Per garantire che i casi d'uso dei consumatori di dati vengano soddisfatti, è essenziale che i prodotti di dati in un data mesh siano progettati e creati con cura. La progettazione di un prodotto di dati inizia con la definizione di come i consumatori di dati utilizzerebbero quel prodotto e di come questo viene poi esposto ai consumatori. I prodotti di dati in un mesh di dati sono basati su un datastore (ad esempio, un data warehouse o un data lake di dominio). Quando crei prodotti di dati in un data mesh, ci sono alcuni fattori chiave che ti consigliamo di considerare durante questo processo. Queste considerazioni sono descritte in questo documento.
Questo documento fa parte di una serie che descrive come implementare un data mesh su Google Cloud. Si presuppone che tu abbia letto e conosca i concetti descritti in Architettura e funzioni in un data mesh e Crea un data mesh moderno e distribuito con Google Cloud.
La serie è composta dalle seguenti parti:
- Architettura e funzioni in un mesh di dati
- Progettare una piattaforma di dati self-service per una mesh di dati
- Creare prodotti dati in un mesh di dati (questo documento)
- Scoprire e utilizzare i prodotti di dati in una data mesh
Quando crei prodotti di dati da un data warehouse del dominio, ti consigliamo di progettare con attenzione le interfacce analitiche (di consumo) per questi prodotti. Queste interfacce di consumo sono un insieme di garanzie sulla qualità dei dati e sui parametri operativi, oltre a un modello di assistenza e alla documentazione del prodotto. Il costo della modifica delle interfacce di consumo è in genere elevato a causa della necessità che sia il produttore di dati sia potenzialmente più consumatori di dati modifichino i propri processi e applicazioni di consumo. Poiché i consumatori di dati si trovano molto probabilmente in unità organizzative separate da quelle dei produttori di dati, coordinare le modifiche può essere difficile.
Le sezioni seguenti forniscono informazioni di base su ciò che devi considerare quando crei un data warehouse del dominio, definisci le interfacce di consumo ed esponi queste interfacce ai consumatori di dati.
Crea un data warehouse del dominio
Non esiste una differenza fondamentale tra la creazione di un data warehouse autonomo e la creazione di un data warehouse di dominio da cui il team di produzione dei dati crea prodotti di dati. L'unica vera differenza tra i due è che quest'ultimo espone un sottoinsieme dei suoi dati tramite le interfacce di consumo.
In molti data warehouse, i dati non elaborati importati dalle origini dati operative vengono sottoposti al processo di arricchimento e verifica della qualità dei dati (curation). Nei data lake gestiti da Dataplex Universal Catalog, i dati curati vengono in genere archiviati in zone curate designate. Al termine della cura, un sottoinsieme dei dati deve essere pronto per l'utilizzo esterno al dominio tramite diversi tipi di interfacce. Per definire queste interfacce di consumo, un'organizzazione deve fornire un insieme di strumenti ai team di dominio che non hanno familiarità con l'adozione di un approccio di data mesh. Questi strumenti consentono ai produttori di dati di creare nuovi prodotti di dati in modalità self-service. Per le pratiche consigliate, consulta Progettare una piattaforma di dati self-service.
Inoltre, i prodotti di dati devono soddisfare i requisiti di governance dei dati definiti a livello centrale. Questi requisiti influiscono sulla qualità, sulla disponibilità e sulla gestione del ciclo di vita dei dati. Poiché questi requisiti aumentano la fiducia dei consumatori di dati nei prodotti di dati e incoraggiano l'utilizzo dei prodotti di dati, i vantaggi dell'implementazione di questi requisiti valgono lo sforzo di supportarli.
Definisci le interfacce di consumo
Consigliamo ai produttori di dati di utilizzare più tipi di interfacce, anziché definirne solo uno o due. Ogni tipo di interfaccia nell'analisi dei dati presenta vantaggi e svantaggi e non esiste un unico tipo di interfaccia che eccella in tutto. Quando i produttori di dati valutano l'idoneità di ciascun tipo di interfaccia, devono considerare quanto segue:
- Possibilità di eseguire il trattamento dati necessario.
- Scalabilità per supportare i casi d'uso attuali e futuri dei consumatori di dati.
- Rendimento richiesto dai consumatori di dati.
- Costo di sviluppo e manutenzione.
- Costo di esecuzione dell'interfaccia.
- Supporto in base alle lingue e agli strumenti utilizzati dalla tua organizzazione.
- Supporto della separazione tra archiviazione e calcolo.
Ad esempio, se il requisito aziendale è quello di poter eseguire query analitiche su un set di dati di dimensioni pari a un petabyte, l'unica interfaccia pratica è una vista BigQuery. Tuttavia, se i requisiti prevedono la fornitura di dati di streaming quasi in tempo reale, un'interfaccia basata su Pub/Sub è più appropriata.
Molte di queste interfacce non richiedono di copiare o replicare i dati esistenti. La maggior parte di questi servizi consente anche di separare l'archiviazione e il calcolo, una funzionalità fondamentale degli Google Cloud strumenti di analisi. I consumatori di dati esposti tramite queste interfacce elaborano i dati utilizzando le risorse di calcolo a loro disposizione. I produttori di dati non devono eseguire il provisioning di infrastrutture aggiuntive.
Esiste un'ampia gamma di interfacce di consumo. Le seguenti interfacce sono le più comuni utilizzate in un data mesh e vengono trattate nelle sezioni seguenti:
- Viste e funzioni autorizzate
- API di lettura diretta
- Dati come stream
- API di accesso ai dati
- Looker Blocks
- Modelli di machine learning (ML)
L'elenco delle interfacce in questo documento non è esaustivo. Esistono anche altre opzioni che potresti prendere in considerazione per le tue interfacce di consumo (ad esempio, BigQuery sharing (in precedenza Analytics Hub)). Tuttavia, queste altre interfacce non rientrano nell'ambito di questo documento.
Visualizzazioni e funzioni autorizzate
Per quanto possibile, i prodotti di dati devono essere esposti tramite viste autorizzate e funzioni autorizzate,incluse le funzioni con valori di tabella. I set di dati autorizzati offrono un modo pratico per autorizzare automaticamente diverse visualizzazioni. L'utilizzo delle viste autorizzate impedisce l'accesso diretto alle tabelle di base e ti consente di ottimizzare le tabelle sottostanti e le query eseguite su di esse, senza influire sull'utilizzo di queste viste da parte dei consumatori. I consumer di questa interfaccia utilizzano SQL per eseguire query sui dati. Il seguente diagramma illustra l'utilizzo dei set di dati autorizzati come interfaccia di consumo.
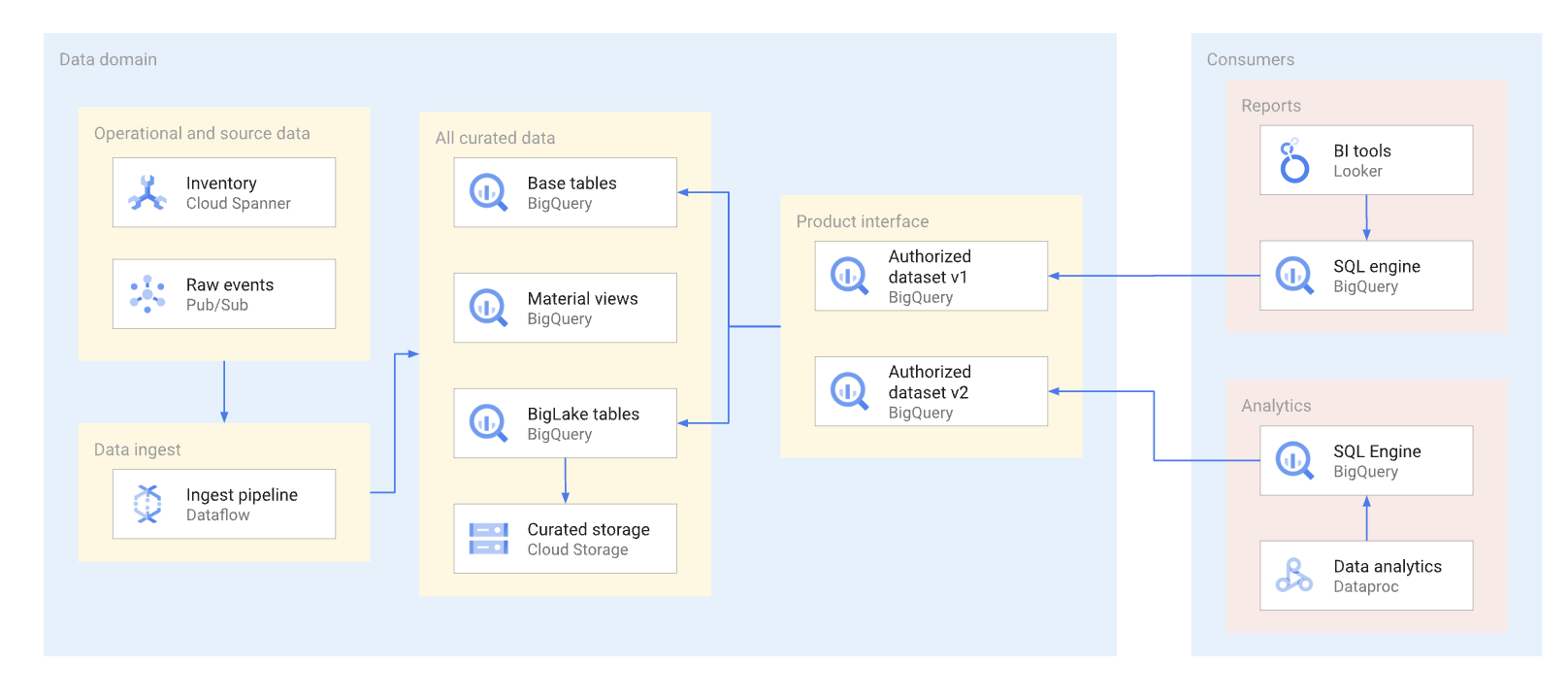
I set di dati e le viste autorizzati consentono di abilitare facilmente il controllo delle versioni delle interfacce. Come mostrato nel seguente diagramma, i produttori di dati possono adottare due approcci principali per il controllo delle versioni:
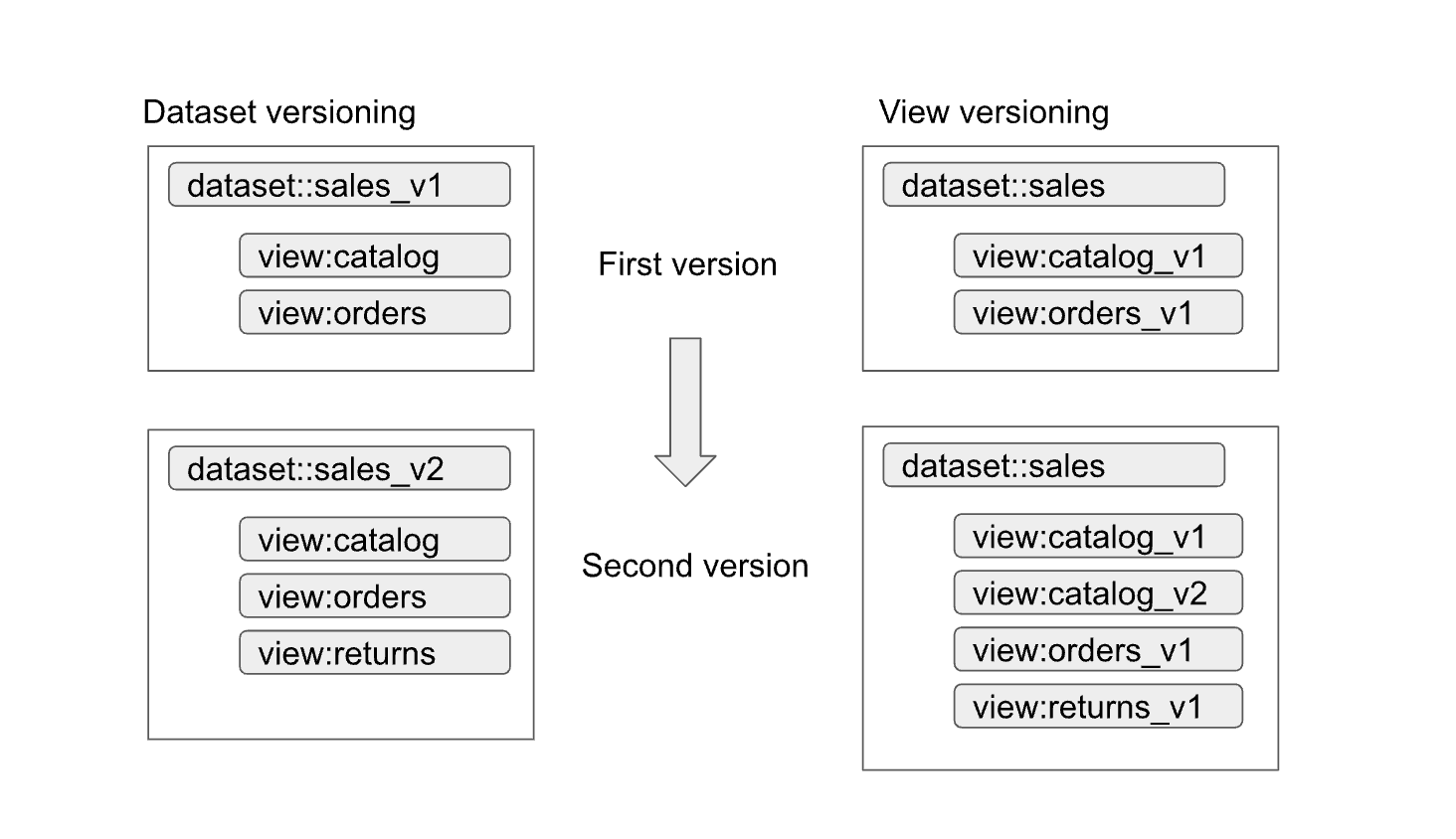
Gli approcci possono essere riassunti come segue:
- Controllo delle versioni del set di dati:in questo approccio, viene controllata la versione del nome del set di dati.
Non viene eseguito il controllo delle versioni delle visualizzazioni e delle funzioni all'interno del set di dati. Mantieni gli stessi nomi per le visualizzazioni e le funzioni indipendentemente dalla versione. Ad esempio,
la prima versione di un set di dati sulle vendite è definita in un set di dati denominato
sales_v1con due visualizzazioni,catalogeorders. Nella seconda versione, il set di dati sulle vendite è stato rinominatosales_v2e tutte le visualizzazioni precedenti nel set di dati mantengono i nomi precedenti, ma hanno nuovi schemi. La seconda versione del set di dati potrebbe anche avere nuove visualizzazioni aggiunte o rimuovere una delle visualizzazioni precedenti. - Controllo delle versioni delle viste:in questo approccio, le versioni delle viste all'interno del set di dati vengono controllate anziché il set di dati stesso. Ad esempio, il set di dati sulle vendite
mantiene il nome di
salesindipendentemente dalla versione. Tuttavia, i nomi delle visualizzazioni all'interno del set di dati cambiano per riflettere ogni nuova versione della visualizzazione (ad esempiocatalog_v1,catalog_v2,orders_v1,orders_v2eorders_v3).
L'approccio migliore al controllo delle versioni per la tua organizzazione dipende dai criteri dell'organizzazione e dal numero di visualizzazioni che diventano obsolete con l'aggiornamento dei dati sottostanti. Il controllo delle versioni del set di dati è la soluzione migliore quando è necessario un aggiornamento importante del prodotto e la maggior parte delle visualizzazioni deve essere modificata. Il controllo delle versioni comporta un minor numero di visualizzazioni con lo stesso nome in set di dati diversi, ma può portare ad ambiguità, ad esempio, come capire se un'unione tra set di dati funziona correttamente. Un approccio ibrido può essere un buon compromesso. In un approccio ibrido, le modifiche compatibili dello schema sono consentite all'interno di un singolo set di dati, mentre le modifiche incompatibili richiedono un nuovo set di dati.
Considerazioni sulle tabelle BigLake
Le viste autorizzate possono essere create non solo sulle tabelle BigQuery, ma anche sulle tabelle BigLake. Le tabelle BigLake consentono ai consumatori di eseguire query sui dati archiviati in Cloud Storage utilizzando l'interfaccia SQL di BigQuery. Le tabelle BigLake supportano controllo dell'accesso granulare senza che i consumatori di dati debbano disporre delle autorizzazioni di lettura per il bucket Cloud Storage sottostante.
I produttori di dati devono considerare quanto segue per le tabelle BigLake:
- La progettazione dei formati dei file e del layout dei dati influisce sulle prestazioni delle query. I formati basati su colonne, ad esempio Parquet o ORC, in genere hanno un rendimento molto migliore per le query analitiche rispetto ai formati JSON o CSV.
- Un layout partizionato Hive consente di eliminare le partizioni e velocizza le query che utilizzano colonne di partizionamento.
- Nella fase di progettazione devono essere presi in considerazione anche il numero di file e le prestazioni di query preferite per le dimensioni dei file.
Se le query che utilizzano le tabelle BigLake non soddisfano i requisiti del contratto di livello di servizio (SLA) per l'interfaccia e non possono essere ottimizzate, ti consigliamo di eseguire le seguenti azioni:
- Per i dati che devono essere esposti al consumatore di dati, convertili in spazio di archiviazione BigQuery.
- Ridefinisci le visualizzazioni autorizzate in modo che utilizzino le tabelle BigQuery.
In genere, questo approccio non causa interruzioni ai consumatori di dati e non richiede modifiche alle loro query. Le query nello spazio di archiviazione BigQuery possono essere ottimizzate utilizzando tecniche non possibili con le tabelle BigLake. Ad esempio, con l'archiviazione BigQuery, i consumatori possono eseguire query sulle viste materializzate con partizionamento e clustering diversi rispetto alle tabelle di base e possono utilizzare BigQuery BI Engine.
API di lettura diretta
Sebbene in genere non consigliamo ai produttori di dati di concedere ai consumatori di dati l'accesso diretto in lettura alle tabelle di base, a volte potrebbe essere pratico consentire tale accesso per motivi quali prestazioni e costi. In questi casi, è necessario prestare particolare attenzione per garantire la stabilità dello schema della tabella.
Esistono due modi per accedere direttamente ai dati in un tipico data warehouse. I produttori di dati possono utilizzare l'API BigQuery Storage Read oppure le API JSON o XML di Cloud Storage. Il seguente diagramma illustra due esempi di consumatori che utilizzano queste API. Uno è un caso d'uso di machine learning (ML), l'altro è un job di elaborazione dei dati.
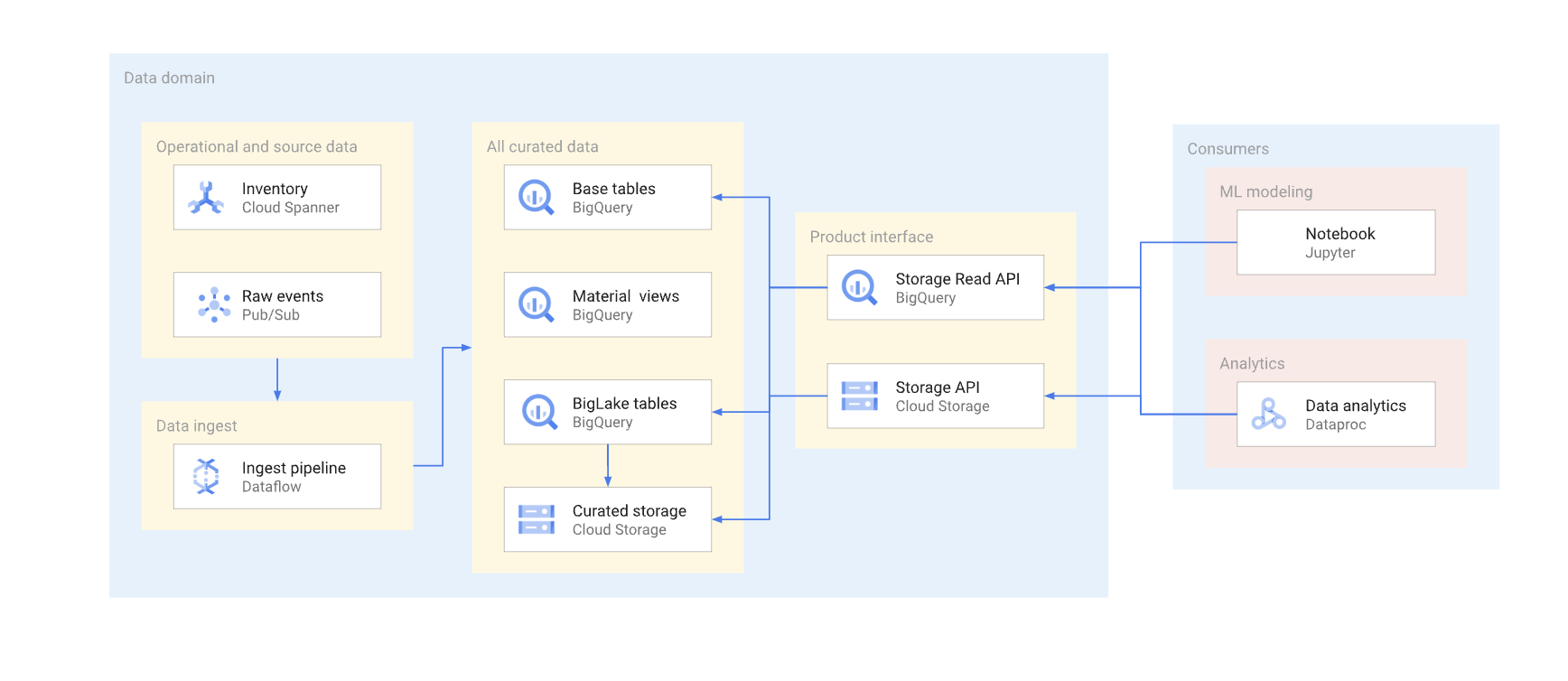
Il controllo delle versioni di un'interfaccia a lettura diretta è complesso. In genere, i produttori di dati devono creare un'altra tabella con uno schema diverso. Devono anche mantenere due versioni della tabella finché tutti i consumatori di dati della versione ritirata non eseguono la migrazione a quella nuova. Se i consumatori possono tollerare l'interruzione della ricostruzione della tabella e il passaggio al nuovo schema, è possibile evitare la duplicazione dei dati. Nei casi in cui le modifiche allo schema possono essere compatibili con le versioni precedenti, è possibile evitare la migrazione della tabella di base. Ad esempio, non devi eseguire la migrazione della tabella di base se vengono aggiunte solo nuove colonne e i dati in queste colonne vengono compilati per tutte le righe.
Di seguito è riportato un riepilogo delle differenze tra l'API Storage di lettura e l'API Cloud Storage. In generale, se possibile, consigliamo ai produttori di dati di utilizzare l'API BigQuery per le applicazioni di analisi.
API Storage Read: l'API Storage Read può essere utilizzata per leggere i dati nelle tabelle BigQuery e per leggere le tabelle BigLake. Questa API supporta il filtraggio e controllo dell'accesso granulare e può essere una buona opzione per i consumatori di analisi dei dati o ML stabili.
API Cloud Storage:i produttori di dati potrebbero dover condividere un particolare bucket Cloud Storage direttamente con i consumatori di dati. Ad esempio, i produttori di dati possono condividere il bucket se i consumatori di dati non possono utilizzare l'interfaccia SQL per qualche motivo o se il bucket ha formati di dati non supportati dall'API Storage Read.
In generale, sconsigliamo ai produttori di dati di consentire l'accesso diretto tramite le API di archiviazione perché l'accesso diretto non consente il filtraggio e controllo dell'accesso granulare. Tuttavia, l'approccio di accesso diretto può essere una scelta valida per set di dati stabili e di piccole dimensioni (gigabyte).
Consentire l'accesso a Pub/Sub al bucket offre ai consumatori di dati un modo semplice per copiare i dati nei loro progetti ed elaborarli lì. In generale, sconsigliamo la copia dei dati se è possibile evitarla. Più copie di dati aumentano il costo di archiviazione e si aggiungono al sovraccarico di manutenzione e monitoraggio della derivazione.
Dati come stream
Un dominio può esporre i dati di streaming pubblicandoli in un argomento Pub/Sub. Gli abbonati che vogliono utilizzare i dati creano sottoscrizioni per utilizzare i messaggi pubblicati in quell'argomento. Ogni abbonato riceve e utilizza i dati in modo indipendente. Il seguente diagramma mostra un esempio di questi flussi di dati.
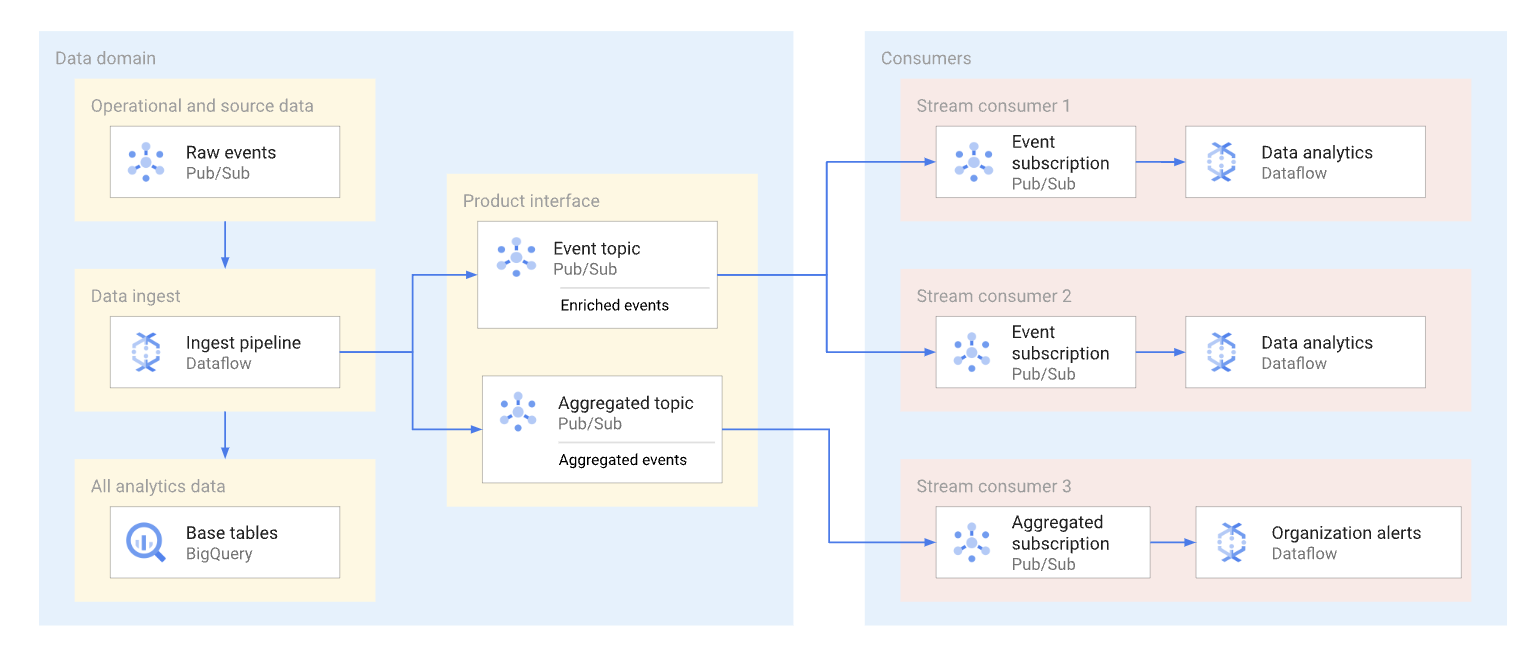
Nel diagramma, la pipeline di importazione legge gli eventi non elaborati, li arricchisce (li cura) e salva questi dati curati nel datastore analitico (tabella di base BigQuery). Allo stesso tempo, la pipeline pubblica gli eventi arricchiti in un argomento dedicato. Questo argomento viene utilizzato da più abbonati, ognuno dei quali potrebbe filtrare questi eventi per ottenere solo quelli pertinenti. La pipeline aggrega e pubblica anche le statistiche sugli eventi nel proprio argomento per essere elaborate da un altro consumer di dati.
Di seguito sono riportati esempi di casi d'uso per le sottoscrizioni Pub/Sub:
- Eventi arricchiti, ad esempio fornendo informazioni complete sul profilo del cliente insieme ai dati su un particolare ordine del cliente.
- Notifiche di aggregazione quasi in tempo reale, ad esempio statistiche totali degli ordini per gli ultimi 15 minuti.
- Avvisi a livello aziendale, ad esempio la generazione di un avviso se il volume degli ordini è diminuito del 20% rispetto a un periodo simile del giorno precedente.
- Notifiche di modifica dei dati (simili al concetto di notifiche di acquisizione delle modifiche ai dati), ad esempio quando lo stato di un determinato ordine cambia.
Il formato dei dati utilizzato dai produttori di dati per i messaggi Pub/Sub influisce sui costi e sulla modalità di elaborazione di questi messaggi. Per i flussi ad alto volume in un'architettura data mesh, i formati Avro o Protobuf sono buone opzioni. Se i produttori di dati utilizzano questi formati, possono assegnare schemi agli argomenti Pub/Sub. Gli schemi contribuiscono a garantire che i consumatori ricevano messaggi ben formati.
Poiché una struttura di dati di streaming può cambiare costantemente, il controllo delle versioni di questa interfaccia richiede il coordinamento tra i produttori e i consumatori di dati. I produttori di dati possono adottare diversi approcci comuni, che sono i seguenti:
- Viene creato un nuovo argomento ogni volta che la struttura del messaggio cambia. Questo
argomento spesso ha uno schema Pub/Sub esplicito. I consumatori di dati
che hanno bisogno della nuova interfaccia possono iniziare a utilizzare i nuovi dati. La versione del messaggio
è implicita nel nome dell'argomento, ad esempio
click_events_v1. I formati dei messaggi sono fortemente tipizzati. Non esiste alcuna variazione nel formato del messaggio tra i messaggi dello stesso argomento. Lo svantaggio di questo approccio è che potrebbero esserci consumatori di dati che non possono passare al nuovo abbonamento. In questo caso, il produttore di dati deve continuare a pubblicare eventi in tutti gli argomenti attivi per un po' di tempo e i consumatori di dati che si iscrivono all'argomento devono gestire un intervallo nel flusso di messaggi o rimuovere i duplicati dei messaggi. - I dati vengono sempre pubblicati nello stesso argomento. Tuttavia, la struttura del messaggio può cambiare. Un attributo del messaggio di Pub/Sub
(separato dal payload) definisce la versione del messaggio. Ad esempio,
v=1.0. Questo approccio elimina la necessità di gestire lacune o duplicati; tuttavia, tutti i consumatori di dati devono essere pronti a ricevere messaggi di un nuovo tipo. Inoltre, i produttori di dati non possono utilizzare gli schemi degli argomenti Pub/Sub per questo approccio. - Un approccio ibrido. Lo schema del messaggio può avere una sezione di dati arbitraria che può essere utilizzata per nuovi campi. Questo approccio può fornire un equilibrio ragionevole tra dati fortemente tipizzati e modifiche frequenti e complesse delle versioni.
API di accesso ai dati
I produttori di dati possono creare un'API personalizzata per accedere direttamente alle tabelle di base in un data warehouse. In genere, questi produttori espongono questa API personalizzata come API REST o gRPC ed eseguono il deployment su Cloud Run o su un cluster Kubernetes. Un gateway API come Apigee può fornire altre funzionalità aggiuntive, come la limitazione del traffico o un livello di memorizzazione nella cache. Queste funzionalità sono utili quando si espone l'API di accesso ai dati ai consumatori al di fuori di un'organizzazione. Google Cloud I potenziali candidati per un'API di accesso ai dati sono query sensibili alla latenza e ad alta concorrenza che restituiscono un risultato relativamente piccolo in una singola API e possono essere memorizzati nella cache in modo efficace.
Di seguito sono riportati alcuni esempi di un'API personalizzata per l'accesso ai dati:
- Una visualizzazione combinata delle metriche SLA della tabella o del prodotto.
- I primi 10 record (potenzialmente memorizzati nella cache) di una determinata tabella.
- Un insieme di dati di statistiche della tabella (numero totale di righe o distribuzione dei dati all'interno delle colonne chiave).
Eventuali linee guida e governance che l'organizzazione ha in merito alla creazione di API per applicazioni sono applicabili anche alle API personalizzate create dai produttori di dati. Le linee guida e la governance dell'organizzazione devono coprire problemi come hosting, monitoraggio, controllo dell'accesso e controllo delle versioni.
Lo svantaggio di un'API personalizzata è che i produttori di dati sono responsabili di qualsiasi infrastruttura aggiuntiva necessaria per ospitare questa interfaccia, nonché della codifica e della manutenzione dell'API personalizzata. Consigliamo ai produttori di dati di esaminare altre opzioni prima di decidere di creare API di accesso ai dati personalizzate. Ad esempio, i produttori di dati possono utilizzare BigQuery BI Engine per ridurre la latenza di risposta e aumentare la contemporaneità.
Looker Blocks
Per prodotti come Looker, che vengono utilizzati molto negli strumenti di business intelligence (BI), potrebbe essere utile mantenere un insieme di widget specifici per gli strumenti BI. Poiché il team di produzione dei dati conosce il modello di dati sottostante utilizzato nel dominio, è il più adatto a creare e gestire un insieme predefinito di visualizzazioni.
Nel caso di Looker, questa visualizzazione potrebbe essere un insieme di Looker Block (modelli di dati LookML predefiniti). I blocchi Looker possono essere facilmente incorporati nelle dashboard ospitate dai consumatori.
personalizzati
Poiché i team che lavorano nei domini di dati hanno una profonda comprensione e conoscenza dei propri dati, spesso sono i team migliori per creare e gestire modelli ML addestrati sui dati del dominio. Questi modelli ML possono essere esposti tramite diverse interfacce, tra cui:
- I modelli BigQuery ML possono essere implementati in un set di dati dedicato e condivisi con i consumatori di dati per le previsioni batch di BigQuery.
- I modelli BigQuery ML possono essere esportati in Vertex AI per essere utilizzati per le previsioni online.
Considerazioni sulla posizione dei dati per le interfacce di consumo
Un aspetto importante da considerare quando i produttori di dati definiscono le interfacce di consumo per i prodotti di dati è la posizione dei dati. In generale, per ridurre al minimo i costi, i dati devono essere elaborati nella stessa regione in cui sono archiviati. Questo approccio aiuta a evitare i costi per il traffico in uscita di dati tra regioni. Questo approccio ha anche la latenza di consumo dei dati più bassa. Per questi motivi, i dati archiviati nelle località BigQuery multiregionali sono in genere i candidati migliori per l'esposizione come prodotto di dati.
Tuttavia, per motivi di prestazioni, i dati archiviati in Cloud Storage ed esposti tramite tabelle BigLake o API di lettura diretta devono essere archiviati in bucket regionali.
Se i dati esposti in un prodotto si trovano in una regione e devono essere uniti a dati in un altro dominio in un'altra regione, i consumatori di dati devono considerare i seguenti limiti:
- Le query tra regioni che utilizzano BigQuery SQL non sono supportate. Se il metodo di consumo principale per i dati è BigQuery SQL, tutte le tabelle nella query devono trovarsi nella stessa posizione.
- Gli impegni BigQuery a tariffa fissa sono regionali. Se un progetto utilizza solo un impegno a tariffa fissa in una regione, ma esegue query su un prodotto di dati in un'altra regione, si applicano i prezzi on demand.
- I consumatori di dati possono utilizzare le API di lettura diretta per leggere i dati di un'altra regione. Tuttavia, si applicano i costi per il traffico in uscita dalla rete tra regioni diverse e i consumatori di dati molto probabilmente riscontreranno latenza per i trasferimenti di dati di grandi dimensioni.
I dati a cui si accede di frequente in più regioni possono essere replicati in queste regioni per ridurre i costi e la latenza delle query sostenuti dai consumatori di prodotti. Ad esempio, i set di dati BigQuery
possono essere copiati
in altre regioni. Tuttavia, i dati devono essere copiati solo quando è necessario. Consigliamo
ai produttori di dati di rendere disponibile solo un sottoinsieme dei dati di prodotto disponibili
a più regioni quando copi i dati. Questo approccio consente di
ridurre al minimo la latenza e il costo della replica. Questo approccio può comportare la necessità di
fornire più versioni dell'interfaccia di consumo con la regione
della posizione dei dati esplicitamente indicata. Ad esempio, le viste autorizzate di BigQuery possono essere esposte tramite denominazione come sales_eu_v1 e sales_us_v1.
Le interfacce di flusso di dati che utilizzano argomenti Pub/Sub non richiedono alcuna logica di replica aggiuntiva per utilizzare i messaggi nelle regioni diverse da quella in cui è archiviato il messaggio. Tuttavia, in questo caso si applicano costi per il traffico in uscita aggiuntivi tra regioni.
Esporre le interfacce di consumo ai consumatori di dati
Questa sezione illustra come rendere rilevabili le interfacce di consumo da parte di potenziali consumatori. Data Catalog è un servizio completamente gestito che le organizzazioni possono utilizzare per fornire i servizi di gestione dei metadati e di rilevamento dei dati. I produttori di dati devono rendere ricercabili le interfacce di consumo dei loro prodotti di dati e annotarle con i metadati appropriati per consentire ai consumatori di prodotti di accedervi in modalità self-service. mer
Le sezioni seguenti descrivono come ogni tipo di interfaccia è definito come voce di Data Catalog.
Interfacce SQL basate su BigQuery
I metadati tecnici, come un nome di tabella completo o uno schema di tabella, vengono registrati automaticamente per le viste autorizzate, le viste BigLake e le tabelle BigQuery disponibili tramite l'API Storage Read. Consigliamo ai produttori di dati di fornire anche informazioni aggiuntive nella documentazione del prodotto di dati per aiutare i consumatori di dati. Ad esempio, per aiutare gli utenti a trovare la documentazione del prodotto per una voce, i produttori di dati possono aggiungere un URL a uno dei tag applicati alla voce. I produttori possono anche fornire quanto segue:
- Set di colonne raggruppate, che devono essere utilizzate nei filtri delle query.
- Valori di enumerazione per i campi con tipo di enumerazione logica, se il tipo non è fornito come parte della descrizione del campo.
- Sono supportati i join con altre tabelle.
Stream di dati
Gli argomenti Pub/Sub vengono registrati automaticamente in Data Catalog. Tuttavia, i produttori di dati devono descrivere lo schema nella documentazione del prodotto di dati.
API Cloud Storage
Data Catalog supporta la definizione delle voci di file Cloud Storage e del relativo schema. Se un set di file del data lake è gestito da Dataplex Universal Catalog, il set di file viene registrato automaticamente in Data Catalog. I fileset non associati a Dataplex Universal Catalog vengono aggiunti utilizzando un approccio diverso.
Altre interfacce
Puoi aggiungere altre interfacce che non hanno il supporto integrato di Data Catalog creando voci personalizzate.
Passaggi successivi
- Consulta un'implementazione di riferimento dell'architettura di mesh di dati.
- Scopri di più su BigQuery.
- Scopri di più su Dataplex.
- Per ulteriori architetture di riferimento, diagrammi e best practice, esplora il Cloud Architecture Center.