Gli esempi riportati di seguito creano e utilizzano un cluster Dataproc con Kerberos abilitato con componenti Ranger e Solr per controllare l'accesso degli utenti alle risorse Hadoop, YARN e HIVE.
Note:
È possibile accedere all'interfaccia utente web di Ranger tramite il gateway dei componenti.
In un cluster Ranger con Kerberos, Dataproc mappa un utente Kerberos all'utente di sistema rimuovendo il realm e l'istanza dell'utente Kerberos. Ad esempio, l'entità Kerberos
user1/cluster-m@MY.REALMè mappata al sistemauser1e i criteri Ranger sono definiti per consentire o negare le autorizzazioni peruser1.
Crea il cluster.
- Il seguente comando
gcloudpuò essere eseguito in una finestra del terminale locale o da Cloud Shell di un progetto.gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=SOLR,RANGER \ --enable-component-gateway \ --properties="dataproc:ranger.kms.key.uri=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key,dataproc:ranger.admin.password.uri=gs://bucket/admin-password.encrypted" \ --kerberos-root-principal-password-uri=gs://bucket/kerberos-root-principal-password.encrypted \ --kerberos-kms-key=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key
- Il seguente comando
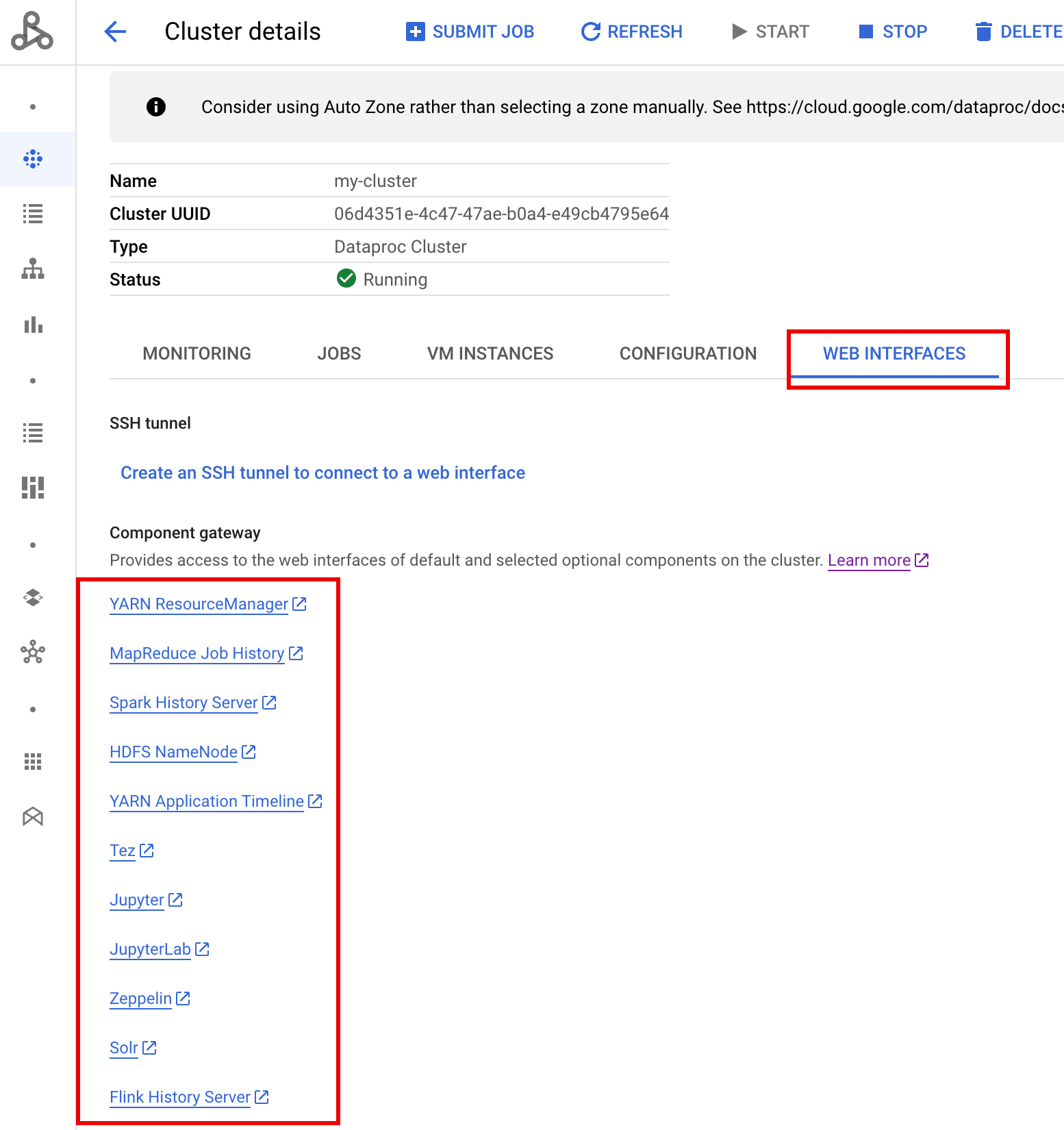
Una volta che il cluster è in esecuzione, vai alla pagina Cluster di Dataproc nella console Google Cloud, quindi seleziona il nome del cluster per aprire la pagina Dettagli cluster. Fai clic sulla scheda Interfacce web per visualizzare un elenco di link del gateway dei componenti alle interfacce web dei componenti predefiniti e facoltativi installati sul cluster. Fai clic sul link Ranger.
Accedi a Ranger inserendo il nome utente "admin" e la password di amministratore di Ranger.
L'interfaccia utente di amministrazione di Ranger si apre in un browser locale.
Criterio di accesso YARN
Questo esempio crea un criterio Ranger per consentire e negare l'accesso degli utenti alla coda root.default di YARN.
Seleziona
yarn-dataprocdall'interfaccia utente di Ranger Admin.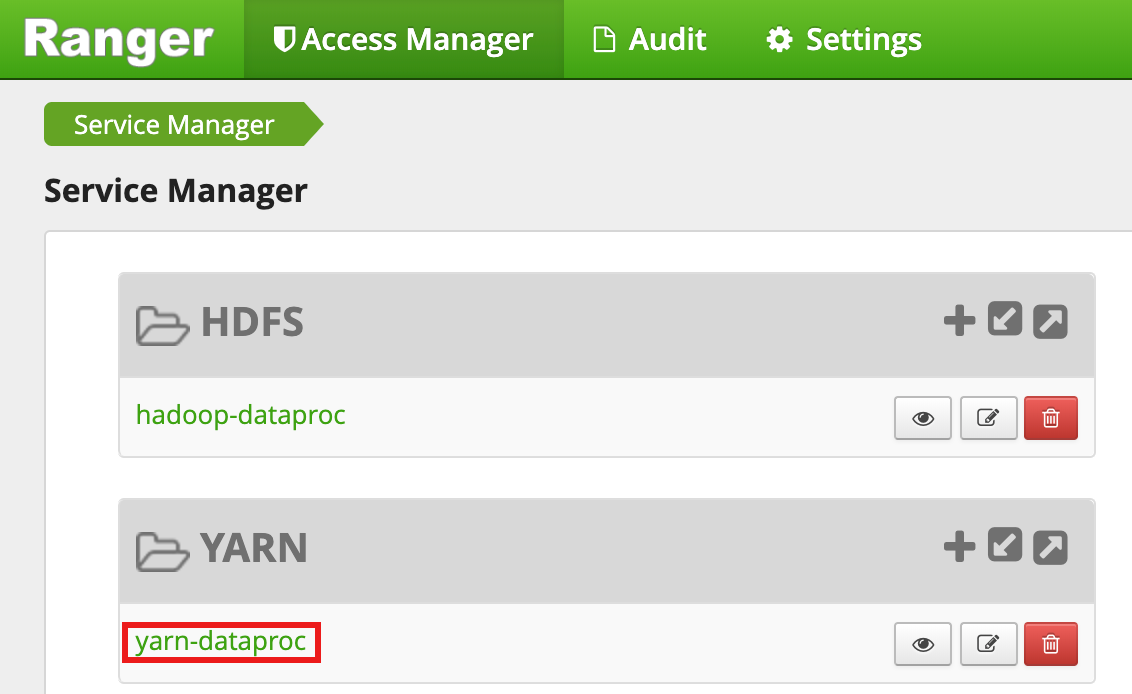
Nella pagina Criteri yarn-dataproc, fai clic su Aggiungi nuovo criterio. Nella pagina Crea criterio, i seguenti campi vengono inseriti o selezionati:
Policy Name: "yarn-policy-1"Queue: "root.default"Audit Logging: "Sì"Allow Conditions:Select User: "userone"Permissions: "Seleziona tutto" per concedere tutte le autorizzazioni
Deny Conditions:Select User: "usertwo"Permissions: "Seleziona tutto" per negare tutte le autorizzazioni
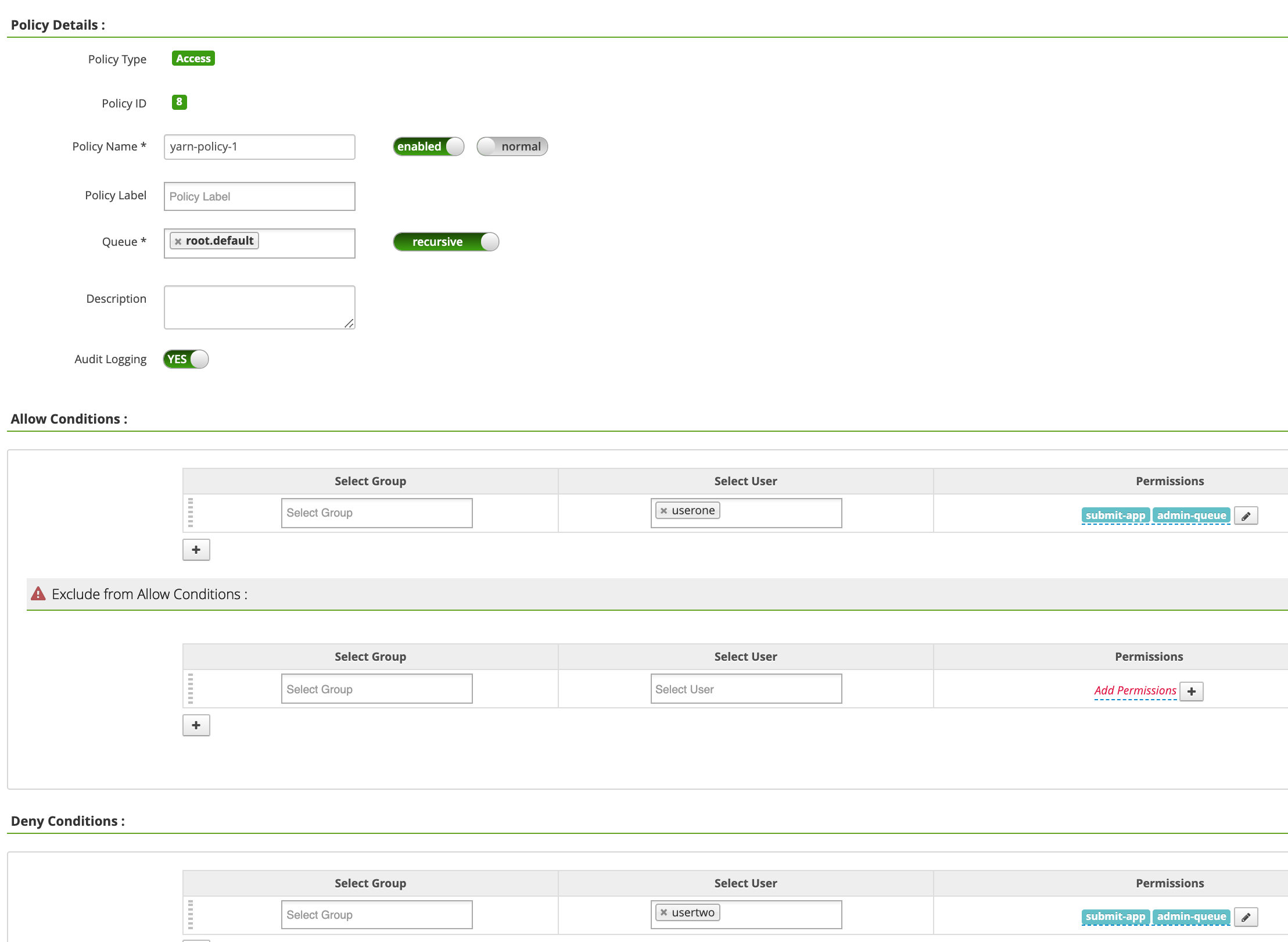
Fai clic su Aggiungi per salvare la norma. Il criterio è elencato nella pagina Norme yarn-dataproc:
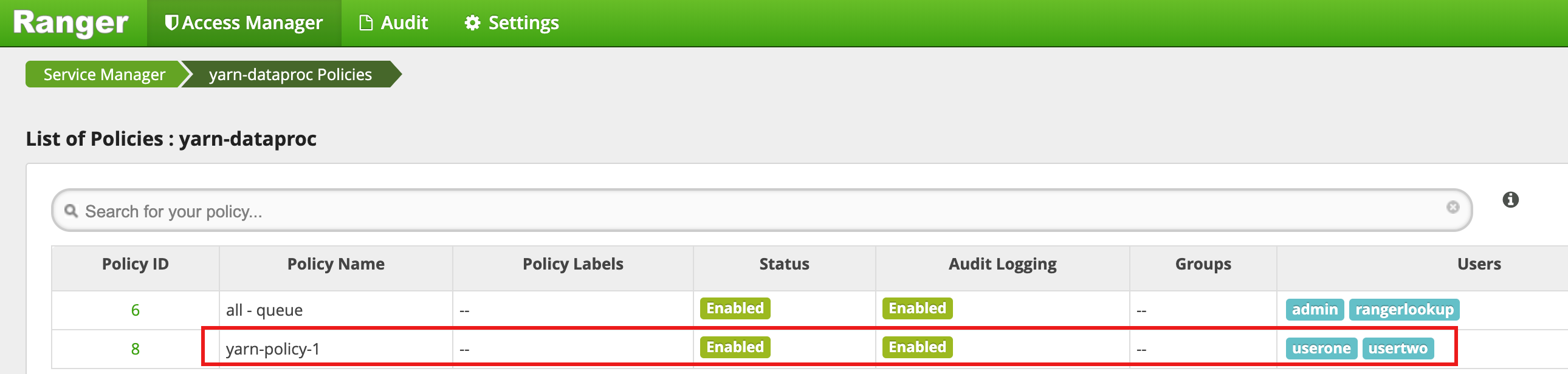
Esegui un job MapReduce Hadoop nella finestra della sessione SSH principale come utente one:
userone@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- L'interfaccia utente di Ranger mostra che
useroneè stato autorizzato a inviare il job.
- L'interfaccia utente di Ranger mostra che
Esegui il job MapReduce di Hadoop dalla finestra della sessione SSH master della VM come
usertwo:usertwo@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- L'interfaccia utente di Ranger mostra che a
usertwoè stato negato l'accesso per inviare il job.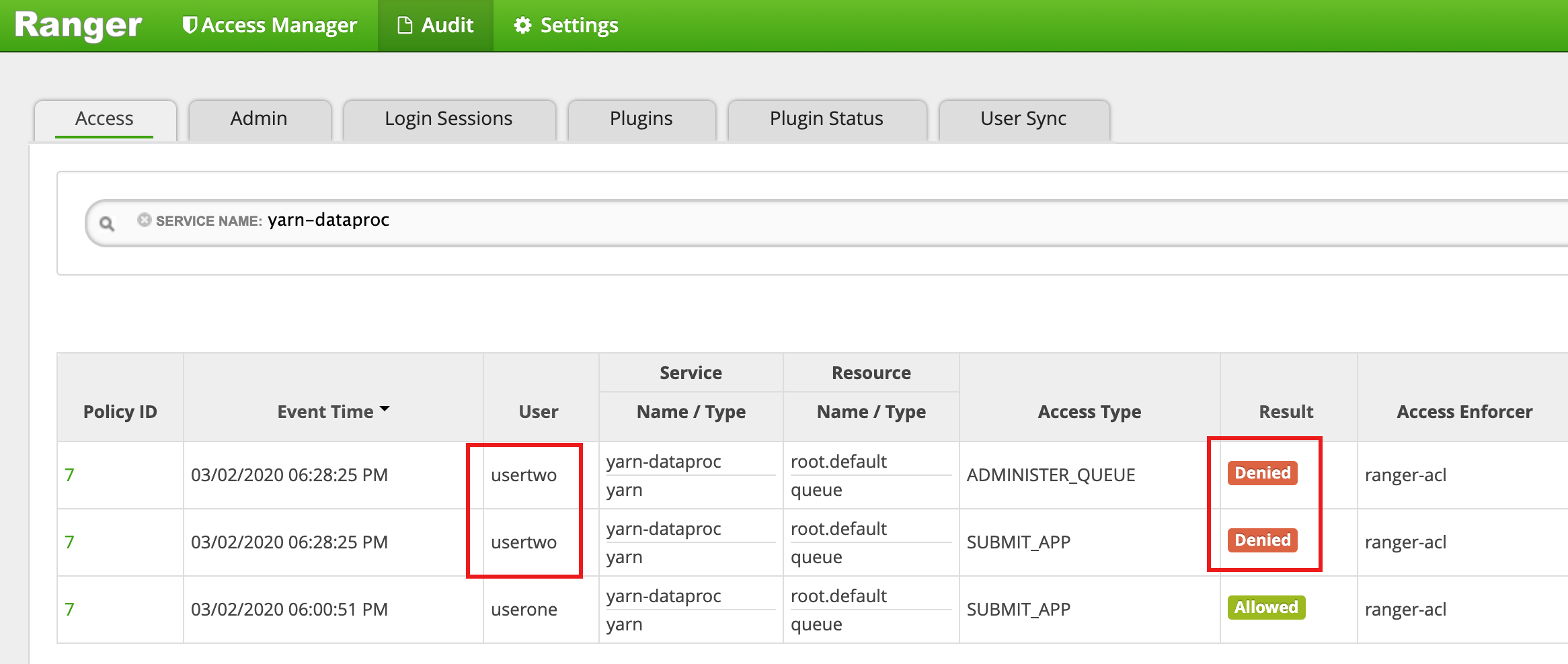
- L'interfaccia utente di Ranger mostra che a
Criterio di accesso HDFS
Questo esempio crea un criterio Ranger per consentire e negare l'accesso utente alla directory HDFS /tmp.
Seleziona
hadoop-dataprocdall'interfaccia utente di Ranger Admin.
Nella pagina Criteri hadoop-dataproc, fai clic su Aggiungi nuovo criterio. Nella pagina Crea criterio, i seguenti campi vengono inseriti o selezionati:
Policy Name: "hadoop-policy-1"Resource Path: "/tmp"Audit Logging: "Sì"Allow Conditions:Select User: "userone"Permissions: "Seleziona tutto" per concedere tutte le autorizzazioni
Deny Conditions:Select User: "usertwo"Permissions: "Seleziona tutto" per negare tutte le autorizzazioni

Fai clic su Aggiungi per salvare la norma. Il criterio è elencato nella pagina Criteri hadoop-dataproc:
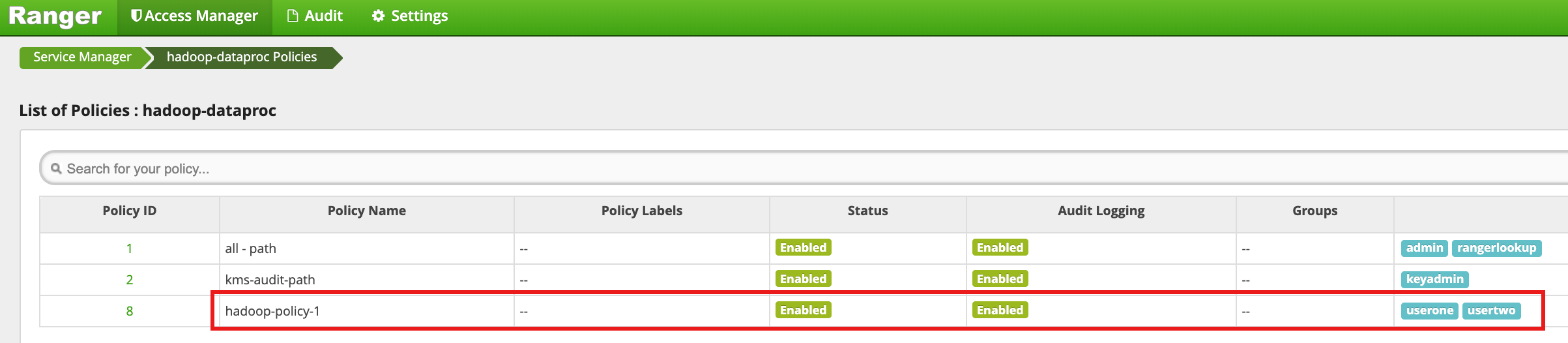
Accedi alla directory
/tmpHDFS come utenteone:userone@example-cluster-m:~$ hadoop fs -ls /tmp
- L'interfaccia utente di Ranger mostra che
useroneè stato consentito l'accesso alla directory /tmp di HDFS.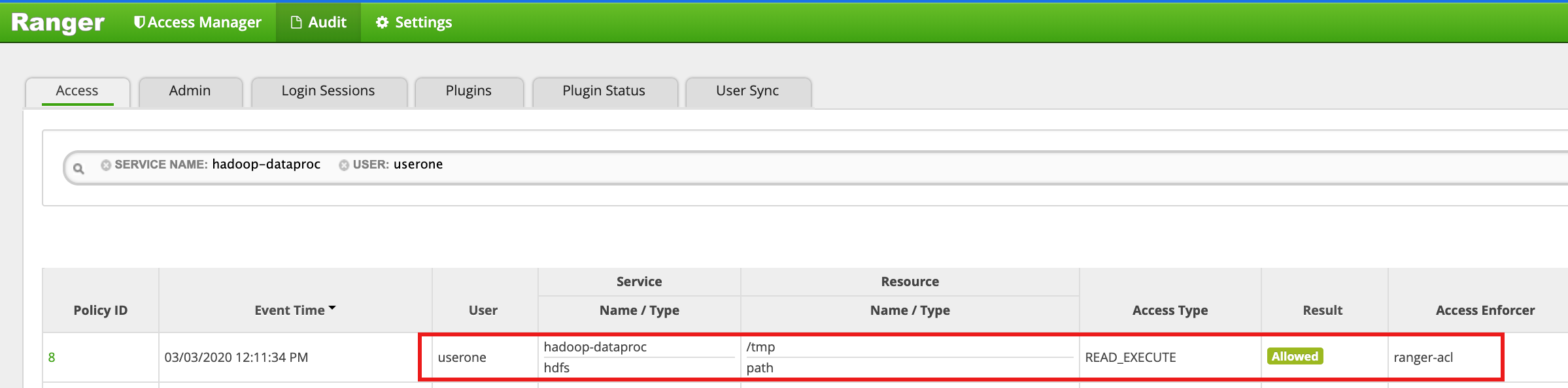
- L'interfaccia utente di Ranger mostra che
Accedi alla directory
/tmpHDFS comeusertwo:usertwo@example-cluster-m:~$ hadoop fs -ls /tmp
- L'interfaccia utente di Ranger mostra che
usertwoè stato negato l'accesso alla directory /tmp di HDFS.
- L'interfaccia utente di Ranger mostra che
Criterio di accesso Hive
Questo esempio crea un criterio Ranger per consentire e negare l'accesso degli utenti a una tabella Hive.
Crea una piccola tabella
employeeutilizzando l'interfaccia a riga di comando Hive nell'istanza principale.hive> CREATE TABLE IF NOT EXISTS employee (eid int, name String); INSERT INTO employee VALUES (1 , 'bob') , (2 , 'alice'), (3 , 'john');
Seleziona
hive-dataprocdall'interfaccia utente di amministrazione di Ranger.
Nella pagina Criteri hive-dataproc, fai clic su Aggiungi nuovo criterio. Nella pagina Crea criterio, i seguenti campi vengono inseriti o selezionati:
Policy Name: "hive-policy-1"database: "default"table: "employee"Hive Column: "*"Audit Logging: "Sì"Allow Conditions:Select User: "userone"Permissions: "Seleziona tutto" per concedere tutte le autorizzazioni
Deny Conditions:Select User: "usertwo"Permissions: "Seleziona tutto" per negare tutte le autorizzazioni
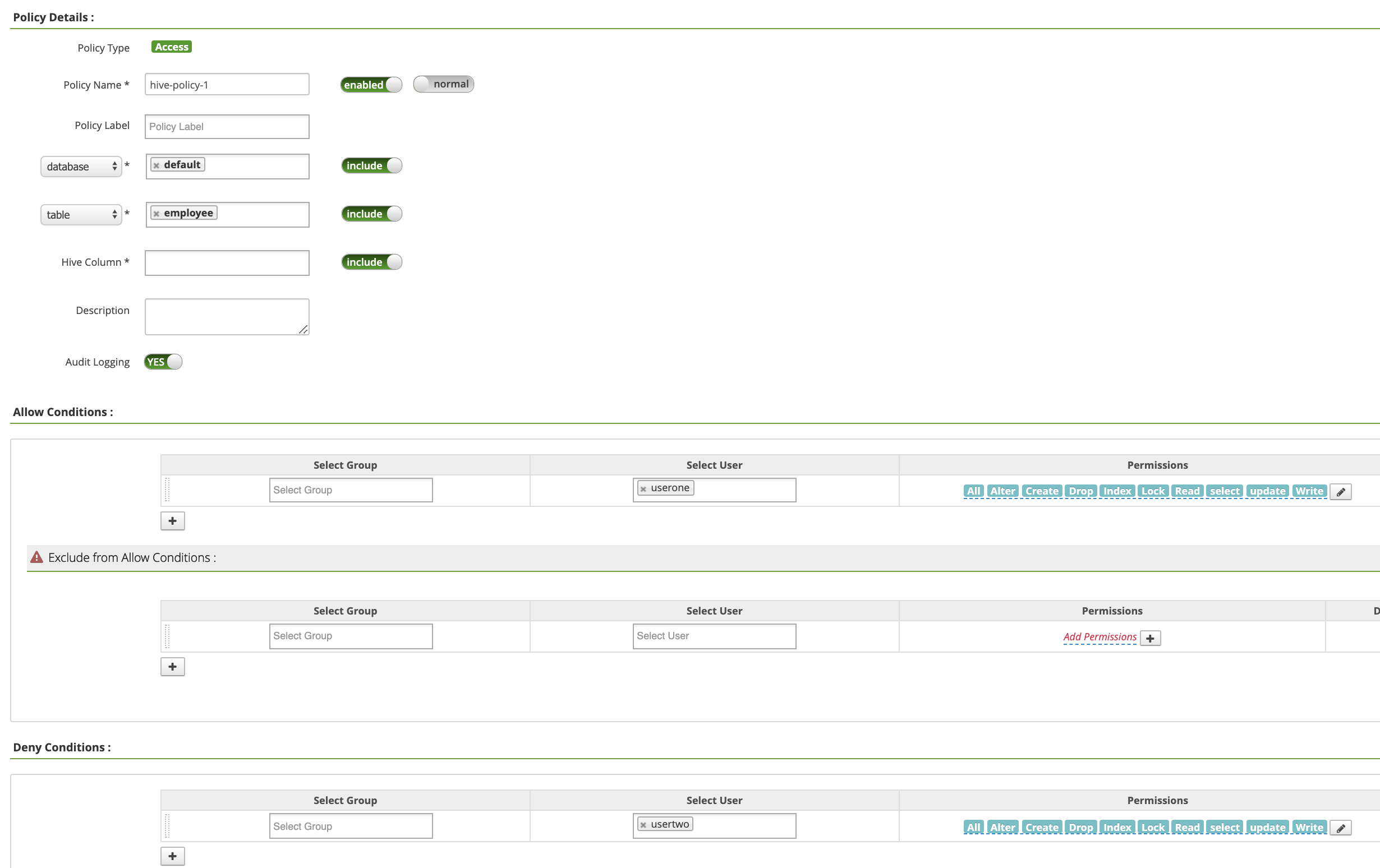
Fai clic su Aggiungi per salvare la norma. Il criterio è elencato nella pagina Norme hive-dataproc:

Esegui una query dalla sessione SSH principale della VM sulla tabella dei dipendenti di Hive come utente one:
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- La query userone va a buon fine:
Connected to: Apache Hive (version 2.3.6) Driver: Hive JDBC (version 2.3.6) Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 1 | bob | | 2 | alice | | 3 | john | +---------------+----------------+ 3 rows selected (2.033 seconds)
- La query userone va a buon fine:
Esegui una query dalla sessione SSH principale della VM sulla tabella dei dipendenti di Hive come utente due:
usertwo@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- A usertwo viene negato l'accesso alla tabella:
Error: Could not open client transport with JDBC Uri: ... Permission denied: user=usertwo, access=EXECUTE, inode="/tmp/hive"
- A usertwo viene negato l'accesso alla tabella:
Accesso granulare a Hive
Ranger supporta il mascheramento e i filtri a livello di riga su Hive. Questo esempio si basa sull'esempio hive-policy-1 precedente aggiungendo criteri di mascheramento e filtro.
Seleziona
hive-dataprocdall'interfaccia utente di amministrazione di Ranger, poi seleziona la scheda Masking (Occultamento) e fai clic su Aggiungi nuova norma.
Nella pagina Crea criterio, i seguenti campi vengono inseriti o selezionati per creare un criterio per mascherare (annullare) la colonna del nome del dipendente:
Policy Name: "hive-masking policy"database: "default"table: "employee"Hive Column: "name"Audit Logging: "Sì"Mask Conditions:Select User: "userone"Access Types: "seleziona" autorizzazioni di aggiunta/modificaSelect Masking Option: "nullify"
Fai clic su Aggiungi per salvare la norma.
Seleziona
hive-dataprocdall'interfaccia utente di amministrazione di Ranger, poi seleziona la scheda Filtro a livello di riga e fai clic su Aggiungi nuova norma.
Nella pagina Crea criterio, i seguenti campi vengono inseriti o selezionati per creare un criterio per filtrare (restituire) le righe in cui
eidnon è uguale a1:Policy Name: "hive-filter policy"Hive Database: "default"Hive Table: "employee"Audit Logging: "Sì"Mask Conditions:Select User: "userone"Access Types: "seleziona" autorizzazioni di aggiunta/modificaRow Level Filter: espressione di filtro "eid != 1"
Fai clic su Aggiungi per salvare la norma.
Ripeti la query precedente dalla sessione SSH principale della VM contro la tabella dei dipendenti di Hive come utenteone:
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- La query restituisce la colonna del nome mascherata e il valore bob
(eid=1) filtrato dai risultati.:
Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 2 | NULL | | 3 | NULL | +---------------+----------------+ 2 rows selected (0.47 seconds)
- La query restituisce la colonna del nome mascherata e il valore bob
(eid=1) filtrato dai risultati.: