Create a Kubernetes cluster to allow for container workload deployment. Clusters are a zonal resource and cannot span multiple zones. To operate clusters in a multi-zone deployment, you must manually create clusters in each zone.
Before you begin
To get the permissions needed to create a Kubernetes cluster, ask your Organization
IAM Admin to grant you the User Cluster Admin role (user-cluster-admin). This
role is not bound to a namespace.
Google Distributed Cloud (GDC) air-gapped has the following limits for Kubernetes clusters:
- 16 clusters per organization
- 42 worker nodes per cluster, and a minimum of three worker nodes
- 4620 pods per cluster
- 110 pods per node
Configure the pod CIDR block
The cluster follows this logic when allocating IP addresses:
- Kubernetes assigns a /24 CIDR block consisting of 256 addresses to each of the nodes. This amount adheres to the default maximum of 110 pods per node for user clusters.
- The size of the CIDR block assigned to a node depends on the maximum pods per node value.
- The block always contains at least twice as many addresses as the maximum number of pods per node.
See the following example to understand how the default value of Per node mask size= /24 was calculated to accommodate 110 pods:
Maximum pods per node = 110
Total number of IP addresses required = 2 * 110 = 220
Per node mask size = /24
Number of IP addresses in a /24 = 2(32 - 24) = 256
Determine the required pod CIDR mask to be configured for the user cluster based on the required number of nodes. Plan for future node additions to the cluster while configuring the CIDR range:
Total number of nodes supported = 2(Per node mask size - pod CIDR mask)
Given that we have a default Per node mask size= /24 , refer to the following table that maps the pod CIDR mask to the number of nodes supported.
| Pod CIDR Mask | Calculation: 2(Per node mask size - CIDR mask) | Maximum number of nodes supported including control plane nodes |
|---|---|---|
| /21 | 2(24 - 21) | 8 |
| /20 | 2(24-20) | 16 |
| /19 | 2(24 - 19) | 32 |
| /18 | 2(24 - 18) | 64 |
Create a Kubernetes cluster
Complete the following steps to create a Kubernetes cluster:
Console
In the navigation menu, select Kubernetes Engine > Clusters.
Click Create Cluster.
In the Name field, specify a name for the cluster.
Select the Kubernetes version for the cluster.
Select the zone in which to create the cluster.
Click Attach Project and select an existing project to attach to your cluster. Then click Save. You can attach or detach projects after creating the cluster from the project details page. You must have a project attached to your cluster before deploying container workloads it.
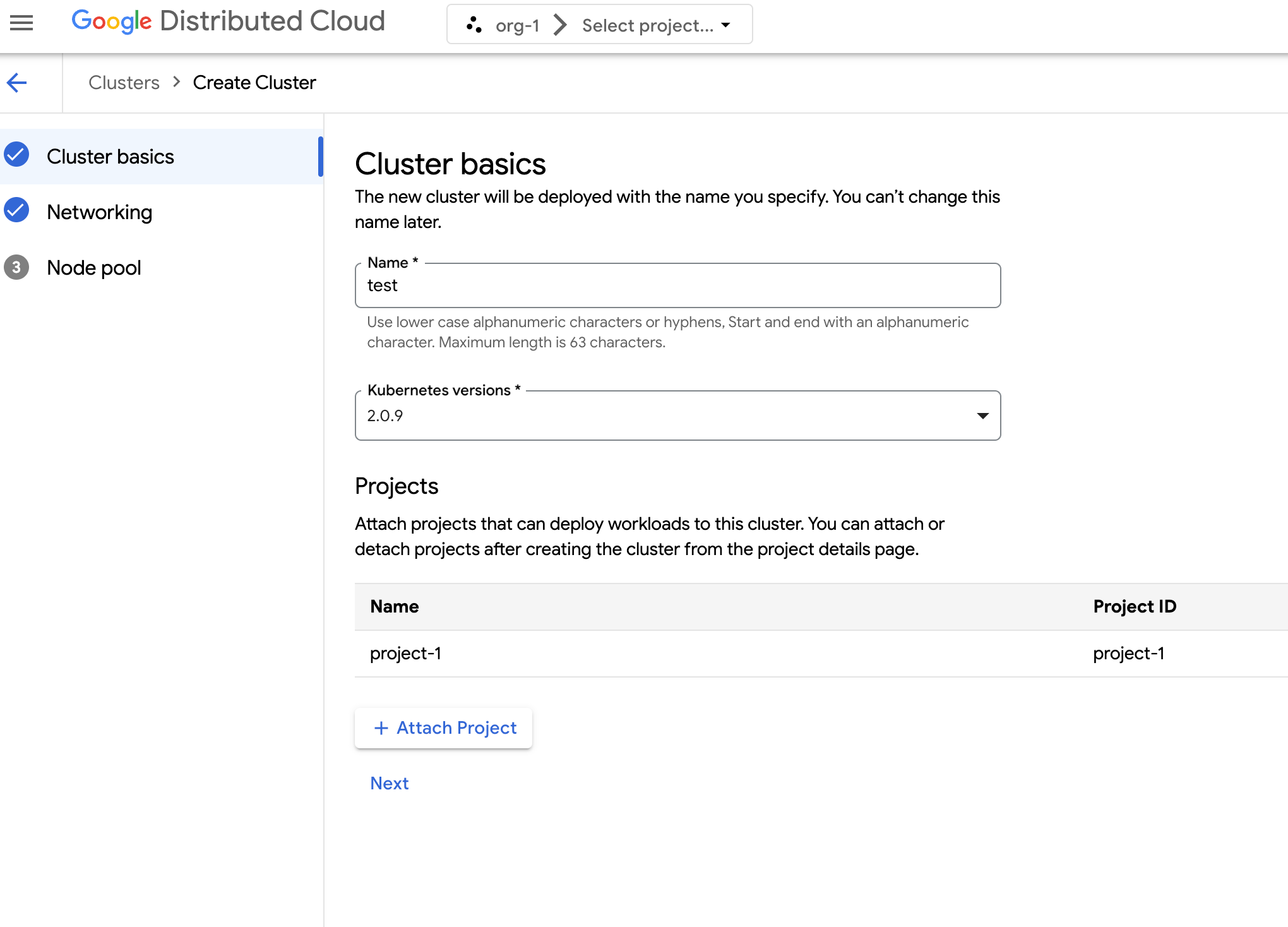
Click Next.
Configure the network settings for your cluster. You can't change these network settings after you create the cluster. The default and only supported Internet Protocol for Kubernetes clusters is Internet Protocol version 4 (IPv4).
If you want to create dedicated load balancer nodes, enter the number of nodes to create. By default, 20 nodes are assigned. If you don't allocate any nodes, load balancer traffic runs through the control plane nodes. This value can be updated after cluster creation.
Select the Service CIDR (Classless Inter-Domain Routing) to use. Your deployed services, such as load balancers, are allocated IP addresses from this range.
Select the Pod CIDR to use. The cluster allocates IP addresses from this range to your pods and VMs.
Click Next.
Review the details of the auto-generated default node pool for the cluster. Click edit Edit to modify the default node pool.
To create additional node pools, select Add node pool. When editing the default node pool or adding a new node pool, you customize it with the following options:
- Assign a name for the node pool. You cannot modify the name after you create the node pool.
- Specify the number of worker nodes to create in the node pool.
Select your machine class that best suits your workload requirements. View the list of the following settings:
- Machine type
- CPU
- Memory
Click Save.
Click Create to create the cluster.
API
To create a new cluster using the API directly, apply a custom resource to your GDC instance:
Create a
Clustercustom resource and save it as a YAML file, such ascluster.yaml:apiVersion: cluster.gdc.goog/v1 kind: Cluster metadata: name: CLUSTER_NAME namespace: platform spec: clusterNetwork: podCIDRSize: POD_CIDR serviceCIDRSize: SERVICE_CIDR initialVersion: kubernetesVersion: KUBERNETES_VERSION loadBalancer: ingressServiceIPSize: LOAD_BALANCER_POOL_SIZE nodePools: - machineTypeName: MACHINE_TYPE name: NODE_POOL_NAME nodeCount: NUMBER_OF_WORKER_NODES taints: TAINTS labels: LABELS acceleratorOptions: gpuPartitionScheme: GPU_PARTITION_SCHEME releaseChannel: channel: UNSPECIFIEDReplace the following:
CLUSTER_NAME: The name of the cluster. The cluster name must not end with-system. The-systemsuffix is reserved for clusters created by GDC.POD_CIDR: The size of network ranges from which pod virtual IP addresses are allocated. If unset, a default value21is used.SERVICE_CIDR: The size of network ranges from which service virtual IP addresses are allocated. If unset, a default value23is used.KUBERNETES_VERSION: The Kubernetes version of the cluster, such as1.26.5-gke.2100. To list the available Kubernetes versions to configure, see List available Kubernetes versions for a cluster.LOAD_BALANCER_POOL_SIZE: The size of non-overlapping IP address pools used by load balancer services. If unset, a default value20is used. If set to0, load balancer traffic runs through the control plane nodes. This value can be updated after cluster creation.MACHINE_TYPE: The machine type for the worker nodes of the node pool. View the available machine types for what is available to configure.NODE_POOL_NAME: The name of the node pool.NUMBER_OF_WORKER_NODES: The number of worker nodes to provision in the node pool.TAINTS: The taints to apply to the nodes of this node pool. This is an optional field.LABELS: The labels to apply to the nodes of this node pool. It contains a list of key-value pairs. This is an optional field.GPU_PARTITION_SCHEME: The GPU partitioning scheme, if you're running GPU workloads. For example,mixed-2. The GPU is not partitioned if this field is not set. For available Multi-Instance GPU (MIG) profiles, see Supported MIG profiles.
Apply the custom resource to your GDC instance:
kubectl apply -f cluster.yaml --kubeconfig MANAGEMENT_API_SERVERReplace
MANAGEMENT_API_SERVERwith the zonal API server's kubeconfig path. If you have not yet generated a kubeconfig file for the API server in your targeted zone, see Sign in for details.
Terraform
In a Terraform configuration file, insert the following code snippet:
provider "kubernetes" { config_path = "MANAGEMENT_API_SERVER" } resource "kubernetes_manifest" "cluster-create" { manifest = { "apiVersion" = "cluster.gdc.goog/v1" "kind" = "Cluster" "metadata" = { "name" = "CLUSTER_NAME" "namespace" = "platform" } "spec" = { "clusterNetwork" = { "podCIDRSize" = "POD_CIDR" "serviceCIDRSize" = "SERVICE_CIDR" } "initialVersion" = { "kubernetesVersion" = "KUBERNETES_VERSION" } "loadBalancer" = { "ingressServiceIPSize" = "LOAD_BALANCER_POOL_SIZE" } "nodePools" = [{ "machineTypeName" = "MACHINE_TYPE" "name" = "NODE_POOL_NAME" "nodeCount" = "NUMBER_OF_WORKER_NODES" "taints" = "TAINTS" "labels" = "LABELS" "acceleratorOptions" = { "gpuPartitionScheme" = "GPU_PARTITION_SCHEME" } }] "releaseChannel" = { "channel" = "UNSPECIFIED" } } } }Replace the following:
MANAGEMENT_API_SERVER: The zonal API server's kubeconfig path. If you have not yet generated a kubeconfig file for the API server in your targeted zone, see Sign in for details.CLUSTER_NAME: The name of the cluster. The cluster name must not end with-system. The-systemsuffix is reserved for clusters created by GDC.POD_CIDR: The size of network ranges from which pod virtual IP addresses are allocated. If unset, a default value21is used.SERVICE_CIDR: The size of network ranges from which service virtual IP addresses are allocated. If unset, a default value23is used.KUBERNETES_VERSION: The Kubernetes version of the cluster, such as1.26.5-gke.2100. To list the available Kubernetes versions to configure, see List available Kubernetes versions for a cluster.LOAD_BALANCER_POOL_SIZE: The size of non-overlapping IP address pools used by load balancer services. If unset, a default value20is used. If set to0, load balancer traffic runs through the control plane nodes. This value can be updated after cluster creation.MACHINE_TYPE: The machine type for the worker nodes of the node pool. View the available machine types for what is available to configure.NODE_POOL_NAME: The name of the node pool.NUMBER_OF_WORKER_NODES: The number of worker nodes to provision in the node pool.TAINTS: The taints to apply to the nodes of this node pool. This is an optional field.LABELS: The labels to apply to the nodes of this node pool. It contains a list of key-value pairs. This is an optional field.GPU_PARTITION_SCHEME: The GPU partitioning scheme, if you're running GPU workloads. For example,mixed-2. The GPU is not partitioned if this field is not set. For available Multi-Instance GPU (MIG) profiles, see Supported MIG profiles.
Apply the new Kubernetes cluster using Terraform:
terraform apply
List available Kubernetes versions for a cluster
You can list the available Kubernetes versions in your GDC
instance using the kubectl CLI:
kubectl get userclustermetadata.upgrade.private.gdc.goog \
-o=custom-columns=K8S-VERSION:.spec.kubernetesVersion \
--kubeconfig MANAGEMENT_API_SERVER
Replace MANAGEMENT_API_SERVER with the kubeconfig path
of your cluster's zonal API server.
The output looks similar to the following:
K8S-VERSION
1.25.10-gke.2100
1.26.5-gke.2100
1.27.4-gke.500
Support GPU workloads in a cluster
Distributed Cloud provides NVIDIA GPU support for Kubernetes clusters, and they run your GPU devices as user workloads. For example, you might prefer running artificial intelligence (AI) and machine learning (ML) notebooks in a GPU environment. Ensure that your cluster supports GPU devices before leveraging AI and ML notebooks. GPU support is enabled by default for clusters who have GPU machines provisioned for them.
Clusters can be created using the GDC console or API directly. Ensure that you provision GPU machines for your cluster to support GPU workloads on its associated containers. For more information, see Create a Kubernetes cluster.
GPUs are statically allocated. The first four GPUs are always dedicated to workloads like pretrained Artificial Intelligence (AI) and Machine Learning (ML) APIs. These GPUs don't run on a Kubernetes cluster. The remaining GPUs are available to Kubernetes clusters. AI and ML notebooks run on Kubernetes clusters.
Be sure to allocate GPU machines for the correct cluster types to ensure components such as AI and ML APIs and notebooks can be used.