在 Looker 中,派生表是一种查询,其结果的使用方式与数据库中的实际表相同。
例如,您可能有一个名为 orders 的数据库表,其中包含许多列。您希望计算一些客户级汇总指标,例如每位客户的订单数量或每位客户的首次下单时间。您可以使用原生派生表或基于 SQL 的派生表创建一个名为 customer_order_summary 的新数据库表,其中包含这些指标。
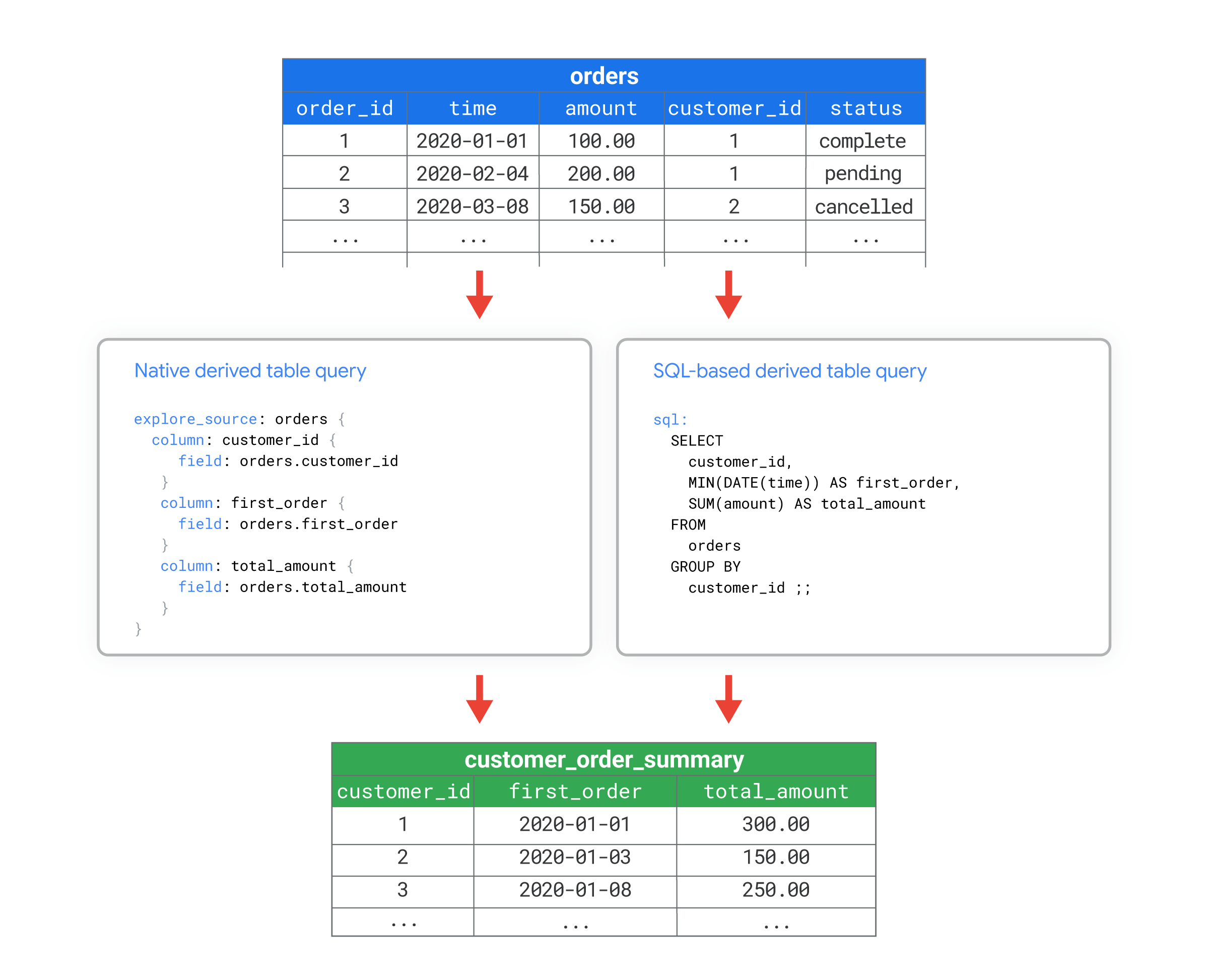
然后,您可以像使用数据库中的任何其他表一样使用派生表 customer_order_summary。
如需了解派生表的常见使用场景,请访问 Looker 食谱:充分利用 Looker 中的派生表。
原生派生表和基于 SQL 的派生表
如需在 Looker 项目中创建派生表,请使用 view 参数下的 derived_table 参数。在 derived_table 参数中,您可以通过以下两种方式之一定义派生表的查询:
- 对于原生派生表,您可以使用基于 LookML 的查询来定义派生表。
- 对于基于 SQL 的派生表,您可以使用 SQL 查询来定义派生表。
例如,以下视图文件展示了如何使用 LookML 从 customer_order_summary 派生表中创建视图。这两个版本的 LookML 说明了如何使用 LookML 或 SQL 来定义衍生表的查询,从而创建等效的衍生表:
- 原生派生表使用
explore_source参数中的 LookML 定义查询。在此示例中,查询基于现有的orders视图,该视图在单独的文件中定义,但未在此示例中显示。原生派生表中的explore_source查询会从orders视图文件中引入customer_id、first_order和total_amount字段。 - 基于 SQL 的派生表使用
sql参数中的 SQL 定义查询。在此示例中,SQL 查询是数据库中orders表的直接查询。
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: first_order {
field: orders.first_order
}
column: total_amount {
field: orders.total_amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
view: customer_order_summary {
derived_table: {
sql:
SELECT
customer_id,
MIN(DATE(time)) AS first_order,
SUM(amount) AS total_amount
FROM
orders
GROUP BY
customer_id ;;
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
这两个版本都会创建一个名为 customer_order_summary 的视图,该视图基于 orders 表,包含 customer_id、first_order, 和 total_amount 列。
除了 derived_table 参数及其子参数之外,此 customer_order_summary 视图的工作方式与任何其他视图文件一样。无论您是使用 LookML 还是 SQL 定义派生表的查询,都可以创建基于派生表列的 LookML 度量和维度。
定义派生表后,您就可以像使用数据库中的任何其他表一样使用它。
原生派生表
原生派生表基于您使用 LookML 字词定义的查询。如需创建原生派生表,您可以使用视图参数的 derived_table 参数中的 explore_source 参数。您可以通过引用模型中的 LookML 维度或度量来创建原生派生表的列。请参阅上一个示例中的原生派生表视图文件。
与基于 SQL 的派生表相比,在对数据进行建模时,原生派生表更易于阅读和理解。
如需详细了解如何创建原生派生表,请参阅创建原生派生表文档页面。
基于 SQL 的派生表
如需创建基于 SQL 的派生表,您需要以 SQL 术语定义查询,并使用 SQL 查询在表中创建列。您无法在基于 SQL 的派生表中引用 LookML 维度和度量。请参阅上一个示例中基于 SQL 的派生表视图文件。
最常见的情况是,您可以使用 view 参数的 derived_table 参数内的 sql 参数来定义 SQL 查询。
在 Looker 中创建基于 SQL 的查询时,一个有用的快捷方式是使用 SQL Runner 创建 SQL 查询并将其转换为派生表定义。
在某些极端情况下,不允许使用 sql 参数。在这种情况下,Looker 支持以下参数来定义 持久性派生表 (PDT) 的 SQL 查询:
create_process:当您为 PDT 使用sql参数时,Looker 会在后台将方言的CREATE TABLE数据定义语言 (DDL) 语句封装在查询周围,以根据您的 SQL 查询创建 PDT。某些方言不支持在单个步骤中使用 SQLCREATE TABLE语句。对于这些方言,您无法使用sql参数创建 PDT。您可以改为使用create_process参数分多个步骤创建 PDT。如需了解相关信息和示例,请参阅create_process参数文档页面。sql_create:如果您的使用情形需要自定义 DDL 命令,并且您的方言支持 DDL(例如 Google 预测性 BigQuery ML),则可以使用sql_create参数创建 PDT,而不是使用sql参数。如需了解相关信息和示例,请参阅sql_create文档页面。
无论您使用的是 sql、create_process 还是 sql_create 参数,在所有这些情况下,您都是使用 SQL 查询来定义派生表,因此这些都被视为基于 SQL 的派生表。
定义基于 SQL 的派生表时,请务必使用 AS 为每个列提供清晰的别名。这是因为您需要在维度(例如 ${TABLE}.first_order)中引用结果集的列名称。这就是上一个示例使用 MIN(DATE(time)) AS first_order 而不是仅使用 MIN(DATE(time)) 的原因。
临时派生表和永久性派生表
除了原生派生表和基于 SQL 的派生表之间的区别之外,还有临时派生表(不会写入数据库)和永久性派生表 (PDT)(会写入数据库中的架构)之间的区别。
原生派生表和基于 SQL 的派生表可以是临时表,也可以是永久表。
临时派生表
之前显示的派生表是临时派生表的示例。它们是临时性的,因为 derived_table 参数中未定义持久性策略。
临时派生表不会写入数据库。当用户运行涉及一个或多个派生表的探索查询时,Looker 会使用特定于方言的 SQL 组合来构建 SQL 查询,其中包含派生表的 SQL 以及所请求的字段、联接和过滤值。如果该组合之前已运行过,并且结果在缓存中仍然有效,Looker 会使用缓存的结果。如需详细了解 Looker 中的查询缓存,请参阅缓存查询文档页面。
否则,如果 Looker 无法使用缓存的结果,则每次用户从临时派生表中请求数据时,Looker 都必须对数据库运行新的查询。因此,您应确保临时派生表的性能良好,不会对数据库造成过大的压力。如果查询需要一段时间才能运行,PDT 通常是更好的选择。
临时派生表支持的数据库方言
为了让 Looker 支持 Looker 项目中的派生表,您的数据库方言也必须支持派生表。下表显示了在最新版 Looker 中哪些方言支持派生表:
点击此处可显示表格。
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | 是 |
| Amazon Athena | 是 |
| Amazon Aurora MySQL | 是 |
| Amazon Redshift | 是 |
| Amazon Redshift 2.1+ | 是 |
| Amazon Redshift Serverless 2.1+ | 是 |
| Apache Druid | 是 |
| Apache Druid 0.13+ | 是 |
| Apache Druid 0.18+ | 是 |
| Apache Hive 2.3+ | 是 |
| Apache Hive 3.1.2+ | 是 |
| Apache Spark 3+ | 是 |
| ClickHouse | 是 |
| Cloudera Impala 3.1+ | 是 |
| Cloudera Impala 3.1+ with Native Driver | 是 |
| Cloudera Impala with Native Driver | 是 |
| DataVirtuality | 是 |
| Databricks | 是 |
| Denodo 7 | 是 |
| Denodo 8 & 9 | 是 |
| Dremio | 是 |
| Dremio 11+ | 是 |
| Exasol | 是 |
| Google BigQuery Legacy SQL | 是 |
| Google BigQuery Standard SQL | 是 |
| Google Cloud PostgreSQL | 是 |
| Google Cloud SQL | 是 |
| Google Spanner | 是 |
| Greenplum | 是 |
| HyperSQL | 是 |
| IBM Netezza | 是 |
| MariaDB | 是 |
| Microsoft Azure PostgreSQL | 是 |
| Microsoft Azure SQL Database | 是 |
| Microsoft Azure Synapse Analytics | 是 |
| Microsoft SQL Server 2008+ | 是 |
| Microsoft SQL Server 2012+ | 是 |
| Microsoft SQL Server 2016 | 是 |
| Microsoft SQL Server 2017+ | 是 |
| MongoBI | 是 |
| MySQL | 是 |
| MySQL 8.0.12+ | 是 |
| Oracle | 是 |
| Oracle ADWC | 是 |
| PostgreSQL 9.5+ | 是 |
| PostgreSQL pre-9.5 | 是 |
| PrestoDB | 是 |
| PrestoSQL | 是 |
| SAP HANA | 是 |
| SAP HANA 2+ | 是 |
| SingleStore | 是 |
| SingleStore 7+ | 是 |
| Snowflake | 是 |
| Teradata | 是 |
| Trino | 是 |
| Vector | 是 |
| Vertica | 是 |
永久性派生表
永久性派生表 (PDT) 是一种派生表,它会写入数据库中的临时架构,并按照您通过持久性策略指定的计划重新生成。
PDT 可以是原生派生表,也可以是基于 SQL 的派生表。
PDT 的要求
如需在 Looker 项目中使用永久性派生表 (PDT),您需要满足以下条件:
- 支持 PDT 的数据库方言。如需查看支持基于 SQL 的永久性派生表和永久性原生派生表的方言列表,请参阅本页后面的支持 PDT 的数据库方言部分。
数据库上的临时架构。这可以是数据库中的任何架构,但我们建议您创建一个仅用于此目的的新架构。您的数据库管理员必须为 Looker 数据库用户配置具有写入权限的架构。
已配置且启用 PDT切换开关处于开启状态的 Looker 连接。此启用 PDT 设置通常在您首次设置 Looker 连接时进行配置(有关数据库方言的说明,请参阅 Looker 方言文档页面),但您也可以在首次设置后为连接启用 PDT。
PDT 支持的数据库方言
为了让 Looker 支持 Looker 项目中的 PDT,您的数据库方言也必须支持 PDT。
为了支持任何类型的 PDT(基于 LookML 或基于 SQL),方言必须支持写入数据库,以及其他要求。某些只读数据库配置不允许持久性正常运行(最常见的是 Postgres 热交换副本数据库)。在这些情况下,您可以改用临时派生表。
下表显示了 Looker 最新版本中支持永久性 SQL 派生表的方言:
点击此处可显示表格。
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | 是 |
| Amazon Athena | 是 |
| Amazon Aurora MySQL | 是 |
| Amazon Redshift | 是 |
| Amazon Redshift 2.1+ | 是 |
| Amazon Redshift Serverless 2.1+ | 是 |
| Apache Druid | 否 |
| Apache Druid 0.13+ | 否 |
| Apache Druid 0.18+ | 否 |
| Apache Hive 2.3+ | 是 |
| Apache Hive 3.1.2+ | 是 |
| Apache Spark 3+ | 是 |
| ClickHouse | 否 |
| Cloudera Impala 3.1+ | 是 |
| Cloudera Impala 3.1+ with Native Driver | 是 |
| Cloudera Impala with Native Driver | 是 |
| DataVirtuality | 否 |
| Databricks | 是 |
| Denodo 7 | 否 |
| Denodo 8 & 9 | 否 |
| Dremio | 否 |
| Dremio 11+ | 否 |
| Exasol | 是 |
| Google BigQuery Legacy SQL | 是 |
| Google BigQuery Standard SQL | 是 |
| Google Cloud PostgreSQL | 是 |
| Google Cloud SQL | 是 |
| Google Spanner | 否 |
| Greenplum | 是 |
| HyperSQL | 否 |
| IBM Netezza | 是 |
| MariaDB | 是 |
| Microsoft Azure PostgreSQL | 是 |
| Microsoft Azure SQL Database | 是 |
| Microsoft Azure Synapse Analytics | 是 |
| Microsoft SQL Server 2008+ | 是 |
| Microsoft SQL Server 2012+ | 是 |
| Microsoft SQL Server 2016 | 是 |
| Microsoft SQL Server 2017+ | 是 |
| MongoBI | 否 |
| MySQL | 是 |
| MySQL 8.0.12+ | 是 |
| Oracle | 是 |
| Oracle ADWC | 是 |
| PostgreSQL 9.5+ | 是 |
| PostgreSQL pre-9.5 | 是 |
| PrestoDB | 是 |
| PrestoSQL | 是 |
| SAP HANA | 是 |
| SAP HANA 2+ | 是 |
| SingleStore | 是 |
| SingleStore 7+ | 是 |
| Snowflake | 是 |
| Teradata | 是 |
| Trino | 是 |
| Vector | 是 |
| Vertica | 是 |
为了支持持久性原生派生表(具有基于 LookML 的查询),方言还必须支持 CREATE TABLE DDL 函数。以下列出了在最新版 Looker 中支持永久性原生(基于 LookML)派生表的方言:
点击此处可显示表格。
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | 是 |
| Amazon Athena | 是 |
| Amazon Aurora MySQL | 是 |
| Amazon Redshift | 是 |
| Amazon Redshift 2.1+ | 是 |
| Amazon Redshift Serverless 2.1+ | 是 |
| Apache Druid | 否 |
| Apache Druid 0.13+ | 否 |
| Apache Druid 0.18+ | 否 |
| Apache Hive 2.3+ | 是 |
| Apache Hive 3.1.2+ | 是 |
| Apache Spark 3+ | 是 |
| ClickHouse | 否 |
| Cloudera Impala 3.1+ | 是 |
| Cloudera Impala 3.1+ with Native Driver | 是 |
| Cloudera Impala with Native Driver | 是 |
| DataVirtuality | 否 |
| Databricks | 是 |
| Denodo 7 | 否 |
| Denodo 8 & 9 | 否 |
| Dremio | 否 |
| Dremio 11+ | 否 |
| Exasol | 是 |
| Google BigQuery Legacy SQL | 是 |
| Google BigQuery Standard SQL | 是 |
| Google Cloud PostgreSQL | 是 |
| Google Cloud SQL | 否 |
| Google Spanner | 否 |
| Greenplum | 是 |
| HyperSQL | 否 |
| IBM Netezza | 是 |
| MariaDB | 是 |
| Microsoft Azure PostgreSQL | 是 |
| Microsoft Azure SQL Database | 是 |
| Microsoft Azure Synapse Analytics | 是 |
| Microsoft SQL Server 2008+ | 是 |
| Microsoft SQL Server 2012+ | 是 |
| Microsoft SQL Server 2016 | 是 |
| Microsoft SQL Server 2017+ | 是 |
| MongoBI | 否 |
| MySQL | 是 |
| MySQL 8.0.12+ | 是 |
| Oracle | 是 |
| Oracle ADWC | 是 |
| PostgreSQL 9.5+ | 是 |
| PostgreSQL pre-9.5 | 是 |
| PrestoDB | 是 |
| PrestoSQL | 是 |
| SAP HANA | 是 |
| SAP HANA 2+ | 是 |
| SingleStore | 是 |
| SingleStore 7+ | 是 |
| Snowflake | 是 |
| Teradata | 是 |
| Trino | 是 |
| Vector | 是 |
| Vertica | 是 |
增量构建 PDT
增量 PDT 是一种永久性派生表,Looker 通过将最新数据附加到该表来构建它,而不是完全重新构建该表。
如果您的方言支持增量 PDT,并且您的 PDT 使用基于触发器的持久性策略(datagroup_trigger、sql_trigger_value 或 interval_trigger),您可以将 PDT 定义为增量 PDT。
如需了解详情,请参阅增量 PDT 文档页面。
增量 PDT 支持的数据库方言
为了让 Looker 在 Looker 项目中支持增量 PDT,您的数据库方言也必须支持增量 PDT。下表显示了 Looker 最新版本中哪些方言支持增量 PDT:
点击此处可显示表格。
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | 否 |
| Amazon Athena | 否 |
| Amazon Aurora MySQL | 否 |
| Amazon Redshift | 是 |
| Amazon Redshift 2.1+ | 是 |
| Amazon Redshift Serverless 2.1+ | 是 |
| Apache Druid | 否 |
| Apache Druid 0.13+ | 否 |
| Apache Druid 0.18+ | 否 |
| Apache Hive 2.3+ | 否 |
| Apache Hive 3.1.2+ | 否 |
| Apache Spark 3+ | 否 |
| ClickHouse | 否 |
| Cloudera Impala 3.1+ | 否 |
| Cloudera Impala 3.1+ with Native Driver | 否 |
| Cloudera Impala with Native Driver | 否 |
| DataVirtuality | 否 |
| Databricks | 是 |
| Denodo 7 | 否 |
| Denodo 8 & 9 | 否 |
| Dremio | 否 |
| Dremio 11+ | 否 |
| Exasol | 否 |
| Google BigQuery Legacy SQL | 否 |
| Google BigQuery Standard SQL | 是 |
| Google Cloud PostgreSQL | 是 |
| Google Cloud SQL | 否 |
| Google Spanner | 否 |
| Greenplum | 是 |
| HyperSQL | 否 |
| IBM Netezza | 否 |
| MariaDB | 否 |
| Microsoft Azure PostgreSQL | 是 |
| Microsoft Azure SQL Database | 否 |
| Microsoft Azure Synapse Analytics | 是 |
| Microsoft SQL Server 2008+ | 否 |
| Microsoft SQL Server 2012+ | 否 |
| Microsoft SQL Server 2016 | 否 |
| Microsoft SQL Server 2017+ | 否 |
| MongoBI | 否 |
| MySQL | 是 |
| MySQL 8.0.12+ | 是 |
| Oracle | 否 |
| Oracle ADWC | 否 |
| PostgreSQL 9.5+ | 是 |
| PostgreSQL pre-9.5 | 是 |
| PrestoDB | 否 |
| PrestoSQL | 否 |
| SAP HANA | 否 |
| SAP HANA 2+ | 否 |
| SingleStore | 否 |
| SingleStore 7+ | 否 |
| Snowflake | 是 |
| Teradata | 否 |
| Trino | 否 |
| Vector | 否 |
| Vertica | 是 |
创建 PDT
如需将派生表设为永久性派生表 (PDT),您需要为该表定义持久性策略。为了优化效果,您还应添加优化策略。
持久化策略
派生表的持久性可由 Looker 管理,也可由数据库使用具体化视图(如果所用方言支持具体化视图)。
如需使派生表保持持久状态,请向 derived_table 定义添加以下参数之一:
- Looker 管理的持久性参数:
- 数据库管理的持久性参数:
使用基于触发器的持久化策略(datagroup_trigger、sql_trigger_value 和 interval_trigger),Looker 会将 PDT 保留在数据库中,直到触发 PDT 进行重建。当 PDT 被触发时,Looker 会重建 PDT 以替换之前的版本。这意味着,借助基于触发器的 PDT,用户无需等待系统构建 PDT,即可从 PDT 获取探索查询的答案。
datagroup_trigger
数据组是创建持久性的最灵活的方法。如果您已使用 sql_trigger 或 interval_trigger 定义了 datagroup,则可以使用 datagroup_trigger 参数来启动持久性派生表 (PDT) 的重建。
Looker 会将 PDT 保留在数据库中,直到其数据组被触发。当数据组被触发时,Looker 会重新构建 PDT 以替换之前的版本。这意味着,在大多数情况下,您的用户无需等待 PDT 构建完成。如果用户在 PDT 构建期间请求数据,并且查询结果不在缓存中,Looker 将返回现有 PDT 中的数据,直到新的 PDT 构建完成。如需了解数据组的概览,请参阅缓存查询。
如需详细了解再生器如何构建 PDT,请参阅Looker 再生器部分。
sql_trigger_value
sql_trigger_value 参数会触发基于您提供的 SQL 语句的永久性派生表 (PDT) 的重新生成。如果 SQL 语句的结果与之前的值不同,系统会重新生成 PDT。否则,数据库中会保留现有的 PDT。这意味着,在大多数情况下,您的用户无需等待 PDT 构建完成。如果用户在 PDT 构建期间请求数据,并且查询结果不在缓存中,Looker 将返回现有 PDT 中的数据,直到新的 PDT 构建完成。
如需详细了解再生器如何构建 PDT,请参阅Looker 再生器部分。
interval_trigger
interval_trigger 参数会根据您提供的时间间隔(例如 "24 hours" 或 "60 minutes")触发永久性派生表 (PDT) 的重新生成。与 sql_trigger 参数类似,这意味着通常情况下,当用户查询 PDT 时,系统会预先构建该 PDT。如果用户在 PDT 构建期间请求数据,并且查询结果不在缓存中,Looker 将返回现有 PDT 中的数据,直到新的 PDT 构建完成。
persist_for
还有一种方法是使用 persist_for 参数来设置派生表在被标记为过期之前应存储的时间长度,这样该表将不再用于查询,并会从数据库中舍弃。
当用户首次对 persist_for 永久性派生表 (PDT) 运行查询时,系统会构建该表。然后,Looker 会在数据库中将 PDT 的保留时间设为 PDT 的 persist_for 参数中指定的时间长度。如果用户在 persist_for 时间内查询 PDT,Looker 会尽可能使用缓存的结果,否则会在 PDT 上运行查询。
在 persist_for 时间过后,Looker 会从数据库中清除 PDT,并且会在用户下次查询 PDT 时重新构建 PDT,这意味着查询需要等待重新构建完成。
使用 persist_for 的 PDT 不会被 Looker 重新生成器自动重新构建,除非存在 PDT 的依赖项级联。当 persist_for 表是依赖关系级联的一部分,并且该级联包含基于触发器的 PDT(使用 datagroup_trigger、interval_trigger 或 sql_trigger_value 持久性策略的 PDT)时,重新生成器将监控并重新构建 persist_for 表,以便重新构建级联中的其他表。请参阅本页上的Looker 如何构建级联派生表部分。
materialized_view: yes
借助具体化视图,您可以使用数据库的功能在 Looker 项目中持久保留派生表。如果您的数据库方言支持具体化视图,并且您的 Looker 连接已配置为启用 PDT 切换开关,您可以通过为派生表指定 materialized_view: yes 来创建具体化视图。具体化视图同时支持原生派生表和基于 SQL 的派生表。
与永久性派生表 (PDT) 类似,具体化视图是一种查询结果,以表的形式存储在数据库的临时架构中。PDT 与具体化视图之间的主要区别在于表的刷新方式:
- 对于 PDT,持久化策略在 Looker 中定义,持久化由 Looker 管理。
- 对于具体化视图,数据库负责维护和刷新表中的数据。
因此,具体化视图功能需要您对所用方言及其功能有深入的了解。在大多数情况下,只要数据库检测到具体化视图查询的表中有新数据,就会刷新具体化视图。对于需要实时数据的场景,具体化视图是最佳选择。
如需了解方言支持、要求和重要注意事项,请参阅 materialized_view 参数文档页面。
优化策略
由于持久性派生表 (PDT) 存储在数据库中,因此您应使用以下策略(以您的方言支持为准)优化 PDT:
例如,如需为派生表示例添加持久性,您可以将其设置为在数据组 orders_datagroup 触发时重建,并在 customer_id 和 first_order 上添加索引,如下所示:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
如果您未添加索引(或与您的方言等效的索引),Looker 会警告您应添加索引以提高查询性能。
PDT 的使用场景
永久性派生表 (PDT) 非常有用,因为它们可以将查询结果持久保存在表中,从而提高查询性能。
作为一般最佳实践,开发者应尽量在绝对必要时才使用 PDT 来对数据进行建模。
在某些情况下,可以通过其他方式优化数据。例如,添加索引或更改列的数据类型可能无需创建 PDT 即可解决问题。请务必使用 SQL Runner 工具中的“Explain”功能分析缓慢查询的执行计划。
除了缩短查询时间并减少频繁运行的查询的数据库负载之外,PDT 还有多种其他应用场景,包括:
如果无法合理地将表中的唯一行标识为主键,您还可以使用 PDT 来定义主键。
使用 PDT 测试优化效果
您可以使用 PDT 来测试不同的索引、分布和其他优化选项,而无需 DBA 或 ETL 开发者提供大量支持。
假设您有一个表,但想测试不同的索引。视图的初始 LookML 可能如下所示:
view: customer {
sql_table_name: warehouse.customer ;;
}
如需测试优化策略,您可以使用 indexes 参数向 LookML 添加索引,如下所示:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
查询视图一次以生成 PDT。然后,运行测试查询并比较结果。如果结果理想,您可以让 DBA 或 ETL 团队将索引添加到原始表中。
请记得将视图代码改回原样,以移除 PDT。
使用 PDT 预先联接或聚合数据
预先联接或预先聚合数据有助于调整查询优化,以处理大量数据或多种类型的数据。
例如,假设您想根据客户首次下单的时间按同类群组创建客户查询。如果每次需要实时获取数据时都运行此查询,可能会产生高昂的费用;不过,您只需计算一次查询,然后通过 PDT 重复使用结果:
view: customer_order_facts {
derived_table: {
sql: SELECT
c.customer_id,
MIN(o.order_date) OVER (PARTITION BY c.customer_id) AS first_order_date,
MAX(o.order_date) OVER (PARTITION BY c.customer_id) AS most_recent_order_date,
COUNT(o.order_id) OVER (PARTITION BY c.customer_id) AS lifetime_orders,
SUM(o.order_value) OVER (PARTITION BY c.customer_id) AS lifetime_value,
RANK() OVER (PARTITION BY c.customer_id ORDER BY o.order_date ASC) AS order_sequence,
o.order_id
FROM warehouse.customer c LEFT JOIN warehouse.order o ON c.customer_id = o.customer_id
;;
sql_trigger_value: SELECT CURRENT_DATE ;;
indexes: [customer_id, order_id, order_sequence, first_order_date]
}
}
级联派生表
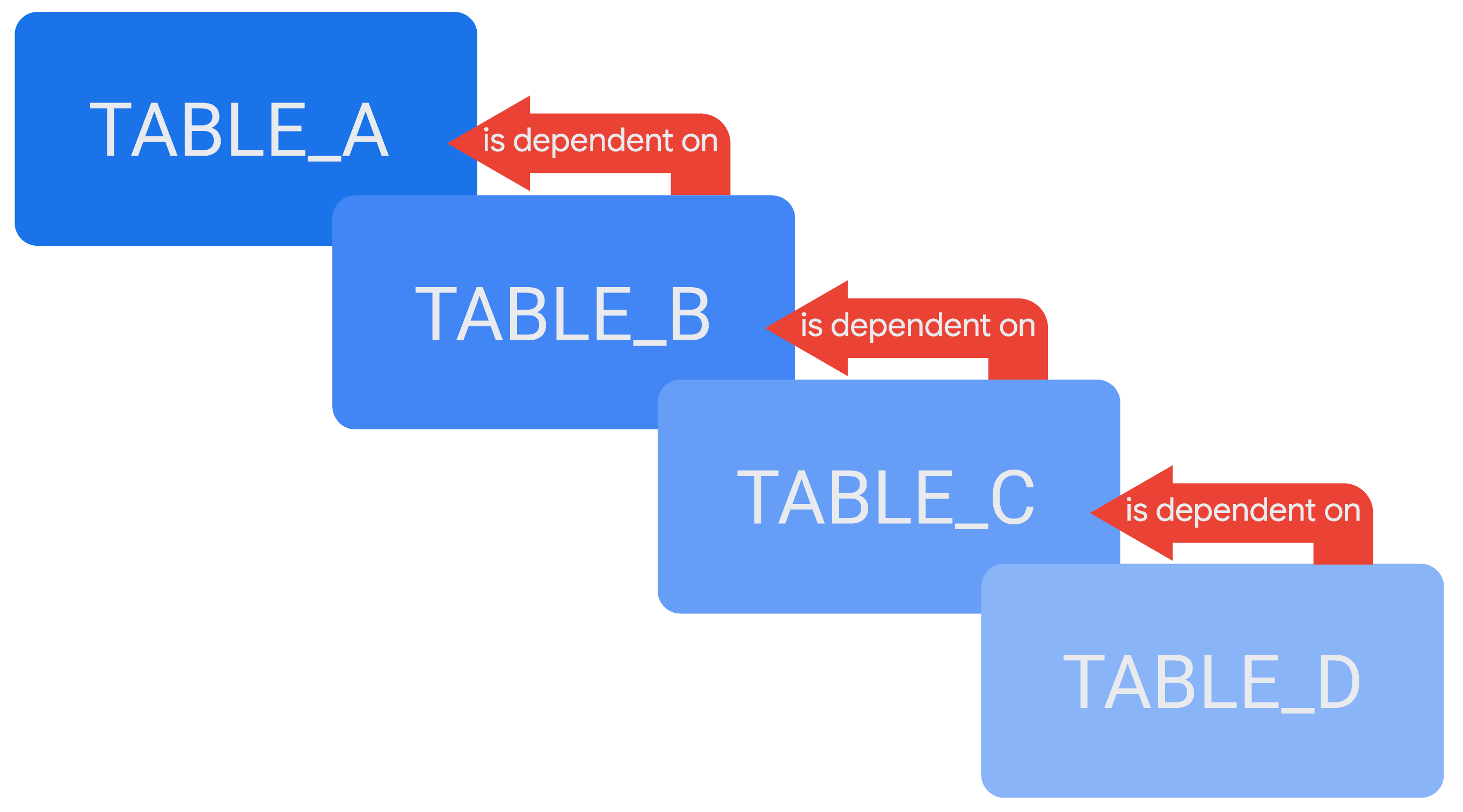
可以在一个派生表的定义中引用另一个派生表,从而创建级联派生表或级联持久派生表 (PDT)(具体取决于情况)链。级联派生表的示例:表 TABLE_D 依赖于另一个表 TABLE_C,而 TABLE_C 依赖于 TABLE_B,TABLE_B 依赖于 TABLE_A。
引用派生表的语法
如需在另一个派生表中引用派生表,请使用以下语法:
`${derived_table_or_view_name.SQL_TABLE_NAME}`
在此格式中,SQL_TABLE_NAME 是一个字面量字符串。例如,您可以使用以下语法引用 clean_events 派生表:
`${clean_events.SQL_TABLE_NAME}`
您可以使用相同的语法来引用 LookML 视图。同样,在本例中,SQL_TABLE_NAME 是一个字面量字符串。
在下一个示例中,系统会根据数据库中的 events 表创建 clean_events PDT。clean_events PDT 会从 events 数据库表中排除不需要的行。然后,系统会显示第二个 PDT;event_summary PDT 是 clean_events PDT 的摘要。每当向 clean_events 添加新行时,event_summary 表都会重新生成。
event_summary PDT 和 clean_events PDT 是级联 PDT,其中 event_summary 依赖于 clean_events(因为 event_summary 是使用 clean_events PDT 定义的)。此特定示例可以在单个 PDT 中更高效地完成,但它有助于演示派生表的引用。
view: clean_events {
derived_table: {
sql:
SELECT *
FROM events
WHERE type NOT IN ('test', 'staff') ;;
datagroup_trigger: events_datagroup
}
}
view: events_summary {
derived_table: {
sql:
SELECT
type,
date,
COUNT(*) AS num_events
FROM
${clean_events.SQL_TABLE_NAME} AS clean_events
GROUP BY
type,
date ;;
datagroup_trigger: events_datagroup
}
}
虽然并非总是必需,但以这种方式引用派生表时,通常最好使用以下格式为该表创建别名:
${derived_table_or_view_name.SQL_TABLE_NAME} AS derived_table_or_view_name
上一个示例执行以下操作:
${clean_events.SQL_TABLE_NAME} AS clean_events
使用别名很有帮助,因为在幕后,PDT 在数据库中是以冗长的代码命名的。在某些情况下(尤其是使用 ON 子句时),您可能会忘记需要使用 ${derived_table_or_view_name.SQL_TABLE_NAME} 语法来检索此长名称。别名有助于避免此类错误。
Looker 如何构建级联派生表
对于级联临时派生表,如果用户的查询结果不在缓存中,Looker 将构建查询所需的所有派生表。如果您有一个 TABLE_D,其定义包含对 TABLE_C 的引用,则 TABLE_D 依赖于 TABLE_C。这意味着,如果您查询 TABLE_D,但该查询不在 Looker 的缓存中,Looker 将重建 TABLE_D。但首先,它必须重建 TABLE_C。
假设存在级联临时派生表,其中 TABLE_D 依赖于 TABLE_C,TABLE_C 依赖于 TABLE_B,TABLE_B 依赖于 TABLE_A。如果 Looker 在缓存中没有针对 TABLE_C 的查询的有效结果,Looker 将构建查询所需的所有表。因此,Looker 将先构建 TABLE_A,然后构建 TABLE_B,最后构建 TABLE_C:

在这种情况下,TABLE_A 必须先生成完毕,Looker 才能开始生成 TABLE_B;TABLE_B 必须先生成完毕,Looker 才能开始生成 TABLE_C。当 TABLE_C 完成后,Looker 会提供查询结果。(由于回答此查询不需要 TABLE_D,因此 Looker 目前不会重建 TABLE_D。)
如需查看使用相同数据组的级联 PDT 的示例场景,请参阅 datagroup 参数文档页面。
PDT 的基本逻辑也一样:Looker 会构建回答查询所需的所有表,直至依赖项链的顶端。但对于 PDT,通常情况下表已存在,无需重建。对于级联 PDT 的标准用户查询,Looker 仅在数据库中没有有效的 PDT 版本时才重建级联中的 PDT。如果您想强制重新构建级联中的所有 PDT,可以通过探索手动重新构建查询的表。
需要了解的一个重要逻辑点是,在 PDT 级联的情况下,依赖型 PDT 本质上是在查询其所依赖的 PDT。对于使用 persist_for 策略的 PDT 来说,这一点尤为重要。通常,persist_for PDT 会在用户查询时构建,在数据库中保留到 persist_for 时间间隔结束,然后直到用户下次查询时才会重新构建。不过,如果 persist_for PDT 是级联的一部分,并且与基于触发器的 PDT(使用 datagroup_trigger、interval_trigger 或 sql_trigger_value 持久性策略的 PDT)相关联,那么每当重建其依赖的 PDT 时,系统实际上都会查询 persist_for PDT。因此,在这种情况下,系统将按照 persist_for 所依赖的 PDT 的时间安排重新构建 persist_for。这意味着,persist_for PDT 可能会受到其依赖项的持久性策略的影响。
手动为查询重建持久表
用户可以从“探索”菜单中选择重新构建派生表并运行选项,以替换持久性设置并重新构建“探索”中当前查询所需的所有永久性派生表 (PDT) 和汇总表:
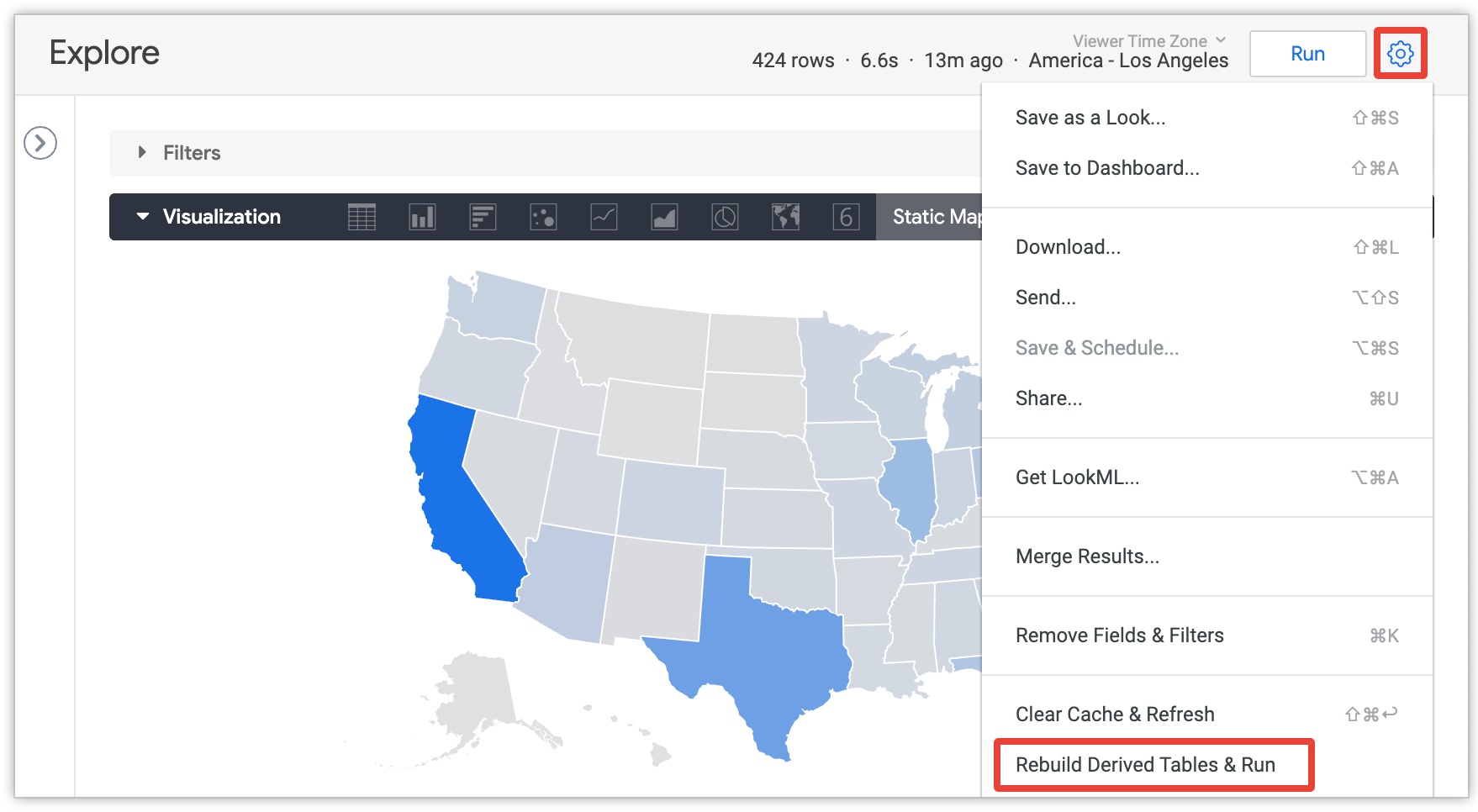
此选项仅对拥有 develop 权限的用户显示,并且仅在探索查询加载完毕后显示。
重建派生表并运行选项会重建回答查询所需的所有持久表(所有 PDT 和汇总表),无论其持久性策略如何。这包括当前查询中的所有汇总表和 PDT,还包括当前查询中的汇总表和 PDT 所引用的任何汇总表和 PDT。
对于增量 PDT,“重新构建派生表并运行”选项会触发新增量的构建。对于增量 PDT,增量包括 increment_key 参数中指定的时间段,以及 increment_offset 参数中指定的先前时间段数(如有)。如需查看一些示例场景,了解增量 PDT 如何根据其配置进行构建,请参阅增量 PDT 文档页面。
对于级联 PDT,这意味着重新构建级联中的所有派生表,从顶部开始。这与您在级联临时派生表中查询表时的行为相同:
请注意以下有关手动重建派生表的事项:
- 对于启动重建派生表并运行操作的用户,查询将等待表重建完成后再加载结果。其他用户的查询仍将使用现有表。重建持久性表后,所有用户都将使用重建后的表。虽然此流程旨在避免在重建表时中断其他用户的查询,但这些用户仍可能会受到数据库额外负载的影响。如果您在营业时间触发重新构建可能会对数据库造成不可接受的压力,则可能需要告知用户,他们不应在这些时间重新构建某些 PDT 或汇总表。
如果用户处于开发模式,并且探索基于开发表,则重新构建派生表并运行操作将重新构建探索的开发表,而不是生产表。但如果开发模式下的探索使用的是派生表的正式版,则系统会重新构建正式版表。如需了解开发表和生产表,请参阅开发模式下的持久表。
对于 Looker 托管的实例,如果派生表的重建时间超过一小时,则该表将无法成功重建,并且浏览器会话将超时。如需详细了解可能会影响 Looker 进程的超时,请参阅管理设置 - 查询文档页面上的查询超时和排队部分。
开发模式下的持久化表
Looker 在开发模式下管理持久化表时有一些特殊行为。
如果您在开发模式下查询持久化表,但未对其定义进行任何更改,Looker 将查询该表的生产版本。如果您确实对表定义做出了会影响表中的数据或查询表的方式的更改,那么下次在开发模式下查询该表时,系统会创建该表的新开发版本。有了这样的开发表,您就可以在不打扰用户的情况下测试更改。
促使 Looker 创建开发表的因素
在可能的情况下,无论您是否处于开发模式,Looker 都会使用现有的生产表来回答查询。但在某些情况下,Looker 无法在开发模式下使用生产表进行查询:
- 如果您的持久化表具有可将数据集范围缩小到在开发模式下更快运行的参数
- 如果您对持久化表的定义进行了更改,而这些更改会影响表中的数据
如果您处于开发模式,并且查询使用包含 if prod 和 if dev 语句的条件 WHERE 子句定义的基于 SQL 的派生表,Looker 将构建一个开发表。
对于在开发模式下没有用于缩小数据集的参数的持久表,Looker 会使用该表的生产版本来回答开发模式下的查询,除非您更改该表的定义,然后在开发模式下查询该表。这适用于对表所做的任何会影响表中的数据或查询表的方式的更改。
以下是一些示例,说明了哪些类型的更改会促使 Looker 创建持久表的开发版本(只有在您做出这些更改后查询表时,Looker 才会创建该表):
- 更改永久性表所基于的查询,例如修改永久性表本身或任何必需表(如果是级联派生表)中的
explore_source、sql、query、sql_create或create_process参数 - 更改表的持久性策略,例如修改表的
datagroup_trigger、sql_trigger_value、interval_trigger或persist_for参数 - 更改派生表的
view的名称 - 更改增量 PDT 的
increment_key或increment_offset - 更改关联模型使用的
connection
如果所做的更改不会修改表的数据或影响 Looker 查询表的方式,Looker 就不会创建开发表。publish_as_db_view 参数就是一个很好的例子:在开发模式下,如果您仅更改派生表的 publish_as_db_view 设置,Looker 无需重建派生表,因此不会创建开发表。
Looker 会将开发表保留多长时间
无论表的实际持久性策略如何,Looker 都会将开发持久性表视为具有 persist_for: "24 hours" 的持久性策略。Looker 这样做是为了确保开发表不会保留超过一天,因为 Looker 开发者在开发期间可能会多次查询表的迭代版本,并且每次都会构建新的开发表。为防止开发表使数据库变得杂乱,Looker 应用 persist_for: "24 hours" 策略,以确保经常从数据库中清理这些表。
否则,Looker 会在开发模式下以与在生产模式下构建持久化表相同的方式构建永久性派生表 (PDT) 和汇总表。
如果您在将更改部署到 PDT 或汇总表时,开发表仍保留在数据库中,Looker 通常可以将开发表用作生产表,这样用户在查询该表时就不必等待该表构建完成。
请注意,部署更改后,可能仍需要重建表才能在生产环境中查询,具体取决于以下情况:
- 如果您在开发模式下查询表的时间已超过 24 小时,则该表的开发版本会被标记为已过期,并且不会用于查询。您可以使用 Looker IDE 或使用持久性派生表页面中的开发标签页来检查未构建的 PDT。如果您有未构建的 PDT,可以在进行更改之前立即在开发模式下查询这些 PDT,以便在生产环境中使用开发表。
- 如果持久化表具有
dev_filters参数(对于原生派生表)或使用if prod和if dev语句的条件WHERE子句(对于基于 SQL 的派生表),则开发表不能用作生产版本,因为开发版本的数据集是缩略版。在这种情况下,在完成表的开发并部署更改之前,您可以注释掉dev_filters参数或条件WHERE子句,然后在开发模式下查询表。然后,当您部署更改时,Looker 会构建可用于生产环境的完整版表。
否则,如果您在没有可作为生产表的有效开发表的情况下部署更改,Looker 将在下次以生产模式查询该表时(对于使用 persist_for 策略的持久化表)或在下次运行 regenerator 时(对于使用 datagroup_trigger、interval_trigger 或 sql_trigger_value 的持久化表)重新构建该表。
在开发模式下检查未构建的 PDT
如果您在将更改部署到持久性派生表 (PDT) 或汇总表时,数据库中保留了开发表,Looker 通常可以将开发表用作生产表,这样用户在查询该表时就不必等待该表构建完成。如需了解详情,请参阅此页面上的Looker 会将开发表保留多长时间和Looker 在什么情况下会创建开发表部分。
因此,最好在部署到生产环境时构建所有 PDT,以便这些表可以立即用作生产版本。
您可以在项目健康状况面板中检查项目中是否存在未构建的 PDT。点击 Looker IDE 中的项目健康状况图标,打开项目健康状况面板。然后点击 Validate PDT Status 按钮。
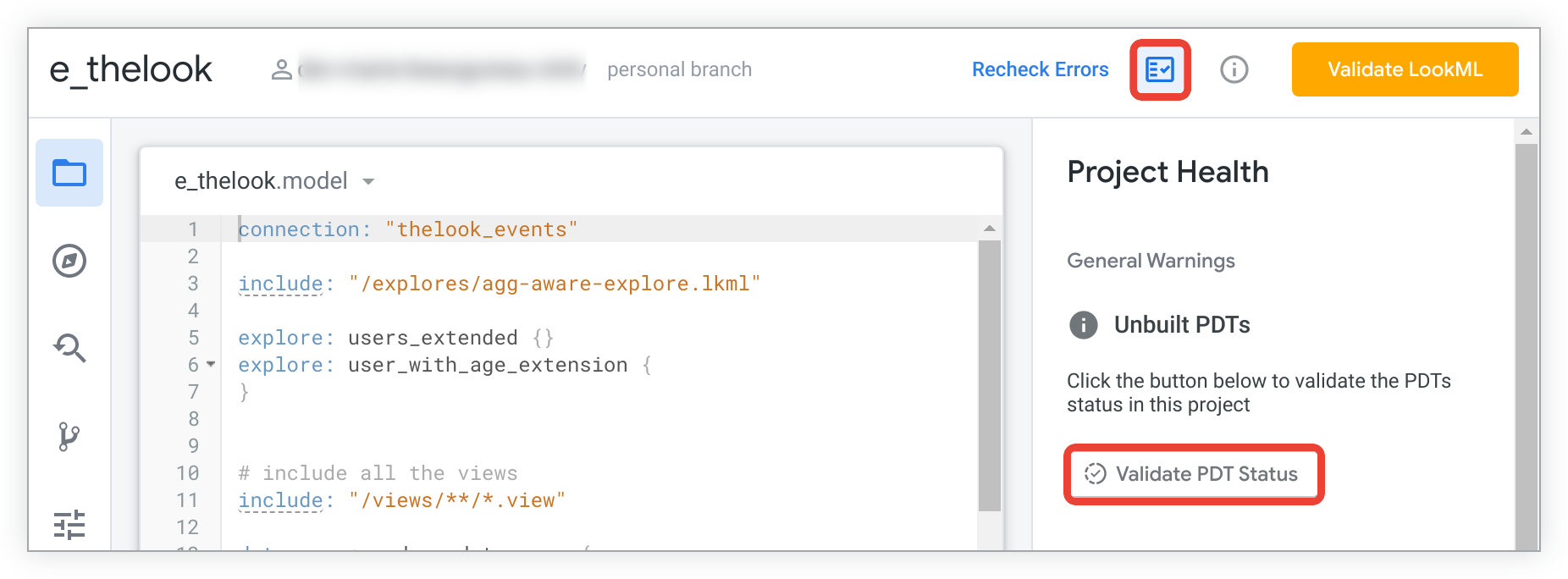
如果有未构建的 PDT,项目健康状况面板会列出这些 PDT:
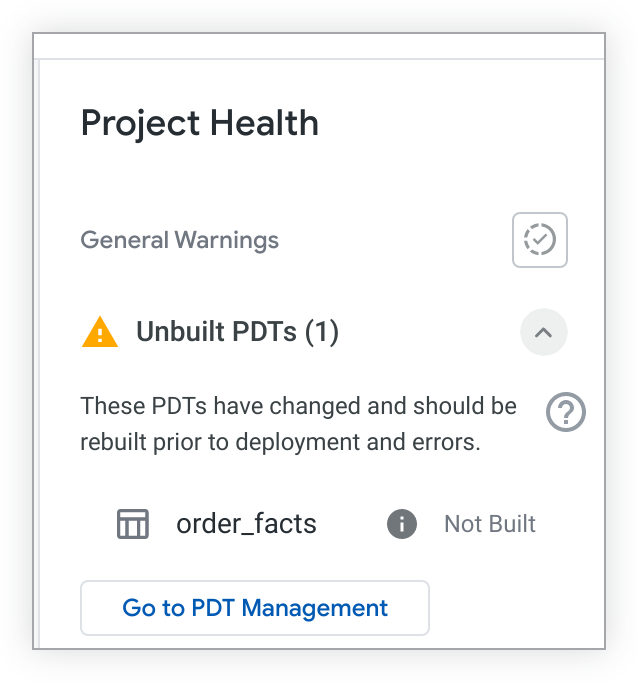
如果您拥有 see_pdts 权限,则可以点击前往 PDT 管理按钮。Looker 将打开持久派生表页面的开发标签页,并将结果过滤为您的特定 LookML 项目。您可以在该页面上查看哪些开发 PDT 已构建,哪些尚未构建,还可以访问其他问题排查信息。如需了解详情,请参阅管理设置 - 永久性派生表文档页面。
在项目中确定未构建的 PDT 后,您可以构建其开发版本,方法是打开查询该表的探索,然后从“探索”菜单中使用重新构建派生表并运行选项。请参阅本页面上的手动为查询重建持久表部分。
表格共享和清理
在任何给定的 Looker 实例中,如果持久化表的定义和持久化方法设置相同,Looker 将在用户之间共享这些表。此外,如果表的定义不再存在,Looker 会将该表标记为已过期。
这样做有几个好处:
- 如果您在开发模式下未对表进行任何更改,则查询将使用现有的生产表。除非您的表是使用包含
if prod和if dev语句的条件WHERE子句定义的基于 SQL 的派生表,否则就是这种情况。如果表是使用条件WHERE子句定义的,那么当您在开发模式下查询该表时,Looker 会构建一个开发表。(对于具有dev_filters参数的原生派生表,Looker 具有在开发模式下使用生产表回答查询的逻辑,除非您更改表的定义,然后在开发模式下查询该表。) - 如果两位开发者在开发模式下恰好对同一表格进行了相同的更改,他们将共享同一开发表格。
- 将更改从开发模式推送到生产模式后,旧的生产定义将不再存在,因此旧的生产表会被标记为已过期,并将被舍弃。
- 如果您决定舍弃开发模式更改,则该表定义将不再存在,因此不需要的开发表会被标记为已过期,并将被舍弃。
在开发模式下更快地工作
在某些情况下,您创建的持久性派生表 (PDT) 需要很长时间才能生成,如果您在开发模式下测试大量更改,这可能会非常耗时。对于这些情况,您可以在开发模式下提示 Looker 创建派生表的较小版本。
对于原生派生表,您可以使用 explore_source 的 dev_filters 子参数来指定仅应用于派生表的开发版本的过滤条件:
view: e_faa_pdt {
derived_table: {
...
datagroup_trigger: e_faa_shared_datagroup
explore_source: flights {
dev_filters: [flights.event_date: "90 days"]
filters: [flights.event_date: "2 years", flights.airport_name: "Yucca Valley Airport"]
column: id {}
column: airport_name {}
column: event_date {}
}
}
...
}
此示例包含一个 dev_filters 参数,用于将数据过滤为过去 90 天内的数据;还包含一个 filters 参数,用于将数据过滤为过去 2 年内的数据以及 Yucca Valley Airport 的数据。
dev_filters 参数与 filters 参数搭配使用,以便将所有过滤条件应用于表的开发版本。如果 dev_filters 和 filters 都为同一列指定了过滤条件,则对于表的开发版本,dev_filters 优先。在此示例中,表的开发版本会将数据过滤为 Yucca Valley Airport 的过去 90 天的数据。
对于基于 SQL 的派生表,Looker 支持有条件的 WHERE 子句,该子句针对表的正式版 (if prod) 和开发版 (if dev) 具有不同的选项:
view: my_view {
derived_table: {
sql:
SELECT
columns
FROM
my_table
WHERE
-- if prod -- date > '2000-01-01'
-- if dev -- date > '2020-01-01'
;;
}
}
在此示例中,如果处于生产模式,查询将包含 2000 年以来的所有数据;如果处于开发模式,查询将仅包含 2020 年以来的数据。有策略地使用此功能来限制结果集并提高查询速度,可以更轻松地验证开发模式更改。
Looker 如何构建 PDT
在定义了持久性派生表 (PDT) 并首次运行或由 regenerator 触发以根据其持久性策略进行重建后,Looker 将执行以下步骤:
- 使用派生表 SQL 语句来创建 CREATE TABLE AS SELECT (或 CTAS) 语句并执行该语句。例如,如需重新构建名为
customer_orders_facts的 PDT,请运行以下命令:CREATE TABLE tmp.customer_orders_facts AS SELECT ... FROM ... WHERE ... - 在构建表时发出语句以创建索引
- 将表从 LC$..(“Looker Create”)重命名为 LR$..(“Looker Read”),以表明该表已可供使用
- 舍弃不应再使用的任何旧版表格
这会带来一些重要影响:
- 构成派生表的 SQL 必须在 CTAS 语句中有效。
- SELECT 语句的结果集中的列别名必须是有效的列名称。
- 指定分布、排序键和索引时使用的名称必须是派生表的 SQL 定义中列出的列名称,而不是 LookML 中定义的字段名称。
Looker 重新生成器
Looker 重新生成器会检查状态并为触发器持久化表启动重建。触发器持久性表是一种使用触发器作为持久性策略的永久性派生表 (PDT) 或汇总表:
- 对于使用
sql_trigger_value的表,触发器是在表的sql_trigger_value参数中指定的查询。当最新触发查询检查的结果与上一次触发查询检查的结果不同时,Looker 再生器会触发表的重建。例如,如果您的派生表通过 SQL 查询SELECT CURDATE()持久化,则在日期更改后,当 Looker 再生器下次检查触发器时,会重建该表。 - 对于使用
interval_trigger的表,触发器是表interval_trigger参数中指定的时间段。当指定的时间过去后,Looker 再生器会触发表的重建。 - 对于使用
datagroup_trigger的表,触发器可以是关联数据组的sql_trigger参数中指定的查询,也可以是数据组的interval_trigger参数中指定的时间段。
Looker 再生器还会针对使用 persist_for 参数的持久化表启动重建,但前提是 persist_for 表是触发持久化表的依赖项级联。在这种情况下,Looker 再生器将启动 persist_for 表的重建,因为需要该表来重建级联中的其他表。否则,再生器不会监控使用 persist_for 策略的持久化表。
Looker 重新生成器周期以固定间隔开始,该间隔由 Looker 管理员在数据库连接的维护时间表设置中配置(默认间隔为 5 分钟)。不过,Looker 再生器会等到完成上一个周期的所有检查和 PDT 重建后,才会开始新的周期。这意味着,如果您有长时间运行的 PDT build,Looker 再生器周期可能不会像维护时间表设置中定义的那样频繁运行。如本页的实现持久化表的重要注意事项部分中所述,其他因素也会影响重建表所需的时间。
如果 PDT 构建失败,再生器可能会尝试在下一个再生器周期中重新构建表:
- 如果数据库连接启用了重试失败的 PDT 构建 设置,即使未满足表的触发条件,Looker 重新生成器也会在下一个重新生成器周期尝试重新构建该表。
- 如果停用了重试失败的 PDT 构建设置,则在满足 PDT 的触发条件之前,Looker 再生器不会尝试重新构建表。
如果用户在持久化表构建期间请求该表中的数据,并且查询结果不在缓存中,Looker 会检查现有表是否仍然有效。(如果之前的表与新版表不兼容,则可能无效。如果新表的定义不同、新表使用不同的数据库连接,或者新表是使用不同版本的 Looker 创建的,则可能会出现这种情况。)如果现有表仍然有效,Looker 会返回现有表中的数据,直到新表构建完成。否则,如果现有表无效,Looker 会在新表重建完成后提供查询结果。
实现持久化表的重要注意事项
考虑到持久性派生表(PDT 和汇总表)的实用性,您的 Looker 实例上可能会积累许多此类表。可以创建这样一种情形:Looker 重新生成器需要同时构建多个表。尤其是对于级联表或长时间运行的表,您可能会遇到以下情况:表在重建之前有很长的延迟时间,或者当数据库努力生成表时,用户在从表中获取查询结果时会遇到延迟。
Looker 重新生成器会检查 PDT 触发器,以确定是否应重新构建触发器持久性表。再生器周期按常规时间间隔设置,由 Looker 管理员在数据库连接的维护时间表设置中进行配置(默认时间间隔为 5 分钟)。
以下几个因素会影响重建表所需的时间:
- 您的 Looker 管理员可能已通过数据库连接中的维护时间表设置更改了再生器触发检查的间隔。
- Looker 再生器不会启动新周期,直到它完成上一个周期的所有检查和 PDT 重建。因此,如果您有长时间运行的 PDT build,Looker 再生器周期可能不会像维护时间表设置那样频繁。
- 默认情况下,重新生成器可以通过连接一次启动一个 PDT 或汇总表的重建。Looker 管理员可以使用连接设置中的 PDT 构建器连接数上限字段来调整重新生成器允许的并发重建数量。
- 由同一
datagroup触发的所有 PDT 和汇总表将在同一重新生成过程中重建。如果您有许多表直接或因级联依赖项而使用数据组,则这可能会造成很大的负载。
除了上述注意事项外,在某些情况下,您还应避免向派生表添加持久性:
- 何时会扩展派生表 - PDT 的每次扩展都会在数据库中创建该表的新副本。
- 当派生表使用模板化过滤条件或 Liquid 参数时,不支持为使用模板化过滤条件或 Liquid 参数的派生表启用持久性。
- 如果使用
access_filters或sql_always_where的用户属性从探索中构建原生派生表,则系统会在数据库中为指定的每个可能的用户属性值构建表的副本。 - 当基础数据频繁变化,而您的数据库方言不支持增量 PDT 时。
- 创建 PDT 所需的费用和时间过高。
根据 Looker 连接上持久化表的数量和复杂程度,队列中可能包含许多需要在每个周期进行检查和重建的持久化表,因此在 Looker 实例上实现派生表时,请务必牢记这些因素。
使用 API 大规模管理 PDT
随着您在实例上创建的 PDT 越来越多,监控和管理以不同时间表刷新的永久性派生表 (PDT) 会变得越来越复杂。您可以考虑使用 Looker Apache Airflow 集成来管理 PDT 安排以及其他 ETL 和 ELT 流程。
监控和排查 PDT 问题
如果您使用永久性派生表 (PDT),尤其是级联 PDT,那么查看 PDT 的状态会很有帮助。您可以使用 Looker 的永久性派生表管理页面查看 PDT 的状态。您还可以查看 PDT 问题排查树,了解分步调试方法。
尝试排查 PDT 问题时:
- 在调查 PDT 事件日志时,请特别注意开发表和生产表之间的区别。
- 验证 Looker 连接中的 Temp Database 设置是否与实际的临时架构或数据库一致。如果连接的临时数据库设置与数据库中的临时架构不匹配,请更新临时数据库设置,以便 Looker 可以在数据库中存储永久性派生表。
- 确定是所有 PDT 都存在问题,还是只有部分 PDT 存在问题。如果其中一个存在问题,则该问题很可能是由 LookML 或 SQL 错误引起的。
- 确定 PDT 的问题是否与计划重新构建的时间相对应。
- 确保所有
sql_trigger_value查询都能成功评估,并且只返回一行和一列。对于基于 SQL 的 PDT,您可以在 SQL Runner 中运行它们来完成此操作。(应用LIMIT可防范失控查询。)如需详细了解如何使用 SQL Runner 调试派生表,请参阅使用 SQL Runner 测试派生表 社区帖子。 - 对于基于 SQL 的 PDT,请使用 SQL Runner 验证 PDT 的 SQL 是否能正常执行。(请务必在 SQL Runner 中应用
LIMIT,以确保查询时间合理。) - 对于基于 SQL 的派生表,请避免使用通用表表达式 (CTE)。将 CTE 与 DT 搭配使用会创建嵌套的
WITH语句,这可能会导致 PDT 失败,且不会显示警告。请改为使用 CTE 的 SQL 创建辅助 DT,并使用${derived_table_or_view_name.SQL_TABLE_NAME}语法从第一个 DT 引用该 DT。 - 检查问题 PDT 所依赖的任何表(无论是常规表还是 PDT 本身)是否存在并且可以查询。
- 确保问题 PDT 所依赖的任何表都没有任何共享锁或排他锁。为了让 Looker 成功构建 PDT,它需要获取对需要更新的表的独占锁定。这会与表上的其他共享锁或排他锁发生冲突。在所有其他锁定都已清除之前,Looker 将无法更新 PDT。对于 Looker 要从中构建 PDT 的表上的任何独占锁,情况也是如此;如果表上有独占锁,Looker 将无法获取共享锁来运行查询,直到独占锁被清除为止。
- 使用 SQL Runner 中的 Show Processes 按钮。如果活跃进程数量较多,可能会导致查询时间变长。
- 监控查询中的注释。请参阅本页中的针对 PDT 的查询注释部分。
查询 PDT 的注释
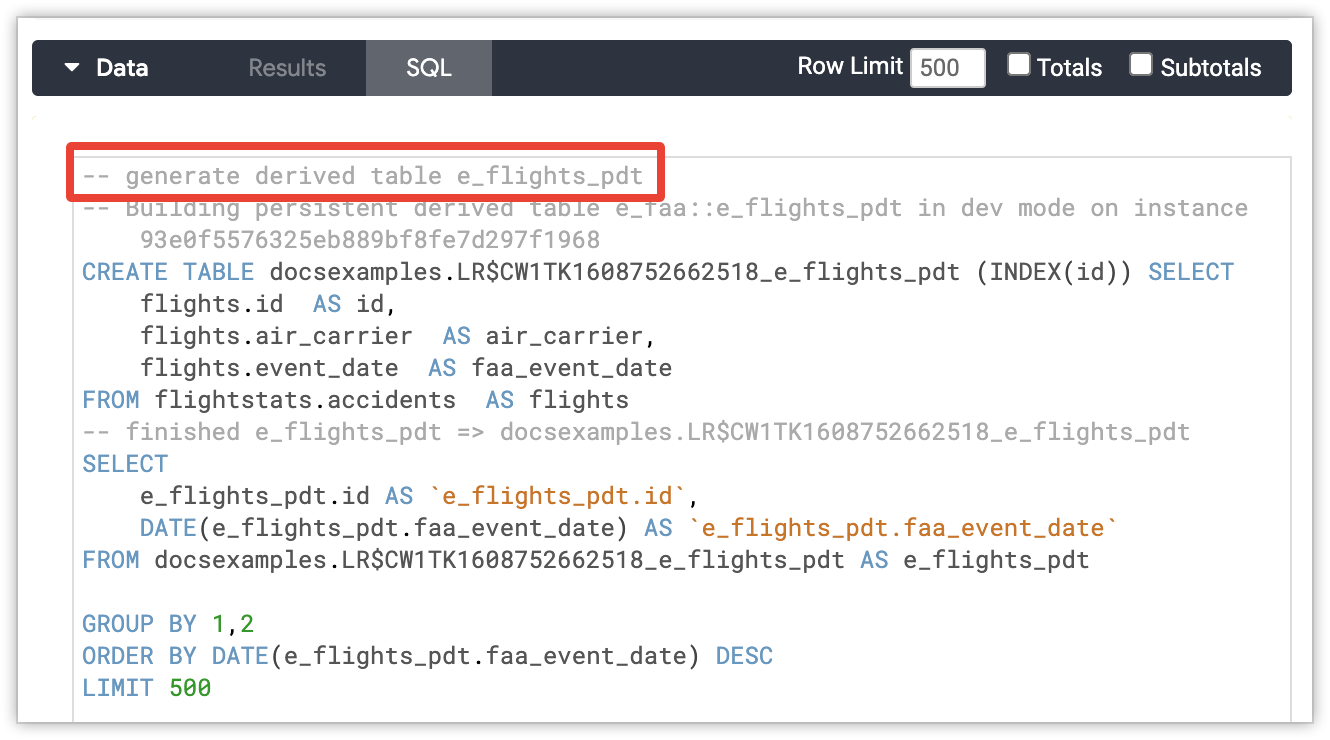
数据库管理员可以区分普通查询和生成持久性派生表 (PDT) 的查询。Looker 会向 CREATE TABLE ... AS SELECT ... 语句添加注释,其中包含 PDT 的 LookML 模型和视图,以及 Looker 实例的唯一标识符(slug)。如果 PDT 是代表处于开发模式下的用户生成的,注释将指明用户的 ID。PDT 生成注释遵循以下模式:
-- Building `<view_name>` in dev mode for user `<user_id>` on instance `<instance_slug>`
CREATE TABLE `<table_name>` SELECT ...
-- finished `<view_name>` => `<table_name>`
如果 Looker 必须为探索的查询生成 PDT,则 PDT 生成注释将显示在探索的 SQL 标签页中。相应注释将显示在 SQL 语句的顶部。
最后,PDT 生成注释会显示在查询管理页面上每个查询的查询详情弹出式窗口的信息标签页中的消息字段中。
在发生故障后重新构建 PDT
如果永久性派生表 (PDT) 出现故障,在查询该 PDT 时会发生以下情况:
- 如果之前运行过相同的查询,Looker 将使用缓存中的结果。(如需了解此功能的工作原理,请参阅缓存查询文档页面。)
- 如果结果不在缓存中,Looker 将从数据库中的 PDT 中提取结果(如果存在有效的 PDT 版本)。
- 如果数据库中没有有效的 PDT,Looker 将尝试重新构建 PDT。
- 如果 PDT 无法重新构建,Looker 将针对查询返回错误。Looker 再生器会在下次查询 PDT 时或下次 PDT 的持久性策略触发重建时尝试重建 PDT。
对于级联 PDT,也适用相同的逻辑,只不过对于级联 PDT:
- 如果无法构建某个表,则会导致依赖链中的 PDT 无法构建。
- 相关 PDT 本质上是在查询其所依赖的 PDT,因此一个表的持久性策略可能会触发链中上游 PDT 的重建。
我们再来看一下之前有关级联表的示例,其中 TABLE_D 依赖于 TABLE_C,而 TABLE_C 依赖于 TABLE_B,TABLE_B 又依赖于 TABLE_A:
如果 TABLE_B 出现故障,所有标准(非级联)行为都适用于 TABLE_B:
- 如果查询
TABLE_B,Looker 会先尝试使用缓存来返回结果。 - 如果此尝试失败,Looker 接下来会尝试使用表的先前版本(如果可能)。
- 如果此尝试也失败,Looker 随后会尝试重建表。
- 最后,如果无法重建
TABLE_B,Looker 将返回错误。
当下次查询表时,或者当表的持久性策略下次触发重建时,Looker 将再次尝试重建 TABLE_B。
这同样适用于 TABLE_B 的被依赖项。因此,如果无法构建 TABLE_B,并且存在对 TABLE_C 的查询,则会发生以下序列:
- Looker 将尝试在
TABLE_C对查询使用缓存。 - 如果缓存中没有结果,Looker 会尝试从数据库中的
TABLE_C中提取结果。 - 如果没有有效的
TABLE_C版本,Looker 将尝试重建TABLE_C,这会在TABLE_B上创建一个查询。 - 然后,Looker 会尝试重建
TABLE_B(如果TABLE_B未修复,则会失败)。 - 如果无法重建
TABLE_B,则无法重建TABLE_C,因此 Looker 会针对TABLE_C上的查询返回错误。 - 然后,Looker 将尝试根据其常规持久化策略重建
TABLE_C,或者在下次查询 PDT 时(包括下次TABLE_D尝试构建时,因为TABLE_D依赖于TABLE_C)重建TABLE_C。
解决 TABLE_B 的问题后,TABLE_B 和每个依赖表都会尝试根据其持久性策略进行重建,或者在下次查询时(包括下次依赖 PDT 尝试重建时)进行重建。或者,如果以开发模式构建了级联 PDT 的开发版本,则可以将这些开发版本用作新的生产 PDT。(如需了解此功能的工作原理,请参阅本页面上的开发模式下的持久化表部分。)或者,您也可以使用 Explore 对 TABLE_D 运行查询,然后手动重建查询的 PDT,这将强制重建依赖关系级联中的所有 PDT。
提高 PDT 性能
当您创建永久性派生表 (PDT) 时,性能可能会成为一个问题。尤其是在表非常大的情况下,查询表的速度可能会很慢,就像查询数据库中的任何大型表一样。
您可以通过过滤数据或控制 PDT 中数据的排序和索引方式来提高性能。
添加过滤条件以限制数据集
对于特别大的数据集,如果行数过多,则针对持久性派生表 (PDT) 的查询速度会变慢。如果您通常只查询最近的数据,请考虑向 PDT 的 WHERE 子句添加一个过滤条件,将表限制为最多包含 90 天的数据。这样,每次重建表时,系统只会向其中添加相关数据,从而大大加快查询运行速度。然后,您可以创建一个单独的、更大的 PDT 用于历史分析,这样既可以快速查询近期数据,也可以查询旧数据。
使用 indexes 或 sortkeys 和 distribution
创建大型永久性派生表 (PDT) 时,对表编制索引(对于 MySQL 或 Postgres 等方言)或添加 sortkey 和分布(对于 Redshift)有助于提高性能。
通常,最好在 ID 或日期字段中添加 indexes 参数。
对于 Redshift,最好在 ID 或日期字段上添加 sortkeys 参数,并在用于联接的字段上添加 distribution 参数。
可提升效果的建议设置
以下设置用于控制持久性派生表 (PDT) 中数据的排序和索引方式。以下设置是可选的,但强烈建议您进行设置:
- 对于 Redshift 和 Aster,请使用
distribution参数指定列名,该列的值用于在集群中分散数据。当两个表通过distribution参数中指定的列联接时,数据库可以在同一节点上找到联接数据,从而最大限度地减少节点间 I/O。 - 对于 Redshift,请将
distribution_style参数设置为all,以指示数据库在每个节点上保留一份完整的数据副本。在联接相对较小的表时,通常会使用此方法来最大限度地减少节点间 I/O。将此值设置为even,以指示数据库在整个集群中均匀分布数据,而不使用分布列。只有在未指定distribution时,才能指定此值。 - 对于 Redshift,请使用
sortkeys参数。这些值用于指定 PDT 的哪些列用于对磁盘上的数据进行排序,以便更轻松地进行搜索。在 Redshift 上,您可以使用sortkeys或indexes,但不能同时使用这两者。 - 在大多数数据库中,使用
indexes参数。这些值用于指定 PDT 的哪些列编入索引。(在 Redshift 上,索引用于生成交错排序键。)