Dokumen ini menjelaskan dua arsitektur referensi yang membantu Anda membuat platform pemelajaran gabungan di Google Cloud menggunakan Google Kubernetes Engine (GKE). Arsitektur referensi dan resource terkait yang dijelaskan dalam dokumen ini mendukung hal berikut:
- Federated learning lintas silo
- Federated learning lintas perangkat, yang dibuat berdasarkan arsitektur lintas silo
Audiens yang dituju untuk dokumen ini adalah arsitek cloud serta engineer AI dan ML yang ingin menerapkan kasus penggunaan federated learning diGoogle Cloud. Fitur ini juga ditujukan untuk pengambil keputusan yang mengevaluasi apakah akan menerapkan federated learning di Google Cloud.
Arsitektur
Diagram di bagian ini menunjukkan arsitektur lintas silo dan arsitektur lintas perangkat untuk federated learning. Untuk mempelajari berbagai aplikasi untuk arsitektur ini, lihat Kasus penggunaan.
Arsitektur lintas silo
Diagram berikut menunjukkan arsitektur yang mendukung pembelajaran gabungan lintas-silo:

Diagram sebelumnya menunjukkan contoh sederhana arsitektur lintas silo. Dalam diagram, semua resource berada dalam project yang sama di organisasi Google Cloud. Resource ini mencakup model klien lokal, model klien global, dan workload federated learning terkait.
Arsitektur referensi ini dapat diubah untuk mendukung beberapa konfigurasi untuk silo data. Anggota konsorsium dapat menghosting silo data mereka dengan cara berikut:
- Di Google Cloud, dalam Google Cloud organisasi yang sama, dan project Google Cloud yang sama.
- Di Google Cloud, dalam organisasi Google Cloud yang sama, dalam project Google Cloud yang berbeda.
- Di Google Cloud, di organisasi Google Cloud yang berbeda.
- Di lingkungan lokal pribadi, atau di cloud publik lainnya.
Agar dapat berkolaborasi, anggota yang berpartisipasi perlu membuat saluran komunikasi yang aman di antara lingkungan mereka. Untuk informasi selengkapnya tentang peran anggota yang berpartisipasi dalam upaya federated learning, cara mereka berkolaborasi, dan apa yang mereka bagikan kepada satu sama lain, lihat Kasus penggunaan.
Arsitektur ini mencakup komponen berikut:
- Jaringan Virtual Private Cloud (VPC) dan subnet.
- Cluster GKE pribadi yang membantu Anda melakukan hal berikut:
- Isolasi node cluster dari internet.
- Batasi eksposur node cluster dan bidang kontrol Anda ke internet dengan membuat cluster GKE pribadi menggunakan jaringan resmi.
- Gunakan node cluster yang dilindungi yang menggunakan image sistem operasi yang telah di-hardening.
- Aktifkan Dataplane V2 untuk jaringan Kubernetes yang dioptimalkan.
- Node pool GKE khusus: Anda membuat node pool khusus untuk secara eksklusif menghosting aplikasi dan resource tenant. Node memiliki taint untuk memastikan bahwa hanya workload tenant yang dijadwalkan ke node tenant. Resource cluster lainnya dihosting di node pool utama.
Enkripsi data (diaktifkan secara default):
- Data dalam penyimpanan.
- Data dalam pengiriman.
- Rahasia cluster pada lapisan aplikasi.
Enkripsi data yang sedang digunakan, dengan mengaktifkan Confidential Google Kubernetes Engine Nodes secara opsional.
Aturan Firewall VPC yang menerapkan hal berikut:
- Aturan dasar pengukuran yang berlaku untuk semua node di cluster.
- Aturan tambahan yang hanya berlaku untuk node di node pool tenant. Aturan firewall ini membatasi traffic masuk ke dan keluar dari node tenant.
Cloud NAT untuk mengizinkan traffic keluar ke internet.
Data Cloud DNS untuk mengaktifkan Akses Google Pribadi sehingga aplikasi dalam cluster dapat mengakses Google API tanpa melalui internet.
Akun layanan yang terdiri dari:
- Akun layanan khusus untuk node dalam node pool tenant.
- Akun layanan khusus untuk aplikasi tenant yang akan digunakan dengan Workload Identity Federation.
Dukungan untuk menggunakan Google Grup untuk kontrol akses berbasis peran (RBAC) Kubernetes.
Repositori Git untuk menyimpan deskriptor konfigurasi.
Repositori Artifact Registry untuk menyimpan image container.
Config Sync dan Policy Controller untuk men-deploy konfigurasi dan kebijakan.
Gateway Cloud Service Mesh untuk mengizinkan traffic masuk dan keluar cluster secara selektif.
Bucket Cloud Storage untuk menyimpan bobot model global dan lokal.
Akses ke Google API dan Google Cloud API lainnya. Misalnya, beban kerja pelatihan mungkin perlu mengakses data pelatihan yang disimpan di Cloud Storage, BigQuery, atau Cloud SQL.
Arsitektur lintas perangkat
Diagram berikut menunjukkan arsitektur yang mendukung federated learning lintas perangkat:
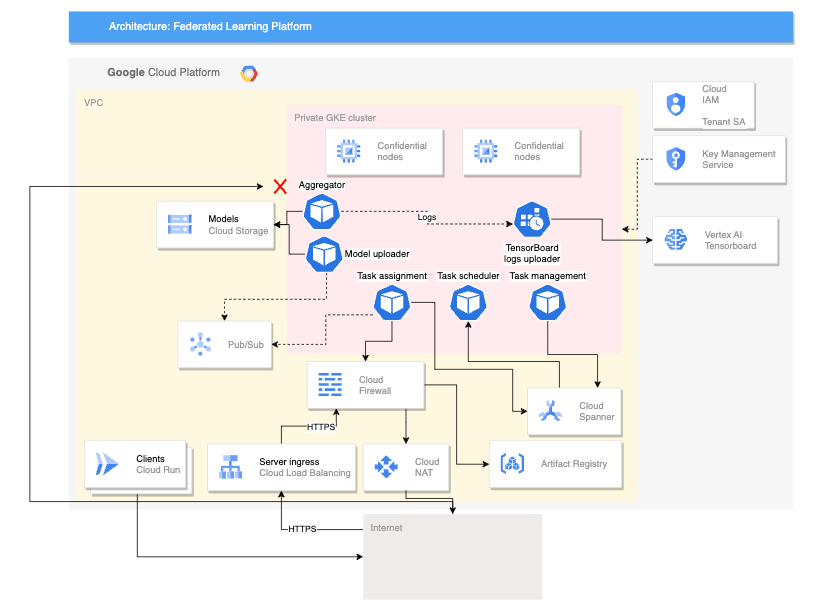
Arsitektur lintas perangkat sebelumnya dibuat berdasarkan arsitektur lintas silo dengan penambahan komponen berikut:
- Layanan Cloud Run yang menyimulasikan perangkat yang terhubung ke server
- Layanan Certificate Authority yang membuat sertifikat pribadi untuk server dan klien agar dapat berjalan
- Vertex AI TensorBoard untuk memvisualisasikan hasil pelatihan
- Bucket Cloud Storage untuk menyimpan model gabungan
- Cluster GKE pribadi yang menggunakan node rahasia sebagai kumpulan utama untuk membantu mengamankan data yang sedang digunakan
Arsitektur lintas perangkat menggunakan komponen dari project Federated Compute Platform (FCP) open source. Project ini mencakup hal berikut:
- Kode klien untuk berkomunikasi dengan server dan menjalankan tugas di perangkat
- Protokol untuk komunikasi klien-server
- Titik koneksi dengan TensorFlow Federated untuk mempermudah menentukan komputasi gabungan Anda
Komponen FCP yang ditampilkan dalam diagram sebelumnya dapat di-deploy sebagai kumpulan microservice. Komponen ini melakukan hal berikut:
- Agregator: Tugas ini membaca gradien perangkat dan menghitung hasil agregasi dengan Privasi Diferensial.
- Pengumpul: Tugas ini berjalan secara berkala untuk membuat kueri tugas aktif dan gradien terenkripsi. Informasi ini menentukan kapan agregasi dimulai.
- Uploader model: Tugas ini memproses peristiwa dan memublikasikan hasil sehingga perangkat dapat mendownload model yang diperbarui.
- Penugasan tugas: Layanan frontend ini mendistribusikan tugas pelatihan ke perangkat.
- Task-management: Tugas ini mengelola tugas.
- Task-scheduler: Tugas ini berjalan secara berkala atau dipicu oleh peristiwa tertentu.
Produk yang digunakan
Arsitektur referensi untuk kedua kasus penggunaan federated learning menggunakan komponen Google Cloud berikut:
- Google Cloud Kubernetes engine (GKE): GKE menyediakan platform dasar untuk federated learning.
- TensorFlow Federated (TFF): TFF menyediakan framework open source untuk machine learning dan komputasi lainnya pada data terdesentralisasi.
GKE juga menyediakan kemampuan berikut ke platform federated learning Anda:
- Menghosting koordinator federated learning: Koordinator federated learning bertanggung jawab untuk mengelola proses federated learning. Pengelolaan ini mencakup tugas seperti mendistribusikan model global kepada partisipan, menggabungkan update dari peserta, dan mengupdate model global. GKE dapat digunakan untuk menghosting koordinator pembelajaran gabungan dengan cara yang sangat tersedia dan skalabel.
- Menghosting peserta federated learning: Peserta federated learning bertanggung jawab untuk melatih model global pada data lokal mereka. GKE dapat digunakan untuk menghosting peserta federated learning dengan cara yang aman dan terisolasi. Pendekatan ini dapat membantu memastikan data peserta disimpan secara lokal.
- Menyediakan saluran komunikasi yang aman dan skalabel: Peserta federated learning harus dapat berkomunikasi dengan koordinator federated learning dengan cara yang aman dan skalabel. GKE dapat digunakan untuk menyediakan saluran komunikasi yang aman dan skalabel antara peserta dan koordinator.
- Mengelola siklus proses deployment federated learning: GKE dapat digunakan untuk mengelola siklus proses deployment federated learning. Pengelolaan ini mencakup tugas seperti menyediakan resource, men-deploy platform federated learning, dan memantau performa platform federated learning.
Selain manfaat ini, GKE juga menyediakan sejumlah fitur yang dapat berguna untuk deployment federated learning, seperti berikut:
- Cluster regional: GKE memungkinkan Anda membuat cluster regional, yang membantu Anda meningkatkan performa deployment pembelajaran gabungan dengan mengurangi latensi antara peserta dan koordinator.
- Kebijakan jaringan: GKE memungkinkan Anda membuat kebijakan jaringan, yang membantu meningkatkan keamanan deployment federated learning dengan mengontrol aliran traffic antara peserta dan koordinator.
- Load balancing: GKE menyediakan sejumlah opsi load balancing, yang membantu meningkatkan skalabilitas deployment federated learning dengan mendistribusikan traffic antara peserta dan koordinator.
TFF menyediakan fitur berikut untuk memfasilitasi penerapan kasus penggunaan federated learning:
- Kemampuan untuk secara deklaratif mengekspresikan komputasi gabungan, yang merupakan serangkaian langkah pemrosesan yang berjalan di server dan sekumpulan klien. Komputasi ini dapat di-deploy ke berbagai lingkungan runtime.
- Agregator kustom dapat dibuat menggunakan open source TFF.
- Dukungan untuk berbagai algoritma federated learning, termasuk
algoritma berikut:
- Pembentukan rata-rata gabungan:
Algoritme yang menghitung rata-rata parameter model klien
yang berpartisipasi. Model ini sangat cocok untuk kasus penggunaan dengan data
yang relatif homogen dan model yang tidak terlalu kompleks. Kasus penggunaan umum adalah
sebagai berikut:
- Rekomendasi yang dipersonalisasi: Perusahaan dapat menggunakan rata-rata gabungan untuk melatih model yang merekomendasikan produk kepada pengguna berdasarkan histori pembelian mereka.
- Deteksi penipuan: Konsorsium bank dapat menggunakan rata-rata gabungan untuk melatih model yang mendeteksi transaksi penipuan.
- Diagnosis medis: Sekelompok rumah sakit dapat menggunakan rata-rata gabungan untuk melatih model yang mendiagnosis kanker.
- Penurunan gradien stokastik gabungan (FedSGD): Algoritme yang menggunakan penurunan gradien stokastik untuk memperbarui parameter
model. Model ini sangat cocok untuk kasus penggunaan dengan data yang heterogen
dan model yang kompleks. Kasus penggunaan umum adalah sebagai berikut:
- Pemrosesan bahasa alami: Perusahaan dapat menggunakan FedSGD untuk melatih model yang meningkatkan akurasi pengenalan ucapan.
- Pengenalan gambar: Perusahaan dapat menggunakan FedSGD untuk melatih model yang dapat mengidentifikasi objek dalam gambar.
- Pemeliharaan prediktif: Perusahaan dapat menggunakan FedSGD untuk melatih model yang memprediksi kapan mesin cenderung akan gagal.
- Federated Adam:
Algoritma yang menggunakan pengoptimal Adam untuk memperbarui parameter model.
Kasus penggunaan umum adalah sebagai berikut:
- Sistem rekomendasi: Perusahaan dapat menggunakan federated Adam untuk melatih model yang merekomendasikan produk kepada pengguna berdasarkan histori pembelian mereka.
- Pengurutan: Perusahaan dapat menggunakan federated Adam untuk melatih model yang mengurutkan hasil penelusuran.
- Prediksi rasio klik-tayang: Perusahaan dapat menggunakan Adam gabungan untuk melatih model yang memprediksi kemungkinan pengguna mengklik iklan.
- Pembentukan rata-rata gabungan:
Algoritme yang menghitung rata-rata parameter model klien
yang berpartisipasi. Model ini sangat cocok untuk kasus penggunaan dengan data
yang relatif homogen dan model yang tidak terlalu kompleks. Kasus penggunaan umum adalah
sebagai berikut:
Kasus penggunaan
Bagian ini menjelaskan kasus penggunaan yang arsitektur lintas silo dan lintas perangkatnya merupakan pilihan yang sesuai untuk platform federated learning Anda.
Federated learning adalah setelan machine learning tempat banyak klien melatih model secara kolaboratif. Proses ini dipimpin oleh koordinator pusat, dan data pelatihan tetap terdesentralisasi.
Dalam paradigma federated learning, klien mendownload model global dan meningkatkan kualitas model dengan melatih data mereka secara lokal. Kemudian, setiap klien mengirim update model yang dihitung kembali ke server pusat tempat update model digabungkan dan iterasi baru model global dibuat. Dalam arsitektur referensi ini, workload pelatihan model berjalan di GKE.
Federated learning mewujudkan prinsip privasi minimalisasi data, dengan membatasi data yang dikumpulkan di setiap tahap komputasi, membatasi akses ke data, dan memproses lalu menghapus data sedini mungkin. Selain itu, penetapan masalah federated learning kompatibel dengan teknik perlindungan privasi tambahan, seperti menggunakan privasi diferensial (DP) untuk meningkatkan anonimisasi model guna memastikan model akhir tidak mengingat data pengguna perorangan.
Bergantung pada kasus penggunaan, melatih model dengan federated learning dapat memiliki manfaat tambahan:
- Kepatuhan: Dalam beberapa kasus, peraturan mungkin membatasi cara data dapat digunakan atau dibagikan. Federated learning dapat digunakan untuk mematuhi peraturan ini.
- Efisiensi komunikasi: Dalam beberapa kasus, lebih efisien untuk melatih model pada data terdistribusi daripada memusatkan data. Misalnya, set data yang perlu dilatih oleh model terlalu besar untuk dipindahkan secara terpusat.
- Membuat data dapat diakses: Federated learning memungkinkan organisasi menyimpan data pelatihan secara terdesentralisasi dalam silo data per pengguna atau per organisasi.
- Akurasi model yang lebih tinggi: Dengan melakukan pelatihan pada data pengguna sebenarnya (sambil memastikan privasi) dan bukan data sintetis (terkadang disebut sebagai data proxy), sering kali menghasilkan akurasi model yang lebih tinggi.
Ada berbagai jenis federated learning, yang dicirikan oleh tempat asal data dan tempat komputasi lokal terjadi. Arsitektur dalam dokumen ini berfokus pada dua jenis federated learning: lintas silo dan lintas perangkat. Jenis federated learning lainnya berada di luar cakupan dokumen ini.
Pemelajaran gabungan dikategorikan lebih lanjut berdasarkan cara partisi set data, yang dapat berupa:
- Federated learning horizontal (HFL): Set data dengan fitur (kolom) yang sama, tetapi sampel (baris) yang berbeda. Misalnya, beberapa rumah sakit mungkin memiliki catatan pasien dengan parameter medis yang sama, tetapi dengan populasi pasien yang berbeda.
- Federated learning vertikal (VFL): Set data dengan sampel (baris) yang sama, tetapi fitur (kolom) yang berbeda. Misalnya, bank dan perusahaan e-commerce mungkin memiliki data pelanggan dengan individu yang tumpang-tindih, tetapi memiliki informasi keuangan dan pembelian yang berbeda.
- Federated Transfer Learning (FTL): Tumpang-tindih sebagian pada sampel dan fitur di antara set data. Misalnya, dua rumah sakit mungkin memiliki catatan pasien dengan beberapa individu yang tumpang-tindih dan beberapa parameter medis yang sama, tetapi juga memiliki fitur unik di setiap set data.
Komputasi gabungan lintas silo adalah tempat anggota yang berpartisipasi adalah organisasi atau perusahaan. Dalam praktiknya, jumlah anggota biasanya kecil (misalnya, dalam seratus anggota). Komputasi lintas silo biasanya digunakan dalam skenario saat organisasi yang berpartisipasi memiliki set data yang berbeda, tetapi mereka ingin melatih model bersama atau menganalisis hasil gabungan tanpa saling berbagi data mentah. Misalnya, anggota yang berpartisipasi dapat memiliki lingkungan di organisasi Google Cloud yang berbeda, seperti saat mereka mewakili entitas hukum yang berbeda, atau di organisasiGoogle Cloud yang sama, seperti saat mereka mewakili departemen yang berbeda dari entitas hukum yang sama.
Anggota yang berpartisipasi mungkin tidak dapat menganggap workload satu sama lain sebagai entitas tepercaya. Misalnya, anggota yang berpartisipasi mungkin tidak memiliki akses ke kode sumber beban kerja pelatihan yang mereka terima dari pihak ketiga, seperti koordinator. Karena tidak dapat mengakses kode sumber ini, anggota yang berpartisipasi tidak dapat memastikan bahwa beban kerja dapat sepenuhnya dipercaya.
Untuk membantu Anda mencegah workload yang tidak tepercaya mengakses data atau resource tanpa otorisasi, sebaiknya lakukan hal berikut:
- Men-deploy workload yang tidak tepercaya di lingkungan terisolasi.
- Berikan hak dan izin akses yang benar-benar diperlukan kepada workload yang tidak tepercaya untuk menyelesaikan putaran pelatihan yang ditetapkan ke workload.
Untuk membantu Anda mengisolasi workload yang berpotensi tidak tepercaya, arsitektur referensi ini menerapkan kontrol keamanan, seperti mengonfigurasi namespace Kubernetes yang terisolasi, dengan setiap namespace memiliki node pool GKE khusus. Komunikasi lintas namespace dan traffic masuk dan keluar cluster dilarang secara default, kecuali jika Anda secara eksplisit mengganti setelan ini.
Contoh kasus penggunaan untuk federated learning lintas silo adalah sebagai berikut:
- Deteksi penipuan: Federated learning dapat digunakan untuk melatih model deteksi penipuan pada data yang didistribusikan di beberapa organisasi. Misalnya, konsorsium bank dapat menggunakan federated learning untuk melatih model yang mendeteksi transaksi penipuan.
- Diagnosis medis: Federated learning dapat digunakan untuk melatih model diagnosis medis pada data yang didistribusikan di beberapa rumah sakit. Misalnya, sekelompok rumah sakit dapat menggunakan federated learning untuk melatih model yang mendiagnosis kanker.
Pembelajaran gabungan lintas perangkat adalah jenis komputasi gabungan dengan anggota yang berpartisipasi adalah perangkat pengguna akhir seperti ponsel, kendaraan, atau perangkat IoT. Jumlah anggota dapat mencapai skala jutaan atau bahkan puluhan juta.
Proses untuk federated learning lintas perangkat mirip dengan proses federated learning lintas silo. Namun, Anda juga harus menyesuaikan arsitektur referensi untuk mengakomodasi beberapa faktor tambahan yang harus Anda pertimbangkan saat menangani ribuan hingga jutaan perangkat. Anda harus men-deploy workload administratif untuk menangani skenario yang ditemukan dalam kasus penggunaan federated learning lintas perangkat. Misalnya, kebutuhan untuk mengkoordinasikan sebagian klien yang akan berlangsung dalam putaran pelatihan. Arsitektur lintas perangkat memberikan kemampuan ini dengan memungkinkan Anda men-deploy layanan FCP. Layanan ini memiliki beban kerja yang memiliki titik koneksi dengan TFF. TFF digunakan untuk menulis kode yang mengelola koordinasi ini.
Contoh kasus penggunaan untuk federated learning lintas perangkat adalah sebagai berikut:
- Rekomendasi yang dipersonalisasi: Anda dapat menggunakan federated learning lintas perangkat untuk melatih model rekomendasi yang dipersonalisasi pada data yang didistribusikan di beberapa perangkat. Misalnya, perusahaan dapat menggunakan federated learning untuk melatih model yang merekomendasikan produk kepada pengguna berdasarkan histori pembelian mereka.
- Pemrosesan bahasa alami: Federated learning dapat digunakan untuk melatih model pemrosesan bahasa alami pada data yang didistribusikan di beberapa perangkat. Misalnya, perusahaan dapat menggunakan federated learning untuk melatih model yang meningkatkan akurasi pengenalan ucapan.
- Memprediksi kebutuhan pemeliharaan kendaraan: Federated learning dapat digunakan untuk melatih model yang memprediksi kapan kendaraan kemungkinan memerlukan pemeliharaan. Model ini dapat dilatih dengan data yang dikumpulkan dari beberapa kendaraan. Pendekatan ini memungkinkan model belajar dari pengalaman semua kendaraan, tanpa mengorbankan privasi setiap kendaraan.
Tabel berikut meringkas fitur arsitektur lintas silo dan lintas perangkat, serta menunjukkan cara mengategorikan jenis skenario federated learning yang berlaku untuk kasus penggunaan Anda.
| Fitur | Komputasi gabungan lintas silo | Komputasi gabungan lintas-perangkat |
|---|---|---|
| Ukuran populasi | Biasanya kecil (misalnya, dalam seratus perangkat) | Dapat diskalakan ke ribuan, jutaan, atau ratusan juta perangkat |
| Anggota yang berpartisipasi | Organisasi atau perusahaan | Perangkat seluler, perangkat edge, kendaraan |
| Partisi data yang paling umum | HFL, VFL, FTL | HFL |
| Sensitivitas data | Data sensitif yang tidak ingin dibagikan peserta satu sama lain dalam format mentah | Data yang terlalu sensitif untuk dibagikan ke server pusat |
| Ketersediaan data | Peserta hampir selalu tersedia | Hanya sebagian peserta yang tersedia kapan saja |
| Contoh kasus penggunaan | Deteksi penipuan, diagnosis medis, perkiraan keuangan | Pelacakan kebugaran, pengenalan suara, klasifikasi gambar |
Pertimbangan desain
Bagian ini memberikan panduan untuk membantu Anda menggunakan arsitektur referensi ini untuk mengembangkan satu atau beberapa arsitektur yang memenuhi persyaratan spesifik Anda dalam hal keamanan, keandalan, efisiensi operasional, biaya, dan performa.
Pertimbangan desain arsitektur lintas silo
Untuk menerapkan arsitektur federated learning lintas silo di Google Cloud, Anda harus menerapkan prasyarat minimum berikut, yang dijelaskan lebih detail di bagian berikut:
- Buat konsorsium federated learning.
- Tentukan model kolaborasi yang akan diterapkan oleh konsorsium federated learning.
- Menentukan tanggung jawab organisasi peserta.
Selain prasyarat tersebut, ada tindakan lain yang harus dilakukan pemilik penggabungan yang berada di luar cakupan dokumen ini, seperti berikut:
- Mengelola konsorsium federated learning.
- Mendesain dan menerapkan model kolaborasi.
- Menyiapkan, mengelola, dan mengoperasikan data pelatihan model serta model yang ingin dilatih oleh pemilik federasi.
- Membuat, melakukan containerization, dan mengatur alur kerja federated learning.
- Men-deploy dan mengelola workload federated learning.
- Siapkan saluran komunikasi bagi organisasi yang ikut serta untuk mentransfer data dengan aman.
Membentuk konsorsium federated learning
Konsorsium federated learning adalah grup organisasi yang berpartisipasi dalam upaya federated learning lintas silo. Organisasi dalam konsorsium hanya membagikan parameter model ML, dan Anda dapat mengenkripsi parameter ini untuk meningkatkan privasi. Jika konsorsium federated learning mengizinkan praktik ini, organisasi juga dapat menggabungkan data yang tidak berisi informasi identitas pribadi (PII).
Menentukan model kolaborasi untuk konsorsium federated learning
Konsorsium federated learning dapat menerapkan berbagai model kolaborasi, seperti berikut:
- Model terpusat yang terdiri dari satu organisasi koordinasi, yang disebut pemilik federasi atau orkestrasi, dan kumpulan organisasi peserta atau pemilik data.
- Model terdesentralisasi yang terdiri atas organisasi yang berkoordinasi sebagai grup.
- Model heterogen yang terdiri dari konsorsium beragam organisasi yang berpartisipasi, yang semuanya membawa berbagai resource ke konsorsium.
Dokumen ini mengasumsikan bahwa model kolaborasi adalah model yang terpusat.
Menentukan tanggung jawab organisasi peserta
Setelah memilih model kolaborasi untuk konsorsium federated learning, pemilik federasi harus menentukan tanggung jawab tiap organisasi peserta.
Pemilik federasi juga harus melakukan hal berikut saat memulai pembuatan konsorsium federated learning:
- Mengoordinasi upaya federated learning.
- Desain dan terapan model ML global dan model ML untuk dibagikan kepada organisasi peserta.
- Tentukan putaran federated learning—pendekatan untuk iterasi proses pelatihan ML.
- Pilih organisasi peserta yang berkontribusi pada sesi federated learning tertentu. Pilihan ini disebut kelompok.
- Desain dan penerapan prosedur verifikasi keanggotaan konsorsium untuk organisasi peserta.
- Perbarui model ML global dan model ML untuk dibagikan ke organisasi peserta.
- Menyediakan alat kepada organisasi peserta untuk memvalidasi bahwa konsorsium federated learning memenuhi persyaratan privasi, keamanan, dan peraturan mereka.
- Menyediakan saluran komunikasi yang aman dan terenkripsi kepada peserta.
- Menyediakan semua data gabungan yang diperlukan dan tidak bersifat rahasia kepada peserta untuk menyelesaikan setiap sesi federated learning.
Organisasi peserta memiliki tanggung jawab berikut:
- Sediakan dan jaga lingkungan yang aman dan terisolasi (silo). Silo adalah tempat organisasi peserta menyimpan data masing-masing, dan tempat pelatihan model ML diterapkan. Organisasi peserta tidak membagikan data mereka sendiri kepada organisasi lain.
- Latih model yang disediakan oleh pemilik federasi menggunakan infrastruktur komputasi dan data lokal masing-masing.
- Bagikan hasil pelatihan model kepada pemilik federasi dalam bentuk data gabungan, setelah menghapus PII apa pun.
Pemilik federasi dan organisasi peserta dapat menggunakan Cloud Storage untuk membagikan model yang diperbarui dan hasil pelatihan.
Pemilik federasi dan organisasi peserta meningkatkan kualitas pelatihan model ML sampai model memenuhi persyaratan mereka.
Menerapkan federated learning di Google Cloud
Setelah membuat konsorsium federated learning dan menentukan cara konsorsium federated learning akan berkolaborasi, sebaiknya organisasi peserta melakukan hal berikut:
- Sediakan dan konfigurasikan infrastruktur yang diperlukan untuk konsorsium federated learning.
- Terapkan model kolaborasi.
- Mulai upaya federated learning.
Menyediakan dan mengonfigurasi infrastruktur untuk konsorsium federated learning
Saat menyediakan dan mengonfigurasi infrastruktur untuk konsorsium federated learning, pemilik federasi bertanggung jawab dalam membuat dan mendistribusikan workload yang melatih model ML federasi ke organisasi peserta. Karena pihak ketiga (pemilik federasi) membuat dan menyediakan workload, organisasi peserta harus melakukan tindakan pencegahan saat men-deploy workload tersebut di lingkungan runtime mereka.
Organisasi peserta harus mengonfigurasi lingkungan sesuai dengan praktik terbaik keamanan individual mereka, dan menerapkan kontrol yang membatasi cakupan dan izin yang diberikan ke setiap beban kerja. Selain mengikuti praktik terbaik keamanan individual, sebaiknya pemilik federasi dan organisasi peserta mempertimbangkan vektor ancaman khusus federated learning.
Mengimplementasikan model kolaborasi
Setelah infrastruktur konsorsium federated learning disiapkan, pemilik federasi mendesain dan menerapkan mekanisme yang memungkinkan organisasi peserta saling berinteraksi. Pendekatan ini mengikuti model kolaborasi yang dipilih pemilik federasi untuk konsorsium federated learning.
Memulai upaya federated learning
Setelah menerapkan model kolaborasi, pemilik federasi menerapkan model ML global untuk dilatih, dan model ML untuk dibagikan dengan organisasi peserta. Setelah model ML tersebut siap, pemilik federasi memulai tahap pertama upaya federated learning.
Selama setiap tahap upaya federated learning, pemilik federasi melakukan hal berikut:
- Mendistribusikan model ML untuk dibagikan kepada organisasi peserta.
- Menunggu organisasi peserta mengirimkan hasil pelatihan model ML yang dibagikan oleh pemilik federasi.
- Mengumpulkan dan memproses hasil pelatihan yang dihasilkan organisasi peserta.
- Mengupdate model ML global saat mereka menerima hasil pelatihan yang sesuai dari organisasi yang berpartisipasi.
- Memperbarui model ML untuk dibagikan ke anggota konsorsium lainnya jika berlaku.
- Menyiapkan data pelatihan untuk tahap federated learning selanjutnya.
- Memulai tahap federated learning selanjutnya.
Keamanan, privasi, dan kepatuhan:
Bagian ini menjelaskan faktor yang harus Anda pertimbangkan saat menggunakan arsitektur referensi ini untuk mendesain dan mem-build platform federated learning di Google Cloud. Panduan ini berlaku untuk kedua arsitektur yang dijelaskan dalam dokumen ini.
Workload federated learning yang Anda deploy di lingkungan dapat mengekspos Anda, data Anda, model federated learning Anda, dan infrastruktur Anda kepada ancaman yang dapat memengaruhi bisnis Anda.
Untuk membantu Anda meningkatkan keamanan lingkungan federated learning, arsitektur referensi ini mengonfigurasi kontrol keamanan GKE yang berfokus pada infrastruktur lingkungan Anda. Kontrol ini mungkin tidak cukup untuk melindungi Anda dari ancaman yang spesifik untuk workload dan kasus penggunaan federated learning Anda. Mengingat kekhususan setiap beban kerja dan kasus penggunaan federated learning, kontrol keamanan yang bertujuan untuk mengamankan penerapan federated learning Anda berada di luar cakupan dokumen ini. Untuk informasi dan contoh selengkapnya tentang ancaman ini, lihat Pertimbangan keamanan Federated Learning.
Kontrol keamanan GKE
Bagian ini membahas kontrol yang Anda terapkan dengan arsitektur ini untuk membantu Anda mengamankan cluster GKE.
Keamanan cluster GKE yang ditingkatkan
Arsitektur referensi ini membantu Anda membuat cluster GKE yang menerapkan setelan keamanan berikut:
- Batasi eksposur node cluster dan bidang kontrol Anda ke internet dengan membuat cluster GKE pribadi menggunakan jaringan resmi.
- Gunakan
shielded node
yang menggunakan image node yang telah melalui proses hardening dengan
runtime
containerd. - Peningkatan isolasi workload tenant menggunakan GKE Sandbox.
- Mengenkripsi data dalam penyimpanan secara default.
- Mengenkripsi data dalam pengiriman secara default.
- Enkripsi secret cluster pada lapisan aplikasi.
- Secara opsional, mengenkripsi data yang sedang digunakan dengan mengaktifkan Confidential Google Kubernetes Engine Nodes.
Untuk mengetahui informasi selengkapnya tentang setelan keamanan GKE, lihat Melakukan hardening untuk keamanan cluster Anda dan Tentang dasbor postur keamanan.
Aturan firewall VPC
Aturan firewall Virtual Private Cloud (VPC) mengatur traffic mana yang diizinkan ke atau dari VM Compute Engine. Aturan tersebut memungkinkan Anda memfilter traffic pada tingkat perincian VM, bergantung pada atribut Lapisan 4.
Anda dapat membuat cluster GKE dengan aturan firewall cluster GKE default. Aturan firewall ini memungkinkan komunikasi antara node cluster dan bidang kontrol GKE, serta antara node dan Pod dalam cluster.
Anda dapat menerapkan aturan firewall tambahan ke node di node pool tenant. Aturan firewall ini membatasi traffic keluar dari node tenant. Pendekatan ini dapat meningkatkan isolasi node tenant. Secara default, semua traffic keluar dari node tenant ditolak. Setiap traffic keluar yang diperlukan harus dikonfigurasi secara eksplisit. Misalnya, Anda membuat aturan firewall untuk mengizinkan traffic keluar dari node tenant ke bidang kontrol GKE, dan ke Google API menggunakan Akses Google Pribadi. Aturan firewall ditargetkan ke node tenant menggunakan akun layanan untuk node pool tenant.
Namespace
Namespace memungkinkan Anda menyediakan cakupan untuk resource terkait dalam suatu cluster, misalnya seperti Pod, Service, dan pengontrol replikasi. Dengan menggunakan namespace, Anda dapat mendelegasikan tanggung jawab administrasi atas resource terkait sebagai suatu unit. Oleh karena itu, namespace merupakan bagian tak terpisahkan dari sebagian besar pola keamanan.
Namespace adalah fitur penting untuk isolasi bidang kontrol. Namun, namespace tidak menyediakan isolasi node, isolasi bidang data, atau isolasi jaringan.
Pendekatan yang umum dilakukan yaitu membuat namespace untuk aplikasi individu. Misalnya, Anda dapat membuat namespace myapp-frontend untuk komponen UI
suatu aplikasi.
Arsitektur referensi ini membantu Anda membuat namespace khusus untuk menghosting aplikasi pihak ketiga. Namespace dan resource-nya dianggap sebagai tenant dalam cluster Anda. Anda dapat menerapkan kebijakan dan kontrol ke namespace untuk membatasi cakupan resource di dalam namespace.
Kebijakan jaringan
Kebijakan jaringan menerapkan aliran traffic jaringan Lapisan 4 menggunakan aturan firewall level Pod. Kebijakan jaringan tercakup dalam suatu namespace.
Dalam arsitektur referensi yang dijelaskan dalam dokumen ini, Anda menerapkan kebijakan jaringan ke namespace tenant yang menghosting aplikasi pihak ketiga. Secara default, kebijakan jaringan menolak semua traffic ke dan dari pod di namespace. Setiap traffic yang diperlukan harus ditambahkan secara eksplisit ke daftar yang diizinkan. Misalnya, kebijakan jaringan dalam arsitektur referensi ini secara eksplisit mengizinkan traffic ke layanan cluster yang diperlukan, seperti DNS internal cluster dan bidang kontrol Cloud Service Mesh.
Config Sync
Config Sync menjaga cluster GKE Anda tetap sinkron dengan konfigurasi yang disimpan di repositori Git. Repositori Git bertindak sebagai satu-satunya sumber tepercaya untuk konfigurasi dan kebijakan cluster Anda. Config Sync bersifat deklaratif. Fitur ini terus memeriksa status cluster dan menerapkan status yang dideklarasikan dalam file konfigurasi untuk menerapkan kebijakan, yang membantu mencegah penyimpangan konfigurasi.
Config Sync diinstal ke dalam cluster GKE Anda. Anda mengonfigurasi Config Sync untuk menyinkronkan konfigurasi dan kebijakan cluster dari repositori Cloud Source. Resource yang disinkronkan mencakup hal berikut:
- Konfigurasi Cloud Service Mesh level cluster
- Kebijakan keamanan level cluster
- Konfigurasi dan kebijakan level namespace tenant, termasuk kebijakan jaringan, akun layanan, aturan RBAC, dan konfigurasi Cloud Service Mesh
Pengontrol Kebijakan
Pengontrol Kebijakan edisi Enterprise Google Kubernetes Engine (GKE) adalah pengontrol penerimaan dinamis untuk Kubernetes yang menerapkan kebijakan berbasis CustomResourceDefinition (CRD) yang dijalankan oleh Open Policy Agent (OPA).
Pengontrol penerimaan merupakan plugin Kubernetes yang mencegat permintaan ke server API Kubernetes sebelum suatu objek disimpan, tetapi setelah permintaan diautentikasi dan diotorisasi. Anda dapat menggunakan pengontrol penerimaan untuk membatasi cara penggunaan suatu cluster.
Pengontrol Kebijakan diinstal ke dalam cluster GKE Anda. Arsitektur referensi ini mencakup contoh kebijakan untuk membantu mengamankan cluster Anda. Kebijakan akan otomatis diterapkan ke cluster Anda menggunakan Config Sync. Anda dapat menerapkan kebijakan berikut:
- Kebijakan yang dipilih untuk membantu menerapkan keamanan Pod. Misalnya, Anda dapat menerapkan kebijakan yang mencegah pod menjalankan container dengan hak istimewa dan yang memerlukan sistem file root hanya baca.
- Kebijakan dari template library Pengontrol Kebijakan. Misalnya, Anda dapat menerapkan kebijakan yang melarang layanan dengan jenis NodePort.
Mesh Layanan Cloud
Cloud Service Mesh adalah mesh layanan yang membantu Anda menyederhanakan pengelolaan komunikasi yang aman di seluruh layanan. Arsitektur referensi ini mengonfigurasi Cloud Service Mesh agar melakukan hal berikut:
- Menyuntikkan proxy sidecar secara otomatis.
- Menerapkan komunikasi mTLS antarlayanan di mesh.
- Membatasi traffic mesh keluar hanya ke host yang diketahui.
- Membatasi traffic masuk hanya dari klien tertentu.
- Memungkinkan Anda mengonfigurasi kebijakan keamanan jaringan berdasarkan identitas layanan, bukan berdasarkan alamat IP rekan yang berada di jaringan.
- Membatasi komunikasi resmi antarlayanan di mesh. Misalnya, aplikasi namespace tenant hanya diizinkan untuk berkomunikasi dengan aplikasi di namespace yang sama, atau dengan sekumpulan host eksternal yang diketahui.
- Merutekan semua traffic masuk dan keluar melalui gateway mesh tempat Anda dapat menerapkan kontrol traffic lebih lanjut.
- Mendukung komunikasi yang aman antar-cluster.
Taint node dan afinitas
Taint node dan afinitas node merupakan mekanisme Kubernetes yang memungkinkan Anda memengaruhi cara pod dijadwalkan ke node cluster.
Node yang terkena taint akan menolak pod. Kubernetes tidak akan menjadwalkan Pod ke node yang terkena taint kecuali jika Pod tersebut memiliki toleransi terhadap taint. Anda dapat menggunakan taint node untuk mencadangkan node agar hanya digunakan oleh workload atau tenant tertentu. Taint dan toleransi sering digunakan dalam cluster multi-tenant. Untuk mengetahui informasi selengkapnya, lihat dokumentasi node khusus dengan taint dan toleransi.
Afinitas node memungkinkan Anda membatasi pod ke node dengan label tertentu. Jika suatu pod memiliki persyaratan afinitas node, Kubernetes tidak akan menjadwalkan Pod tersebut ke node kecuali jika node memiliki label yang cocok dengan persyaratan afinitas. Anda dapat menggunakan afinitas node untuk memastikan bahwa pod dijadwalkan ke node yang sesuai.
Anda dapat menggunakan taint node dan afinitas node affinity secara bersamaan untuk memastikan bahwa pod workload tenant dijadwalkan secara eksklusif ke node yang dicadangkan untuk tenant.
Arsitektur referensi ini membantu Anda mengontrol penjadwalan aplikasi tenant dengan cara berikut:
- Membuat node pool GKE khusus untuk tenant. Setiap node yang ada dalam pool memiliki taint yang terkait dengan nama tenant.
- Otomatis menerapkan toleransi dan afinitas node yang sesuai ke Pod mana pun yang menargetkan namespace tenant. Anda dapat menerapkan toleransi dan afinitas tersebut menggunakan mutasi PolicyController.
Hak istimewa terendah
Praktik terbaik keamanan bisa dilakukan dengan menerapkan prinsip hak istimewa terendah untuk project dan resource Google Cloud Anda, seperti cluster GKE. Dengan menggunakan pendekatan ini, aplikasi yang berjalan di dalam cluster Anda, serta developer dan operator yang menggunakan cluster tersebut, hanya memiliki serangkaian izin minimum yang diperlukan.
Arsitektur referensi ini membantu Anda menggunakan akun layanan dengan hak istimewa terendah melalui cara berikut:
- Setiap node pool GKE menerima akun layanannya sendiri. Misalnya, node yang berada dalam node pool tenant menggunakan akun layanan khusus untuk node tersebut. Akun layanan node dikonfigurasi dengan izin minimum yang diperlukan.
- Cluster menggunakan Workload Identity Federation untuk GKE untuk mengaitkan akun layanan Kubernetes dengan akun layanan Google. Dengan cara ini, aplikasi tenant dapat diberi akses terbatas ke Google API mana pun yang diperlukan tanpa harus mendownload dan menyimpan kunci akun layanan. Misalnya, Anda dapat memberikan izin ke akun layanan untuk membaca data dari bucket Cloud Storage.
Arsitektur referensi ini membantu Anda membatasi akses ke resource cluster dengan cara berikut:
- Buatlah contoh peran Kubernetes RBAC dengan izin terbatas untuk mengelola aplikasi. Anda dapat memberikan peran ini kepada pengguna dan grup yang mengoperasikan aplikasi di namespace tenant. Dengan menerapkan peran pengguna dan grup yang terbatas ini, pengguna tersebut hanya memiliki izin untuk mengubah resource aplikasi di namespace tenant. Mereka tidak memiliki izin untuk mengubah resource level cluster atau setelan keamanan yang sensitif seperti kebijakan Cloud Service Mesh.
Otorisasi Biner
Otorisasi Biner memungkinkan Anda menerapkan kebijakan yang Anda tentukan tentang image container yang di-deploy di lingkungan GKE. Otorisasi Biner hanya mengizinkan deployment image container yang sesuai dengan kebijakan yang Anda tetapkan. Tindakan ini tidak mengizinkan deployment image container lainnya.
Dalam arsitektur referensi ini, Otorisasi Biner diaktifkan dengan konfigurasi defaultnya. Untuk memeriksa konfigurasi default Otorisasi Biner, lihat Mengekspor file YAML kebijakan.
Untuk informasi selengkapnya tentang cara mengonfigurasi kebijakan, lihat panduan khusus berikut:
Verifikasi pengesahan lintas organisasi
Anda dapat menggunakan Otorisasi Biner untuk memverifikasi pengesahan yang dihasilkan oleh penanda tangan pihak ketiga. Misalnya, dalam kasus penggunaan federated learning lintas-silo, Anda dapat memverifikasi pengesahan yang dibuat oleh organisasi peserta lain.
Untuk memverifikasi pengesahan yang dibuat oleh pihak ketiga, Anda harus melakukan hal berikut:
- Menerima kunci publik yang digunakan pihak ketiga untuk membuat pengesahan yang perlu Anda verifikasi.
- Buat attestor untuk memverifikasi pengesahan.
- Tambahkan kunci publik yang Anda terima dari pihak ketiga ke attestor yang Anda buat.
Untuk informasi selengkapnya tentang cara membuat pengautentikasi, lihat panduan khusus berikut:
- Google Cloud CLI
- Konsol Google Cloud
- REST API
- resource Terraform
google_binary_authorization_attestor
Dasbor GKE Compliance
Dasbor Kepatuhan GKE memberikan insight yang bisa ditindaklanjuti untuk memperkuat postur keamanan Anda, dan membantu Anda mengotomatiskan pelaporan kepatuhan untuk tolok ukur dan standar industri. Anda dapat mendaftarkan cluster GKE untuk mengaktifkan pelaporan kepatuhan otomatis.
Untuk mengetahui informasi selengkapnya, lihat Tentang dasbor Kepatuhan GKE.
Pertimbangan keamanan federated learning
Meskipun memiliki model berbagi data yang ketat, federated learning tidak secara inheren aman dari menjadi target serangan, dan Anda harus mempertimbangkan risiko ini saat men-deploy salah satu arsitektur yang dijelaskan dalam dokumen ini. Bisa saja terdapat risiko kebocoran informasi yang tidak diinginkan tentang model ML atau data pelatihan model. Misalnya, penyerang mungkin sengaja membahayakan model ML global atau tahap dari upaya federated learning, atau mungkin menjalankan serangan waktu (sejenis serangan side-channel) untuk mengumpulkan informasi tentang ukuran set data pelatihan.
Ancaman yang paling umum terhadap penerapan federated learning adalah sebagai berikut:
- Penghafalan data pelatihan yang disengaja atau tidak disengaja. Implementasi federated learning Anda atau penyerang mungkin secara sengaja atau tidak sengaja menyimpan data dengan cara yang mungkin sulit digunakan. Penyerang mungkin dapat mengumpulkan informasi tentang model ML global atau tahap sebelumnya dari upaya federated learning dengan merekayasa data yang tersimpan.
- Mengekstrak informasi dari update ke model ML global. Selama upaya federated learning, penyerang dapat merekayasa balik update ke model ML global yang dikumpulkan pemilik federasi dari organisasi dan perangkat peserta.
- Pemilik federasi mungkin membahayakan tahapan-tahapannya. Pemilik federasi yang tersusupi dapat mengontrol silo atau perangkat yang tidak sah dan memulai tahap upaya federated learning. Pada akhir proses, pemilik federasi yang disusupi mungkin dapat mengumpulkan informasi tentang update yang dikumpulkannya dari organisasi dan perangkat peserta yang sah dengan membandingkan update tersebut dengan update yang dihasilkan oleh silo penipu.
- Organisasi dan perangkat peserta dapat membahayakan model ML global. Selama upaya federated learning, penyerang mungkin mencoba memengaruhi performa, kualitas, atau integritas model ML global secara berbahaya dengan menghasilkan update yang tidak palsu atau tidak penting.
Untuk membantu mengurangi dampak ancaman yang dijelaskan di bagian ini, sebaiknya lakukan praktik terbaik berikut:
- Sesuaikan model untuk mengurangi penghafalan data pelatihan seminimal mungkin.
- Menerapkan mekanisme yang menjaga privasi.
- Audit model ML global, model ML yang ingin Anda bagikan, data pelatihan, dan infrastruktur yang Anda terapkan untuk mencapai sasaran federated learning secara rutin.
- Terapkan algoritma agregasi yang aman untuk memproses hasil pelatihan dari organisasi peserta.
- Membuat dan mendistribusikan kunci enkripsi data dengan aman menggunakan infrastruktur kunci publik.
- Deploy infrastruktur ke platform komputasi rahasia.
Pemilik Federasi juga harus melakukan langkah-langkah tambahan berikut:
- Verifikasi identitas setiap organisasi peserta dan integritas setiap silo jika menggunakan arsitektur lintas silo, serta identitas dan integritas setiap perangkat jika menggunakan arsitektur lintas perangkat.
- Batasi cakupan pembaruan pada model ML global yang dapat dihasilkan oleh organisasi dan perangkat peserta.
Keandalan
Bagian ini menjelaskan faktor desain yang harus Anda pertimbangkan saat menggunakan salah satu arsitektur referensi dalam dokumen ini untuk mendesain dan mem-build platform federated learning di Google Cloud.
Saat mendesain arsitektur federated learning di Google Cloud, sebaiknya ikuti panduan di bagian ini untuk meningkatkan ketersediaan dan skalabilitas beban kerja, serta membantu membuat arsitektur Anda tahan terhadap pemadaman dan bencana.
GKE: GKE mendukung beberapa jenis cluster berbeda yang dapat Anda sesuaikan dengan persyaratan ketersediaan workload dan anggaran Anda. Misalnya, Anda dapat membuat cluster regional yang mendistribusikan bidang kontrol dan node di beberapa zona dalam satu region, atau cluster zona yang memiliki bidang kontrol dan node di satu zona. Arsitektur referensi lintas silo dan lintas perangkat mengandalkan cluster GKE regional. Untuk informasi selengkapnya tentang aspek yang perlu dipertimbangkan saat membuat cluster GKE, lihat pilihan konfigurasi cluster.
Bergantung pada jenis cluster dan cara bidang kontrol dan node cluster didistribusikan di seluruh region dan zona, GKE menawarkan berbagai kemampuan disaster recovery untuk melindungi workload Anda dari pemadaman layanan zona dan regional. Untuk mengetahui informasi selengkapnya tentang kemampuan pemulihan dari bencana GKE, lihat Merancang pemulihan dari bencana untuk pemadaman layanan infrastruktur cloud: Google Kubernetes Engine.
Google Cloud Load Balancing: GKE mendukung beberapa cara load balancing traffic ke beban kerja Anda. Implementasi GKE dari API Kubernetes Gateway dan Kubernetes Service memungkinkan Anda menyediakan dan mengonfigurasi Cloud Load Balancing secara otomatis untuk mengekspos workload yang berjalan di cluster GKE dengan aman dan andal.
Dalam arsitektur referensi ini, semua traffic masuk dan keluar melewati gateway Cloud Service Mesh. Dengan gateway ini, Anda dapat mengontrol dengan ketat aliran traffic di dalam dan di luar cluster GKE.
Tantangan keandalan untuk federated learning lintas perangkat
Federated learning lintas perangkat memiliki sejumlah tantangan keandalan yang tidak ditemukan dalam skenario lintas silo. Contoh ini meliputi:
- Konektivitas perangkat yang tidak andal atau terputus-putus
- Penyimpanan perangkat terbatas
- Komputasi dan memori terbatas
Konektivitas yang tidak andal dapat menyebabkan masalah seperti berikut:
- Update yang tidak berlaku dan perbedaan model: Saat perangkat mengalami konektivitas yang terputus-putus, update model lokalnya mungkin menjadi tidak berlaku, yang mewakili informasi yang sudah tidak berlaku dibandingkan dengan status saat ini dari model global. Menggabungkan pembaruan yang sudah tidak berlaku dapat menyebabkan perbedaan model, yaitu saat model global menyimpang dari solusi optimal karena inkonsistensi dalam proses pelatihan.
- Kontribusi yang tidak seimbang dan model yang bias: Komunikasi yang terputus-putus dapat menyebabkan distribusi kontribusi yang tidak merata dari perangkat yang berpartisipasi. Perangkat dengan konektivitas yang buruk mungkin berkontribusi lebih sedikit update, sehingga menyebabkan representasi distribusi data yang mendasarinya tidak seimbang. Ketidakseimbangan ini dapat membiaskan model global terhadap data dari perangkat dengan koneksi yang lebih andal.
- Peningkatan overhead komunikasi dan konsumsi energi: Komunikasi terputus-putus dapat menyebabkan peningkatan overhead komunikasi, karena perangkat mungkin perlu mengirim ulang update yang hilang atau rusak. Masalah ini juga dapat meningkatkan konsumsi daya di perangkat, terutama untuk perangkat dengan masa pakai baterai terbatas, karena perangkat tersebut mungkin perlu mempertahankan koneksi aktif selama jangka waktu yang lebih lama untuk memastikan transmisi update berhasil.
Untuk membantu mengurangi beberapa efek yang disebabkan oleh komunikasi yang terputus-putus, arsitektur referensi dalam dokumen ini dapat digunakan dengan FCP.
Arsitektur sistem yang menjalankan protokol FCP dapat dirancang untuk memenuhi persyaratan berikut:
- Menangani putaran yang berjalan lama.
- Mengaktifkan eksekusi spekulatif (putaran dapat dimulai sebelum jumlah klien yang diperlukan dikumpulkan untuk mengantisipasi lebih banyak pemeriksaan dalam waktu dekat).
- Mengaktifkan perangkat untuk memilih tugas yang ingin mereka ikuti. Pendekatan ini dapat mengaktifkan fitur seperti pengambilan sampel tanpa penggantian, yang merupakan strategi pengambilan sampel dengan setiap unit sampel populasi hanya memiliki satu peluang untuk dipilih. Pendekatan ini membantu memitigasi kontribusi yang tidak seimbang dan model yang bias
- Dapat diperluas untuk teknik anonimisasi seperti privasi diferensial (DP) dan agregasi tepercaya (TAG).
Untuk membantu memitigasi kemampuan komputasi dan penyimpanan perangkat yang terbatas, teknik berikut dapat membantu:
- Memahami kapasitas maksimum yang tersedia untuk menjalankan komputasi pembelajaran gabungan
- Memahami jumlah data yang dapat disimpan pada waktu tertentu
- Mendesain kode federated learning sisi klien untuk beroperasi dalam komputasi dan RAM yang tersedia di klien
- Memahami implikasi kehabisan penyimpanan dan menerapkan proses untuk mengelolanya
Pengoptimalan biaya
Bagian ini berisi panduan untuk mengoptimalkan biaya pembuatan dan pengoperasian platform federated learning di Google Cloud yang Anda buat menggunakan arsitektur referensi ini. Panduan ini berlaku untuk kedua arsitektur yang dijelaskan dalam dokumen ini.
Menjalankan workload di GKE dapat membantu Anda membuat lingkungan lebih hemat biaya dengan menyediakan dan mengonfigurasi cluster sesuai dengan persyaratan resource workload Anda. Hal ini juga memungkinkan fitur yang mengonfigurasi ulang cluster dan node cluster secara dinamis, seperti menskalakan node cluster dan Pod secara otomatis, serta dengan menyesuaikan ukuran cluster.
Untuk informasi selengkapnya tentang cara mengoptimalkan biaya lingkungan GKE, lihat Praktik terbaik untuk menjalankan aplikasi Kubernetes yang hemat biaya di GKE.
Efisiensi operasional
Bagian ini menjelaskan faktor-faktor yang harus Anda pertimbangkan untuk mengoptimalkan efisiensi saat menggunakan arsitektur referensi ini untuk membuat dan menjalankan platform federated learning di Google Cloud. Panduan ini berlaku untuk kedua arsitektur yang dijelaskan dalam dokumen ini.
Untuk meningkatkan otomatisasi dan pemantauan arsitektur federated learning, sebaiknya Anda mengadopsi prinsip MLOps, yang merupakan prinsip DevOps dalam konteks sistem machine learning. Dengan mempraktikkan MLOps, berarti Anda mengadvokasi otomatisasi dan pemantauan di semua langkah konstruksi sistem ML, termasuk integrasi, pengujian, rilis, deployment, dan pengelolaan infrastruktur. Untuk mengetahui informasi selengkapnya tentang MLOps, lihat MLOps: Pipeline otomatisasi dan continuous delivery di machine learning.
Pengoptimalan performa
Bagian ini menjelaskan faktor-faktor yang harus Anda pertimbangkan untuk mengoptimalkan performa workload saat menggunakan arsitektur referensi ini untuk membuat dan menjalankan platform federated learning di Google Cloud. Panduan ini berlaku untuk kedua arsitektur yang dijelaskan dalam dokumen ini.
GKE mendukung beberapa fitur untuk menyesuaikan dan menskalakan lingkungan GKE secara otomatis dan manual untuk memenuhi permintaan workload Anda, serta membantu Anda menghindari penyediaan resource secara berlebihan. Misalnya, Anda dapat menggunakan Pemberi Rekomendasi untuk menghasilkan insight dan rekomendasi guna mengoptimalkan penggunaan resource GKE.
Saat memikirkan cara menskalakan lingkungan GKE, sebaiknya Anda mendesain rencana jangka pendek, menengah, dan panjang untuk cara Anda menskalakan lingkungan dan workload. Misalnya, bagaimana Anda ingin mengembangkan jejak GKE dalam beberapa minggu, bulan, dan tahun? Dengan memiliki rencana yang siap, Anda dapat memanfaatkan fitur skalabilitas yang disediakan GKE secara maksimal, mengoptimalkan lingkungan GKE, dan mengurangi biaya. Untuk informasi selengkapnya tentang perencanaan skalabilitas cluster dan workload, lihat Tentang Skalabilitas GKE.
Untuk meningkatkan performa beban kerja ML, Anda dapat menggunakan Cloud Tensor Processing Unit (Cloud TPU), akselerator AI yang dirancang Google dan dioptimalkan untuk pelatihan dan inferensi model AI berskala besar.
Deployment
Untuk men-deploy arsitektur referensi lintas silo dan lintas perangkat yang dijelaskan dalam dokumen ini, lihat repositori GitHub Federated Learning di Google Cloud.
Langkah berikutnya
- Pelajari cara menerapkan algoritma federated learning di platform TensorFlow Federated.
- Pelajari Kemajuan dan Masalah Terbuka dalam Federated Learning.
- Baca tentangfederated learning di Blog Google AI.
- Tonton cara Google menjaga privasi saat menggunakan federated learning dengan informasi gabungan yang telah dilakukan de-identifikasi untuk meningkatkan kualitas model ML.
- Baca Menuju Federated Learning dalam skala besar.
- Pelajari cara menerapkan pipeline MLOps untuk mengelola siklus proses model machine learning.
- Untuk ringkasan prinsip dan rekomendasi arsitektur yang khusus untuk beban kerja AI dan ML di Google Cloud, lihat perspektif AI dan ML di Framework Arsitektur.
- Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.
Kontributor
Penulis:
- Grace Mollison | Solutions Lead
- Marco Ferrari | Cloud Solutions Architect
Kontributor lainnya:
- Chloé Kiddon | Staff Software Engineer dan Manager
- Laurent Grangeau | Solutions Architect
- Lilian Felix | Cloud Engineer