Dans Looker, une table dérivée est une requête dont les résultats sont utilisés comme s'il s'agissait d'une table réelle de la base de données.
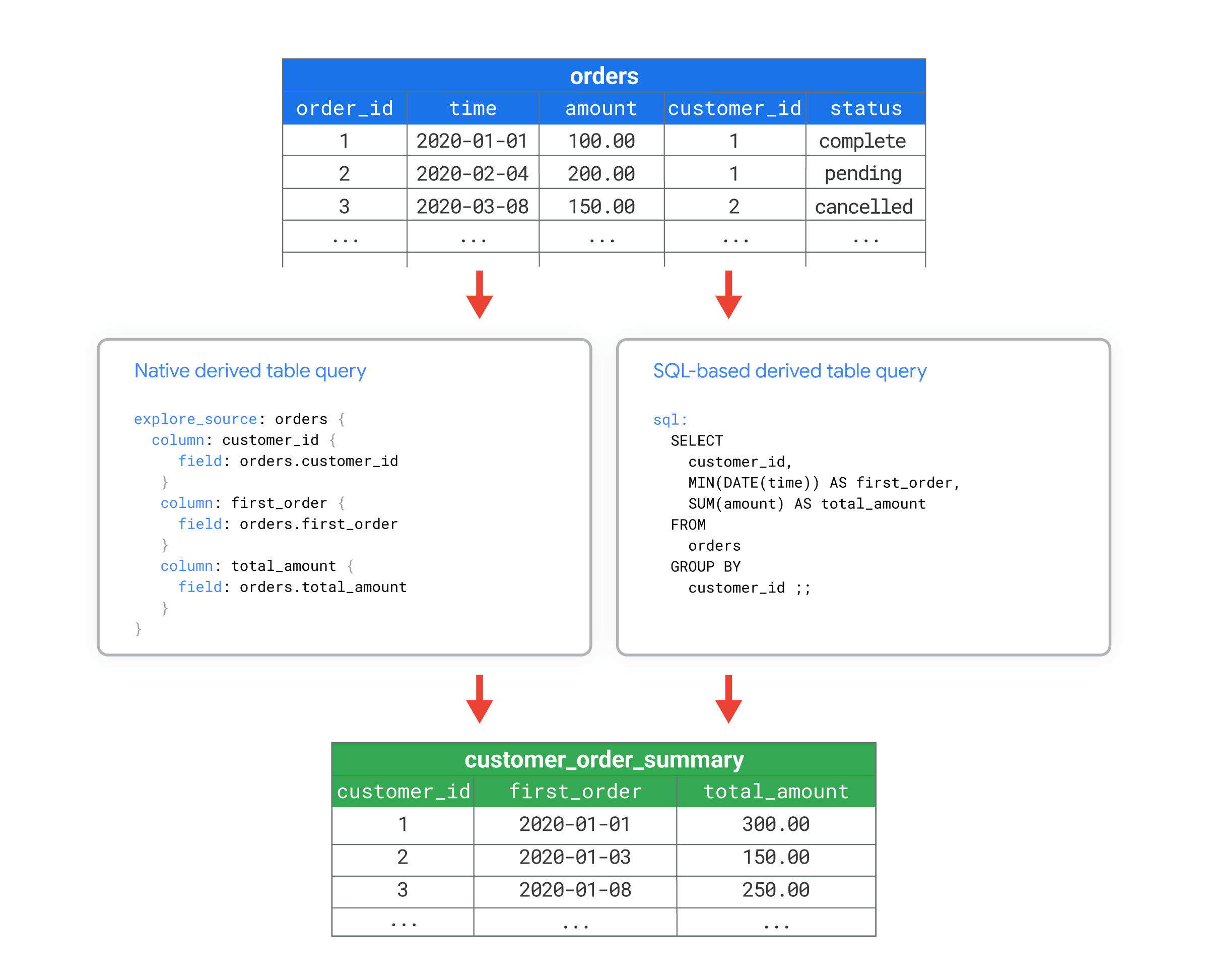
Imaginons par exemple que vous ayez une table de base de données intitulée orders possédant de nombreuses colonnes. Vous souhaitez calculer certaines métriques agrégées au niveau du client, comme le nombre de commandes passées par chaque client ou le moment auquel chaque client a passé sa première commande. Vous pouvez créer une table de base de données nommée customer_order_summary qui inclut ces métriques à l'aide d'une table dérivée native ou d'une table dérivée basée sur SQL.
Vous pouvez désormais travailler avec la table dérivée customer_order_summary comme s'il s'agissait d'une autre table de la base de données.
Pour découvrir les cas d'utilisation courants des tables dérivées, consultez Livres de recettes Looker : tirer le meilleur parti des tables dérivées dans Looker.
Tables dérivées natives et tables dérivées SQL
Pour créer une table dérivée dans votre projet Looker, utilisez le paramètre derived_table sous un paramètre view. Dans le paramètre derived_table, vous pouvez définir la requête pour la table dérivée de l'une des deux manières suivantes :
- Pour une table dérivée native, vous définissez la table dérivée avec une requête basée sur LookML.
- Pour une table dérivée basée sur SQL, vous définissez la table dérivée avec une requête SQL.
Par exemple, les fichiers de vue suivants montrent comment utiliser LookML pour créer une vue à partir d'une table dérivée customer_order_summary. Les deux versions de LookML illustrent comment créer des tables dérivées équivalentes en utilisant LookML ou SQL pour définir la requête pour la table dérivée :
- La table dérivée native définit la requête avec LookML dans le paramètre
explore_source. Dans cet exemple, la requête est basée sur une vueordersexistante, définie dans un fichier distinct qui n'est pas présenté dans cet exemple. La requêteexplore_sourcedans la table dérivée native importe les champscustomer_id,first_orderettotal_amountà partir du fichier de vueorders. - La table dérivée basée sur SQL définit la requête à l'aide de SQL dans le paramètre
sql. Dans cet exemple, la requête SQL est une requête directe de la tableordersdans la base de données.
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: first_order {
field: orders.first_order
}
column: total_amount {
field: orders.total_amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
view: customer_order_summary {
derived_table: {
sql:
SELECT
customer_id,
MIN(DATE(time)) AS first_order,
SUM(amount) AS total_amount
FROM
orders
GROUP BY
customer_id ;;
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
Les deux versions créent une vue appelée customer_order_summary basée sur la table orders, avec les colonnes customer_id, first_order, et total_amount.
À l'exception du paramètre derived_table et de ses sous-paramètres, cette vue customer_order_summary fonctionne comme n'importe quel autre fichier de vue. Que vous définissiez la requête de la table dérivée avec LookML ou SQL, vous pouvez créer des mesures et dimensions LookML basées sur les colonnes de la table dérivée.
Une fois que vous avez défini votre table dérivée, vous pouvez l'utiliser comme n'importe quelle autre table dans votre base de données.
Tables dérivées natives
Les tables dérivées natives sont basées sur des requêtes que vous définissez en utilisant les termes LookML. Pour créer une table dérivée native, vous utilisez le paramètre explore_source à l'intérieur du paramètre derived_table d'un paramètre view. Vous créez les colonnes de votre table dérivée native en vous référant aux dimensions et mesures LookML dans votre modèle. Consultez le fichier de vue Tableau dérivée native dans l'exemple précédent.
Comparées aux tables dérivées basées sur SQL, les tables dérivées natives sont beaucoup plus faciles à lire et à comprendre lors de la modélisation des données.
Pour savoir comment créer des tables dérivées natives, consultez la page de documentation Créer des tables dérivées natives.
Tables dérivées basées sur SQL
Pour créer une table dérivée basée sur SQL, vous devez définir une requête SQL, en créant des colonnes dans la table à l'aide d'une requête SQL. Vous ne pouvez pas faire référence à des dimensions et mesures LookML dans une table dérivée basée sur SQL. Consultez le fichier de vue Tableau dérivée basée sur SQL dans l'exemple précédent.
Le plus souvent, vous définissez la requête SQL à l'aide du paramètre sql à l'intérieur du paramètre derived_table d'un paramètre view.
Pour créer des requêtes basées sur SQL dans Looker, un raccourci utile consiste à utiliser SQL Runner pour créer la requête SQL et la convertir en définition de table dérivée.
Certains cas extrêmes ne permettent pas d'utiliser le paramètre sql. Dans ce cas, Looker prend en charge les paramètres suivants pour définir une requête SQL pour les tables dérivées persistantes (PDT) :
create_process: lorsque vous utilisez le paramètresqlpour une PDT, Looker encapsule en arrière-plan l'instruction LDD (langage de définition de données)CREATE TABLEdu dialecte autour de votre requête pour créer la PDT à partir de votre requête SQL. Certains dialectes ne prennent pas en charge l'instruction SQLCREATE TABLEen une seule étape. Pour ces dialectes, vous ne pouvez pas créer de PDT avec le paramètresql. Vous pouvez en revanche utiliser le paramètrecreate_processpour créer une table PDT en plusieurs étapes. Pour obtenir des informations et des exemples, consultez la page de documentation sur le paramètrecreate_process.sql_create: si votre cas d'utilisation nécessite des commandes DDL personnalisées et que votre dialecte est compatible avec LDD (par exemple, BigQuery ML prédictif de Google), vous pouvez utiliser le paramètresql_createpour créer une PDT au lieu d'utiliser le paramètresql. Pour obtenir des informations et des exemples, consultez la page de documentationsql_create.
Que vous utilisiez le paramètre sql, create_process ou sql_create, vous définissez dans tous les cas la table dérivée avec une requête SQL. Il s'agit donc de tables dérivées basées sur SQL.
Lorsque vous définissez une table dérivée basée sur SQL, assurez-vous de donner à chaque colonne un alias clair en utilisant AS. En effet, vous devez mentionner les noms de colonnes du jeu de résultats dans vos dimensions, comme ${TABLE}.first_order. C'est pourquoi l'exemple précédent utilise MIN(DATE(time)) AS first_order au lieu de MIN(DATE(time)).
Tables dérivées temporaires et persistantes
En plus de la distinction entre les tables dérivées natives et celles basées sur SQL, il existe également une distinction entre les tables dérivées temporaires (qui ne sont pas écrites dans la base de données) et les tables dérivées persistantes (PDT, Persistent Derived Tables), qui sont écrites dans un schéma de votre base de données.
Les tables dérivées natives et tables dérivées basées sur SQL peuvent être temporaires ou persistantes.
Tables dérivées temporaires
Les tables dérivées présentées précédemment sont des exemples de tables dérivées temporaires. Elles sont temporaires, car aucune stratégie de persistance n'est définie dans le paramètre derived_table.
Les tables dérivées temporaires ne sont pas écrites sur la base de données. Lorsqu'un utilisateur exécute une requête Explorer impliquant une ou plusieurs tables dérivées, Looker construit une requête SQL en utilisant une combinaison spécifique au dialecte du code SQL de la ou des tables dérivées et des champs, jointures et valeurs de filtre nécessaires. Si la combinaison a été exécutée auparavant et que les résultats se trouvent toujours dans le cache, Looker utilise les résultats mis en cache. Pour en savoir plus sur la mise en cache des requêtes dans Looker, consultez la page de documentation Mise en cache des requêtes.
Autrement, si Looker ne peut pas utiliser de résultats mis en cache, il doit exécuter une nouvelle requête sur votre base de données à chaque fois qu'un utilisateur demande des données d'une table dérivée temporaire. C'est pourquoi vous devriez vous assurer que vos tables dérivées temporaires sont performantes et ne soumettent pas la base à une charge excessive. Lorsque l'exécution des requêtes prend un certain temps, il est souvent préférable d'utiliser une PDT.
Dialectes de base de données pris en charge pour les tables dérivées temporaires
Pour que Looker prenne en charge les tables dérivées dans votre projet, votre dialecte de base de données doit également les prendre en charge. Le tableau suivant répertorie les dialectes prenant en charge les tables dérivées dans la dernière version de Looker :
Cliquez ici pour afficher le tableau.
| Dialecte | Compatibilité |
|---|---|
| Actian Avalanche | Oui |
| Amazon Athena | Oui |
| Amazon Aurora MySQL | Oui |
| Amazon Redshift | Oui |
| Amazon Redshift 2.1+ | Oui |
| Amazon Redshift Serverless 2.1+ | Oui |
| Apache Druid | Oui |
| Apache Druid 0.13+ | Oui |
| Apache Druid 0.18+ | Oui |
| Apache Hive 2.3+ | Oui |
| Apache Hive 3.1.2+ | Oui |
| Apache Spark 3+ | Oui |
| ClickHouse | Oui |
| Cloudera Impala 3.1+ | Oui |
| Cloudera Impala 3.1+ with Native Driver | Oui |
| Cloudera Impala with Native Driver | Oui |
| DataVirtuality | Oui |
| Databricks | Oui |
| Denodo 7 | Oui |
| Denodo 8 & 9 | Oui |
| Dremio | Oui |
| Dremio 11+ | Oui |
| Exasol | Oui |
| Google BigQuery Legacy SQL | Oui |
| Google BigQuery Standard SQL | Oui |
| Google Cloud PostgreSQL | Oui |
| Google Cloud SQL | Oui |
| Google Spanner | Oui |
| Greenplum | Oui |
| HyperSQL | Oui |
| IBM Netezza | Oui |
| MariaDB | Oui |
| Microsoft Azure PostgreSQL | Oui |
| Microsoft Azure SQL Database | Oui |
| Microsoft Azure Synapse Analytics | Oui |
| Microsoft SQL Server 2008+ | Oui |
| Microsoft SQL Server 2012+ | Oui |
| Microsoft SQL Server 2016 | Oui |
| Microsoft SQL Server 2017+ | Oui |
| MongoBI | Oui |
| MySQL | Oui |
| MySQL 8.0.12+ | Oui |
| Oracle | Oui |
| Oracle ADWC | Oui |
| PostgreSQL 9.5+ | Oui |
| PostgreSQL pre-9.5 | Oui |
| PrestoDB | Oui |
| PrestoSQL | Oui |
| SAP HANA | Oui |
| SAP HANA 2+ | Oui |
| SingleStore | Oui |
| SingleStore 7+ | Oui |
| Snowflake | Oui |
| Teradata | Oui |
| Trino | Oui |
| Vector | Oui |
| Vertica | Oui |
Tables dérivées persistantes
Une table dérivée persistante (PDT) est une table dérivée qui est écrite dans un schéma entièrement nouveau de la base de données et régénérée selon la fréquence que vous définissez avec une stratégie de persistance.
Une PDT peut être une table dérivée native ou une table dérivée basée sur SQL.
Conditions requises pour les tables PDT
Pour utiliser des tables dérivées persistantes (PDT) dans votre projet Looker, vous avez besoin des éléments suivants :
- Un dialecte de base de données qui prend en charge les PDT. Consultez la section Dialectes de base de données compatibles avec les PDT plus loin sur cette page pour obtenir la liste des dialectes compatibles avec les tables dérivées persistantes basées sur SQL et les tables dérivées persistantes natives.
Un schéma entièrement nouveau sur votre base de données. Il peut s'agir de n'importe quel schéma sur votre base de données mais nous vous recommandons de créer un nouveau schéma qui sera utilisé uniquement à cette fin. Votre administrateur de base de données doit configurer le schéma avec une autorisation d'écriture pour l'utilisateur de la base de données Looker.
Une connexion Looker configurée avec l'option Activer les PDT activée. Le paramètre Activer les PDT est généralement configuré lorsque vous configurez initialement votre connexion Looker (consultez la page de documentation sur les dialectes Looker pour obtenir des instructions concernant le dialecte de votre base de données). Toutefois, vous pouvez également activer les PDT pour votre connexion après la configuration initiale.
Dialectes de base de données pris en charge pour les tables PDT
Pour que Looker prenne en charge les tables PDT dans votre projet, votre dialecte de base de données doit également les prendre en charge.
Pour prendre en charge tout type de PDT (basées sur LookML ou SQL), le dialecte doit prendre en charge les écritures sur la base de données, parmi d'autres conditions. Certaines configurations de bases de données en lecture seule n'autorisent pas la persistance (il s'agit généralement de bases de données de réplication à chaud Postgres). Dans ce type de cas, il est préférable d'utiliser des tables dérivées temporaires.
Le tableau suivant indique les dialectes qui prennent en charge les tables dérivées persistantes basées sur SQL dans la dernière version de Looker :
Cliquez ici pour afficher le tableau.
| Dialecte | Compatibilité |
|---|---|
| Actian Avalanche | Oui |
| Amazon Athena | Oui |
| Amazon Aurora MySQL | Oui |
| Amazon Redshift | Oui |
| Amazon Redshift 2.1+ | Oui |
| Amazon Redshift Serverless 2.1+ | Oui |
| Apache Druid | Non |
| Apache Druid 0.13+ | Non |
| Apache Druid 0.18+ | Non |
| Apache Hive 2.3+ | Oui |
| Apache Hive 3.1.2+ | Oui |
| Apache Spark 3+ | Oui |
| ClickHouse | Non |
| Cloudera Impala 3.1+ | Oui |
| Cloudera Impala 3.1+ with Native Driver | Oui |
| Cloudera Impala with Native Driver | Oui |
| DataVirtuality | Non |
| Databricks | Oui |
| Denodo 7 | Non |
| Denodo 8 & 9 | Non |
| Dremio | Non |
| Dremio 11+ | Non |
| Exasol | Oui |
| Google BigQuery Legacy SQL | Oui |
| Google BigQuery Standard SQL | Oui |
| Google Cloud PostgreSQL | Oui |
| Google Cloud SQL | Oui |
| Google Spanner | Non |
| Greenplum | Oui |
| HyperSQL | Non |
| IBM Netezza | Oui |
| MariaDB | Oui |
| Microsoft Azure PostgreSQL | Oui |
| Microsoft Azure SQL Database | Oui |
| Microsoft Azure Synapse Analytics | Oui |
| Microsoft SQL Server 2008+ | Oui |
| Microsoft SQL Server 2012+ | Oui |
| Microsoft SQL Server 2016 | Oui |
| Microsoft SQL Server 2017+ | Oui |
| MongoBI | Non |
| MySQL | Oui |
| MySQL 8.0.12+ | Oui |
| Oracle | Oui |
| Oracle ADWC | Oui |
| PostgreSQL 9.5+ | Oui |
| PostgreSQL pre-9.5 | Oui |
| PrestoDB | Oui |
| PrestoSQL | Oui |
| SAP HANA | Oui |
| SAP HANA 2+ | Oui |
| SingleStore | Oui |
| SingleStore 7+ | Oui |
| Snowflake | Oui |
| Teradata | Oui |
| Trino | Oui |
| Vector | Oui |
| Vertica | Oui |
Pour prendre en charge les tables dérivées natives persistantes (qui comprennent des requêtes basées sur LookML), le dialecte doit également prendre en charge une fonction LDD CREATE TABLE. Voici la liste des dialectes qui prennent en charge les tables dérivées natives (basées sur LookML) persistantes dans la dernière version de Looker :
Cliquez ici pour afficher le tableau.
| Dialecte | Compatibilité |
|---|---|
| Actian Avalanche | Oui |
| Amazon Athena | Oui |
| Amazon Aurora MySQL | Oui |
| Amazon Redshift | Oui |
| Amazon Redshift 2.1+ | Oui |
| Amazon Redshift Serverless 2.1+ | Oui |
| Apache Druid | Non |
| Apache Druid 0.13+ | Non |
| Apache Druid 0.18+ | Non |
| Apache Hive 2.3+ | Oui |
| Apache Hive 3.1.2+ | Oui |
| Apache Spark 3+ | Oui |
| ClickHouse | Non |
| Cloudera Impala 3.1+ | Oui |
| Cloudera Impala 3.1+ with Native Driver | Oui |
| Cloudera Impala with Native Driver | Oui |
| DataVirtuality | Non |
| Databricks | Oui |
| Denodo 7 | Non |
| Denodo 8 & 9 | Non |
| Dremio | Non |
| Dremio 11+ | Non |
| Exasol | Oui |
| Google BigQuery Legacy SQL | Oui |
| Google BigQuery Standard SQL | Oui |
| Google Cloud PostgreSQL | Oui |
| Google Cloud SQL | Non |
| Google Spanner | Non |
| Greenplum | Oui |
| HyperSQL | Non |
| IBM Netezza | Oui |
| MariaDB | Oui |
| Microsoft Azure PostgreSQL | Oui |
| Microsoft Azure SQL Database | Oui |
| Microsoft Azure Synapse Analytics | Oui |
| Microsoft SQL Server 2008+ | Oui |
| Microsoft SQL Server 2012+ | Oui |
| Microsoft SQL Server 2016 | Oui |
| Microsoft SQL Server 2017+ | Oui |
| MongoBI | Non |
| MySQL | Oui |
| MySQL 8.0.12+ | Oui |
| Oracle | Oui |
| Oracle ADWC | Oui |
| PostgreSQL 9.5+ | Oui |
| PostgreSQL pre-9.5 | Oui |
| PrestoDB | Oui |
| PrestoSQL | Oui |
| SAP HANA | Oui |
| SAP HANA 2+ | Oui |
| SingleStore | Oui |
| SingleStore 7+ | Oui |
| Snowflake | Oui |
| Teradata | Oui |
| Trino | Oui |
| Vector | Oui |
| Vertica | Oui |
Augmentation de la génération de tables PDT
Une augmentation de table PDT est une table dérivée persistante que Looker crée en ajoutant des données à jour à la table, au lieu de la régénérer entièrement.
Si votre dialecte prend en charge les PDT incrémentales et que votre PDT utilise une stratégie de persistance basée sur un déclencheur (datagroup_trigger, sql_trigger_value ou interval_trigger), vous pouvez définir la PDT comme PDT incrémentale.
Pour en savoir plus, consultez la page de documentation sur les TPD incrémentaux.
Dialectes de base de données pris en charge pour les augmentations de tables PDT
Pour que Looker prenne en charge les augmentations de tables PDT dans votre projet, votre dialecte de base de données doit également les prendre en charge. Le tableau suivant indique les dialectes qui prennent en charge les tables PDT incrémentielles dans la dernière version de Looker :
Cliquez ici pour afficher le tableau.
| Dialecte | Compatibilité |
|---|---|
| Actian Avalanche | Non |
| Amazon Athena | Non |
| Amazon Aurora MySQL | Non |
| Amazon Redshift | Oui |
| Amazon Redshift 2.1+ | Oui |
| Amazon Redshift Serverless 2.1+ | Oui |
| Apache Druid | Non |
| Apache Druid 0.13+ | Non |
| Apache Druid 0.18+ | Non |
| Apache Hive 2.3+ | Non |
| Apache Hive 3.1.2+ | Non |
| Apache Spark 3+ | Non |
| ClickHouse | Non |
| Cloudera Impala 3.1+ | Non |
| Cloudera Impala 3.1+ with Native Driver | Non |
| Cloudera Impala with Native Driver | Non |
| DataVirtuality | Non |
| Databricks | Oui |
| Denodo 7 | Non |
| Denodo 8 & 9 | Non |
| Dremio | Non |
| Dremio 11+ | Non |
| Exasol | Non |
| Google BigQuery Legacy SQL | Non |
| Google BigQuery Standard SQL | Oui |
| Google Cloud PostgreSQL | Oui |
| Google Cloud SQL | Non |
| Google Spanner | Non |
| Greenplum | Oui |
| HyperSQL | Non |
| IBM Netezza | Non |
| MariaDB | Non |
| Microsoft Azure PostgreSQL | Oui |
| Microsoft Azure SQL Database | Non |
| Microsoft Azure Synapse Analytics | Oui |
| Microsoft SQL Server 2008+ | Non |
| Microsoft SQL Server 2012+ | Non |
| Microsoft SQL Server 2016 | Non |
| Microsoft SQL Server 2017+ | Non |
| MongoBI | Non |
| MySQL | Oui |
| MySQL 8.0.12+ | Oui |
| Oracle | Non |
| Oracle ADWC | Non |
| PostgreSQL 9.5+ | Oui |
| PostgreSQL pre-9.5 | Oui |
| PrestoDB | Non |
| PrestoSQL | Non |
| SAP HANA | Non |
| SAP HANA 2+ | Non |
| SingleStore | Non |
| SingleStore 7+ | Non |
| Snowflake | Oui |
| Teradata | Non |
| Trino | Non |
| Vector | Non |
| Vertica | Oui |
Créer des PDT
Pour transformer une table dérivée en table dérivée persistante (PDT), vous devez définir une stratégie de persistance pour la table. Pour optimiser les performances, vous devez également ajouter une stratégie d'optimisation.
Stratégies de persistance
La persistance d'une table dérivée peut être gérée par Looker ou, pour les dialectes compatibles avec les vues matérialisées, par votre base de données à l'aide de vues matérialisées.
Pour rendre une table dérivée persistante, ajoutez l'un des paramètres suivants à la définition derived_table :
- Paramètres de persistance gérés par Looker :
- Paramètres de persistance gérés par la base de données :
Avec les stratégies de persistance basées sur des déclencheurs (datagroup_trigger, sql_trigger_value et interval_trigger), Looker conserve la table PDT dans la base de données jusqu'à ce qu'elle soit déclenchée pour être reconstruite. Une fois la PDT déclenchée, Looker la régénère pour remplacer la version précédente. Ainsi, avec les PDT basées sur des éléments déclencheurs, vos utilisateurs n'auront pas à attendre que la PDT soit générée pour obtenir des réponses pour les requêtes d'exploration issues de la PDT.
datagroup_trigger
Les groupes de données constituent la méthode la plus souple pour créer de la persistance. Si vous avez défini un groupe de données avec sql_trigger ou interval_trigger, vous pouvez utiliser le paramètre datagroup_trigger pour lancer la régénération de vos tables dérivées persistantes (PDT).
Looker maintient la table PDT dans la base de données jusqu'au déclenchement de son groupe de données. Une fois le groupe de données déclenché, Looker régénère la table PDT pour remplacer la version précédente. Ainsi, dans la plupart des cas, les utilisateurs n'auront pas à attendre que la table PDT soit générée. Si un utilisateur demande des données d'une table PDT en cours de génération et si les résultats de la requête ne sont pas mis en cache, Looker renvoie les données de la table PDT existante jusqu'à la génération de la nouvelle PDT. Pour obtenir une présentation des groupes de données, consultez Mise en cache des requêtes.
Consultez la section Régénérateur Looker pour en savoir plus sur la façon dont le régénérateur crée des tables PDT.
sql_trigger_value
Le paramètre sql_trigger_value déclenche la régénération d'une table dérivée persistante (PDT) basée sur une instruction SQL que vous fournissez. Si le résultat de l'instruction SQL est différent de la valeur précédente, la table PDT est régénérée. Sinon, la table PDT existante est maintenue dans la base de données. Ainsi, dans la plupart des cas, les utilisateurs n'auront pas à attendre que la table PDT soit générée. Si un utilisateur demande des données d'une table PDT en cours de génération et si les résultats de la requête ne sont pas mis en cache, Looker renvoie les données de la table PDT existante jusqu'à la génération de la nouvelle PDT.
Consultez la section Régénérateur Looker pour en savoir plus sur la façon dont le régénérateur crée des tables PDT.
interval_trigger
Le paramètre interval_trigger déclenche la régénération d'une table dérivée persistante (PDT) en fonction d'un intervalle de temps que vous fournissez, tel que "24 hours" ou "60 minutes". De même que le paramètre sql_trigger, ceci signifie qu'habituellement la PDT sera prédéfinie au moment où vos utilisateurs en font la requête. Si un utilisateur demande des données d'une table PDT en cours de génération et si les résultats de la requête ne sont pas mis en cache, Looker renvoie les données de la table PDT existante jusqu'à la génération de la nouvelle PDT.
persist_for
Vous pouvez également utiliser le paramètre persist_for pour définir la durée pendant laquelle la table dérivée doit être stockée avant d'être marquée comme expirée. Elle ne sera alors plus utilisée pour les requêtes et sera supprimée de la base de données.
Une persist_for table dérivée persistante (PDT) est créée lorsqu'un utilisateur exécute une requête pour la première fois dessus. Looker maintient ensuite la table PDT dans la base de données pendant la durée spécifiée dans le paramètre persist_for de la table PDT. Si un utilisateur envoie une requête à la table PDT pendant la période persist_for, Looker utilise les résultats mis en cache, le cas échéant, ou exécute la requête sur la table PDT.
Après le délai persist_for, Looker efface la PDT de votre base de données et la table est régénérée lors de la demande de données suivante, et l'utilisateur doit attendre la fin de la régénération.
Les PDT qui utilisent persist_for ne sont pas automatiquement régénérées par le générateur Looker, sauf en cas de cascade de dépendances de PDT. Lorsqu'une table persist_for fait partie d'une cascade de dépendances avec des tables PDT basées sur des déclencheurs (tables PDT qui utilisent la stratégie de persistance datagroup_trigger, interval_trigger ou sql_trigger_value), le régénérateur surveille et régénère la table persist_for afin de régénérer les autres tables de la cascade. Consultez la section Comment Looker génère des tables dérivées en cascade sur cette page.
materialized_view: yes
Les vues matérialisées vous permettent d'utiliser la fonctionnalité de votre base de données pour rendre persistantes vos tables dérivées dans votre projet Looker. Si le dialecte de votre base de données prend en charge les vues matérialisées et que votre connexion Looker est configurée avec l'option Activer les PDT activée, vous pouvez créer une vue matérialisée en spécifiant materialized_view: yes pour une table dérivée. Les vues matérialisées sont compatibles avec les tables dérivées natives et les tables dérivées basées sur SQL.
Similaire à une table dérivée persistante (PDT), une vue matérialisée est le résultat d'une requête enregistrée sous la forme d'une table dans le schéma entièrement nouveau de votre base de données. La principale différence entre une PDT et une vue matérialisée se situe au niveau de l'actualisation des tables :
- Pour les PDT, la stratégie de persistance est définie dans Looker, et la persistance est gérée par Looker.
- Pour les vues matérialisées, la base de données est responsable de l'entretien et de l'actualisation des données de la table.
Pour cette raison, la fonctionnalité vue matérialisée nécessite une connaissance avancée de votre dialecte et de ses caractéristiques. Dans la plupart des cas, votre base de données actualisera la vue matérialisée à chaque fois qu'elle détectera de nouvelles données dans les tables interrogées par la vue matérialisée. Les vues matérialisées sont optimales pour les scénarios requérant des données en temps réel.
Consultez la page de documentation sur le paramètre materialized_view pour en savoir plus sur les dialectes compatibles, les exigences et les points importants à prendre en compte.
Stratégies d'optimisation
Étant donné que des tables dérivées persistantes (PDT) sont stockées dans votre base de données, vous devriez optimiser vos PDT en suivant les stratégies suivantes, selon ce que prend en charge votre dialecte :
Par exemple, pour ajouter de la persistance à l'exemple de table dérivée, vous pouvez la définir pour qu'elle se reconstruise lorsque le groupe de données orders_datagroup se déclenche, et ajouter des index sur customer_id et first_order, comme ceci :
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
Si vous n'ajoutez aucun index (ni équivalent pour votre dialecte), Looker vous invite à le faire pour améliorer les performances des requêtes.
Cas d'utilisation des TPD
Les tables dérivées persistantes (PDT) sont utiles, car elles peuvent améliorer les performances d'une requête en conservant les résultats de la requête dans une table.
En règle générale, les développeurs doivent essayer de modéliser les données sans utiliser de PDT jusqu'à ce que cela soit absolument nécessaire.
Dans certains cas, les données peuvent être optimisées par d'autres moyens. Par exemple, l'ajout d'un index ou la modification du type de données d'une colonne peuvent résoudre un problème sans qu'il soit nécessaire de créer une PDT. Veillez à analyser les plans d'exécution des requêtes lentes à l'aide de l'outil "Expliquer" de SQL Runner.
En plus de réduire la durée des requêtes et la charge de la base de données pour les requêtes fréquemment exécutées, les PDT peuvent être utilisées dans plusieurs autres cas, y compris :
Vous pouvez également utiliser un PDT pour définir une clé primaire dans les cas où il n'existe aucun moyen raisonnable d'identifier une ligne unique dans une table comme clé primaire.
Utiliser les PDT pour tester les optimisations
Vous pouvez utiliser les PDT pour tester différentes options d'indexation, de distribution et d'optimisation sans avoir besoin d'une assistance importante de la part de votre administrateur de base de données ou de vos développeurs ETL.
Prenons l'exemple d'une table pour laquelle vous souhaitez tester différents index. Voici un exemple de code LookML initial pour la vue :
view: customer {
sql_table_name: warehouse.customer ;;
}
Pour tester des stratégies d'optimisation, vous pouvez utiliser le paramètre indexes pour ajouter des index au code LookML, comme ceci :
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Interrogez la vue une fois pour générer la PDT. Exécutez ensuite vos requêtes de test et comparez vos résultats. Si vos résultats sont favorables, vous pouvez demander à votre équipe DBA ou ETL d'ajouter les index à la table d'origine.
N'oubliez pas de modifier à nouveau le code de vue pour supprimer le PDT.
Utiliser des PDT pour préjoindre ou agréger des données
Il peut être utile de préjoindre ou de préagréger les données pour ajuster l'optimisation des requêtes pour les volumes élevés ou les types de données multiples.
Par exemple, supposons que vous souhaitiez créer une requête pour les clients par cohorte en fonction de la date de leur première commande. Cette requête peut être coûteuse à exécuter plusieurs fois chaque fois que les données sont nécessaires en temps réel. Toutefois, vous pouvez calculer la requête une seule fois, puis réutiliser les résultats avec une PDT :
view: customer_order_facts {
derived_table: {
sql: SELECT
c.customer_id,
MIN(o.order_date) OVER (PARTITION BY c.customer_id) AS first_order_date,
MAX(o.order_date) OVER (PARTITION BY c.customer_id) AS most_recent_order_date,
COUNT(o.order_id) OVER (PARTITION BY c.customer_id) AS lifetime_orders,
SUM(o.order_value) OVER (PARTITION BY c.customer_id) AS lifetime_value,
RANK() OVER (PARTITION BY c.customer_id ORDER BY o.order_date ASC) AS order_sequence,
o.order_id
FROM warehouse.customer c LEFT JOIN warehouse.order o ON c.customer_id = o.customer_id
;;
sql_trigger_value: SELECT CURRENT_DATE ;;
indexes: [customer_id, order_id, order_sequence, first_order_date]
}
}
Tables dérivées en cascade
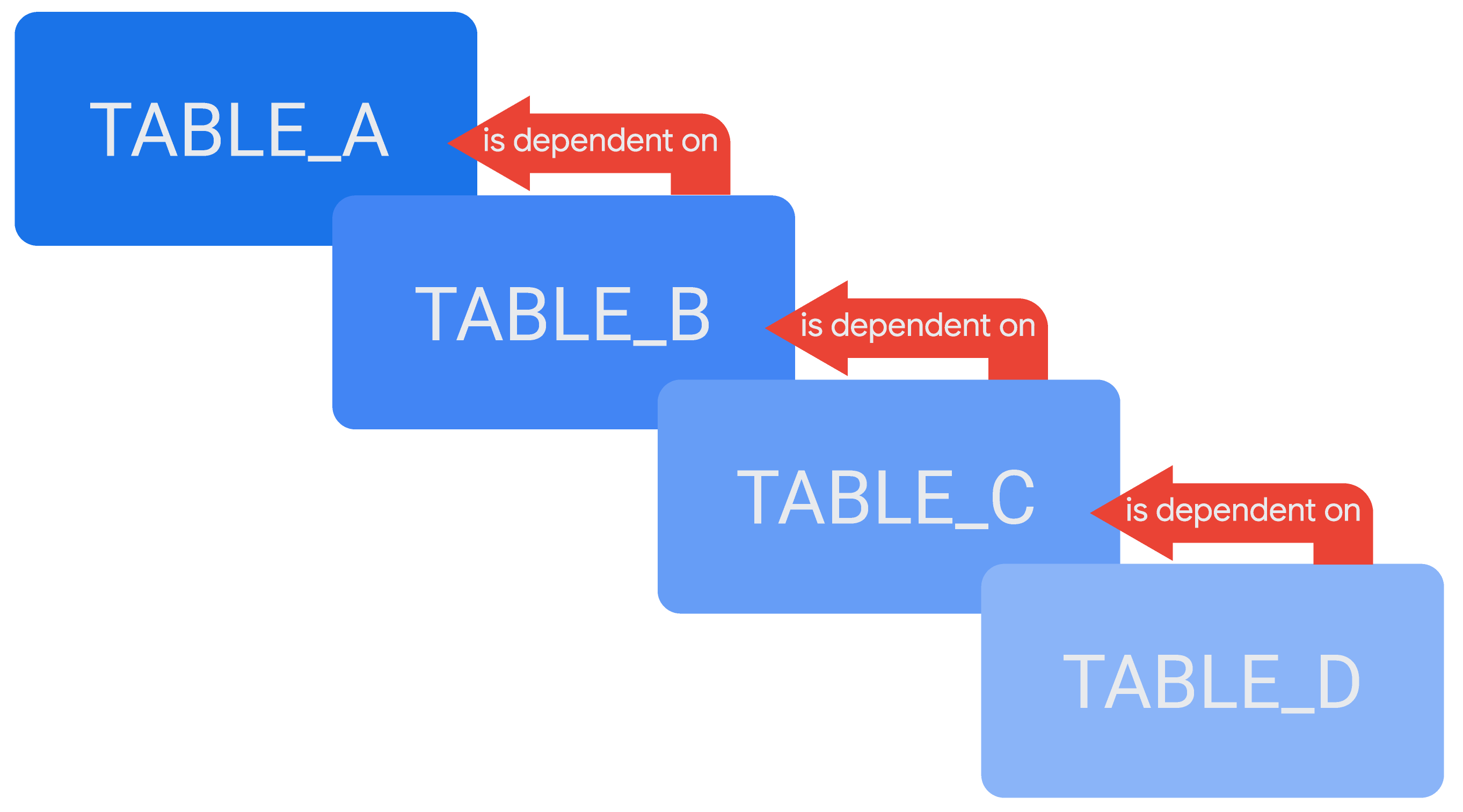
Il est possible de référencer une table dérivée dans la définition d'une autre, créant ainsi une chaîne de tables dérivées en cascade ou de tables dérivées persistantes (PDT) en cascade, selon le cas. Un exemple de tables dérivées en cascade serait une table, TABLE_D, qui dépend d'une autre table, TABLE_C, tandis que TABLE_C dépend de TABLE_B et que TABLE_B dépend de TABLE_A.
Syntaxe pour référencer une table dérivée
Pour référencer une table dérivée dans une autre table dérivée, utilisez cette syntaxe :
`${derived_table_or_view_name.SQL_TABLE_NAME}`
Dans ce format, SQL_TABLE_NAME est une chaîne littérale. Par exemple, vous pouvez faire référence à la table dérivée clean_events avec cette syntaxe :
`${clean_events.SQL_TABLE_NAME}`
Vous pouvez utiliser la même syntaxe pour désigner une vue LookML. À nouveau, dans ce cas, SQL_TABLE_NAME est une chaîne littérale.
Dans l'exemple suivant, la PDT clean_events est créée à partir de la table events de la base de données. Le PDT clean_events exclut les lignes indésirables de la table de base de données events. Une seconde PDT, event_summary, qui est une synthèse de la PDT clean_events, est affichée. La table event_summary est régénérée chaque fois que de nouvelles lignes sont ajoutées à clean_events.
Les PDT event_summary et clean_events sont des PDT en cascade, où event_summary dépend de clean_events (puisque event_summary est défini à l'aide de la PDT clean_events). Cet exemple particulier pourrait être plus efficace avec une seule PDT, mais il nous permet d'illustrer les références à ce type de table.
view: clean_events {
derived_table: {
sql:
SELECT *
FROM events
WHERE type NOT IN ('test', 'staff') ;;
datagroup_trigger: events_datagroup
}
}
view: events_summary {
derived_table: {
sql:
SELECT
type,
date,
COUNT(*) AS num_events
FROM
${clean_events.SQL_TABLE_NAME} AS clean_events
GROUP BY
type,
date ;;
datagroup_trigger: events_datagroup
}
}
Bien que ce ne soit pas toujours nécessaire, lorsque vous référencez une table dérivée de cette façon, il est souvent utile de créer un alias pour la table en utilisant ce format :
${derived_table_or_view_name.SQL_TABLE_NAME} AS derived_table_or_view_name
L'exemple précédent donne le résultat suivant :
${clean_events.SQL_TABLE_NAME} AS clean_events
Il est judicieux d'utiliser un alias, car en arrière-plan, les tables PDT sont nommées dans la base de données avec de longs codes. Dans certains cas (en particulier avec les clauses ON), il n'est pas rare d'oublier qu'il faut utiliser la syntaxe ${derived_table_or_view_name.SQL_TABLE_NAME} pour extraire ce long nom. Un alias permet d'éviter ce type d'erreur.
Comment Looker génère des tables dérivées en cascade
En cas de tables dérivées temporaires en cascade, si les résultats d'une requête d'utilisateur ne sont pas mis en cache, Looker génère toutes les tables dérivées nécessaires pour la requête. Si vous avez un TABLE_D dont la définition contient une référence à TABLE_C, alors TABLE_D est dépendant de TABLE_C. Cela signifie que, si vous interrogez TABLE_D et que la requête ne se trouve pas dans le cache de Looker, Looker régénère TABLE_D. Mais avant cela, il doit reconstruire TABLE_C.
Prenons l'exemple d'un scénario avec des tables dérivées temporaires en cascade, où TABLE_D dépend de TABLE_C, qui dépend de TABLE_B, qui dépend de TABLE_A. Si Looker n'a pas de résultats valides pour une requête sur TABLE_C dans le cache, Looker génère toutes les tables nécessaires pour la requête. Looker générera donc TABLE_A, puis TABLE_B, puis TABLE_C :

Dans ce scénario, TABLE_A doit être généré avant que Looker puisse commencer à générer TABLE_B, et TABLE_B doit être généré avant que Looker puisse commencer à générer TABLE_C. Une fois TABLE_C terminé, Looker fournit les résultats de la requête. (Étant donné que TABLE_D n'est pas nécessaire pour répondre à cette requête, Looker ne reconstruira pas TABLE_D pour le moment.)
Consultez la page de documentation sur le paramètre datagroup pour obtenir un exemple de scénario de tables PDT en cascade qui utilisent le même groupe de données.
La même logique de base s'applique aux PDT : Looker génère toutes les tables requises pour répondre à une requête, en remontant la chaîne de dépendances. Mais, avec les PDT, les tables existent déjà souvent et n'ont pas besoin de régénération. Avec les requêtes utilisateur standard sur les tables PDT en cascade, Looker régénère les tables PDT dans la cascade uniquement s'il n'y a aucune version valide de PDT dans la base de données. Si vous souhaitez forcer la régénération de toutes les PDT d'une cascade, vous pouvez régénérer manuellement les tables pour une requête via une exploration.
Il est essentiel de comprendre que, en cas de cascade PDT, une PDT dépendante envoie une requête à la PDT dont elle dépend. C'est particulièrement important si des tables PDT utilisent la stratégie persist_for. En général, les tables PDT persist_for sont générées lorsqu'un utilisateur les demande. Elles restent dans la base de données jusqu'à la fin de leur intervalle persist_for et ne sont pas régénérées tant qu'un utilisateur n'a pas renvoyé de requête. Toutefois, si une PDT persist_for fait partie d'une cascade avec des PDT basées sur des déclencheurs (PDT qui utilisent la stratégie de persistance datagroup_trigger, interval_trigger ou sql_trigger_value), la PDT persist_for est essentiellement interrogée chaque fois que ses PDT dépendantes sont régénérées. Ainsi, la table PDT persist_for sera régénérée à la fréquence de ses tables PDT dépendantes. Cela signifie que les PDT persist_for peuvent être affectées par la stratégie de persistance des tables dont elles dépendent.
Régénération manuelle de tables persistantes pour une requête
Les utilisateurs peuvent sélectionner l'option Recréer les tables dérivées et exécuter dans le menu d'une exploration pour remplacer les paramètres de persistance et recréer toutes les tables dérivées persistantes (PDT) et les tables agrégées requises pour la requête actuelle dans l'exploration :
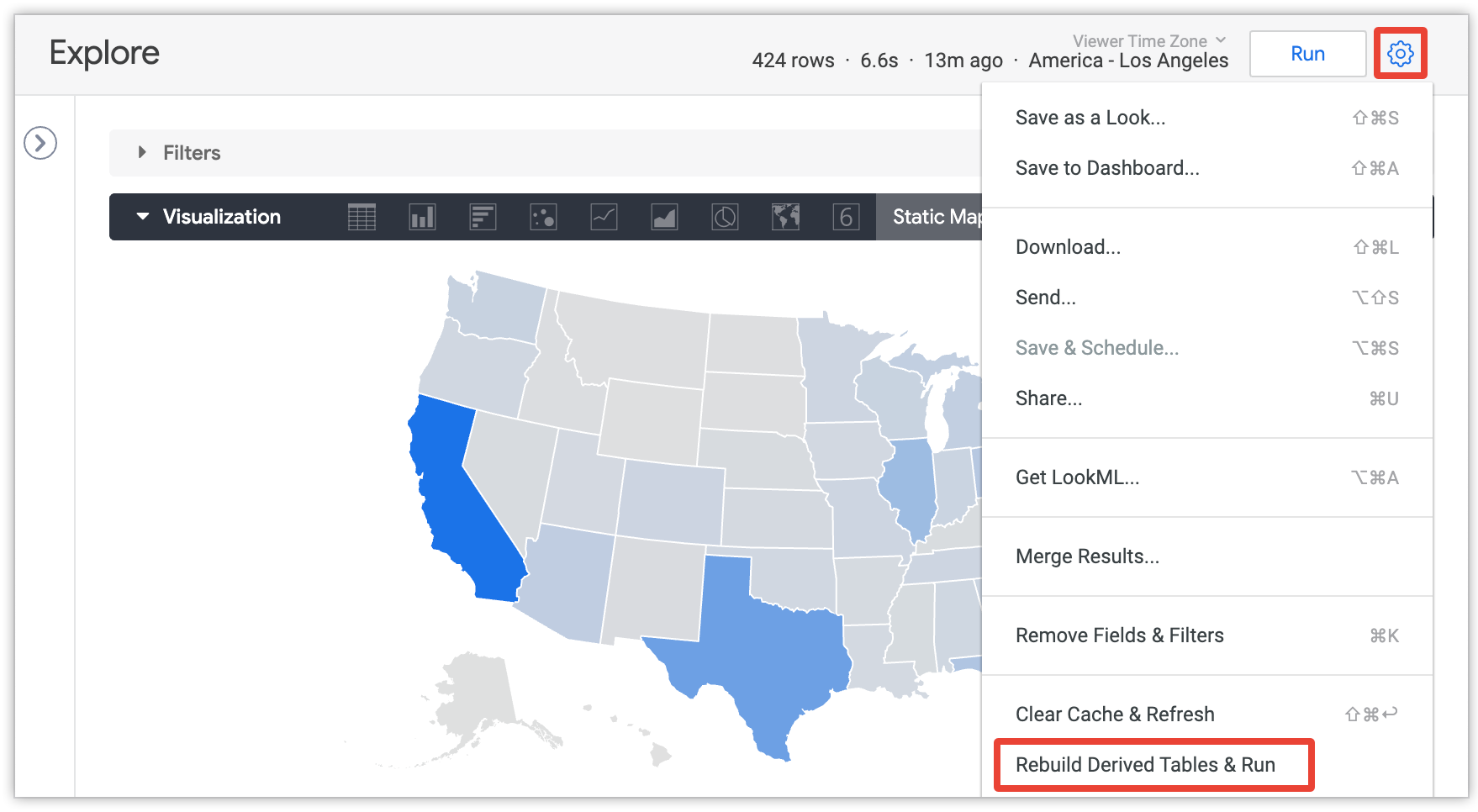
Cette option n'est visible que par les utilisateurs disposant de l'autorisation develop et uniquement après le chargement de la requête Explorer.
L'option Régénérer les tables dérivées et exécuter régénère toutes les tables persistantes (toutes les PDT et les tables agrégées) nécessaires pour répondre à la requête, quelle que soit leur stratégie de persistance. Cela inclut toutes les tables agrégées et les tables PDT dans la requête actuelle, ainsi que toutes les tables agrégées et les tables PDT référencées par les tables agrégées et les tables PDT dans la requête actuelle.
Dans le cas des PDT incrémentielles, l'option Reconstruire les tables dérivées et exécuter déclenche la création d'un nouvel incrément. Avec les PDT incrémentielles, un incrément inclut la période spécifiée dans le paramètre increment_key, ainsi que le nombre de périodes précédentes spécifié dans le paramètre increment_offset, le cas échéant. Consultez la page de documentation PDT incrémentielles pour découvrir des exemples de scénarios montrant comment les PDT incrémentielles sont créées en fonction de leur configuration.
En cas de tables PDT en cascade, toutes les tables dérivées sont régénérées dans la cascade, en commençant par la première. Le même comportement se produit lorsque vous envoyez une requête à une table dans une cascade de tables dérivées temporaires :
Voici quelques points à noter concernant la reconstruction manuelle des tables dérivées :
- Pour l'utilisateur qui sélectionne l'opération Rebuild Derived Tables & Run, la requête attend que les tables soient régénérées avant de charger des résultats. Les requêtes des autres utilisateurs continueront d'utiliser les tables existantes. Une fois les tables persistantes régénérées, tous les utilisateurs s'en servent. Bien que ce processus soit conçu pour ne pas interrompre les requêtes des autres utilisateurs lors de la régénération des tables, ceux-ci risquent malgré tout d'être ralentis par la charge supplémentaire pesant sur la base de données. Si le lancement d'une régénération pendant les heures de bureau risque de soumettre votre base de données à une pression inacceptable, vous devrez peut-être demander aux utilisateurs de ne pas régénérer certaines tables PDT ni agréger de tables pendant ces heures.
Si un utilisateur est en mode Développement et que l'exploration est basée sur une table de développement, l'opération Recréer les tables dérivées et exécuter recréera la table de développement, et non la table de production, pour l'exploration. Toutefois, si l'exploration en mode Développement utilise la version de production d'une table dérivée, la table de production sera reconstruite. Pour en savoir plus sur les tables de développement et de production, consultez Tables persistantes en mode Développement.
Pour les instances hébergées par Looker, si la table dérivée met plus d'une heure à se régénérer, elle ne se régénérera pas correctement et la session du navigateur expirera. Pour en savoir plus sur les délais d'expiration qui peuvent affecter les processus Looker, consultez la section Délais d'expiration et mise en file d'attente des requêtes de la page de documentation Paramètres d'administration – Requêtes.
Tables persistantes en mode Développement
Looker a des comportements spéciaux pour gérer des tables persistantes en mode Développement.
Si vous interrogez une table persistante en mode Développement sans en modifier la définition, Looker interroge la version de production de cette table. Si vous apportez une modification à la définition de la table qui affecte les données de celle-ci ou la façon dont elle est interrogée, une nouvelle version de développement de la table sera créée la prochaine fois que vous interrogerez la table en mode Développement. Une table de développement de la sorte vous permet de tester les modifications sans déranger les utilisateurs.
Quelles commandes entraînent la création d'une table de développement par Looker ?
Dans la mesure du possible, Looker utilise la table de production existante pour répondre aux requêtes, que vous soyez ou non en mode Développement. Cependant, dans certains cas, Looker ne peut pas utiliser de table de production pour les requêtes en mode Développement :
- Si votre table persistante dispose d'un paramètre qui affine son ensemble de données afin de travailler plus vite en mode Développement
- Si vous avez apporté des modifications à la définition de votre table persistante qui affectent les données de la table
Looker créera une table de développement si vous êtes en mode Développement et que vous interrogez une table dérivée basée sur SQL définie à l'aide d'une clause WHERE conditionnelle avec des instructions if prod et if dev.
Pour les tables persistantes qui ne comportent pas de paramètre permettant de limiter l'ensemble de données en mode Développement, Looker utilise la version de production de la table pour répondre aux requêtes en mode Développement, sauf si vous modifiez la définition de la table, puis interrogez la table en mode Développement. Cela s'applique à toutes les modifications affectant les données dans la table ou la façon dont elle est interrogée.
Voici quelques exemples de modifications entraînant la création d'une version de développement d'une table persistante par Looker (Looker créera la table uniquement si vous interrogez la table après avoir apporté ces modifications) :
- Modifier la requête sur laquelle repose la table persistante, par exemple en modifiant le paramètre
explore_source,sql,query,sql_createoucreate_processdans la table persistante elle-même ou dans toute table requise (dans le cas de tables dérivées en cascade) - Modifier la stratégie de persistance de la table, par exemple en modifiant les paramètres
datagroup_trigger,sql_trigger_value,interval_triggeroupersist_forde la table - Modifier le nom de la
viewd'une table dérivée - Modifier le
increment_keyou leincrement_offsetd'une PDT incrémentielle - Modifier le
connectionutilisé par le modèle associé
Looker ne créera pas de table de développement en réponse aux modifications qui ne changent pas les données de la table et n'affectent pas la façon dont Looker interroge la table. Le paramètre publish_as_db_view est un bon exemple : en mode Développement, si vous modifiez uniquement le paramètre publish_as_db_view d'une table dérivée, Looker n'a pas besoin de régénérer la table dérivée et ne créera donc pas de table de développement.
Durée de persistance des tables de développement
Quelle que soit la stratégie de persistance réelle de la table, Looker traite les tables persistantes de développement comme si elles avaient une stratégie de persistance de persist_for: "24 hours". Looker le fait pour s'assurer que les tables de développement ne sont pas persistantes plus d'une journée, car un développeur Looker peut interroger plusieurs itérations d'une table lors du développement, ce qui entraîne à chaque fois la génération d'une table de développement. Pour empêcher les tables de développement d'encombrer la base de données, Looker applique la stratégie persist_for: "24 hours" pour s'assurer que les tables sont fréquemment nettoyées par rapport à la base de données.
Sinon, Looker génère des tables dérivées persistantes (PDT) et des tables agrégées en mode Développement de la même façon qu'il génère des tables persistantes en mode Production.
Si une table de développement est persistante sur votre base de données lorsque vous déployez des modifications sur une table PDT ou une table agrégée, Looker peut souvent utiliser la table de développement comme table de production afin que les utilisateurs n'aient pas à attendre la création de la table lorsqu'ils l'interrogent.
Notez que, lorsque vous déployez vos modifications, vous devez peut-être régénérer la table pour qu'elle soit interrogée en production, en fonction de la situation :
- Si votre interrogation de la table en mode Développement remonte à plus de 24 heures, la version du développement de la table sera marquée comme étant expirée et ne sera pas utilisée pour les requêtes. Vous pouvez rechercher les tables PDT non créées à l'aide de l'IDE Looker ou de l'onglet Développement de la page Tables dérivées persistantes. Si vous disposez de tables PDT déconstruites, vous pouvez les interroger en mode Développement avant d'apporter vos modifications afin que la table de développement puisse être utilisée en production.
- Si une table persistante comprend le paramètre
dev_filters(pour les tables dérivées natives) ou la clause conditionnelleWHEREutilisant les instructionsif prodetif dev(pour les tables dérivées basées sur SQL), la table de développement ne peut pas être utilisée en tant que version de production, car la version de développement dispose d'un ensemble de données abrégé. Dans ce cas, après avoir terminé le développement de la table et avant de déployer vos modifications, vous pouvez exclure par commentaire le paramètredev_filtersou la clause conditionnelleWHERE, puis interroger la table en mode Développement. Looker générera alors une version complète de la table qui pourra être utilisée pour la production lorsque vous déploierez vos modifications.
Sinon, si vous déployez vos modifications alors qu'aucune table de développement valide ne peut être utilisée comme table de production, Looker reconstruira la table la prochaine fois qu'elle sera interrogée en mode Production (pour les tables persistantes qui utilisent la stratégie persist_for) ou la prochaine fois que le régénérateur s'exécutera (pour les tables persistantes qui utilisent datagroup_trigger, interval_trigger ou sql_trigger_value).
Recherche de tables PDT déconstruites en mode Développement
Si une table de développement est persistante sur votre base de données lorsque vous déployez des modifications sur une table dérivée persistante (PDT) ou une table agrégée, Looker peut souvent utiliser la table de développement comme table de production afin que les utilisateurs n'aient pas à attendre la création de la table lorsqu'ils l'interrogent. Pour en savoir plus, consultez les sections Durée de persistance des tables de développement et Quelles commandes entraînent la création d'une table de développement par Looker ? sur cette page.
Par conséquent, toutes vos tables PDT doivent être créées lors du déploiement en production afin que celles-ci puissent être utilisées immédiatement comme versions de production.
Vous pouvez rechercher les tables PDT déconstruites de votre projet dans le panneau État du projet. Cliquez sur l'icône État du projet dans l'IDE Looker pour ouvrir le panneau État du projet. Cliquez ensuite sur le bouton Valider l'état des PDT.
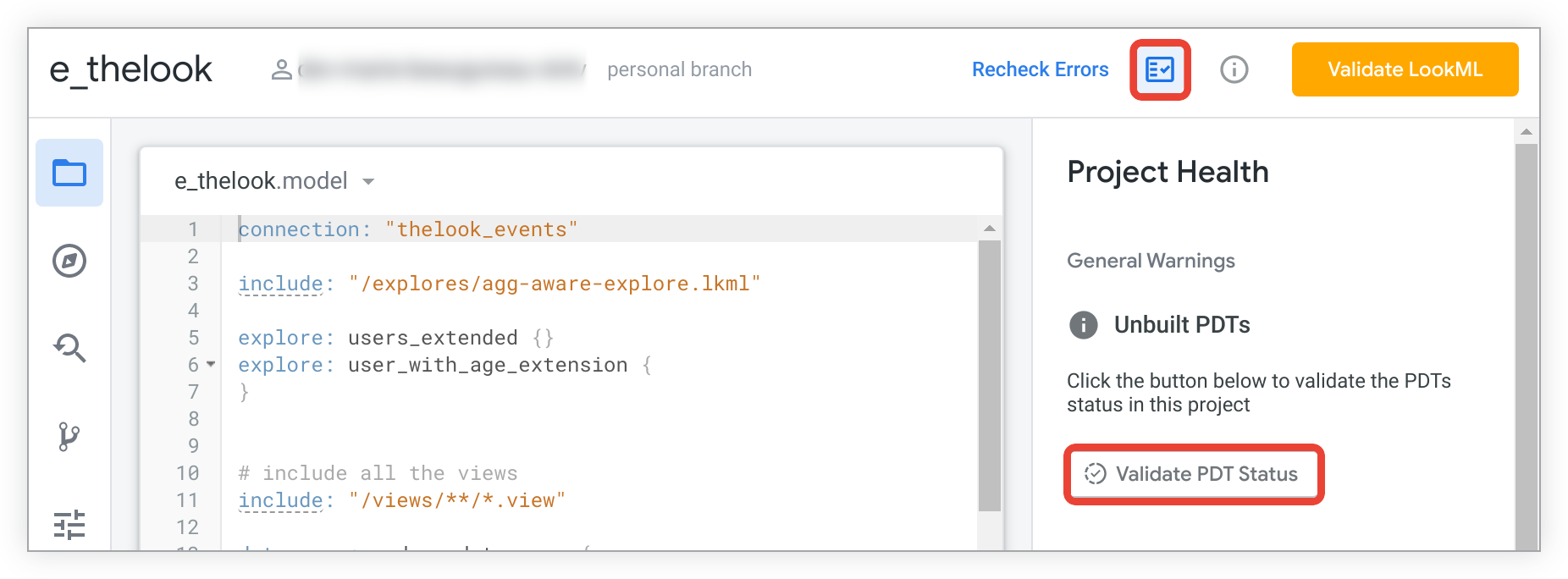
Les tables PDT déconstruites seront listées dans le panneau État du projet :
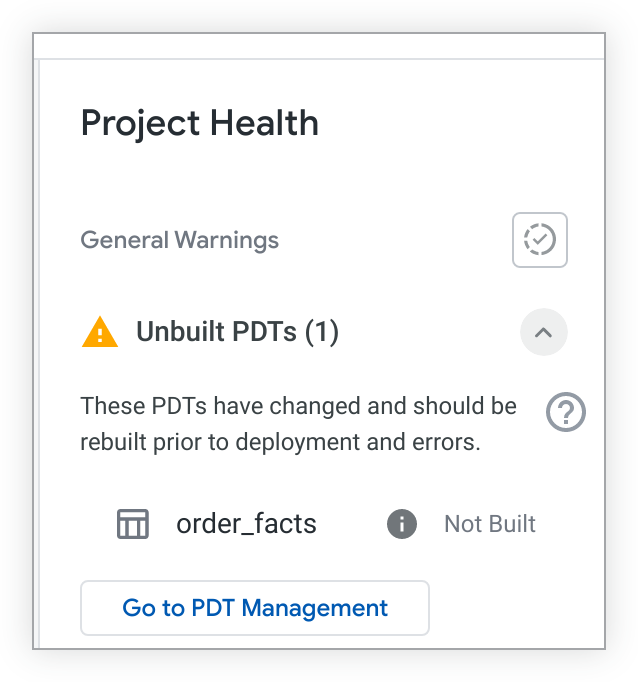
Si vous disposez de l'autorisation see_pdts, vous pouvez cliquer sur le bouton Accéder à la gestion des PDT. Looker ouvre l'onglet Développement de la page Tables dérivées persistantes et filtre les résultats pour votre projet LookML spécifique. Vous pouvez consulter les tables PDT construites et déconstruites, et accéder à d'autres informations de dépannage. Pour en savoir plus, consultez la page de documentation Paramètres Admin – Tables dérivées persistantes.
Si vous identifiez une table PDT déconstruite dans votre projet, vous pouvez créer une version de développement en ouvrant une exploration qui interroge la table, puis en utilisant l'option Regénérer les tables dérivées et exécuter du menu "Explorer". Consultez la section Régénération manuelle de tables persistantes pour une requête sur cette page.
Partage et nettoyage de tables
Au sein d'une instance Looker donnée, Looker partage entre les utilisateurs les tables persistantes ayant la même définition et faisant appel à la même méthode de persistance. Par ailleurs, si la définition d'une table cesse d'exister, Looker marque cette dernière comme ayant expiré.
Cela présente plusieurs avantages :
- Si vous n'avez apporté aucune modification à une table en mode Développement, vos requêtes utiliseront les tables de production existantes. C'est le cas, sauf si votre table est une table dérivée basée sur SQL définie à l'aide d'une clause
WHEREconditionnelle avec des instructionsif prodetif dev. Si la table est définie avec une clause conditionnelleWHERE, Looker créera alors une table de développement si vous interrogez la table en mode Développement. (Pour les tables dérivées natives avec le paramètredev_filters, Looker dispose de la logique pour utiliser la table de production afin de répondre à des requêtes en mode Développement, sauf si vous modifiez la définition de la table, puis interrogez la table en mode Développement.) - Si deux développeurs apportent la même modification à une table en mode Développement, ils partageront la même table de développement.
- Après la mise en production des changements apportés en mode Développement, l'ancienne définition de production n'existe plus, de sorte que l'ancienne table de production est marquée comme étant expirée et est supprimée.
- Si vous décidez d'annuler les modifications effectuées en mode Développement, cette définition de la table n'existe plus, et les tables de développement devenues inutiles sont marquées comme expirées et supprimées.
Gains d'efficacité en mode Développement
Il arrive qu'une table dérivée persistante (PDT) soit très longue à générer, ce qui peut être frustrant si vous testez de nombreuses modifications en mode Développement. Dans ce cas, vous pouvez demander à Looker de créer des versions plus petites d'une table dérivée en mode Développement.
Pour les tables dérivées natives, vous pouvez utiliser le sous-paramètre dev_filters de explore_source pour spécifier les filtres qui ne sont appliqués qu'aux versions de développement de la table dérivée :
view: e_faa_pdt {
derived_table: {
...
datagroup_trigger: e_faa_shared_datagroup
explore_source: flights {
dev_filters: [flights.event_date: "90 days"]
filters: [flights.event_date: "2 years", flights.airport_name: "Yucca Valley Airport"]
column: id {}
column: airport_name {}
column: event_date {}
}
}
...
}
Cet exemple comprend un paramètre dev_filters qui filtre les données des 90 derniers jours ainsi qu'un paramètre filters qui filtre les données des deux dernières années pour l'aéroport de Yucca Valley.
Le paramètre dev_filters fonctionne parallèlement au paramètre filters afin que tous les filtres soient appliqués à la version de développement de la table. Si dev_filters et filters spécifient des filtres pour la même colonne, dev_filters est prioritaire pour la version de développement de la table. Dans cet exemple, la version de développement de la table filtrera les données des 90 derniers jours pour l'aéroport de Yucca Valley.
Pour les tables dérivées basées sur SQL, Looker prend en charge une clause WHERE conditionnelle avec différentes options pour les versions de production (if prod) et de développement (if dev) de la table :
view: my_view {
derived_table: {
sql:
SELECT
columns
FROM
my_table
WHERE
-- if prod -- date > '2000-01-01'
-- if dev -- date > '2020-01-01'
;;
}
}
Dans cet exemple, la requête inclut toutes les données datées à partir de l'an 2000 en mode Production, mais seulement à partir de 2020 en mode Développement. Utilisée à bon escient pour limiter le jeu de résultats obtenu et accélérer les requêtes, cette fonctionnalité peut simplifier considérablement la validation des modifications apportées en mode Développement.
Comment Looker génère les PDT
Une fois qu'une table dérivée persistante (PDT) a été définie et qu'elle est exécutée pour la première fois ou déclenchée par le régénérateur pour être reconstruite selon sa stratégie de persistance, Looker effectue les étapes suivantes :
- Utilisez le code SQL de la table dérivée pour créer une instruction CREATE TABLE AS SELECT (ou CTAS) et l'exécuter. Par exemple, pour reconstruire une PDT appelée
customer_orders_facts:CREATE TABLE tmp.customer_orders_facts AS SELECT ... FROM ... WHERE ... - Émettez les instructions pour créer les index lorsque la table est créée.
- Renommez la table en remplaçant LC$.. ("Looker Create") par LR$.. ("Looker Read"), pour indiquer que la table est prête à être utilisée.
- Supprimez les anciennes versions du tableau qui ne doivent plus être utilisées.
Voici quelques implications importantes :
- Le code SQL qui forme la table dérivée doit être valide dans une instruction CTAS.
- Les alias de colonne de l'ensemble de résultats de l'instruction SELECT doivent être des noms de colonne valides.
- Les noms utilisés pour spécifier la distribution, les clés de tri et les index doivent être les noms de colonnes listés dans la définition SQL de la table dérivée, et non les noms de champs définis dans LookML.
Le régénérateur Looker
Le régénérateur Looker vérifie le statut et lance les régénérations des tables persistantes à déclenchement. Une table persistante à déclenchement est une table dérivée persistante (PDT) ou une table agrégée qui utilise un déclenchement comme stratégie de persistance :
- Pour les tables qui utilisent
sql_trigger_value, le déclencheur est une requête spécifiée dans le paramètresql_trigger_valuede la table. Le régénérateur Looker déclenche une régénération de la table lorsque le résultat du dernier contrôle de requête de déclenchement diffère du précédent. Par exemple, si votre table dérivée est persistante avec la requête SQLSELECT CURDATE(), le régénérateur Looker régénérera la table lors du prochain contrôle du déclencheur après un changement de date. - Pour les tables qui utilisent
interval_trigger, le déclencheur est une durée spécifiée dans le paramètreinterval_triggerde la table. Le régénérateur Looker déclenche une régénération de la table lorsque la durée spécifiée est passée. - Pour les tables qui utilisent
datagroup_trigger, le déclencheur peut être une requête spécifiée dans le paramètresql_triggerdu groupe de données associé, ou une durée spécifiée dans le paramètreinterval_triggerdu groupe de données.
Le régénérateur Looker lance également les régénérations des tables persistantes qui utilisent le paramètre persist_for, mais uniquement lorsque la table persist_for est une cascade de dépendances d'une table persistante à déclenchement. Dans ce cas, le régénérateur Looker lance la régénération d'une table persist_for, étant donné que la table est nécessaire pour recréer les autres tables dans la cascade. Autrement, le régénérateur ne surveille pas les tables persistantes qui utilisent la stratégie persist_for.
Le cycle du régénérateur Looker commence à un intervalle régulier configuré par votre administrateur Looker dans le paramètre Calendrier de maintenance de votre connexion à la base de données (l'intervalle par défaut est de cinq minutes). Toutefois, le régénérateur Looker ne démarre un nouveau cycle qu'une fois qu'il a terminé toutes les vérifications et les régénérations de PDT du cycle précédent. Cela signifie que si vous avez des PDT qui mettent longtemps à se générer, le cycle de régénération de Looker peut ne pas s'exécuter aussi souvent que défini dans le paramètre Planning de la maintenance. D'autres facteurs peuvent affecter le temps de régénération de vos tables, comme décrit dans la section Points importants à prendre en compte pour implémenter des tables persistantes de cette page.
En cas d'échec de génération d'une table PDT, le régénérateur peut essayer de régénérer la table lors du prochain cycle :
- Si le paramètre Retry Failed PDT Builds (Retenter la création des tables PDT ayant échoué) est activé sur votre connexion à la base de données, le régénérateur Looker tentera de recréer la table lors du prochain cycle de régénération, même si la condition de déclenchement de la table n'est pas remplie.
- Si le paramètre Relancer les générations de tables dérivées persistantes en échec est désactivé, le régénérateur Looker ne tentera pas de régénérer la table tant que la condition de déclenchement de la table PDT n'est pas remplie.
Si un utilisateur demande des données d'une table persistante en cours de génération et si les résultats de la requête ne sont pas mis en cache, Looker vérifie si la table existante est toujours valide. (La table précédente peut ne pas être valide si elle n'est pas compatible avec la nouvelle version de la table, ce qui peut se produire à cause d'une définition différente ou d'une connexion de base de données différente de la nouvelle table ou parce que la nouvelle table a été créée avec une version différente de Looker.) Si la table existante est toujours valide, Looker renvoie les données issues de la table existante jusqu'à la génération de la nouvelle table. Autrement, si la table existante n'est pas valide, Looker renvoie les résultats de requête une fois que la nouvelle table est régénérée.
Éléments importants à prendre en compte lors de la mise en œuvre de tables persistantes
En prenant en compte l'utilité des tables persistantes (PDT et tables agrégées), il est possible d'en accumuler un grand nombre sur votre instance Looker. Il est possible de créer un scénario dans lequel le régénérateur Looker a besoin de générer de nombreuses tables à la fois. En particulier avec les tables en cascade ou les tables de longue durée, vous pouvez créer un scénario dans lequel les tables mettent beaucoup de temps à se reconstruire ou dans lequel les utilisateurs subissent un délai pour obtenir les résultats des requêtes d'une table pendant que la base de données s'efforce de générer la table.
Le régénérateur Looker vérifie les déclencheurs de tables PDT pour déterminer s'il doit régénérer les tables persistantes à déclenchement. Le cycle du régénérateur est défini à un intervalle régulier configuré par votre administrateur Looker dans le paramètre Calendrier de maintenance de votre connexion à la base de données (l'intervalle par défaut est de cinq minutes).
Plusieurs facteurs peuvent affecter le temps de régénération de vos tables :
- Il est possible que votre administrateur Looker ait modifié l'intervalle des vérifications du déclencheur du régénérateur à l'aide du paramètre Planning de maintenance sur votre connexion à la base de données.
- Le régénérateur Looker ne démarre un nouveau cycle qu'une fois qu'il a terminé toutes les vérifications et les régénérations de PDT du cycle précédent. Par conséquent, si vous avez des PDT dont la création prend du temps, le cycle de régénération de Looker peut ne pas être aussi fréquent que le paramètre Calendrier de maintenance.
- Par défaut, le régénérateur peut lancer la régénération d'une table PDT ou agrégée à un temps donnée sur une connexion. Un administrateur Looker peut ajuster le nombre de régénérations simultanées autorisées pour le régénérateur à l'aide du champ Nombre maximal de connexions du générateur PDT dans les paramètres d'une connexion.
- Toutes les tables PDT et agrégées déclenchées par le même
datagroupseront reconstruites au cours du même processus de régénération. Il peut s'agir d'une charge lourde si vous disposez de nombreuses tables qui utilisent le groupe de données, soit directement ou en conséquence de dépendances en cascade.
Outre les considérations exposées ci-dessus, il existe d'autres situations dans lesquelles vous devriez éviter d'ajouter de la persistance à une table dérivée :
- Lorsque les tables dérivées seront étendues : chaque extension d'une PDT créera une nouvelle copie de la table dans votre base de données.
- Lorsque des tables dérivées utilisent des filtres basés sur un modèle ou des paramètres Liquid : la persistance n'est pas prise en charge pour les tables dérivées qui utilisent des filtres basés sur un modèle ou des paramètres Liquid.
- Lorsque des tables dérivées natives sont créées à partir d'explorations qui utilisent des attributs utilisateur avec
access_filtersousql_always_where, des copies de la table sont créées dans votre base de données pour chaque valeur d'attribut utilisateur possible spécifiée. - Lorsque les données sous-jacentes changent fréquemment et que votre dialecte de base de données n'est pas compatible avec les PDT incrémentielles.
- Lorsque le coût et le temps nécessaires à la création de PDT sont trop élevés.
Selon le nombre et la complexité des tables persistantes sur votre connexion Looker, la file d'attente peut contenir de nombreuses tables persistantes en attente de contrôle et de régénération à chaque cycle. Il est donc important de garder ces facteurs à l'esprit lors de la mise en œuvre de tables dérivées sur votre instance Looker.
Gérer les PDT à grande échelle à l'aide de l'API
Plus vous créez des tables dérivées persistantes (PDT) sur votre instance, plus la surveillance et la gestion des PDT qui s'actualisent selon un calendrier variable se compliquent. Envisagez d'utiliser l'intégration Apache Airflow de Looker pour gérer vos plannings de PDT en même temps que vos autres processus ETL et ELT.
Surveillance et correction de tables PDT
Si vous utilisez des tables dérivées persistantes (PDT), et en particulier des PDT en cascade, il peut être utile de consulter leur état. Vous pouvez utiliser la page d'administration Tables dérivées persistantes de Looker pour voir l'état de vos PDT. Pour en savoir plus, consultez la page de documentation Paramètres Admin - Tables dérivées persistantes.
Lorsque vous essayez de corriger des PDT :
- Lors de l'examen du journal des événements PDT, soyez particulièrement attentif à la distinction entre les tables de développement et les tables de production.
- Vérifiez que le paramètre Base de données temporaire de votre connexion Looker correspond à votre base de données ou schéma temporaire. Si le paramètre Base de données temporaire de la connexion ne correspond pas au schéma temporaire de votre base de données, mettez à jour le paramètre Base de données temporaire afin que Looker puisse stocker des tables dérivées persistantes dans votre base de données.
- Déterminez si toutes les tables PDT posent problème, ou une seule d'entre elles. Dans ce dernier cas, le problème est probablement dû à une erreur LookML ou SQL.
- Déterminez si les problèmes liés à la table PDT coïncident avec les régénérations planifiées.
- Veillez à ce que toutes les requêtes
sql_trigger_valuefonctionnent correctement et ne renvoient qu'une seule ligne et une seule colonne. Pour les tables PDT basées sur SQL, vous pouvez le faire en les exécutant dans SQL Runner. (L'application d'unLIMITprotège contre les requêtes incontrôlables.) Pour en savoir plus sur l'utilisation de SQL Runner pour déboguer les tables dérivées, consultez l'article de la communauté Utiliser SQL Runner pour tester les tables dérivées . - Pour les tables PDT basées sur SQL, utilisez SQL Runner pour vérifier si le code SQL d'une table s'exécute sans erreur. (N'oubliez pas d'appliquer une clause
LIMITdans SQL Runner pour maintenir des délais raisonnables d'exécution des requêtes.) - Pour les tables dérivées basées sur SQL, évitez d'utiliser des expressions de table courantes (CTE). La combinaison de CTE et de tables dérivées crée des instructions
WITHimbriquées pouvant provoquer des erreurs inattendues au niveau des tables PDT. Utilisez plutôt le code SQL de votre CTE pour créer une DT secondaire et référencez cette DT à partir de votre première DT à l'aide de la syntaxe${derived_table_or_view_name.SQL_TABLE_NAME}. - Assurez-vous que la table PDT posant problème n'est liée à aucune table existante (qu'il s'agisse d'une table normale ou d'une autre table PDT) susceptible d'être interrogée.
- Assurez-vous que les tables dont la PDT posant problème dépend ne possèdent pas de verrous partagés ou exclusifs. Pour créer une table PDT, Looker doit acquérir un verrou exclusif sur la table à mettre à jour. Cela crée un conflit avec les autres verrous partagés ou exclusifs associés à la table. Looker ne peut pas mettre à jour la table PDT tant que les autres verrous ne sont pas supprimés. Il en va de même pour les verrous exclusifs associés à la table à partir de laquelle Looker crée une table PDT. Si cette table comporte un verrou exclusif, Looker ne peut pas acquérir de verrou partagé pour exécuter les requêtes tant que tous les verrous exclusifs ne sont pas supprimés.
- Utilisez le bouton Afficher les processus dans SQL Runner. Si de nombreux processus sont actifs, l'exécution des requêtes pourrait être ralentie.
- Surveillez les commentaires figurant dans la requête. Consultez la section Commentaires de requête pour les tables PDT sur cette page.
Commentaires de requête pour les tables PDT
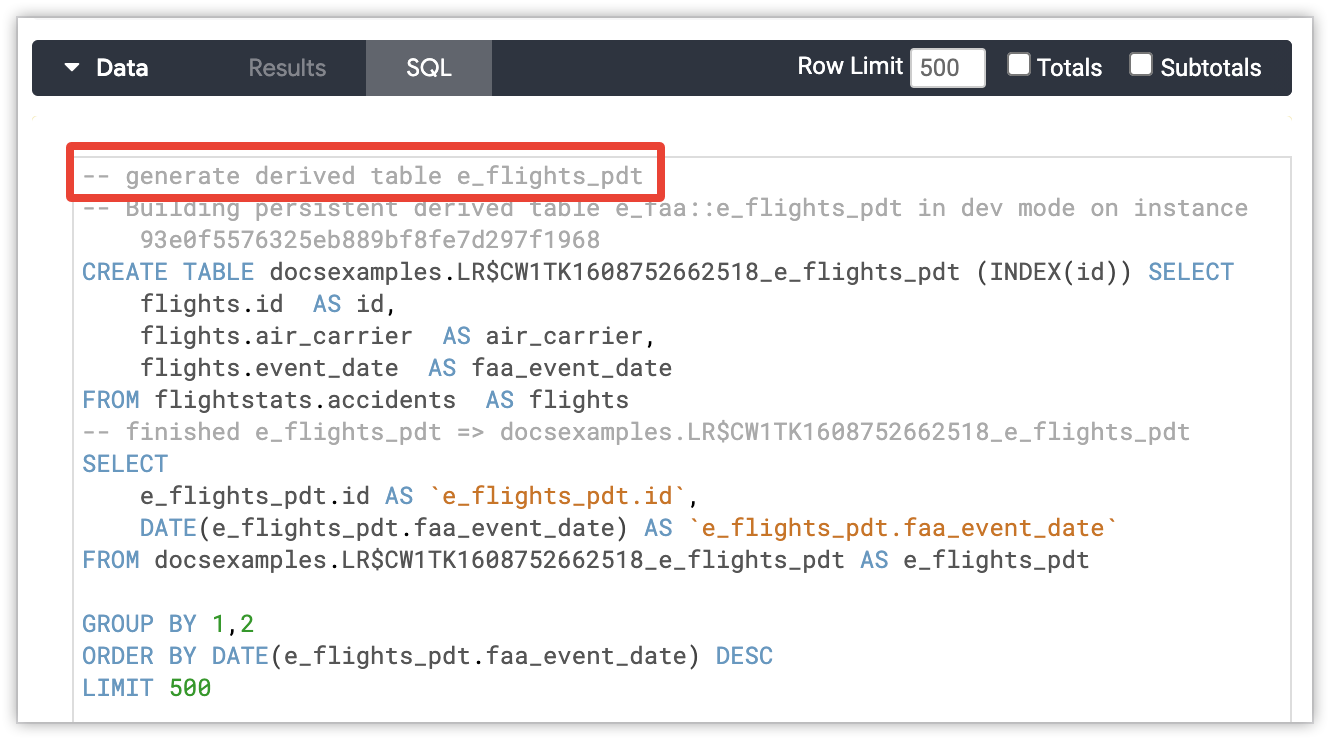
Les administrateurs de bases de données peuvent distinguer les requêtes normales de celles qui génèrent des tables dérivées persistantes (PDT). Looker ajoute des commentaires à l'instruction CREATE TABLE ... AS SELECT ... incluant le modèle et la vue LookML de la table PDT, ainsi qu'un identifiant unique (slug) pour l'instance Looker. Si la table PDT est générée au nom d'un utilisateur en mode Développement, les commentaires indiquent l'ID de cet utilisateur. Les commentaires de génération d'une table PDT suivent le schéma ci-dessous :
-- Building `<view_name>` in dev mode for user `<user_id>` on instance `<instance_slug>`
CREATE TABLE `<table_name>` SELECT ...
-- finished `<view_name>` => `<table_name>`
Le commentaire de génération d'une table PDT s'affiche également dans l'onglet SQL d'une exploration, si Looker a dû générer une table PDT pour la requête de cette exploration. Dans ce cas, le commentaire apparaît en haut de l'instruction SQL.
Enfin, le commentaire de génération d'une table PDT apparaît dans le champ Message de l'onglet Infos du pop-up Détails de la requête pour chaque requête sur la page d'administration Requêtes.
Régénération d'une table PDT après échec
En cas d'échec d'une table dérivée persistante (PDT), voici ce qui se produit lors de l'interrogation de cette table :
- Looker utilise les résultats dans le cache si la même requête a été exécutée précédemment. (Pour en savoir plus, consultez la page de documentation Mise en cache des requêtes.)
- Si les résultats ne sont pas dans le cache, Looker extrait les résultats de la table PDT dans la base de données, si une version valide de la table PDT existe.
- S'il n'existe aucune table PDT valide dans la base de données, Looker tente de régénérer la table PDT.
- Si la table PDT ne peut pas être régénérée, Looker renvoie une erreur pour une requête. Le régénérateur Looker tentera de régénérer la table PDT à la prochaine interrogation de la table PDT ou à la prochaine régénération déclenchée par la stratégie de persistance de la table PDT.
Avec les PDT en cascade, la même logique s'applique, sauf ce qui suit :
- Un échec de création de table empêche la création de PDT tout le long de la chaîne de dépendance.
- Une PDT dépendante envoie essentiellement une requête à la PDT sur laquelle elle repose. La stratégie de persistance d'une table peut donc déclencher des régénérations des PDT tout au long de la chaîne.
Reprenons l'exemple précédent de tables en cascade, où TABLE_D dépend de TABLE_C, qui dépend de TABLE_B, qui dépend de TABLE_A :
Si TABLE_B échoue, tout le comportement standard (non en cascade) s'applique à TABLE_B :
- Si
TABLE_Best interrogé, Looker essaie d'abord d'utiliser le cache pour renvoyer les résultats. - Si cette tentative échoue, Looker essaie ensuite d'utiliser une version précédente de la table, si possible.
- Si cette tentative échoue également, Looker essaie ensuite de reconstruire la table.
- Enfin, si
TABLE_Bne peut pas être régénérée, Looker renvoie une erreur.
Looker essaie à nouveau de régénérer TABLE_B lorsque la table est interrogée à nouveau ou lorsque la stratégie de persistance de la table déclenche à nouveau une régénération.
Il en va de même pour les dépendances de TABLE_B. Par conséquent, si TABLE_B ne peut pas être créé et qu'il existe une requête sur TABLE_C, la séquence suivante se produit :
- Looker essaiera d'utiliser le cache pour la requête sur
TABLE_C. - Si les résultats ne sont pas dans le cache, Looker essaie d'extraire les résultats de
TABLE_Cdans la base de données. - S'il n'existe aucune version valide de
TABLE_C, Looker tente de régénérerTABLE_C, ce qui crée une requête surTABLE_B. - Looker essaie ensuite de régénérer
TABLE_B(qui échoue siTABLE_Bn'a pas été corrigé). - Si
TABLE_Bne peut pas être régénérée,TABLE_Cne peut pas l'être non plus. Looker renvoie donc une erreur pour la requête surTABLE_C. - Looker tentera ensuite de régénérer
TABLE_Cselon sa stratégie de persistance habituelle, ou la prochaine fois que la PDT sera interrogée (y compris la prochaine fois queTABLE_Dtentera de générer, carTABLE_Ddépend deTABLE_C).
Une fois le problème résolu avec TABLE_B, TABLE_B et chacune des tables dépendantes tenteront de se régénérer en fonction de leurs stratégies de persistance ou lors de leur prochaine interrogation (y compris lors de la prochaine tentative de régénération d'une PDT dépendante). Ou, si une version de développement des tables PDT dans la cascade a été générée en mode Développement, les versions de développement peuvent être utilisées comme les nouvelles tables PDT de production. (Pour en savoir plus, consultez la section Tables persistantes en mode Développement de cette page.) Vous pouvez également utiliser un Explore pour exécuter une requête sur TABLE_D, puis régénérer manuellement les PDT pour la requête. Cela forcera la régénération de toutes les PDT dans la cascade de dépendances.
Améliorer les performances des tables PDT
Lorsque vous créez des tables dérivées persistantes (PDT), les performances peuvent être un problème. Surtout lorsque la table est très volumineuse, l'interroger peut être lent, comme pour toute table volumineuse de votre base de données.
Vous pouvez améliorer les performances en filtrant les données ou en contrôlant la façon dont les données du tableau PDT sont triées et indexées.
Ajouter des filtres pour limiter l'ensemble de données
Avec des ensembles de données particulièrement volumineux, un grand nombre de lignes ralentit les requêtes sur une table dérivée persistante (PDT). Si vous n'interrogez généralement que des données récentes, pensez à ajouter un filtre à la clause WHERE de votre PDT qui limite la table à 90 jours de données ou moins. De cette façon, seules les données pertinentes seront ajoutées à la table à chaque fois qu'elle sera reconstruite, ce qui accélérera considérablement l'exécution des requêtes. Vous pouvez ensuite créer une PDT distincte et plus volumineuse pour l'analyse historique. Cela vous permettra d'exécuter des requêtes rapides pour les données récentes et d'interroger les anciennes données.
Utiliser indexes ou sortkeys et distribution
Lorsque vous créez une table dérivée persistante (PDT) volumineuse, l'indexation de la table (pour les dialectes tels que MySQL ou Postgres) ou l'ajout de clés de tri et de distribution (pour Redshift) peuvent améliorer les performances.
Il est généralement préférable d'ajouter le paramètre indexes aux champs d'ID ou de date.
Pour Redshift, il est généralement préférable d'ajouter le paramètre sortkeys aux champs d'ID ou de date, et le paramètre distribution au champ utilisé pour la jointure.
Paramètres recommandés pour améliorer les performances
Les paramètres suivants contrôlent la façon dont les données de la table dérivée persistante (PDT) sont triées et indexées. Ces paramètres sont facultatifs, mais vivement recommandés :
- Pour Redshift et Aster, utilisez le paramètre
distributionafin de spécifier le nom de la colonne dont la valeur est utilisée pour répartir les données dans un cluster. Lorsque deux tables sont jointes par la colonne spécifiée dans le paramètredistribution, la base de données peut trouver les données de jointure sur le même nœud, ce qui minimise les E/S entre les nœuds. - Pour Redshift, définissez le paramètre
distribution_stylesurallafin d'indiquer à la base de données de conserver une copie complète des données sur chaque nœud. Cette option est souvent utilisée pour minimiser les E/S entre les nœuds lorsque des tables relativement petites sont jointes. Définissez cette valeur surevenpour indiquer à la base de données de répartir les données de manière uniforme dans le cluster sans utiliser de colonne de distribution. Cette valeur ne peut être spécifiée que lorsquedistributionn'est pas spécifié. - Pour Redshift, utilisez le paramètre
sortkeys. Les valeurs spécifient les colonnes de la PDT utilisées pour trier les données sur le disque afin de faciliter la recherche. Sur Redshift, vous pouvez utilisersortkeysouindexes, mais pas les deux. - Dans la plupart des bases de données, utilisez le paramètre
indexes. Les valeurs indiquent les colonnes du PDT qui sont indexées. (Sur Redshift, les index sont utilisés pour générer des clés de tri entrelacées.)