Ce document décrit plusieurs façons de mettre en œuvre une architecture mutualisée dans Spanner. Il traite également des modèles de gestion des données et de la gestion du cycle de vie des locataires.
On appelle multi-tenancy une architecture dans laquelle une seule instance (quelques instances tout au plus) d'une application logicielle dessert plusieurs locataires ou clients. Ce modèle logiciel peut passer d'un locataire ou d'un client unique à des centaines, voire des milliers. Cette approche est fondamentale pour les plates-formes de cloud computing où l'infrastructure sous-jacente est partagée par plusieurs organisations.
Considérez l'architecture mutualisée comme une forme de partitionnement basée sur des ressources informatiques partagées, telles que des bases de données. L'analogie est flagrante avec les locataires d'un immeuble d'habitation : l'infrastructure est partagée, mais chaque locataire dispose d'un espace dédié. L'architecture mutualisée fait partie intégrante de la plupart, pour ne pas dire de la totalité, des applications Software as a Service (SaaS).
Ce document est destiné aux architectes de bases de données, aux architectes de données et aux ingénieurs qui mettent en œuvre des applications mutualisées sur Spanner en guise de bases de données relationnelles. En se basant sur ce contexte, il décrit plusieurs approches permettant de stocker des données sur des architectures mutualisées. Les termes "Locataire", "Client" et "Organisation" sont utilisés indifféremment tout au long de l'article pour faire référence à l'entité qui accède à l'application mutualisée.
Cet article s'appuie sur l'exemple d'un fournisseur SaaS de solutions RH qui implémente son application mutualisée sur Google Cloud . Dans cet exemple, plusieurs clients du fournisseur SaaS de solutions RH doivent accéder à l'application mutualisée. Ces clients sont appelés "locataires".
Spanner est la base de données entièrement gérée, pensée pour les entreprises, distribuée et cohérente de Google Cloud, qui associe les avantages du modèle de base de données relationnelle à une évolutivité horizontale non relationnelle. Spanner possède une sémantique relationnelle, avec des schémas, des types de données appliqués, une cohérence forte, des transactions ACID multi-instructions et un langage de requête SQL mettant en œuvre la norme SQL ANSI 2011.
Spanner fait disparaître les temps d'arrêt pour les opérations de maintenance planifiées ou les défaillances de région, il est associé à un contrat de niveau de service garantissant une disponibilité de 99,999 %. Il est parfaitement adapté aux applications mutualisées modernes, car il offre à la fois haute disponibilité et évolutivité optimale. Cet article décrit les différentes approches architecturales permettant de mettre en œuvre une architecture mutualisée avec Spanner.
Critères de mappage des données des locataires
Dans une application mutualisée, les données de chaque locataire sont isolées par le biais de l'une des différentes approches architecturales existantes pour la base de données Spanner sous-jacente. La liste suivante décrit les différentes approches architecturales utilisées pour mapper les données d'un locataire sur Spanner :
- Instance : les données d'un locataire sont stockées sur une instance Spanner unique, qui ne contient que la base de données attribuée à ce locataire.
- Base de données : les données d'un locataire résident dans une base de données, sur une instance Spanner contenant plusieurs bases de données attribuées à différents locataires.
- Schéma : les données d'un locataire résident dans des tables dédiées/exclusives au sein d'une base de données, les données de plusieurs locataires peuvent se trouver dans la même base de données.
- Table : les données d'un locataire sont stockées dans des lignes de tables de base de données. Ces tables sont partagées avec d'autres locataires.
Les critères précédents sont appelés modèles de gestion des données et sont décrits en détail dans la section Modèles de gestion des données stockées sur des architectures mutualisées. Cette présentation est basée sur les critères suivants :
- Isolation : le degré d'isolation des données entre plusieurs locataires constitue un critère majeur pour une architecture mutualisée. L'isolation dépend des choix effectués pour les critères relevant d'autres catégories. Par exemple, certaines exigences réglementaires et de conformité peuvent imposer un degré d'isolation plus élevé.
- Agilité : facilité d'intégration et de suppression d'activités pour un locataire dans le cadre de la création d'une instance, d'une base de données ou d'une table.
- Opérations : disponibilité ou complexité de la mise en œuvre d'activités d'administration et d'opérations de base de données classiques spécifiques à chaque locataire (maintenance régulière, journalisation, sauvegardes ou opérations de reprise après sinistre, entre autres).
- Échelle : capacité à évoluer facilement pour faire face à la croissance future. La description de chaque modèle précise le nombre de locataires acceptés par le modèle.
- Performances:la capacité d'allouer des ressources exclusives à chaque locataire, de répondre au phénomène du voisin bruyant et d'offrir des performances prévisibles en lecture et en écriture pour chacun locataire.
- Réglementations et conformité : capacité à répondre aux exigences des secteurs et pays très réglementés, qui imposent l'isolation complète des ressources et des opérations de maintenance (par exemple, les exigences de résidence des données pour la France nécessitent que les informations personnelles soient stockées exclusivement sur le territoire français).
Chaque modèle de gestion des données en lien avec ces critères est détaillé dans la section suivante. Utilisez les mêmes critères lorsque vous sélectionnez un modèle de gestion des données pour un ensemble spécifique de locataires.
Modèles de gestion des données stockées sur des architectures mutualisées
Les sections suivantes décrivent les quatre principaux schémas de gestion des données : instance, base de données, schéma et table.
Instance
Pour assurer une isolation complète, le modèle de gestion des données de type "Instance" stocke les données de chaque locataire dans sa propre instance et sa propre base de données Spanner. Une instance Spanner peut comporter une ou plusieurs bases de données. Dans ce modèle, une seule base de données est créée. Pour l'application RH évoquée précédemment, une instance Spanner distincte avec une base de données est créée pour chaque organisation cliente.
Comme le montre le schéma suivant, le modèle de gestion des données attribue une instance à chaque locataire.
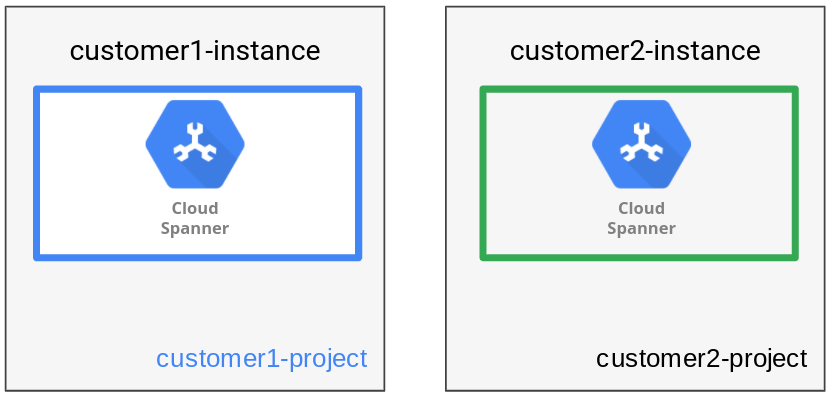
Le fait de disposer d'une instance distincte pour chaque locataire permet d'utiliser des projets Google Cloud distincts afin de définir des limites de confiance spécifiques à chacun des locataires. Autre avantage : chaque configuration d'instance peut être choisie en fonction de l'emplacement du locataire concerné (emplacement régional ou multirégional), ce qui permet d'optimiser la flexibilité et les performances de la solution.
L'architecture peut facilement évoluer pour accepter n'importe quel nombre de locataires. Les fournisseurs SaaS peuvent créer autant d'instances que nécessaire dans les régions souhaitées, sans limite stricte.
Le tableau suivant décrit l'impact du modèle de gestion des données de type "Instance" sur différents critères.
| Critères | Instance : modèle de gestion des données "Un locataire par instance" |
|---|---|
| Isolation |
|
| Agilité |
|
| Opérations |
|
| Effectuer le scaling |
|
| Performances |
|
| Exigences réglementaires et de conformité |
|
Pour résumer, les points clés à retenir sont les suivants :
- Avantage : niveau d'isolation le plus élevé
- Inconvénient : coûts opérationnels les plus importants
Le modèle de gestion des données de type "Instance" est le mieux adapté aux scénarios suivants :
- Différents locataires sont répartis sur un large éventail de régions et requièrent une solution localisée.
- Les exigences réglementaires et de conformité pour certains locataires nécessitent des niveaux de sécurité plus élevés et des protocoles d'audit plus stricts.
- La "taille" des locataires varie considérablement, de sorte que le partage de ressources entre des locataires à fort volume de trafic peut entraîner des conflits de ressources et une dégradation de performances mutuelle.
Base de données
Dans le modèle de gestion des données de type "Base de données", les données de chaque locataire résident dans une base de données spécifique au sein d'une instance Spanner unique. Plusieurs bases de données peuvent résider dans une seule instance. Si une instance est insuffisante pour le nombre de locataires, créez plusieurs instances. Ce modèle implique qu'une instance Spanner unique soit partagée entre plusieurs locataires.
Spanner est soumis à une limite stricte de 100 bases de données par instance. Cette limite signifie que si le fournisseur SaaS doit évoluer au-delà de 100 clients, il doit créer et utiliser plusieurs instances Spanner.
Pour l'application RH, le fournisseur SaaS crée et gère chaque locataire avec une base de données distincte dans une instance Spanner.
Comme le montre le schéma suivant, le modèle de gestion de données associe un locataire à chaque base de données.
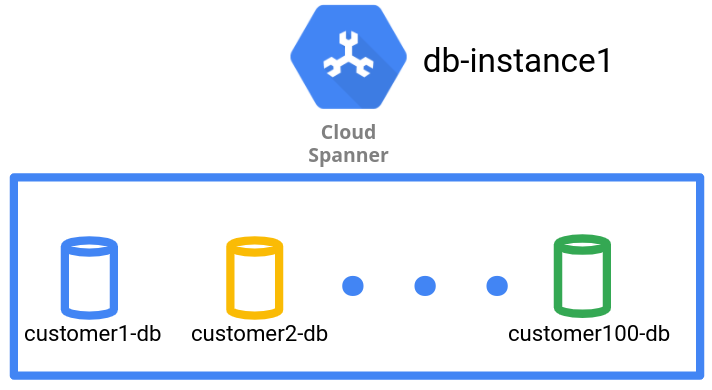
Le modèle de gestion des données de type "Base de données" permet d'obtenir une isolation logique au niveau des bases de données pour les données de différents locataires. Toutefois, comme il s'agit d'une instance Spanner unique, toutes les bases de données locataires partagent la même configuration régionale, et la même configuration de calcul et de stockage sous-jacente.
Le tableau suivant décrit l'impact du modèle de gestion des données de type "Base de données" sur différents critères.
| Critères | Base de données : modèle de gestion des données "Un locataire par base de données" |
|---|---|
| Isolation |
|
| Agilité |
|
| Opérations |
|
| Effectuer le scaling |
|
| Performances |
|
| Exigences réglementaires et de conformité |
|
Pour résumer, les points clés à retenir sont les suivants :
- Avantage : niveau d'isolation supérieur
- Inconvénient : nombre limité de locataires par instance et pas de flexibilité pour les emplacements
Le modèle de gestion des données de type "Base de données" est le mieux adapté aux scénarios suivants :
- Plusieurs clients partagent une même résidence de données (par exemple, en France ou au Royaume-Uni), et/ou dépendent de la même autorité réglementaire.
- Les locataires nécessitent une séparation des données et une sauvegarde/restauration au niveau du système, mais ne voient aucun inconvénient à partager les ressources d'infrastructure.
Schéma
Dans le modèle de gestion des données de type "Schéma", une base de données unique, qui met en œuvre un seul schéma, est utilisée pour plusieurs locataires. Un ensemble distinct de tables est utilisé pour les données de chaque locataire. Il est possible de différencier ces tables en incluant le tenant ID dans les noms de tables en tant que préfixe ou suffixe.
Ce modèle de gestion des données, qui utilise un ensemble de tables distinct pour chaque locataire, offre un niveau d'isolation bien inférieur à celui des options précédentes (modèles de gestion de type "Instance" et "Base de données"). En revanche, il facilite l'intégration, car il implique la création de tables, ainsi que l'application de l'intégrité référentielle et la génération des index associés.
Il convient de noter que les autorisations d'accès pour Spanner accordées via Identity and Access Management (IAM) ne le sont qu'au niveau de l'instance ou de la base de données. Il est impossible d'accorder des autorisations d'accès au niveau de la table. Notez également qu'il existe une limite de 5 000 tables par base de données. Pour de nombreux clients, cette limite représente un frein à leur utilisation de l'application.
De plus, l'utilisation de tables distinctes pour chaque client peut entraîner une accumulation d'opérations de mise à jour du schéma. Un tel volume d'opérations peut nécessiter beaucoup de temps.
Pour l'application RH, le fournisseur SaaS peut créer un ensemble de tables pour chaque client, en ajoutant le préfixe tenant ID dans les noms de table (par exemple, customer1_employee, customer1_payroll, customer1_department).
Comme le montre le schéma suivant, le modèle de gestion des données de type "Schéma" attribue un ensemble de tables à chaque locataire.
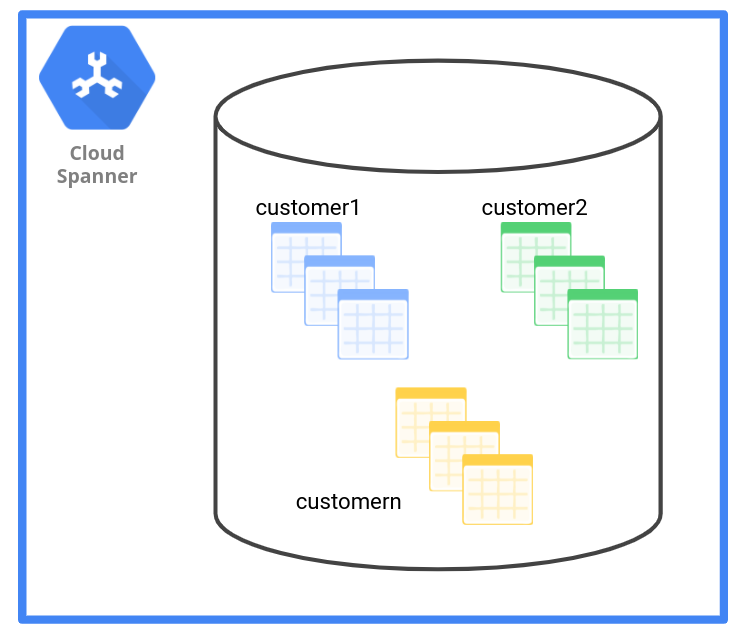
Le tableau suivant décrit l'impact du modèle de gestion des données de type "Schéma" sur différents critères.
| Critères | Schéma : modèle de gestion des données "Un ensemble de tables pour chaque locataire" |
|---|---|
| Isolation |
|
| Agilité |
|
| Opérations |
|
| Effectuer le scaling |
|
| Performances |
|
| Exigences réglementaires et de conformité |
|
Pour résumer, les points clés à retenir sont les suivants :
- Avantage : intégration très simple
- Inconvénient : coûts opérationnels plus élevés et aucun contrôle de sécurité au niveau des tables
Le modèle de gestion des données de type "Schéma" est le mieux adapté aux scénarios suivants :
- Les applications internes qui correspondent à différents services de l'entreprise, dans lesquelles l'isolation stricte et la sécurité des données ne sont pas prépondérantes par rapport à la facilité de maintenance.
- Les applications mutualisées ne nécessitant pas une séparation stricte des données du fait d'exigences légales ou réglementaires spécifiques.
Bien qu'il soit possible de créer plusieurs ensembles de tables (chaque ensemble représentant un locataire) dans une base de données, il s'agit du modèle le moins idéal en ce qui concerne les bases de données. Cela est principalement dû au fait que les tables doivent respecter des conventions de nommage. L'application et tout outil de base de données (par exemple, l'IDE utilisé et les outils de migration de schéma) doivent comprendre la convention de nommage. En outre, si le nombre de tables par locataire est assez conséquent, le modèle de gestion des données de type "Schéma" n'offre pas des capacités de scaling très importantes.
Une meilleure approche consiste à passer à une base de données pour chaque locataire et à augmenter le nombre d'instances, ou à passer au modèle de gestion des données de type "Table".
Table
Le dernier modèle de gestion des données dessert plusieurs locataires avec un ensemble commun de tables. Chaque table contient les données de plusieurs locataires. Ce modèle de gestion des données représente un niveau extrême d'architecture mutualisée dans lequel tous les éléments, de l'infrastructure au schéma de données, sont partagés entre plusieurs locataires. Dans une table, les lignes sont partitionnées en fonction de clés primaires, le tenant ID étant le premier élément de la clé. Du point de vue de l'évolutivité, Spanner offre une meilleure compatibilité avec ce modèle, car il permet une mise à l'échelle des tables sans aucune limitation.
Pour l'application de RH, la clé primaire de la table "fiche de salaire" peut être une combinaison de customerID et payrollID.
Comme le montre le schéma suivant, le modèle de gestion des données de type "Table" associe une table unique à plusieurs locataires.

Comme pour le modèle "Schéma", l'accès aux données dans le modèle "Table" ne peut pas être contrôlé séparément pour différents locataires. Si vous utilisez moins de tables, les opérations de mise à jour du schéma sont plus rapides lorsque chaque locataire dispose de ses propres tables de base de données. Dans une large mesure, cette approche simplifie l'intégration, la suppression et les opérations.
Le tableau suivant décrit l'impact du modèle de gestion des données de type "Table" sur différents critères.
| Critères | Table : modèle de gestion des données "Une table pour plusieurs locataires" |
|---|---|
| Isolation |
|
| Agilité |
|
| Opérations |
|
| Effectuer le scaling |
|
| Performances |
|
| Exigences réglementaires et de conformité |
|
Pour résumer, les points clés à retenir sont les suivants :
- Avantage : modèle hautement évolutif présentant des coûts opérationnels faibles
- Inconvénient : risque important de conflits de ressources et impossibilité d'appliquer des contrôles de sécurité spécifiques à chaque locataire
Ce modèle est particulièrement adapté aux scénarios suivants :
- Les applications internes qui correspondent à différents services de l'entreprise, dans lesquelles l'isolation stricte et la sécurité des données ne sont pas prépondérantes par rapport à la facilité de maintenance.
- Partage maximal des ressources pour les locataires souhaitant utiliser la fonctionnalité d'application gratuite tout en limitant le provisionnement de ressources.
Modèles de gestion des données et gestion du cycle de vie des locataires
Le tableau suivant présente une vue d'ensemble des performances des différents modèles de gestion des données pour tous les critères mentionnés précédemment.
| Instance | Base de données | Schéma | Table | |
|---|---|---|---|---|
| Isolation | Terminé | Terminé | Faible | Le plus faible |
| Agilité | Faible | Moyenne | Moyenne | La plus élevée |
| Facilité d'utilisation | Élevé | Élevée | Faible | Faible |
| Évoluer | Élevé | Limitée | Potentiellement très limitée | Élevé |
| Performances* | Élevé | Moyenne | Moyenne | Potentiellement élevées |
| Réglementations et conformité | La plus élevée | Élevé | Faible | Faible |
* Les performances dépendent fortement de la conception du schéma et des bonnes pratiques relatives aux requêtes. Les valeurs indiquées ici ne représentent qu'une estimation moyenne.
Les meilleurs modèles de gestion de données pour une application mutualisée spécifique sont ceux qui répondent à la plupart des exigences de cette application en fonction des critères retenus. Si un critère particulier n'est pas requis, vous pouvez ignorer la ligne dans laquelle il se trouve.
Modèles de gestion des données combinés
En général, un modèle de gestion des données unique suffit pour répondre aux exigences d'une application mutualisée. En pareil cas, il est possible de prendre en compte un seul modèle de gestion des données dans le cadre de la conception.
Certaines applications mutualisées nécessitent l'utilisation simultanée de plusieurs modèles de gestion des données. Cela peut être le cas pour une application mutualisée offrant une version gratuite, un niveau standard et un niveau entreprise.
Version gratuite :
- Cette version doit être économique.
- Un volume de données maximum doit être défini.
- En général, certaines fonctionnalités sont limitées.
- Le modèle de gestion des données de type "Table" est un bon candidat pour une version gratuite.
- La gestion des locataires est simple.
- Il n'est pas nécessaire de créer des ressources locataires spécifiques ou exclusives.
Niveau standard :
- Ce niveau convient aux clients payants qui n'ont pas d'exigences fortes en matière de scaling ou d'isolation.
- Les modèles de gestion des données de type "Schéma" et "Base de données" sont de bons candidats pour le niveau standard.
- Les tables et les index sont exclusivement réservés au locataire.
- La sauvegarde est facile dans le modèle de gestion des données de type "Base de données".
- La sauvegarde n'est pas disponible pour le modèle de gestion des données de type "Schéma".
- La sauvegarde des données locataire doit être mise en œuvre via un utilitaire externe à Spanner.
Niveau Entreprise :
- Il s'agit généralement d'un niveau "haut de gamme" offrant une autonomie complète sur tous les aspects.
- Le locataire dispose de ressources dédiées, parmi lesquelles des capacités de scaling spécifiques et une isolation intégrale.
- Le modèle de gestion des données de type "Instance" convient parfaitement pour le niveau Entreprise.
Il est recommandé d'utiliser des bases de données différentes pour exploiter différents modèles de gestion des données. Bien qu'il soit possible de combiner différents modèles de gestion de données dans une même base de données Spanner, il est en pratique difficile de mettre en œuvre la logique d'accès et les opérations du cycle de vie d'une application.
La section Conception d'applications décrit certaines considérations relatives à la conception d'applications mutualisées qui s'appliquent en cas d'utilisation d'un modèle de gestion des données unique ou de plusieurs modèles de gestion des données.
Gérer le cycle de vie des locataires
Les locataires ont un cycle de vie. Par conséquent, vous devez mettre en œuvre les opérations de gestion correspondantes au sein de votre application mutualisée. Au-delà des opérations de base permettant de créer, mettre à jour et supprimer des locataires, envisagez la mise en œuvre des opérations supplémentaires liées aux données présentées ci-dessous :
Exportation des données des locataires :
- Lorsque vous supprimez un locataire, il est recommandé d'exporter ses données dans un premier temps, puis éventuellement de mettre l'ensemble de données à disposition du locataire.
- Lorsque vous utilisez le modèle de gestion des données de type "Table" ou "Schéma", le système d'application mutualisée doit mettre en œuvre l'exportation ou assurer un mappage avec la fonctionnalité de base de données correspondante (exportation de la base de données).
Sauvegarde des données des locataires :
- Lorsque vous utilisez le modèle de gestion des données de type "Instance" ou "Base de données" et que vous souhaitez sauvegarder des données pour des locataires individuels, utilisez les fonctions d'exportation ou de sauvegarde de l'application de base de données.
- Lorsque vous utilisez le modèle de gestion des données de type "Schéma" ou "Table" et que vous souhaitez sauvegarder des données pour des locataires individuels, l'application mutualisée doit mettre en œuvre cette opération. La base de données Spanner ne peut pas déterminer quelles données appartiennent à quel locataire.
Déplacer les données des locataires :
Déplacer les données d'un locataire d'un modèle de gestion de données à un autre (ou déplacer les données d'un locataire au sein du même modèle de gestion de données entre instances ou bases de données) nécessite d'extraire les données du modèle de gestion des données "Table", puis de les insérer dans le modèle de gestion des données "Base de données".
- Lorsqu'un temps d'arrêt de l'application est envisageable, effectuez une exportation/importation.
- Lorsque cela n'est pas possible, effectuez une migration de base de données sans temps d'arrêt.
Limiter les problèmes de "voisins bruyants" est un autre motif de déplacement des données de locataires.
Conception d'applications
Lorsque vous créez une application mutualisée, mettez en œuvre une logique métier axée sur le locataire. Concrètement, cela signifie que chaque fois que l'application exécute une logique métier, elle doit le faire dans le contexte d'un locataire connu.
Du point de vue de la base de données, l'application doit être conçue de sorte que chaque requête soit exécutée en fonction du modèle de gestion de données qui héberge les données du locataire. Les sections suivantes mettent en évidence certains concepts essentiels de la conception d'applications mutualisées.
Configuration dynamique des connexions et des requêtes des locataires
Le mappage dynamique des données de locataires sur des requêtes d'applications mutualisées utilise une configuration de mappage :
- Pour les modèles de gestion de données de type "Base de données" ou "Instance", une chaîne de connexion suffit pour l'accès aux données d'un locataire.
- Pour les modèles de gestion de données de type "Schéma", les noms de table corrects doivent être déterminés.
- Pour les modèles de gestion de données de type "Table", les requêtes doivent être exécutées sur la base de données. Utilisez les prédicats appropriés pour récupérer les données d'un locataire spécifique.
Les données d'un locataire peuvent résider dans n'importe lequel des quatre modèles de gestion des données. La mise en œuvre de mappage suivante concerne une configuration de connexion dans le cas général d'une application mutualisée qui utilise tous les modèles de gestion de données en même temps. Lorsque les données d'un locataire donné résident dans un modèle, certaines applications mutualisées utilisent le même modèle de gestion de données pour tous les locataires. Ce cas est traité implicitement par le mappage suivant.
Si un locataire exécute une logique métier (par exemple, un employé qui se connecte avec son ID de locataire), la logique d'application doit déterminer le modèle de gestion des données du locataire, l'emplacement des données pour un ID de locataire donné et, éventuellement, la convention de nommage de table (pour le modèle "Schéma").
Cette logique d'application nécessite un mappage de type "locataire / modèle de gestion de données". Dans l'exemple de code suivant, connection string fait référence à la base de données où résident les données du locataire. L'exemple identifie l'instance Spanner et la base de données. Pour les modèles de gestion de données de type "Instance" et "Base de données", le code suivant est suffisant pour permettre à l'application de se connecter et d'exécuter des requêtes :
tenant id -> (data management pattern,
database connection string,
[table_prefix])
Une conception supplémentaire est nécessaire pour les modèles de gestion de données de type "Schéma" et "Table".
Modèle de gestion des données de type "Schéma"
Pour le modèle de gestion des données "Schéma", plusieurs locataires partagent la même base de données. Chaque locataire dispose de son propre ensemble de tables. Les tables sont différenciées par leur nom. On ne peut déterminer directement à quel locataire appartient telle ou telle table.
Une approche consiste à ajouter l'ID du locataire en tant que préfixe aux noms de tables. Par exemple, la table EMPLOYEE est nommée T356_EMPLOYEE pour le locataire ayant l'ID 356. L'application doit ajouter le préfixe Ttenant ID à chaque table avant d'envoyer la requête à la base de données renvoyée par le mappage.
Une autre approche consiste à ajouter un préfixe table_prefix au mappage utilisé par la requête, afin que les tables appropriées pour un locataire soient bien identifiées par celle-ci.
Une approche mixte est également possible : si le modèle de gestion de données est le modèle de type "Schéma" et que le préfixe de la table est vide, le mappage par défaut est employé (les ID de locataires sont ajoutés en tant que préfixes aux noms de tables).
Modèle de gestion des données de type "Table"
Une conception similaire est requise pour le modèle de gestion des données de type "Table". Dans ce modèle, il existe un seul schéma. Les données des locataires sont stockées sous forme de lignes. Pour pouvoir accéder aux données, ajoutez un prédicat à chaque requête afin de sélectionner le locataire approprié.
Pour identifier le locataire approprié, il est possible de créer une colonne appelée TENANT dans chaque table. La valeur de la colonne est tenant ID. Chaque requête doit ajouter un prédicat AND TENANT = tenant ID à une clause WHERE existante ou ajouter une clause WHERE avec le prédicat AND TENANT = tenant ID.
Pour qu'il soit possible de se connecter à la base de données et de créer les requêtes appropriées, l'identifiant du locataire doit être disponible dans la logique d'application. Cet identifiant peut être transmis en tant que paramètre ou stocké en tant que contexte de thread.
Certaines opérations de cycle de vie nécessitent que vous changiez la configuration du mappage "locataire / modèle de gestion de données". Par exemple, lorsque vous déplacez les données d'un locataire entre des modèles de gestion de données, vous devez mettre à jour le modèle de gestion de données associé au locataire et la chaîne de connexion à la base de données. Vous devrez peut-être également mettre à jour le préfixe de table.
Génération et attribution de requêtes
Un principe fondamental sous-jacent des applications mutualisées est que plusieurs locataires peuvent partager une même ressource cloud. Les modèles de gestion des données mentionnés précédemment relèvent de cette catégorie, sauf dans le cas où un seul locataire est associé à une instance Spanner unique.
Le partage des ressources ne se limite pas au partage du stockage de données. La surveillance et la journalisation sont également partagées. Par exemple, dans les modèles de gestion des données de type "Table" et "Schéma", toutes les requêtes de tous les locataires sont enregistrées dans le même journal d'audit.
Si une requête est consignée, il est nécessaire d'examiner le texte de la requête afin de déterminer le locataire pour lequel celle-ci a été exécutée. Dans le modèle de gestion des données de type "Table", vous devez analyser le prédicat. Dans le modèle de gestion des données de type "Schéma", vous devez analyser l'un des noms de table.
Dans les modèles de gestion des données de type "Base de données" et "Instance", le texte de la requête ne contient aucune information sur le locataire. Pour obtenir des informations sur les locataires pour ces modèles, vous devez interroger la table de mappage "locataire / modèle de gestion de données".
Il serait plus facile d'analyser les journaux et les requêtes en déterminant le locataire d'une requête donnée sans avoir à analyser le texte de la requête elle-même. Une méthode permettant d'identifier de manière uniforme un locataire pour une requête sur tous les modèles de gestion de données consiste à ajouter un commentaire contenant le tenant ID et éventuellement un libellé (label) dans le texte de la requête.
La requête suivante sélectionne toutes les données concernant les employés pour le locataire identifié par TENANT 356. Pour qu'il ne soit pas nécessaire d'analyser la syntaxe SQL et d'extraire l'ID de locataire du prédicat, l'ID du locataire est ajouté en tant que commentaire. Il est possible d'extraire un commentaire sans avoir à analyser la syntaxe SQL.
select * from EMPLOYEE
-- TENANT 356
where TENANT = 'T356';
ou
select * from T356_EMPLOYEE;
-- TENANT 356
Avec cette conception, chaque requête exécutée pour un locataire est attribuée à ce locataire, quel que soit le modèle de gestion de données. Si un locataire est "déplacé" d'un modèle de gestion de données à un autre, le texte de la requête peut changer, mais l'attribution reste la même dans le texte de la requête.
L'exemple de code précédent n'est qu'une méthode parmi d'autres. Il est également possible d'insérer un objet JSON en tant que commentaire, plutôt qu'un libellé et une valeur:
select * from T356_EMPLOYEE;
-- {"TENANT": 356}
Opérations du cycle de vie des accès de locataires
En fonction de votre philosophie de conception, une application mutualisée peut mettre en œuvre directement les opérations de cycle de vie des données décrites précédemment, ou créer un outil d'administration des locataires distinct.
Indépendamment de la stratégie de mise en œuvre, les opérations de cycle de vie peuvent devoir s'exécuter sans que la logique d'application soit exécutée en même temps. Par exemple, lors du déplacement d'un locataire d'un modèle de gestion de données à un autre, la logique d'application ne peut s'exécuter, car les données ne se trouvent pas dans une seule et même base de données. Lorsque les données ne se trouvent pas dans une seule base de données, deux opérations supplémentaires sont nécessaires du point de vue de l'application :
- Arrêter un locataire : désactive tous les accès de la logique d'application tout en autorisant les opérations du cycle de vie des données.
- Démarrer un locataire : la logique d'application peut accéder aux données d'un locataire, tandis que les opérations de cycle de vie qui pourraient interférer avec la logique de l'application sont désactivées.
Bien qu'il ne soit pas souvent utilisé, "l'arrêt d'urgence de locataire" peut constituer une autre opération de cycle de vie importante. Utilisez cet arrêt lorsque vous suspectez une violation de données et que vous devez interdire tous les accès aux données d'un locataire (pas seulement pour la logique d'application, mais également pour les opérations de cycle de vie des données). Une violation de données peut provenir de l'intérieur ou de l'extérieur de la base de données.
Une opération de cycle de vie associée permettant de supprimer l'état d'urgence doit également être disponible. Une telle opération peut nécessiter que plusieurs administrateurs se connectent simultanément pour mettre en œuvre un contrôle mutuel.
Isolement des applications
Les divers modèles de gestion des données acceptent différents degrés d'isolation des données de locataires. Du niveau le plus isolé (instance) au niveau le moins isolé (table), différents degrés d'isolation sont possibles.
Dans le contexte d'une application mutualisée, une décision de déploiement similaire doit être prise : tous les locataires accèdent-ils à leurs données (dans des modèles de gestion de données qui peuvent être différents) à l'aide du même déploiement d'application ? Par exemple, un cluster Kubernetes unique peut prendre en charge tous les locataires, et lorsqu'un locataire accède à ses données, le même cluster peut exécuter la logique métier.
Comme pour les modèles de gestion de données, il se peut aussi que différents locataires soient dirigés vers différents déploiements d'applications. Les locataires ayant de nombreux comptes utilisateur peuvent avoir accès à un déploiement d'application réservé, tandis que les locataires ayant moins de comptes ou ceux utilisant la version gratuite peuvent partager un déploiement d'application.
Au lieu de faire correspondre directement les modèles de gestion des données décrits dans cet article avec les modèles de gestion des données d'application équivalents, vous pouvez utiliser le modèle de gestion de données de type "Base de données" afin que tous les locataires partagent un seul et même déploiement d'application. Il est possible d'utiliser le modèle de gestion des données "Base de données" pour que tous les locataires partagent un même déploiement d'application.
L'architecture mutualisée est une solution "conception d'application / modèle de gestion des données" importante, en particulier lorsque l'efficacité des ressources est essentielle. Spanner est compatible avec plusieurs modèles de gestion de données. Vous pouvez l'utiliser pour mettre en œuvre des applications mutualisées. Grâce à son évolutivité extrême et à ses contrats de niveau de service rigoureux, Spanner est une base de données idéale pour les déploiements d'applications mutualisées destinées à de nombreux utilisateurs.
Étapes suivantes
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.