In dieser Anleitung wird beschrieben, wie Sie ein Microsoft SQL Server-Datenbanksystem in zwei Google Cloud-Regionen als DR-Lösung (Disaster Recovery, Notfallwiederherstellung) bereitstellen und verwalten. Außerdem erfahren Sie, wie Sie von einer ausgefallenen Datenbankinstanz zu einer normal funktionierenden Instanz wechseln. Im Rahmen dieses Dokuments ist ein Notfall ein Ereignis, bei dem eine primäre Datenbank ausfällt bzw. unzulänglich wird.
Eine primäre Datenbank kann ausfallen, wenn die Region, in der sie sich befindet, ausfällt bzw. unzugänglich wird. Selbst wenn eine Region verfügbar ist und ordnungsgemäß funktioniert, kann eine primäre Datenbank aufgrund eines Systemfehlers ausfallen. In diesen Fällen besteht die Notfallwiederherstellung darin, Clients zur weiteren Verarbeitung eine sekundäre Datenbank zur Verfügung zu stellen.
Diese Anleitung richtet sich an Datenbankarchitekten, Administratoren und Entwickler.
Ziele
- Stellen Sie mithilfe der AlwaysOn-Verfügbarkeitsgruppen von Microsoft SQL Server eine multiregionale Notfallwiederherstellungsumgebung in Google Cloud bereit.
- Simulieren Sie ein Notfallereignis und führen Sie einen vollständigen Notfallwiederherstellungsprozess aus, um die Konfiguration der Notfallwiederherstellung zu validieren.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweis
Für diese Anleitung benötigen Sie ein Google Cloud-Projekt. Sie können ein neues Projekt erstellen oder ein vorhandenes Projekt auswählen:
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Aktivieren Sie Cloud Shell in der Google Cloud Console.
Informationen zur Notfallwiederherstellung
Bei Google Cloud ist die Notfallwiederherstellung darauf ausgerichtet, die Kontinuität der Verarbeitung zu gewährleisten, insbesondere wenn eine Region ausfällt bzw. unzugänglich wird. Systeme wie ein Datenbankverwaltungssystem werden in mindestens zwei Regionen bereitstellt, um die Notfallwiederherstellung zu implementieren. Bei dieser Einrichtung funktioniert das System weiterhin, wenn eine der Regionen ausfällt.
Notfallwiederherstellung von Datenbanksystemen
Das Verfügbarmachen einer sekundären Datenbank bei einem Ausfall der primären Datenbankinstanz wird als Datenbank-Notfallwiederherstellung (oder Datenbank-DR) bezeichnet. Weitere Informationen zu diesem Konzept finden Sie unter Notfallwiederherstellung für Microsoft SQL Server. Wenn die primäre Datenbank ausfällt, sollte der Zustand der sekundären Datenbank idealerweise dem Zustand der primären Datenbank entsprechen, oder der sekundären Datenbank sollte nur ein kleiner Satz der letzten Transaktionen aus der primären Datenbank fehlen.
Notfallwiederherstellungsarchitektur
Das folgende Diagramm zeigt für Microsoft SQL Server eine minimale Architektur, die die Datenbank-DR unterstützt.

Abbildung 1. Standardarchitektur für die Notfallwiederherstellung mit Microsoft SQL Server.
Diese Architektur funktioniert folgendermaßen:
- Zwei Instanzen von Microsoft SQL Server (eine primäre Instanz und eine Standby-Instanz) befinden sich in derselben Region (R1), aber in verschiedenen Zonen (Zonen A und B). Die beiden Instanzen in R1 koordinieren ihren Zustand mit dem synchronen Commit-Modus. Der synchrone Modus wird verwendet, da er Hochverfügbarkeit unterstützt und einen konsistenten Datenzustand beibehält.
- Eine Instanz von Microsoft SQL Server (die sekundäre oder die Notfallwiederherstellungsinstanz) befindet sich in einer zweiten Region (R2). Für die Notfallwiederherstellung wird die sekundäre Instanz in R2 mit der primären Instanz in R1 synchronisiert. Dazu wird der asynchrone Commit-Modus verwendet. Der asynchrone Modus wird aufgrund seiner Leistung verwendet. Die Commit-Verarbeitung in der primären Instanz wird dadurch nicht verlangsamt.
Im gezeigten Diagramm stellt die Architektur eine Verfügbarkeitsgruppe dar. Bei Verwendung mit einem Listener stellt die Verfügbarkeitsgruppe den Clients denselben Verbindungsstring bereit, wenn die Clients durch Folgendes bereitgestellt werden:
- Primäre Instanz
- Standby-Instanz (nach einem Zonenausfall)
- Sekundäre Instanz (nach einem Ausfall der Region und nachdem die sekundäre Instanz zur neuen primären Instanz geworden ist)
In einer Variante der obigen Architektur stellen Sie die beiden Instanzen in der ersten Region (R1) in derselben Zone bereit. Dieser Ansatz kann die Leistung verbessern, ist aber nicht hochverfügbar. Ein einzelner Zonenausfall ist möglicherweise erforderlich, um den DR-Prozess zu initiieren.
Grundlegender Notfallwiederherstellungsprozess
Der DR-Prozess wird gestartet, wenn eine Region ausfällt und die primäre Datenbank den Vorgang in einer anderen Betriebsregion fortsetzt. Der DR-Prozess schreibt die erforderlichen Betriebsschritte vor, die entweder manuell oder automatisch ausgeführt werden müssen, um dem Ausfall einer Region entgegenzuwirken und eine ausgeführte primäre Instanz in einer verfügbaren Region einzurichten.
Ein grundlegender DR-Prozess für die Datenbank besteht aus den folgenden Schritten:
- Die erste Region (R1), die die primäre Datenbankinstanz ausführt, fällt aus.
- Das operative Team erkennt und bestätigt offiziell den Notfall und entscheidet, ob ein Failover erforderlich ist.
- Wenn ein Failover erforderlich ist, wird die sekundäre Datenbankinstanz in der zweiten Region (R2) zur neuen primären Instanz.
- Clients setzen die Verarbeitung in der neuen primären Datenbank fort und greifen auf die primäre Instanz in R2 zu.
Dieser grundlegende Prozess richtet zwar eine funktionierende primäre Datenbank neu ein, doch wird keine vollständige DR-Architektur aufgebaut, in der die neue primäre Datenbank eine Standby- und eine sekundäre Datenbankinstanz hat.
Vollständiger Notfallwiederherstellungsprozess
Ein vollständiger DR-Prozess ergänzt den grundlegenden DR-Prozess durch Schritte, mit denen eine vollständige DR-Architektur nach einem Failover eingerichtet wird. Das folgende Diagramm zeigt eine vollständige Datenbank-DR-Architektur.
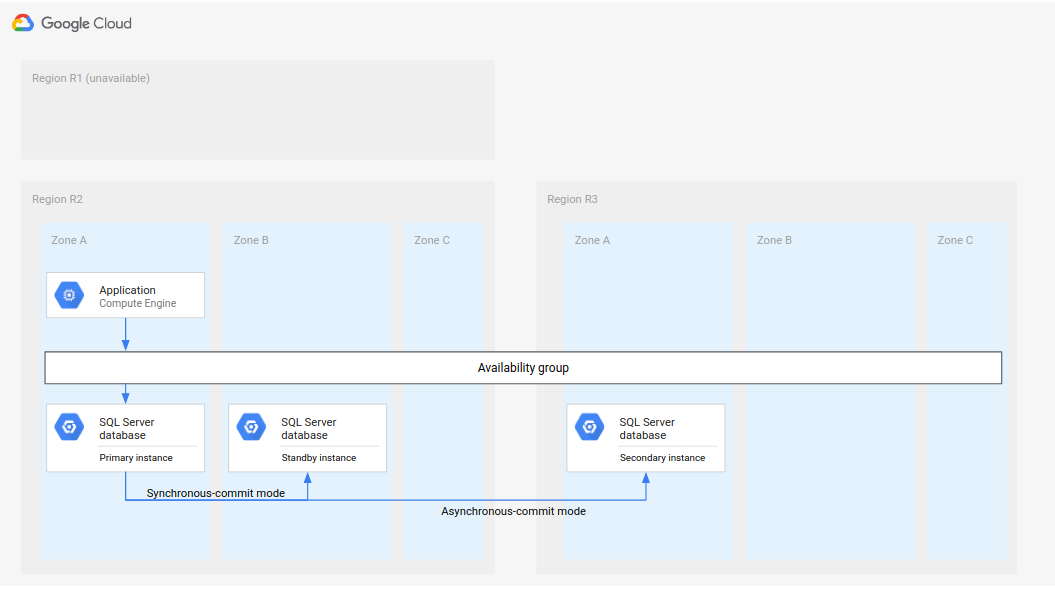
Abbildung 2. Notfallwiederherstellung bei dem Ausfall einer primären Region (R1).
Diese vollständige Datenbank-DR-Architektur funktioniert so:
- Die erste Region (R1), die die primäre Datenbankinstanz ausführt, fällt aus.
- Das operative Team erkennt und bestätigt offiziell den Notfall und entscheidet, ob ein Failover erforderlich ist.
- Wenn ein Failover erforderlich ist, wird die sekundäre Datenbankinstanz in der zweiten Region (R2) als primäre Instanz festgelegt.
- Eine weitere sekundäre Instanz, die neue Standby-Instanz, wird in R2 erstellt und gestartet und zur primären Instanz hinzugefügt. Die Standby-Instanz befindet sich in einer anderen Zone als die primäre Instanz. Die primäre Datenbank besteht nun aus zwei hochverfügbaren Instanzen (primäre Instanz und Standby-Instanz).
- In einer dritten Region (R3) wird eine neue sekundäre (Standby-Datenbankinstanz) erstellt und gestartet. Diese sekundäre Instanz ist asynchron mit der neuen primären Instanz in R2 verbunden. Die ursprüngliche Notfallwiederherstellungsarchitektur wird an diesem Punkt neu erstellt und ist verwendungsbereit.
Fallback zu einer wiederhergestellten Region
Sobald die erste Region (R1) wieder online ist, kann sie die neue sekundäre Datenbank hosten. Wenn R1 früh genug verfügbar ist, können Sie Schritt 5 im vollständigen Wiederherstellungsprozess in R1 statt in R3 (die dritte Region) implementieren. In diesem Fall ist keine dritte Region erforderlich.
Das folgende Diagramm zeigt die Architektur, wenn R1 rechtzeitig verfügbar wird.

Abbildung 3. Die Notfallwiederherstellung wird nach einem Ausfall der Region R1 wieder verfügbar.
In dieser Architektur sind die Wiederherstellungsschritte identisch mit denen, die weiter oben unter Vollständiger Notfallwiederherstellungsprozess beschrieben sind. Der einzige Unterschied besteht darin, dass R1 statt R3 zum Standort für die sekundären Instanzen wird.
SQL Server-Version auswählen
In dieser Anleitung werden die folgenden Versionen von Microsoft SQL Server unterstützt:
- SQL Server 2016 Enterprise Edition
- SQL Server 2017 Enterprise Edition
- SQL Server 2019 Enterprise Edition
In dieser Anleitung wird die Option "AlwaysOn Verfügbarkeitsgruppen" in SQL Server verwendet.
Wenn Sie keine primäre Microsoft SQL Server-Datenbank mit Hochverfügbarkeit (High Availability, HA) benötigen und eine einzelne Datenbankinstanz als primäre Datenbankdatenbank erforderlich ist, können Sie die folgenden SQL Server-Versionen verwenden:
- SQL Server 2016 Standard Edition
- SQL Server 2017 Standard Edition
- SQL Server 2019 Standard Edition
Bei den Versionen 2016, 2017 und 2019 von SQL Server ist Microsoft SQL Server Management Studio im Image installiert. Sie müssen das Programm nicht separat installieren. In einer Produktionsumgebung empfehlen wir jedoch, in jeder Region eine Instanz von Microsoft SQL Server Management Studio auf einer separaten VM zu installieren. Wenn Sie eine HA-Umgebung einrichten, sollten Sie Microsoft SQL Server Management Studio für jede Zone einmal installieren. So ist sichergestellt, dass die Instanz auch dann verfügbar bleibt, wenn eine andere Zone ausfällt.
Microsoft SQL Server für multiregionale Notfallwiederherstellung einrichten
In diesem Abschnitt wird das Image sql-ent-2016-win-2016 für Microsoft SQL Server 2016 Enterprise Edition verwendet. Wenn Sie Microsoft SQL Server 2017 Enterprise Edition installieren, verwenden Sie sql-ent-2017-win-2016. Verwenden Sie für Microsoft SQL Server 2019 Enterprise Edition sql-ent-2019-win-2019. Eine vollständige Liste der Images finden Sie unter Images.
HA-Cluster mit zwei Instanzen einrichten
Um eine multiregionale Datenbank-DR-Architektur für SQL Server einzurichten, müssen Sie zuerst einen HA-Cluster mit zwei Instanzen in einer Region erstellen. Eine Instanz dient als primäre und die andere als sekundäre Instanz. Folgen Sie der Anleitung unter Always On-Verfügbarkeitsgruppen von SQL Server konfigurieren, um diesen Schritt auszuführen.
In dieser Anleitung wird us-central1 für die primäre Region (mit der Bezeichnung R1) verwendet.
Lesen Sie zuerst die folgenden Hinweise.
Erstens: Wenn Sie die Schritte unter SQL Server Always On-Verfügbarkeitsgruppen konfigurieren ausführen, erstellen Sie zwei SQL Server-Instanzen in derselben Zone (us-central1-f). Diese Einrichtung schützt Sie nicht vor einem Ausfall von us-central1-f. Um Hochverfügbarkeit zu unterstützen, stellen Sie daher eine SQL Server-Instanz (cluster-sql1) in us-central1-c und eine zweite Instanz (cluster-sql2) in us-central1-f bereit. Die Schritte im nächsten Abschnitt (zum Hinzufügen einer sekundären Instanz für die Notfallwiederherstellung) gehen von dieser Bereitstellungskonfiguration aus.
Zweitens: Die Schritte unter SQL Server AlwaysOn-Verfügbarkeitsgruppen konfigurieren umfassen das Ausführen dieser Anweisung:
BACKUP DATABASE TestDB to disk = '\\cluster-sql2\SQLBackup\TestDB.bak' WITH INIT
Diese Anweisung führt dazu, dass die Standby-Instanz ausfällt. Führen Sie stattdessen den folgenden Befehl aus (der Name der Sicherungsdatei ist unterschiedlich):
BACKUP DATABASE TestDB to disk = '\\cluster-sql2\SQLBackup\TestDB-backup.bak' WITH INIT
Drittens: Führen Sie die Schritte unter SQL Server AlwaysOn-Verfügbarkeitsgruppen konfigurieren aus, um Sicherungsverzeichnisse zu erstellen. Sie verwenden diese Sicherungen nur, wenn Sie die primäre Instanz und die Standby-Instanz zu Beginn und nicht danach synchronisieren. Ein alternativer Ansatz zum Erstellen von Sicherungsverzeichnissen ist die Auswahl der Option Automatisches Seeding in diesen Schritten. Dieser Ansatz vereinfacht den Einrichtungsprozess.
Viertens: Wenn die Datenbanken nicht synchronisiert werden, führen Sie in cluster-sql2 den folgenden Befehl aus:
ALTER DATABASE [TestDB] SET HADR AVAILABILITY GROUP = [cluster-ag]
Fünftens: Erstellen Sie im Rahmen dieser Anleitung einen Domaincontroller in us-central1-f, wie im folgenden Diagramm dargestellt.

Abbildung 4. In dieser Anleitung implementierte Standardarchitektur zur Notfallwiederherstellung.
Obwohl Sie die vorherige Architektur für diese Anleitung implementiert haben, gilt es als Best Practice, einen Domaincontroller in mehreren Zonen einzurichten. Dieser Ansatz gewährleistet, dass eine HA- und DR-fähige Datenbankarchitektur eingerichtet wird. Wenn z. B. ein Ausfall in einer bestimmt Zone auftritt, wird diese Zone nicht als Single Point of Failure für die bereitgestellte Architektur angelegt.
Sekundäre Instanz für die Notfallwiederherstellung hinzufügen
Als Nächstes richten Sie eine dritte SQL Server-Instanz (eine sekundäre Instanz mit dem Namen cluster-sql3) und das Netzwerk ein:
Erstellen Sie in Cloud Shell unter derselben Virtual Private Cloud (VPC), die Sie für die primäre Region verwendet haben, ein Subnetz in der sekundären Region (
us-east1):gcloud compute networks subnets create wsfcsubnet4 --network wsfcnet \ --region us-east1 --range 10.3.0.0/24Ändern Sie die Firewallregel mit dem Namen
allow-internal-ports, damit das neue Subnetz Traffic erhält:gcloud compute firewall-rules update allow-internal-ports \ --source-ranges 10.0.0.0/24,10.1.0.0/24,10.2.0.0/24,10.3.0.0/24Die Regel
allow-internal-portsist in den Schritten aus der Anleitung enthalten, die Sie zuvor ausgeführt haben.Erstellen Sie eine SQL Server-Instanz:
gcloud compute instances create cluster-sql3 --machine-type n1-highmem-4 \ --boot-disk-type pd-ssd --boot-disk-size 200GB \ --image-project windows-sql-cloud --image-family sql-ent-2016-win-2016 \ --zone us-east1-b \ --network-interface "subnet=wsfcsubnet4,private-network-ip=10.3.0.4,aliases=10.3.0.5;10.3.0.6" \ --can-ip-forward --metadata sysprep-specialize-script-ps1="Install-WindowsFeature Failover-Clustering -IncludeManagementTools;"Legen Sie ein Windows-Passwort für die neue SQL Server-Instanz fest:
Rufen Sie in der Google Cloud Console die Seite „Compute Engine“ auf.
Wählen Sie in der Spalte Verbinden für den Compute Engine-Cluster
cluster-sql3die Drop-down-Liste Windows-Passwort festlegen aus.Legen Sie den Nutzernamen und das Passwort fest. Notieren Sie sie zur späteren Verwendung.
Klicken Sie auf RDP, um eine Verbindung zur Instanz
cluster-sql3herzustellen.Geben Sie den Nutzernamen und das Passwort aus Schritt 4 ein und klicken Sie auf OK.
Öffnen Sie als Administrator ein Windows PowerShell-Fenster und konfigurieren Sie das DNS und die geöffneten Ports:
netsh interface ip set dns Ethernet static 10.2.0.100 netsh advfirewall firewall add rule name="Open Port 5022 for Availability Groups" dir=in action=allow protocol=TCP localport=5022 netsh advfirewall firewall add rule name="Open Port 1433 for SQL Server" dir=in action=allow protocol=TCP localport=1433Fügen Sie die Instanz der Windows-Domain hinzu:
Add-Computer -DomainName "dbeng.com" -Credential "dbeng.com\Administrator" -Restart -ForceMit diesem Befehl wird die RDP-Verbindung beendet.
Sekundäre Instanz zum Failover-Cluster hinzufügen
Als Nächstes fügen Sie die sekundäre Instanz (cluster-sql3) dem Windows-Failovercluster hinzu:
Stellen Sie die Verbindung zu den Instanzen
cluster-sql1odercluster-sql2über RDP her und melden Sie sich als Administrator an.Öffnen Sie ein PowerShell-Fenster als Administrator und legen Sie Variablen für die Clusterumgebung in dieser Anleitung fest:
$node3 = "cluster-sql3" $nameWSFC = "cluster-dbclus" # Name of clusterFügen Sie dem Cluster die sekundäre Instanz hinzu:
Get-Cluster | WHERE Name -EQ $nameWSFC | Add-ClusterNode -NoStorage -Name $node3Die Ausführung dieses Befehls kann eine Weile dauern. Da es vorkommen kann, dass der Prozess nicht mehr automatisch antwortet und nicht automatisch zurückgegeben werden kann, drücken Sie gelegentlich
Enter.Aktivieren Sie im Knoten die Option "AlwaysOn Hohe Verfügbarkeit":
Enable-SqlAlwaysOn -ServerInstance $node3 -ForceErstellen Sie zwei Ordner unter
C:\SQLDataundC:\SQLLog, um die Datenbankdaten und Logdateien zu speichern:New-item -ItemType Directory "C:\SQLData" New-item -ItemType Directory "C:\SQLLog"
Der Knoten ist jetzt mit dem Failover-Cluster verbunden.
Sekundäre Instanz zur vorhandenen Verfügbarkeitsgruppe hinzufügen
Als Nächstes fügen Sie der Verfügbarkeitsgruppe die SQL Server-Instanz (die sekundäre Instanz) und die Datenbank hinzu:
Öffnen Sie in einem der drei Instanzknoten (
cluster-sql1,cluster-sql2odercluster-sql3) Microsoft SQL Server Management Studio und stellen Sie eine Verbindung zur primären Instanz (cluster-sql1) her:- Wechseln Sie zum Object Explorer.
- Wählen Sie die Drop-down-Liste Verbinden aus.
- Wählen Sie Datenbank-Engine aus.
- Wählen Sie in der Drop-down-Liste Servername die Option
cluster-sql1aus. Wenn der Cluster nicht aufgeführt ist, geben Sie ihn in das Feld ein.
Klicken Sie auf Neue Abfrage.
Fügen Sie den folgenden Befehl ein, um dem Listener, der für den Knoten verwendet wird, eine IP-Adresse hinzuzufügen. Klicken Sie dann auf Ausführen:
ALTER AVAILABILITY GROUP [cluster-ag] MODIFY LISTENER 'cluster-listene' (ADD IP ('10.3.0.6', '255.255.255.0'))Erweitern Sie im Object Explorer den Knoten AlwaysOn Hohe Verfügbarkeit und maximieren Sie den Knoten Verfügbarkeitsgruppen.
Klicken Sie mit der rechten Maustaste auf die Verfügbarkeitsgruppe
cluster-agund wählen Sie Replikat hinzufügen aus.Klicken Sie auf der Seite Einführung auf den Knoten AlwaysOn Hohe Verfügbarkeit und dann auf den Knoten Verfügbarkeitsgruppen.
Klicken Sie auf der Seite Mit Replikaten verbinden auf Verbinden, um eine Verbindung zum vorhandenen sekundären Replikat
cluster-sql2herzustellen.Klicken Sie auf der Seite Replikate angeben auf Replikat hinzufügen und fügen Sie dann den neuen Knoten
cluster-sql3hinzu. Wählen Sie Automatisches Failover nicht aus, da automatisches Failover zu einem synchronen Commit führt. Eine solche Einrichtung erstreckt sich über regionale Grenzen, die wir nicht empfehlen.Wählen Sie auf der Seite Datensynchronisierung auswählen die Option Automatisches Seeding aus.
Da es keinen Listener gibt, wird auf der Seite Validierung eine Warnung angezeigt, die Sie ignorieren können.
Führen Sie die Schritte des Assistenten aus.
Der Failover-Modus für cluster-sql1 und cluster-sql2 ist automatisch, für cluster-sql3 jedoch manuell. Hierin unterscheidet sich die Hochverfügbarkeit von der Notfallwiederherstellung.
Die Verfügbarkeitsgruppe ist jetzt bereit. Sie haben zwei Knoten für Hochverfügbarkeit und einen dritten Knoten für die Notfallwiederherstellung konfiguriert.
Eine Notfallwiederherstellung simulieren
In diesem Abschnitt testen Sie die DR-Architektur für diese Anleitung und ziehen optionale Implementierungen in Betracht.
Ausfall simulieren und ein DR-Failover ausführen
Simulieren Sie einen Fehler (Ausfall) in der primären Region:
Stellen Sie in Microsoft SQL Server Management Studio auf
cluster-sql1eine Verbindung zucluster-sql1her.Eine Tabelle erstellen Nachdem Sie in späteren Schritten Replikate hinzugefügt haben, prüfen Sie, ob das Replikat funktioniert. Dafür muss diese Tabelle vorhanden sein.
USE TestDB GO CREATE TABLE dbo.TestTable_Before_DR (ID INT NOT NULL) GOFahren Sie in Cloud Shell beide Server in der primären Region (
us-central1) herunter:gcloud compute instances stop cluster-sql2 --zone us-central1-f --quiet gcloud compute instances stop cluster-sql1 --zone us-central1-c --quiet
Stellen Sie in Microsoft SQL Server Management Studio auf
cluster-sql3eine Verbindung zucluster-sql3her.Führen Sie ein Failover aus und legen Sie für den Verfügbarkeitsmodus ein synchrones Commit fest. Das Erzwingen eines Failovers ist erforderlich, da sich der Knoten im asynchronen Commit-Modus befindet.
ALTER AVAILABILITY GROUP [cluster-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL3' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOSie können die Verarbeitung fortsetzen,
cluster-sql3ist jetzt die primäre Instanz.(Optional) Erstellen Sie eine neue Tabelle in
cluster-sql3. Nachdem Sie die Replikate mit der neuen primären Instanz synchronisiert haben, prüfen Sie, ob diese Tabelle auf die Replikate repliziert wird.USE TestDB GO CREATE TABLE dbo.TestTable_After_DR (ID INT NOT NULL) GO
Obwohl cluster-sql3 an diesem Punkt die primäre Instanz ist, sollten Sie ein Fallback auf die ursprüngliche Region ausführen oder eine neue sekundäre Instanz und eine Standby-Instanz einrichten, um eine vollständige DR-Architektur neu zu erstellen. Im nächsten Abschnitt werden diese Optionen erläutert.
(Optional) DR-Architektur neu erstellen, die Transaktionen vollständig repliziert
In diesem Anwendungsfall wird ein Ausfall beschrieben, bei dem alle Transaktionen von der primären in die sekundäre Datenbank repliziert werden, bevor die primäre Datenbank ausfällt. In diesem idealen Szenario gehen keine Daten verloren. Der Zustand der sekundären Datenbank ist zum Zeitpunkt des Ausfalls mit der primären Datenbank konsistent.
In diesem Szenario haben Sie zwei Möglichkeiten, eine vollständige DR-Architektur neu zu erstellen:
- Fallback auf die ursprüngliche primäre und die ursprüngliche Standby-Instanz (sofern diese verfügbar sind) ausführen.
- Neue Standby- und sekundäre Instanz für
cluster-sql3erstellen, falls die ursprüngliche primäre und die Standby-Instanz nicht verfügbar sind.
Ansatz 1: Fallback auf die ursprüngliche primäre und die Standby-Instanz ausführen
Starten Sie in Cloud Shell die ursprüngliche (alte) primäre Instanz und die Standby-Instanz:
gcloud compute instances start cluster-sql1 --zone us-central1-c --quiet gcloud compute instances start cluster-sql2 --zone us-central1-f --quietFügen Sie in Microsoft SQL Server Management Studio
cluster-sql1undcluster-sql2wieder als sekundäre Replikate hinzu:Fügen Sie unter
cluster-sql3die beiden Server im asynchronen Commit-Modus hinzu:USE [master] GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL1' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL2' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GOStarten Sie die Synchronisierung der Datenbanken unter
cluster-sql1noch einmal:USE [master] GO ALTER DATABASE [TestDB] SET HADR RESUME; GOStarten Sie die Synchronisierung der Datenbanken unter
cluster-sql2noch einmal:USE [master] GO ALTER DATABASE [TestDB] SET HADR RESUME; GO
Machen Sie
cluster-sql1wieder zur primären Version:Ändern Sie in
cluster-sql3den Verfügbarkeitsmodus voncluster-sql1zu einem synchronen Commit. Die Instanzcluster-sql1wird wieder zur primären Instanz.USE [master] GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOMachen Sie
cluster-sql1incluster-sql1zur primären Instanz und die beiden anderen Knoten zu sekundären Instanzen:USE [master] GO -- Node 1 becomes primary ALTER AVAILABILITY GROUP [cluster-ag] FAILOVER; GO -- Node 2 has synchronous commit ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO -- Node 3 has asynchronous commit ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL3' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO
Nachdem alle Befehle erfolgreich waren, ist cluster-sql1 die primäre Instanz und die anderen Knoten sind sekundäre Instanzen, wie das folgende Diagramm zeigt.

Ansatz 2: Neue primäre und Standby-Instanz einrichten
Es ist möglich, dass Sie die ursprünglichen primären und Standby-Instanzen nach dem Ausfall nicht wiederherstellen können, die Wiederherstellung zu lange dauert oder die Region nicht zugänglich ist. Ein möglicher Ansatz besteht darin, die primäre Datenbank cluster-sql3 beizubehalten und dann ein neues Standby und eine neue sekundäre Instanz zu erstellen, wie im folgenden Diagramm dargestellt.

Abbildung 5. Notfallwiederherstellung ohne verfügbare ursprüngliche primäre Region R1
Diese Implementierung erfordert folgende Schritte:
Behalten Sie
cluster-sql3als primäre Domain inus-east1bei.Fügen Sie eine neue Standby-Instanz (
cluster-sql4) zu einer anderen Zone inus-east1hinzu. Dadurch wird die neue Bereitstellung hochverfügbar.Erstellen Sie eine neue sekundäre Instanz (
cluster-sql5) in einer separaten Region, z. B.us-west2. Mit diesem Schritt wird die neue Bereitstellung für die Notfallwiederherstellung eingerichtet. Die allgemeine Bereitstellung ist nun abgeschlossen. Die Datenbankarchitektur unterstützt HA und DR vollständig.
Optional: Fallback ausführen, wenn Transaktionen fehlen
Ein weniger ideales Szenario ist, wenn eine oder mehrere auf der primären Instanz zugesicherten Transaktionen nicht zum Zeitpunkt des Ausfalls auf die sekundäre Instanz repliziert werden. Dieser Vorgang wird auch als harter Ausfall bezeichnet. Bei einem Failover gehen alle zugesicherten Transaktionen verloren, die nicht repliziert werden.
Um die Failover-Schritte für dieses Szenario zu testen, müssen Sie einen harten Ausfall erzeugen. Der beste Ansatz zum Erzeugen eines harten Ausfalls lautet:
- Ändern Sie das Netzwerk so, dass keine Verbindung zwischen der primären Instanz und den sekundären Instanzen besteht.
- Ändern Sie die primäre Instanz auf irgendeine Weise, z. B. durch Hinzufügen von Daten oder einer Tabelle.
- Führen Sie den Failover-Prozess wie zuvor beschrieben aus, damit die sekundäre Instanz zur neuen primären Instanz wird.
Die Schritte für den Failover-Prozess sind mit dem idealen Szenario identisch. Der einzige Unterschied besteht darin, dass die Tabelle, die der primären Datenbank hinzugefügt wird, nachdem die Netzwerkverbindung unterbrochen wurde, in der sekundären Instanz nicht sichtbar ist.
Ihre einzige Option für einen harten Ausfall ist das Entfernen der Replikate (cluster-sql1 und cluster-sql2) aus der Verfügbarkeitsgruppe und das erneute Synchronisieren der Replikate. Mit der Synchronisierung wird der Zustand entsprechend der sekundären Instanz geändert. Jede Transaktion, die vor dem Ausfall nicht repliziert wurde, geht verloren.
Wenn Sie cluster-sql1 als sekundäre Instanz hinzufügen möchten, können Sie dieselben Schritte befolgen, die Sie oben zum Hinzufügen von cluster-sql3 ausgeführt haben (siehe Sekundäre Instanz zum Failover-Cluster hinzufügen). Es gibt jedoch folgenden Unterschied: cluster-sql3 ist jetzt die primäre Instanz, nicht cluster-sql1. Ersetzen Sie alle Instanzen von cluster-sql3 durch den Namen des Servers, den Sie der Verfügbarkeitsgruppe hinzufügen. Wenn Sie dieselbe VM (cluster-sql1 und cluster-sql2) wiederverwenden, müssen Sie den Server nicht zum Windows Server-Failover-Cluster hinzufügen. Fügen Sie lediglich die SQL Server-Instanz wieder zur Verfügbarkeitsgruppe hinzu.
An diesem Punkt ist cluster-sql3 die primäre Instanz und cluster-sql1 und cluster-sql2 sind sekundäre Instanzen. Es ist jetzt möglich, ein Fallback auf cluster-sql1 auszuführen, um cluster-sql2 zur Standby-Instanz und cluster-sql3 zur sekundären Instanz zu machen. Das System hat jetzt denselben Zustand wie vor dem Fehler.
Automatische Ausfallsicherung
Ein automatisches Failover auf eine sekundäre Instanz ist nicht möglich, da die primäre Instanz zu Problemen führen kann. Sobald die ursprüngliche primäre Datenbank wieder verfügbar ist, kann eine Split-Brain-Situation auftreten, wenn einige Clients auf die sekundäre Instanz zugreifen, während andere in die wiederhergestellte primäre Instanz schreiben. In diesem Fall könnten die primäre und die sekundäre Instanz gleichzeitig aktualisiert werden, wodurch ihr Zustand voneinander abweichen würde. Um dies zu vermeiden, finden Sie in dieser Anleitung Schritte für ein manuelles Failover, bei dem Sie entscheiden, ob (oder wann) ein Failover erfolgt.
Wenn Sie ein automatisches Failover implementieren, müssen Sie dafür sorgen, dass nur eine der konfigurierten Instanzen die primäre Instanz ist und geändert werden kann. Eine Standby- oder sekundäre Instanz darf keinem Client (außer der primären Instanz für die Zustandsreplikation) Schreibzugriff gewähren. Darüber hinaus müssen Sie eine schnelle Kette von aufeinander folgenden Failovers vermeiden. Beispielsweise wäre ein Failover alle fünf Minuten keine zuverlässige Strategie zur Notfallwiederherstellung. Bei automatisierten Failover-Prozessen können Sie Maßnahmen gegen problematische Szenarien wie diese treffen. Sie können bei Bedarf auch einen Datenbankadministrator für komplexe Entscheidungen einbeziehen.
Alternative Bereitstellungsarchitektur
In dieser Anleitung wird eine Architektur zur Notfallwiederherstellung mit einer sekundären Instanz eingerichtet, die in einem Failover zur primären Instanz wird, wie im folgenden Diagramm dargestellt.

Abbildung 6. Standardarchitektur für die Notfallwiederherstellung mit Microsoft SQL Server.
Dies bedeutet, dass bei einem Failover eine einzelne Instanz so lange vorhanden ist, bis ein Fallback möglich ist, oder bis Sie eine Standby-Instanz (für HA) und eine sekundäre Instanz (für DR) konfigurieren.
Eine alternative Bereitstellungsarchitektur besteht darin, zwei sekundäre Instanzen zu konfigurieren. Beide Instanzen sind Replikate der primären Instanz. Wenn ein Failover auftritt, können Sie eine der sekundären Instanzen als Standby neu konfigurieren. Die folgenden Diagramme zeigen die Bereitstellungsarchitektur vor und nach einem Failover.
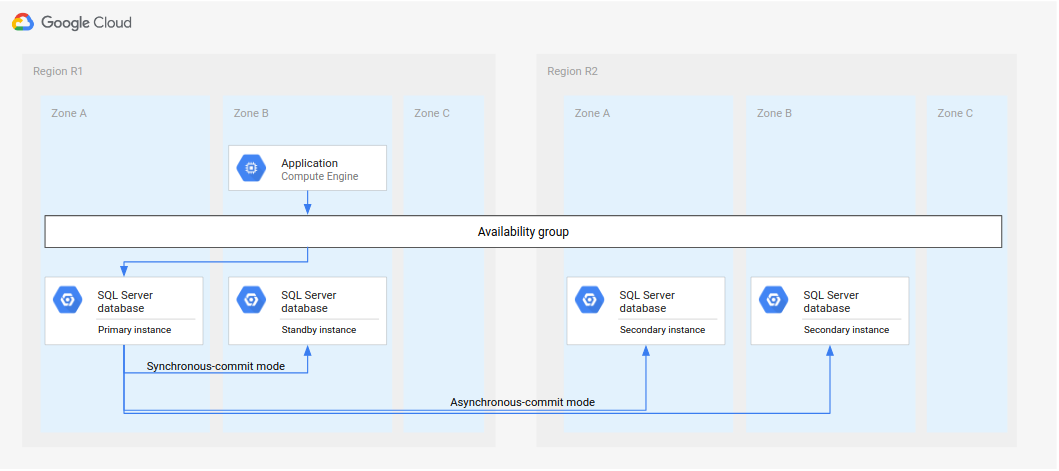
Abbildung 7. Standardarchitektur der Notfallwiederherstellung mit zwei sekundären Instanzen.

Abbildung 8. Standardarchitektur für die Notfallwiederherstellung mit zwei sekundären Instanzen nach dem Failover.
Sie müssen zwar trotzdem eine der beiden sekundären Instanzen als Standby-Instanz festlegen (Abbildung 8), dieser Prozess ist jedoch deutlich schneller als das Erstellen und Konfigurieren einer neuen Standby-Instanz.
Sie können die Notfallwiederherstellung auch mit einer Einrichtung erreichen, die dieser Architektur mit zwei sekundären Instanzen entspricht. Zusätzlich zu den zwei sekundären Instanzen in einer zweiten Region (Abbildung 7) können Sie weitere sekundäre Instanzen in einer dritten Region bereitstellen. Mit dieser Konfiguration können Sie eine HA- und DR-fähige Bereitstellungsarchitektur nach einem Ausfall der primären Region effizient erstellen.
Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen in Rechnung gestellt werden:
Projekt löschen
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Nächste Schritte
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center