Der Explore-Abfrage-Tracker und der Bereich Explore-Leistung enthalten detaillierte Leistungsdaten für eine Explore-Abfrage. Anhand dieser Daten lassen sich wichtige Ausgangspunkte für die Fehlerbehebung und Lösung von Leistungsproblemen bei Abfragen ermitteln. Außerdem erhalten Sie Empfehlungen für Verbesserungen.
Abfrage-Tracker
Im Explore-Abfrage-Tracker wird der Fortschritt einer Explore-Abfrage während der Ausführung in den drei Phasen der Abfrage angezeigt.
![]()
Wenn die Ausführung einer Abfrage lange dauert, kann der Query Tracker angeben, welche Phase der Abfrage das Leistungsproblem verursacht. So lässt sich ermitteln, wo Leistungsprobleme auftreten können und wo Optimierungsmaßnahmen am effektivsten sind.
Der Abfrage-Tracker wird angezeigt, wenn ein Explore ausgeführt wird, sofern entweder der Bereich Explore-Visualisierung oder der Bereich Explore-Daten geöffnet ist.
Bereich Leistung
Wenn Sie das Explore-Feld Leistung aufrufen möchten, klicken Sie auf den Link Leistungsdetails ansehen, der für jede ausgeführte Explore-Abfrage verfügbar ist.

Im Bereich Leistung wird die Zeit angezeigt, die die Abfrage in den drei Abfragephasen verbracht hat. Außerdem sind Links zur Leistungsdokumentation und zum Dashboard „Systemaktivität“ enthalten, in dem aktuelle und bisherige Leistungsdaten für die Abfrage und den Explore angezeigt werden, mit dem die Abfrage erstellt wurde.
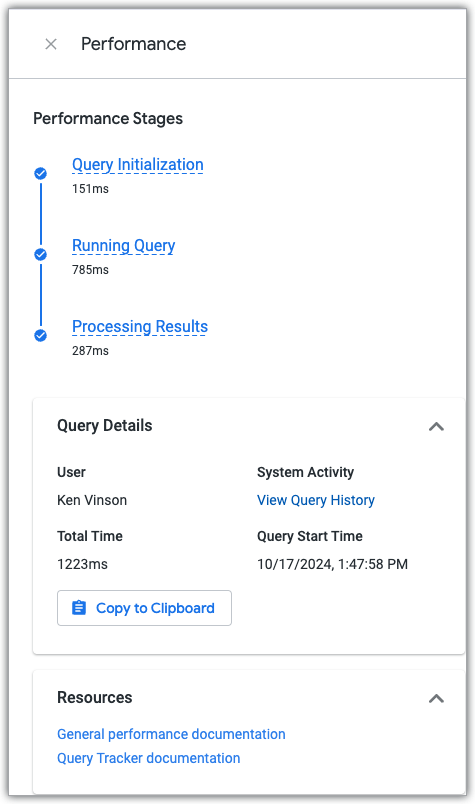
Abfragephasen
Wenn in einem Looker-Explore eine Datenbankabfrage ausgeführt wird, erfolgt dies in drei Phasen:
- Die Phase der Abfrageinitialisierung
- Die Phase der ausgeführten Abfrage
- Die Phase der Verarbeitungsergebnisse
Phase der Abfrageinitialisierung
Während der Phase Abfrageinitialisierung führt Looker alle Aufgaben aus, die erforderlich sind, bevor die Abfrage an Ihre Datenbank gesendet wird. Die Phase Abfrageinitialisierung umfasst die folgenden Aufgaben:
- LookML-Modell kompilieren
- Prüfen, ob persistente abgeleitete Tabellen (Persistent Derived Tables, PDTs) erstellt werden müssen
- SQL für die Abfrage generieren
- Datenbankverbindung abrufen
Auf der Dokumentationsseite Messwerte zur Abfrageleistung wird beschrieben, wie Sie die Explore-Funktion Messwerte zur Abfrageleistung in Systemaktivität verwenden, um detaillierte Aufschlüsselungen einer Abfrage aufzurufen. Die Phase Abfrageinitialisierung des Abfragetrackers umfasst die Ereignisse, die in den Phasen Asynchrone Worker-Phase, Initialisierungsphase und Phase für die Verarbeitung von Verbindungen des Explorers Messwerte zur Abfrageleistung beschrieben werden.
Phase „Abfrage wird ausgeführt“
In der Phase Abfrage wird ausgeführt kontaktiert Looker Ihre Datenbank, fragt sie ab und gibt die Ergebnisse der Abfrage zurück. Leistungsprobleme in dieser Phase können auf Probleme mit der externen Datenbank hinweisen, z. B. PDTs, deren Neuerstellung lange dauert und die möglicherweise optimiert werden müssen, oder externe Datenbanktabellen, die möglicherweise optimiert werden müssen. Die Phase Abfrage wird ausgeführt umfasst die folgenden Aufgaben:
- Erstellen aller PDTs in der Datenbank, die für die Explore-Abfrage erforderlich sind
- Die angeforderte Abfrage wird für die Datenbank ausgeführt.
Auf der Dokumentationsseite Messwerte zur Abfrageleistung wird beschrieben, wie Sie die Explore-Funktion Messwerte zur Abfrageleistung in Systemaktivität verwenden, um detaillierte Aufschlüsselungen einer Abfrage aufzurufen. Die Phase Abfrage wird ausgeführt des Abfrage-Trackers umfasst die Ereignisse, die in der Phase Hauptabfragen des Explore Leistungsmesswerte für Abfragen beschrieben werden.
Wenn in dieser Phase Leistungsprobleme auftreten, können Sie Folgendes tun:
- Erstellen Sie Explores nach Möglichkeit mit
many_to_one-Joins. Wenn Sie Ansichten von der detailliertesten bis zur höchsten Detailebene (many_to_one) zusammenführen, wird in der Regel die beste Abfrageleistung erzielt. - Maximieren Sie das Caching, um die Synchronisierung mit Ihren ETL-Richtlinien zu ermöglichen und den Datenbankabfrage-Traffic zu reduzieren. Standardmäßig speichert Looker Abfragen eine Stunde lang im Cache. Sie können die Caching-Richtlinie steuern und Looker-Datenaktualisierungen mit Ihrem ETL-Prozess synchronisieren, indem Sie Datengruppen in Explores mit dem Parameter
persist_withanwenden. Durch die Maximierung des Caching kann Looker enger in die Backend-Datenpipeline integriert werden. So kann die Cache-Nutzung maximiert werden, ohne dass das Risiko besteht, veraltete Daten zu analysieren. Benannte Caching-Richtlinien können auf ein gesamtes Modell oder auf einzelne Explores und abgeleitete Tabellen (Persistent Derived Tables, PDTs) angewendet werden. - Verwenden Sie die Funktion für die Aggregat-Erkennung von Looker, um Zusammenfassungs- oder Übersichtstabellen zu erstellen, die Looker nach Möglichkeit für Abfragen verwenden kann, insbesondere für häufige Abfragen großer Datenbanken. Sie können die Aggregatfunktion auch verwenden, um die Leistung ganzer Dashboards deutlich zu verbessern. Weitere Informationen finden Sie in der Anleitung zu aggregierten Daten.
- Verwenden Sie PDTs, um Abfragen zu beschleunigen. Konvertieren Sie Explores mit vielen komplexen oder leistungsschwachen Joins oder Dimensionen mit Unterabfragen oder Unterauswahlen in PDTs, damit die Ansichten vor der Laufzeit zusammengeführt und bereit sind.
- Wenn Ihr Datenbankdialekt inkrementelle PDTs unterstützt, konfigurieren Sie inkrementelle PDTs, um die Zeit zu verkürzen, die Looker für das Neuerstellen von PDT-Tabellen benötigt.
- Vermeiden Sie es, Ansichten in Explores mit verketteten Primärschlüsseln zu verbinden, die in Looker definiert sind. Verwenden Sie stattdessen die Basisfelder, aus denen der verkettete Primärschlüssel der Ansicht besteht. Alternativ können Sie die Ansicht als PDT neu erstellen, wobei der verkettete Primärschlüssel in der SQL-Definition der Tabelle und nicht im LookML einer Ansicht vordefiniert ist.
- Verwenden Sie das Tool „In SQL-Runner erklären“ für Benchmarking.
EXPLAINgibt einen Überblick über den Abfrageausführungsplan Ihrer Datenbank für eine bestimmte SQL-Abfrage und ermöglicht es Ihnen, Abfragekomponenten zu erkennen, die optimiert werden können. Weitere Informationen finden Sie im Communitybeitrag zum Optimieren von SQL mitEXPLAIN. - Indexe deklarieren Sie können sich die Indexe der einzelnen Tabellen direkt in Looker im SQL Runner ansehen. Klicken Sie dazu in einer Tabelle auf das Zahnradsymbol und wählen Sie dann Indexe anzeigen aus.
Die häufigsten Spalten, die von Indexen profitieren können, sind wichtige Datumsangaben und Fremdschlüssel. Wenn Sie diesen Spalten Indexe hinzufügen, wird die Leistung für fast alle Abfragen gesteigert. Dies gilt auch für PDTs. LookML-Parameter wie
indexes,sort keysunddistributionkönnen entsprechend angewendet werden.
Phase „Ergebnisse werden verarbeitet“
Während der Phase Ergebnisse werden verarbeitet verarbeitet und rendert Looker die Ergebnisse der Abfrage. Die Phase Verarbeitungsergebnisse umfasst die folgenden Aufgaben:
- Abfrageergebnisse in den Cache streamen
- Tabellenkalkulationen auflösen
- Ergebnisse der Liquid-Vorlagensprache formatieren
- Abfragen zusammenführen
- Gesamtsummen und Zwischensummen berechnen
Auf der Dokumentationsseite Messwerte zur Abfrageleistung wird beschrieben, wie Sie die Explore-Funktion Messwerte zur Abfrageleistung in Systemaktivität verwenden, um detaillierte Aufschlüsselungen einer Abfrage aufzurufen. Die Phase Ergebnisse werden verarbeitet des Abfrage-Trackers umfasst die Ereignisse, die in der Phase nach der Abfrage der Explore Messwerte zur Abfrageleistung beschrieben werden.
Wenn in dieser Phase Leistungsprobleme auftreten, können Sie Folgendes tun:
- Verwenden Sie Funktionen wie Ergebnisse zusammenführen, benutzerdefinierte Felder und Tabellenkalkulationen nur sparsam. Diese Funktionen sind als Proof of Concept gedacht, um Ihnen bei der Entwicklung Ihres Modells zu helfen. Es empfiehlt sich, alle häufig verwendeten Berechnungen und Funktionen in LookML fest zu codieren. Dadurch wird SQL generiert, das in Ihrer Datenbank verarbeitet werden kann. Zu viele Berechnungen können den Java-Arbeitsspeicher der Looker-Instanz beanspruchen und dazu führen, dass die Looker-Instanz langsamer reagiert.
- Beschränken Sie die Anzahl der Ansichten, die Sie in ein Modell einbeziehen, wenn eine große Anzahl von Ansichtsdateien vorhanden ist. Wenn Sie alle Ansichten in ein einziges Modell einbeziehen, kann sich die Leistung verlangsamen. Wenn ein Projekt eine große Anzahl von Ansichten enthält, sollten Sie in jedes Modell nur die Ansichtsdateien einbeziehen, die benötigt werden. Verwenden Sie strategische Namenskonventionen für Ansichtsdateinamen, damit Sie Gruppen von Ansichten in ein Modell einbeziehen können. Ein Beispiel finden Sie in der Dokumentation zum Parameter
includes. - Vermeiden Sie es, standardmäßig eine große Anzahl von Datenpunkten in Dashboardkacheln und Looks zurückzugeben. Abfragen, die Tausende von Datenpunkten zurückgeben, benötigen mehr Arbeitsspeicher. Sorgen Sie dafür, dass Daten nach Möglichkeit eingeschränkt werden, indem Sie Frontend-
Filter auf Dashboards, Looks und Explores anwenden und auf LookML-Ebene die Parameter
required filters,conditionally_filterundsql_always_whereverwenden. - Verwenden Sie die Option Alle Ergebnisse nur sparsam, um Abfragen herunterzuladen oder zu senden, da einige Abfragen sehr groß sein und den Looker-Server bei der Verarbeitung überlasten können.