Mit dem BigQuery-Connector für Apache Spark können Data Scientists das Leistungspotenzial der nahtlos skalierbaren SQL-Engine von BigQuery mit den Funktionen für maschinelles Lernen von Apache Spark kombinieren. In dieser Anleitung wird gezeigt, wie Sie Dataproc, BigQuery und Apache Spark ML verwenden, um maschinelles Lernen mit einem Dataset durchzuführen.
Lernziele
Verwenden Sie die lineare Regression, um ein Modell zum Geburtsgewicht als Funktion mit fünf Faktoren zu erstellen:- Schwangerschaftswochen
- Alter der Mutter
- Alter des Vaters
- Mutterzunahme während der Schwangerschaft
- Apgar-Score
Verwenden Sie die folgenden Tools:
- BigQuery zur Vorbereitung der linearen Regressionseingabetabelle, die in Ihr Google Cloud-Projekt geschrieben wird
- Python zum Abfragen und Verwalten von Daten in BigQuery
- Apache Spark, um auf die resultierende Tabelle mit linearen Regression zuzugreifen
- Spark ML zum Erstellen und Bewerten des Modells
- Dataproc PySpark-Job zum Aufrufen von Spark ML-Funktionen
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Compute Engine
- Dataproc
- BigQuery
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweis
In Dataproc-Clustern sind die Spark-Komponenten einschließlich Spark ML installiert. Wenn Sie einen Dataproc-Cluster einrichten und den Code in diesem Beispiel auszuführen, müssen Sie folgende Aufgaben ausführen bzw. ausgeführt haben:
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc, BigQuery, Compute Engine APIs.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc, BigQuery, Compute Engine APIs.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init - Erstellen Sie einen Dataproc-Cluster in Ihrem Projekt. In Ihrem Cluster sollte eine Dataproc-Version mit Spark 2.0 oder höher ausgeführt werden (enthält ML-Bibliotheken).
Teilmenge der natality-Daten von BigQuery erstellen
In diesem Abschnitt erstellen Sie ein Dataset in Ihrem Projekt, dann eine Tabelle in diesem Dataset, in das Sie eine Teilmenge der Daten zu Geburtenraten aus dem öffentlich zugänglichen BigQuery-Dataset natality kopieren. Später in dieser Anleitung verwenden Sie die Teilmengendaten in dieser Tabelle, um das Geburtsgewicht in Abhängigkeit vom Alter der Mutter, des Vaters und von den Schwangerschaftswochen vorherzusagen.
Sie können die Datenteilmenge mit der Google Cloud Console oder durch Ausführen eines Python-Skripts auf Ihrem lokalen Computer erstellen.
Console
Erstellen Sie ein Dataset in Ihrem Projekt.
- Rufen Sie die Web-UI von BigQuery auf.
- Klicken Sie im linken Navigationsbereich auf den Namen Ihres Projekts und anschließend auf DATASET ERSTELLEN.
- Führen Sie im Dialogfeld Dataset erstellen folgende Schritte aus:
- Geben Sie als Dataset ID (Dataset-ID) "natality_regression" ein.
- Wählen Sie unter Speicherort der Daten einen Standort für das Dataset aus. Der Standardwert für den Standort ist
US multi-region. Nachdem ein Dataset erstellt wurde, kann der Standort nicht mehr geändert werden. - Wählen Sie für Standard-Tabellenablauf eine der folgenden Optionen aus:
- Nie: (Standardeinstellung) Sie müssen die Tabelle manuell löschen.
- Anzahl Tage: Die Tabelle wird nach der angegebenen Anzahl von Tagen ab ihrer Erstellung gelöscht.
- Wählen Sie für Verschlüsselung eine der folgenden Optionen aus:
- Von Google verwalteter Schlüssel (Standardeinstellung).
- Vom Kunden verwalteter Schlüssel: Siehe Daten mit Cloud KMS-Schlüsseln schützen.
- Klicken Sie auf Dataset erstellen.
Führen Sie eine Abfrage für das öffentliche "natality"-Dataset aus und speichern Sie die Abfrageergebnisse in einer neuen Tabelle in Ihrem Dataset.
- Kopieren Sie die folgende Abfrage und fügen Sie sie in den Abfrageeditor ein. Klicken Sie dann auf „Ausführen“.
SELECT weight_pounds, mother_age, father_age, gestation_weeks, weight_gain_pounds, apgar_5min FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL AND mother_age IS NOT NULL AND father_age IS NOT NULL AND gestation_weeks IS NOT NULL AND weight_gain_pounds IS NOT NULL AND apgar_5min IS NOT NULL
- Klicken Sie nach etwa einer Minute auf ERGEBNISSE SPEICHERN und wählen Sie Speicheroptionen aus, um die Ergebnisse als BigQuery-Tabelle im Dataset
natality_regressionIhres Projekts zu speichern.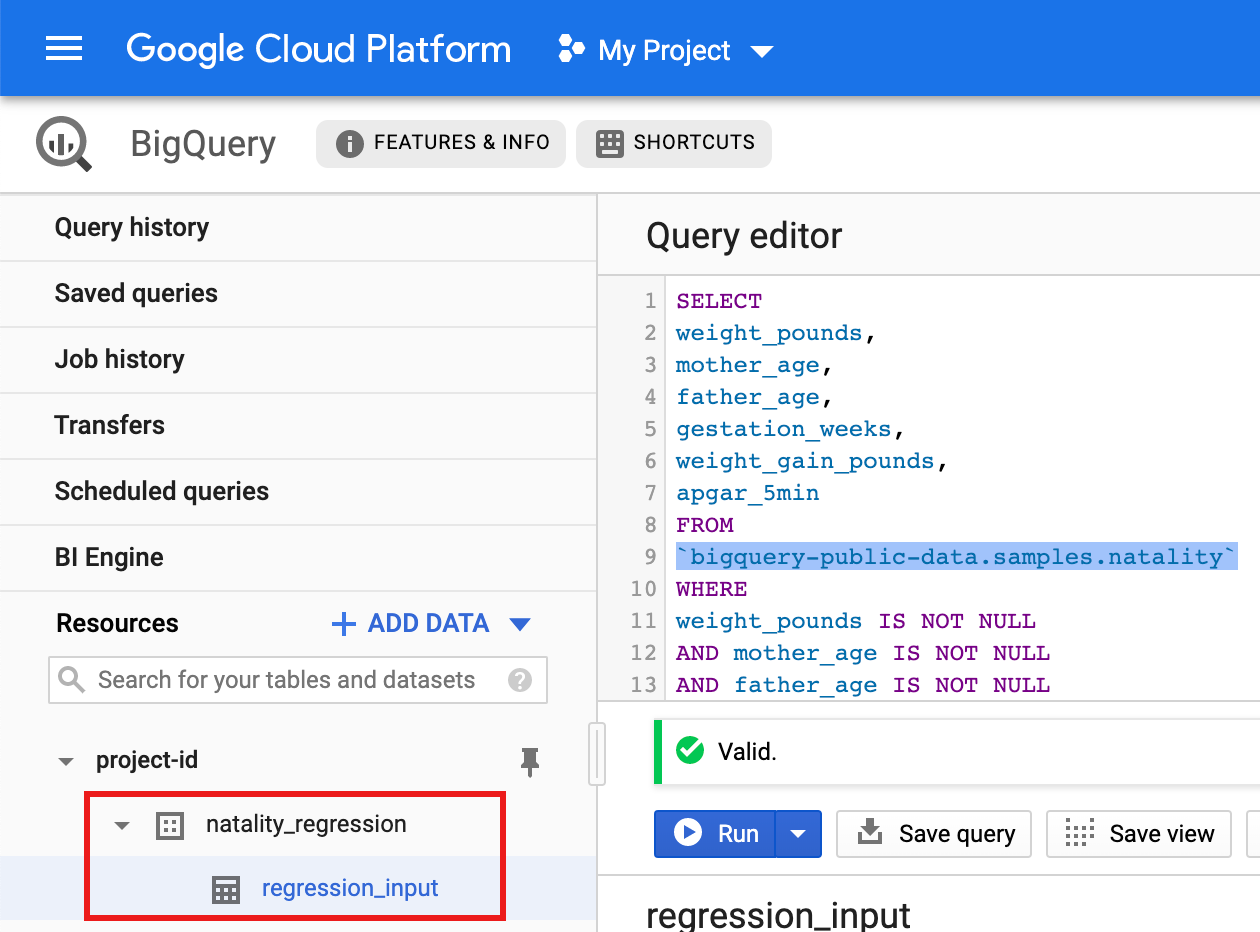
- Kopieren Sie die folgende Abfrage und fügen Sie sie in den Abfrageeditor ein. Klicken Sie dann auf „Ausführen“.
Python
Anleitungen zum Installieren von Python und der Google Cloud-Clientbibliothek für Python (zur Ausführung des Codes erforderlich) finden Sie unter Python-Entwicklungsumgebung einrichten. Es wird empfohlen, eine
virtualenvvon Python zu installieren und zu verwenden.Kopieren Sie den nachfolgenden
natality_tutorial.py-Code und fügen Sie ihn in einepython-Shell auf Ihrem lokalen Computer ein. Drücken Sie in der Shell die Taste<return>, um den Code auszuführen und das BigQuery-Dataset "natality_regression" in Ihrem Google Cloud-Standardprojekt mit der Tabelle "regression_input" zu erstellen. Diese Tabelle wird mit einer Teilmenge der öffentlichennatality-Daten gefüllt.Bestätigen Sie, dass das Dataset
natality_regressionund die Tabelleregression_inputerstellt wurden.
Lineare Regression ausführen
In diesem Abschnitt führen Sie eine lineare Regression von PySpark aus. Dazu senden Sie den Job über die Google Cloud Console an den Dataproc-Dienst oder führen den Befehl gcloud über ein lokales Terminal aus.
Console
Kopieren Sie den folgenden Code und fügen Sie ihn in eine neue
natality_sparkml.py-Datei auf Ihrem lokalen Computer ein."""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()Kopieren Sie die lokale Datei
natality_sparkml.pyin einen Cloud Storage-Bucket in Ihrem Projekt.gsutil cp natality_sparkml.py gs://bucket-name
Führen Sie die Regression über die Dataproc-Seite Job senden aus.
Fügen Sie im Feld Python-Hauptdatei den
gs://-URI des Cloud Storage-Buckets ein, in dem sich Ihre Kopie dernatality_sparkml.py-Datei befindet.Wählen Sie
PySparkals Jobtyp aus.Fügen Sie
gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jarin das Feld Jar-Dateien ein. Dadurch wird der Spark-BigQuery-Connector der PySpark-Anwendung zur Laufzeit zur Verfügung gestellt, damit sie BigQuery-Daten in einem Spark-DataFrame lesen kann.Füllen Sie die Felder Job-ID, Region und Cluster aus.
Klicken Sie auf Submit (Senden), um den Job in Ihrem Cluster auszuführen.
Wenn der Job abgeschlossen ist, wird im Fenster mit den Dataproc-Jobdetails die Ausgabemodell der linearen Regression angezeigt.
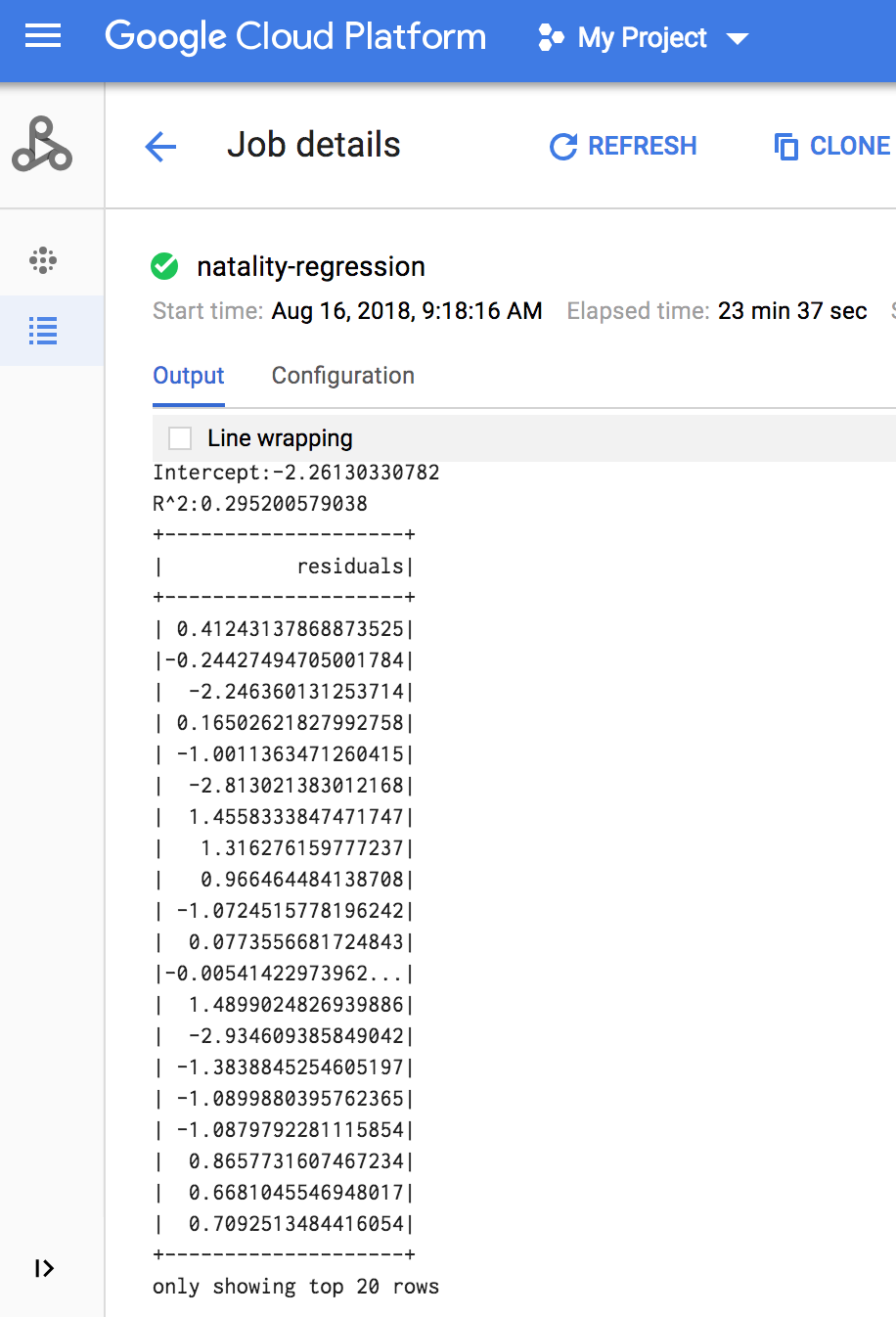
gcloud
Kopieren Sie den folgenden Code und fügen Sie ihn in eine neue
natality_sparkml.py-Datei auf Ihrem lokalen Computer ein."""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()Kopieren Sie die lokale Datei
natality_sparkml.pyin einen Cloud Storage-Bucket in Ihrem Projekt.gsutil cp natality_sparkml.py gs://bucket-name
Senden Sie den PySpark-Job an den Dataproc-Dienst. Führen Sie dazu den unten gezeigten
gcloud-Befehl in einem Terminalfenster auf Ihrem lokalen Computer aus.- Der Flag-Wert --jars macht den spark-bigquery-connector dem PySpark-Job zur Laufzeit verfügbar, damit er BigQuery-Daten in einen Spark DataFrame lesen kann.
gcloud dataproc jobs submit pyspark \ gs://your-bucket/natality_sparkml.py \ --cluster=cluster-name \ --region=region \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- Der Flag-Wert --jars macht den spark-bigquery-connector dem PySpark-Job zur Laufzeit verfügbar, damit er BigQuery-Daten in einen Spark DataFrame lesen kann.
Die Ausgabe der linearen Regression (Modellübersicht) wird im Terminalfenster angezeigt, wenn der Job abgeschlossen ist.
<<< # Print the model summary. ... print "Coefficients:" + str(model.coefficients) Coefficients:[0.0166657454602,-0.00296751984046,0.235714392936,0.00213002070133,-0.00048577251587] <<< print "Intercept:" + str(model.intercept) Intercept:-2.26130330748 <<< print "R^2:" + str(model.summary.r2) R^2:0.295200579035 <<< model.summary.residuals.show() +--------------------+ | residuals| +--------------------+ | -0.7234737533344147| | -0.985466980630501| | -0.6669710598385468| | 1.4162434829714794| |-0.09373154375186754| |-0.15461747949235072| | 0.32659061654192545| | 1.5053877697929803| | -0.640142797263989| | 1.229530260294963| |-0.03776160295256...| | -0.5160734239126814| | -1.5165972740062887| | 1.3269085258245008| | 1.7604670124710626| | 1.2348130901905972| | 2.318660276655887| | 1.0936947030883175| | 1.0169768511417363| | -1.7744915698181583| +--------------------+ only showing top 20 rows.
Bereinigen
Nachdem Sie die Anleitung abgeschlossen haben, können Sie die erstellten Ressourcen bereinigen, damit sie keine Kontingente mehr nutzen und keine Gebühren mehr anfallen. In den folgenden Abschnitten erfahren Sie, wie Sie diese Ressourcen löschen oder deaktivieren.
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten, wenn Sie das zum Ausführen der Anleitung erstellte Projekt löschen.
So löschen Sie das Projekt:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Dataproc-Cluster löschen
Siehe Cluster löschen.