Ce document fait partie d'une série qui fournit des informations et des conseils clés sur la planification et l'exécution des migrations de base de données Oracle® 11g/12c vers Cloud SQL pour PostgreSQL version 12. Outre la section d'introduction à la configuration, la série inclut les éléments suivants :
- Migrer des utilisateurs Oracle vers Cloud SQL pour PostgreSQL : terminologie et fonctionnalités (ce document)
- Migrer des utilisateurs Oracle vers Cloud SQL pour PostgreSQL : types de données, utilisateurs et tables
- Migrer des utilisateurs Oracle vers Cloud SQL pour PostgreSQL : requêtes, procédures stockées, fonctions et déclencheurs
- Migrer des utilisateurs Oracle vers Cloud SQL pour PostgreSQL : sécurité, opérations, surveillance et journalisation
- Migrer des utilisateurs et des schémas de Oracle Database vers Cloud SQL pour PostgreSQL
Terminologie
Cette section décrit les similitudes et les différences de terminologie entre les bases de données Oracle et Cloud SQL pour PostgreSQL. Elle examine et compare les principaux aspects de chacune des plates-formes de base de données. La comparaison fait la distinction entre les versions 11g et 12c d'Oracle, en raison des différences architecturales (par exemple, Oracle 12c introduit la fonctionnalité de charge de travail mutualisée). La version Cloud SQL pour PostgreSQL référencée ici est la version 12.
Cette section met en évidence les principales différences de terminologie entre Oracle et Cloud SQL pour PostgreSQL. Une description de bas niveau est détaillée plus loin dans ce document.
| Oracle 11g | Description | Cloud SQL pour PostgreSQL | Différences majeures |
|---|---|---|---|
| instance | Une instance Oracle 11g ne peut contenir qu'une seule base de données. | instance | Une instance Cloud SQL pour PostgreSQL contient exactement un cluster de base de données. Un cluster de base de données est un ensemble de bases de données stockées dans une zone de données commune. |
| base de données | Une base de données est considérée comme une instance unique (le nom de la base de données est identique au nom de l'instance). | base de données | Les bases de données multiples ou uniques diffusent plusieurs applications. |
| schema | Le schéma et les utilisateurs sont identiques, car ils sont considérés comme propriétaires d'objets de base de données (il est possible de créer un utilisateur sans spécifier de schéma ni attribuer celui-ci à un schéma). | schema | Une base de données contient un ou plusieurs schémas. Les objets tels que les tables sont contenus dans des schémas. Le même nom d'objet peut être utilisé dans différents schémas au sein d'une même base de données sans conflit. |
| Utilisateur | Identique au schéma, car les deux sont propriétaires d'objets de base de données, par exemple : instance → base de données → schémas/utilisateurs → objets de base de données. | Rôle | Un rôle peut être un utilisateur de base de données ou un groupe d'utilisateurs de base de données, selon la configuration. Il peut également posséder des objets de base de données tels que des tables.
Les rôles sont limités à l'ensemble d'un cluster de base de données. Il est possible d'attribuer un rôle à un autre rôle. |
| Rôle | Ensemble défini d'autorisations de base de données pouvant être associées en tant que groupe et attribuées aux utilisateurs de la base de données | ||
| admin/ utilisateurs SYSTÈME |
Administrateurs d'Oracle ayant le niveau d'accès le plus élevé :SYS
|
cloudsqlsuperuser | Cloud SQL pour PostgreSQL est fourni avec l'utilisateur postgres par défaut. L'utilisateur fait partie du rôle cloudsqlsuperuser et possède les attributs (privilèges) suivants : CREATEROLE, CREATEDB et LOGIN. Comme Cloud SQL pour PostgreSQL est un service géré, il restreint l'accès à certaines tables et procédures système qui requièrent des privilèges avancés. Par conséquent, l'utilisateur postgres ne possède pas les attributs SUPERUSER ou REPLICATION. Vous ne pouvez pas créer d'utilisateurs disposant d'attributs superuser ni accéder à ceux-ci. |
| dictionnaire/ métadonnées |
Oracle utilise les tables de métadonnées suivantes :USER_TableName
|
dictionnaire/ métadonnées |
Cloud SQL pour PostgreSQL utilise INFORMATION_SCHEMA de la norme ANSI pour fournir des informations sur le dictionnaire et les métadonnées. |
| vues dynamiques du système | Vues dynamiques Oracle :V$ViewName |
vues dynamiques du système |
Cloud SQL pour PostgreSQL offre les vues de statistiques dynamiques suivantes :pg_stat_ViewNamepg_statio_ViewName |
| espace de table | Principale structure de stockage logique des bases de données Oracle. Chaque espace de table peut contenir un ou plusieurs fichiers de données. | espace de table | Dans Cloud SQL pour PostgreSQL, les fichiers de données sont stockés ensemble dans le répertoire de données PGDATA d'un cluster de base de données, à l'aide d'une structure de répertoires prédéfinie. Les espaces de table dans Cloud SQL pour PostgreSQL permettent de définir des emplacements personnalisés dans le système de fichiers où les fichiers de données peuvent être stockés.Comme Cloud SQL pour PostgreSQL est un service géré, Google Cloud il gère pour vous le système de fichiers sous-jacent de la machine hôte. Vous ne pouvez pas créer d'espaces de table sur Cloud SQL pour PostgreSQL. |
| fichiers de données | Éléments physiques d'une base de données Oracle qui contiennent les données et sont définis sous un espace de table spécifique. Un fichier de données est défini par sa taille initiale et sa taille maximale. Il peut contenir des données pour plusieurs tables. Les fichiers de données Oracle utilisent le suffixe .dbf (facultatif). |
fichiers de données | Cloud SQL pour PostgreSQL stocke chaque base de données dans un cluster de base de données dans son propre sous-répertoire. Chaque table et index d'une base de données est stocké dans un fichier distinct de ce sous-répertoire. |
| espace de table système | Contient les tables du dictionnaire de données et affiche les objets de l'ensemble de la base de données Oracle. | N'existe pas | Les tables de dictionnaire et les objets de vues de données sont stockés dans INFORMATION_SCHEMA dans le répertoire de données PGDATA d'un cluster de base de données à l'aide d'une structure de répertoires prédéfinie. |
| espace de table temporaire | Contient des objets de schéma valides pour la durée d'une session. Permet
également d'exécuter des opérations qui ne peuvent pas tenir dans la mémoire du serveur. |
fichiers temporaires | Les fichiers temporaires permettent de stocker des opérations en cours qui ne peuvent pas tenir dans la mémoire du serveur. Ces fichiers sont stockés dans un répertoire appelé pgsql_tmp et ne sont créés que lorsque l'instruction SQL est en cours d'exécution. |
| Espace de table d'annulation | Type spécial d'espace de table système permanent utilisé par Oracle pour gérer les opérations de rollback lors de l'exécution de la base de données en mode de gestion d'annulation automatique (par défaut). |
N'existe pas | Pour permettre les opérations de rollback, Cloud SQL pour PostgreSQL conserve les lignes mises à jour ou supprimées dans le fichier de données de la table. Le vidage consiste à récupérer ou à réutiliser l'espace disque occupé par des lignes mises à jour ou supprimées. |
| ASM | La gestion automatique de l'espace de stockage (ASM) d'Oracle est un système de fichiers de base de données et de gestion de disque intégré hautes performances assuré automatiquement par une base de données Oracle configurée avec ASM. | Non compatible | Cloud SQL pour PostgreSQL s'appuie sur le système de fichiers du système d'exploitation pour stocker des fichiers de données et ne dispose pas d'équivalent Oracle ASM. Cependant, Cloud SQL pour PostgreSQL est compatible avec de nombreuses fonctionnalités d'automatisation du stockage, telles que l'augmentation automatique du stockage et des performances, ou encore le scaling automatisé. |
| tables/vues | Objets de base de données essentiels créés par l'utilisateur. | tables/vues | Identique à Oracle. |
| vues matérialisées | Définies avec des instructions SQL spécifiques, elles peuvent être actualisées manuellement ou automatiquement en fonction de configurations spécifiques. |
vues matérialisées | Les vues matérialisées fonctionnent de la même manière que Oracle. Elles sont actualisées manuellement à l'aide d'instructions REFRESH
MATERIALIZED VIEW. |
| séquence | Générateur de valeur unique Oracle. | séquence | Semblable à Oracle. |
| synonyme | Objets de base de données Oracle qui servent d'identifiants alternatifs pour d'autres objets de base de données. | Non compatible | Cloud SQL pour PostgreSQL n'offre pas de synonymes. comme solution de contournement, vous pouvez utiliser les vues pour définir les autorisations appropriées. |
| partitionnement | Oracle propose de nombreuses solutions de partitionnement pour diviser de grandes tables en plus petits éléments gérés. | partitionnement | Cloud SQL pour PostgreSQL est compatible avec le partitionnement déclaratif du style Oracle et avec le partitionnement à l'aide de l'héritage, ce qui permet d'accroître les flexibilités de partitionnement. |
| Base de données Flashback | Fonctionnalité propriétaire développée par Oracle permettant d'initialiser une base de données Oracle à une heure prédéfinie, ce qui vous permet d'interroger ou de restaurer des données modifiées ou corrompues par erreur. | Non compatible | En tant que solution alternative, vous pouvez utiliser les sauvegardes Cloud SQL et la récupération à un moment précis pour restaurer une base de données à un état antérieur (par exemple, restaurer la base avant une suppression de table). |
| sqlplus | Interface de ligne de commande Oracle qui vous permet d'interroger et de gérer l'instance de base de données. | psql | Interface de ligne de commande équivalente de Cloud SQL pour PostgreSQL pour interroger et gérer. Peut être connectée depuis n'importe quel client disposant des autorisations appropriées pour Cloud SQL. |
| PL/SQL | Langage procédural étendu d'Oracle pour ANSI SQL. | PL/pgSQL | Cloud SQL pour PostgreSQL possède son propre langage procédural appelé PL/pgSQL, qui est semblable au langage PL/SQL d'Oracle à de nombreux aspects. Pour obtenir un résumé des principales différences entre les deux langages, consultez la section Portage depuis Oracle PL/SQL. |
| packages et contenu des packages | Fonctionnalité propre à Oracle permettant de regrouper les procédures et les fonctions stockées sous la même référence logique. | Non disponible | Cloud SQL pour PostgreSQL organise les fonctions à l'aide de schémas. |
| procédures et fonctions stockées | Utilise PL/SQL pour mettre en œuvre la fonctionnalité de code. | Procédures et fonctions stockées | Cloud SQL pour PostgreSQL est compatible avec la mise en œuvre de procédures et fonctions stockées, avec divers langages de programmation tels que PL/pgSQL et C. |
| déclencheur | Objet Oracle permettant de contrôler la mise en œuvre du LMD sur les tables. | déclencheur | Semblable à Oracle. |
| PFILE/SPFILE | Les paramètres au niveau de l'instance et de la base de données Oracle sont conservés dans un fichier binaire appelé SPFILE (dans les versions précédentes, il s'appelait PFILE), qui peut être utilisé comme fichier texte pour définir les paramètres manuellement. |
Options de base de données Cloud SQL pour PostgreSQL | Vous pouvez définir ou modifier des paramètres Cloud SQL pour PostgreSQL via l'utilitaire d'options de base de données. |
| SGA/PGA/ AMM |
Paramètres de mémoire Oracle qui contrôlent l'allocation de mémoire à l'instance de base de données. | Plusieurs paramètres liés à la mémoire | Cloud SQL pour PostgreSQL possède ses propres paramètres de mémoire. Certains paramètres similaires sont shared_buffers, temp_buffers et work_mem. Dans Cloud SQL pour PostgreSQL, ces paramètres sont prédéfinis par le type d'instance choisi, et la valeur change en conséquence. Vous pouvez ajuster certains de ces paramètres à l'aide de l'utilitaire d'indicateurs de base de données. |
| cache des tampons | Réduction des opérations d'E/S SQL en récupérant les données mises en cache à partir du cache des tampons. Les paramètres de mémoire peuvent être gérés au niveau de la base de données ou au niveau de la session via des optimisations de requête. | Fonctionnalité similaire | La taille du cache des tampons de Cloud SQL pour PostgreSQL est contrôlée par le paramètre shared_buffer, qui n'est pas exposé dans Cloud SQL. Cloud SQL fournit une métrique d'utilisation de la mémoire, qui permet de redimensionner l'instance. |
| optimisations de base de données | Oracle est capable de fournir un impact contrôlé aux instructions SQL qui influera sur le comportement de l'optimiseur pour améliorer les performances. Oracle dispose de plus de 50 optimisations de base de données différentes. | Non compatible | Cloud SQL pour PostgreSQL n'est pas compatible avec les optimisations de base de données. À un degré limité, vous pouvez contrôler le planificateur de requêtes de Cloud SQL pour PostgreSQL à l'aide de la syntaxe JOIN explicite. |
| RMAN | Gestionnaire de récupération de données Oracle. Utilisé pour effectuer des sauvegardes de base de données avec des fonctionnalités étendues afin de prendre en charge plusieurs scénarios de reprise après sinistre et plus encore (clonage, etc.). | Sauvegarde Cloud SQL pour PostgreSQL | Cloud SQL pour PostgreSQL propose deux méthodes pour appliquer des sauvegardes complètes : les sauvegardes à la demande et automatisées. |
| Vidage des données (EXPDP/ IMPDP) |
Utilitaire de génération de fichiers de vidage Oracle pouvant être utilisé pour de nombreuses fonctionnalités, telles que l'exportation/importation, la sauvegarde de base de données (au niveau du schéma ou de l'objet), les métadonnées de schéma, la génération de fichiers SQL de schéma, etc. | Exportation/importation Cloud SQL pour PostgreSQL | Cloud SQL pour PostgreSQL propose deux formats d'exportation/importation vers et depuis des buckets Cloud Storage : SQL et CSV. Vous pouvez également vous connecter à l'instance de base de données en utilisant des utilitaires d'exportation/importation tels que pg_dump. |
| Outil de chargement SQL | Outil vous permettant d'importer des données à partir de fichiers externes tels que des fichiers texte, des fichiers CSV, etc. | psql \copy |
La commande \copy du client psql vous permet de charger des fichiers texte, CSV ou binaires (Oracle est compatible avec des formats de fichiers supplémentaires) dans une table de base de données avec une structure correspondante. |
| Protection des données | Solution de reprise après sinistre Oracle utilisant une instance de secours. Elle permet aux utilisateurs d'effectuer des opérations READ à partir de l'instance de secours. |
Haute disponibilité et réplication Cloud SQL pour PostgreSQL | Pour obtenir une reprise après sinistre ou une haute disponibilité, Cloud SQL pour PostgreSQL propose l'architecture d'instance dupliquée de basculement et, pour les opérations en lecture seule (séparation READ/WRITE), l'instance dupliquée avec accès en lecture. |
| Protection active des données/ Golden Gate |
Principales solutions de réplication d'Oracle, qui peuvent répondre à plusieurs besoins, comme les machines de secours (DR), l'instance en lecture seule, la réplication bidirectionnelle (multimaître), l'entreposage de données, etc. | Instance dupliquée avec accès en lecture Cloud SQL pour PostgreSQL | Cloud SQL pour PostgreSQL offre une fonctionnalité d'Instance dupliquée avec accès en lecture pour mettre en œuvre le clustering avec la séparation LECTURE/ÉCRITURE. Actuellement, il n'est pas possible d'effectuer une configuration multimaître, telle que la réplication bidirectionnelle GoldenGate ou la réplication hétérogène. |
| RAC | Oracle Real Application Cluster. Solution de clustering propriétaire développée par Oracle permettant de fournir une haute disponibilité en déployant plusieurs instances de base de données avec une seule unité de stockage. | Non compatible | Cloud SQL pour PostgreSQL n'est pas compatible avec une architecture multimaître. Cloud SQL pour PostgreSQL offre une haute disponibilité via une instance de secours et une évolutivité en lecture accrue via des instances dupliquées avec accès en lecture. |
| Grid/Cloud Control (OEM) | Logiciel Oracle pour la gestion et la surveillance des bases de données et d'autres services associés présenté sous la forme d'une application Web. Cet outil est utile pour analyser des bases de données en temps réel afin de comprendre les charges de travail élevées. | Google Cloud console, Cloud Monitoring |
Utilisez Cloud SQL pour PostgreSQL pour la surveillance, notamment grâce à des graphiques détaillés basés sur l'heure et les ressources. Utilisez également Cloud Monitoring pour stocker des métriques de surveillance Cloud SQL pour PostgreSQL et des analyses de journaux spécifiques à des fonctionnalités de surveillance avancées. |
| Journaux de RÉTABLISSEMENT | Journaux de transaction Oracle comportant au moins deux fichiers définis pré-alloués qui stockent toutes les modifications de données au fur et à mesure qu'elles sont effectuées. L'objectif principal du journal de rétablissement est de protéger la base de données en cas de défaillance d'une instance. | Journaux WAL | Cloud SQL pour PostgreSQL utilise WAL (Write-Ahead Logging) afin que les modifications apportées aux fichiers de données soient vidées sur le stockage permanent pour permettre la reprise après plantage. |
| journaux d'archive | Les journaux d'archive fournissent une assistance pour les opérations de sauvegarde et de réplication, entre autres. Si cette option est activée, Oracle écrit dans les journaux d'archive après chaque opération de changement de journal de rétablissement. | L'archivage WAL | Mise en œuvre Cloud SQL pour PostgreSQL de la conservation des journaux WAL L'archivage WAL est utilisé et activé avec la récupération à un moment précis. |
| fichier de contrôle | Le fichier de contrôle Oracle contient des informations sur la base de données, telles que des fichiers de données, des noms de journaux de rétablissement, des emplacements, le numéro de séquence de journal actuel et des informations sur le point de contrôle de l'instance. | PGDATA and pg_control
|
L'architecture de Cloud SQL pour PostgreSQL ne partage pas un concept équivalent à un fichier de contrôle Oracle. Les fichiers liés à la base de données sont organisés dans un répertoire communément appelé PGDATA. Les informations WAL liées aux enregistrements et aux points de contrôle sont stockées dans pg_control. |
| Numéro de modification du système (SCN) | Le SCN indique un moment précis dans une base de données Oracle. | Numéro séquentiel dans le journal (LSN) | L'équivalent de Cloud SQL pour PostgreSQL est le LSN. À l'instar des numéros SCN, les LN sont incrémentés de façon monotone au fil du temps. |
| Rapport AWR | Le rapport AWR (Automatic Workload Repository) d'Oracle est un rapport détaillé qui fournit des informations sur les performances des instances de base de données Oracle. Il est considéré comme un outil de diagnostic des performances. | collecteur de statistiques | Cloud SQL pour PostgreSQL ne dispose pas d'un rapport équivalent à Oracle AWR, mais PostgreSQL collecte les données sur les performances collectées par les collecteurs de statistiques. Les statistiques collectées sont exposées sur les vues pg_stat_* et pg_statio_*. |
DBMS_SCHEDULER
|
Utilitaire Oracle permettant de définir et de planifier des opérations. | Non compatible | Cloud SQL pour PostgreSQL n'offre pas d'utilitaire de planification intégré. Google Cloud fournit Cloud Scheduler, qui vous permet de planifier des tâches de base de données, telles que des exportations. |
| Chiffrement transparent des données | Chiffrement des données stockées sur des disques pour la protection des données au repos. | Norme AES (Advanced Encryption Standard) pour Cloud SQL | Cloud SQL pour PostgreSQL utilise la norme AES-256 (Advanced Encryption Standard) de 256 bits pour protéger les données au repos et en transit. |
| Compression avancée | Pour améliorer l'empreinte de stockage de la base de données, réduire les coûts de stockage et améliorer les performances, Oracle fournit des fonctionnalités avancées de compression des données (tables/index). | TOAST | Bien que cela ne soit pas directement comparable à la compression Oracle avancée, Cloud SQL pour PostgreSQL utilise une infrastructure appelée TOAST pour compresser automatiquement et de manière transparente les données de longueur variable trop grandes pour tenir dans une seule page de données. |
| SQL Developer | Interface utilisateur graphique SQL gratuite d'Oracle pour la gestion et l'exécution d'instructions SQL et PL/SQL. | pgAdmin | Interface utilisateur graphique Cloud SQL pour PostgreSQL gratuite pour la gestion et l'exécution d'instructions de code SQL et PostgreSQL. |
| Journal d'alertes | Journal principal d'Oracle pour les opérations et les erreurs générales liées à la base de données. | Création de rapports d'erreur et journalisation PostgreSQL | Utilisez la visionneuse de journaux de Cloud Logging pour inspecter les journaux d'erreurs PostgreSQL. |
| Table DUAL | Table spéciale Oracle pour récupérer des valeurs de pseudo-colonnes telles que SYSDATE ou USER. |
N'existe pas | Cloud SQL pour PostgreSQL permet d'omettre les clauses FROM des instructions SQL. Par exemple :SELECT NOW();
est une instruction valide dans PostgreSQL. |
| table externe | Oracle permet aux utilisateurs de créer des tables externes qui contiennent les données source sur des fichiers en dehors de la base de données. | Non compatible | En tant que service géré, Cloud SQL pour PostgreSQL n'expose pas le système de fichiers sous-jacent de l'hôte exécutant l'instance de base de données. Pour contourner le problème, vous pouvez importer les données sources dans une table PostgreSQL pour les interroger. |
| Écouteur | Processus réseau Oracle chargé d'écouter les connexions à la base de données. | Réseaux autorisés par Cloud SQL | Cloud SQL pour PostgreSQL accepte les connexions provenant de sources à distance sous condition que celles-ci soient autorisées sur la page de configuration des réseaux autorisés de Cloud SQL. |
| TNSNAMES | Ce fichier de configuration réseau Oracle définit les adresses des base de données pour établir des connexions à l'aide d'alias de connexion. | N'existe pas | Cloud SQL pour PostgreSQL accepte les connexions externes utilisant le nom de connexion de l'instance Cloud SQL ou l'adresse IP privée/publique. Le proxy Cloud SQL est une méthode d'accès sécurisé supplémentaire permettant de se connecter à Cloud SQL pour PostgreSQL sans avoir à autoriser d'adresses IP spécifiques ni à configurer SSL. |
| Port par défaut de l'instance | 1521 | Port par défaut de l'instance | 5432 |
| Lien vers la base de données | Objet de schéma Oracle qui peut être utilisé pour interagir avec des objets de base de données locaux/distants. | Wrapper de données étrangères (FDW) | L'extension postgres_fdw dans Cloud SQL pour PostgreSQL permet d'exposer les tables d'autres bases de données PostgreSQL ("étrangères") en tant que tables "étrangères" dans la base de données actuelle. Ces tables sont alors disponibles, un peu comme s'il s'agissait de tables locales. |
Différences de terminologie entre Oracle 12c et Cloud SQL pour PostgreSQL
| Oracle 12c | Description | Cloud SQL pour PostgreSQL | Différences majeures |
|---|---|---|---|
| Instance | La fonctionnalité mutualisée introduite dans Oracle 12c permet à une instance de stocker plusieurs bases de données en tant que bases de données connectables (PDB), par opposition à Oracle 11g, où une instance Oracle ne peut héberger qu'une seule base de données. | Instance | Une instance Cloud SQL pour PostgreSQL contient exactement un cluster de base de données. Un cluster de base de données est un ensemble de bases de données stockées dans une zone de données commune. |
| CDB | Une base de données de conteneurs mutualisés (CDB) peut prendre en charge une ou plusieurs PDB, tandis que des objets CDB globaux (affectant toutes les PDB) peuvent être créés, par exemple des rôles. | Instance PostgreSQL | L'instance Cloud SQL pour PostgreSQL est comparable à la CDB d'Oracle. Ils fournissent tous deux une couche système pour les bases de données hébergées. |
| PDB | Les PDB (bases de données connectables) peuvent être utilisées pour isoler les services et les applications et en tant qu'ensembles portables de schémas. | Bases de données/ schémas PostgreSQL |
Une base de données Cloud SQL pour PostgreSQL peut diffuser plusieurs services et applications et desservir de nombreux utilisateurs de base de données. |
| Séquences de session | À partir de la version Oracle 12c, vous pouvez créer des séquences au niveau de la session (renvoyer des valeurs uniques dans une session) ou au niveau global (par exemple, lorsque vous utilisez des tables temporaires). | Séquence temporaire | Une séquence temporaire est créée pour la session de base de données actuelle et est automatiquement supprimée à la fermeture de la session. |
| Colonnes d'identité | Le type IDENTITY Oracle 12c génère une séquence et l'associe à une colonne de table sans qu'il soit nécessaire de créer manuellement un objet de séquence distinct. |
Colonne SERIAL | Lorsque vous définissez le type de données d'une colonne comme SERIAL, Cloud SQL pour PostgreSQL crée automatiquement une séquence et renseigne la valeur de la colonne à l'aide de cette séquence lorsque de nouvelles lignes sont insérées dans la table. |
| Segmentation | Solution dans laquelle une base de données Oracle est partitionnée en plusieurs bases de données plus petites (segments) pour permettre l'évolutivité, la disponibilité et la géolocalisation des environnements OLTP. | Non compatible (en tant que fonctionnalité) | Cloud SQL pour PostgreSQL ne dispose pas d'une fonctionnalité de segmentation équivalente. La segmentation peut être mise en œuvre en associant Cloud SQL pour PostgreSQL (en tant que plate-forme de données) avec une couche d'application compatible. |
| Base de données en mémoire | Oracle propose une suite de fonctionnalités permettant d'améliorer les performances de la base de données pour les charges de travail OLTP ainsi que les charges de travail mixtes. | Non compatible | Cloud SQL pour PostgreSQL n'a pas de fonctionnalité équivalente intégrée. Vous pouvez toutefois utiliser notre service Redis géré Memorystore comme alternative. |
| Masquage | Dans le cadre des fonctionnalités de sécurité avancées d'Oracle, le masquage des colonnes peut empêcher la récupération des données sensibles par les utilisateurs et les applications. | Non compatible | Cloud SQL pour PostgreSQL n'a pas de fonctionnalité équivalente intégrée. Toutefois, vous pouvez exploiter la protection des données sensibles pour anonymiser les données sensibles. |
Fonctionnalités
Bien que les bases de données Oracle 11g/12c et Cloud SQL pour PostgreSQL reposent sur différentes architectures (infrastructure et langages procéduraux étendus), elles possèdent dans les deux cas les mêmes aspects fondamentaux qu'un système de base de données relationnelle. Elles sont compatibles avec les objets de base de données, les charges de travail multi-utilisateur simultanées et les transactions avec des propriétés ACID. Elles gèrent également les contentions de verrouillage avec plusieurs niveaux d'isolation (en fonction des besoins de l'application), et elles répondent aux exigences continues de l'application pour les opérations de traitement transactionnel en ligne (OLTP) et de traitement analytique en ligne (OLAP).
La section suivante présente un aperçu des principales différences fonctionnelles entre Oracle et Cloud SQL pour PostgreSQL. Dans certains cas, s'il est nécessaire de mettre en évidence les différences, cette section inclut des comparaisons techniques détaillées.
Créer et afficher des bases de données
| Oracle 11g/12c | Cloud SQL pour PostgreSQL 12 |
|---|---|
Généralement, vous créez des bases de données et consultez celles qui existent déjà à l'aide de l'assistant de configuration de bases de données Oracle. Les bases de données ou instances créées manuellement nécessitent la spécification de paramètres supplémentaires :SQL> CREATE DATABASE ORADB
|
Utilisez une instruction au format CREATE DATABASE Name;, comme dans cet exemple :postgres=> CREATE DATABASE PGSQLDB; |
| Oracle 12c | Cloud SQL pour PostgreSQL 12 |
Dans Oracle 12c, vous pouvez créer des bases de données connectables (PDB) à partir d'un modèle de base de données de conteneurs (CDB) ou en clonant une PDB à partir d'une PDB existante. Vous devez utilisez plusieurs paramètres :SQL> CREATE PLUGGABLE DATABASE PDB
|
Utilisez une instruction au format CREATE DATABASE Name;, comme dans cet exemple :postgres=> CREATE DATABASE PGSQLDB; |
Répertoriez toutes les PDB :SQL> SHOW is PDBS; |
Répertoriez toutes les bases de données existantes :postgres=> \list |
Connectez-vous à une autre PDB :SQL> ALTER SESSION SET CONTAINER=pdb; |
Connectez-vous à une autre base de données :postgres=> \connect databaseName;
ou : postgres=> \c databaseName |
Ouvrez ou fermez une PDB spécifique (ouverte/en lecture seule) :SQL> ALTER PLUGGABLE DATABASE pdb CLOSE; |
Non compatible avec une base de données unique. Toutes les bases de données se trouvent dans la même instance Cloud SQL pour PostgreSQL. Par conséquent, toutes les bases de données sont soit actives, soit inactives. |
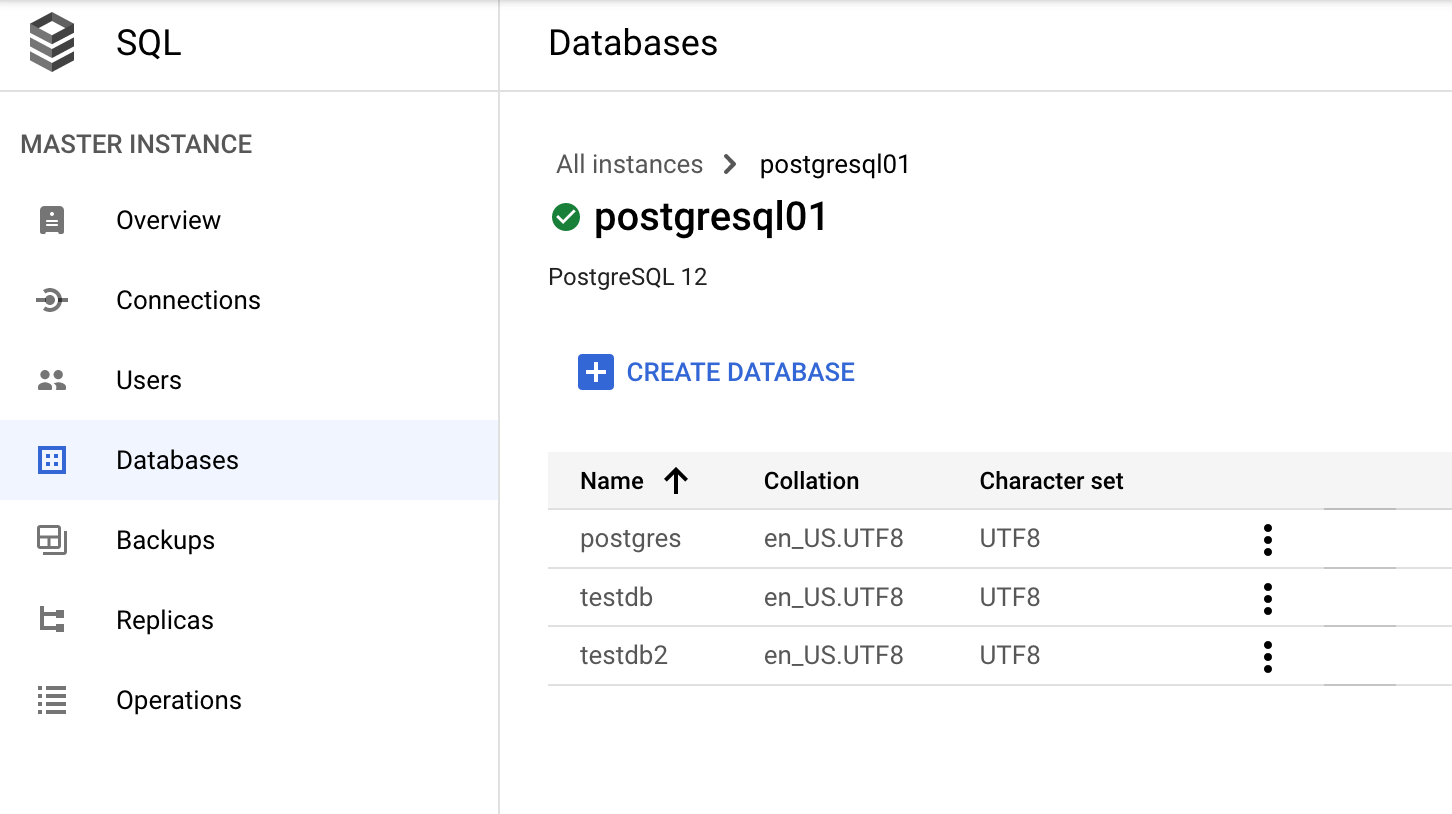
Gérer une base de données via la console Google Cloud
Dans la Google Cloud console, accédez à Databases (Bases de données)> SQL> Instance> (Sélectionnez votre instance PostgreSQL)> Databases (Bases de données).
Dictionnaire de données et affichages dynamiques
Les bases de données Oracle fournissent un dictionnaire de données avec des affichages de performances dynamiques (vues V$) qui facilitent diverses tâches de maintenance et de surveillance des bases de données. Le dictionnaire de données stocke toutes les informations utilisées pour gérer les objets de la base de données, tandis que les affichages dynamiques des performances contiennent de nombreuses informations liées aux performances de la base de données. Ces affichages sont mis à jour en continu pendant l'exécution de la base de données.
En revanche, PostgreSQL propose plusieurs catalogues de métadonnées ayant un objectif semblable au dictionnaire de données et aux affichages dynamiques des performances d'Oracle :
- Catalogue système : métadonnées sur tous les objets de la base de données.
- Vues de collecte de statistiques : rapports sur les activités de PostgreSQL.
- Vues de schéma d'informations : métadonnées relatives à tous les objets de base de données signalés conformément à la norme SQL ANSI.
Afficher les métadonnées et les vues dynamiques du système
Cette section présente les principales tables de métadonnées et affichages dynamiques du système utilisés dans Oracle, ainsi que les objets de base de données correspondants dans Cloud SQL pour PostgreSQL version 12.
Oracle fournit des centaines de tables de métadonnées système et de vues (dans certains schémas système, par exemple SYS ou SYSTEM), tandis que PostgreSQL ne contient que plusieurs dizaines. Pour chaque cas, il peut y avoir plusieurs objets de base de données, avec un objectif spécifique.
Oracle fournit plusieurs niveaux d'objets de métadonnées, chacun nécessitant des droits différents :
USER_TableName: visible par l'utilisateur.ALL_TableName: visible par tous les utilisateurs.DBA_TableName: visible uniquement par les utilisateurs disposant du droit DBA, tels queSYSetSYSTEM.
Pour les vues de performances dynamiques, Oracle utilise les préfixes V$/GV$. En revanche, les métadonnées et les vues Cloud SQL pour PostgreSQL résident dans les schémas information_schema et pg_catalog.
| Type de métadonnées | Table/vue Oracle | Table/vue/requête Cloud SQL pour PostgreSQL |
|---|---|---|
| Sessions ouvertes | V$SESSION |
pg_catalog.pg_stat_activity |
| Exécution de transactions | V$TRANSACTION |
Non compatible. Pour contourner ce problème, pg_locks fournit une liste de transactions ouvertes contenant un ou plusieurs verrous. |
| Objets de base de données | DBA_OBJECTS |
pg_catalog.pg_class |
| Tables | DBA_TABLES |
pg_catalog.pg_tables |
| Colonnes de table | DBA_TAB_COLUMNS |
pg_catalog.pg_attribute |
| Droits sur les tables et colonnes | TABLE_PRIVILEGES |
information_schema.table_privileges
information_schema.column_privileges |
| Partitions | DBA_TAB_PARTITIONS
DBA_TAB_SUBPARTITIONS |
pg_catalog.pg_partitioned_table |
| Vues | DBA_VIEWS |
pg_catalog.pg_views |
| Contraintes | DBA_CONSTRAINTS |
pg_catalog.pg_constraint |
| Index | DBA_INDEXES |
pg_catalog.pg_index |
| Vues matérialisées | DBA_MVIEWS |
pg_catalog.pg_matviews |
| Procédures stockées | DBA_PROCEDURES |
pg_catalog.pg_proc |
| Fonctions stockées | DBA_PROCEDURES |
pg_catalog.pg_proc |
| Déclencheurs | DBA_TRIGGERS |
pg_catalog.pg_trigger |
| Utilisateurs | DBA_USERS |
pg_catalog.pg_user |
| Droits d'utilisateur | DBA_SYS_PRIVS |
pg_catalog.pg_roles |
| Tâches/ programmateur |
DBA_JOBS |
Non compatible. |
| Espaces de table | DBA_TABLESPACES |
pg_catalog.pg_tablespace |
| Fichiers de données | DBA_DATA_FILES |
Non compatible. |
| Synonymes | DBA_SYNONYMS |
Non compatible. |
| Séquences | DBA_SEQUENCES |
pg_catalog.pg_sequence |
| Liens de base de données | DBA_DB_LINKS |
pg_catalog.pg_foreign_server |
| Statistiques | DBA_TAB_STATISTICS
DBA_TAB_COL_STATISTICS
DBA_SQLTUNE_STATISTICS
DBA_CPU_USAGE_STATISTICS |
pg_catalog.pg_stats |
| Verrous | DBA_LOCK |
pg_catalog.pg_locks |
| Paramètres de base de données | V$PARAMETER |
pg_catalog.pg_settings
show |
| Segments | DBA_SEGMENTS |
Non compatible. |
| Rôles | DBA_ROLES |
pg_catalog.pg_roles |
| Historique des sessions | V$ACTIVE_SESSION_HISTORY |
Non compatible. |
| Version | V$VERSION |
select version(); |
| Événements d'attente | V$WAITCLASSMETRIC |
Non compatible. |
| Optimisation et analyse SQL |
V$SQL |
Non compatible. |
| Réglage de la mémoire de l'instance |
V$SGA
V$SGASTAT
V$SGAINFO
V$SGA_CURRENT_RESIZE_OPS
V$SGA_RESIZE_OPS
V$SGA_DYNAMIC_COMPONENTS
V$SGA_DYNAMIC_FREE_MEMORY
V$PGASTAT |
Non intégré à Cloud SQL pour PostgreSQL. Utilisez l'extension pg_buffercache pour examiner le cache des tampons partagé en temps réel. |
Paramètres système
Les bases de données Oracle et Cloud SQL pour PostgreSQL peuvent être spécifiquement configurées pour offrir certaines fonctionnalités non disponibles avec la configuration par défaut. Pour modifier les paramètres de configuration dans Oracle, certaines autorisations d'administration sont requises (principalement les autorisations utilisateur SYS/SYSTEM).
Voici un exemple de modification de la configuration Oracle à l'aide de l'instruction ALTER SYSTEM. Dans cet exemple, l'utilisateur modifie le paramètre "Nombre maximal d'échecs de connexion" au niveau de la configuration spfile (la modification n'est valide qu'après un redémarrage) :
SQL> ALTER SYSTEM SET SEC_MAX_FAILED_LOGIN_ATTEMPTS=2 SCOPE=spfile;
Dans l'exemple suivant, l'utilisateur demande à afficher la valeur du paramètre Oracle :
SQL> SHOW PARAMETER SEC_MAX_FAILED_LOGIN_ATTEMPTS;
Le résultat ressemble à ce qui suit :
NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ sec_max_failed_login_attempts integer 2
La modification du paramètre Oracle fonctionne dans trois champs d'application :
- SPFILE : les modifications de paramètres sont écrites dans le fichier
spfiled'Oracle. Un redémarrage de l'instance est nécessaire pour que le changement prenne effet. - MÉMOIRE : les modifications de paramètres ne sont appliquées à la couche mémoire que lorsqu'aucun changement de paramètre statique n'est autorisé.
- LES DEUX : les modifications de paramètres sont appliquées à la fois dans le fichier de paramètres du serveur et dans la mémoire de l'instance, où aucun changement de paramètre statique n'est autorisé.
Options de configuration Cloud SQL pour PostgreSQL
Vous pouvez modifier les paramètres système de Cloud SQL pour PostgreSQL à l'aide des options de configuration dans la console Google Cloud , gcloud CLI ou CURL. Consultez la liste complète des paramètres compatibles avec Cloud SQL pour PostgreSQL que vous pouvez modifier.
Les paramètres PostgreSQL peuvent être divisés en plusieurs catégories :
- Paramètres dynamiques : ces éléments peuvent être modifiés lors de l'exécution de la base de données.
- Paramètres de base de données : ne s'appliquent qu'à une base de données spécifique dans une instance PostgreSQL.
- Paramètres de rôle : ne s'appliquent qu'à un rôle de base de données spécifique.
- Paramètres statiques : un redémarrage de l'instance est nécessaire pour que la modification prenne effet.
- Paramètres de session : ces éléments ne peuvent être modifiés au niveau de la session que pour la durée de la session en cours, et sont exclus des autres sessions.
- Paramètres globaux : ces éléments ont un effet global sur toutes les sessions en cours et à venir.
Exemples de modification des paramètres Cloud SQL pour PostgreSQL
Console
Utilisez la console Google Cloud pour activer le paramètre log_connections.
Accédez à la page Modifier l'instance de Cloud Storage.
Sous Options, cliquez sur Ajouter un élément et recherchez
log_connections, comme dans la capture d'écran suivante.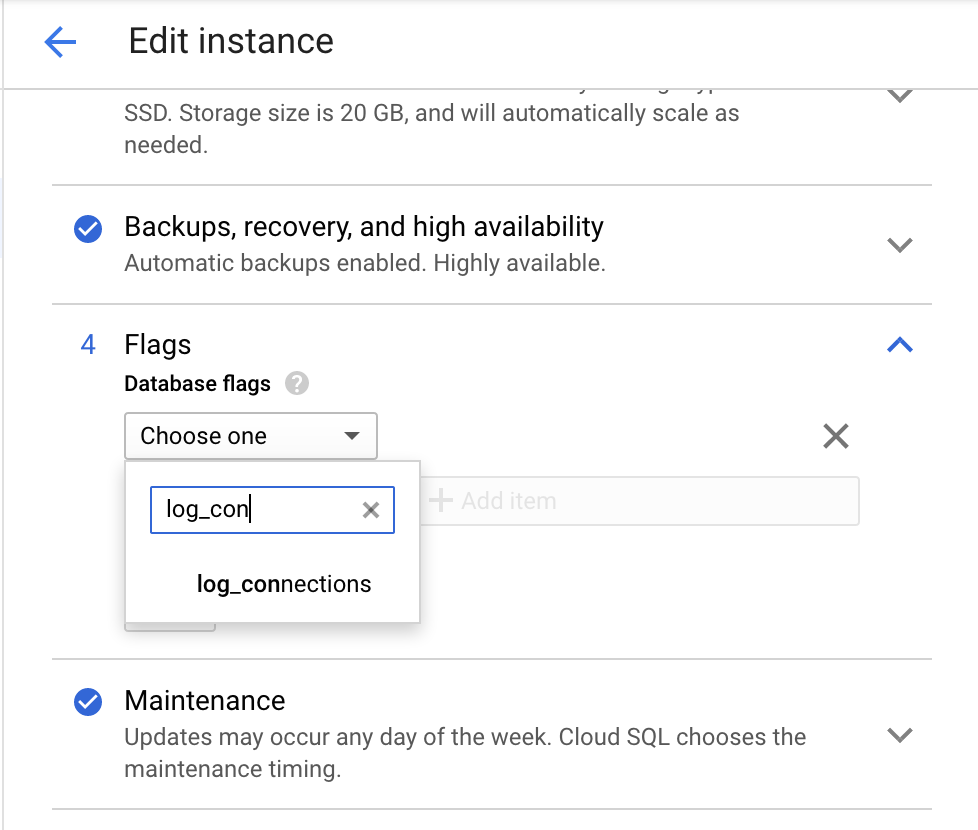
gcloud
- Utilisez gcloud CLI pour activer le paramètre
log_connections:
gcloud sql instances patch INSTANCE_NAME \
--database-flags log_connections=on
Le résultat est le suivant :
WARNING: This patch modifies database flag values, which may require your instance to be restarted. Check the list of supported flags - /sql/docs/postgres/flags - to see if your instance will be restarted when this patch is submitted. Do you want to continue (Y/n)?
Cloud SQL pour PostgreSQL
Définissez timezone au niveau de la session. Cette modification reste en vigueur pour la session en cours et ne s'applique qu'à la durée de cette session.
Afficher le paramètre de configuration
timezone:postgres=> SHOW timezone;Le résultat suivant s'affiche, dans lequel
timezoneest défini surset to UTC:TimeZone ---------- UTC (1 row)
Définissez
timezonesur UTC-9 :postgres=> SET timezone='UTC-9';Afficher le paramètre de configuration
timezone:postgres> SHOW timezone;Le résultat suivant s'affiche, dans lequel
timezoneest défini surUTC-9:TimeZone ---------- UTC-9 (1 row)
Transactions et niveaux d'isolation
Cette section décrit les principales différences d'exécution et de niveaux d'isolation des transactions entre Oracle et Cloud SQL pour PostgreSQL.
Mode de commit
Par défaut, Oracle ne fonctionne pas en mode autocommit, ce qui signifie que chaque transaction LMD doit être déterminée à l'aide des instructions COMMIT/ROLLBACK. L'une des principales différences entre Oracle et PostgreSQL est que PostgreSQL émet un message COMMIT après chaque commande qui ne suit pas START TRANSACTION (ou BEGIN). C'est également le cas de certains autres moteurs de base de données.
Bien que le commit automatique soit activé par défaut, il peut être désactivé au niveau de la session à l'aide de SET AUTOCOMMIT OFF.
Niveaux d'isolation
La norme SQL ANSI/ISO (SQL :92) définit quatre niveaux d'isolation. Chaque niveau fournit une approche différente pour gérer l'exécution simultanée de transactions de base de données :
- Read Uncommitted : une transaction en cours de traitement peut afficher les données non validées générées par l'autre transaction. Si un rollback est effectué, toutes les données sont restaurées à leur état précédent.
- Read Committed : une transaction ne voit que les modifications de données validées, les modifications non validées ("lectures sales") ne sont pas possibles.
- Repeatable Read : une transaction ne peut afficher les modifications apportées par l'autre transaction qu'une fois que les deux transactions ont émis un
COMMITou que les deux ont été annulées. - Serializable : niveau d'isolation le plus strict et contraignant. Ce niveau verrouille tous les enregistrements accessibles et la ressource afin que les enregistrements ne puissent pas être ajoutés à la table.
Les niveaux d'isolation des transactions gèrent la la façon dont les données modifiées peuvent être vues par les autres transactions en cours d'exécution. En outre, lorsque plusieurs transactions simultanées accèdent aux mêmes données, le niveau d'isolation sélectionné affecte la manière dont les différentes transactions interagissent.
Oracle est compatible avec les niveaux d'isolation suivants :
- Read Committed (par défaut)
- Serializable
- Lecture seule (ne fait pas partie de la norme SQL ANSI/ISO (SQL:92))
Contrôle de simultanéité multiversion Oracle (MVCC, Multiversion Concurrence Control) :
- Oracle utilise le mécanisme MVCC pour fournir une cohérence de lecture automatique sur l'ensemble de la base de données et des sessions.
- Oracle s'appuie sur le numéro de modification du système (SCN, System Change Number) de la transaction actuelle pour obtenir une vue cohérente de la base de données. Par conséquent, toutes les requêtes de base de données ne renvoient que des données validées par rapport au SCN au moment de l'exécution de la requête.
- Les niveaux d'isolation peuvent être modifiés au niveau des transactions et des sessions.
Voici un exemple de définition de niveaux d'isolation :
-- Transaction Level
SQL> SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SQL> SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SQL> SET TRANSACTION READ ONLY;
-- Session Level
SQL> ALTER SESSION SET ISOLATION_LEVEL = SERIALIZABLE;
SQL> ALTER SESSION SET ISOLATION_LEVEL = READ COMMITTED;
Cloud SQL pour PostgreSQL est compatible avec les quatre niveaux d'isolation des transactions suivants, spécifiés dans la norme ANSI SQL:92:
- Read Uncommitted (équivalent à Read Committed)
- Read Committed (par défaut)
- Repeatable Read
- Serializable
Le niveau d'isolation par défaut de Cloud SQL pour PostgreSQL est READ COMMITTED.
Ces niveaux d'isolation peuvent être modifiés aux niveaux SESSION, TRANSACTION et INSTANCE.
Pour vérifier les niveaux d'isolation actuels au niveau TRANSACTION et au niveau SESSION, utilisez l'instruction suivante :
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
Le résultat est le suivant :
current_setting ----------------- read committed (1 row)
Vous pouvez modifier la syntaxe du niveau d'isolation comme suit :
SET [SESSION CHARACTERISTICS AS] TRANSACTION ISOLATION LEVEL [ REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED | SERIALIZABLE]
Vous pouvez également modifier le niveau d'isolation au niveau de la SESSION :
postgres=> SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- Verify
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
Le résultat est le suivant :
current_setting ----------------- repeatable read (1 row)
Le niveau d'isolation défini au niveau INSTANCE est contrôlé à l'aide de l'option de base de données
default_transaction_isolation. Vous pouvez vérifier cela à l'aide de l'instruction suivante :
postgres=> SHOW DEFAULT_TRANSACTION_ISOLATION;
Le résultat est le suivant :
default_transaction_isolation ------------------------------- repeatable read (1 row)
Étape suivante
- En savoir plus sur les comptes utilisateur Cloud SQL pour PostgreSQL.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.