This document describes best practices for designing access control and boundaries between workloads on Google Distributed Cloud (GDC) air-gapped. This document is intended for an architect or technical lead designing workloads on GDC who wants to balance efficient resource usage, isolation of workloads, and ease of operations.
GDC resource hierarchy overview
This section introduces key concepts of the resource hierarchy and how that hierarchy relates to access control in the GDC platform. For more information on the GDC resource hierarchy, see the Overview page.
GDC implements Kubernetes Role-Based Access Control (RBAC) but also has a unique resource model. Some aspects of the resource hierarchy are relevant for any workload type, and some aspects like Kubernetes clusters are only required for Kubernetes-based workloads. If you are deploying only virtual machine (VM) based workloads, you can skip the sections related to nodes and cluster design.
Logical view of resources
This section introduces the GDC resource hierarchy of organizations and projects and the logical relationship between resources. The purpose of the resource hierarchy is two-fold:
- Provide a hierarchy of ownership, which binds the lifecycle of a resource to its immediate parent in the hierarchy.
- Provide attach points and inheritance for access control policies.
The following diagram shows a logical view of the resource hierarchy.
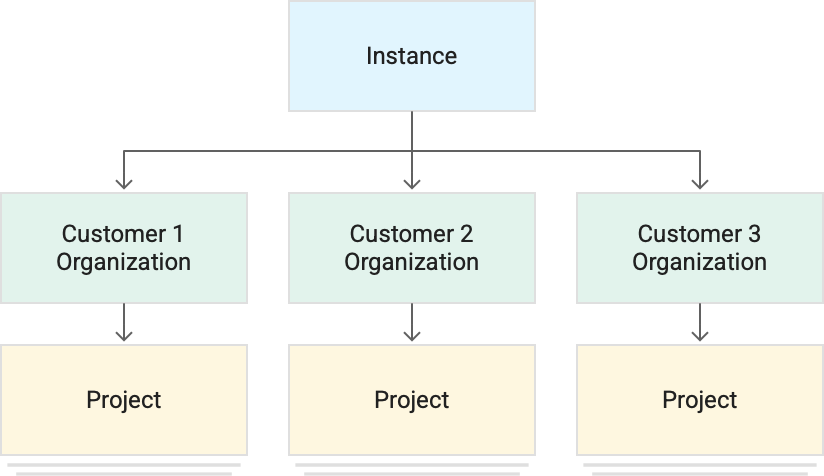
One instance of GDC can contain multiple customer organizations. Each organization can contain multiple projects. Each project contains multiple resources such as VM-based workloads and container-based workloads. Each organization has separate physical and administrative boundaries and configures identity authentication separately.
Design access boundaries between resources
This section introduces Google recommended best practices for designing the hierarchy and segregation for workloads in GDC using organizations, projects, and Kubernetes clusters. This guidance balances efficient resource usage, isolation of workloads, and ease of operations.
Design organizations for physical and logical isolation between customers
The Organization resource is the root for all the resources owned by a single
customer. Granular access control between workloads within an organization can
be defined through role bindings and network policies. See
Identity and access management for more
information.
Each organization within a GDC instance provides physical isolation for compute infrastructure, and logical isolation for networking, storage, and other services. Users in one organization have no access to resources in another organization unless explicitly granted access. Network connectivity from one organization to another is not allowed by default, unless explicitly configured to allow data transfer out from one organization and data transfer in to another.
Define the scope of workloads that can share an organization
The scope of an organization in your company context might vary based on how your company defines trust boundaries. Some companies might prefer to create multiple organization resources for different entities in the company. For example, each company department might be an independent customer of GDC with an independent organization if the departments require complete physical and administrative separation of their workloads.
In general, we recommend that you group multiple workloads into a single organization based on the following signals:
- Workloads can share dependencies. For example, this might be a shared data source, connectivity between workloads, or a shared monitoring tool.
- Workloads can share an administrative root of trust. The same Platform Administrator (PA) can be trusted with privileged access over all workloads in the organization.
- Workloads are allowed to share underlying physical infrastructure with other workloads in the same organization, as long as sufficient logical segregation is in place.
- The same budget holder has accountability for workload budgets in aggregate. For details on viewing aggregate costs for the organization or granular analysis per workload, see the Billing page.
- Workload availability requirements can be met in a single site GDC instance. When you require high availability that spans geographic distance, you must configure organizations across multiple GDC instances and external network connectivity.
Design projects for logical isolation between workloads
Within an organization, we recommend provisioning multiple projects to create a logical separation between resources. Projects in the same organization might share the underlying physical infrastructure, but projects are used to separate workloads with a logical boundary based on Identity and Access Management (IAM) policies and network policies.
When designing project boundaries, think of the largest set of functionality that can be shared by resources, such as role bindings, network policies, or observability requirements. Group the resources that can share this functionality into a project, and move resources that cannot share this functionality to another project.
In Kubernetes terms, a project is a Kubernetes namespace that is reserved across all clusters in an organization. Though a namespace is reserved across multiple clusters, that does not mean a pod is automatically scheduled across all clusters. A pod scheduled to a particular cluster remains scheduled to that particular cluster.
The following diagram shows how a role binding is applied to a project that spans multiple clusters.
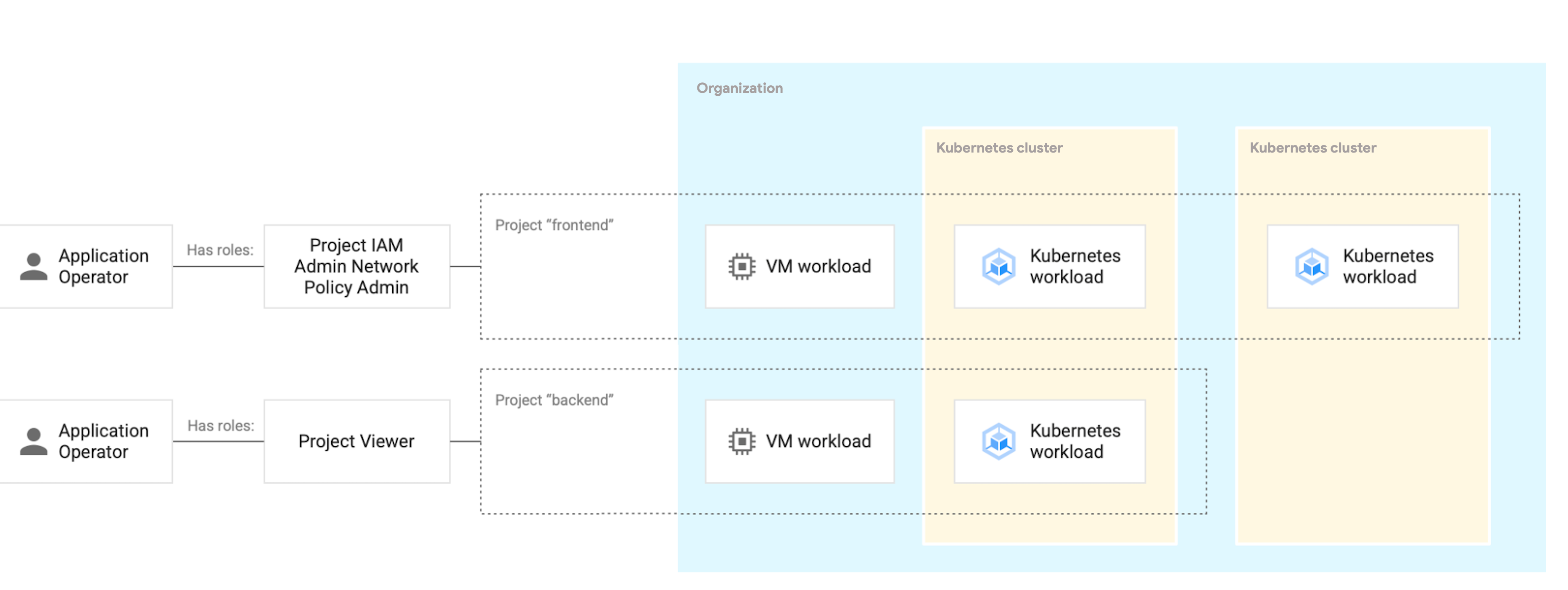
Role bindings are set at the project level to define who can do what to which resource type. User workloads like VMs or pods are deployed into a project and access to these workloads is governed by the role binding. The role binding applies consistently to VM-based workloads and container-based workloads, regardless of which cluster they are deployed on.
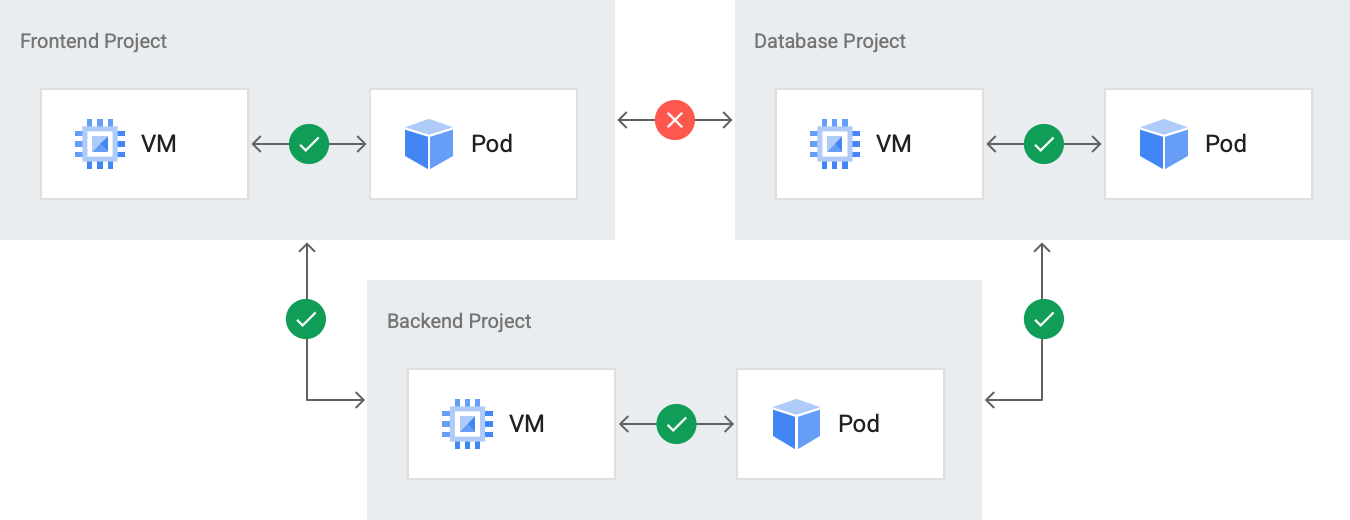
The following diagram shows how network policies manage access between projects.
Inter-project communication between the Backend Project, Frontend Project,
and Database Project is disabled. However, resources within each project can
communicate with each other.

Network policies are set at the project level to selectively allow network access between resources. By default, all resources within a single project are allowed to communicate with each other on the internal network, and a resource in one project cannot communicate with a resource in another project. This behavior for network policies applies whether resources are deployed to the same cluster or not.
You can also define a ProjectNetworkPolicy custom resource to enable
inter-project communication. This policy is defined for each project to allow
ingress traffic from other projects. The following diagram illustrates a
ProjectNetworkPolicy custom resource defined for the Backend Project to
enable data transfer in from the Frontend Project and Database Project.
Additionally, the observability stack collects metrics across the organization, but you can filter and query at various levels of the resource hierarchy. As needed for your operations, you can query metrics per cluster, per namespace, and so on.
Create projects per deployment environment
For each workload, we recommend creating separate projects for production, development, and any other deployment environments you require. Separating your production and development deployment environments lets you define role bindings and network policies granularly, so that changes made in a project used for development don't impact the production environment.
Grant resource-level role bindings within projects
Depending on your team structure and requirements, you might allow Application Operators (AO) to modify any resource within the project they manage, or you might require more granular access control. Within a project, you grant granular role bindings to let individual developers access some but not all resources in the project. For example, a team might have a database administrator who must manage the database but not modify other code, while the software developers on the team must not have permission to modify the database.
Design clusters for logical isolation of Kubernetes operations
A Kubernetes cluster is not a hard tenant boundary because role bindings and network policies apply to projects, not Kubernetes clusters. Kubernetes clusters and projects have a many-to-many relationship. You might have multiple Kubernetes clusters in a single project, or a single Kubernetes cluster that spans multiple projects.
Best practices for designing Kubernetes clusters
To deploy container-based workloads, you must first create a Kubernetes cluster. Kubernetes clusters are not required if you plan to only have VM-based workloads.
This section introduces best practices for designing Kubernetes clusters:
- Create separate clusters per deployment environment
- Create fewer, larger clusters
- Create fewer, larger node pools within a cluster
Create separate clusters per deployment environment
In addition to separate projects per deployment environment, we recommend that you design separate Kubernetes clusters per deployment environment. By segregating both the Kubernetes cluster and project per environment, you isolate resource consumption, access policies, maintenance events, and cluster-level configuration changes between your production and non-production workloads.
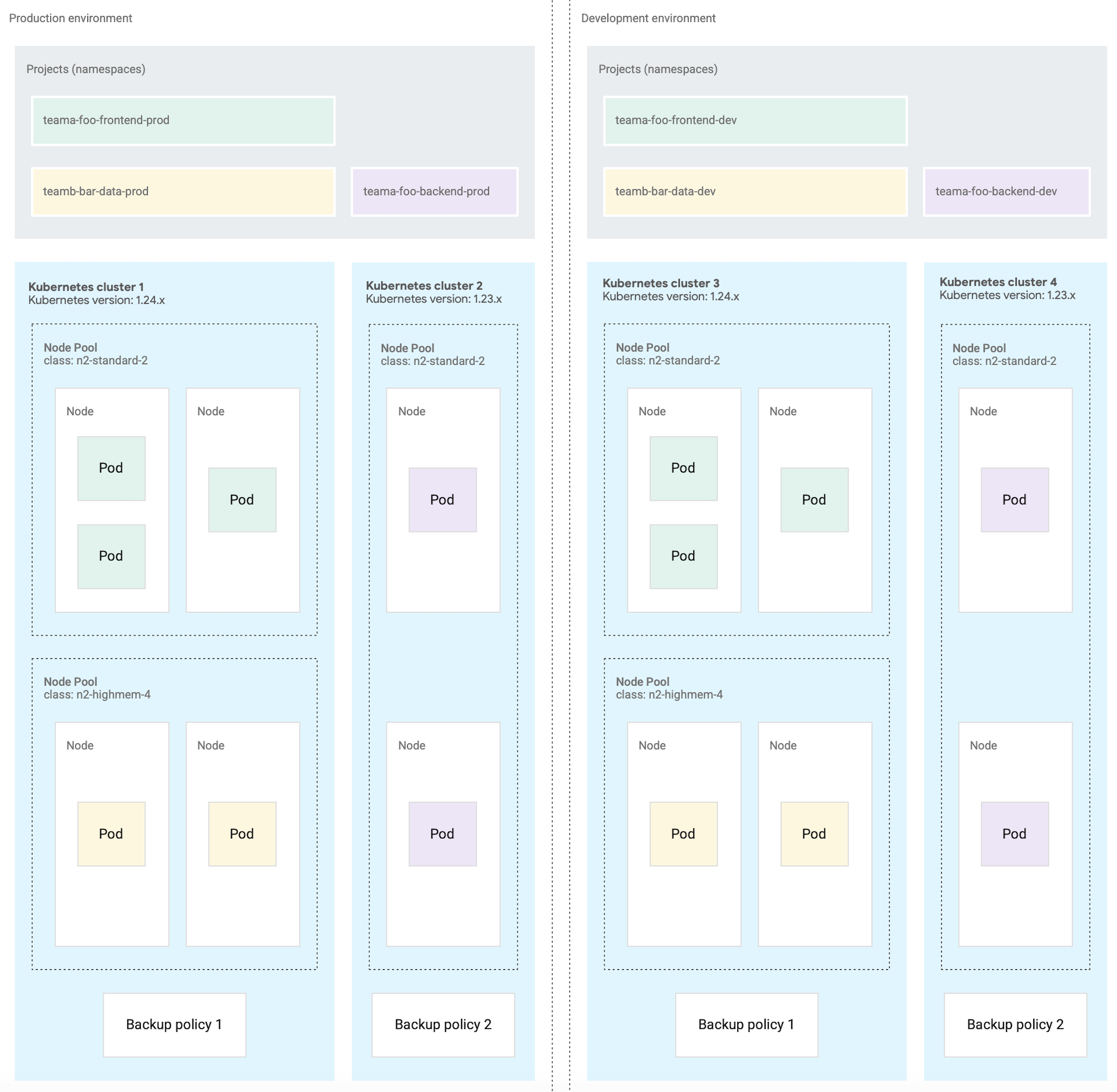
The following diagram shows a sample Kubernetes cluster design for multiple workloads that span projects, clusters, deployment environments, and machine classes.

This sample architecture assumes that workloads within a deployment environment are allowed to share clusters. Each deployment environment has a separate set of Kubernetes clusters. You then assign projects to the Kubernetes cluster of the appropriate deployment environment. A Kubernetes cluster might be further subdivided into multiple node pools for different machine class requirements.
Alternatively, designing multiple Kubernetes clusters is useful for container operations like the following scenarios:
- You have some workloads pinned to a specific Kubernetes version, so you maintain different clusters at different versions.
- You have some workloads that require different GDC Kubernetes cluster configurations, such as the backup policy, so you create multiple clusters with different configurations.
- You run copies of a cluster in parallel to facilitate disruptive version upgrades or a blue-green deployment strategy.
- You build an experimental workload that risks throttling the API server or other single point of failures within a cluster, so you isolate it from existing workloads.
The following diagram shows an example where multiple clusters are configured per deployment environment due to requirements such as the container operations described in the previous section.
Create fewer clusters
For efficient resource utilization, we recommend designing the fewest number of Kubernetes clusters that meet your requirements for segregating deployment environments and container operations. Each additional cluster incurs additional overhead resource consumption, such as additional control plane nodes required. Therefore, a larger cluster with many workloads utilizes underlying compute resources more efficiently than many small clusters.
If users are responsible for choosing where to deploy between multiple clusters of similar configuration, it creates additional complexity for users to monitor cluster capacity and plan for cross-cluster dependencies.
If a cluster is approaching capacity, we recommend that you add additional nodes to a cluster instead of creating a new cluster.
Create fewer node pools within a cluster
For efficient resource utilization, we recommend designing fewer, larger node pools within a Kubernetes cluster.
Configuring multiple node pools is useful when you need to schedule pods that require a different machine class or different operating system (OS) image than others. Create a node pool for each combination of machine class and OS image your workloads require, and set the node capacity to autoscaling to allow for efficient usage of compute resources.
Where to deploy user workloads
On the GDC platform, operations to deploy VM-based workloads and operations to deploy container-based workloads are different. This section introduces the differences and where you deploy each resource.
Connect to the org admin cluster for VM-based workloads
To deploy VM-based workloads, connect to the org admin cluster.
Projects containing only VM-based workloads do not require a Kubernetes cluster. Therefore, you do not need to provision Kubernetes clusters for these workloads.
Connect and deploy to the cluster for container-based workloads
For container-based workloads, pods are deployed to a single Kubernetes cluster. You are responsible for creating Kubernetes clusters, and for assigning Kubernetes clusters to a project. We recommend only allocating clusters to projects in the appropriate deployment environment. For example, a cluster for production workloads is assigned to a project for production workloads.
For pod scheduling within a Kubernetes cluster, GDC adopts the general Kubernetes concepts of scheduling, preemption, and eviction. Best practices on scheduling pods within a cluster vary based on the requirements of your workload.
Identity and access management
Configure an identity provider per organization
As an Operator, you configure one or more identity providers per organization.
You might have a scenario where your company has multiple departments with separate organizations, and each organization connects to the same identity provider for authentication. In that case, it is your responsibility to understand and audit the combination of privileges a user has across organizations. Ensure that a user with privileges in multiple organizations does not violate the requirements for separating workloads into distinct organizations.
Alternatively, you might have a scenario where different sets of users use different identity providers to authenticate within a single organization, such as when multiple vendor teams work together in a single organization. Consider whether consolidating user identities into a single identity provider or maintaining separate identity providers works best with your company's approach to identity management.
Configure multi-factor authentication for your identity provider
GDC relies on your Identity Platform for Authentication, including additional security settings such as multi-factor authentication. It is good practice to configure multi-factor authentication with a physical key for any user that might potentially access sensitive resources.
Restrict managed services and marketplace services
You might prefer to block some projects from certain services, to either limit the potential attack surface in a project or avoid use of unapproved services. By default, managed services like Artificial Intelligence and Machine Learning are available to use in any project. In comparison to managed services, marketplace services must first be enabled for the organization.
To deny service access from projects, apply Gatekeeper constraints against the custom resource definition of a service and a list of namespaces. The approach to deny access with Gatekeeper applies to managed and marketplace services.
Managing kubeconfig files for multiple clusters
Different operational tasks require a connection to different clusters. For
example, you perform tasks like binding an IAM role to a project on the org
admin cluster, and tasks like deploying a Kubernetes Pod resource - on a Kubernetes cluster.
When using the user interface (UI), you do not need to be aware of which underlying cluster performs a task, as the UI abstracts away the low-level operations like connecting to a cluster.
However, when working with the gdcloud CLI or kubectl CLI, a single
user might have multiple kubeconfig files for accomplishing their tasks. Ensure
that you sign in
using kubeconfig credentials for the appropriate cluster for your task.
Best practices for Kubernetes service accounts
For Kubernetes service accounts, authorization is based on a secret token. To mitigate the risk of service account tokens, consider the following best practices:
- Avoid downloading persistent service account credentials for use outside of GDC.
- Be aware of Kubernetes escalation paths for users or service accounts who have the ability to create and edit pods.
- Set the
expirationSecondsfield to a short time period for the service account token projection of your workloads. - Regularly rotate service account credentials.
Consider principles of least privilege when granting roles
Consider the principle of least privilege (PoLP) when granting role bindings to users. In accordance with PoLP, you should give a subject only privileges required to complete its task.
For example, you grant the Project IAM Admin role within a single project to a user, so that this user delegates authority to grant roles within that project. This user then grants granular roles to other developers in the project based on the specific services they use. The Project IAM Admin role must be restricted to a trusted lead because this role could be used to escalate privilege, granting oneself or others additional roles in the project.
Audit regularly for excessive privilege
Be sure to review roles granted within your organization and audit against excessive privilege. You must ensure that the roles granted are necessary for an individual user to complete their job, and that combinations of roles across projects do not lead to an escalation or exfiltration risk.
If your company uses multiple organizations, we do not recommend that an individual user has highly privileged roles across multiple organizations, as this might violate the reason for segregating organizations in the first place.