クエリのスケジューリング
このページでは、BigQuery で定期的なクエリをスケジュールする方法について説明します。
クエリを定期的に実行するようにスケジュールできます。スケジュールされたクエリは、GoogleSQL で作成する必要があります。GoogleSQL で作成するクエリには、データ定義言語(DDL)、データ操作言語(DML)によるステートメントを含めることができます。クエリ文字列と宛先テーブルはパラメータ化が可能で、クエリ結果を日付と時刻で整理できます。
クエリのスケジュールを作成または更新すると、クエリのスケジュールされた時間は、ローカル時間から UTC に変換されます。UTC は夏時間の影響を受けません。
始める前に
- スケジュールされたクエリは、BigQuery Data Transfer Service の機能を使用します。BigQuery Data Transfer Service を有効にするために必要なすべての操作が完了していることを確認します。
- このドキュメントの各タスクを実行するために必要な権限をユーザーに与える Identity and Access Management(IAM)のロールを付与します。
- 顧客管理の暗号鍵(CMEK)を指定する場合は、以下を確認してください。サービス アカウントに暗号化および復号する権限があることと、CMEK を使用するのに必要な Cloud KMS 鍵のリソース ID があること。CMEK が BigQuery Data Transfer Service と連携する仕組みについては、スケジュールされたクエリで暗号鍵を指定するをご覧ください。
必要な権限
クエリのスケジュールを設定するには、次の IAM 権限が必要です。
転送を作成するには、
bigquery.transfers.update、bigquery.datasets.getの権限か、bigquery.jobs.create、bigquery.transfers.get、bigquery.datasets.getの権限が必要です。スケジュールされたクエリを実行するには、次のものが必要です。
bigquery.datasets.get(抽出先データセットに対する権限)bigquery.jobs.create
スケジュールされたクエリを変更または削除するには、bigquery.transfers.update および bigquery.transfers.get 権限か、bigquery.jobs.create 権限とスケジュールされたクエリに対するオーナー権限が必要です。
IAM 事前定義ロールの BigQuery 管理者(roles/bigquery.admin)には、クエリをスケジュールまたは変更するために必要な権限が含まれています。
BigQuery での IAM のロールの詳細については、事前定義ロールと権限をご覧ください。
サービス アカウントによって実行されるスケジュール設定済みのクエリを作成または更新するには、そのサービス アカウントへのアクセス権が必要です。ユーザーにサービス アカウントのロールを付与する方法については、サービス アカウントのユーザーロールをご覧ください。Google Cloud コンソールのスケジュールされたクエリ UI でサービス アカウントを選択するには、次の IAM 権限が必要です。
iam.serviceAccounts.listは、サービス アカウントを一覧表示します。iam.serviceAccountUser: サービス アカウントをスケジュールされたクエリに割り当てます。
構成オプション
以下のセクションでは、構成オプションについて説明します。
クエリ文字列
クエリ文字列は、GoogleSQL で記述された有効なものでなければなりません。スケジュールされたクエリは、実行のたびに以下のクエリ パラメータを受け取ることができます。
クエリをスケジュールする前に @run_time パラメータと @run_date パラメータを使用してクエリ文字列を手動でテストするには、bq コマンドライン ツールを使用します。
利用可能なパラメータ
| パラメータ | GoogleSQL の型 | 値 |
|---|---|---|
@run_time |
TIMESTAMP |
UTC 時間で表されます。定期的に実行するようスケジュールされたクエリの場合、run_time は実行予定時刻を表します。たとえば、スケジュールされたクエリが「24 時間ごと」に設定されている場合、実際の実行時間が多少異なる場合でも、連続する 2 つのクエリ間の run_time の差は、ちょうど 24 時間になります。 |
@run_date |
DATE |
論理カレンダー日を表します。 |
例
この例の @run_time パラメータはクエリ文字列の一部であり、hacker_news.stories という名前の一般公開データセットに対してクエリを実行します。
SELECT @run_time AS time, title, author, text FROM `bigquery-public-data.hacker_news.stories` LIMIT 1000
宛先テーブル
スケジュールされたクエリの設定時に結果の宛先テーブルが存在しない場合は、BigQuery によってテーブルが作成されます。
DDL または DML クエリを使用している場合は、 Google Cloud コンソールで [処理を行うロケーション] またはリージョンを選択します。処理を行うロケーションは、宛先テーブルを作成する DDL または DML クエリに必要です。
宛先テーブルが存在し、WRITE_APPEND 書き込み設定を使用している場合、BigQuery はデータを宛先テーブルに追加し、スキーマのマッピングを試みます。BigQuery は、フィールドの追加と並べ替えを自動的に許可し、足りないオプション フィールドを受け入れます。実行間でテーブル スキーマが大きく変更され、BigQuery がその変更を自動的に処理できない場合、スケジュールされたクエリは失敗します。
クエリは、さまざまなプロジェクトやデータセットからテーブルを参照できます。スケジュールされたクエリを構成するときは、テーブル名に宛先データセットを含める必要はありません。宛先データセットは別に指定します。
スケジュール設定されたクエリの宛先データセットとテーブルは、スケジュール設定されたクエリと同じプロジェクト内に存在する必要があります。
書き込み設定
選択した書き込み設定によって、クエリ結果が既存の宛先テーブルに書き込まれる方法が決まります。
WRITE_TRUNCATE: テーブルが存在する場合、BigQuery によってテーブルのデータが上書きされます。WRITE_APPEND: テーブルが存在する場合、BigQuery によってデータがテーブルに追加されます。
DDL または DML クエリを使用している場合は、書き込み設定オプションを使用できません。
BigQuery がクエリを正常に完了できる場合にのみ、宛先テーブルの作成、切り捨て、追加が行われます。作成、切り捨て、追加アクションは、ジョブ完了時に 1 つのアトミック更新として発生します。
クラスタリング
スケジュールされたクエリは、DDL CREATE TABLE AS SELECT ステートメントでテーブルが作成された場合にのみ、新しいテーブルでクラスタリングを作成できます。データ定義言語ステートメントの使用ページのクエリ結果からクラスタ化テーブルを作成するをご覧ください。
パーティショニングのオプション
スケジュールされたクエリでは、分割または非分割の宛先テーブルを作成できます。パーティショニングは、 Google Cloud コンソール、bq コマンドライン ツール、API 設定メソッドで使用できます。パーティショニングで DDL または DML クエリを使用する場合は、[Destination table partitioning field] を空白のままにします。
BigQuery では、次のタイプのテーブル パーティショニングを使用できます。
- 整数範囲パーティショニング: 特定の
INTEGER列の値の範囲に基づいてパーティション分割されたテーブル。 - 時間単位列パーティショニング:
TIMESTAMP、DATE、またはDATETIME列に基づいてパーティション分割されたテーブル。 - 取り込み時間パーティショニング: 取り込み時間でパーティション分割されたテーブル。BigQuery は、BigQuery がデータを取り込む時間に基づいて、パーティションに自動的に行を割り当てます。
Google Cloud コンソールでスケジュールされたクエリを使用してパーティション分割テーブルを作成するには、次のオプションを使用します。
整数範囲パーティショニングを使用するには、[宛先テーブルのパーティショニング フィールド] を空白のままにします。
時間単位列パーティショニングを使用するには、スケジュールされたクエリを設定するときに、[宛先テーブルのパーティショニング フィールド] に列名を指定します。
取り込み時間パーティショニングを使用するには、[宛先テーブルのパーティショニング フィールド] を空白のままにして、宛先テーブルの名前で日付パーティショニングを指定します。例:
mytable${run_date}詳細については、パラメータ テンプレートの構文をご覧ください。
利用可能なパラメータ
スケジュールされたクエリを設定するときに、ランタイム パラメータを使用して宛先テーブルをどのように分割するかを指定できます。
| パラメータ | テンプレートの種類 | 値 |
|---|---|---|
run_time |
フォーマットされたタイムスタンプ | スケジュールごとに UTC 時間で設定されます。定期的に実行するようスケジュールされたクエリの場合、run_time は実行予定時刻を表します。たとえば、スケジュールされたクエリが「24 時間ごと」に設定されている場合、実際の実行時間が多少異なる場合でも、連続する 2 つのクエリ間の run_time の差は、ちょうど 24 時間になります。TransferRun.runTime をご覧ください。 |
run_date |
日付文字列 | %Y-%m-%d の形式の run_time パラメータの日付(たとえば、2018-01-01)。この形式は、取り込み時間分割テーブルと互換性があります。 |
テンプレート システム
スケジュールされたクエリは、テンプレート構文で宛先テーブル名におけるランタイム パラメータをサポートします。
パラメータ テンプレート構文
テンプレート構文は、基本的な文字列のテンプレートと時間オフセットをサポートします。パラメータは、次の形式で参照されます。
{run_date}{run_time[+\-offset]|"time_format"}
| パラメータ | 目的 |
|---|---|
run_date |
このパラメータは、YYYYMMDD 形式の日付に置き換えられます。 |
run_time |
このパラメータは、次のプロパティをサポートします。
|
- run_time、offset、time 形式の間に空白文字は使用できません。
- 文字列にリテラル中かっこを含めるには、
'\{' and '\}'としてエスケープできます。 - time_format に
"YYYY|MM|DD"などのリテラル引用符や縦線を含めるには、'\"'や'\|'のフォーマット文字列でエスケープします。
パラメータ テンプレートの例
以下の例は、時刻形式が異なる宛先テーブル名を指定して、実行時間をオフセットする方法を示しています。| run_time(UTC) | テンプレート パラメータ | 出力宛先テーブル名 |
|---|---|---|
| 2018-02-15 00:00:00 | mytable |
mytable |
| 2018-02-15 00:00:00 | mytable_{run_time|"%Y%m%d"} |
mytable_20180215 |
| 2018-02-15 00:00:00 | mytable_{run_time+25h|"%Y%m%d"} |
mytable_20180216 |
| 2018-02-15 00:00:00 | mytable_{run_time-1h|"%Y%m%d"} |
mytable_20180214 |
| 2018-02-15 00:00:00 | mytable_{run_time+1.5h|"%Y%m%d%H"}
または mytable_{run_time+90m|"%Y%m%d%H"} |
mytable_2018021501 |
| 2018-02-15 00:00:00 | {run_time+97s|"%Y%m%d"}_mytable_{run_time+97s|"%H%M%S"} |
20180215_mytable_000137 |
サービス アカウントの使用
サービス アカウントとして認証を行うために、スケジュールされたクエリを設定できます。サービス アカウントとは、 Google Cloud プロジェクトに関連付けられた特別なアカウントです。サービス アカウントは、エンドユーザーの認証情報ではなく、独自のサービス認証情報に関連付けられたジョブを実行できます。たとえば、バッチ処理パイプライン、スケジュールされたクエリなどを実行できます。
サービス アカウントの認証の詳細については、認証の概要をご覧ください。
サービス アカウントを使用して、スケジュールされたクエリを設定できます。フェデレーション ID でログインした場合、転送を作成するにはサービス アカウントが必要です。Google アカウントでログインした場合、転送用のサービス アカウントは省略可能です。
bq コマンドライン ツールまたは Google Cloud コンソールを使用して、サービス アカウントの認証情報で既存のスケジュールされたクエリを更新できます。詳細については、スケジュールされたクエリの認証情報を更新するをご覧ください。
スケジュールされたクエリで暗号鍵を指定する
転送実行のデータを暗号化する顧客管理の暗号鍵(CMEK)を指定できます。CMEK を使用して、スケジュールされたクエリからの転送をサポートできます。転送で CMEK を指定すると、BigQuery Data Transfer Service は取り込まれたデータの中間ディスク上キャッシュに CMEK を適用して、データ転送ワークフロー全体が CMEK 遵守になるようにします。
最初に CMEK で作成されていなかった既存の転送は、更新して CMEK を追加することはできません。たとえば、最初にデフォルトの方法で暗号化されていた宛先テーブルを CMEK で暗号化されるように変更することはできません。逆に、CMEK で暗号化された宛先テーブルを別のタイプの暗号化に変更することはできません。
転送構成が CMEK 暗号化を使用して最初に作成された場合は、転送の CMEK を更新できます。転送構成の CMEK を更新すると、BigQuery Data Transfer Service は転送の次回実行時に CMEK を宛先テーブルに伝播します。BigQuery Data Transfer Service は、古い CMEK を転送中に新しい CMEK に置き換えます。詳細については、転送の更新をご覧ください。
プロジェクトのデフォルト鍵を使用することもできます。転送でプロジェクトのデフォルト鍵を指定すると、BigQuery Data Transfer Service は、新しい転送構成のデフォルト鍵としてプロジェクトのデフォルト鍵を使用します。
スケジュールされたクエリを設定する
スケジュールの構文の説明については、schedule の書式をご覧ください。スケジュールの構文の詳細については、リソース: TransferConfig をご覧ください。
コンソール
Google Cloud コンソールで [BigQuery] ページを開きます。
関心のあるクエリを実行します。結果に問題がなければ、[スケジュール] をクリックします。
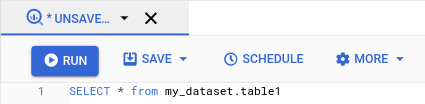
スケジュールされたクエリのオプションが [新たにスケジュールされたクエリ] ペインに表示されます。
![[新たにスケジュールされたクエリ] ペイン。](https://cloud.google.com/static/bigquery/images/new-scheduled-query-top-console.png?hl=ja)
[新たにスケジュールされたクエリ] ペインで次の操作を行います。
- [スケジュールされたクエリの名前] に、クエリの名前(
My scheduled queryなど)を入力します。スケジュールされたクエリの名前は、後でクエリの変更が必要になった場合に識別できる任意の名前にできます。 (省略可)デフォルトでのクエリは、毎日実行されるようにスケジュールされます。デフォルトのスケジュールを変更するには、[繰り返し] プルダウン メニューからオプションを選択します。
カスタム頻度を指定するには、[カスタム] を選択し、[カスタム スケジュール] に Cron と同様の時間指定を入力します(例:
every mon 23:30、every 6 hours)。カスタム間隔などの有効なスケジュールの詳細については、リソース:TransferConfigのscheduleフィールドをご覧ください。
開始時間を変更するには、[設定時間に開始する] オプションを選択し、目的の開始日時を入力します。
終了時刻を指定するには、[終了時刻を設定] オプションを選択し、目的の終了日時を入力します。
クエリをスケジュールなしで保存して、後でオンデマンドで実行できるようにするには、[繰り返しの頻度] メニューで [オンデマンド] を選択します。
- [スケジュールされたクエリの名前] に、クエリの名前(
GoogleSQL
SELECTクエリを使用する場合は、[クエリ結果の宛先テーブルを設定する] オプションを選択し、宛先データセットに関する次の情報を入力します。- [データセット名] で、適切な宛先データセットを選択します。
- [テーブル名] に、宛先テーブルの名前を入力します。
[宛先テーブルの書き込み設定] で、[テーブルに追加する] を選択してデータをテーブルに追加するか、[テーブルを上書きする] を選択して宛先テーブルを上書きします。

[ロケーション タイプ] を選択します。
クエリ結果の宛先テーブルを有効にしている場合は、[自動ロケーション選択] を選択して、宛先テーブルが存在するロケーションを自動的に選択できます。
ない場合は、クエリ対象のデータが配置されているロケーションを選択します。
詳細オプション:
(省略可)CMEK: 顧客管理の暗号鍵を使用する場合は、[詳細オプション] で [顧客管理の暗号鍵] を選択します。使用可能な CMEK のリストが表示され、ここから選択できます。顧客管理の暗号鍵(CMEK)が BigQuery Data Transfer Service と連携する仕組みについては、スケジュールされたクエリで暗号鍵を指定するをご覧ください。
サービス アカウントとして認証: Google Cloud プロジェクトに 1 つ以上のサービス アカウントが関連付けられている場合は、ユーザーの認証情報を使用する代わりに、スケジュールされたクエリをサービス アカウントに関連付けることができます。[スケジュールされたクエリの認証情報] でメニューをクリックすると、利用可能なサービス アカウントの一覧が表示されます。フェデレーション ID でログインしている場合は、サービス アカウントが必要です。

その他の構成:
(省略可)[メール通知を送信する] をオンにして、転送実行失敗のメール通知を許可します。
(省略可)[Pub/Sub トピック] に、Pub/Sub トピックの名前(例:
projects/myproject/topics/mytopic)を入力します。
[保存] をクリックします。
bq
オプション 1: bq query コマンドを使用する。
スケジュールされたクエリを作成するには、オプション destination_table(または target_dataset)、--schedule、--display_name を bq query コマンドに追加します。
bq query \ --display_name=name \ --destination_table=table \ --schedule=interval
以下を置き換えます。
name。スケジュールされたクエリの表示名。表示名は、後でクエリの変更が必要になった場合に識別できる任意の名前にすることができます。table。クエリ結果の宛先テーブル。--target_datasetは、DDL および DML クエリで使用される場合に、クエリ結果のターゲット データセットに名前を付ける代替の方法です。--destination_tableと--target_datasetのいずれかを使用します。両方を使用することはできません。
interval。bq queryと使用すると、クエリを定期的に実行するようスケジュールできます。クエリを実行する頻度を指定する必要があります。カスタム間隔などの有効なスケジュールの詳細については、リソース:TransferConfigのscheduleフィールドをご覧ください。例:--schedule='every 24 hours'--schedule='every 3 hours'--schedule='every monday 09:00'--schedule='1st sunday of sep,oct,nov 00:00'
オプションのフラグ:
--project_idはプロジェクト ID です。--project_idを指定しない場合は、デフォルトのプロジェクトが使用されます。--replaceは、スケジュールされたクエリの実行後に、宛先テーブルをクエリ結果で上書きします。既存のデータはすべて消去されます。パーティション分割されていないテーブルの場合、スキーマも消去されます。--append_tableは、結果を宛先テーブルに追加します。DDL クエリと DML クエリの場合、
--locationフラグを指定して、処理する特定のリージョンを指定することもできます。--locationが指定されていない場合は、最も近い Google Cloud ロケーションが使用されます。
たとえば、次のコマンドはクエリ SELECT 1 from mydataset.test を使用して、My Scheduled Query という名前のスケジュールされたクエリを作成します。宛先テーブルは、mydataset データセットの mytable です。スケジュールされたクエリは、デフォルトのプロジェクトで作成されます。
bq query \
--use_legacy_sql=false \
--destination_table=mydataset.mytable \
--display_name='My Scheduled Query' \
--schedule='every 24 hours' \
--replace=true \
'SELECT
1
FROM
mydataset.test'
オプション 2: bq mk コマンドを使用する。
スケジュールされたクエリは一種の転送です。クエリをスケジュールするには、bq コマンドライン ツールを使用して転送構成を作成します。
クエリをスケジュールするには、標準 SQL 言語にする必要があります。
bq mk コマンドを入力し、次の必須フラグを指定します。
--transfer_config--data_source--target_dataset(DDL および DML クエリでは省略可能)--display_name--params
オプションのフラグ:
--project_idはプロジェクト ID です。--project_idを指定しない場合は、デフォルトのプロジェクトが使用されます。--scheduleは、クエリを実行する頻度です。--scheduleが指定されていない場合、デフォルトでは「24 時間ごと」に作成されます。DDL クエリと DML クエリの場合、
--locationフラグを指定して、処理する特定のリージョンを指定することもできます。--locationが指定されていない場合は、最も近い Google Cloud ロケーションが使用されます。--service_account_nameは、個々のユーザー アカウントではなく、サービス アカウントを使用してスケジュールされたクエリの認証を行う場合に使用します。--destination_kms_keyでは、この転送に顧客管理の暗号鍵(CMEK)を使用する場合、その鍵の鍵のリソース ID を指定します。CMEK が BigQuery Data Transfer Service でどのように機能するかについては、スケジュールされたクエリで暗号鍵を指定するをご覧ください。
bq mk \ --transfer_config \ --target_dataset=dataset \ --display_name=name \ --params='parameters' \ --data_source=data_source
次のように置き換えます。
dataset。転送構成のターゲット データセット。- このパラメータは、DDL クエリと DML クエリでは省略可能です。他のすべてのクエリに必要です。
name。転送構成の表示名。表示名は、後でクエリの変更が必要になった場合に識別できる任意の名前にすることができます。parametersには、作成される転送構成のパラメータを JSON 形式で指定します。例:--params='{"param":"param_value"}'。- スケジュールされたクエリでは、
queryパラメータを指定する必要があります。 destination_table_name_templateパラメータは、宛先テーブルの名前です。- このパラメータは、DDL クエリと DML クエリでは省略可能です。他のすべてのクエリに必要です。
write_dispositionパラメータには、宛先テーブルを切り詰める(上書きする)WRITE_TRUNCATE、または宛先テーブルにクエリ結果を追加するWRITE_APPENDを選択します。- このパラメータは、DDL クエリと DML クエリでは省略可能です。他のすべてのクエリに必要です。
- スケジュールされたクエリでは、
data_source。データソース:scheduled_query。- (省略可)
--service_account_nameパラメータは、個々のユーザー アカウントではなく、サービス アカウントで認証を行う場合に使用します。 - (省略可)
--destination_kms_keyには、Cloud KMS 鍵の鍵リソース ID を指定します(例:projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name)。
たとえば、次のコマンドは、クエリ SELECT 1
from mydataset.test を使用して、My Scheduled Query という名前のスケジュールされたクエリ転送構成を作成します。宛先テーブル mytable は書き込みごとに切り詰められます。抽出先データセットは mydataset です。スケジュールされたクエリはデフォルト プロジェクトに作成され、サービス アカウントとして認証されます。
bq mk \
--transfer_config \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}' \
--data_source=scheduled_query \
--service_account_name=abcdef-test-sa@abcdef-test.
コマンドの初回実行時に、次のようなメッセージが表示されます。
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
メッセージの指示に従って、認証コードをコマンドラインに貼り付けます。
API
projects.locations.transferConfigs.create メソッドを使用して、TransferConfig リソースのインスタンスを指定します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
サービス アカウントを使用してスケジュールされたクエリを設定する
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
スケジュールされたクエリのステータスを表示する
コンソール
スケジュールされたクエリのステータスを確認するには、ナビゲーション メニューで [スケジュール設定] をクリックし、[スケジュールされたクエリ] でフィルタします。詳細を確認するには、スケジュールされたクエリをクリックします。
bq
スケジュールされたクエリは一種の転送です。スケジュールされたクエリの詳細を表示するには、まず bq コマンドライン ツールを使用して転送構成を一覧表示します。
bq ls コマンドを入力して、転送フラグ --transfer_config を指定します。次のフラグも必要です。
--transfer_location
例:
bq ls \
--transfer_config \
--transfer_location=us
単一のスケジュールされたクエリの詳細を表示するには、bq show コマンドを入力し、そのスケジュールされたクエリまたは転送構成の transfer_path を指定します。
例:
bq show \
--transfer_config \
projects/862514376110/locations/us/transferConfigs/5dd12f26-0000-262f-bc38-089e0820fe38
API
projects.locations.transferConfigs.list メソッドを使用して、TransferConfig リソースのインスタンスを指定します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
スケジュールされたクエリを更新する
Console
スケジュールされたクエリを更新するには、次の手順を行います。
- ナビゲーション メニューで、[スケジュールされたクエリ] または [スケジュール設定] をクリックします。
- スケジュールされたクエリのリストで、変更するクエリの名前をクリックします。
- [スケジュールされたクエリの詳細] ページが表示されたら、[編集] をクリックします。
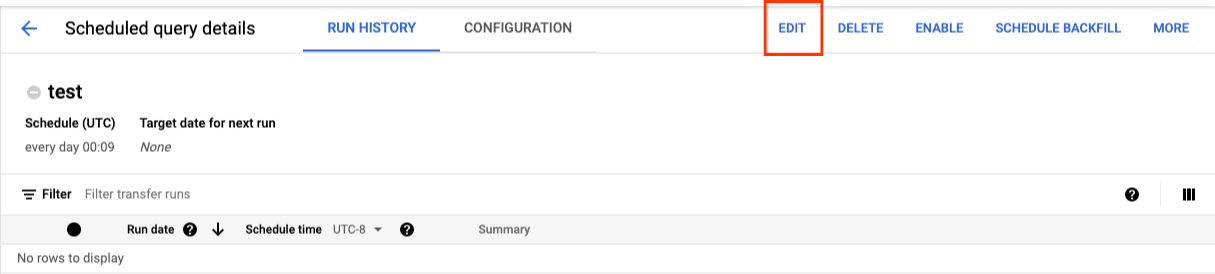
- (省略可)クエリ編集ペインでクエリテキストを変更します。
- [スケジュールされたクエリ] をクリックし、[スケジュールされたクエリを更新] を選択します。
- (省略可)クエリの他のスケジュール オプションを変更します。
- [更新] をクリックします。
bq
スケジュールされたクエリは一種の転送です。スケジュール設定されたクエリを更新するには、bq コマンドライン ツールを使用して転送構成を作成します。
必要な --transfer_config フラグを指定して bq update コマンドを入力します。
オプションのフラグ:
--project_idはプロジェクト ID です。--project_idを指定しない場合は、デフォルトのプロジェクトが使用されます。--scheduleは、クエリを実行する頻度です。--scheduleが指定されていない場合、デフォルトでは「24 時間ごと」に作成されます。--service_account_nameは、--update_credentialsも設定されている場合にのみ有効になります。詳細については、スケジュールされたクエリの認証情報を更新するをご覧ください。--target_dataset(DDL および DML クエリで省略可)は、DDL および DML クエリで使用される場合に、クエリ結果のターゲット データセットに名前を付ける代替の方法です。--display_nameは、スケジュールされたクエリの名前です。--paramsには、作成される転送構成のパラメータを JSON 形式で指定します。例: --params='{"param":"param_value"}'.--destination_kms_keyでは、この転送に顧客管理の暗号鍵(CMEK)を使用する場合、Cloud KMS 鍵の鍵のリソース ID を指定します。顧客管理の暗号鍵(CMEK)が BigQuery Data Transfer Service と連携する仕組みについては、スケジュールされたクエリで暗号鍵を指定するをご覧ください。
bq update \ --target_dataset=dataset \ --display_name=name \ --params='parameters' --transfer_config \ RESOURCE_NAME
次のように置き換えます。
dataset。転送構成のターゲット データセット。 このパラメータは、DDL クエリと DML クエリでは省略可能です。他のすべてのクエリに必要です。name。転送構成の表示名。表示名は、後でクエリの変更が必要になった場合に識別できる任意の名前にすることができます。parametersには、作成される転送構成のパラメータを JSON 形式で指定します。例:--params='{"param":"param_value"}'。- スケジュールされたクエリでは、
queryパラメータを指定する必要があります。 destination_table_name_templateパラメータは、宛先テーブルの名前です。このパラメータは、DDL クエリと DML クエリでは省略可能です。他のすべてのクエリに必要です。write_dispositionパラメータには、宛先テーブルを切り詰める(上書きする)WRITE_TRUNCATE、または宛先テーブルにクエリ結果を追加するWRITE_APPENDを選択します。このパラメータは、DDL クエリと DML クエリでは省略可能です。他のすべてのクエリに必要です。
- スケジュールされたクエリでは、
- (省略可)
--destination_kms_keyには、Cloud KMS 鍵の鍵リソース ID を指定します(例:projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name)。 RESOURCE_NAME: 転送のリソース名(転送構成とも呼ばれます)。転送のリソース名がわからない場合は、bq ls --transfer_config --transfer_location=locationを使用してリソース名を探します。
たとえば、次のコマンドは、クエリ SELECT 1
from mydataset.test を使用して、My Scheduled Query という名前のスケジュールされたクエリ転送構成を更新します。宛先テーブル mytable は書き込みごとに切り詰められます。抽出先データセットは mydataset です。
bq update \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}'
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
API
projects.transferConfigs.patch メソッドを使用して、transferConfig.name パラメータで転送のリソース名を指定します。転送のリソース名が不明の場合は、bq ls --transfer_config --transfer_location=location コマンドを発行してすべての転送を一覧表示するか、projects.locations.transferConfigs.list メソッドを呼び出して、parent パラメータでプロジェクト ID を指定します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
所有権制限のあるスケジュールされたクエリを更新する
所有していないスケジュールされたクエリを更新しようとすると、更新が失敗し、次のエラー メッセージが表示されることがあります。
Cannot modify restricted parameters without taking ownership of the transfer configuration.
スケジュールされたクエリのオーナーは、スケジュールされたクエリに関連付けられているユーザー、またはスケジュールされたクエリに関連付けられているサービス アカウントへのアクセス権を持つユーザーです。関連付けられたユーザーは、スケジュールされたクエリの構成の詳細で確認できます。スケジュールされたクエリを更新して所有権を取得する方法については、スケジュールされたクエリの認証情報を更新するをご覧ください。ユーザーにサービス アカウントへのアクセス権を付与するには、サービス アカウント ユーザーロールが必要です。
スケジュールされたクエリの所有者制限付きパラメータは次のとおりです。
- クエリテキスト
- 宛先データセット
- 宛先テーブル名のテンプレート
スケジュールされたクエリの認証情報を更新する
既存のクエリをスケジュールする場合は、クエリのユーザー認証情報の更新が必要になることがあります。新たにスケジュールされたクエリでは、認証情報が自動的に最新の状態になります。
認証情報の更新が必要になる可能性がある状況としては、次のようなものがあります。
- スケジュールされたクエリで Google ドライブデータをクエリする。
クエリをスケジュールしようとすると、INVALID_USER エラーが発生する。
Error code 5 : Authentication failure: User Id not found. Error code: INVALID_USERIDクエリを更新しようとすると、次の制限付きパラメータ エラーが発生します。
Cannot modify restricted parameters without taking ownership of the transfer configuration.
コンソール
スケジュールされたクエリの認証情報を更新するには:
[展開] ボタンをクリックして、[認証情報を更新] を選択します。
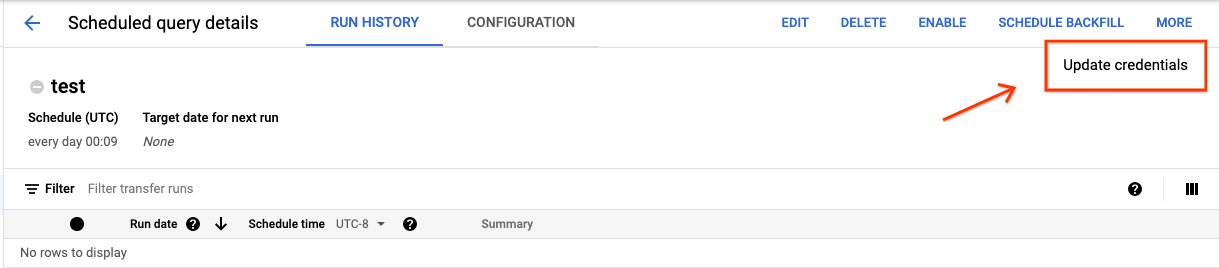
変更が有効になるまで 10~20 分かかります。ブラウザのキャッシュのクリアが必要になる場合もあります。
bq
スケジュールされたクエリは一種の転送です。スケジュールされたクエリの認証情報を更新するには、bq コマンドライン ツールを使用して転送構成を更新します。
bq update コマンドを入力して、転送フラグ --transfer_config を指定します。次のフラグも必要です。
--update_credentials
オプション フラグ:
--service_account_nameは、個々のユーザー アカウントではなく、サービス アカウントを使用してスケジュールされたクエリの認証を行う場合に使用します。
たとえば、次のコマンドは、サービス アカウントとして認証を行うように、スケジュールされたクエリの転送構成を更新します。
bq update \
--update_credentials \
--service_account_name=abcdef-test-sa@abcdef-test. \
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
過去の日付に基づく手動実行を設定する
今後実行するクエリをスケジュールできるだけでなく、手動でクエリの即時実行をトリガーすることもできます。クエリで run_date パラメータを使用していて、前回の実行中に問題が発生した場合は、即時実行をトリガーする必要があります。
たとえば、毎日 09:00 に、抽出元テーブルに対して現在の日付と一致する行をクエリするとします。しかし、過去 3 日間、抽出元テーブルにデータが追加されていないことがわかりました。このような場合、指定した日付範囲内の過去のデータに対してクエリが実行されるように設定できます。このように設定したクエリは、スケジュールされたクエリで構成されている日付に対応する run_date と run_time のパラメータの組み合わせに従って実行されます。
スケジュールされたクエリを設定した後、過去の日付範囲を使用してクエリを実行する方法を以下に説明します。
コンソール
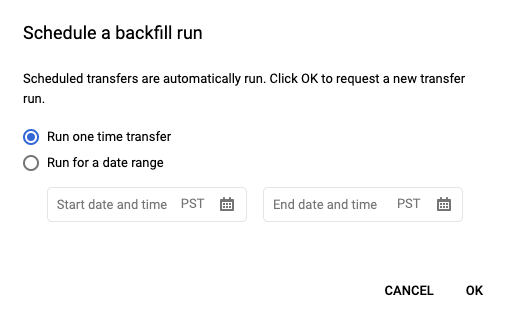
[スケジュール] をクリックしてスケジュールされたクエリを保存した後、[スケジュールされたクエリ] ボタンをクリックします。これにより、現在スケジュールされているクエリのリストが表示されます。表示名をクリックすると、そのクエリのスケジュールの詳細が表示されます。ページの右上にある [バックフィルをスケジュール] をクリックし、過去の日付範囲を指定します。
![[バックフィルをスケジュール] ボタン。](https://cloud.google.com/static/bigquery/images/scheduled-query-manual-run-button-console.png?hl=ja)
選択されている実行時間は、日付範囲として選択した開始日から終了日の前日まで適用されます。
例 1
スケジュールされたクエリは、太平洋時間の every day 09:00 に実行されるように設定されています。1 月 1 日、1 月 2 日、1 月 3 日のデータがありません。次のように過去の日付範囲を選択します。
Start Time = 1/1/19
End Time = 1/4/19
この場合、次の時間に対応する run_date パラメータと run_time パラメータを使用してクエリが実行されます。
- 2019 年 1 月 1 日の 09:00(太平洋時間)
- 2019 年 1 月 2 日の 09:00(太平洋時間)
- 2019 年 1 月 3 日の 09:00(太平洋時間)
例 2
スケジュールされたクエリは、太平洋時間の every day 23:00 に実行されるように設定されています。1 月 1 日、1 月 2 日、1 月 3 日のデータがありません。次のように過去の日付範囲を選択します(前の例よりも後の日付を選択している理由は、UTC では太平洋時間の 23:00 には日付が変わっているためです)。
Start Time = 1/2/19
End Time = 1/5/19
この場合、次の時間に対応する run_date パラメータと run_time パラメータを使用してクエリが実行されます。
- 2019 年 1 月 2 日の 06:00(UTC)、つまり太平洋時間での 2019 年 1 月 1 日の 23:00
- 2019 年 1 月 3 日の 06:00(UTC)、つまり太平洋時間での 2019 年 1 月 2 日の 23:00
- 2019 年 1 月 4 日の 06:00(UTC)、つまり太平洋時間での 2019 年 1 月 3 日の 23:00
手動実行を設定した後、ページを更新して、実行リストで手動実行を確認します。
bq
手動で過去の期間でクエリを実行するには:
bq mk コマンドを入力して、転送実行フラグ --transfer_run を指定します。次のフラグも必要です。
--start_time--end_time
bq mk \ --transfer_run \ --start_time='start_time' \ --end_time='end_time' \ resource_name
以下を置き換えます。
start_timeとend_time。 Z で終わるタイムスタンプ、または有効なタイムゾーンのオフセットを含むタイムスタンプ。例:- 2017-08-19T12:11:35.00Z
- 2017-05-25T00:00:00+00:00
resource_name。スケジュールされたクエリ(または転送)のリソース名。リソース名は、転送構成とも呼ばれます。
たとえば、コマンド projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7 は、スケジュールされたクエリリソース(または転送構成)のバックフィルをスケジュールします。
bq mk \
--transfer_run \
--start_time 2017-05-25T00:00:00Z \
--end_time 2017-05-25T00:00:00Z \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
詳細については、bq mk --transfer_run をご覧ください。
API
projects.locations.transferConfigs.scheduleRun メソッドを使用し、TransferConfig リソースのパスを指定します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
スケジュールされたクエリのアラートを設定する
行数指標に基づいて、スケジュールされたクエリのアラート ポリシーを構成できます。詳細については、スケジュールされたクエリでアラートを設定するをご覧ください。
スケジュールされたクエリを削除する
コンソール
Google Cloud コンソールの [スケジュールされたクエリ] ページでスケジュールされたクエリを削除するには、次の操作を行います。
- ナビゲーション メニューで [スケジュールされたクエリ] をクリックします。
- スケジュールされたクエリのリストで、削除するスケジュールされたクエリの名前をクリックします。
[スケジュールされたクエリの詳細] ページで、[削除] をクリックします。
![[スケジュールされたクエリ] ページでスケジュールされたクエリを削除します。](https://cloud.google.com/static/bigquery/images/delete-scheduled-query.png?hl=ja)
または、 Google Cloud コンソールの [スケジュール設定] ページでスケジュールされたクエリを削除することもできます。
- ナビゲーション メニューで [スケジュール設定] をクリックします。
- スケジュールされたクエリのリストで、削除するスケジュールされたクエリの [操作] メニューをクリックします。
[削除] を選択します。
![[スケジュール設定] ページでスケジュールされたクエリを削除します。](https://cloud.google.com/static/bigquery/images/delete-scheduled-query-scheduling-page.png?hl=ja)
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
スケジュールされたクエリを無効または有効にする
スケジュールを削除せずに、選択したクエリのスケジュールされた実行を一時停止するには、スケジュールを無効にします。
選択したクエリのスケジュールを無効にするには、次の操作を行います。
- Google Cloud コンソールのナビゲーション メニューで、[スケジュール] をクリックします。
- スケジュールされたクエリのリストで、無効にするスケジュールされたクエリの [操作] メニューをクリックします。
[無効にする] を選択します。
![[スケジュール設定] ページでスケジュールされたクエリを無効にします。](https://cloud.google.com/static/bigquery/images/disable-scheduled-query-scheduling-page.png?hl=ja)
無効になったスケジュールされたクエリを有効にするには、有効にするスケジュールされたクエリの [操作] メニューをクリックし、[有効にする] を選択します。
割り当て
スケジュールされたクエリは常にバッチ クエリジョブとして実行され、手動クエリと同じ BigQuery の割り当てと上限が適用されます。
スケジュールされたクエリは、BigQuery Data Transfer Service の機能を使用しますが、転送ではなく、読み込みジョブの割り当ての対象ではありません。
クエリの実行に使用される ID によって、適用される割り当てが決まります。これは、スケジュールされたクエリの構成によって異なります。
作成者の認証情報(デフォルト): サービス アカウントを指定しない場合、スケジュールされたクエリは、作成したユーザーの認証情報を使用して実行されます。クエリジョブは作成者のプロジェクトに課金され、そのユーザーとプロジェクトの割り当てが適用されます。
サービス アカウント認証情報: サービス アカウントを使用するようにスケジュールされたクエリを構成すると、サービス アカウントの認証情報を使用して実行されます。この場合、ジョブの料金はスケジュールされたクエリを含むプロジェクトに請求されますが、実行は指定されたサービス アカウントの割り当ての対象となります。
料金
スケジュールされたクエリは、手動の BigQuery クエリと同じ料金です。
サポートされるリージョン
スケジュールされたクエリは、次のロケーションでサポートされています。
リージョン
次の表は、BigQuery が利用可能な南北アメリカのリージョンを示したものです。| リージョンの説明 | リージョン名 | 詳細 |
|---|---|---|
| コロンバス(オハイオ州) | us-east5 |
|
| ダラス | us-south1 |
|
| アイオワ | us-central1 |
|
| ラスベガス | us-west4 |
|
| ロサンゼルス | us-west2 |
|
| メキシコ | northamerica-south1 |
|
| モントリオール | northamerica-northeast1 |
|
| バージニア州北部 | us-east4 |
|
| オレゴン | us-west1 |
|
| ソルトレイクシティ | us-west3 |
|
| サンパウロ | southamerica-east1 |
|
| サンチアゴ | southamerica-west1 |
|
| サウスカロライナ州 | us-east1 |
|
| トロント | northamerica-northeast2 |
|
| リージョンの説明 | リージョン名 | 詳細 |
|---|---|---|
| デリー | asia-south2 |
|
| 香港 | asia-east2 |
|
| ジャカルタ | asia-southeast2 |
|
| メルボルン | australia-southeast2 |
|
| ムンバイ | asia-south1 |
|
| 大阪 | asia-northeast2 |
|
| ソウル | asia-northeast3 |
|
| シンガポール | asia-southeast1 |
|
| シドニー | australia-southeast1 |
|
| 台湾 | asia-east1 |
|
| 東京 | asia-northeast1 |
| リージョンの説明 | リージョン名 | 詳細 |
|---|---|---|
| ベルギー | europe-west1 |
|
| ベルリン | europe-west10 |
|
| フィンランド | europe-north1 |
|
| フランクフルト | europe-west3 |
|
| ロンドン | europe-west2 |
|
| マドリッド | europe-southwest1 |
|
| ミラノ | europe-west8 |
|
| オランダ | europe-west4 |
|
| パリ | europe-west9 |
|
| ストックホルム | europe-north2 |
|
| トリノ | europe-west12 |
|
| ワルシャワ | europe-central2 |
|
| チューリッヒ | europe-west6 |
|
| リージョンの説明 | リージョン名 | 詳細 |
|---|---|---|
| ダンマーム | me-central2 |
|
| ドーハ | me-central1 |
|
| テルアビブ | me-west1 |
| リージョンの説明 | リージョン名 | 詳細 |
|---|---|---|
| ヨハネスブルグ | africa-south1 |
マルチリージョン
次の表は、BigQuery が利用可能なマルチリージョンを示しています。| マルチリージョンの説明 | マルチリージョン名 |
|---|---|
| 欧州連合の加盟国内のデータセンター1 | EU |
| 米国内のデータセンター2 | US |
1 EU マルチリージョン内のデータは、europe-west1(ベルギー)または europe-west4(オランダ)のいずれかのロケーションにのみ保存されます。データの保存と処理が行われる正確な場所は、BigQuery によって自動的に決定されます。
2 US マルチリージョン内のデータは、us-central1(アイオワ)、us-west1(オレゴン)、us-central2(オクラホマ)のいずれかのロケーションにのみ保存されます。データの保存と処理が行われる正確な場所は、BigQuery によって自動的に決定されます。
次のステップ
- サービス アカウントを使用し、
@run_dateパラメータと@run_timeパラメータを含むスケジュールされたクエリの例については、スケジュールされたクエリによるテーブル スナップショットの作成をご覧ください。