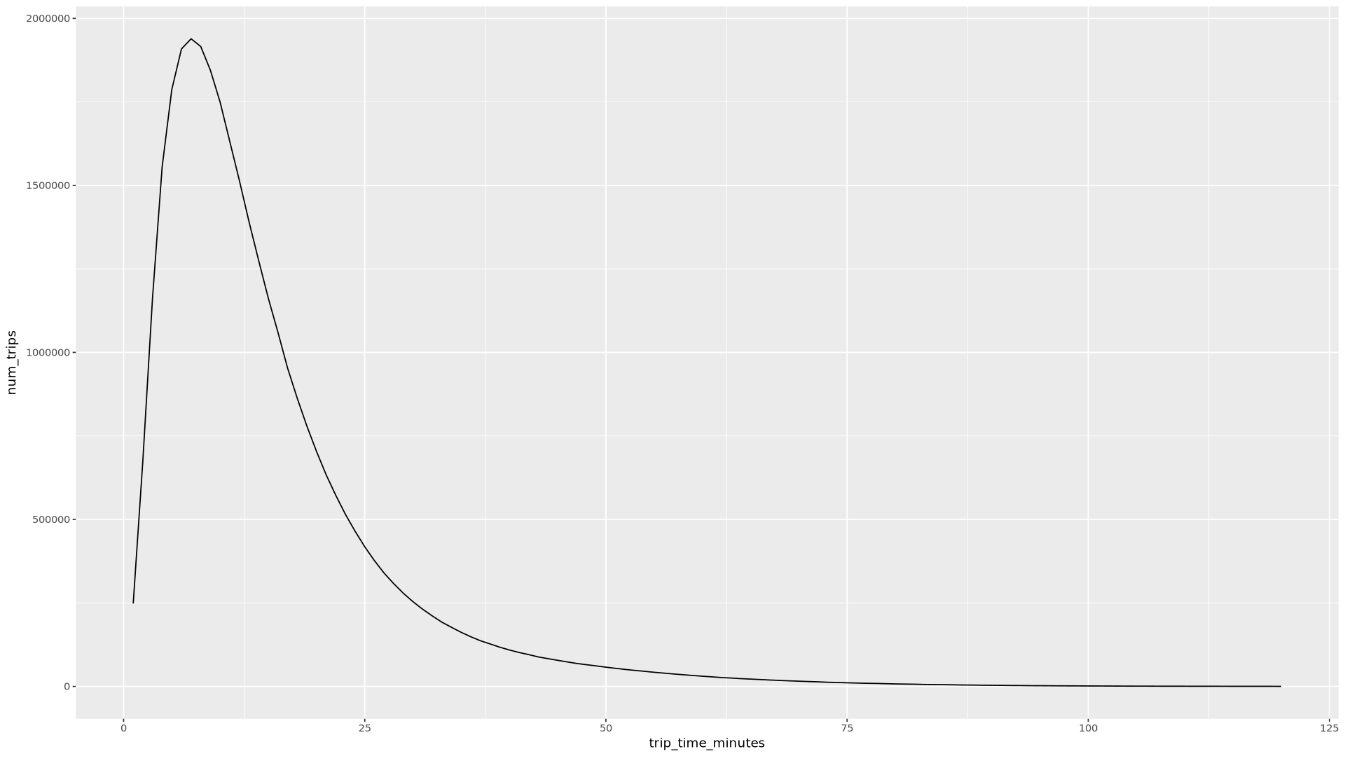
Output perintah
ggplotkedua adalah sebagai berikut, yang menampilkan jumlah tarif rata-rata perjalanan berdasarkan waktu perjalanan: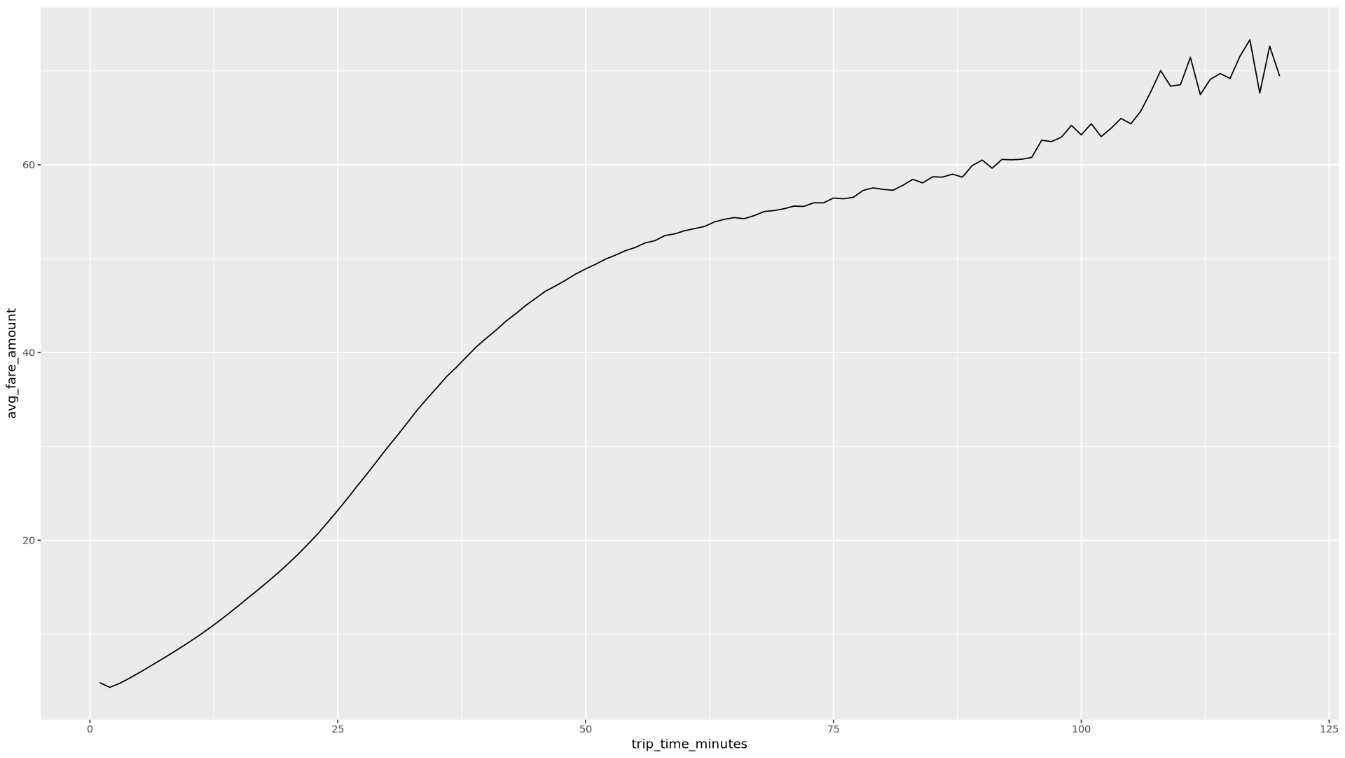
Untuk melihat contoh visualisasi lainnya dengan kolom lain dalam data, lihat notebook.
Menyimpan data sebagai file CSV ke Cloud Storage
Tugas berikutnya adalah menyimpan data yang diekstrak dari BigQuery sebagai file CSV di Cloud Storage sehingga Anda dapat menggunakannya untuk tugas ML lebih lanjut.
Di notebook, muat data pelatihan dan evaluasi dari BigQuery ke R:
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) # Split data into 75% training, 25% evaluation train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )Periksa jumlah pengamatan di setiap set data:
print(paste0("Training instances count: ", nrow(train_data))) print(paste0("Evaluation instances count: ", nrow(eval_data)))Sekitar 75% dari total instance harus dalam pelatihan, dengan sekitar 25% instance yang tersisa dalam evaluasi.
Tulis data ke file CSV lokal:
# Write data frames to local CSV files, with headers dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = TRUE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = TRUE, sep = ",")Upload file CSV ke Cloud Storage dengan menggabungkan perintah
gsutilyang diteruskan ke sistem:# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)Anda juga dapat mengupload file CSV ke Cloud Storage menggunakan library googleCloudStorageR, yang memanggil Cloud Storage JSON API.
Anda juga dapat menggunakan bigrquery untuk menulis data dari R kembali ke BigQuery. Menulis kembali ke BigQuery biasanya dilakukan setelah menyelesaikan beberapa prapemrosesan atau menghasilkan hasil yang akan digunakan untuk analisis lebih lanjut.
Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam dokumen ini, Anda harus menghapusnya.
Menghapus project
Cara termudah untuk menghilangkan penagihan adalah dengan menghapus project yang Anda buat. Jika Anda berencana mempelajari beberapa arsitektur, tutorial, atau panduan memulai, maka menggunakan kembali project dapat membantu Anda agar tidak melampaui batas kuota project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Langkah berikutnya
- Pelajari lebih lanjut cara menggunakan data BigQuery di notebook R di dokumentasi bigrquery.
- Pelajari praktik terbaik untuk ML engineering di Aturan ML.
- Untuk ringkasan prinsip dan rekomendasi arsitektur yang khusus untuk beban kerja AI dan ML di Google Cloud, lihat perspektif AI dan ML di Framework Arsitektur.
- Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.
Kontributor
Author: Alok Pattani | Developer Advocate
Kontributor lainnya:
- Jason Davenport | Developer Advocate
- Firat Tekiner | Senior Product Manager