Dopo aver creato un cluster Dataproc, puoi regolarlo ("scalare") aumentando o diminuendo il numero di nodi worker primari o secondari (scalabilità orizzontale) nel cluster. Puoi scalare un cluster Dataproc in qualsiasi momento, anche quando i job sono in esecuzione sul cluster. Non puoi modificare il tipo di macchina di un cluster esistente (scalabilità verticale). Per scalare verticalmente, crea un cluster utilizzando un tipo di macchina supportato, poi esegui la migrazione dei job al nuovo cluster.
Puoi scalare un cluster Dataproc per:
- per aumentare il numero di worker per eseguire un job più rapidamente.
- per ridurre il numero di worker e risparmiare denaro (vedi Ritiro controllato come opzione da utilizzare quando ridimensioni un cluster per evitare di perdere il lavoro in corso).
- per aumentare il numero di nodi per espandere lo spazio di archiviazione Hadoop Distributed File System (HDFS) disponibile.
Poiché i cluster possono essere scalati più di una volta, potresti voler aumentare o diminuire le dimensioni del cluster in una sola volta, per poi diminuirle o aumentarle in un secondo momento.
Utilizzare il ridimensionamento
Esistono tre modi per scalare il cluster Dataproc:
- Utilizza lo strumento a riga di comando
gcloudin gcloud CLI. - Modifica la configurazione del cluster nella consoleGoogle Cloud .
- Utilizza l'API REST.
I nuovi worker aggiunti a un cluster utilizzeranno lo stesso
tipo di macchina
dei worker esistenti. Ad esempio, se un cluster viene creato con worker che utilizzano il tipo di macchina n1-standard-8, anche i nuovi worker utilizzeranno il tipo di macchina n1-standard-8.
Puoi scalare il numero di worker primari o di worker secondari (preemptible) o entrambi. Ad esempio, se aumenti solo il numero di worker preemptible, il numero di worker principali rimane invariato.
gcloud
Per scalare un cluster congcloud dataproc clusters update,
esegui questo comando:
gcloud dataproc clusters update cluster-name \ --region=region \ [--num-workers and/or --num-secondary-workers]=new-number-of-workers
gcloud dataproc clusters update dataproc-1 \
--region=region \
--num-workers=5
...
Waiting on operation [operations/projects/project-id/operations/...].
Waiting for cluster update operation...done.
Updated [https://dataproc.googleapis.com/...].
clusterName: my-test-cluster
...
masterDiskConfiguration:
bootDiskSizeGb: 500
masterName: dataproc-1-m
numWorkers: 5
...
workers:
- my-test-cluster-w-0
- my-test-cluster-w-1
- my-test-cluster-w-2
- my-test-cluster-w-3
- my-test-cluster-w-4
...
API REST
Consulta clusters.patch.
Esempio
PATCH /v1/projects/project-id/regions/us-central1/clusters/example-cluster?updateMask=config.worker_config.num_instances,config.secondary_worker_config.num_instances
{
"config": {
"workerConfig": {
"numInstances": 4
},
"secondaryWorkerConfig": {
"numInstances": 2
}
},
"labels": null
}
Console
Dopo aver creato un cluster, puoi scalare un cluster aprendo la pagina Dettagli cluster del cluster dalla pagina Cluster della Google Cloud console, quindi facendo clic sul pulsante Modifica nella scheda Configurazione. Inserisci un nuovo valore per il numero di nodi worker e/o
nodi worker preemptive (aggiornati rispettivamente a "5" e "2" nello screenshot seguente).
Inserisci un nuovo valore per il numero di nodi worker e/o
nodi worker preemptive (aggiornati rispettivamente a "5" e "2" nello screenshot seguente).
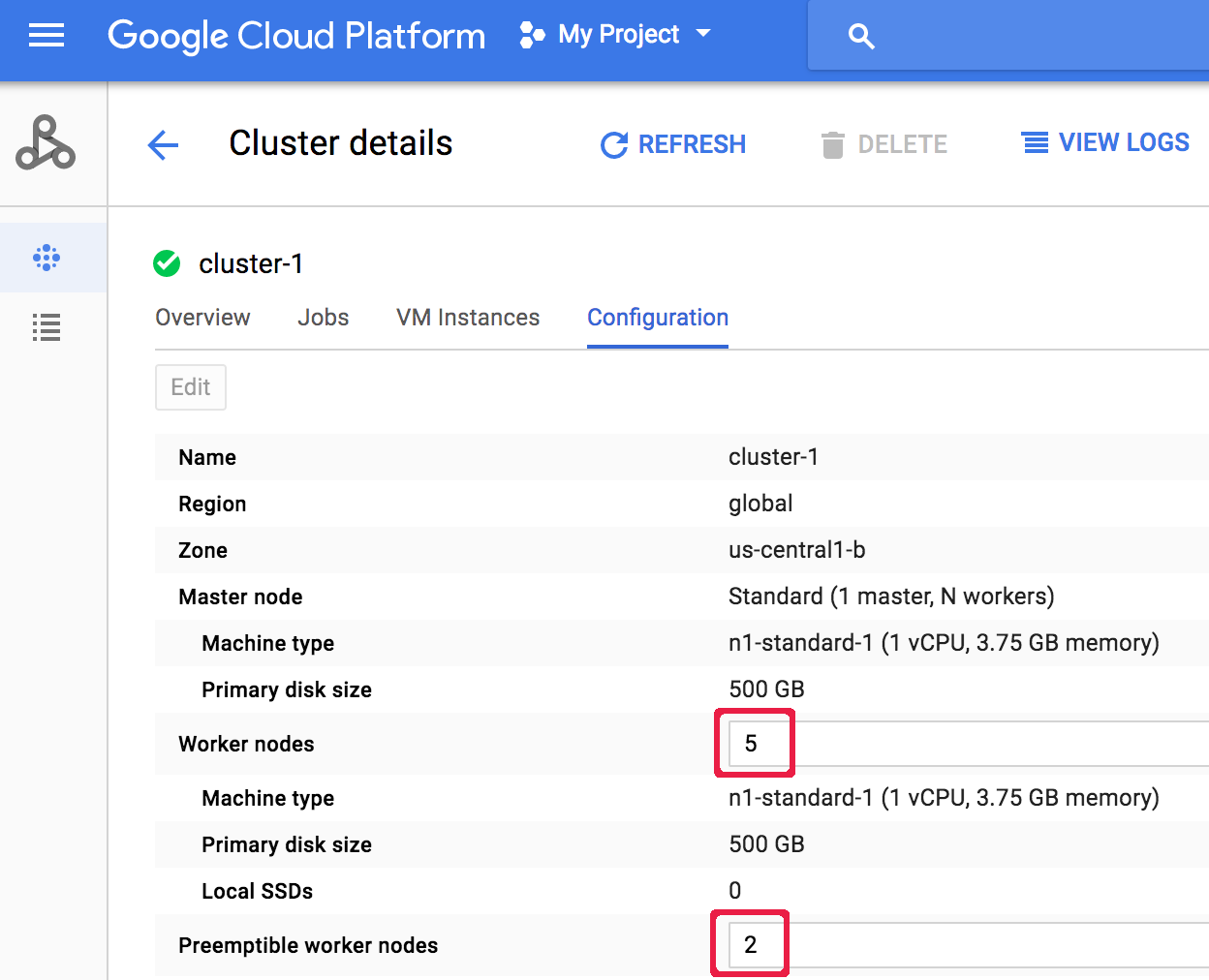 Fai clic su Salva per aggiornare il cluster.
Fai clic su Salva per aggiornare il cluster.
Come Dataproc seleziona i nodi del cluster da rimuovere
Nei cluster creati con versioni immagine 1.5.83+, 2.0.57+, e 2.1.5+, quando viene ridimensionato un cluster, Dataproc tenta di ridurre al minimo l'impatto della rimozione dei nodi sulle applicazioni YARN in esecuzione rimuovendo prima i nodi inattivi, non integri e inattivi, poi rimuovendo i nodi con il minor numero di master di applicazioni YARN e container in esecuzione.
Ritiro gestito automaticamente
Quando riduci le dimensioni di un cluster, il lavoro in corso potrebbe interrompersi prima del completamento. Se utilizzi Dataproc v 1.2 o versioni successive, puoi utilizzare il ritiro gestito automaticamente, che incorpora il ritiro gestito automaticamente dei nodi YARN per completare il lavoro in corso su un worker prima che venga rimosso dal cluster Cloud Dataproc.
Ritiro gestito automaticamente e worker secondari
Il gruppo di worker secondari (preemptive) continua a eseguire il provisioning o l'eliminazione
dei worker per raggiungere le dimensioni previste anche dopo che un'operazione di scalabilità del cluster
è contrassegnata come completata. Se tenti di ritirare normalmente un worker secondario
e ricevi un messaggio di errore simile al seguente:
"Il gruppo di worker secondari non può essere modificato al di fuori di Dataproc. Se hai creato o aggiornato di recente questo cluster, attendi qualche minuto prima di ritirarlo in modo controllato per consentire a tutte le istanze secondarie di entrare o uscire dal cluster.
Dimensioni previste del gruppo di lavoratori secondari: x, dimensioni effettive: y",
attendi
qualche minuto e ripeti la richiestarimozione controllatao.
Utilizza il ritiro gestito automaticamente
Il ritiro controllato di Dataproc incorpora il ritiro controllato dei nodi YARN per completare il lavoro in corso su un worker prima che venga rimosso dal cluster Cloud Dataproc. Per impostazione predefinita, il rimozione controllata è disattivato. Puoi attivarla impostando un valore di timeout quando aggiorni il cluster per rimuovere uno o più worker dal cluster.
gcloud
Quando aggiorni un cluster per rimuovere uno o più worker, utilizza il comando gcloud dataproc clusters update con il flag--graceful-decommission-timeout. I valori di timeout
(stringa) possono essere "0s" (valore predefinito; ritiro forzato e non graduale) o una durata positiva relativa all'ora corrente (ad esempio, "3s").
La durata massima è di 1 giorno.
gcloud dataproc clusters update cluster-name \ --region=region \ --graceful-decommission-timeout="timeout-value" \ [--num-workers and/or --num-secondary-workers]=decreased-number-of-workers \ ... other args ...
API REST
Vedi clusters.patch.gracefulDecommissionTimeout. I valori di timeout (stringa) possono essere "0" (valore predefinito; ritiro forzato e non controllato) o una durata in secondi (ad esempio, "3s"). La durata massima è di 1 giorno.Console
Dopo aver creato un cluster, puoi selezionare rimozione controllata di un cluster aprendo la pagina Dettagli cluster del cluster dalla pagina Cluster della consoleGoogle Cloud , quindi facendo clic sul pulsante Modifica nella scheda Configurazione.
Nella sezione Ritiro controllato, seleziona
Utilizza il ritiro controllato e poi seleziona un valore di timeout.
 Fai clic su Salva per aggiornare il cluster.
Fai clic su Salva per aggiornare il cluster.
Annullamento di un'operazione di riduzione delle dimensioni della rimozione controllata
Sui cluster Dataproc creati con le versioni immagine
2.0.57+
o 2.1.5+,
puoi eseguire il comando gcloud dataproc operations cancel
o inviare una richiesta
operations.cancel
API Dataproc per annullare un'operazione di riduzione delle dimensioni del ritiro controllato.
Quando annulli un'operazione di riduzione delle dimensioni della rimozione controllata:
I worker nello stato
DECOMMISSIONINGvengono riassegnati e diventanoACTIVEal termine dell'annullamento dell'operazione.Se l'operazione di scale down include aggiornamenti delle etichette, questi potrebbero non essere applicati.
Per verificare lo stato della richiesta di annullamento, puoi
eseguire il comando gcloud dataproc operations describe
o inviare una richiesta
operations.get
all'API Dataproc. Se l'operazione di annullamento ha esito positivo, lo stato dell'operazione interna viene contrassegnato
come CANCELLED.