
BigQuery
From cloud data warehouse to an AI-ready data platform
BigQuery is a fully managed, AI-ready data analytics platform that helps you maximize value from your data and is designed to be multi-engine, multi-format, and multi-cloud.
Store 10 GiB of data and run up to 1 TiB of queries for free per month. New customers also get $300 in free credits to try BigQuery and other Google Cloud products.

Features
Gemini in BigQuery for an AI-powered assistive experience
BigQuery provides a single, unified workspace that includes a SQL, a notebook and a NL-based canvas interface for data practitioners of various coding skills to simplify analytics workflows from data ingestion and preparation to data exploration and visualization to ML model creation and use. Gemini in BigQuery provides AI-powered assistive and collaboration features including code assist, visual data preparation, and intelligent recommendations that help enhance productivity and optimize costs.
Bring multiple engines to a single copy of data
Serverless Apache Spark is available directly in BigQuery. You can write and execute Spark in BigQuery Studio without exporting data or managing infrastructure. BigQuery metastore provides shared runtime metadata for SQL and open source engines for a unified set of security and governance controls across all engines and storage types. By bringing multiple engines, including SQL, Spark and Python, to a single copy of data and metadata, you can break down data silos and increase efficiency.
Manage all data types and open formats
Customers use BigQuery to manage all data types across clouds, structured and unstructured, with fine grained access controls. Support for open table formats gives you the flexibility to use existing open source and legacy tools while getting the benefits of an integrated data platform. BigLake, BigQuery’s storage engine, lets you have a common way to work with data and makes open formats like Apache Iceberg, Delta, and Hudi available for governance and performance acceleration.
Built-in machine learning
BigQuery ML provides built-in capabilities to create and run ML models for your BigQuery data. You can leverage a broad range of models for predictions, and access the latest Gemini models to derive insights from all data types and unlock generative AI tasks such as text summarization, text generation, multimodal embeddings, and vector search. It increases the model development speed by directly bringing ML to your data and eliminating the need to move data from BigQuery.
Built-in data governance
Data governance is built into BigQuery, including full integration of Dataplex capabilities such as a unified metadata catalog, data quality, lineage, and profiling. Customers can use rich AI-driven metadata search and discovery capabilities for assets including dataset schemas, notebooks and reports, public and commercial dataset listings, and more. BigQuery users can also use governance rules to manage policies on BigQuery object tables.
Enterprise capabilities
BigQuery continues to build new enterprise capabilities. Cross-region disaster recovery provides managed failover in the unlikely event of a regional disaster as well as data backup and recovery features to help you recover from user errors. BigQuery operational health monitoring provides organization-wide views of your BigQuery operational environment. BigQuery Migration Services provides a comprehensive collection of tools for migrating to BigQuery from legacy or cloud data warehouses.
Real-time analytics with streaming data pipelines
BigQuery can ingest streaming data and make it immediately available to query and integrate to streaming products, like Dataflow. BigQuery BI Engine is an in-memory analysis service that offers sub-second query response time and high concurrency. Accelerate query performance and reduce costs within BigQuery with materialized views. Continuous queries is a new BigQuery feature that unlocks continuous analytical processing through a SQL statement to fuel event-driven applications.
With built-in business intelligence, create and share insights in a few clicks with Looker Studio or build data-rich experiences that go beyond BI with Looker. Analyze billions of rows of live BigQuery data in Google Sheets with familiar tools, like pivot tables, charts, and formulas, to easily derive insights from big data with Connected Sheets.
How It Works
BigQuery's serverless architecture lets you use SQL queries to analyze your data. You can store and analyze your data within BigQuery or use BigQuery to assess your data where it lives. To test how it works for yourself, query data—without a credit card—using the BigQuery sandbox.
Common Uses
Data warehouse migration
Migrate data warehouses to BigQuery
Migrate data warehouses to BigQuery
Solve for today’s analytics demands and seamlessly scale your business by moving to Google Cloud’s enterprise data warehouse. Streamline your migration path from Netezza, Oracle, Redshift, Teradata, or Snowflake to BigQuery using the free and fully managed BigQuery Migration Service.

Tutorials, quickstarts, & labs
Migrate data warehouses to BigQuery
Migrate data warehouses to BigQuery
Solve for today’s analytics demands and seamlessly scale your business by moving to Google Cloud’s enterprise data warehouse. Streamline your migration path from Netezza, Oracle, Redshift, Teradata, or Snowflake to BigQuery using the free and fully managed BigQuery Migration Service.
Transfer data into BigQuery
Bring any data into BigQuery
Bring any data into BigQuery
Make analytics easier by bringing together data from multiple sources into BigQuery. You can upload data files from local sources, Google Drive, or Cloud Storage buckets, use BigQuery Data Transfer Service (DTS), Cloud Data Fusion plugins, replicate data from relational databases with Datastream for BigQuery, or leverage Google's industry-leading data integration partnerships.

Tutorials, quickstarts, & labs
Bring any data into BigQuery
Bring any data into BigQuery
Make analytics easier by bringing together data from multiple sources into BigQuery. You can upload data files from local sources, Google Drive, or Cloud Storage buckets, use BigQuery Data Transfer Service (DTS), Cloud Data Fusion plugins, replicate data from relational databases with Datastream for BigQuery, or leverage Google's industry-leading data integration partnerships.
Generative AI
Unlock generative AI use cases with BigQuery and Gemini models
Unlock generative AI use cases with BigQuery and Gemini models
Build data pipelines that blend structured data, unstructured data and generative AI models together to create a new class of analytical applications. BigQuery integrates with Gemini 1.0 Pro using Vertex AI. The Gemini 1.0 Pro model is designed for higher input/output scale and better result quality across a wide range of tasks like text summarization and sentiment analysis. You can now access it using simple SQL statements or BigQuery’s embedded DataFrame API from right inside the BigQuery console.
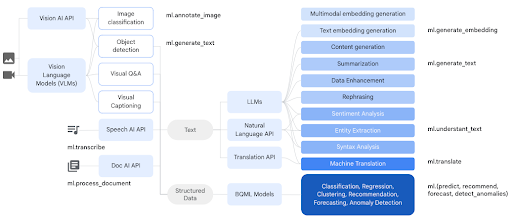
Tutorials, quickstarts, & labs
Unlock generative AI use cases with BigQuery and Gemini models
Unlock generative AI use cases with BigQuery and Gemini models
Build data pipelines that blend structured data, unstructured data and generative AI models together to create a new class of analytical applications. BigQuery integrates with Gemini 1.0 Pro using Vertex AI. The Gemini 1.0 Pro model is designed for higher input/output scale and better result quality across a wide range of tasks like text summarization and sentiment analysis. You can now access it using simple SQL statements or BigQuery’s embedded DataFrame API from right inside the BigQuery console.
Unlock value from all data types
Derive insights from images, documents, and audio files and combine with structured data
Derive insights from images, documents, and audio files and combine with structured data
Unstructured data represents a large portion of untapped enterprise data. However, it can be challenging to interpret, making it difficult to extract meaningful insights from it. Leveraging the power of BigLake, you can derive insights from images, documents, and audio files using a broad range of AI models including Vertex AI’s vision, document processing, and speech-to-text APIs, open-source TensorFlow Hub models, or your own custom models.
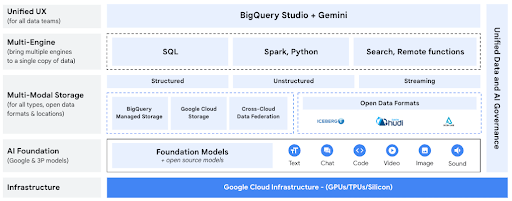
Tutorials, quickstarts, & labs
Derive insights from images, documents, and audio files and combine with structured data
Derive insights from images, documents, and audio files and combine with structured data
Unstructured data represents a large portion of untapped enterprise data. However, it can be challenging to interpret, making it difficult to extract meaningful insights from it. Leveraging the power of BigLake, you can derive insights from images, documents, and audio files using a broad range of AI models including Vertex AI’s vision, document processing, and speech-to-text APIs, open-source TensorFlow Hub models, or your own custom models.
Real-time analytics
Event-driven analysis
Event-driven analysis
Gain a competitive advantage by responding to business events in real time with event-driven analysis. Built-in streaming capabilities automatically ingest streaming data and make it immediately available to query. This allows you to stay agile and make business decisions based on the freshest data. Or use Dataflow to enable fast, simplified streaming data pipelines for a comprehensive solution.

Tutorials, quickstarts, & labs
Event-driven analysis
Event-driven analysis
Gain a competitive advantage by responding to business events in real time with event-driven analysis. Built-in streaming capabilities automatically ingest streaming data and make it immediately available to query. This allows you to stay agile and make business decisions based on the freshest data. Or use Dataflow to enable fast, simplified streaming data pipelines for a comprehensive solution.
Predictive analytics
Predict business outcomes with leading AI/ML
Predict business outcomes with leading AI/ML
Predictive analytics can be used to streamline operations, boost revenue, and mitigate risk. BigQuery ML democratizes the use of ML by empowering data analysts to build and run models using existing business intelligence tools and spreadsheets. Predictive analytics can guide business decision-making across the organization.

Tutorials, quickstarts, & labs
Predict business outcomes with leading AI/ML
Predict business outcomes with leading AI/ML
Predictive analytics can be used to streamline operations, boost revenue, and mitigate risk. BigQuery ML democratizes the use of ML by empowering data analysts to build and run models using existing business intelligence tools and spreadsheets. Predictive analytics can guide business decision-making across the organization.
Log analytics
Analyze log data
Analyze log data
Analyze and gain deeper insights into your logging data with BigQuery. You can store, explore, and run queries on generated data from servers, sensors, and other devices simply using GoogleSQL. Additionally, you can analyze log data alongside the rest of your business data for broader analysis all natively within BigQuery.
Tutorials, quickstarts, & labs
Analyze log data
Analyze log data
Analyze and gain deeper insights into your logging data with BigQuery. You can store, explore, and run queries on generated data from servers, sensors, and other devices simply using GoogleSQL. Additionally, you can analyze log data alongside the rest of your business data for broader analysis all natively within BigQuery.
Marketing analytics
Increase marketing ROI and performance with data and AI
Increase marketing ROI and performance with data and AI
Bring the power of Google AI to your marketing data by unifying marketing and business data sources in BigQuery. Get a holistic view of the business, increase marketing ROI and performance using more first-party data, and deliver personalized and targeting marketing at scale with ML/AI built-in. Share insights and performance with Looker Studio or Connected Sheets.
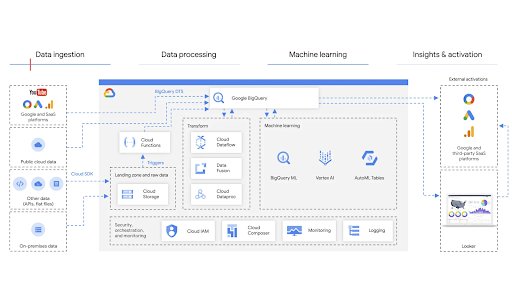
Tutorials, quickstarts, & labs
Increase marketing ROI and performance with data and AI
Increase marketing ROI and performance with data and AI
Bring the power of Google AI to your marketing data by unifying marketing and business data sources in BigQuery. Get a holistic view of the business, increase marketing ROI and performance using more first-party data, and deliver personalized and targeting marketing at scale with ML/AI built-in. Share insights and performance with Looker Studio or Connected Sheets.
Data clean rooms
BigQuery data clean rooms for privacy-centric data sharing
BigQuery data clean rooms for privacy-centric data sharing
Create a low-trust environment for you and your partners to collaborate without copying or moving the underlying data right within BigQuery. This allows you to perform privacy-enhancing transformations in BigQuery SQL interfaces and monitor usage to detect privacy threats on shared data. Benefit from BigQuery scale without needing to manage any infrastructure and built-in BI and AI/ML.
Tutorials, quickstarts, & labs
BigQuery data clean rooms for privacy-centric data sharing
BigQuery data clean rooms for privacy-centric data sharing
Create a low-trust environment for you and your partners to collaborate without copying or moving the underlying data right within BigQuery. This allows you to perform privacy-enhancing transformations in BigQuery SQL interfaces and monitor usage to detect privacy threats on shared data. Benefit from BigQuery scale without needing to manage any infrastructure and built-in BI and AI/ML.
Pricing
| How BigQuery pricing works | BigQuery pricing is based on compute (analysis), storage, additional services, and data ingestion and extraction. Loading and exporting data are free. | |
|---|---|---|
| Services and usage | Subscription type | Price (USD) |
Free tier | The BigQuery free tier gives customers 10 GiB storage, up to 1 TiB queries free per month, and other resources. | Free |
Compute (analysis) | On-demand Generally gives you access to up to 2,000 concurrent slots, shared among all queries in a single project. | Starting at $6.25 per TiB scanned. First 1 TiB per month is free. |
Standard edition Low-cost option for standard SQL analysis | $0.04 per slot hour | |
Enterprise edition Supports advanced enterprise analytics | $0.06 per slot hour | |
Enterprise Plus edition Supports mission-critical enterprise analytics | $0.10 per slot hour | |
Storage | Active local storage Based on the uncompressed bytes used in tables or table partitions modified in the last 90 days. | Starting at $0.02 Per GiB. The first 10 GiB is free each month. |
Long-term logical storage Based on the uncompressed bytes used in tables or table partitions modified for 90 consecutive days. | Starting at $0.01 Per GiB. The first 10 GiB is free each month. | |
Active physical storage Based on the compressed bytes used in tables or table partitions modified for 90 consecutive days. | Starting at $0.04 Per GiB. The first 10 GiB is free each month. | |
Long-term physical storage Based on compressed bytes in tables or partitions that have not been modified for 90 consecutive days. | Starting at $0.02 Per GiB. The first 10 GiB is free each month. | |
Data ingestion | Batch loading Import table from Cloud Storage | Free When using the shared slot pool |
Streaming inserts You are charged for rows that are successfully inserted. Individual rows are calculated using a 1 KB minimum. | $0.01 per 200 MiB | |
BigQuery Storage Write API Data loaded into BigQuery, is subject to BigQuery storage pricing or Cloud Storage pricing. | $0.025 per 1 GiB. The first 2 TiB per month are free. | |
Data extraction | Batch export Export table data to Cloud Storage. | Free When using the shared slot pool |
Streaming reads Use the storage Read API to perform streaming reads of table data. | Starting at $1.10 per TiB read | |
Learn more about BigQuery pricing. View all pricing details
How BigQuery pricing works
BigQuery pricing is based on compute (analysis), storage, additional services, and data ingestion and extraction. Loading and exporting data are free.
Free tier
The BigQuery free tier gives customers 10 GiB storage, up to 1 TiB queries free per month, and other resources.
Free
Compute (analysis)
On-demand
Generally gives you access to up to 2,000 concurrent slots, shared among all queries in a single project.
Starting at
$6.25
per TiB scanned. First 1 TiB per month is free.
Standard edition
Low-cost option for standard SQL analysis
$0.04
per slot hour
Enterprise edition
Supports advanced enterprise analytics
$0.06
per slot hour
Enterprise Plus edition
Supports mission-critical enterprise analytics
$0.10
per slot hour
Storage
Active local storage
Based on the uncompressed bytes used in tables or table partitions modified in the last 90 days.
Starting at
$0.02
Per GiB. The first 10 GiB is free each month.
Long-term logical storage
Based on the uncompressed bytes used in tables or table partitions modified for 90 consecutive days.
Starting at
$0.01
Per GiB. The first 10 GiB is free each month.
Active physical storage
Based on the compressed bytes used in tables or table partitions modified for 90 consecutive days.
Starting at
$0.04
Per GiB. The first 10 GiB is free each month.
Long-term physical storage
Based on compressed bytes in tables or partitions that have not been modified for 90 consecutive days.
Starting at
$0.02
Per GiB. The first 10 GiB is free each month.
Data ingestion
Batch loading
Import table from Cloud Storage
Free
When using the shared slot pool
Streaming inserts
You are charged for rows that are successfully inserted. Individual rows are calculated using a 1 KB minimum.
$0.01
per 200 MiB
BigQuery Storage Write API
Data loaded into BigQuery, is subject to BigQuery storage pricing or Cloud Storage pricing.
$0.025
per 1 GiB. The first 2 TiB per month are free.
Data extraction
Batch export
Export table data to Cloud Storage.
Free
When using the shared slot pool
Streaming reads
Use the storage Read API to perform streaming reads of table data.
Starting at
$1.10
per TiB read
Learn more about BigQuery pricing. View all pricing details
Pricing calculator
Custom quote
Start your proof of concept
New customers get $300 in free credits to try BigQuery and other Google Cloud products
Try BigQuery sandbox without a credit card
Learn how to locate and query public datasets in BigQuery
Learn how to load data into BigQuery
Learn how to create and use tables in BigQuery
Partners & Integration
Work with a partner with BigQuery expertise



































































































ETL and data integration
Reverse ETL and MDM
BI and data visualization
Data governance and security
Connectors and developer tools
Machine learning and advanced analytics
Data Quality and Observability
Consulting partners
From data ingestion to visualization, many partners have integrated their data solutions with BigQuery. Listed above are partner integrations through Google Cloud Ready - BigQuery.
Visit our partner directory to learn about these BigQuery partners.
FAQ
What makes BigQuery different from other enterprise data warehouse alternatives?
BigQuery is Google Cloud’s fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform.
What is an enterprise data warehouse?
An enterprise data warehouse is a system used for the analysis and reporting of structured and semi-structured data from multiple sources. Many organizations are moving from traditional data warehouses that are on-premises to cloud data warehouses, which provide more cost savings, scalability, and flexibility.
How secure is BigQuery?
BigQuery offers robust security, governance, and reliability controls that offer high availability and a 99.99% uptime SLA. Your data is protected with encryption by default and customer-managed encryption keys.
How can I get started with BigQuery?
There are a few ways to get started with BigQuery. New customers get $300 in free credits to spend on BigQuery. All customers get 10 GB storage and up to 1 TB queries free per month, not charged against their credits. You can get these credits by signing up for the BigQuery free trial. Not ready yet? You can use the BigQuery sandbox without a credit card to see how it works.
What is the BigQuery sandbox?
The BigQuery sandbox lets you try out BigQuery without a credit card. You stay within BigQuery’s free tier automatically, and you can use the sandbox to run queries and analysis on public datasets to see how it works. You can also bring your own data into the BigQuery sandbox for analysis. There is an option to upgrade to the free trial where new customers get a $300 credit to try BigQuery.
What are the most common ways companies use BigQuery?
Companies of all sizes use BigQuery to consolidate siloed data into one location so you can perform data analysis and get insights from all of your business data. This allows companies to make decisions in real time, streamline business reporting, and incorporate machine learning into data analysis to predict future business opportunities.












