Specificare colonne nidificate e ripetute negli schemi delle tabelle
Questa pagina descrive come definire uno schema di tabella con colonne nidificate e ripetute in BigQuery. Per una panoramica degli schemi delle tabelle, vedi Specifica di uno schema.
Definisci colonne nidificate e ripetute
Per creare una colonna con dati nidificati, imposta il tipo di dati della colonna su
RECORD nello schema. È possibile accedere a un RECORD come tipo
STRUCT
in GoogleSQL. Un STRUCT è un contenitore di campi ordinati.
Per creare una colonna con dati ripetuti, imposta la
modalità della colonna su REPEATED nello schema.
È possibile accedere a un campo ripetuto come tipo
ARRAY in
GoogleSQL.
Una colonna RECORD può avere la modalità REPEATED, che viene rappresentata come un array di tipi STRUCT. Inoltre, un campo all'interno di un record può essere ripetuto, il che
è rappresentato come un STRUCT che contiene un ARRAY. Un array non può contenere
direttamente un altro array. Per saperne di più, consulta la sezione
Dichiarare un tipo di ARRAY.
Limitazioni
Gli schemi nidificati e ripetuti sono soggetti alle seguenti limitazioni:
- Uno schema non può contenere più di 15 livelli di tipi
RECORDnidificati.
Le colonne di tipo - Il limite massimo di profondità di annidamento è di 15 livelli. Questo limite è
indipendente dal fatto che i
RECORDsiano scalari o basati su array (ripetuti).
RECORD possono contenere tipi RECORD nidificati, chiamati anche
record secondari.Il tipo RECORD non è compatibile con UNION, INTERSECT, EXCEPT DISTINCT e SELECT DISTINCT.
Schema di esempio
L'esempio seguente mostra dati nidificati e ripetuti di esempio. Questa tabella contiene informazioni sulle persone. È composto dai seguenti campi:
idfirst_namelast_namedob(data di nascita)addresses(un campo nidificato e ripetuto)addresses.status(attuale o precedente)addresses.addressaddresses.cityaddresses.stateaddresses.zipaddresses.numberOfYears(anni all'indirizzo)
Il file di dati JSON avrebbe il seguente aspetto. Nota che la colonna degli indirizzi
contiene un array di valori (indicato da [ ]). I più indirizzi
nell'array sono i dati ripetuti. I più campi all'interno di ogni indirizzo sono
i dati nidificati.
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
Lo schema di questa tabella è il seguente:
[ { "name": "id", "type": "STRING", "mode": "NULLABLE" }, { "name": "first_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "last_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "dob", "type": "DATE", "mode": "NULLABLE" }, { "name": "addresses", "type": "RECORD", "mode": "REPEATED", "fields": [ { "name": "status", "type": "STRING", "mode": "NULLABLE" }, { "name": "address", "type": "STRING", "mode": "NULLABLE" }, { "name": "city", "type": "STRING", "mode": "NULLABLE" }, { "name": "state", "type": "STRING", "mode": "NULLABLE" }, { "name": "zip", "type": "STRING", "mode": "NULLABLE" }, { "name": "numberOfYears", "type": "STRING", "mode": "NULLABLE" } ] } ]
Specifica delle colonne nidificate e ripetute nell'esempio
Per creare una nuova tabella con le colonne nidificate e ripetute precedenti, seleziona una delle seguenti opzioni:
Console
Specifica la colonna addresses nidificata e ripetuta:
Nella console Google Cloud , apri la pagina BigQuery.
Nel riquadro a sinistra, fai clic su Explorer:

Se non vedi il riquadro a sinistra, fai clic su Espandi riquadro a sinistra per aprirlo.
Nel riquadro Explorer, espandi il progetto, fai clic su Set di dati e poi seleziona un set di dati.
Nel riquadro dei dettagli, fai clic su Crea tabella.
Nella pagina Crea tabella, specifica i seguenti dettagli:
- Per Origine, seleziona Tabella vuota nel campo Crea tabella da.
Nella sezione Destinazione, specifica i seguenti campi:
- Per Set di dati, seleziona il set di dati in cui vuoi creare la tabella.
- In Tabella, inserisci il nome della tabella che vuoi creare.
Per Schema, fai clic su Aggiungi campo e inserisci lo schema della tabella seguente:
- In Nome campo, inserisci
addresses. - Per Type (Tipo), seleziona RECORD (REGISTRAZIONE).
- Per Modalità, scegli REPEATED.
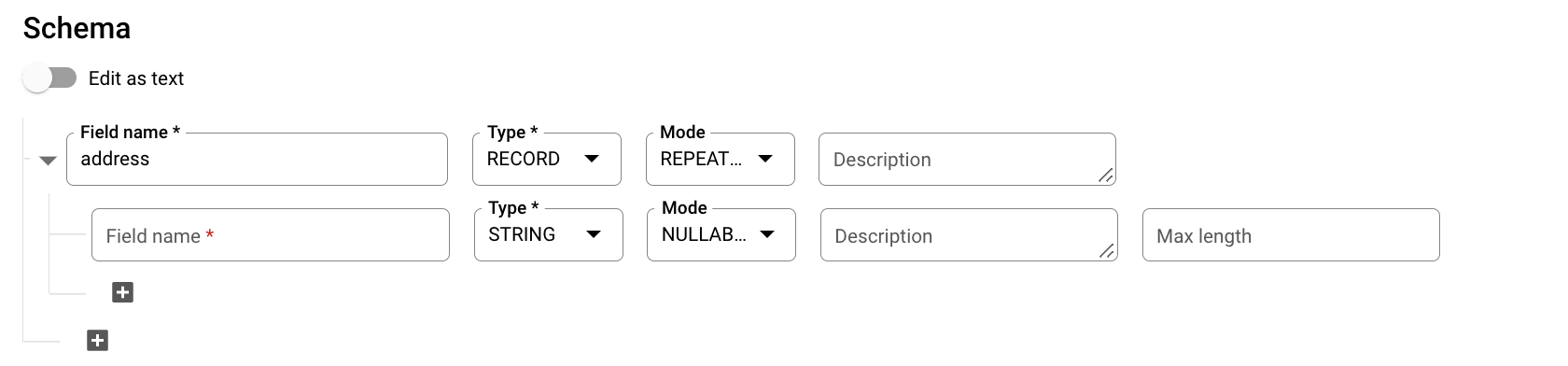
Specifica i seguenti campi per un campo nidificato:
- Nel campo Nome campo, inserisci
status. - In Tipo, scegli STRING.
- In Modalità, lascia il valore impostato su NULLABLE.
Fai clic su Aggiungi campo per aggiungere i seguenti campi:
Nome campo Tipo Modalità addressSTRINGNULLABLEcitySTRINGNULLABLEstateSTRINGNULLABLEzipSTRINGNULLABLEnumberOfYearsSTRINGNULLABLE
In alternativa, fai clic su Modifica come testo e specifica lo schema come array JSON.
- Nel campo Nome campo, inserisci
- In Nome campo, inserisci
SQL
Utilizza l'istruzione CREATE TABLE.
Specifica lo schema utilizzando l'opzione
colonna:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione:
CREATE TABLE IF NOT EXISTS mydataset.mytable ( id STRING, first_name STRING, last_name STRING, dob DATE, addresses ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> ) OPTIONS ( description = 'Example name and addresses table');
Fai clic su Esegui.
Per saperne di più su come eseguire le query, consulta Eseguire una query interattiva.
bq
Per specificare la colonna addresses nidificata e ripetuta in un file di schema JSON,
utilizza un editor di testo per creare un nuovo file. Incolla la definizione dello schema di esempio
mostrata sopra.
Dopo aver creato il file dello schema JSON, puoi fornirlo tramite lo strumento a riga di comando bq. Per ulteriori informazioni, vedi Utilizzare un file di schema JSON.
Vai
Prima di provare questo esempio, segui le istruzioni di configurazione di Go nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Go.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Node.js
Prima di provare questo esempio, segui le istruzioni di configurazione di Node.js nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Node.js.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Inserisci i dati nelle colonne nidificate nell'esempio
Utilizza le seguenti query per inserire record di dati nidificati in tabelle con colonne di tipo di dati RECORD.
Esempio 1
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22", ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> [("current","123 First Avenue","Seattle","WA","11111","1")])
Esempio 2
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22",[("current","123 First Avenue","Seattle","WA","11111","1")])
Eseguire query su colonne nidificate e ripetute
Per selezionare il valore di un ARRAY in una posizione specifica, utilizza un operatore di indice di array.
Per accedere agli elementi in un STRUCT, utilizza
l'operatore punto.
Il seguente esempio seleziona il nome, il cognome e il primo indirizzo
elencati nel campo addresses:
SELECT first_name, last_name, addresses[offset(0)].address FROM mydataset.mytable;
Il risultato è il seguente:
+------------+-----------+------------------+ | first_name | last_name | address | +------------+-----------+------------------+ | John | Doe | 123 First Avenue | | Jane | Doe | 789 Any Avenue | +------------+-----------+------------------+
Per estrarre tutti gli elementi di un ARRAY, utilizza l'operatore UNNEST con un CROSS JOIN.
Il seguente esempio seleziona nome, cognome, indirizzo e stato per
tutti gli indirizzi non situati a New York:
SELECT first_name, last_name, a.address, a.state FROM mydataset.mytable CROSS JOIN UNNEST(addresses) AS a WHERE a.state != 'NY';
Il risultato è il seguente:
+------------+-----------+------------------+-------+ | first_name | last_name | address | state | +------------+-----------+------------------+-------+ | John | Doe | 123 First Avenue | WA | | John | Doe | 456 Main Street | OR | | Jane | Doe | 321 Main Street | NJ | +------------+-----------+------------------+-------+
Modificare colonne nidificate e ripetute
Dopo aver aggiunto una colonna nidificata o una colonna nidificata e ripetuta alla definizione dello schema di una tabella, puoi modificare la colonna come faresti con qualsiasi altro tipo di colonna. BigQuery supporta in modo nativo diverse modifiche dello schema, ad esempio l'aggiunta di un nuovo campo nidificato a un record o l'allentamento della modalità di un campo nidificato. Per maggiori informazioni, consulta Modifica degli schemi delle tabelle.
Quando utilizzare colonne nidificate e ripetute
BigQuery offre prestazioni migliori quando i dati sono denormalizzati. Anziché preservare uno schema relazionale come uno schema a stella o a fiocco di neve, denormalizza i dati e sfrutta le colonne nidificate e ripetute. Le colonne nidificate e ripetute possono mantenere le relazioni senza l'impatto sulle prestazioni della conservazione di uno schema relazionale (normalizzato).
Ad esempio, un database relazionale utilizzato per monitorare i libri della biblioteca probabilmente manterrà
tutte le informazioni sull'autore in una tabella separata. Una chiave come author_id verrebbe
utilizzata per collegare il libro agli autori.
In BigQuery, puoi conservare la relazione tra libro e autore senza creare una tabella separata per l'autore. Invece, crei una colonna autore e nidifichi al suo interno campi come nome, cognome, data di nascita e così via. Se un libro ha più autori, puoi ripetere la colonna dell'autore nidificata.
Supponiamo di avere la seguente tabella mydataset.books:
+------------------+------------+-----------+ | title | author_ids | num_pages | +------------------+------------+-----------+ | Example Book One | [123, 789] | 487 | | Example Book Two | [456] | 89 | +------------------+------------+-----------+
Hai anche la seguente tabella, mydataset.authors, con informazioni complete per ogni ID autore:
+-----------+-------------+---------------+ | author_id | author_name | date_of_birth | +-----------+-------------+---------------+ | 123 | Alex | 01-01-1960 | | 456 | Rosario | 01-01-1970 | | 789 | Kim | 01-01-1980 | +-----------+-------------+---------------+
Se le tabelle sono di grandi dimensioni, l'unione regolare potrebbe richiedere molte risorse. A seconda della tua situazione, potrebbe essere utile creare una singola tabella contenente tutte le informazioni:
CREATE TABLE mydataset.denormalized_books( title STRING, authors ARRAY<STRUCT<id INT64, name STRING, date_of_birth STRING>>, num_pages INT64) AS ( SELECT title, ARRAY_AGG(STRUCT(author_id, author_name, date_of_birth)) AS authors, ANY_VALUE(num_pages) FROM mydataset.books, UNNEST(author_ids) id JOIN mydataset.authors ON id = author_id GROUP BY title );
La tabella risultante sarà simile alla seguente:
+------------------+-------------------------------+-----------+
| title | authors | num_pages |
+------------------+-------------------------------+-----------+
| Example Book One | [{123, Alex, 01-01-1960}, | 487 |
| | {789, Kim, 01-01-1980}] | |
| Example Book Two | [{456, Rosario, 01-01-1970}] | 89 |
+------------------+-------------------------------+-----------+
BigQuery supporta il caricamento di dati nidificati e ripetuti da formati di origine che supportano schemi basati su oggetti, come file JSON, file Avro, file di esportazione Firestore e file di esportazione Datastore.
Rimuovere i record duplicati in una tabella
La seguente query utilizza la funzione row_number()
per identificare i record duplicati che hanno gli stessi valori per
last_name e first_name negli esempi utilizzati e li ordina in base a dob:
CREATE OR REPLACE TABLE mydataset.mytable AS ( SELECT * except(row_num) FROM ( SELECT *, row_number() over (partition by last_name, first_name order by dob) row_num FROM mydataset.mytable) temp_table WHERE row_num=1 )
Sicurezza delle tabelle
Per controllare l'accesso alle tabelle in BigQuery, vedi Controllare l'accesso alle risorse con IAM.
Passaggi successivi
- Per inserire e aggiornare righe con colonne nidificate e ripetute, consulta la sezione Sintassi Data Manipulation Language (DML).