Questo documento descrive l'architettura complessiva di un sistema di machine learning (ML) che utilizza le librerie TensorFlow Extended (TFX). Viene inoltre illustrato come configurare l'integrazione continua (CI), la distribuzione continua (CD) e l'addestramento continuo (CT) per il sistema ML utilizzando Cloud Build e Vertex AI Pipelines.
In questo documento, i termini sistema ML e pipeline ML si riferiscono alle pipeline di addestramento del modello ML, anziché alle pipeline di assegnazione del punteggio o di previsione del modello.
Questo documento è rivolto a data scientist e ML engineer che vogliono adattare le proprie pratiche CI/CD per spostare le soluzioni ML in produzione su Google Cloude che vogliono contribuire a garantire la qualità, la manutenibilità e l'adattabilità delle proprie pipeline ML.
Questo documento tratta i seguenti argomenti:
- Comprendere CI/CD e l'automazione nel machine learning.
- Progettazione di una pipeline ML integrata con TFX.
- Orchestrazione e automazione della pipeline ML utilizzando Vertex AI Pipelines.
- Configurazione di un sistema CI/CD per la pipeline ML utilizzando Cloud Build.
MLOps
Per integrare un sistema ML in un ambiente di produzione, devi orchestrare i passaggi della pipeline ML. Inoltre, devi automatizzare l'esecuzione della pipeline per l'addestramento continuo dei modelli. Per sperimentare nuove idee e funzionalità, devi adottare pratiche CI/CD nelle nuove implementazioni delle pipeline. Le sezioni seguenti forniscono una panoramica generale di CI/CD e CT in ML.
Automazione di pipeline ML
In alcuni casi d'uso, il processo manuale di addestramento, convalida e deployment dei modelli di ML può essere sufficiente. Questo approccio manuale funziona se il tuo team gestisce solo pochi modelli ML che non vengono riqualificati o modificati di frequente. In pratica, tuttavia, i modelli spesso si guastano quando vengono implementati nel mondo reale perché non riescono ad adattarsi ai cambiamenti nelle dinamiche degli ambienti o ai dati che descrivono queste dinamiche.
Affinché il sistema di ML si adatti a queste modifiche, devi applicare le seguenti tecniche MLOps:
- Automatizza l'esecuzione della pipeline ML per riaddestrare nuovi modelli su nuovi dati per acquisire eventuali pattern emergenti. CT viene trattato più avanti in questo documento nella sezione ML con Vertex AI Pipelines.
- Configura un sistema di distribuzione continua per eseguire il deployment frequente di nuove implementazioni dell'intera pipeline di machine learning. CI/CD viene trattato più avanti in questo documento nella sezione Configurazione CI/CD per ML su Google Cloud.
Puoi automatizzare le pipeline di produzione ML per riaddestrare i modelli con nuovi dati. Puoi attivare la pipeline on demand, in base a una pianificazione, alla disponibilità di nuovi dati, al peggioramento delle prestazioni del modello, a variazioni significative delle proprietà statistiche dei dati o in base ad altre condizioni.
Pipeline CI/CD rispetto alla pipeline CT
La disponibilità di nuovi dati è uno dei fattori scatenanti del riaddestramento del modello di ML. La disponibilità di una nuova implementazione della pipeline ML (inclusi nuova architettura del modello, feature engineering e iperparametri) è un altro trigger importante per rieseguire la pipeline ML. Questa nuova implementazione della pipeline ML funge da nuova versione del servizio di previsione del modello, ad esempio un microservizio con un'API REST per la pubblicazione online. La differenza tra i due casi è la seguente:
- Per addestrare un nuovo modello ML con nuovi dati, viene eseguita la pipeline CT distribuita in precedenza. Non vengono implementate nuove pipeline o componenti; alla fine della pipeline viene pubblicato solo un nuovo servizio di previsione o un modello appena addestrato.
- Per addestrare un nuovo modello ML con una nuova implementazione, viene eseguito il deployment di una nuova pipeline tramite una pipeline CI/CD.
Per eseguire rapidamente il deployment di nuove pipeline ML, devi configurare una pipeline CI/CD. Questa pipeline è responsabile del deployment automatico di nuove pipeline e componenti ML quando sono disponibili e approvate nuove implementazioni per vari ambienti (come sviluppo, test, gestione temporanea, pre-produzione e produzione).
Il seguente diagramma mostra la relazione tra la pipeline CI/CD e la pipeline ML CT.

Figura 1. Pipeline CI/CD e ML CT.
L'output di queste pipeline è il seguente:
- Se viene fornita una nuova implementazione, una pipeline CI/CD riuscita esegue il deployment di una nuova pipeline ML CT.
- Se vengono forniti nuovi dati, una pipeline CT riuscita addestra un nuovo modello e lo implementa come servizio di previsione.
Progettazione di un sistema ML basato su TFX
Le sezioni seguenti descrivono come progettare un sistema ML integrato utilizzando TensorFlow Extended (TFX) per configurare una pipeline CI/CD per il sistema ML. Sebbene esistano diversi framework per la creazione di modelli ML, TFX è una piattaforma ML integrata per lo sviluppo e il deployment di sistemi ML di produzione. Una pipeline TFX è una sequenza di componenti che implementano un sistema ML. Questa pipeline TFX è progettata per attività di ML scalabili e ad alte prestazioni. Queste attività includono la modellazione, l'addestramento, la convalida, l'inferenza e la gestione dei deployment. Le librerie chiave di TFX sono le seguenti:
- TensorFlow Data Validation (TFDV): Utilizzato per rilevare anomalie nei dati.
- TensorFlow Transform (TFT): Utilizzato per la pre-elaborazione dei dati e il feature engineering.
- Estimator TensorFlow e Keras: utilizzati per creare e addestrare modelli ML.
- TensorFlow Model Analysis (TFMA): utilizzato per la valutazione e l'analisi dei modelli ML.
- TensorFlow Serving (TFServing): utilizzato per pubblicare modelli ML come API REST e gRPC.
Panoramica del sistema ML TFX
Il seguente diagramma mostra come le varie librerie TFX sono integrate per comporre un sistema di ML.

Figura 2. Un tipico sistema ML basato su TFX.
La Figura 2 mostra un tipico sistema ML basato su TFX. I seguenti passaggi possono essere completati manualmente o mediante una pipeline automatizzata:
- Estrazione dei dati: il primo passaggio consiste nell'estrazione dei nuovi dati di addestramento dalle relative origini dati. Gli output di questo passaggio sono file di dati utilizzati per l'addestramento e la valutazione del modello.
- Convalida dei dati: TFDV convalida i dati rispetto allo schema dei dati (non elaborati) previsto. Lo schema dei dati viene creato e corretto durante la fase di sviluppo, prima dell'implementazione del sistema. I passaggi di convalida dei dati rilevano anomalie correlate sia alla distribuzione dei dati sia agli sbilanciamenti dello schema. I risultati di questo passaggio sono le anomalie (se presenti) e una decisione sull'esecuzione o meno dei passaggi successivi.
- Trasformazione dei dati: dopo la convalida, i dati vengono suddivisi e
preparati per l'attività di ML eseguendo trasformazioni dei dati e operazioni di
ingegneria delle funzionalità utilizzando TFT. Gli output di questo passaggio sono file di dati per addestrare e valutare il modello, di solito trasformati in formato
TFRecords. Inoltre, gli artefatti di trasformazione prodotti aiutano a costruire gli input del modello e incorporano il processo di trasformazione nel modello salvato esportato dopo l'addestramento. - Addestramento e ottimizzazione del modello: per implementare e addestrare il modello ML, utilizza l'API
tf.Kerascon i dati trasformati prodotti dal passaggio precedente. Per selezionare le impostazioni dei parametri che portano al modello migliore, puoi utilizzare Keras Tuner, una libreria di ottimizzazione degli iperparametri per Keras. In alternativa, puoi utilizzare altri servizi come Katib, Vertex AI Vizier o lo strumento di ottimizzazione degli iperparametri di Vertex AI. L'output di questo passaggio è un modello salvato utilizzato per la valutazione e un altro modello salvato utilizzato per la pubblicazione online del modello per la previsione. - Valutazione e convalida del modello: quando il modello viene esportato dopo il passaggio di addestramento, viene valutato su un set di dati di test per valutare la qualità del modello utilizzando TFMA. TFMA valuta la qualità del modello nel suo complesso e identifica la parte delmodello dei datii che non funziona. Questa valutazione contribuisce a garantire che il modello venga promosso per la pubblicazione solo se soddisfa i criteri di qualità. I criteri possono includere un rendimento equo su vari sottoinsiemi di dati (ad esempio, dati demografici e località) e un rendimento migliore rispetto ai modelli precedenti o a un modello di riferimento. L'output di questo passaggio è un insieme di metriche di rendimento e una decisione sull'opportunità di promuovere il modello in produzione.
- Pubblicazione del modello per la previsione: dopo la convalida del modello appena addestrato, viene eseguito il deployment come microservizio per pubblicare previsioni online utilizzando TensorFlow Serving. L'output di questo passaggio è un servizio di previsione di cui è stato eseguito il deployment del modello ML addestrato. Puoi sostituire questo passaggio memorizzando il modello addestrato in un registro dei modelli. Successivamente viene avviato un processo CI/CD separato per la pubblicazione del modello.
Per un esempio di come utilizzare le librerie TFX, consulta il tutorial ufficiale sul componente TFX Keras.
Sistema ML TFX su Google Cloud
In un ambiente di produzione, i componenti del sistema devono essere eseguiti su larga scala su una piattaforma affidabile. Il seguente diagramma mostra come viene eseguito ogni passaggio della pipeline ML TFX utilizzando un servizio gestito su Google Cloud, il che garantisce agilità, affidabilità e prestazioni su larga scala.

Figura 3. Sistema ML basato su TFX su Google Cloud.
La tabella seguente descrive i servizi Google Cloud mostrati nella figura 3:
| Passaggio | Libreria TFX | Google Cloud servizio |
|---|---|---|
| Estrazione e convalida dei dati | TensorFlow Data Validation | Dataflow |
| Trasformazione dei dati | TensorFlow Transform | Dataflow |
| Addestramento e ottimizzazione del modello | TensorFlow | Vertex AI Training |
| Valutazione e convalida del modello | TensorFlow Model Analysis | Dataflow |
| Distribuzione del modello per le previsioni | TensorFlow Serving | Vertex AI Inference |
| Spazio di archiviazione del modello | N/D | Vertex AI Model Registry |
- Dataflow è un servizio completamente gestito, serverless e affidabile per l'esecuzione di pipeline Apache Beam su larga scala su Google Cloud. Dataflow
viene utilizzato per scalare i seguenti processi:
- Calcolo delle statistiche per convalidare i dati in arrivo.
- Esecuzione della preparazione e della trasformazione dei dati.
- Valutare il modello su un set di dati di grandi dimensioni.
- Calcolo delle metriche su diversi aspetti del set di dati di valutazione.
- Cloud Storage
è uno spazio di archiviazione durevole e ad alta disponibilità per oggetti binari di grandi dimensioni.
Cloud Storage ospita gli artefatti prodotti
durante l'esecuzione della pipeline ML, tra cui:
- Anomalie dei dati (se presenti)
- Dati e artefatti trasformati
- Modello esportato (addestrato)
- Metriche di valutazione del modello
- Vertex AI Training è un servizio gestito per addestrare modelli ML su larga scala. Puoi eseguire job di addestramento del modello con container predefiniti per TensorFlow, scikit-learn, XGBoost e PyTorch. Puoi anche eseguire qualsiasi framework utilizzando i tuoi container personalizzati. Per la tua infrastruttura di addestramento, puoi utilizzare acceleratori e più nodi per l'addestramento distribuito. Inoltre, è disponibile un servizio scalabile basato sull'ottimizzazione bayesiana per l'ottimizzazione degli iperparametri.
- Vertex AI Inference è un servizio gestito per eseguire previsioni batch utilizzando i modelli addestrati e previsioni online eseguendo il deployment dei modelli come microservizio con un'API REST. Il servizio si integra anche con Vertex Explainable AI e Vertex AI Model Monitoring per comprendere i tuoi modelli e ricevere avvisi in caso di disallineamento e deviazione di una caratteristica o dell'attribuzione di una caratteristica.
- Vertex AI Model Registry consente di gestire il ciclo di vita dei modelli ML. Puoi creare versioni dei modelli importati e visualizzare le relative metriche sul rendimento. Un modello può quindi essere utilizzato per le previsioni batch o per il deployment per la pubblicazione online utilizzando Vertex AI Inference.
Orchestrazione del sistema ML utilizzando Vertex AI Pipelines
Questo documento ha illustrato come progettare un sistema ML basato su TFX e come eseguire ogni componente del sistema su larga scala su Google Cloud. Tuttavia, è necessario un orchestratore per collegare i diversi componenti del sistema tra loro. L'orchestratore esegue la pipeline in sequenza e passa automaticamente da un passaggio all'altro in base alle condizioni definite. Ad esempio, una condizione definita potrebbe essere l'esecuzione del passaggio di pubblicazione del modello dopo il passaggio di valutazione del modello se le metriche di valutazione soddisfano le soglie predefinite. I passaggi possono essere eseguiti anche in parallelo per risparmiare tempo, ad esempio per convalidare l'infrastruttura di deployment e valutare il modello. L'orchestrazione della pipeline di ML è utile sia nelle fasi di sviluppo che di produzione:
- Durante la fase di sviluppo, l'orchestrazione aiuta i data scientist a eseguire l'esperimento di ML, anziché eseguire manualmente ogni passaggio.
- Durante la fase di produzione, l'orchestrazione aiuta ad automatizzare l'esecuzione della pipeline ML in base a una pianificazione o a determinate condizioni di attivazione.
ML con Vertex AI Pipelines
Vertex AI Pipelines è un servizio gestito che ti consente di orchestrare e automatizzare pipeline ML in cui ogni componente della pipeline può essere eseguito in contenitori su Google Cloud o altre piattaforme cloud. Google Cloud I parametri e gli artefatti della pipeline generati vengono archiviati automaticamente in Vertex ML Metadata, che consente il monitoraggio della derivazione e dell'esecuzione. Il servizio Vertex AI Pipelines è costituito da quanto segue:
- Un'interfaccia utente per la gestione e il monitoraggio di esperimenti, job ed esecuzioni.
- Un motore per la pianificazione di flussi di lavoro di ML in più passaggi.
- Un SDK Python per definire e manipolare pipeline e componenti.
- Integrazione con Vertex ML Metadata per salvare informazioni su esecuzioni, modelli, set di dati e altri artefatti.
Di seguito è riportato un esempio di pipeline eseguita su Vertex AI Pipelines:
- Un insieme di attività ML containerizzate o componenti. Un componente della pipeline è un codice autonomo confezionato come immagine Docker. Un componente esegue un passaggio della pipeline. Accetta argomenti di input e produce artefatti.
- Una specifica della sequenza delle attività di ML, definita tramite un linguaggio specifico per il dominio (DSL) di Python. La topologia del flusso di lavoro è definita implicitamente collegando gli output di un passaggio upstream agli input di un passaggio downstream. Un passaggio nella definizione della pipeline richiama un componente nella pipeline. In una pipeline complessa, i componenti possono essere eseguiti più volte in loop oppure possono essere eseguiti in modo condizionale.
- Un insieme di parametri di input della pipeline, i cui valori vengono passati ai componenti della pipeline, inclusi i criteri per il filtraggio dei dati e la posizione in cui archiviare gli artefatti prodotti dalla pipeline.
Il seguente diagramma mostra un grafico di esempio di Vertex AI Pipelines.
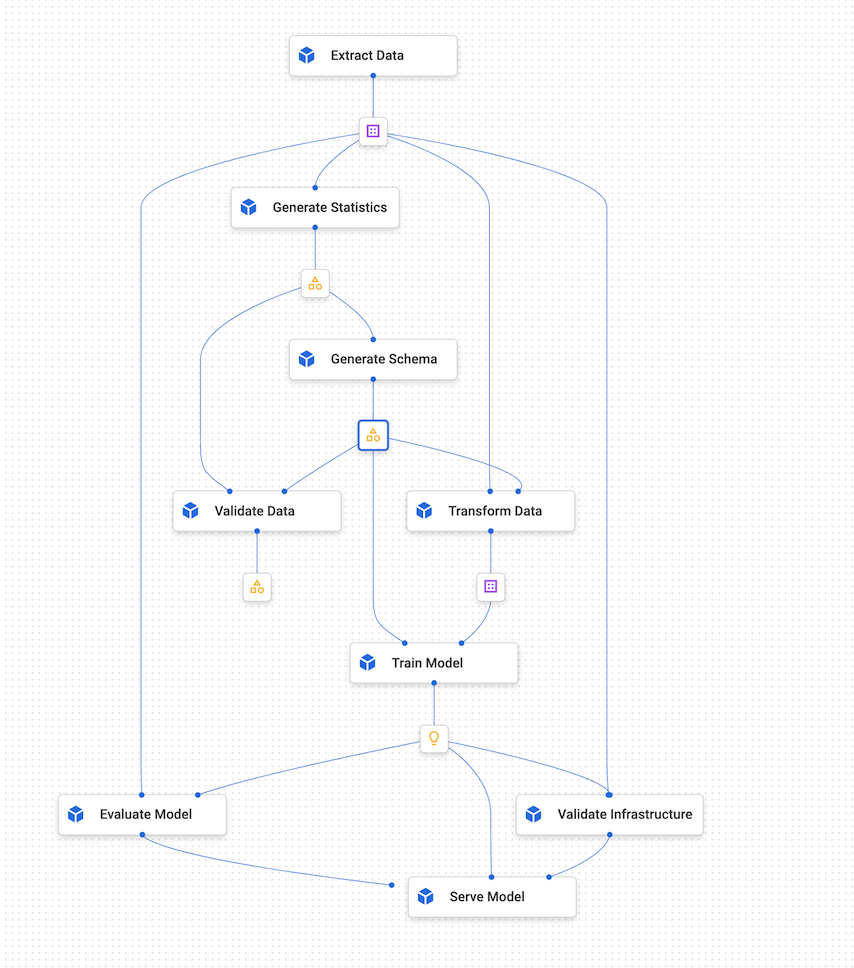
Figura 4. Un grafico di esempio di Vertex AI Pipelines.
SDK Kubeflow Pipelines
L'SDK Kubeflow Pipelines consente di creare componenti, definire la loro orchestrazione ed eseguirli come pipeline. Per maggiori dettagli sui componenti di Kubeflow Pipelines, consulta la sezione Creare componenti nella documentazione di Kubeflow.
Puoi anche utilizzare il DSL della pipeline TFX e utilizzare i componenti TFX. Un componente TFX incapsula le funzionalità dei metadati. Il driver fornisce i metadati all'executor eseguendo query sull'archivio di metadati. L'editore accetta i risultati dell'esecutore e li memorizza nei metadati. Puoi anche implementare il tuo componente personalizzato, che ha la stessa integrazione con i metadati. Puoi compilare le pipeline TFX in un file YAML compatibile con Vertex AI Pipelines utilizzando tfx.orchestration.experimental.KubeflowV2DagRunner. Poi puoi inviare il file a Vertex AI Pipelines per l'esecuzione.
Il seguente diagramma mostra come in Vertex AI Pipelines un'attività in container possa richiamare altri servizi come job BigQuery, job di addestramento (distribuiti) Vertex AI e job Dataflow.

Figura 5. Vertex AI Pipelines che richiama servizi gestitiGoogle Cloud .
Vertex AI Pipelines ti consente di orchestrare e automatizzare una pipeline ML di produzione eseguendo i servizi Google Cloud richiesti. Nella figura 5, Vertex ML Metadata funge da archivio dei metadati ML per Vertex AI Pipelines.
I componenti della pipeline non sono limitati all'esecuzione di servizi correlati a TFX su Google Cloud. Questi componenti possono eseguire qualsiasi servizio correlato a dati e calcolo, tra cui Dataproc per i job SparkML, AutoML e altri carichi di lavoro di calcolo.
Il containerizzazione delle attività in Vertex AI Pipelines presenta i seguenti vantaggi:
- Disaccoppia l'ambiente di esecuzione dal runtime del codice.
- Garantisce la riproducibilità del codice tra l'ambiente di sviluppo e quello di produzione, perché gli elementi che testi sono gli stessi in produzione.
- Isola ogni componente nella pipeline; ognuno può avere la propria versione del runtime, lingue diverse e librerie diverse.
- Aiuta a comporre pipeline complesse.
- Si integra con Vertex ML Metadata per la tracciabilità e la riproducibilità delle esecuzioni e degli artefatti della pipeline.
Per un'introduzione completa a Vertex AI Pipelines, consulta l'elenco degli esempi di notebook disponibili.
Attivazione e pianificazione di Vertex AI Pipelines
Quando esegui il deployment di una pipeline in produzione, devi automatizzarne le esecuzioni, a seconda degli scenari descritti nella sezione Automazione di pipeline ML.
L'SDK Vertex AI ti consente di gestire la pipeline in modo programmatico. La classe google.cloud.aiplatform.PipelineJob include API per creare esperimenti e per eseguire il deployment e l'esecuzione di pipeline. Utilizzando l'SDK, puoi quindi richiamare Vertex AI Pipelines da un altro servizio per ottenere trigger basati su eventi o scheduler.

Figura 6. Diagramma di flusso che mostra più trigger per Vertex AI Pipelines utilizzando le funzioni Pub/Sub e Cloud Run.
Nella figura 6 puoi vedere un esempio di come attivare il servizio Vertex AI Pipelines per eseguire una pipeline. La pipeline viene attivata utilizzando l'SDK Vertex AI da una funzione Cloud Run. La funzione Cloud Run stessa è un abbonato a Pub/Sub e viene attivata in base ai nuovi messaggi. Qualsiasi servizio che vuole attivare l'esecuzione della pipeline può pubblicare nell'argomento Pub/Sub corrispondente. L'esempio precedente ha tre servizi di pubblicazione:
- Cloud Scheduler pubblica i messaggi in base a una pianificazione e quindi attiva la pipeline.
- Cloud Composer pubblica i messaggi nell'ambito di un flusso di lavoro più ampio, ad esempio un flusso di lavoro di importazione dei dati che attiva la pipeline di addestramento dopo che BigQuery importa nuovi dati.
- Cloud Logging pubblica un messaggio in base ai log che soddisfano alcuni criteri di filtro. Puoi configurare i filtri per rilevare l'arrivo di nuovi dati o anche avvisi di distorsione e deviazione generati dal servizio Vertex AI Model Monitoring.
Configurazione di CI/CD per ML su Google Cloud
Vertex AI Pipelines consente di orchestrare sistemi ML che comportano più passaggi, tra cui pre-elaborazione dei dati, addestramento e valutazione dei modelli e deployment dei modelli. Nella fase di esplorazione della data science, Vertex AI Pipelines aiuta a sperimentare rapidamente l'intero sistema. Nella fase di produzione, Vertex AI Pipelines ti consente di automatizzare l'esecuzione della pipeline in base a nuovi dati per addestrare o riaddestrare il modello ML.
Architettura CI/CD
Il seguente diagramma mostra una panoramica di alto livello di CI/CD per ML con Vertex AI Pipelines.
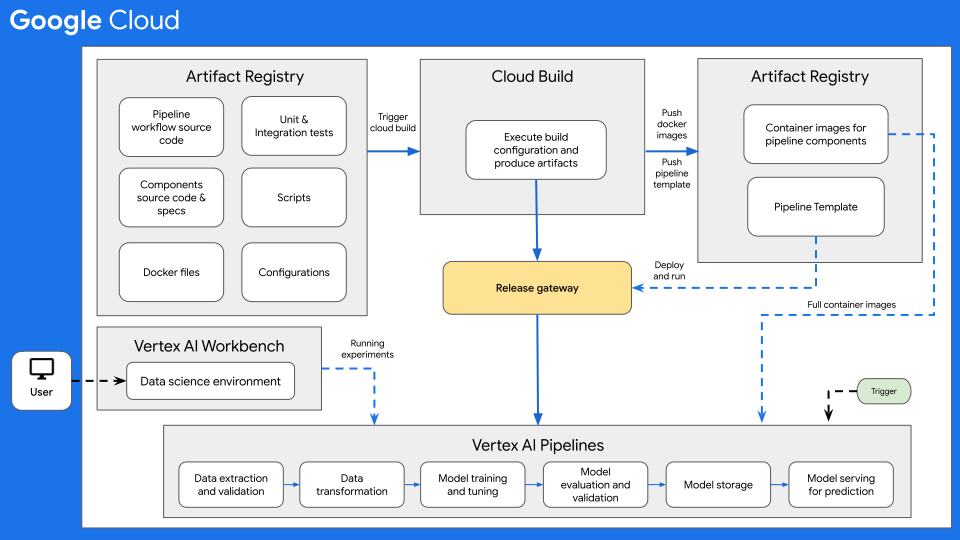
Figura 7: panoramica di alto livello di CI/CD con Vertex AI Pipelines.
Al centro di questa architettura c'è Cloud Build. Cloud Build può importare codice sorgente da Artifact Registry, GitHub, o Bitbucket, quindi eseguire una build in base alle tue specifiche e produrre artefatti come container Docker o file tar Python.
Cloud Build esegue la build come una serie di passaggi di build,
definiti in un
file di configurazione della build
(cloudbuild.yaml). Ogni passaggio di build viene eseguito in un container Docker. Puoi
utilizzare i passaggi di build supportati
forniti da Cloud Build oppure
scrivere i tuoi passaggi di build.
Il processo Cloud Build, che esegue la CI/CD richiesta per il tuo sistema ML, può essere eseguito manualmente o tramite trigger di build automatizzati. I trigger eseguono i passaggi di build configurati ogni volta che vengono inviate modifiche al codice sorgente della build. Puoi impostare un trigger di build per eseguire la routine di build in caso di modifiche al repository di codice sorgente o solo quando le modifiche soddisfano determinati criteri.
Inoltre, puoi avere routine di build (file di configurazione di Cloud Build) eseguite in risposta a trigger diversi. Ad esempio, puoi creare routine di build attivate quando vengono eseguiti commit nel ramo di sviluppo o nel ramo principale.
Puoi utilizzare le sostituzioni delle variabili di configurazione per definire le variabili di ambiente al momento della build. Queste sostituzioni vengono
acquisite dalle build attivate. Queste variabili includono $COMMIT_SHA,
$REPO_NAME, $BRANCH_NAME, $TAG_NAME e $REVISION_ID. Altre variabili
non basate su trigger sono $PROJECT_ID e $BUILD_ID. Le sostituzioni sono
utili per le variabili il cui valore non è noto fino al momento della build o per riutilizzare una
richiesta di build esistente con valori di variabile diversi.
Caso d'uso del flusso di lavoro CI/CD
Un repository del codice sorgente in genere include i seguenti elementi:
- Il codice sorgente del workflow delle pipeline Python in cui è definito il workflow della pipeline
- Il codice sorgente dei componenti della pipeline Python e i file di specifica dei componenti corrispondenti per i diversi componenti della pipeline, come la convalida dei dati, la trasformazione dei dati, l'addestramento del modello, la valutazione del modello e la gestione del modello.
- I Dockerfile necessari per creare immagini container Docker, uno per ogni componente della pipeline.
- Test di unità e integrazione Python per testare i metodi implementati nel componente e nella pipeline complessiva.
- Altri script, incluso il file
cloudbuild.yaml, i trigger di test e i deployment della pipeline. - File di configurazione (ad esempio, il file
settings.yaml), incluse le configurazioni dei parametri di input della pipeline. - Notebooks utilizzati per l'analisi esplorativa dei dati, l'analisi dei modelli e <x0A>la sperimentazione interattiva sui modelli.
Nell'esempio seguente, una routine di build viene attivata quando uno sviluppatore esegue il push del codice sorgente nel ramo di sviluppo dal proprio ambiente di data science.
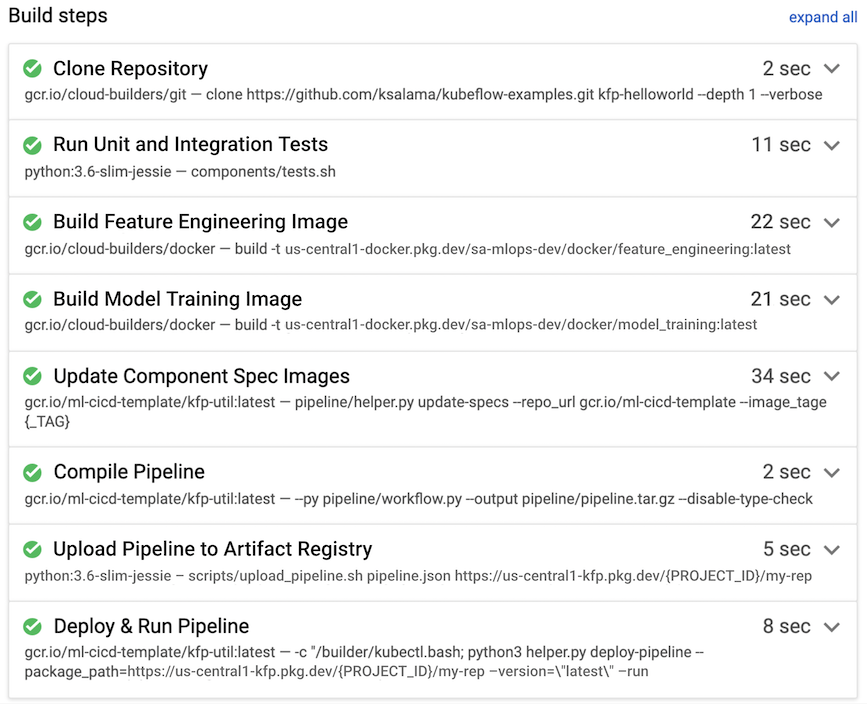
Figura 8. Esempio di passaggi di build eseguiti da Cloud Build.
Cloud Build in genere esegue i seguenti passaggi di build, mostrati anche nella figura 7:
- Il repository del codice sorgente viene copiato nell'ambiente di runtime di Cloud Build, nella directory
/workspace. - Esegui test delle unità e di integrazione.
- (Facoltativo) Esegui l'analisi statica del codice utilizzando un analizzatore come Pylint.
- Se i test vengono superati, vengono create le immagini container Docker, una per ogni
componente della pipeline. Le immagini sono taggate con il parametro
$COMMIT_SHA. - Le immagini container Docker vengono caricate in Artifact Registry (come mostrato nella figura 7).
- L'URL dell'immagine viene aggiornato in ciascuno dei file
component.yamlcon le immagini container Docker create e taggate. - Il workflow della pipeline viene compilato per produrre il file
pipeline.json. - Il file
pipeline.jsonviene caricato su Artifact Registry. - (Facoltativo) Esegui la pipeline con i valori dei parametri nell'ambito di un test di integrazione o di un'esecuzione di produzione. La pipeline eseguita genera un nuovo modello e potrebbe anche eseguirne il deployment come API su Vertex AI Inference.
Per un esempio di MLOps end-to-end pronto per la produzione che include CI/CD utilizzando Cloud Build, consulta Vertex Pipelines End-to-end Samples su GitHub.
Ulteriori considerazioni
Quando configuri l'architettura CI/CD ML su Google Cloud, considera quanto segue:
- Per l'ambiente di data science, puoi utilizzare una macchina locale o un Vertex AI Workbench.
- Puoi configurare la pipeline Cloud Build automatizzata in modo da ignorare i trigger, ad esempio se vengono modificati solo i file di documentazione o se vengono modificati i notebook di sperimentazione.
- Puoi eseguire la pipeline per i test di integrazione e regressione come
test di build. Prima che la pipeline venga eseguita il deployment nell'ambiente di destinazione, puoi utilizzare il metodo
wait()per attendere il completamento dell'esecuzione della pipeline inviata. - In alternativa all'utilizzo di Cloud Build, puoi utilizzare altri sistemi di build come Jenkins. Un deployment pronto all'uso di Jenkins è disponibile su Google Cloud Marketplace.
- Puoi configurare la pipeline in modo che venga eseguito il deployment automaticamente in diversi ambienti, tra cui sviluppo, test e gestione temporanea, in base a diversi trigger. Inoltre, puoi eseguire il deployment in ambienti specifici manualmente, ad esempio pre-produzione o produzione, in genere dopo aver ottenuto l'approvazione di una release. Puoi avere più routine di build per trigger diversi o per ambienti di destinazione diversi.
- Puoi utilizzare Apache Airflow, un framework di orchestrazione e pianificazione molto diffuso, per i flussi di lavoro di uso generale, che puoi eseguire utilizzando il servizio Cloud Composer completamente gestito.
- Quando esegui il deployment di una nuova versione del modello in produzione, esegui il deployment come canary per farti un'idea delle sue prestazioni (utilizzo di CPU, memoria e disco). Prima di configurare il nuovo modello per gestire tutto il traffico live, puoi anche eseguire test A/B. Configura il nuovo modello in modo che gestisca il 10-20% del traffico live. Se il nuovo modello ha un rendimento migliore di quello attuale, puoi configurarlo in modo che gestisca tutto il traffico. In caso contrario, il sistema di pubblicazione esegue il rollback al modello corrente.
Passaggi successivi
- Scopri di più sulla distribuzione continua in stile GitOps con Cloud Build.
- Per una panoramica dei principi e dei consigli architetturali specifici per i workload di AI e ML in Google Cloud, consulta la prospettiva AI e ML nel framework Well-Architected.
- Per ulteriori architetture di riferimento, diagrammi e best practice, esplora il Cloud Architecture Center.
Collaboratori
Autori:
- Ross Thomson | Cloud Solutions Architect
- Khalid Salama | Staff Software Engineer, Machine Learning
Altro collaboratore: Wyatt Gorman | HPC Outbound Product Manager