Panoramica sulla sicurezza e la governance dei dati
Che cos'è la governance dei dati?
Questo documento ti aiuta a comprendere il concetto di governance dei dati e quali controlli potresti aver bisogno per proteggere le risorse BigQuery.
Introduzione
La governance dei dati è un approccio basato su principio per gestire i dati durante il suo ciclo di vita, dall'acquisizione all'uso, fino allo smaltimento. Il tuo programma di governance dei dati definisce chiaramente criteri, procedure, responsabilità e controlli sulle attività relative ai dati. Questo programma garantisce che le informazioni vengano raccolte, gestite, utilizzate e diffuse in modo da soddisfare le esigenze di integrità e sicurezza dei dati della tua organizzazione. Inoltre, queste risorse consentono ai tuoi dipendenti di scoprire e utilizzare al meglio i dati.
Da quando i dati vengono importati a quando possono essere utilizzati per ottenere informazioni e informazioni preziose, la gestione e la governance dei dati devono essere considerate con la massima importanza per qualsiasi organizzazione.
Ti consigliamo di creare una pratica di governance dei dati incentrata su tre componenti chiave:
- Un framework che consente alle persone di definire, accettare e applicare in modo forzato i criteri dei dati.
- Processi efficaci per il controllo, la supervisione e la gestione di tutti gli asset di dati in sistemi on-premise, archiviazione sul cloud e piattaforme di datastore.
- gli strumenti e le tecnologie giusti per supervisionare e gestire la conformità alle norme sui dati.
Le sezioni successive presentano un framework di governance dei dati basato su Gartner Data Governance attraversando l'architettura di riferimento del data lake e gli strumenti e le tecnologie che ne consentono l'implementazione. Per una discussione sulle esigenze aziendali soddisfatte dalla governance e sui processi coinvolti nell'operatività della governance dei dati, consulta il white paper Principi e best practice per la governance dei dati nel cloud.
Gestione dell'accesso ai dati
Convenzionalmente, le aziende si sono affidate alla sicurezza del perimetro per proteggere le proprie risorse interne. La sicurezza del perimetro, nota anche come sicurezza guscio d'uovo o sicurezza castle-and-moat, presuppone che le minacce siano esterne alle sue mura e che qualsiasi elemento all'interno delle pareti perimetrali sia attendibile. Questa ipotesi si è rivelata errata con le convenienti costose per le aziende, perché quando un utente malintenzionato accede alla rete interna, può passare ad altri sistemi ed esplorare asset di dati preziosi quasi ostacolati.
Gli utenti malintenzionati possono accedere a reti interne tramite vulnerabilità, malware installato da dipendenti, ingegneria sociale e altri mezzi. Tuttavia, gli agenti esterni dannosi che creano lacune nel modello di sicurezza del perimetro non sono l'unica minaccia. I dipendenti fidati possono modificare, eliminare o esfiltrare consapevolmente o involontariamente i dati quando gli asset nella rete interna non sono protetti correttamente.
Infine, ma non meno importante, la sicurezza del perimetro è diventata sempre più complessa a causa dell'evoluzione della rete aziendale. Ad esempio, un perimetro è difficile da applicare nelle seguenti situazioni:
- Quando i dipendenti devono lavorare da remoto da reti non attendibili, ad esempio da siti client, dall'aeroporto o da casa.
- Quando fornitori, partner e collaboratori hanno bisogno di un accesso più diretto alle tue risorse di dati.
- Quando alcuni dei sistemi aziendali ora si trovano nel cloud.
Se stai eseguendo la migrazione da un data warehouse aziendale on-premise esistente, è possibile che il tuo approccio attuale per consentire agli utenti di accedere ai dati delle query o delle visualizzazioni non sia approfondito o che sia complesso e costoso da gestire, oppure entrambi. Il passaggio a un data warehouse su cloud come BigQuery ti offre la sicurezza approfondita e, dal tuo lato, una manutenzione ridotta, perché il framework di sicurezza fa parte dell'offerta di servizi gestiti.
Il resto del documento introduce e descrive in dettaglio come ottenere la gestione dell'accesso ai dati su Google Cloud e BigQuery. L'obiettivo è fornire una panoramica di ciò che ottieni da questo framework di sicurezza quando esegui la migrazione del data warehouse aziendale. Gli stessi principi si applicano se esegui la migrazione da un altro cloud o crei le tue risorse BigQuery da zero.
Gestione delle risorse
Per configurare i carichi di lavoro in Google Cloud, devi rispettare la struttura che regola tutte le risorse di Google Cloud e le linee guida specifiche per ciascuno dei suoi prodotti.
Tutte le risorse in Google Cloud sono organizzate in una gerarchia. Al livello più basso, ci sono i componenti fondamentali come set di dati BigQuery, bucket Cloud Storage e macchine virtuali Compute Engine. Queste risorse di basso livello vengono raggruppate in container logici denominati progetti. I progetti costituiscono la base per utilizzare tutti i servizi Google Cloud, gestire la fatturazione e assegnare ruoli e autorizzazioni sulle risorse del progetto. I progetti sono a loro volta raggruppati in cartelle che possono corrispondere a diversi reparti o team all'interno di un'azienda. Nella parte superiore della gerarchia si trova il nodo organizzazione che rappresenta l'azienda alla quale appartiene e che contiene più cartelle. Per ulteriori dettagli, consulta la documentazione relativa alla gerarchia delle risorse.
Dal punto di vista di Google Cloud, i set di dati BigQuery si trovano al livello più basso della gerarchia delle risorse. Con lo zoom, dal punto di vista di BigQuery, sono container di primo livello utilizzati per organizzare e controllare l'accesso alle tabelle e alle viste. In linea di principio, sono simili ai database o agli spazi dei nomi negli ambienti tradizionali di elaborazione delle transazioni online (OLTP) e di elaborazione analitica online (OLAP). Al momento della creazione, scegli una località per il set di dati. Una query può fare riferimento solo a set di dati nella stessa località. Pertanto, è importante considerare la località quando crei inizialmente set di dati e query di progettazione.
Framework di sicurezza
L'iniziativa BeyondCorp di Google definisce un framework di sicurezza basato sulla sicurezza Zero Trust. In questo framework, il principio dei controlli di accesso dinamico definisce che qualsiasi utente o dispositivo che voglia accedere a una risorsa:
- Devono eseguire l'autenticazione con le proprie credenziali.
- Deve essere autorizzato ad accedere alla risorsa.
- Deve comunicare tramite crittografia.
Questi requisiti devono essere soddisfatti indipendentemente dalla posizione della rete dell'utente o del dispositivo, sia all'interno dell'Intranet aziendale, da una rete Wi-Fi pubblica sia in aereo.
Le sezioni successive di questo articolo esplorano concetti e best practice per gestire l'accesso agli asset di dati, inclusi i principi definiti in BeyondCorp. L'articolo spiega anche come implementare un overlay di sicurezza perimetrale come misura protettiva contro l'esfiltrazione.
Autenticazione e autorizzazione
L'autenticazione si riferisce alla procedura di determinazione e verifica dell'identità di un client che interagisce con BigQuery. Con autorizzazione si fa riferimento alla procedura per determinare quali autorizzazioni l'identità verificata ha per interagire con BigQuery e i suoi set di dati. In breve, l'autenticazione identifica chi sei e l'autorizzazione determina cosa puoi fare.
Identità
Su Google Cloud, Cloud Identity è il provider di identità integrato. Quando esegui la migrazione dal data warehouse on-premise, valuta la possibilità di federare il tuo provider di identità esistente come Microsoft Active Directory con Cloud Identity. Puoi continuare a utilizzare il tuo provider di identità esistente per gestire le seguenti attività:
- Provisioning e gestione di utenti e gruppi.
- Configurazione del Single Sign-On.
- Configurazione dell'autenticazione a più fattori.
Gli utenti di BigQuery potrebbero essere esseri umani, ma anche applicazioni non umane che comunicano tramite una libreria client o l'API REST BigQuery. Queste applicazioni devono identificarsi utilizzando un account di servizio, il tipo speciale di identità Google destinato a rappresentare un utente "non umano".
Cloud Identity è la prima metà del prodotto più grande chiamato Identity and Access Management (IAM).
Una volta che un utente è stato autenticato, devi comunque determinare se ha i privilegi necessari per interagire con BigQuery e i suoi set di dati.
Gestione degli accessi
Oltre all'autenticazione, IAM offre un controllo centralizzato per l'autorizzazione delle identità con autorizzazioni specifiche per BigQuery e i suoi set di dati. IAM gestisce il criterio di sicurezza per BigQuery nell'organizzazione e consente di concedere l'accesso alle risorse BigQuery a livelli granulari oltre a livello di progetto accesso.
In IAM, le autorizzazioni determinano le operazioni consentite su una risorsa, ma non puoi assegnarle direttamente alle identità Google (utenti, account di servizio, gruppi Google, Google Workspace o domini Cloud Identity). Devi invece assegnare i ruoli (ovvero le raccolte di autorizzazioni) alle identità Google e utilizzare un criterio (dichiarato in un file JSON o YAML) per applicare queste associazioni in uno qualsiasi dei seguenti livelli di risorse Google Cloud:
- Organizzazione
- Cartella
- Progetto
- Livello di risorsa (set di dati BigQuery)
I ruoli BigQuery possono essere associati a uno qualsiasi dei livelli di risorse elencati in precedenza, ad esempio:
- A livello di progetto, un utente può avere il ruolo di
admin,metadataViewerejobUser. - A livello di risorsa del set di dati BigQuery, un utente (o una visualizzazione) può avere il ruolo di
dataEditor,dataOwnerodataViewer.
IAM per tabelle e visualizzazioni
BigQuery ti consente di assegnare i ruoli singolarmente a determinati tipi di risorse all'interno dei set di dati, come tabelle e visualizzazioni, senza fornire l'accesso completo alle risorse del set di dati. Le autorizzazioni a livello di tabella determinano gli utenti, i gruppi e gli account di servizio che possono accedere a una tabella o una visualizzazione.
Per saperne di più sul controllo dell'accesso alle tabelle e alle visualizzazioni, consulta Introduzione ai controlli dell'accesso alle tabelle.
I ruoli non possono essere applicati alle seguenti singole risorse: routine o modelli.
In alternativa, puoi utilizzare una vista autorizzata per concedere a utenti specifici l'accesso ai risultati delle query, senza concedere loro l'accesso alle tabelle sottostanti. Utilizza le viste autorizzate per limitare l'accesso a un livello di risorse inferiore, come tabella, colonna, riga o cella. Si consiglia la sicurezza a livello di colonna e la sicurezza a livello di riga, entrambe le forme di classificazione dei dati rispetto alle viste autorizzate, ma le tue esigenze e circostanze determinano i metodi migliori da utilizzare.
IAM per gli endpoint
IAM consente di gestire l'autenticazione e l'autorizzazione in base alle identità. Ti permette anche di creare un perimetro sicuro intorno ai servizi che hanno endpoint pubblici come BigQuery. Per scoprire di più su questo metodo di controllo dell'accesso, consulta la sezione sulla sicurezza della rete.
Metodi di implementazione
Lo sforzo di migrazione spesso richiede la connessione di un'applicazione on-premise a BigQuery. Ecco alcuni esempi di quando è richiesto questo accesso:
- Pipeline di dati on-premise che caricano dati in BigQuery.
- Report, analisi o altre applicazioni aziendali on-premise che eseguono query o estraggono dati da BigQuery.
Per accedere ai dati da BigQuery, un'applicazione deve ottenere e inviare le credenziali insieme alle richieste API. Puoi utilizzare credenziali di breve o lunga durata per interagire con l'API BigQuery da un'applicazione on-premise o da un altro cloud pubblico.
Un client BigQuery deve essere autenticato utilizzando un account di servizio o le credenziali di un utente. Dopo l'autenticazione di un client, devi trasmettere un token di accesso o una chiave all'API BigQuery. Queste credenziali vengono quindi controllate per verificarne l'autorizzazione, per assicurare che il client disponga di autorizzazioni IAM sufficienti per qualsiasi interazione con BigQuery.
Credenziali di breve durata
Le credenziali di breve durata scadono automaticamente dopo una breve durata (durata massima di un'ora per OAuth 2.0 e OpenID, 12 ore per JWT), che viene specificato al momento della creazione. Se vuoi evitare di gestire le chiavi degli account di servizio o se vuoi emettere sovvenzioni in scadenza ai servizi Google Cloud, utilizza credenziali di breve durata.
I seguenti tipi di credenziali possono essere richiesti come brevi:
- Token di accesso OAuth 2.0
- Token ID OpenID Connect
- Token web JSON (JWT) autofirmati
- Oggetti binari autofirmati (blob)
Le credenziali di breve durata consentono ai servizi on-premise di comunicare con BigQuery senza richiedere un'identità Google Cloud. Anche se un'identità Google Cloud deve ottenere le credenziali di breve durata, l'applicazione o il servizio che utilizza il token non richiede un'identità Google Cloud.
Credenziali di lunga durata
Le credenziali di lunga durata (ad esempio, le chiavi private dell'account di servizio o i token di accesso OAuth 2.0 con token di aggiornamento) consentono l'accesso a BigQuery finché non vengono eliminate o revocate. Le chiavi private dell'account di servizio rimangono una volta create e non richiedono l'aggiornamento. I token di accesso OAuth 2.0 scadono, ma possono essere utilizzati per un periodo di tempo prolungato con un token di aggiornamento associato. Questo token di aggiornamento ti consente di richiedere nuovi token di accesso (senza richiedere la riautenticazione) per tutto il tempo per cui il token di aggiornamento rimane attivo. Questa procedura è illustrata in OAuth 2.0 Playground di Google.
Considerando la loro lunga durata, dovresti gestire le credenziali di lunga durata con cautela sulle macchine client remote o sui nodi worker. Ti consigliamo di conservarli in una posizione sicura, che limita l'accesso solo agli utenti autorizzati. Non memorizzare mai le credenziali in un repository di codice: chiunque abbia accesso al tuo codice avrà accesso anche alla tua chiave e, di conseguenza, ai tuoi dati. Nel caso di credenziali divulgate, puoi usare i perimetri di servizio per ridurre il rischio di questo accesso indesiderato dall'esterno.
Ecco alcune strategie consigliate per l'archiviazione di credenziali di lunga durata:
- Cloud Storage con o senza Key Management Service (KMS)
- Spazio di archiviazione on-premise sicuro
- Soluzione di gestione dei secret di terze parti
Una chiave privata dell'account di servizio è un JWT firmato tramite crittografia che appartiene a un singolo account di servizio. Il JWT firmato viene utilizzato direttamente come token di connessione, pertanto non è necessaria una richiesta di rete al server di autorizzazione di Google. In caso di fuga, le chiavi non scadono automaticamente o l'accesso viene revocato. Pertanto, è una best practice per la sicurezza ruotare le chiavi regolarmente. Questo processo richiede la generazione di una nuova chiave, assicurando che tutti gli utenti e i servizi autorizzati abbiano accesso alla nuova chiave e l'eliminazione della vecchia chiave. La rotazione delle chiavi garantisce che l'accesso di una chiave compromessa a BigQuery venga revocato automaticamente, anche se viene rilevata la perdita.
Richieste BigQuery non anonime
Sia le chiavi degli account di servizio privati sia i token di aggiornamento supportano l'autenticazione tramite account di servizio. Più utenti e applicazioni potrebbero avere accesso allo stesso account di servizio, in modo che queste richieste siano anonime, poiché non è possibile identificare l'utente o l'applicazione. Tuttavia, molti clienti aziendali richiedono che l'accesso alle risorse Google Cloud come BigQuery sia attribuibile al singolo utente che ha avviato la richiesta. In questo caso, puoi utilizzare il flusso OAuth 2.0 a tre vie (3LO) per l'autenticazione per conto di un utente finale, anziché di un account di servizio.
In un flusso a due vie, un'applicazione contiene direttamente le credenziali di un account di servizio e chiama l'API BigQuery per suo conto. Tuttavia, in un flusso a tre vie, il proprietario della risorsa concede a un client l'accesso alle risorse di BigQuery senza condividere direttamente le proprie credenziali; le richieste vengono effettuate per conto dell'utente e, a volte, è necessario il consenso dell'utente. Dopo l'autenticazione di un utente, è possibile scambiare un codice di autorizzazione con un token di accesso e un token di aggiornamento.
Sicurezza della rete
Una rete Virtual Private Cloud è simile a una rete fisica, ma virtualizzata in Google Cloud. Puoi definire regole firewall a livello di rete per controllare il traffico da e verso le tue istanze di macchine virtuali. Tuttavia, non puoi definire regole firewall per servizi basati su API come BigQuery o Cloud Storage. Per questi tipi di servizi, puoi utilizzare i Controlli di servizio Virtual Private Cloud (VPC) per limitare il traffico.
Un VPC definisce i perimetri di servizio intorno ai servizi basati su API di Google con un endpoint pubblico, come BigQuery o Cloud Storage. I perimetri di servizio mitigano i rischi di esfiltrazione dei dati limitando il traffico in uscita e il traffico in entrata tra le risorse all'interno del perimetro e le risorse esterne al perimetro. Se implementi correttamente questi controlli, le reti non autorizzate non possono accedere ai dati e ai servizi e i dati non possono essere copiati nei progetti Google Cloud non autorizzati. Le comunicazioni gratuite possono comunque verificarsi all'interno del perimetro, ma la comunicazione è limitata all'interno del perimetro.
Ti consigliamo di utilizzare Controlli di servizio VPC e i controlli di accesso IAM. Dove IAM offre un controllo dell'accesso granulare basato sull'identità, i Controlli di servizio VPC consentono una sicurezza del perimetro più ampia basata sul contesto.
Controllo dell'accesso sensibile al contesto
Le richieste API dalla rete Internet pubblica sono consentite o negate per le risorse all'interno di un perimetro di servizio in base ai livelli di accesso del perimetro in questione. Le richieste vengono classificate in base al contesto del client, ad esempio intervalli IP e identità degli account utente/di servizio. Ad esempio, se una richiesta API BigQuery proviene da una credenziale valida ma da una rete non attendibile, può essere negato l'accesso alla rete VPC e al perimetro di servizio, come mostra il seguente diagramma.
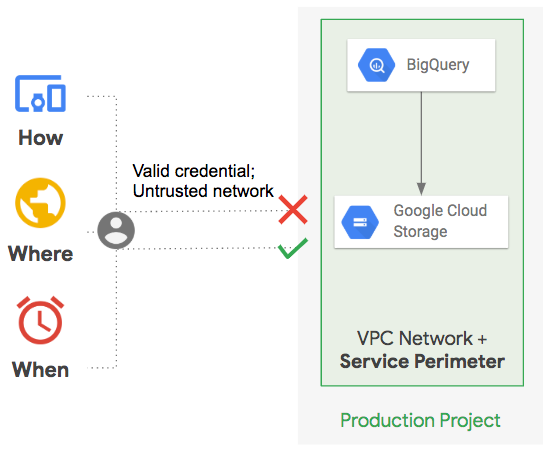
Perimetri di servizio
I perimetri di servizio VPC sono configurati a livello di organizzazione Google Cloud, quindi i criteri di sicurezza possono essere gestiti a livello centrale. Più progetti all'interno dell'organizzazione e dei servizi (ad esempio, l'API BigQuery) possono essere assegnati a ciascun perimetro. I progetti e i dati nello stesso perimetro di servizio possono elaborare, trasformare e copiare in modo flessibile i dati, purché tutte queste azioni rimangano all'interno del perimetro. Il seguente diagramma mostra come utilizzare i perimetri di servizio.
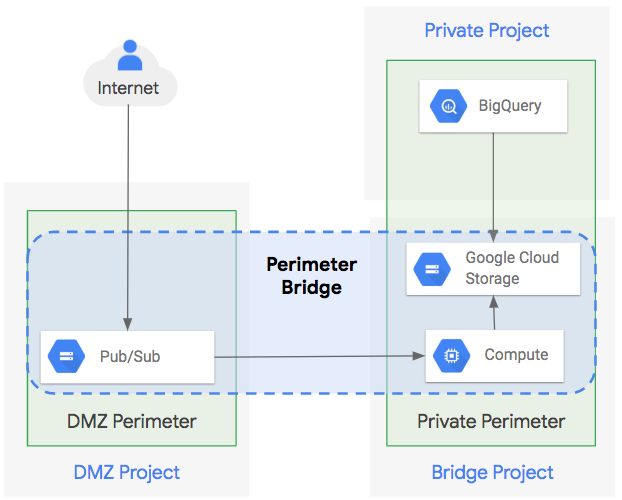
Se le risorse Google Cloud in diversi perimetri di servizio devono comunicare (ad esempio BigQuery in un progetto e un perimetro di servizio e Compute Engine in un altro), puoi creare un perimetro bridge a livello di organizzazione. Un bridge del perimetro consente la comunicazione tra le risorse Google Cloud tra più perimetri di servizio. Sebbene un progetto Google Cloud possa appartenere a un solo perimetro di servizio, può far parte di più bridge del perimetro.
Accesso ai dati in ambienti ibridi
Per ambienti cloud on-premise e cloud, puoi configurare l'accesso privato Google per le reti on-premise per consentire la comunicazione privata tra il perimetro di servizio e gli ambienti on-premise. Questo può consentire agli ambienti on-premise di accedere ai set di dati BigQuery. Queste richieste devono essere inviate tramite una connessione privata a Google Cloud, che può essere una VPN basata su route o una connessione Cloud Interconnect. Le richieste non attraversano la rete Internet pubblica.
Questa configurazione estende il perimetro di servizio dalle reti on-premise ai dati archiviati nei servizi Google Cloud, garantendo che i dati sensibili rimangano privati. Puoi utilizzare questa configurazione di comunicazione privata solo per le API su restricted.googleapis.com. Il seguente diagramma mostra un esempio di questa configurazione.
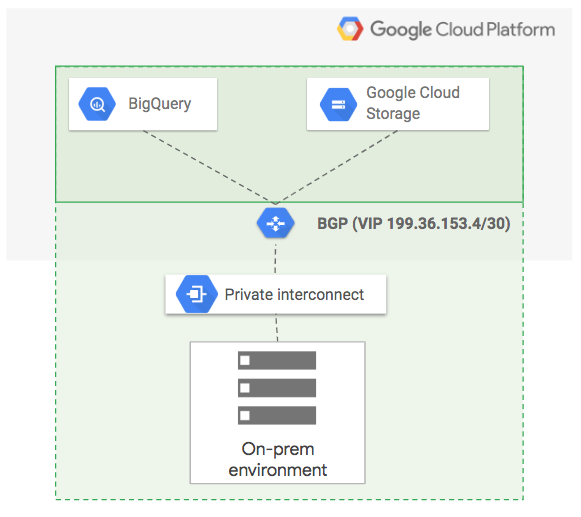
Crittografia
Quando esamini il modo in cui i dati vengono archiviati e trasferiti su Google Cloud e BigQuery, rispetto al data warehouse aziendale on-premise, è utile riconsiderare il framework della sicurezza.
Il principio dei controlli di accesso dinamici di BeyondCorp stabilisce che ogni accesso deve essere criptato. Per questo è essenziale che tu istituisca la crittografia come metodo di protezione dei dati, per assicurare che, anche nel caso improbabile di esposizione dei dati, i dati siano leggibili non at-rest o in transito. In questo modo, la crittografia aggiunge un ulteriore livello di difesa per la protezione dei dati.
Crittografia at-rest
Google Cloud cripta i dati at-rest per impostazione predefinita, senza la necessità di ulteriori azioni da parte tua. Lo standard di crittografia avanzata (AES) viene utilizzato per criptare i dati at-rest come consigliato dal National Institute of Standards and Technology.
Prima che vengano scritti su disco, i dati in un set di dati BigQuery vengono suddivisi in diversi blocchi. Ogni blocco è criptato con una chiave di crittografia dei dati (DEK) univoca. L'utilizzo di chiavi diverse ha un impatto probabilmente improbabile sulla compromissione della DEK solo su quel blocco di dati. Queste chiavi vengono quindi criptate con chiavi univoche (KEK). Mentre le DEK criptate sono archiviate vicino ai dati associati, queste sono archiviate a livello centrale in Cloud Key Management Service (KMS). Questo metodo gerarchico per la gestione delle chiavi è chiamato crittografia busta. Per maggiori dettagli, consulta la sezione sulla gestione delle chiavi dell'articolo Crittografia dei dati at-rest.
Il seguente diagramma mostra come funziona la crittografia at-rest.
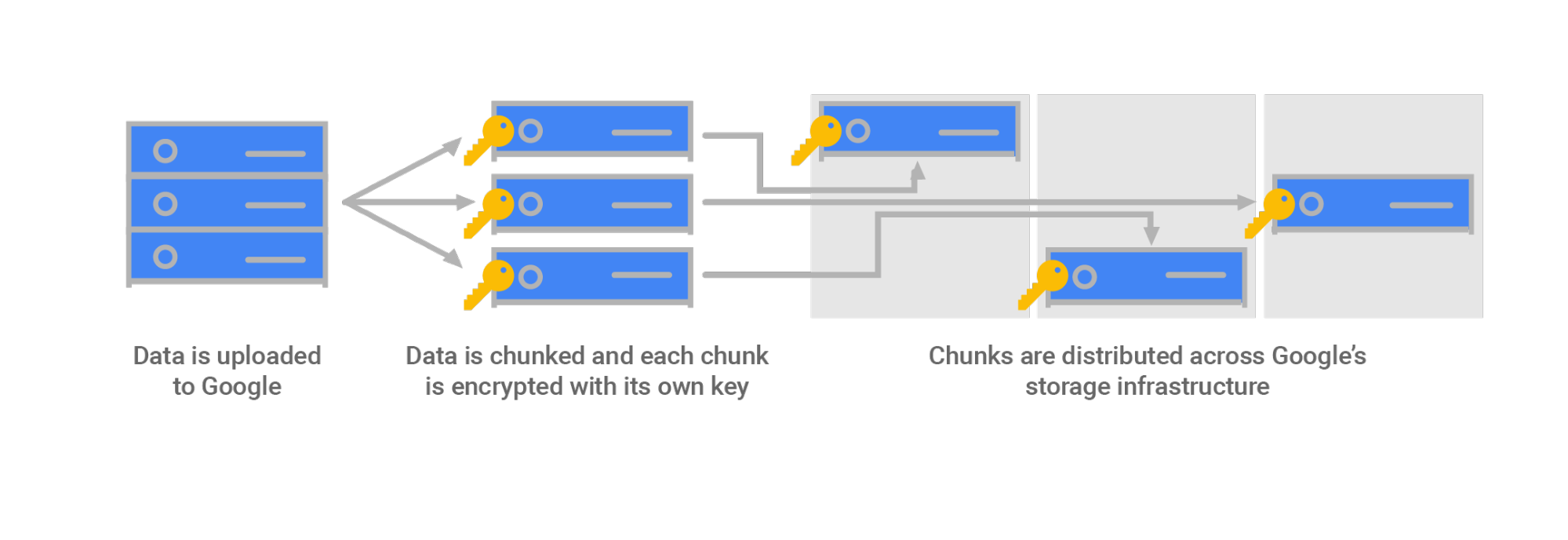
Per impostazione predefinita, tutte le chiavi sono gestite da Google. Tuttavia, puoi scegliere di gestire autonomamente le chiavi. Questa tecnica è chiamata chiavi di crittografia gestite dal cliente (CMEK). Con questa tecnica utilizzerai Cloud KMS per creare, ruotare, distruggere automaticamente e distruggere le chiavi di crittografia simmetriche. Per ulteriori informazioni sull'utilizzo di CMEK con BigQuery, consulta Protezione dei dati con le chiavi Cloud KMS.
Crittografia dei dati in transito
Google Cloud cripta e autentica tutti i dati in transito quando questi si spostano al di fuori dei limiti fisici controllati da Google o per conto di Google. All'interno di questi confini, i dati in transito sono generalmente autenticati, ma non necessariamente criptati.
La crittografia dei dati in transito difende i tuoi dati, dopo aver stabilito e autenticato una connessione, da potenziali malintenzionati:
- Eliminando la necessità di affidarsi ai livelli inferiori della rete, che in genere vengono forniti da terze parti.
- Impedisce agli utenti malintenzionati di accedere ai dati se le comunicazioni vengono intercettate.
A livello generale, la crittografia dei dati in transito funziona come segue: i dati vengono criptati prima della trasmissione, quindi gli endpoint vengono autenticati e, quando raggiungono la destinazione, vengono decriptati e verificati. Tuttavia, i metodi di sicurezza utilizzati dipendono dal tipo di connessione protetta. Questa sezione si concentra sull'utilizzo della crittografia per proteggere le connessioni da e verso BigQuery.
BigQuery è un servizio Google Cloud quindi, quando un utente o un'applicazione invia una richiesta, quest'ultima raggiunge prima un sistema distribuito a livello globale chiamato Google Front End (GFE). GFE termina il traffico per il traffico su proxy HTTP(S), TCP e TLS in entrata, fornisce contromisure agli attacchi DDoS e instrada le route e il carico al traffico su qualsiasi servizio.
È necessario tenere presente che il traffico da o verso un servizio di Google Cloud potrebbe aver bisogno di ulteriori misure di sicurezza. Queste misure sono pertinenti quando esegui la migrazione dei processi a monte e a valle. Ad esempio, le richieste tra un utente o un'applicazione a un'applicazione personalizzata ospitata su Google Cloud possono essere instradate in diversi modi. In generale, se utilizzi Cloud Load Balancing, il traffico passa attraverso il GFE, quindi questa route rientra nella categoria precedente. Se utilizzi una VPN Cloud, la connessione è protetta da IPsec. Se invece ti connetti direttamente a una VM utilizzando un indirizzo IP esterno, un indirizzo IP del bilanciatore del carico di rete o tramite Cloud Dedicated Interconnect, la connessione non è criptata per impostazione predefinita. Pertanto, consigliamo vivamente di utilizzare un protocollo di sicurezza come TLS.
Per ulteriori informazioni su come Google Cloud gestisce la crittografia dei dati in transito per ogni flusso di connessione, consulta Crittografia dei dati in transito in Google Cloud.
Eliminazione delle criptovalute
Oltre alla crittografia fornita da Google per impostazione predefinita, se necessario, la tua applicazione può applicare la propria crittografia, ad esempio quando richiede colonne specifiche di mascheramento dei dati in una tabella o l'eliminazione delle criptovalute.
L'eliminazione di criptovalute, o cripto-shredding, è il processo di rendering dei dati non recuperabile eliminando la chiave utilizzata per criptarla. Poiché i dati non possono più essere decriptati, vengono eliminati.
Poiché viene eliminata solo la chiave, anziché l'intero dato criptato, questo metodo di eliminazione è veloce, permanente e comunemente usato in casi come:
- Quando i dati criptati sono molto più grandi della chiave, ad esempio nei dischi criptati, nei telefoni, nei record di database.
- Quando eliminare i dati criptati è troppo costoso, complesso o non attuabile, ad esempio in dati distribuiti attraverso molti repository o in uno spazio di archiviazione non modificabile.
BigQuery fornisce funzioni per creare chiavi e criptare e decriptare i dati all'interno delle query utilizzando i concetti di crittografia AEAD.
Rilevamento dati
Il volume, la varietà e la velocità dei dati a disposizione delle organizzazioni di tutte le dimensioni stanno aumentando. Questa proliferazione dei dati può presentare diverse sfide, tra cui:
- I dati che ti servono sono difficili da trovare perché sono sparsi, non organizzati o duplicati in più repository di dati.
- Anche se trovi alcuni dati, non è chiaro da dove provengono, se rappresentano ciò che stai cercando e se sono sufficienti per prendere una decisione aziendale.
- I dati sono difficili da gestire. Non è chiaro chi sia il proprietario di un dato, chi può accedervi e qual è la procedura per ottenere l'accesso ai dati.
I metadati sono costituiti da attributi che descrivono i dati e aiutano a superare le sfide precedenti. La raccolta di metadati è simile alla creazione di un catalogo delle schede per una biblioteca, in cui ogni libro ha una scheda fisica che indica informazioni, come autore, anno di pubblicazione, edizione e argomento. Come un libro, a un dato può essere associato un insieme di attributi, ad esempio il proprietario, l'origine, la data di elaborazione o la valutazione della qualità.
Tradizionalmente, le aziende hanno provato ad acquisire e organizzare i metadati utilizzando diversi metodi, che vanno da fogli di lavoro, pagine wiki, sistemi sviluppati internamente e software di terze parti. I problemi più comuni includono la necessità di inserimento manuale, selezione e manutenzione, nonché la compatibilità e l'ambito del sistema. Un ultimo problema è che i processi di individuazione e raccolta di metadati sono spesso processi organici che si basano su un'esperienza personale trasferita da una persona all'altra, che non è scalabile per un'organizzazione in crescita. In questo contesto, come fa un analista che non fa parte di questo gruppo di persone a trovare i dati a cui ha accesso e come ha senso?
Oltre a queste sfide interne, le aziende stanno affrontando un aumento dei requisiti normativi e di conformità, come il Regolamento generale sulla protezione dei dati (GDPR), il Comitato di Basilea per la supervisione delle banche 239 (BCBS239) e l'HIPAA (Health Insurance Portability and Accountability Act), che li richiedono di monitorare, proteggere e creare report sui propri dati.
La risposta di Google Cloud a queste esigenze dei clienti è Data Catalog, un servizio di gestione di metadati completamente gestito e scalabile che consente alla tua organizzazione di individuare, classificare e comprendere i tuoi dati in Google Cloud.
L'architettura di Data Catalog si basa su:
- Archivio di metadati: basato su Cloud Spanner, il database a elevata coerenza distribuito a livello globale per l'archiviazione di tutte le voci di metadati.
- Sincronizzatori in tempo reale e batch: per l'importazione automatica di metadati tecnici.
- Indice di ricerca di Google: sfrutta la stessa tecnologia utilizzata per la ricerca di Gmail e Google Drive, un sistema scalabile ed efficiente con elenchi di controllo dell'accesso (ACL) integrati.
Data Catalog offre una visualizzazione unificata di tutti gli asset di dati. quindi ti offre una base per creare un solido processo di governance dei dati.
Il seguente diagramma mostra un'architettura semplificata con funzionalità Data Catalog che forniscono metadati, ricerca e prevenzione della perdita di dati per BigQuery, Pub/Sub e Cloud Storage. Queste funzionalità saranno illustrate nelle sezioni successive.
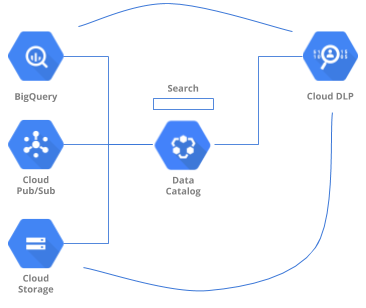
Metadati
La possibilità di trovare i dati giusti per prendere decisioni è al centro del processo di scoperta dei dati. Proprio come ti servono i metadati sui libri disponibili per trovare un libro in una biblioteca, hai bisogno anche dei metadati sulle tue risorse di dati per trovarli in un ambiente di big data.
Data Catalog può importare automaticamente i metadati da BigQuery, Pub/Sub e Cloud Storage. Inoltre, distingue tra due diversi tipi di metadati: tecnico e aziendale.
Da un lato, i metadati tecnici includono informazioni come nomi di tabelle, nomi di colonne, descrizioni e date di creazione. Questo tipo di metadati è già presente nel sistema di origine. Data Catalog importa automaticamente i metadati tecnici nel suo indice, ogni volta che vengono creati, senza che tu debba registrare manualmente nuovi asset di dati.
Al contrario, gli asset di dati hanno un contesto aziendale implicito associato, ad esempio se una colonna contiene informazioni che consentono l'identificazione personale (PII), chi ne è il proprietario, una data di eliminazione o conservazione e un punteggio di qualità dei dati. Questo tipo di metadati è chiamato metadati aziendali.
I metadati sull'attività sono più complessi dei metadati tecnici in quanto gli utenti con ruoli diversi sono interessati a sottoinsiemi differenti del contesto aziendale. Ad esempio, un analista di dati potrebbe essere interessato allo stato di un job ETL, se è stato eseguito correttamente, quante righe sono state elaborate o se si sono verificati errori o avvisi. A un Product Manager potrebbe interessare la classificazione dei dati, se pubblica o privata, se i dati si trovano nel ciclo di vita, ad esempio produzione, test o QA, o se sono completi e di qualità.
Per gestire questa complessità, Data Catalog ti consente di raggruppare i metadati aziendali in modelli. Un modello è un gruppo di coppie chiave-valore di metadati chiamate attributi. Un set di modelli è simile a uno schema di database per i tuoi metadati.
I tag metadati sono istanze dei modelli che possono essere applicati sia alle tabelle che alle colonne. Quando questi tag vengono applicati alle colonne, gli utenti possono determinare se una determinata colonna contiene PII, se la colonna è stata ritirata e quale formula è stata utilizzata per calcolare una determinata quantità. In sostanza, i metadati aziendali forniscono il contesto necessario per utilizzare i dati in modo significativo.
Il seguente diagramma mostra una tabella di esempio del cliente (cust_tbl) e diversi tag di metadati aziendali associati e le relative colonne.
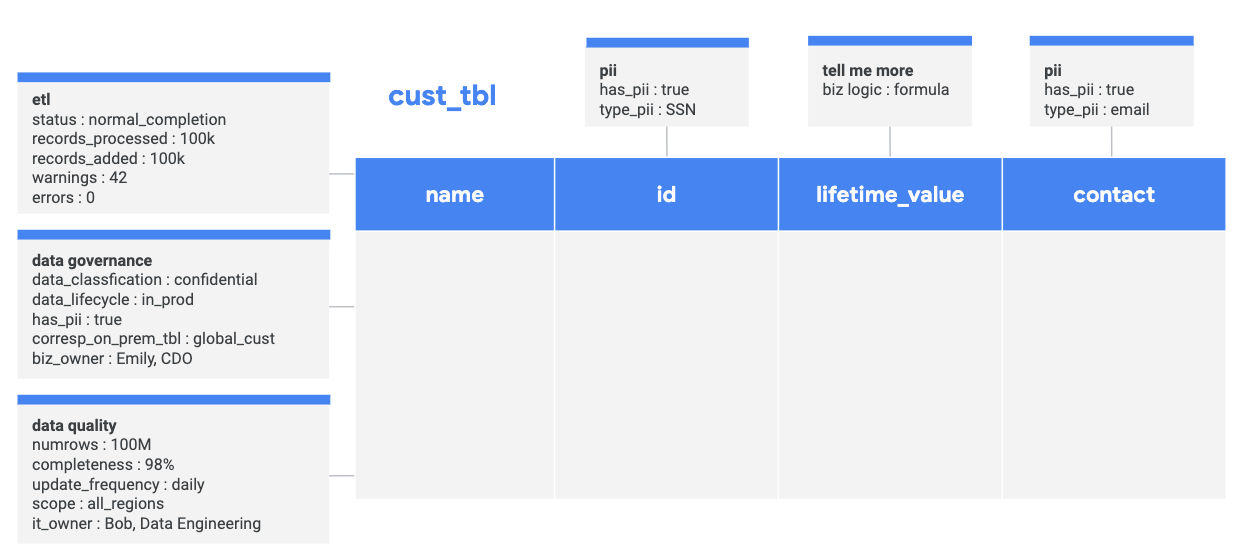
Oltre a un'interfaccia utente intuitiva, Data Catalog fornisce agli utenti tecnici un'API per annotare o recuperare i metadati in blocco. I linguaggi supportati sono Python, Java e NodeJS. L'API non solo ti consente di scalare le tue attività di metadati, ma anche di integrarle in modo programmatico con Data Catalog, che apre la strada alla creazione di applicazioni aziendali personalizzate che utilizzano Data Catalog come parte del loro backend.
Cerca
L'aggiunta di metadati agli asset di dati è la base per il rilevamento dei dati, ma è solo la metà della storia. L'altra metà è la possibilità di trovare un asset tramite una solida funzionalità di ricerca che utilizza metadati tecnici e aziendali per restituire risultati pertinenti.
Data Catalog indicizza tutti i metadati dalle origini e li rende disponibili tramite un'interfaccia utente intuitiva e un'API per l'integrazione programmatica. Funziona nello stile della ricerca Google utilizzando parole chiave che corrispondono ai metadati. Offre inoltre la ricerca facet per utenti esperti. Con i suoi filtri intuitivi e i predicati qualificati, la ricerca per facet consente agli utenti di restringere i risultati, ad esempio cercando solo tabelle, set di dati o file oppure solo all'interno di un progetto, un'organizzazione o un prodotto Google Cloud specifico.
Nella sua interfaccia utente, Data Catalog mostra anche un elenco delle tabelle BigQuery utilizzate spesso nelle ricerche. Questa funzionalità consente di accedere comodamente ai dettagli della tabella, allo schema e alla console BigQuery.
Controllo dell'accesso
Consentendo ai tuoi utenti di cercare tra i metadati e scoprire gli asset di dati, potrai aumentare la produttività, l'indipendenza e il coinvolgimento. Tuttavia, non tutti dovrebbero avere accesso a tutti i metadati. Quando le persone giuste hanno accesso ai dati giusti, consenti ai tuoi dipendenti di concentrarsi su un sottoinsieme di asset di dati pertinenti ai loro ruoli e contribuisci a prevenire l'esfiltrazione di metadati o dati.
Data Catalog è integrato con IAM, permettendoti di controllare quali utenti possono trovare asset di dati selezionati nelle loro ricerche o di creare metadati aziendali per gli asset.
Per semplificare i controlli di accesso ai metadati tecnici, l'importazione automatica applica lo stesso insieme di autorizzazioni ai metadati concessi ai dati taggati. Se un utente ha accesso ai dati, ha accesso anche ai metadati tecnici estratti e può trovare gli asset di dati con una ricerca in Data Catalog. Questo metodo fornisce un'impostazione predefinita ragionevole che non richiede alcun intervento manuale, invece di attendere la registrazione di un asset di dati e di concedere un insieme separato di autorizzazioni.
Per i metadati aziendali, devi definire quali utenti o gruppi di utenti hanno accesso ai metadati. Alcuni di questi utenti hanno accesso sia ai metadati che ai dati, solo a uno di loro o a nessuno dei due.
- Se non ha accesso ai metadati, non riesce a trovare gli asset di dati nella ricerca di Data Catalog.
- Se hanno accesso ai metadati, ma non ai dati, possono trovare l'asset di dati, ma non possono leggere i dati. Questa funzionalità consente agli utenti di scoprire set di dati utili senza esporre i dati sottostanti, il che aumenta l'usabilità degli asset di dati di un'organizzazione senza compromettere la sicurezza. Gli utenti possono poi inoltrare ai proprietari dei dati le richieste di accesso, che potrebbero essere approvate o rifiutate a seconda del caso d'uso aziendale, della sensibilità dei dati e di altri fattori.
Questa sezione ha introdotto il modo in cui Data Catalog si integra con IAM per applicare il controllo dell'accesso sui metadati. Inoltre, puoi controllare chi ha accesso al prodotto Data Catalog stesso concedendo i ruoli Data Catalog agli utenti. Per controllare l'accesso ai tuoi asset di dati, utilizza una combinazione di IAM e Controlli di servizio VPC. Per ulteriori informazioni, consulta la documentazione di Data Catalog IAM.
Derivazione
Nel contesto del data warehouse, la lineage si riferisce al percorso che un asset di dati attraversa dalla sua origine alla destinazione. L'origine di un asset di dati può essere un'origine esterna (ad esempio i dati di mercato forniti da una terza parte) o un'origine interna (ad esempio un database relazionale per l'archiviazione delle transazioni dei clienti). La destinazione dell'asset di dati potrebbe essere una dashboard, un report o un feed di dati mostrato come API.
In tutti questi casi, è importante sapere che i dati presentati nella destinazione riflettono accuratamente le trasformazioni applicate ai dati originali. Per i consumatori dei dati è importante potersi fidare dei dati che ricevono, per consentire agli enti regolatori di verificare e comprendere i dati segnalati, così come per gli stakeholder interni identificare le lacune nei processi aziendali e nelle interrelazioni nelle pipeline di trattamento dati.
I dati da acquisire dipendono dall'ambito del business case. Può includere metadati come l'origine dati di origine, i proprietari dei dati, il processo aziendale in cui l'asset di dati viene trasformato o le applicazioni e i servizi coinvolti durante le trasformazioni.
L'acquisizione manuale di queste informazioni è soggetta a errori e non è scalabile in casi aziendali non reali. Ti consigliamo quindi di avvicinarti alla derivazione dei dati da un punto di vista programmatico:
- Determina l'insieme di attributi dei metadati che devi acquisire per soddisfare le tue esigenze aziendali o normative.
- Crea modelli per acquisire questi metadati dell'attività.
Data Catalog supporta cinque tipi di dati che puoi combinare per creare tag avanzati:
double,string,boolean,datetimeeenum. Quest'ultimo tipo può utilizzare un set di valori personalizzati per descrivere una fase nella trasformazione dei dati o valori enumerati simili. - Utilizza l'API Data Catalog per registrare i metadati di derivazione pertinenti su ogni passaggio pertinente della pipeline di dati.
In alternativa a Data Catalog, puoi utilizzare Cloud Data Fusion, la versione gestita di Google di CDAP, per implementare la trasformazione dei dati. Cloud Data Fusion incapsula l'ambiente di elaborazione dati in un unico ambiente controllato, consentendo la registrazione automatica della derivazione a livello di set di dati e di campo. Per ulteriori informazioni, consulta la documentazione relativa alla derivazione CDAP open source.
Classificazione e gestione dei dati
In un data warehouse aziendale, il volume, la velocità e la varietà dei dati importati possono creare difficoltà per la classificazione e la gestione dei dati.
La classificazione dei dati è il processo di classificazione dei dati in tipi, moduli o categorie utilizzando le rispettive caratteristiche. Classificare i dati in modo efficace è essenziale per applicare criteri di governance appropriati a diversi tipi di dati.
Ad esempio, a seconda del contenuto di un documento aziendale, puoi classificarlo con un livello di sensibilità, come non protetto o riservato. Ognuno di questi tipi può quindi applicare criteri specifici per la propria gestione, ad esempio i documenti riservati sono accessibili solo a un determinato gruppo di utenti e vengono conservati per sette anni.
Ci sono diversi aspetti da considerare nella gestione dei dati:
- Gestione della modifica dei dati: controllo degli effetti quando le dimensioni dei dati cambiano. Anche se cambiano raramente, la modifica può avere un effetto a onde perché i dati nelle tabelle potrebbero non essere più veri per le dimensioni aggiornate.
- Gestione dei dati di riferimento: garantire che tutti i sistemi dell'organizzazione abbiano una visione accurata e coerente dei dati di riferimento.
- Conservazione ed eliminazione: come impedire agli utenti di modificare o eliminare i dati e come farli scadere automaticamente.
Quando esegui la migrazione a BigQuery, sfrutta le funzionalità automatizzate per la classificazione dei dati, come Cloud Data Loss Prevention (DLP). Le seguenti sezioni presentano funzionalità e tecniche utili per affrontare queste sfide di classificazione e gestione dei dati in Google Cloud.
Prevenzione della perdita di dati
Cloud Data Loss Prevention è un servizio Google Cloud che facilita la governance dei dati aiutandoti a classificare i tuoi dati per consentirti di concedere l'accesso giusto alle persone giuste. Cloud DLP offre una piattaforma di ispezione, classificazione e anonimizzazione dei dati. Include più di 150 rilevatori predefiniti per identificare pattern, formati e checksum. Puoi anche creare rilevatori personalizzati usando un dizionario o un'espressione regolare. Puoi aggiungere regole hotword per aumentare la precisione dei risultati e impostare regole di esclusione per ridurre il numero di falsi positivi.
Questa sezione descrive le funzionalità di Cloud DLP che possono aiutarti a classificare e oscurare i dati sensibili.
Profila i tuoi dati
Cloud DLP può generare automaticamente profili per i dati BigQuery in un'organizzazione, una cartella o un progetto. I profili dei dati contengono metriche e metadati relativi alle tabelle e ti aiutano a determinare dove si trovano i dati sensibili e ad alto rischio. Cloud DLP segnala queste metriche a livello di progetto, set di dati, tabella e colonna.
La profilazione ti aiuta a stare al passo con la crescita dei dati nella tua organizzazione. Per impostazione predefinita, Cloud DLP profila automaticamente nuove tabelle e riprofila le tabelle con aggiornamenti dello schema. Se necessario, puoi perfezionare la selezione dei dati da profilare e la cadenza di profilazione.
Per ulteriori informazioni, consulta Profili di dati per dati BigQuery.

Ispezionare una singola tabella
La profilazione dati rimanda a tabelle e colonne specifiche che potrebbero contenere dati sensibili. Per saperne di più su queste tabelle, puoi controllarle. Quando esegui un job di ispezione su una singola tabella, puoi ottenere i dettagli seguenti:
- Numero di risultati.
- Sono stati trovati tipi di informazioni sensibili, come indirizzi email e numeri di carte di credito.
- Probabilità che un risultato corrisponda al tipo di dati sensibili che stai cercando.
- La posizione esatta di ogni risultato.
- La stringa che ha attivato ciascun risultato.
Anonimizzazione dei dati sensibili
Cloud DLP fornisce una serie di strumenti per anonimizzare i tuoi dati, tra cui mascheramento, tokenizzazione, pseudonimizzazione e spostamento delle date.
Tagging automatico dei dati
L'API DLP può creare automaticamente tag Data Catalog per classificare i dati sensibili. Puoi applicare questo flusso di lavoro nelle tue tabelle BigQuery, nei bucket Cloud Storage o nei flussi di dati esistenti.
Agevola la classificazione automatica dei dati in una pipeline
Cloud DLP analizza i tuoi dati e segnala i risultati con un livello di probabilità. Ad esempio, se il livello di probabilità dei dati è elevato, puoi elaborare grandi quantità di dati automaticamente. Per semplificare il riconoscimento delle PII nella tua pipeline, estrazione-trasformazione-carico o estrazione-caricamento-trasformazione, puoi:
- Importare i dati in un bucket di quarantena.
- Esegui Cloud DLP per identificare le PII nei dati. Questa operazione può essere eseguita analizzando l'intero set di dati o campionando i dati. L'API DLP può essere chiamata dai passaggi di trasformazione della tua pipeline oppure da script autonomi come Cloud Functions. Il tutorial Automazione della classificazione dei dati caricati in Cloud Storage presenta un esempio utilizzando quest'ultimo.
- Spostare i dati nel warehouse.
Sicurezza a livello di colonna
Partendo dal concetto di classificazione dei dati, BigQuery fornisce l'accesso granulare alle colonne sensibili mediante tag di criteri, ovvero una classificazione dei tipi basata sui dati. Utilizzando la sicurezza a livello di colonna di BigQuery, puoi creare criteri che verificano, al momento della query, se un utente dispone dell'accesso corretto.
Per ulteriori informazioni su come utilizzare i tag di criteri per la sicurezza a livello di colonna, consulta Introduzione alla sicurezza a livello di colonna di BigQuery.
Sicurezza a livello di riga
La sicurezza a livello di riga consente di filtrare i dati e consentire l'accesso a righe specifiche in una tabella, in base alle condizioni utente idonee. La sicurezza a livello di riga estende il principio del privilegio minimo consentendo il controllo granulare degli accessi a un sottoinsieme di dati in una tabella BigQuery, mediante criteri di accesso a livello di riga. I criteri di accesso a livello di riga possono coesistere su una tabella con sicurezza a livello di colonna.
Per ulteriori informazioni sull'utilizzo dei criteri di accesso alle righe per la sicurezza a livello di riga, consulta Introduzione alla sicurezza a livello di riga di BigQuery.
Gestione dati master
I dati master, noti anche come dati di riferimento, sono dati utilizzati all'interno di un'organizzazione. Esempi comuni di asset di dati master includono clienti, prodotti, fornitori, località e account. La gestione dei dati master (MDM) è un insieme di procedure che assicurano che i dati master siano accurati e coerenti in tutta l'organizzazione.
Affinché i diversi sistemi e divisioni funzionino e interagiscano correttamente, l'accuratezza e la coerenza dei dati sono fondamentali. In caso contrario, suddivisioni diverse di un'organizzazione potrebbero avere record diversi per la stessa entità, il che può comportare errori costosi. Ad esempio, quando un client aggiorna il proprio indirizzo sul sito web dell'azienda, se il reparto fatturazione legge da un repository client diverso, le fatture future potrebbero non raggiungere questo client.
In MDM, un sistema autoritativo è la fonte di riferimento per specifici asset di dati master. Idealmente, gli altri sistemi dell'organizzazione utilizzano i dati master del sistema ufficiale dell'asset. Tuttavia, come sempre, non è sempre possibile.
Comunicazione diretta con un sistema autorevole
In questo scenario, i sistemi comunicano direttamente con il sistema autorevole incaricato di un determinato asset di dati master. I sistemi autorevoli creano e aggiornano i dati master, mentre gli altri sistemi dell'organizzazione li utilizzano sempre dai rispettivi sistemi autorevoli.
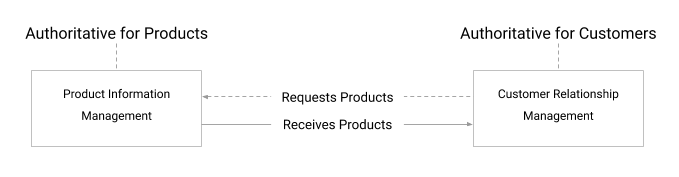
Ad esempio, nel diagramma un sistema di gestione delle informazioni sui prodotti (PIM) è quello ufficiale dell'azienda per i prodotti. Quando un altro sistema, ad esempio un sistema di gestione dei rapporti con i clienti (CRM), necessita di dati master sul prodotto, recupera i dati dalla PIM. Il sistema CRM può essere considerato autorevole per un asset di dati diverso, ad esempio per i clienti dell'azienda.
Questo scenario è ideale perché conserva gli asset di dati master nei rispettivi sistemi autorevoli, senza bisogno di pipeline di trasformazione complesse. Se il sistema consumer richiede solo un determinato sottoinsieme di dati master o dati in un formato diverso, è responsabilità di tale sistema filtrarli o convertirli.
Copia oro da un'unica fonte
In questo scenario, il sistema di consumo non può comunicare direttamente con il sistema autorevole. I motivi alla base di queste limitazioni possono variare, ad esempio:
- Il sistema ufficiale potrebbe non disporre di capacità o disponibilità sufficienti per gestire il volume delle richieste di tutta l'organizzazione.
- La comunicazione tra i sistemi potrebbe essere limitata dai criteri di sicurezza o potrebbe essere impossibile a causa dei limiti dell'infrastruttura.
Per superare queste limitazioni, puoi utilizzare il tuo data warehouse per rendere i dati master disponibili per i sistemi dei consumatori. Quando esegui la migrazione al cloud, BigQuery ti fornisce un repository ad alta disponibilità, può gestire livelli elevati di contemporaneità e può essere ampiamente accessibile all'interno della tua organizzazione, seguendo le regole IAM. Pertanto, BigQuery è un ottimo candidato per l'hosting della tua copia d'oro.
Ti consigliamo di creare una pipeline di dati ELT per leggere i dati master dal sistema ufficiale, caricarli nel datastore e distribuirli ai consumatori. Preferiamo una pipeline ELT rispetto a una pipeline ETL perché utenti diversi potrebbero avere esigenze diverse per lo stesso asset di dati master. Quindi, puoi prima caricare l'asset invariato nel tuo data warehouse, quindi creare trasformazioni specializzate per i consumatori. In Google Cloud, puoi utilizzare Dataflow per creare pipeline in grado di connettersi in modo nativo a BigQuery. Puoi quindi utilizzare Cloud Composer per orchestrare queste pipeline.
Il sistema autorevole rimane la fonte attendibile per l'asset di dati, mentre i dati master copiati nel data warehouse sono indicati come copia d'oro. Il tuo data warehouse non diventa un sistema autorevole.

Ad esempio, nel diagramma il sistema CRM non può richiedere i dati di prodotto direttamente dal sistema PIM. Crei una pipeline ETL che estrae i dati dal sistema PIM, li copia nel data warehouse, esegue le trasformazioni e li distribuisce agli altri sistemi, uno dei quali è il sistema CRM.
Se i tuoi sistemi recuperano i dati master in batch o a fini analitici, BigQuery è la casa ideale per la tua copia digitale. Tuttavia, se la maggior parte degli accessi ai dati master proviene da sistemi che eseguono ricerche a riga singola, puoi prendere in considerazione un repository diverso ottimizzato per tali condizioni, ad esempio Cloud Bigtable. Potresti anche raggiungere un equilibrio utilizzando entrambi i repository. Quello con più traffico contiene la copia dorata. Ti consigliamo di estrarre sempre i dati dal sistema di copia dell'oro e di sincronizzarli con l'altro repository. Puoi farlo utilizzando una pipeline di dati.
Testo dorato da più fonti
Gli scenari precedenti utilizzavano un singolo sistema autorevole per un determinato asset di dati master. Tuttavia, in pratica è possibile utilizzare più sistemi in un'organizzazione per mantenere caratteristiche diverse dello stesso asset. Ad esempio, un sistema PIM può essere la fonte di riferimento per le informazioni tecniche e logistiche dei prodotti, come dimensioni, peso e provenienza. Tuttavia, un sistema di gestione del catalogo dei prodotti può essere la fonte di riferimento per le informazioni sui prodotti correlate alle vendite, come i colori, i canali di vendita, il prezzo e la stagionalità. Inoltre, è comune avere diversi sistemi con attributi sovrapposti per lo stesso asset, ad esempio sistemi che in precedenza non facevano parte di MDM o che erano stati incorporati nell'organizzazione tramite acquisizioni e unioni.
In questi casi, è necessaria una pipeline più complessa per unire i dati master di più origini in un'unica copia dorata archiviata nel data warehouse, come mostrato nel diagramma seguente. I dati vengono quindi distribuiti ai sistemi consumer in modo simile alla sezione precedente. Il tuo data warehouse non è ancora un sistema autorevole, ma semplicemente un repository per la copia dorata dei dati master.
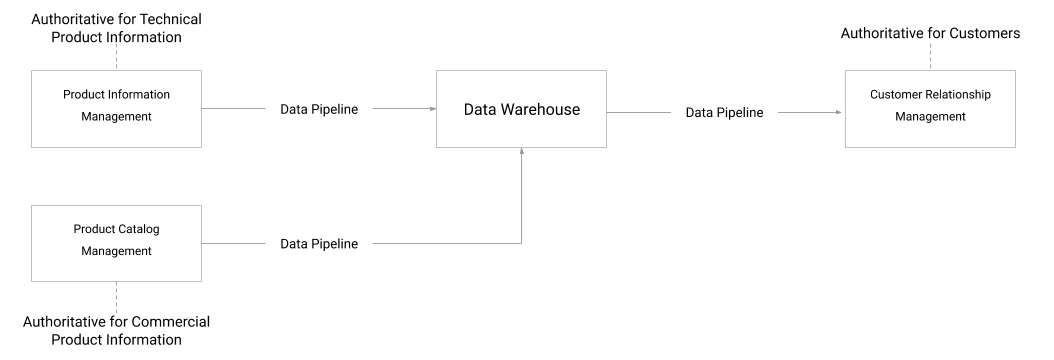
In Google Cloud, Dataflow è ben posizionato come strumento per creare pipeline complesse rappresentate da un grafico aciclico diretto (DAG). Queste pipeline leggono da più origini e scrivono i risultati uniti in BigQuery. Un'altra opzione è utilizzare uno strumento visivo come Cloud Data Fusion per creare la pipeline. Cloud Data Fusion offre inoltre numerosi plug-in per origini dati e sink.
Dimensioni che cambiano lentamente
Gli attributi nelle tabelle delle dimensioni in uno schema a stella o fiocco di neve non dovrebbero mai cambiare o cambiare raramente. Un attributo che non cambia mai è chiamato attributo originale. Alcuni esempi sono la data di nascita e la affidabilità creditizia originale. Se un attributo cambia raramente, la dimensione a cui appartiene è denominata dimensione che cambia lentamente (SCD). Quando cambia una SCD, i dati già nella tabella dei dati devono fare riferimento alla versione precedente della SCD. Pertanto, occorre un metodo per mantenere la cronologia delle SCD.
Quando esegui la migrazione del data warehouse, valuta la possibilità di incorporare un metodo di gestione SCD o di migliorare quelli esistenti:
- Quando evolvi lo schema durante la fase di trasferimento di schema e dati per assicurarti di tenere conto delle SCD.
- Durante la fase di migrazione della pipeline, per assicurarti di conservare la cronologia delle SCD e di utilizzarla in modo riproducibile negli scenari, ad esempio per calcolare gli output dei backfill, rielaborarli a causa delle modifiche logiche e monitorare la derivazione.
Metodi di gestione delle SCD tradizionali
I metodi tradizionali per gestire le modifiche SCD sono indicati come tipi SCD da 0 a 6. Il metodo più comune è il tipo SCD 2, in cui i dati storici vengono monitorati creando colonne aggiuntive nella tabella delle dimensioni. Le colonne aggiunte sono una chiave surrogata e una delle seguenti: una versione, le date di inizio/fine di validità o una data corrente più un flag per indicare quale riga è corrente. Per ulteriori informazioni su come applicare questa e altre tecniche in BigQuery, consulta la sezione Gestire i cambiamenti.
Data engineering funzionale
Un altro metodo per gestire le SCD è stato presentato da Maxime Beauchemin, autore di Apache Airflow, nel suo articolo Functional Data Engineering. Questo articolo propone un paradigma in cui una pipeline di dati è composta da una raccolta di attività deterministiche e idempotenti organizzate in un DAG per riflettere le relative interdipendenze direzionali.
Un'attività è deterministica quando l'output dipende solo dai suoi input e non da qualsiasi stato locale o globale, seguendo quindi i concetti di programmazione funzionale. Un'attività è considerata idempotente quando può essere eseguita più di una volta con gli stessi parametri di input e producendo comunque lo stesso output. In altre parole, non provoca ulteriori effetti collaterali. Un esempio di questo aspetto nel computing è l'operazione REST PUT. L'esecuzione di un'attività è chiamata istanza. Le istanze di attività con input diversi scrivono i dati in partizioni diverse della stessa tabella di output.
Poiché uno degli input per le attività sono le dimensioni, Beauchemin sostiene la creazione di istantanea delle dimensioni ogni volta che viene attivata un'esecuzione ETL. Uno snapshot delle dimensioni duplica tutte le righe delle dimensioni richieste per l'esecuzione ETL insieme a un timestamp. Le tabelle delle dimensioni diventano una raccolta di snapshot in punti diversi. Questi snapshot mantengono la cronologia delle modifiche alle SCD e consentono di eseguire nuovamente qualsiasi istanza di attività e ottenere output coerenti riproducibili.
Questo metodo è diverso da quello tradizionale di gestione delle SCD come SCD di tipo 2. Evita la complessità di gestire le chiavi surrogate e le colonne aggiuntive, riducendo i tempi di progettazione, a scapito di uno spazio di archiviazione relativamente economico. L'articolo riconosce che i due metodi possono coesistere.
Gestione degli SCD in BigQuery
BigQuery supporta gli schemi a stella e a fiocco di neve, incluse le tabelle di dimensioni. Pertanto, si applica uno qualsiasi dei due metodi precedenti.
BigQuery va oltre e promuove la denormalizzazione dello schema con il supporto nativo dei campi nidificati e ripetuti. Questi campi possono essere utilizzati nelle tabelle di fatto quando l'attributo al momento dell'evento è importante. Possono essere utilizzate anche nelle tabelle delle dimensioni per registrare valori storici con un approccio di tipo 2 o snapshot solo per gli attributi che cambiano invece dell'intera riga della dimensione.
Conservazione ed eliminazione dei dati
In situazioni specifiche, potresti voler impedire agli utenti di modificare o eliminare dati in BigQuery. Puoi applicare questa limitazione rimuovendo tali utenti dai ruoli che includono autorizzazioni che consentono queste operazioni. Questi ruoli sono
roles/bigquery.dataOwner,
roles/bigquery.dataEditor
e
roles/bigquery.admin.
Un'altra opzione è creare ruoli IAM personalizzati che non includono le autorizzazioni di modifica ed eliminazione specifiche.
Se è necessario soddisfare le normative per la conservazione dei record elettronici, ti consigliamo di esportare i dati in Cloud Storage e di utilizzare la funzionalità di blocco dei bucket, che può aiutarti a gestire determinate normative di conservazione dei record.
In altre situazioni, potrebbe essere necessario eliminare automaticamente i dati dopo un determinato periodo di tempo. BigQuery può soddisfare questa esigenza tramite una data di scadenza configurabile. Puoi applicare la data di scadenza a un set di dati, a una tabella o a partizioni di tabelle specifiche. La scadenza dei dati non necessari è una misura del controllo dei costi e dell'ottimizzazione dello spazio di archiviazione. Per ulteriori informazioni, consulta le best practice di BigQuery. Per una panoramica più ampia dell'eliminazione dei dati su Google Cloud, consulta questa pagina della documentazione.
Se un cliente Google Cloud determina che una normativa è applicabile alla stessa, deve completare la propria valutazione della conformità rispetto ai requisiti specifici con la supervisione del proprio consulente legale e dell'autorità di regolamentazione corrispondente.
Gestione qualità dati
I processi di gestione della qualità dei dati includono quanto segue:
- Creazione di controlli per la convalida.
- Attivazione del monitoraggio e dei report sulla qualità.
- Supportare la procedura di classificazione per la valutazione del livello di gravità dell'incidente.
- Attivazione dell'analisi delle cause principali e dei suggerimenti per risolvere i problemi relativi ai dati.
- Monitoraggio degli incidenti relativi ai dati.
I consumatori di dati diversi potrebbero avere requisiti di qualità dei dati diversi, quindi è importante documentare le aspettative in termini di qualità dei dati, nonché tecniche e strumenti a supporto del processo di convalida e monitoraggio dei dati. Stabilire processi efficaci per la gestione della qualità dei dati contribuisce a fornire dati più affidabili per l'analisi.
Metadati della qualità
Un data warehouse fornisce ai responsabili delle decisioni l'accesso a una quantità immensa di dati selezionati. Tuttavia, non tutti i dati nel tuo data warehouse devono essere trattati allo stesso modo:
- Nel contesto del processo decisionale, i dati di alta qualità dovrebbero avere una maggiore influenza sulle vostre decisioni, mentre quelli di qualità inferiore dovrebbero avere una minore influenza.
- Nel contesto del monitoraggio della qualità dei dati, i dati di bassa qualità possono essere utilizzati per attivare avvisi automatici o manuali per verificare i processi che lo generano, anche prima che i dati raggiungano il data warehouse.
Inoltre, parti diverse dell'organizzazione potrebbero avere soglie diverse per la qualità dei dati. Ad esempio, i dati di basso livello potrebbero essere perfettamente utilizzabili per lo sviluppo e i test, ma potrebbero essere considerati inutilizzabili per la finanza o per la conformità.
Questa sezione presenta i metadati come meccanismo per fornire ai responsabili delle decisioni ed elabora il contesto necessario per valutare i dati presentati.
Struttura e formato
I metadati sono informazioni strutturate associate a un dato per qualificarlo. Nel contesto della qualità dei dati, i metadati consentono di raccogliere attributi pertinenti come accuratezza, attualità e completezza.
La semantica e gli attributi specifici acquisiti nei metadati della qualità dei dati (DQM) dipendono dal contesto commerciale idoneo. Consigliamo vivamente di adottare un insieme standard di attributi in tutta l'azienda per facilitare la comunicazione e la gestione. L'insieme di attributi che scegli può essere ricavato da standard di settore come il modello di qualità dei dati ISO/IEC 25012:2008 o da consigli di organizzazioni professionali come la community di gestione dei dati (DAMA).
Anche il formato in cui il tuo DQM viene memorizzato e presentato ai responsabili delle decisioni è una considerazione importante. Formati diversi possono essere adatti a diverse attività decisionali. Ad esempio, Moges et al., compila e presenta un elenco dei seguenti formati per DQM:
- Ordinale di livello N: un insieme finito di valori come eccellente, buona e media.
- Intervallo: una scala numerica con limiti inferiore e superiore come 0-100 per rappresentare il livello qualitativo con maggiore flessibilità rispetto a un ordinale.
- Probabilità: la qualità dei dati su una scala 0-1 che indica la probabilità che i dati siano corretti.
- Elemento grafico: code visive come i colori per indicare il livello qualitativo.
Metadati di qualità nel cloud
Tradizionalmente, le aziende non hanno mantenuto un repository DQM coerente, a seconda delle conoscenze condivise. A volte questa conoscenza viene acquisita in repository separati come fogli di lavoro, pagine Intranet e tabelle di database ad hoc. L'impegno a scoprire, cercare, comprendere e gestire queste disparate fonti DQM ostacola la collaborazione e potrebbe superare il loro valore di supporto alle decisioni.
Data Catalog ti offre un modo centralizzato di gestire i tuoi metadati:
- I tag dei metadati personalizzati, noti anche come metadati delle attività, supportano qualsiasi attributo relativo alla qualità dei dati che scegli di far parte delle definizioni standard e li raggruppa in modelli logici che puoi personalizzare per ogni contesto aziendale.
- Supporta tipi enumerati personalizzati per la rappresentazione di attributi ordinali e tipi di stringa e doppio per rappresentare intervalli, probabilità e valori numerici che possono essere utilizzati per rappresentazioni grafiche diverse. Puoi accedere a questi valori dei metadati tramite l'interfaccia utente di Data Catalog o tramite le relative librerie API e client, che ti consentono di creare applicazioni personalizzate per i responsabili delle decisioni.
- Puoi utilizzare l'API Data Catalog nei processi a monte. Quando la qualità dei dati per una determinata origine scende al di sotto di una soglia, il processo tagga i dati di bassa qualità come tali e attiva un avviso prima che raggiunga BigQuery. I dati stessi possono essere inviati a un bucket di quarantena in Cloud Storage per la verifica e, possibilmente, per la correzione e la rielaborazione.
Considerazioni sul DQM
Si potrebbe presumere che, senza DQM, i responsabili delle decisioni abbiano maggiori probabilità di utilizzare dati di bassa qualità e produrre decisioni di scarsa qualità. In realtà, l'aggiunta di DQM al mix può sovraccaricare i responsabili delle decisioni a causa della quantità di informazioni che devono assorbire per generare alternative. La presenza di troppe informazioni può incidere negativamente sulla tempestività e sulla qualità delle decisioni.
Pertanto, è fondamentale addestrare i responsabili delle decisioni sulla semantica e sulle best practice di DQM. Moges et al. suggeriscono che fornire DQM e formazione è vantaggioso per le attività critiche in cui le conseguenze dell'utilizzo di dati di bassa qualità sono elevate. Tuttavia, il DQM potrebbe essere controproducente per le attività che richiedono un'elevata efficienza o quando il personale non è adeguatamente formato.
Controllo
Le organizzazioni devono essere in grado di controllare i propri sistemi per assicurarsi che funzionino come previsto. Il monitoraggio, il controllo e il monitoraggio aiutano i team di sicurezza a raccogliere dati, identificare le minacce e intervenire su tali minacce prima che causino la perdita o i danni commerciali. È importante eseguire controlli regolari, perché questi controlli verificano l'efficacia dei controlli al fine di mitigare rapidamente le minacce e valutare lo stato complessivo della sicurezza. Il controllo può anche essere necessario per dimostrare la conformità normativa con i revisori esterni.
Un primo passaggio per garantire un corretto controllo dell'accesso ai dati è controllare periodicamente gli utenti e i gruppi associati al progetto Google Cloud e ai singoli set di dati BigQuery. Questi utenti devono essere proprietari o amministratori oppure un ruolo più restrittivo è sufficiente per le loro mansioni lavorative? È anche importante controllare chi è in grado di modificare i criteri IAM sui tuoi progetti.
Un secondo passaggio nell'analisi dei log è rispondere a domande come "Chi ha fatto cosa, dove e quando?" con dati e metadati di BigQuery.
- Per i tuoi dati, BigQuery include per impostazione predefinita in Cloud Logging due flussi di log immutabili: attività di amministrazione e log di controllo dell'accesso ai dati.
- Per i tuoi metadati, Data Catalog supporta anche i flussi di audit logging, sebbene a differenza di BigQuery, il logging degli accessi ai dati deve essere abilitato manualmente.
I log delle attività di amministrazione contengono voci di log per le chiamate dei log o altre azioni amministrative che modificano la configurazione o i metadati delle risorse. Ad esempio, la creazione di nuovi account di servizio o le modifiche alle autorizzazioni IAM, come la concessione di un nuovo accesso in lettura agli utenti ai set di dati BigQuery, vengono registrate nei log delle attività di amministrazione.
I log di accesso ai dati registrano le chiamate API autenticate dall'utente che creano, modificano o leggono i dati forniti dall'utente. Ad esempio, i log di accesso ai dati registrano se un utente ha eseguito una query su un set di dati BigQuery o ha richiesto i risultati della query. L'attribuzione delle query a un utente anziché a un account di servizio facilita il controllo dell'accesso ai dati.
Per entrambi i tipi di log, puoi creare avvisi di Cloud Monitoring che si attivano in determinate condizioni da te specificate. Quando vengono attivati, questi avvisi possono inviare notifiche attraverso diversi canali, inclusi email, SMS, servizi di terze parti e persino webhook a un URL personalizzato.
Tieni presente che gli audit log potrebbero includere informazioni sensibili, quindi è opportuno limitare l'accesso ai log. L'accesso agli audit log può essere limitato utilizzando i ruoli IAM.
Ti consigliamo di esportare gli audit log di BigQuery da Cloud Logging in un set di dati BigQuery per i seguenti motivi:
- Cloud Logging conserva gli audit log solo per un periodo di conservazione dei log limitato. L'esportazione in un'altra posizione di archiviazione protetta, come BigQuery o Cloud Storage, ti consente di mantenere un periodo di conservazione a lungo termine.
- In BigQuery puoi eseguire query SQL sui log, abilitando i filtri complessi per l'analisi.
- Puoi anche creare dashboard utilizzando strumenti di visualizzazione come Looker Studio.
Per ulteriori informazioni, consulta questo post del blog Best practice per lavorare con Google Cloud Audit Logs.
Quali sono i passaggi successivi?
- Guarda il video e scopri di più sulle best practice in Organizzazione delle risorse BigQuery
- Esplora architetture di riferimento, diagrammi, tutorial e best practice su Google Cloud. Dai un'occhiata alla nostra serie di framework dell'architettura in Cloud Architecture Center.