BigQuery Omni の概要
BigQuery Omni を使用すると、BigLake テーブルを使用して、Amazon Simple Storage Service(Amazon S3)または Azure Blob Storage に保存されたデータに対して BigQuery 分析を実行できます。
多くの組織は、データを複数のパブリック クラウドに保存しています。すべてのデータから分析情報を得るのは困難であるため、このようなデータはサイロ化されてしまうことがよくあります。低コストで高速であり、分散型データ ガバナンスによる追加のオーバーヘッドを発生させないマルチクラウド データツールでデータを分析できれば望ましい状況です。BigQuery Omni では統合されたインターフェースを使用できるため、この負担を軽減できます。
外部データに対して BigQuery 分析を実行するには、まず Amazon S3 または Blob Storage に接続する必要があります。外部データに対してクエリを実行するには、Amazon S3 または Blob Storage のデータを参照する BigLake テーブルを作成する必要があります。
BigQuery Omni ツール
次の BigQuery Omni ツールを使用して、外部データに対して BigQuery 分析を実行できます。
- クロスクラウド結合: BigQuery Omni リージョンのデータを結合できる BigQuery リージョンからクエリを直接実行します。
- クロスクラウド マテリアライズド ビュー: マテリアライズド ビューのレプリカを使用して、BigQuery Omni リージョンからデータを継続的に複製します。データのフィルタリングがサポートされます。
SELECTを使用したクロスクラウド転送: BigQuery Omni リージョンでCREATE TABLE AS SELECTステートメントまたはINSERT INTO SELECTステートメントを使用してクエリを実行し、結果を BigQuery リージョンに移動します。LOADを使用したクロスクラウド転送:LOAD DATAステートメントを使用して、Amazon Simple Storage Service(Amazon S3)または Azure Blob Storage から BigQuery にデータを直接読み込みます。
次の表に、各クロスクラウド ツールの主な機能と機能を示します。
| クロスクラウド結合 | クロスクラウド マテリアライズド ビュー | SELECT を使用したクロスクラウド転送 |
LOAD を使用したクロスクラウド転送 |
|
|---|---|---|---|---|
| 推奨される用途 | ローカル テーブルと結合したり、2 つの異なる BigQuery Omni リージョン間(AWS リージョンと Azure Blob Storage リージョンの間など)でデータを結合したりするために、1 回限りの用途で外部データをクエリする。クロスクラウド結合は、データが大きくなく、キャッシュ保存が主要な要件でない場合に使用します。 | キャッシュ保存が主要な要件である場合に、繰り返されるクエリやスケジュールされたクエリを設定して外部データを継続的に増分転送する。たとえば、ダッシュボードの維持に使用します。 | キャッシュ保存やクエリの最適化などの手動での制御が主要な要件であり、クロスクラウド結合やクロスクラウド マテリアライズド ビューでサポートされない複雑なクエリを使用する場合に、BigQuery Omni リージョンから BigQuery リージョンへの 1 回限りの用途で外部データをクエリする。 | 大規模なデータセットをフィルタリングなしでそのまま移行し、スケジュールされたクエリを使用して元データを移動する。 |
| データ移動前のフィルタリングのサポート | あり。一部のクエリ演算子には制限が適用されます。詳細については、クロスクラウド結合の制限事項をご覧ください。 | あり。集計関数や UNION 演算子など、一部のクエリ演算子には制限が適用されます。 |
あり。クエリ演算子に対する制限はありません。 | なし |
| 転送サイズの上限 | 1 回の転送あたり 60 GB(リモート リージョンへのサブクエリごとに転送が 1 回発生) | 上限なし | 1 回の転送あたり 60 GB(リモート リージョンへのサブクエリごとに転送が 1 回発生) | 上限なし |
| データ転送の圧縮 | ワイヤ圧縮 | 列指向 | ワイヤ圧縮 | ワイヤ圧縮 |
| キャッシュ保存 | 非対応 | マテリアライズド ビューを使用したキャッシュ対応テーブルでサポート | 非対応 | 非対応 |
| 下り(外向き)の料金 | AWS 下り(外向き)と大陸間の費用 | AWS 下り(外向き)と大陸間の費用 | AWS 下り(外向き)と大陸間の費用 | AWS 下り(外向き)と大陸間の費用 |
| データ転送のコンピューティング使用量 | ソースの AWS または Azure Blob Storage リージョンのスロットを使用(予約またはオンデマンド) | 不使用 | ソースの AWS または Azure Blob Storage リージョンのスロットを使用(予約またはオンデマンド) | 不使用 |
| フィルタリングのコンピューティング使用量 | ソースの AWS または Azure Blob Storage リージョンのスロットを使用(予約またはオンデマンド) | ローカルのマテリアライズド ビューとメタデータの計算にソースの AWS または Azure Blob Storage リージョンのスロットを使用(予約またはオンデマンド) | ソースの AWS または Azure Blob Storage リージョンのスロットを使用(予約またはオンデマンド) | 不使用 |
| 増分転送 | 非対応 | 集計以外のマテリアライズド ビューでサポート | 非対応 | 非対応 |
Amazon Simple Storage Service(Amazon S3)または Azure Blob Storage から Google Cloudにデータを転送する手段として、次の方法も検討できます。
- Storage Transfer Service: Google Cloud と Amazon Simple Storage Service(Amazon S3)または Azure Blob Storage のオブジェクト ストレージおよびファイル ストレージ間でデータを転送します。
- BigQuery Data Transfer Service: あらかじめ設定されたスケジュールに基づいて、BigQuery へのデータ転送を自動化します。さまざまなソースをサポートし、データ移行に適しています。BigQuery Data Transfer Service はフィルタリングには対応していません。
アーキテクチャ
BigQuery のアーキテクチャではコンピューティングとストレージが分離されているため、必要に応じてスケールアウトが可能で、非常に大量のワークロードを処理できます。BigQuery Omni は、BigQuery のクエリエンジンを他のクラウドで実行できるように、このアーキテクチャを拡大したものです。この結果、データを BigQuery ストレージへ物理的に移動する必要はありません。データがすでに存在する場所で処理が行われます。
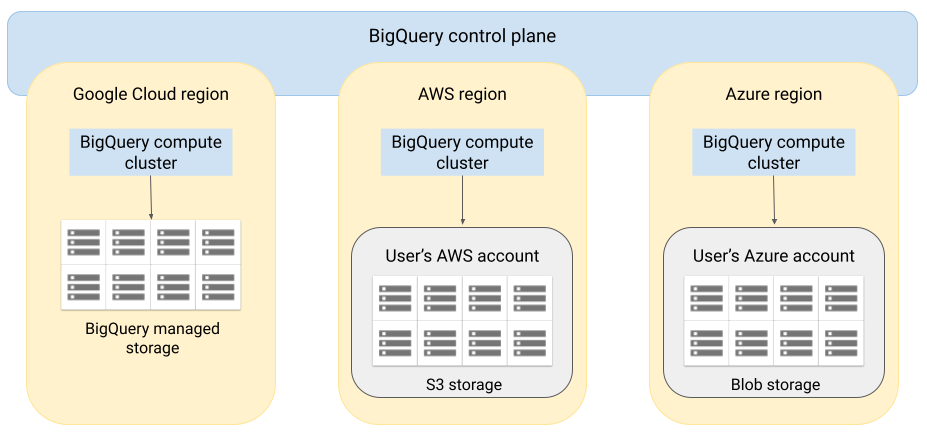
クエリの結果は安全な接続を経由して Google Cloud に戻し、たとえば Google Cloud コンソールに表示できます。または、結果を Amazon S3 バケットや Blob Storage に直接書き込むこともできます。この場合、クエリの結果がクラウド間で転送されることはありません。
BigQuery Omni は、標準の AWS IAM ロールや Azure Active Directory プリンシパルを使用して、サブスクリプション内のデータにアクセスします。読み取りと書き込みのアクセスを BigQuery Omni に委託でき、そのアクセス権はいつでも無効にできます。
データに対してクエリを実行する際のデータフロー
以下の図は、次のクエリに対する Google Cloud と AWS または Azure との間のデータ移動を示しています。
SELECTステートメントCREATE EXTERNAL TABLEステートメント

- BigQuery コントロール プレーンが、Google Cloud コンソール、bq コマンドライン ツール、API メソッド、またはクライアント ライブラリを介してクエリジョブを受信します。
- BigQuery コントロール プレーンが、クエリジョブの処理のために BigQuery データプレーン(AWS または Azure)に送信します
- BigQuery データプレーンが、VPN 接続を介してコントロール プレーンからクエリを受信します。
- BigQuery データプレーンが、Amazon S3 バケットまたは Blob Storage からテーブルデータを読み取ります。
- BigQuery データプレーンが、テーブルデータに対してクエリジョブを実行します。テーブルデータの処理は、指定された AWS または Azure リージョンで行われます。
- クエリ結果は、VPN 接続を介してデータプレーンからコントロール プレーンに送信されます。
- BigQuery コントロール プレーンが、クエリジョブのレスポンスとして表示するクエリジョブの結果を受信します。このデータは最大 24 時間保存されます。
- クエリ結果が返されます。
詳細については、Amazon S3 データに対してクエリを実行すると Blob Storage データをご覧ください。
データのエクスポート時のデータフロー
次の図は、EXPORT DATA ステートメントにおける Google Cloud と AWS または Azure との間のデータ移動を示しています。

- BigQuery コントロール プレーンが、 Google Cloud コンソール、bq コマンドライン ツール、API メソッド、またはクライアント ライブラリを介して、エクスポート クエリジョブを受信します。クエリには、Amazon S3 バケットまたは Blob Storage 内のクエリ結果の送信先パスが含まれます。
- BigQuery コントロール プレーンが、エクスポート クエリ ジョブの処理のために BigQuery データプレーン(AWS または Azure)に送信します。
- BigQuery データプレーンが、VPN 接続を介してコントロール プレーンからエクスポート クエリを受信します。
- BigQuery データプレーンが、Amazon S3 バケットまたは Blob Storage からテーブルデータを読み取ります。
- BigQuery データプレーンが、テーブルデータに対してクエリジョブを実行します。テーブルデータの処理が、指定した AWS または Azure リージョンで行われます。
- BigQuery が、Amazon S3 バケットまたは Blob Storage の指定された送信先パスにクエリ結果を書き込みます。
詳細については、クエリ結果を Amazon S3 にエクスポートすると Blob Storage をご覧ください。
利点
パフォーマンス。クラウド間でデータがコピーされず、データが存在する同じリージョンでクエリが実行されるため、分析情報をより迅速に取得できます。
費用。データは移動されないため、アウトバウンド データ転送の費用を節約できます。クエリは Google が管理するクラスタで実行されるため、AWS や Azure アカウントで、BigQuery Omni 分析に関連する追加料金は請求されません。クエリの実行にのみ、BigQuery の価格モデルに従って請求が行われます。
セキュリティとデータ ガバナンス。データは、ユーザー独自の AWS または Azure サブスクリプションで管理します。パブリック クラウドから元データの移動やコピーをする必要はありません。すべての計算は、データと同じリージョン内で実行される BigQuery マルチテナント サービスで行われます。
サーバーレス アーキテクチャ。BigQuery の他の部分と同様、BigQuery Omni はサーバーレス サービスです。Google が、BigQuery Omni を実行するクラスタをデプロイして管理します。リソースのプロビジョニングやクラスタの管理は必要ありません。
管理のしやすさ。BigQuery Omni は、 Google Cloudによる統合型管理インターフェースを提供します。BigQuery Omni では、既存の Google Cloud アカウントと BigQuery プロジェクトを使用できます。 Google Cloud コンソールで GoogleSQL クエリを作成して AWS または Azure でデータにクエリを実行し、 Google Cloud コンソールに結果を表示できます。
クロスクラウド転送。S3 バケットと Blob Storage から標準の BigQuery テーブルにデータを読み込むことができます。詳細については、Amazon S3 データを転送すると Blob Storage データを BigQuery に転送するをご覧ください。
パフォーマンス向上のためのメタデータ キャッシュ
キャッシュに保存されたメタデータを使用すると、Amazon S3 データを参照する BigLake テーブルに対するクエリのパフォーマンスを改善できます。これは、多数のファイルを扱う場合、またはデータが Apache Hive パーティション分割データの場合に特に便利です。
BigQuery は、CMETA を分散メタデータ システムとして使用して、大規模なテーブルを効率的に処理します。CMETA には、列レベルとブロックレベルのきめ細かいメタデータが用意されています。このメタデータには、システム テーブルからアクセスできます。これにより、データアクセスと処理が最適化され、クエリのパフォーマンスが向上します。大規模なテーブルのクエリ パフォーマンスをさらに高速化するために、BigQuery にはメタデータ キャッシュが保持されます。CMETA 更新ジョブにより、このキャッシュは最新の状態に保たれます。メタデータには、ファイル名、パーティショニング情報、ファイルの物理的なメタデータ(行数など)が含まれます。テーブルでメタデータのキャッシュ保存を有効にするかどうかを選択できます。多数のファイルと Hive パーティション フィルタを使用したクエリには、メタデータ キャッシュが最適です。
メタデータのキャッシュ保存を有効にしていない場合、テーブルのクエリはオブジェクト メタデータを取得するために外部データソースを読み取る必要があります。このデータを読み取ると、クエリのレイテンシが増加します。外部データソースから数百万のファイルを一覧表示するには、数分かかることがあります。メタデータのキャッシュ保存を有効にすると、クエリで外部データソースのファイルを一覧表示することを回避し、ファイルをより高速にパーティション分割してプルーニングできます。
メタデータ キャッシュ保存は、Cloud Storage オブジェクトのバージョニングとも統合されています。キャッシュが入力または更新されると、その時点での Cloud Storage オブジェクトのライブ バージョンに基づいてメタデータがキャプチャされます。その結果、メタデータ キャッシュ保存が有効になっているクエリは、新しいバージョンが Cloud Storage でライブになっても、特定のキャッシュ保存されたオブジェクト バージョンに対応するデータを読み取ります。Cloud Storage で後で更新されたオブジェクト バージョンのデータにアクセスするには、メタデータ キャッシュを更新する必要があります。
この機能を制御するプロパティが 2 つあります。
- 最大の未更新は、キャッシュに保存されたメタデータをクエリで使用するタイミングを指定します。
- メタデータ キャッシュ モードは、メタデータの収集方法を指定します。
メタデータのキャッシュ保存を有効にする場合は、テーブルに対するオペレーションで許容されるメタデータ未更新の最大間隔を指定します。たとえば、1 時間の間隔を指定すると、テーブルに対するオペレーションでは、キャッシュに保存されたメタデータが過去 1 時間以内に更新されている場合、そのメタデータが使用されます。キャッシュに保存されたメタデータがそれより古い場合、オペレーションは代わりに Amazon S3 からメタデータを取得します。未更新の間隔は 30 分~7 日の間で指定できます。
BigLake テーブルまたはオブジェクト テーブルでメタデータのキャッシュ保存を有効にすると、BigQuery によりメタデータ生成更新ジョブがトリガーされます。キャッシュを自動または手動で更新することを選択できます。
- 自動更新の場合、キャッシュはシステムが定義した間隔(通常は 30~60 分)で更新されます。Amazon S3 内のファイルがランダムな間隔で追加、削除、変更される場合、キャッシュを自動的に更新することをおすすめします。更新のタイミングを制御する必要がある場合(たとえば、抽出、変換、読み込みジョブの最後に更新をトリガーするなど)は、手動更新を使用します。
手動で更新する場合は、
BQ.REFRESH_EXTERNAL_METADATA_CACHEシステム プロシージャを実行して、要件を満たすスケジュールでメタデータのキャッシュを更新します。パイプラインの出力など、既知の間隔で Amazon S3 内のファイルが追加、削除、変更される場合、キャッシュを手動で更新することをおすすめします。複数の手動更新を同時に発行しても、成功するのは 1 つだけです。
メタデータ キャッシュは、更新されなければ 7 日後に期限切れになります。
手動と自動のキャッシュ更新はどちらも、INTERACTIVE クエリの優先度で実行されます。
BACKGROUND 予約を使用する
自動更新を使用する場合は、予約を作成してから、メタデータ キャッシュ更新ジョブを実行するプロジェクトの BACKGROUND ジョブタイプの割り当てを作成することをおすすめします。BACKGROUND 予約を使用すると、更新ジョブは専用のリソースプールを使用するため、更新ジョブとユーザーのクエリによるリソースの競合を防ぎ、利用可能なリソースが十分でない場合にジョブが失敗するのを防ぐことができます。
共有スロットプールを使用すると追加費用は発生しませんが、代わりに BACKGROUND 予約を使用すると、専用のリソースプールが割り当てられ、パフォーマンスの安定性が向上します。また、更新ジョブの信頼性と BigQuery のクエリ全体の効率も向上します。
未更新間隔とメタデータ キャッシュ モードの値は、設定する前に、どのように相互作用するかを検討する必要があります。以下の例を考えてみましょう。
- テーブルのメタデータ キャッシュを手動で更新していて、未更新間隔を 2 日に設定した場合、キャッシュに保存されたメタデータを使用するテーブルのオペレーションを行うには 2 日以内の間隔で、
BQ.REFRESH_EXTERNAL_METADATA_CACHEシステム プロシージャを実行する必要があります。 - テーブルのメタデータ キャッシュを自動的に更新していて、未更新間隔を 30 分に設定した場合、メタデータ キャッシュのリフレッシュが通常の 30~60 分より長くかかると、テーブルに対する操作の一部が Amazon S3 から読み込まれる可能性があります。
メタデータ更新ジョブに関する情報を探すには、次の例に示すように INFORMATION_SCHEMA.JOBS ビューをクエリします。
SELECT * FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` WHERE job_id LIKE '%metadata_cache_refresh%' AND creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 HOUR) ORDER BY start_time DESC LIMIT 10;
詳細については、メタデータのキャッシュ保存をご覧ください。
キャッシュが有効なテーブルのマテリアライズド ビュー
Amazon Simple Storage Service(Amazon S3)メタデータ キャッシュが有効になっているテーブルのマテリアライズド ビューを使用すると、Amazon S3 に保存されている構造化データをクエリする際のパフォーマンスと効率性を向上させることができます。これらのマテリアライズド ビューは、BigQuery マネージド ストレージ テーブルに対するマテリアライズド ビューと同様に、自動更新とスマート チューニングの便益を含めて、機能します。
マテリアライズド ビューの Amazon S3 データをサポート対象の BigQuery リージョンで結合に使用できるようにするには、マテリアライズド ビューのレプリカを作成します。マテリアライズド ビューのレプリカは、承認済みマテリアル ビューにのみ作成できます。
制限事項
BigLake テーブルの制限事項に加えて、BigQuery Omni には以下の制限が適用されます。これには、Amazon S3 と Blob Storage のデータに基づく BigLake テーブルが含まれます。
- Standard エディションと Enterprise Plus エディションでは、BigQuery Omni リージョンのデータの操作はサポートされていません。エディションの詳細については、BigQuery エディションの概要をご覧ください。
OBJECT_PRIVILEGES、STREAMING_TIMELINE_BY_*、TABLE_SNAPSHOTS、TABLE_STORAGE、TABLE_CONSTRAINTS、KEY_COLUMN_USAGE、CONSTRAINT_COLUMN_USAGE、PARTITIONSのINFORMATION_SCHEMAビューは、Amazon S3 と Blob Storage のデータに基づく BigLake テーブルでは使用できません。- Blob Storage では、マテリアライズド ビューはサポートされていません。
- JavaScript UDF はサポートされていません。
次の SQL ステートメントはサポートされていません。
- BigQuery ML ステートメント。
- BigQuery で管理されるデータを必要とするデータ定義言語(DDL)ステートメント。たとえば、
CREATE EXTERNAL TABLE、CREATE SCHEMA、CREATE RESERVATIONはサポートされていますが、CREATE TABLEはサポートされていません。 - データ操作言語(DML)ステートメント。
宛先の一時テーブルのクエリと読み取りには、次の制限が適用されます。
SELECTステートメントを使用した宛先一時テーブルのクエリはサポートされていません。
スケジュールされたクエリは、API または CLI メソッドを通じてのみサポートされています。宛先テーブルのオプションはクエリでは無効になっています。
EXPORT DATAクエリのみが許可されています。BigQuery Storage API は、BigQuery Omni リージョンでは使用できません。
クエリで
ORDER BY句を使用しており、結果のサイズが 256 MB を超える場合、クエリは失敗します。この問題を解決するには、結果のサイズを小さくするか、クエリからORDER BY句を削除します。BigQuery Omni の割り当ての詳細については、割り当てと上限をご覧ください。データセットと外部テーブルでは、顧客管理の暗号鍵(CMEK)はサポートされていません。
料金
BigQuery Omni の料金と期間限定特典については、BigQuery Omni の料金をご覧ください。
割り当てと上限
BigQuery Omni の割り当てについては、割り当てと上限をご覧ください。
クエリ結果が 20 GiB より大きい場合は、結果を Amazon S3 または Blob Storage にエクスポートすることを検討してください。BigQuery Connection API の割り当てについては、BigQuery Connection API をご覧ください。
ロケーション
BigQuery Omni は、クエリを実行するテーブルを含むデータセットと同じロケーションでクエリを処理します。データセットを作成した後で、そのロケーションを変更することはできません。データは AWS アカウントまたは Azure アカウント内に存在します。BigQuery Omni リージョンでは、Enterprise エディションの予約とオンデマンド コンピューティング(分析)の料金がサポートされています。エディションの詳細については、BigQuery エディションの概要をご覧ください。
| リージョンの説明 | リージョン名 | 同じロケーションに配置された BigQuery リージョン | |
|---|---|---|---|
| AWS | |||
| AWS - US East(北バージニア) | aws-us-east-1 |
us-east4 |
|
| AWS 米国西部(オレゴン) | aws-us-west-2 |
us-west1 |
|
| AWS - アジア太平洋(ソウル) | aws-ap-northeast-2 |
asia-northeast3 |
|
| AWS - アジア太平洋(シドニー) | aws-ap-southeast-2 |
australia-southeast1 |
|
| AWS - ヨーロッパ(アイルランド) | aws-eu-west-1 |
europe-west1 |
|
| AWS - ヨーロッパ(フランクフルト) | aws-eu-central-1 |
europe-west3 |
|
| Azure | |||
| Azure - East US 2 | azure-eastus2 |
us-east4 |
|
次のステップ
- Amazon S3 への接続と Blob Storage への接続の方法を確認する。
- Amazon S3 と Blob Storage の BigLake テーブルの作成方法を学習する。
- Amazon S3 と Blob Storage の BigLake テーブルに対してクエリを実行する方法を学習する。
- クロスクラウド結合を使用して、Amazon S3 と Blob Storage の BigLake テーブルを Google Cloud テーブルと結合する方法を学習する。
- Amazon S3 にクエリ結果をエクスポートする方法と Blob Storage にクエリ結果をエクスポートする方法を確認する。
- Amazon S3 からデータを転送する方法と Blob Storage から BigQuery にデータを転送する方法を確認する。
- VPC Service Controls の境界を設定する方法を確認する。
- ロケーションを指定する方法を確認する。