This document is part of a series that provides key information and guidance related to planning and performing Oracle® 11g/12c database migrations to Cloud SQL for PostgreSQL version 12. In addition to the introductory setup part, the series includes the following parts:
- Migrating Oracle users to Cloud SQL for PostgreSQL: Terminology and functionality
- Migrating Oracle users to Cloud SQL for PostgreSQL: Data types, users, and tables
- Migrating Oracle users to Cloud SQL for PostgreSQL: Queries, stored procedures, functions, and triggers
- Migrating Oracle users to Cloud SQL for PostgreSQL: Security, operations, monitoring, and logging (this document)
- Migrating Oracle Database users and schemas to Cloud SQL for PostgreSQL
Security
This section offers guidance on encryption, auditing, and access control.
Encryption
Both Oracle and Cloud SQL for PostgreSQL offer data encryption mechanisms to add an additional protection layer beyond basic user authentication and user-privilege management.
Encryption at rest
Data that is not moving through networks (stored) is known as "data at rest." Oracle offers the TDE (Transparent Data Encryption) mechanism to add an encryption layer at the operating system level. In Cloud SQL, data is encrypted using 256-bit Advanced Encryption Standard (AES-256), or better. These data keys are encrypted using a master key stored in a secure keystore and changed regularly. For more information about encryption at rest, see Encryption at rest in Google Cloud.
Encryption in transit
Oracle offers Advanced Security for handling encryption of data over the network. Cloud SQL encrypts and authenticates all data in transit at one or more network layers when data moves outside physical boundaries not controlled by Google or on behalf of Google. Data in transit inside a physical boundary controlled by or on behalf of Google is generally authenticated but might not be encrypted by default. You can choose which additional security measures to apply based on your threat model. For example, you can configure SSL for intra-zone connections to Cloud SQL. For information about encryption in transit, see Encryption in transit in Google Cloud.
Auditing
Oracle provides several methods for auditing (for example, standard and fine-grained auditing). In contrast, auditing in Cloud SQL for PostgreSQL can be achieved by the following means:
- pgAudit extension. Record and track SQL operations performed against a given database instance.
- Cloud Audit Logs. Audit administrative and maintenance operations done on a Cloud SQL for PostgreSQL instance.
Access control
Users can connect to the Cloud SQL for PostgreSQL instance by using a PostgreSQL client with an authorized static IP address or by using Cloud SQL Proxy, like any other database connection. For other connection sources such as App Engine or Compute Engine, users have several options such as using Cloud SQL Proxy. For more information about these options, see instance access control.
Cloud SQL for PostgreSQL integrates with Identity and Access Management (IAM) and provides a set of predefined roles designed to help you control access to your Cloud SQL resources. These roles allow IAM users to initiate various administrative operations such as instance restarts, backups, and failovers. See project access control for more information.
Operations
This section offers guidance on export and import operations, instance-level backup and restore, and standby instances for read-only operations and disaster recovery implementation.
Export and import
Oracle's main method for performing logical export and import operations is the
Data Pump utility,
using the EXPDP/IMPDP commands (an older version of Oracle export/import
functionality included the exp/imp commands). The
Cloud SQL for PostgreSQL equivalent commands are the pg_dump and the
pg_restore utilities, which generate dump files and then import at a database
or object level (including exporting and importing metadata only).
There is no direct Cloud SQL for PostgreSQL equivalent solution for the
Oracle DBMS_DATAPUMP utility (the Oracle method to apply the EXPDP/IMPDP
functionality interacts directly with the DBMS_DATAPUMP package). To convert
from Oracle DBMS_DATAPUMP PL/SQL code, use alternative code (for example, Bash
and Python) to implement logical elements and the Cloud SQL for PostgreSQL
programs pg_dump and pg_restore to run export/import operations.
Oracle SQL*Loader can be used to load external files into database tables. SQL*Loader can use a configuration file (called a control file), which holds the metadata used by SQL*Loader to determine how data should be parsed and loaded into the Oracle database. SQL*Loader supports both fixed and variable source files.
The pg_dump and pg_restore utilities run at the client level and connect
remotely to the Cloud SQL for PostgreSQL instance. Dump files are created at
the client side. To load external files into Cloud SQL for PostgreSQL, use
the COPY command from the psql client interface, or use Dataflow or
Dataproc. This section focuses primarily on the
Cloud SQL for PostgreSQL COPY command, which is a more direct equivalent
to Oracle's SQL*Loader utility.
For more complex data loads into your Cloud SQL for PostgreSQL database, consider using Dataflow or Dataproc, which involves creating an ETL process.
For more information about Dataflow, see the Dataflow documentation, and for more information about Dataproc, see the Dataproc documentation.
pg_dump
The
pg_dump
client utility performs consistent backups and output in script or archive file
formats. Script dump is a set of SQL statements that can be executed to
reproduce the original database object definitions and table data. These SQL
statements could be fed to any PostgreSQL client for restore. Backups in archive
file formats must be used with pg_restore during restore operations, but
backups allow selective objects to be restored and are designed to be portable
across architectures.
Usage:
-- Single database backup & specific tables backup # pg_dump database_name > outputfile.sql # pg_dump -t table_name database_name > outputfile.sql -- Dump all tables in a given schema with a prefix and ignore a given table # pg_dump -t 'schema_name.table_prefixvar>*' -T schema_name.ignore_table database_name > outputfile.sql -- Backup metadata only - Schema only # pg_dump -s database_name > metadata.sql -- Backup in custom-format archive pg_dump -Fc database_name > outputfile.dump
pg_restore
The
pg_restore
client program restores a PostgreSQL database from an archive created by
pg_dump. If a database name is not specified, pg_restore outputs a script
containing the SQL commands necessary to rebuild the database similar to the
pg_dump.
Usage:
-- Connect to an existing database and restore the backup archive
pg_restore -d database_name outputfile.dump
-- Create and restore the database from the backup archive
pg_restore -C -d database_name outputfile.dump
psql COPY command
psql is a command-line client interface to Cloud SQL for PostgreSQL. With
the
COPY
command, psql reads the file specified in the command arguments and routes the
data between the server and the local file system.
Usage:
-- Connect to an existing database and restore the backup archive psql -p 5432 -U username -h cloud_sql_instance_ip -d database_name -c "\copy emps from '/opt/files/inputfile.csv' WITH csv;" -W
Cloud SQL for PostgreSQL export/import:
The following documentation links illustrate how to use the gcloud CLI to interact with the Cloud SQL instance and with Cloud Storage in order to apply Export and Import operations.
Instance-level backup and restore
In Cloud SQL, backup and recovery tasks are handled through automated and on-demand database backups.
Backups provide a way to restore your Cloud SQL instance to recover lost data or recover from a problem with your instance. We recommend that you enable automated backups for any instance that contains data that you need to protect from loss or damage.
You can create a backup at any time, which is useful if you are about to perform a risky operation on your database, or if you need a backup and don't want to wait for the backup window. You can create on-demand backups for any instance, whether the instance has automatic backups enabled or not.
On-demand backups are not automatically deleted the way automated backups are. They persist until you delete them or until their instance is deleted. Because they are not automatically deleted, on-demand backups can have a long-term effect on your billing charges if you don't delete them
When you enable automated backups, you specify a 4-hour backup window. The backup starts during this window. When possible, schedule backups when your instance has the least activity. If your data has not changed since your last backup, no backup is taken.
Cloud SQL retains up to 7 automated backups for each instance. The storage used by backups is charged at a reduced rate depending on the region where the backups are stored. For more about the pricing list, see Cloud SQL for PostgreSQL pricing.
You can use Cloud SQL for PostgreSQL database instance restoration to restore to the same instance, overwrite existing data, or restore to a different instance. Cloud SQL for PostgreSQL also lets you restore a PostgreSQL database to a specific point in time with the automated backup option enabled.
For more information about how to create or manage on-demand and automatic backups, see Creating and managing on-demand and automatic backups.
The following table lists the common backup and restore operations in Oracle and their equivalent in Cloud SQL for PostgreSQL:
| Description | Oracle (Recovery Manager - RMAN) |
Cloud SQL for PostgreSQL |
|---|---|---|
| Scheduled automatic backups | Create a DBMS_SCHEDULER job that will execute your
RMAN script on a scheduled basis. |
gcloud sql instances patch INSTANCE_NAME --backup-start-time HH:MM
|
| Manual full database backups | BACKUP DATABASE PLUS ARCHIVELOG;
|
gcloud sql backups create --async --instance INSTANCE_NAME
|
| Restore database | RUN
|
gcloud sql backups list --instance INSTANCE_NAME
|
| Incremental differential | BACKUP INCREMENTAL LEVEL 0 DATABASE;
|
All backups are incremental, with no option to choose incremental type. |
| Incremental cumulative | BACKUP INCREMENTAL LEVEL 0 CUMULATIVE DATABASE;
|
All backups are incremental, with no option to choose incremental type. |
| Restore database to a specific point in time | RUN
|
gcloud sql instances clone SOURCE_INSTANCE_NAME NEW_INSTANCE_NAME \
|
| Backup database archive logs | BACKUP ARCHIVELOG ALL;
|
Not supported. |
Standby instances for read-only operations and disaster recovery implementation
Oracle Active Data Guard allows a standby instance to serve as a read-only endpoint while new data is still being applied through the redo and archive logs. You can also use Oracle GoldenGate to enable an additional instance for read purposes while data modifications are applied in real time, serving as a Change Data Capture (CDC) solution.
Cloud SQL for PostgreSQL uses a standby instance for high availability. This instance is kept in sync with the primary instance through disk-level replication. Unlike Active Data Guard, it's not open for reads or writes. When the primary goes down or becomes unresponsive for approximately 60 seconds, the primary automatically fails over to the standby instance. Within a few seconds, the roles swap and the new primary takes over.
Cloud SQL for PostgreSQL also offers read-replicas to scale read requests. They are designed to offload reads from the primary instance, not serve as a standby instance for disaster recovery. Unlike the standby instance, read replicas are kept in sync with the primary asynchronously. They can be in a different zone from the primary and also in a different region. You can create a read replica by using the Google Cloud console or the gcloud CLI. Note that some operations require an instance reboot (for example, adding high availability to an existing primary instance).
Logging and monitoring
Oracle's alert log file is the main source for identifying general system events and error events in order to understand any Oracle database instance lifecycle (mainly troubleshooting failure events and error events).
The Oracle alert log displays information about the following:
- Oracle database instance errors and warnings (
ORA-+ error number). - Oracle database instance startup and shutdown events.
- Network and connection related issues.
- Database redo logs switching events.
- Oracle trace files might be mentioned with a link for additional details regarding a specific database event.
Oracle provides dedicated log files for different services such as LISTENER, ASM, and Enterprise Manager (OEM), which do not have equivalent components in Cloud SQL for PostgreSQL.
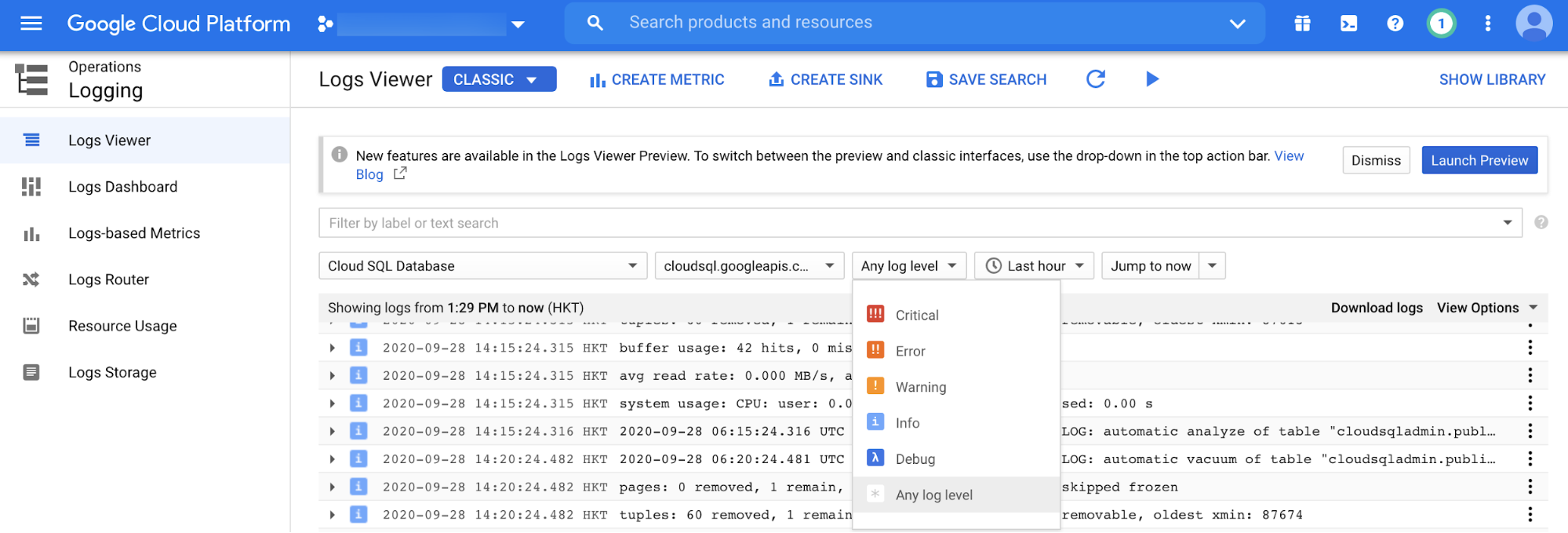
Viewing Cloud SQL for PostgreSQL operation logs
Cloud Logging
is the main platform to view all log entries in postgres.log (the equivalent
of alert.log in Oracle). You can filter by the log event level (for example,
Critical, Error, or Warning). Event timeframe and free text filtering are also
available.
Cloud SQL for PostgreSQL database instance monitoring
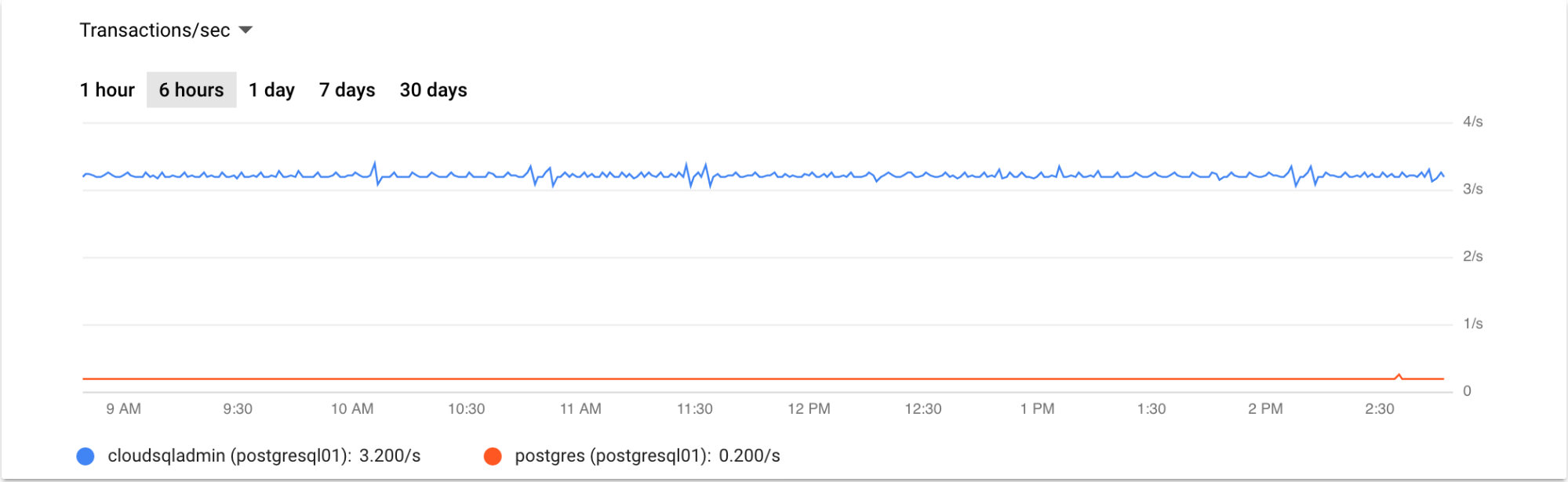
Oracle's main UI monitoring dashboards are part of the OEM and Grid/Cloud Control products (for example, Top Activity Graphs) and are useful for real-time database instance monitoring at the session or SQL statement level. Cloud SQL for PostgreSQL provides similar monitoring capabilities using the Google Cloud console. You can view summarized information about the Cloud SQL for PostgreSQL database instances with multiple monitoring metrics such as CPU utilization, storage usage, memory usage, read/write operations, ingress/egress bytes, active connections, and more.
Cloud Logging supports additional monitoring metrics for Cloud SQL for PostgreSQL. The following screenshot shows a Cloud SQL for PostgreSQL queries graph for the last 12 hours.
Cloud SQL for PostgreSQL read-replica monitoring
You can monitor read-replicas the same way you monitor the primary instance, using the Google Cloud console monitoring metrics (as described earlier). Also, there is a dedicated monitoring metric for monitoring the replication delay—determining the lag between the primary instance to the read-replica instance in bytes (can be monitored from the read-replica instance overview tab in the Google Cloud console).
You can use the gcloud CLI to retrieve the replication status:
gcloud sql instances describe REPLICA_NAME
You can also do replication monitoring by using commands from a PostgreSQL client, which provides the status of the primary and standby databases.
You can use the following SQL statement to verify the read-replica status:
postgres=> select * from pg_stat_replication;
Cloud SQL for PostgreSQL monitoring
This section describes basic Cloud SQL for PostgreSQL monitoring methods that are considered routine tasks performed by a database administrator (DBA) like Oracle or Cloud SQL for PostgreSQL.
Session monitoring
Oracle session monitoring is done by querying the dynamic performance views
known as the "V$" views. The V$SESSION and V$PROCESS views are commonly used
to gain real-time insights about current database activity, using SQL
statements. You can monitor session activity by querying the
pg_stat_activity
dynamic view:
postgres=> select * from pg_stat_activity;
Long transaction monitoring
You can identify long-running queries by applying appropriate filters on
columns such as query_start and state in the
pg_stat_activity
dynamic view.
Lock monitoring
You can monitor database locks using the
pg_locks
dynamic view, which provides real-time information about lock occurrences that
might lead to performance issues.
What's next
- Explore more about Cloud SQL for PostgreSQL user accounts.
- Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.