Neste documento, descrevemos várias maneiras de implementar a multilocação no Spanner. Nele, também abordamos padrões de gerenciamento de dados e gerenciamento do ciclo de vida do locatário.
Multilocação é quando uma única instância, ou algumas instâncias, de um aplicativo de software atende a vários locatários ou clientes. Esse padrão de software pode ser escalonado de um único locatário ou cliente para centenas ou milhares. Essa abordagem é fundamental para as plataformas de computação em nuvem em que a infraestrutura subjacente é compartilhada entre várias organizações.
Pense na multilocação como uma forma de particionamento com base em recursos de computação compartilhados, como bancos de dados. Uma analogia são locatários em um prédio de apartamentos: infraestrutura compartilhada, mas espaço dedicado a locatários. A multilocação faz parte da maioria dos aplicativos de software como serviço (SaaS, na sigla em inglês), se não de todos.
Este documento é destinado a arquitetos de bancos de dados, arquitetos de dados e engenheiros que implementam aplicativos multilocatários no Spanner como banco de dados relacional. Usando esse contexto, ele descreve várias abordagens para armazenar dados multilocatários. Os termos "locatário", "cliente" e "organização" são usados alternadamente em todo o artigo para indicar a entidade que está acessando o aplicativo multilocatário.
Neste artigo, usamos um provedor de SaaS de recursos humanos (RH) que implementa um aplicativo multilocatário em Google Cloud como exemplo. No exemplo, vários clientes do provedor de SaaS de RH precisam acessar o aplicativo multilocatário. Esses clientes são chamados de locatários.
O Spanner é o banco de dados totalmente gerenciado, distribuído, de nível empresarial e consistente do Google Cloudque combina os benefícios do modelo de banco de dados relacional com a escalonabilidade horizontal não relacional. O Spanner tem semânticas relacionais, com esquemas, tipos de dados aplicados, consistência forte, transações ACID com várias instruções e uma linguagem de consulta SQL que implementa o ANSI 2011 SQL.
Com o Spanner, não há tempo de inatividade para manutenção planejada nem falhas de região e ele oferece um SLA de disponibilidade de 99,999%. Ele fornece suporte a aplicativos modernos multilocatários oferecendo alta disponibilidade e escalonabilidade. Neste artigo, discutimos as diferentes abordagens de arquitetura para implementar a multilocação com o Spanner.
Critérios para critérios de mapeamento de dados de locatários
Em um aplicativo multilocatário, os dados de cada locatário ficam isolados em uma das várias abordagens de arquitetura no banco de dados subjacente do Spanner. A lista a seguir descreve as diferentes abordagens de arquitetura usadas para mapear os dados de um locatário no Spanner:
- Instância: um locatário reside exclusivamente em uma instância do Spanner, com exatamente um banco de dados para esse locatário.
- Banco de dados: um locatário reside em um banco de dados em uma única instância do Spanner que contém vários bancos de dados.
- Esquema: um locatário reside em tabelas exclusivas dentro de um banco de dados, e vários locatários podem estar localizados no mesmo banco de dados.
- Tabela: os dados do locatário são linhas nas tabelas do banco de dados. Essas tabelas são compartilhadas com outros locatários.
Os critérios anteriores são chamados de padrões de gerenciamento de dados e são discutidos em detalhes na seção Padrões de gerenciamento de dados de multilocação. Essa discussão é baseada nos seguintes critérios:
- Isolamento: o grau de isolamento de dados em vários locatários é uma grande consideração para a multilocação. O isolamento é determinado pelas opções feitas para os critérios em outras categorias. Por exemplo, determinados requisitos regulamentares e de conformidade podem ditar um grau maior de isolamento.
- Agilidade: a facilidade de integração e suspensão das atividades para um locatário em relação à criação de uma instância, banco de dados ou tabela.
- Operações: a disponibilidade ou a complexidade da implementação de atividades típicas e específicas de locatário do banco de dados e atividades de administração, como manutenção regular, geração de registros, backups ou operações de recuperação de desastres.
- Escala: capacidade de escalonamento contínuo para permitir o crescimento futuro. A descrição de cada padrão contém o número de locatários que o padrão suporta.
- Desempenho:a capacidade de alocar recursos exclusivos para cada locatário, lidar com o fenômeno do vizinho barulhento e oferecer desempenho previsível de leitura e gravação para cada locatário.
- Regulamentos e conformidade: a capacidade de atender aos requisitos de setores e países altamente regulamentados que exigem o isolamento completo de recursos e operações de manutenção, por exemplo, os requisitos de residência de dados para a França exigem que as informações de identificação pessoal sejam armazenadas fisicamente e exclusivamente na França.
Cada padrão de gerenciamento de dados relacionado a esses critérios é detalhado na próxima seção. Use os mesmos critérios ao selecionar um padrão de gerenciamento de dados para um conjunto específico de locatários.
Padrões de gerenciamento de dados de multilocação
Nas seções a seguir, descrevemos os quatro principais padrões de gerenciamento de dados: instância, banco de dados, esquema e tabela.
Instância
Para fornecer isolamento completo, o padrão de gerenciamento de dados de instância armazena os dados de cada locatário em sua própria instância e banco de dados do Spanner. Uma instância do Spanner pode ter um ou mais bancos de dados. Neste padrão, apenas um banco de dados é criado. Para o aplicativo de RH discutido anteriormente, uma instância separada do Spanner com um banco de dados é criada para cada organização de cliente.
Conforme visto no diagrama a seguir, o padrão de gerenciamento de dados tem um locatário por instância.
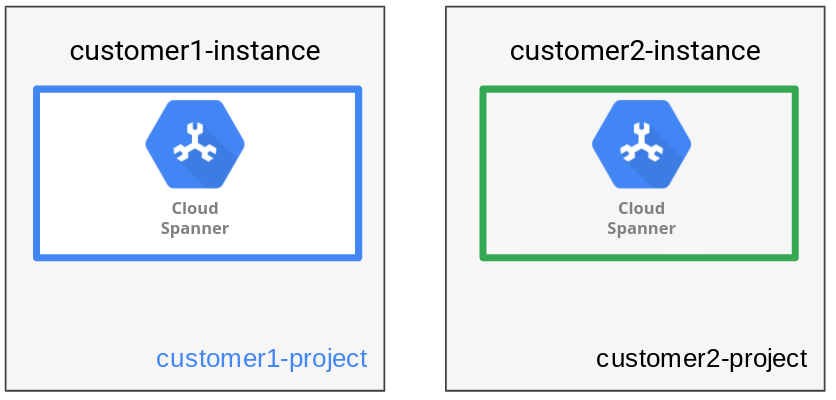
Ter instâncias separadas para cada locatário permite o uso de projetos separados do Google Cloud para atingir limites de confiança separados para diferentes locatários. Um benefício adicional é a opção de escolha de cada configuração de instância com base na localização de cada locatário (regional ou multirregional), otimizando a flexibilidade e o desempenho do local.
A arquitetura pode ser escalonada facilmente para qualquer número de locatários. Os provedores de SaaS podem criar qualquer número de instâncias nas regiões desejadas, sem limites absolutos.
Na tabela a seguir, descrevemos como o padrão de gerenciamento de dados de instância afeta critérios diferentes.
| Critério | Instância: um locatário por padrão de gerenciamento de dados de instância |
|---|---|
| Isolamento |
|
| Agilidade |
|
| Operações |
|
| Escala |
|
| Desempenho |
|
| Requisitos regulatórios e de conformidade |
|
Em resumo, os principais pontos são:
- Vantagem: nível mais alto de isolamento
- Desvantagem: a maior sobrecarga operacional
O padrão de gerenciamento de dados da instância é mais adequado nos seguintes cenários:
- Locatários diferentes distribuídos em uma ampla variedade de regiões e que precisam de uma solução localizada.
- Requisitos regulatórios e de conformidade para alguns locatários que exigem níveis mais altos de segurança e protocolos de auditoria.
- O tamanho do locatário varia muito, de modo que o compartilhamento de recursos entre locatários de alto volume e alto tráfego pode causar contenção e degradação mútua.
Banco de dados
No padrão de gerenciamento de dados do banco de dados, cada locatário reside em um banco de dados em uma única instância do Spanner. Vários bancos de dados podem residir em uma única instância. Se uma instância for insuficiente para o número de locatários, crie várias instâncias. Esse padrão implica que uma única instância do Spanner é compartilhada entre vários locatários.
O Spanner tem um limite absoluto de 100 bancos de dados por instância. Esse limite significa que, se o provedor de SaaS precisar escalonar mais de 100 clientes, ele precisará criar e usar várias instâncias do Spanner.
Para o aplicativo de RH, o provedor de SaaS cria e gerencia cada locatário com um banco de dados separado em uma instância do Spanner.
Conforme visto no diagrama a seguir, o padrão de gerenciamento de dados tem um locatário por banco de dados.
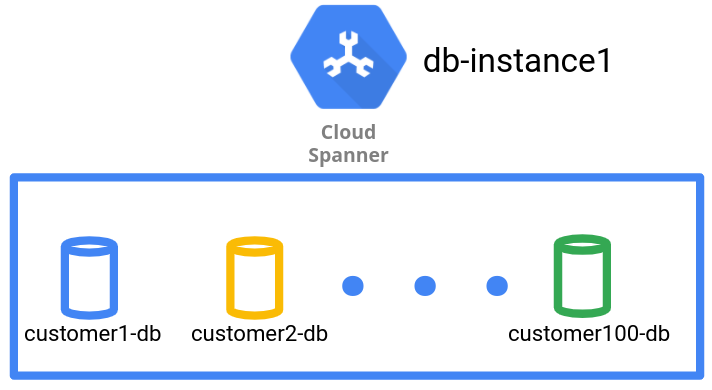
O padrão de gerenciamento de dados do banco de dados alcança o isolamento lógico no nível do banco de dados para diferentes locatários. No entanto, como se trata de uma instância única do Spanner, todos os bancos de dados de locatário compartilham a mesma configuração regional e configuração de computação e armazenamento subjacente.
Na tabela a seguir, descrevemos como o padrão de gerenciamento de dados do banco de dados afeta diferentes critérios.
| Critério | Banco de dados: um locatário por padrão de gerenciamento de dados do banco de dados |
|---|---|
| Isolamento |
|
| Agilidade |
|
| Operações |
|
| Escala |
|
| Desempenho |
|
| Requisitos regulatórios e de conformidade |
|
Em resumo, os principais pontos são:
- Vantagem: nível de isolamento mais alto
- Desvantagem: número limitado de locatários por instância e inflexibilidade do local
O padrão de gerenciamento de dados do banco de dados é mais adequado nos seguintes cenários:
- Vários clientes na mesma residência de dados, por exemplo, França ou Reino Unido, e/ou sob a mesma autoridade regulatória.
- Os locatários precisam de separação de dados baseada no sistema e de backup/restauração, mas são ajustados com o compartilhamento de recursos da infraestrutura.
Schema
No padrão de gerenciamento de dados de esquema, um único banco de dados, que implementa um
único esquema, é usado para vários locatários, e um conjunto separado de tabelas é usado
para os dados de cada locatário. Essas tabelas podem ser diferenciadas incluindo o
tenant ID nos nomes das tabelas como prefixo ou sufixo.
Esse padrão de gerenciamento de dados de uso de um conjunto separado de tabelas para cada locatário fornece um nível de isolamento muito menor em comparação às opções anteriores (os padrões de gerenciamento de instância e banco de dados). O padrão também simplifica a integração, que envolve a criação de novas tabelas e a integridade e índices referenciais associados.
Uma ressalva significativa é que as permissões de acesso do Spanner pelo Identity and Access Management (IAM) são fornecidas apenas no nível da instância ou do banco de dados. Não é possível fornecer permissões de acesso no nível da tabela. Há também um limite de 5.000 tabelas por banco de dados. Para muitos clientes, esse limite restringe o uso do aplicativo.
Além disso, o uso de tabelas separadas para cada cliente pode resultar em um grande backlog de operações de atualização de esquema. Esse backlog leva muito tempo para ser resolvido.
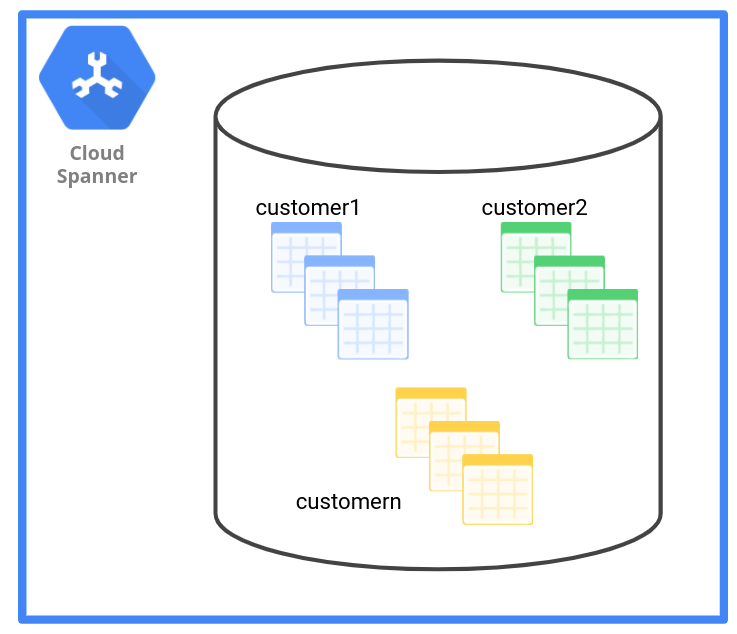
Para o aplicativo de RH, o provedor de SaaS pode criar um conjunto de tabelas para cada
cliente usando o tenant ID como prefixo nos nomes das tabelas. Por exemplo,
customer1_employee, customer1_payroll, customer1_department.
Conforme visto no diagrama abaixo, o padrão de gerenciamento de dados de esquema tem um conjunto de tabelas para cada locatário.
Veja na tabela abaixo como o padrão de gerenciamento de dados de esquema afeta diferentes critérios.
| Critério | Esquema: um conjunto de tabelas para cada padrão de gerenciamento de dados de locatário |
|---|---|
| Isolamento |
|
| Agilidade |
|
| Operações |
|
| Escala |
|
| Desempenho |
|
| Requisitos regulatórios e de conformidade |
|
Em resumo, os principais pontos são:
- Vantagem: integração simples
- Desvantagem: maior sobrecarga operacional. Sem controles de segurança no nível da tabela
O padrão de gerenciamento de dados de esquema é mais adequado nos seguintes cenários:
- Aplicativos internos que atendem a diferentes departamentos em que o isolamento rigoroso da segurança de dados não é uma grande preocupação em comparação com a facilidade de manutenção.
- Aplicativos multilocatários em que os dados não exigem separação rigorosa com base em requisitos legais ou regulamentares.
Embora seja possível criar vários conjuntos de tabelas (cada conjunto representando um locatário) em um banco de dados, esse é o padrão menos ideal de uma perspectiva de banco de dados. A principal razão é que as tabelas precisam seguir as convenções de nomenclatura. O aplicativo e todas as ferramentas de banco de dados, como o ambiente de desenvolvimento integrado e as ferramentas de migração de esquema, precisam entender a convenção de nomenclatura. Além disso, se o número de tabelas por locatário for razoavelmente grande, o padrão de gerenciamento de dados de esquema não fornecerá um escalonamento significativo.
Uma abordagem melhor é migrar para um banco de dados por locatário e aumentar o número de instâncias ou migrar para o padrão de gerenciamento de dados de tabela.
Tabela
O padrão final de gerenciamento de dados atende a vários locatários com um conjunto comum de
tabelas. Cada tabela contém dados para vários locatários. Esse padrão
de gerenciamento de dados representa um nível extremo de multilocação, em que tudo, da
infraestrutura ao esquema e modelo de dados, é compartilhado entre vários locatários. Em
uma tabela, as linhas são particionadas com base em chaves primárias, com tenant ID como o
primeiro elemento da chave. De uma perspectiva de escalonamento, o Spanner
é mais compatível com esse padrão, porque ele consegue escalonar tabelas sem limitação.
Para o aplicativo de RH, a chave primária da tabela de folha de pagamento pode ser uma combinação de
customerID e payrollID.
Conforme visto no diagrama abaixo, o padrão de gerenciamento de dados de tabela tem uma tabela para vários locatários.

Assim como no padrão de esquema, o acesso aos dados no padrão de tabela não pode ser controlado separadamente para locatários diferentes. Usar menos tabelas significa que as operações de atualização de esquema são concluídas mais rapidamente quando cada locatário tem as próprias tabelas de banco de dados. Em grande parte, essa abordagem simplifica a integração, suspensão e as operações.
A tabela a seguir descreve como o padrão de gerenciamento de dados de tabela afeta diferentes critérios.
| Critério | Tabela: uma tabela para vários padrões de gerenciamento de dados de locatários |
|---|---|
| Isolamento |
|
| Agilidade |
|
| Operações |
|
| Escala |
|
| Desempenho |
|
| Requisitos regulatórios e de conformidade |
|
Em resumo, os principais pontos são:
- Vantagem: altamente escalonável; baixa sobrecarga operacional
- Desvantagem: alta contenção de recursos; ausência de controles de segurança para cada locatário.
Esse padrão é mais adequado nos seguintes cenários:
- Aplicativos internos que atendem a diferentes departamentos em que o isolamento restrito de segurança de dados não é uma grande preocupação em comparação com a facilidade de manutenção.
- Compartilhamento máximo de recursos para locatários que usam a funcionalidade de aplicativo de nível gratuito ao minimizar o provisionamento de recursos ao mesmo tempo.
Padrões de gerenciamento de dados e gerenciamento do ciclo de vida do locatário
A tabela a seguir compara vários padrões de gerenciamento de dados em todos os critérios em um alto nível.
| Instância | Banco de dados | Schema | Tabela | |
|---|---|---|---|---|
| Isolamento | Concluído | Concluído | Baixa | Mais baixa |
| Agilidade | Baixa | Moderada | Moderada | Maior |
| Facilidade de operações | Alta | Alto | Baixo | Baixa |
| Escala | Alta | Limitado | Potencialmente muito limitada | Alta |
| Desempenho* | Alta | Moderada | Moderada | Potencialmente alto |
| Regulações e conformidade | Maior | Alta | Baixo | Baixo |
* O desempenho depende muito do design do esquema e das práticas recomendadas de consulta. Esses valores são apenas uma expectativa média.
Os melhores padrões de gerenciamento de dados para um aplicativo multilocatário específico são aqueles que atendem à maioria dos requisitos com base nos critérios. Se um critério específico não for necessário, ignore a linha em que ele está.
Padrões combinados de gerenciamento de dados
Muitas vezes, um único padrão de gerenciamento de dados é suficiente para atender aos requisitos de um aplicativo multilocatário. Nesse caso, o design pode assumir um único padrão de gerenciamento de dados.
No entanto, alguns aplicativos multilocatários exigem vários padrões de gerenciamento de dados ao mesmo tempo. Por exemplo, um aplicativo multilocatário compatível com nível gratuito, normal ou empresarial.
Nível gratuito:
- Precisa ser econômico
- Precisa ter um limite maior de volume de dados
- Geralmente compatível com funcionalidades limitadas
- O padrão de gerenciamento de dados de tabela é um bom candidato de nível gratuito
- O gerenciamento de locatários é simples
- Não é necessário criar recursos de locatário específicos ou exclusivos
Nível normal:
- Ideal para clientes pagantes que não têm requisitos de escalonamento ou isolamento específicos.
- O padrão de gerenciamento de dados de esquema e o padrão de gerenciamento de dados
do banco de dados são bons candidatos de nível normal
- Tabelas e índices são exclusivos para o locatário
- O backup é fácil no padrão de gerenciamento de dados do banco de dados
- O backup não é compatível com o padrão de gerenciamento de dados do esquema
- O backup de locatário precisa ser implementado como um utilitário fora do Spanner
Nível empresarial:
- Geralmente um nível sofisticado com autonomia total em todos os aspectos
- O locatário conta com recursos dedicados que incluem escalonamento dedicado e isolamento total
- O padrão de gerenciamento de dados de instância é adequado para o nível empresarial
Uma prática recomendada é manter diferentes padrões de gerenciamento de dados em diferentes bancos de dados. É possível combinar diferentes padrões de gerenciamento de dados em um banco de dados do Spanner, mas isso dificulta a implementação da lógica de acesso do aplicativo e das operações do ciclo de vida.
Na seção Design do aplicativo, fazemos algumas considerações sobre o design de aplicativos multilocatários que se aplicam ao usar um único padrão de gerenciamento de dados ou vários padrões.
Gerencie o ciclo de vida do locatário
Os locatários têm um ciclo de vida. Portanto, é preciso implementar as operações de gerenciamento correspondentes no aplicativo de multilocação. Além das operações básicas de criação, atualização e exclusão de locatários, considere as seguintes operações adicionais relacionadas a dados:
Exportar dados de locatários:
- Ao excluir um locatário, uma prática recomendada é exportar os dados primeiro e possivelmente disponibilizar o conjunto de dados para eles.
- Ao usar o padrão de gerenciamento de dados de tabela ou esquema, o sistema de aplicativos multilocatários precisa implementar a exportação ou mapeá-la para a funcionalidade do banco de dados (exportação de banco de dados).
Fazer backup de dados de locatários:
- Ao usar o padrão de gerenciamento de dados de instância ou banco de dados e fazer backup de dados para locatários individuais, use as funções de exportação ou backup do banco de dados.
- Ao usar o padrão de gerenciamento de dados de esquema ou tabela e fazer backup de dados para locatários individuais, o aplicativo multilocatário precisa implementar essa operação. O banco de dados do Spanner não é capaz de determinar quais dados pertencem a quais locatários.
Transferir dados de locatário:
A transferência de um locatário de um padrão de gerenciamento de dados para outro (ou a transferência de um locatário dentro do mesmo padrão de gerenciamento de dados entre instâncias ou bancos de dados) requer a extração dos dados do padrão de gerenciamento de dados de tabela e a inserção deles no padrão de gerenciamento de dados de banco de dados.
- Quando houver inatividade do aplicativo, execute uma exportação/importação.
- Quando não houver inatividade, execute uma migração do banco de dados sem inatividade.
Simular uma situação de vizinho barulhento é um outro motivo para transferir locatários.
Design do aplicativo
Ao projetar um aplicativo multilocatário, implemente a lógica de negócios de reconhecimento de locatários. Isso significa que sempre que o aplicativo executar a lógica de negócios, ele precisará estar sempre no contexto de um locatário conhecido.
Do ponto de vista do banco de dados, o design do aplicativo significa que cada consulta precisa ser executada no padrão de gerenciamento de dados no qual o locatário reside. Nas seções a seguir, destacamos alguns dos conceitos centrais do design de aplicativos multilocatários.
Conexão dinâmica de locatário e configuração de consultas
O mapeamento dinâmico de dados de locatário para solicitações do aplicativo de locatário usa uma configuração de mapeamento:
- Para padrões de gerenciamento de dados do banco de dados ou de instância, uma string de conexão é suficiente para acessar os dados de um locatário.
- Para padrões de gerenciamento de dados de esquema, é necessário determinar os nomes corretos das tabelas.
- No caso dos padrões de gerenciamento de dados de tabela, as consultas precisam ser executadas no banco de dados. Use os predicados apropriados para recuperar os dados de um locatário específico.
Um locatário pode residir em qualquer um dos quatro padrões de gerenciamento de dados. A implementação de mapeamento a seguir aborda uma configuração de conexão para o caso geral de um aplicativo multilocatário que usa todos os padrões de gerenciamento de dados ao mesmo tempo. Quando um determinado locatário reside em um padrão, alguns aplicativos multilocatários usam um padrão de gerenciamento de dados em todos eles. Esse caso é coberto implicitamente pelo seguinte mapeamento.
Se um locatário executar a lógica de negócios (por exemplo, um funcionário que faz login com o ID de locatário), a lógica do aplicativo precisará determinar o padrão de gerenciamento de dados do locatário, a localização dos dados de um determinado ID de locatário e, opcionalmente, a convenção de nomenclatura de tabelas (para o padrão do esquema).
Essa lógica de aplicativo requer o mapeamento do padrão de gerenciamento de locatário para dados. No
exemplo de código a seguir, connection string se refere ao banco de dados em que
estão os dados do locatário. O exemplo identifica a instância
do Spanner e o banco de dados. Para a instância e o banco de dados do padrão de gerenciamento de dados,
o código a seguir é suficiente para que o aplicativo se conecte e
execute consultas:
tenant id -> (data management pattern,
database connection string,
[table_prefix])
Um design adicional é necessário para os padrões de gerenciamento de dados de esquema e tabela.
Padrão de gerenciamento de dados de esquema
Para o padrão de gerenciamento de dados de esquema, há vários locatários no mesmo banco de dados. Cada locatário tem seu próprio conjunto de tabelas. As tabelas são separadas pelo nome de cada uma. A tabela que pertence ao locatário é determinística.
Uma abordagem é preceder os nomes da tabela com o ID do locatário. Por exemplo, a
tabela EMPLOYEE é chamada T356_EMPLOYEE para o locatário com o ID 356. O
aplicativo precisa preceder cada tabela com o prefixo
Ttenant ID antes de enviar a consulta ao banco de dados retornado pelo
mapeamento.
Outra abordagem é preceder o table_prefix para o mapeamento usado pela
consulta para encontrar as tabelas corretas de um locatário.
Uma abordagem mista também é possível: se o padrão de gerenciamento de dados for o padrão de esquema e o prefixo da tabela estiver vazio, o mapeamento padrão será aplicado (precedendo os nomes das tabelas com IDs de locatário).
Padrão de gerenciamento de dados de tabela
Um design semelhante é necessário para o padrão de gerenciamento de dados de tabela. Nesse padrão, há um único esquema. Os dados do locatário são armazenados como linhas. Para acessar os dados adequadamente, anexe um predicado a cada consulta para selecionar o locatário apropriado.
Uma abordagem para encontrar o locatário apropriado é ter uma coluna chamada TENANT
em cada tabela. O valor da coluna é tenant ID. Cada consulta precisa anexar um
predicado AND TENANT = tenant ID a uma cláusula WHERE atual ou adicionar uma
cláusula WHERE com o predicado AND TENANT = tenant ID.
Para se conectar ao banco de dados e criar as consultas apropriadas, o identificador de locatário precisa estar disponível na lógica do aplicativo. Ele pode ser transmitido como um parâmetro ou armazenado como contexto de thread.
Algumas operações de ciclo de vida exigem que você modifique a configuração de mapeamento do padrão de gerenciamento de locatário para dados. Por exemplo, ao transferir um locatário entre os padrões de gerenciamento de dados, você precisa atualizar esse padrão e a string de conexão do banco de dados. Talvez também seja necessário atualizar o prefixo da tabela.
Geração e atribuição de consultas
Um princípio fundamental e subjacente de aplicativos multilocatários é que vários locatários podem compartilhar um único recurso de nuvem. Os padrões de gerenciamento de dados anteriores se enquadram nessa categoria, exceto quando um único locatário é alocado em uma única instância do Spanner.
O compartilhamento de recursos vai além do compartilhamento de dados. O monitoramento e a geração de registros também são compartilhados. Por exemplo, no padrão de gerenciamento de dados de tabela e de esquema, todas as consultas de todos os locatários são registradas no mesmo registro de auditoria.
Se uma consulta for registrada, o texto dela precisará ser examinado para determinar para qual locatário a consulta foi executada. No padrão de gerenciamento de dados de tabela, você precisa analisar o predicado. No padrão de gerenciamento de dados de esquema, é necessário analisar um dos nomes da tabela.
No padrão de gerenciamento de dados de banco de dados ou no padrão de gerenciamento de dados da instância, o texto da consulta não apresenta informações de locatário. Para obter informações de locatário para esses padrões, é necessário consultar a tabela de mapeamento tenant-to-data-management-pattern.
Seria mais fácil analisar registros e consultas determinando o locatário de uma
determinada consulta sem analisar o texto da consulta. Uma maneira de identificar uniformemente um
locatário para uma consulta em todos os padrões de gerenciamento de dados é adicionar um comentário ao
texto da consulta que tem o tenant ID e, opcionalmente, um label.
A consulta a seguir seleciona todos os dados do funcionário para o locatário identificado por
TENANT 356. Para evitar a análise da sintaxe SQL e extrair o ID de locatário do
predicado, o ID do locatário é adicionado como um comentário. É possível extrair um comentário
sem ter que analisar a sintaxe SQL.
select * from EMPLOYEE
-- TENANT 356
where TENANT = 'T356';
ou
select * from T356_EMPLOYEE;
-- TENANT 356
Com esse design, cada consulta executada para um locatário é atribuída a ele, independentemente do padrão de gerenciamento de dados. Se um locatário for transferido de um padrão de gerenciamento de dados para outro, o texto da consulta poderá mudar, mas a atribuição permanecerá a mesma no texto da consulta.
O exemplo de código anterior é apenas um método. Outro método é inserir um objeto JSON como um comentário em vez de um rótulo e um valor:
select * from T356_EMPLOYEE;
-- {"TENANT": 356}
Operações de ciclo de vida de acesso de locatários
Dependendo da filosofia de design, um aplicativo multilocatário pode implementar diretamente as operações de ciclo de vida dos dados descritas anteriormente ou criar uma ferramenta separada de administração de locatários.
Independentemente da estratégia de implementação, as operações de ciclo de vida podem precisar ser executadas sem a lógica do aplicativo em execução ao mesmo tempo. Por exemplo, ao transferir um locatário de um padrão de gerenciamento de dados para outro, a lógica do aplicativo não pode ser executada porque os dados não estão em um único banco de dados. Quando os dados não estão em um único banco de dados, eles exigem duas outras operações do ponto de vista do aplicativo:
- Como interromper um locatário: desativa todo o acesso à lógica do aplicativo ao permitir operações do ciclo de vida dos dados.
- Como iniciar um locatário: a lógica do aplicativo pode acessar os dados de um locatário enquanto as operações do ciclo de vida que interfeririam na lógica do aplicativo são desativadas.
Embora não seja usada com frequência, uma desativação de emergência do locatário pode ser outra operação importante do ciclo de vida. Use-a ao suspeitar de uma violação e impeça todo o acesso aos dados de um locatário, não apenas a lógica do aplicativo, mas as operações do ciclo de vida também. Uma violação pode se originar dentro ou fora do banco de dados.
Uma operação de ciclo de vida correspondente que remove o status de emergência também precisa estar disponível. Essa operação pode exigir que dois ou mais administradores façam login ao mesmo tempo, para implementar um controle mútuo.
Isolamento de aplicativos
Os vários padrões de gerenciamento de dados são compatíveis com diferentes graus do isolamento de dados de locatário. Do nível mais isolado (instância) ao nível menos isolado (tabela), diferentes graus de isolamento são possíveis.
No contexto de um aplicativo multilocatário, é necessário tomar uma decisão de implantação semelhante: todos os locatários acessam os dados (possivelmente em padrões diferentes de gerenciamento de dados) usando a mesma implantação do aplicativo? Por exemplo, um único cluster do Kubernetes pode aceitar todos os locatários e, quando um locatário acessar os dados, o mesmo cluster executará a lógica de negócios.
Como no caso dos padrões de gerenciamento de dados, locatários diferentes podem ser direcionados para implantações de aplicativo diferentes. Locatários grandes podem ter acesso a uma implantação de aplicativo exclusiva, enquanto locatários menores ou no nível gratuito compartilham uma implantação de aplicativo.
Em vez de corresponder diretamente aos padrões de gerenciamento de dados discutidos neste artigo com padrões equivalentes de gerenciamento de dados de aplicativos, é possível usar o padrão de gerenciamento de dados do banco de dados para que todos os locatários compartilhem uma única implantação de aplicativo. É possível fazer com que o padrão de gerenciamento de dados de banco de dados e todos esses locatários compartilhem uma única implantação de aplicativo.
A multilocação é um padrão importante de gerenciamento de dados de design de aplicativo, especialmente quando a eficiência dos recursos tem um papel fundamental. O Spanner é compatível com vários padrões de gerenciamento de dados: use-o para implementar aplicativos multilocatários. Com uma escalabilidade extrema e SLAs rigorosos, o Spanner é um banco de dados ideal para grandes implantações de aplicativos multilocatários.
A seguir
- Confira arquiteturas de referência, diagramas, tutoriais e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.