Dicas de otimização de desempenho do MySQL
A otimização do desempenho é um aspecto essencial do gerenciamento de qualquer banco de dados. A otimização do desempenho pode ser realizada em todas as etapas do gerenciamento do banco de dados, desde a escolha dos componentes de hardware e software para hospedagem dos servidores de banco de dados até a configuração do esquema e do design do modelo de dados. Neste documento, você verá dicas de otimização de desempenho para bancos de dados MySQL na nuvem, mais especificamente do Cloud SQL para MySQL, incluindo práticas recomendadas para instanciar novos bancos de dados e otimizar os atuais.
Artigos relacionados
Considerações sobre hardware
As configurações de hardware são uma consideração importante para o desempenho do banco de dados. É importante ter um bom entendimento do número de usuários ativos e simultâneos de um aplicativo, do tamanho do banco de dados e dos índices e da latência esperada do aplicativo ou serviço antes de definir as configurações de hardware. Veja a seguir algumas considerações importantes sobre hardware:
Unidade de processamento central (CPU)
A capacidade de processamento é um dos fatores mais importantes em um sistema de banco de dados de alto desempenho. O número de conexões/usuários/linhas simultâneos determina o número de núcleos necessários para processar solicitações de banco de dados. A CPU alocada ao banco de dados precisa processar a carga de trabalho normal + a carga de trabalho extrema (extrema) para que os aplicativos sejam executados em níveis ideais.
No caso do Cloud SQL, a oferta MySQL totalmente gerenciada do Google Cloud, a CPU é alocada na forma de CPU virtual (vCPU, na sigla em inglês). O número de vCPUs alocadas em um banco de dados determina a quantidade de memória e de capacidade de rede de uma instância de banco de dados, já que cada vCPU tem uma quantidade máxima de memória alocada a ela e até mesmo a capacidade de processamento da rede varia com base no número de vCPUs. O Cloud SQL fornece flexibilidade para escalonar o número de vCPUs para a instância, facilitando o cumprimento dos requisitos de capacidade de memória e de rede do aplicativo.
Memória
Uma consideração importante para determinar a quantidade de memória a ser alocada a um banco de dados é garantir que o conjunto de trabalho se encaixe no pool de buffers. Um conjunto de trabalho são os dados usados ativamente pelo banco de dados a qualquer momento. A memória alocada precisa ser suficiente para manter esse conjunto de trabalho ou dados acessados com frequência, que geralmente consistem em dados de banco de dados, índices, buffers de sessão, cache de dicionário e tabelas de hash. Uma maneira de verificar se a memória é suficiente é verificar o status de leitura do disco no banco de dados. O ideal é que as leituras de disco sejam menores ou muito mínimas em condições normais de carga de trabalho.
Em caso de alocação de memória insuficiente para a instância, a instância pode ter problemas de Memória insuficiente, que fazem com que a instância do banco de dados seja reiniciada e leve à inatividade do banco de dados ou do aplicativo.
Armazenamento
O armazenamento do banco de dados é outro componente que desempenha um papel importante na otimização de desempenho. O Cloud SQL oferece dois tipos de armazenamento
- SSD (padrão)
- HDD
O SSD oferece um desempenho e uma capacidade de processamento muito melhores do que o HDD. Por isso, sempre escolha SSD para melhor desempenho, especialmente para cargas de trabalho de produção.
As operações de entrada/saída por segundo (IOPs, na sigla em inglês) de leitura e gravação alocadas à instância dependem da quantidade de armazenamento alocada durante a criação da instância. Quanto maior o tamanho do disco, maiores as IOPs de leitura e gravação. Portanto, é aconselhável criar instâncias com um tamanho de dados mais alto para um melhor desempenho das IOPs. A captura de tela a seguir do console do Google Cloud mostra o resumo dos recursos (incluindo a capacidade máxima) alocados para a instância do banco de dados no momento da criação, ajudando os usuários a confirmar e entender exatamente como o banco de dados será configurado depois que ele for instanciado.
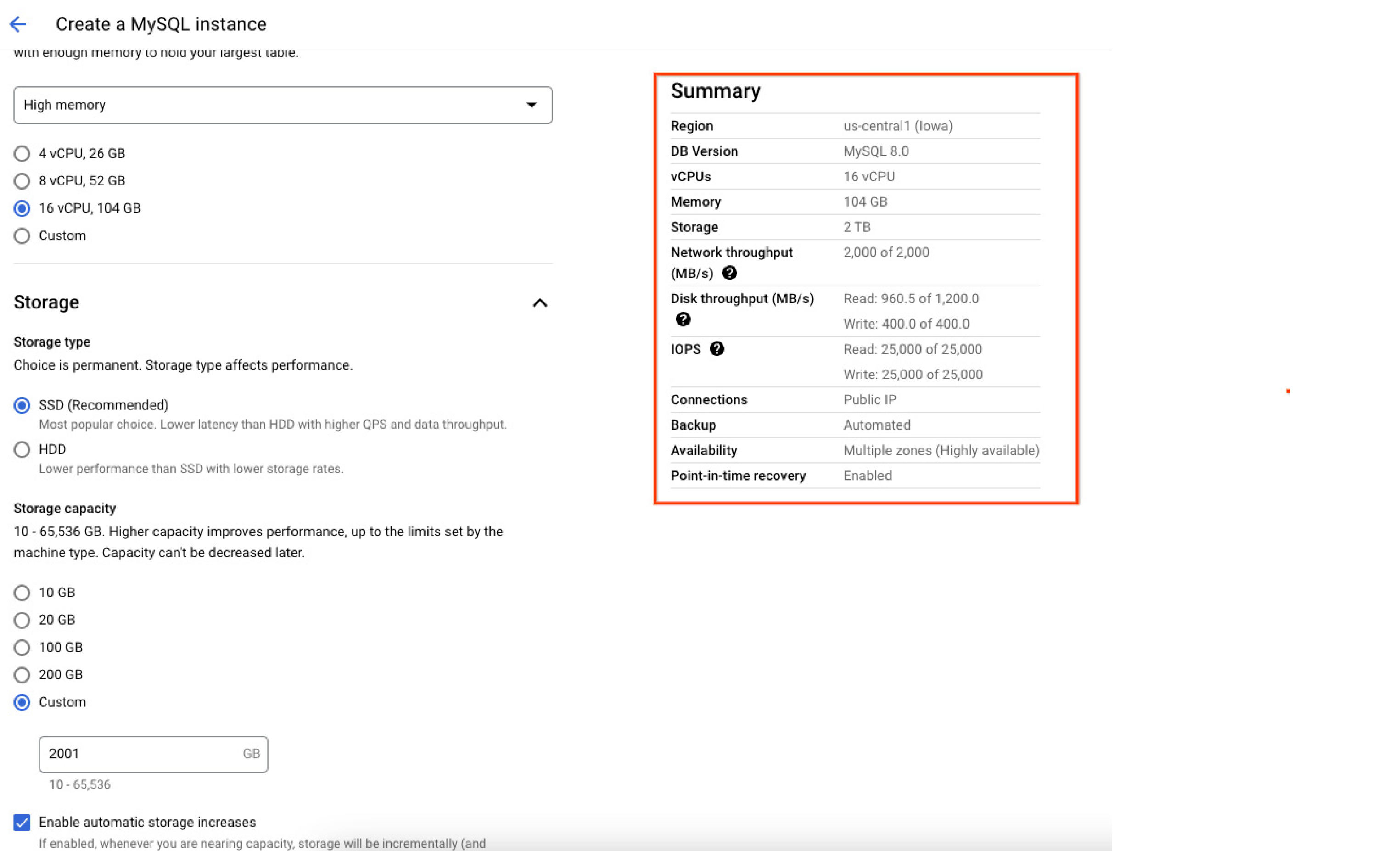
Região
Uma das maneiras de reduzir a latência da rede é escolher a região da instância mais próxima do aplicativo ou serviço. O Cloud SQL para MySQL está disponível em todas as regiões do Google Cloud, o que facilita instanciar um banco de dados o mais próximo possível dos usuários finais.
Escalonamento flexível
O Cloud SQL oferece uma maneira fácil de aumentar ou diminuir os recursos (CPU, memória ou armazenamento) atribuídos a uma instância de banco de dados. Isso pode ser útil para cargas de trabalho com diferentes requisitos de recursos. Por exemplo, os usuários podem aumentar (escalonar verticalmente) os recursos durante o período de maior requisito de carga de trabalho e, em seguida, reduzir os recursos quando a situação de pico da carga de trabalho terminar.
Configurações do MySQL
Esta seção contém as práticas recomendadas para que as configurações do banco de dados MySQL melhorem o desempenho.
Versão
Escolha a versão mais recente do MySQL ao criar um novo banco de dados. As versões mais recentes têm correções de bugs e otimizações para melhor desempenho em comparação com versões mais antigas. O CloudSQL fornece a versão mais recente do MySQL disponível no mercado e a torna a versão padrão ao criar um novo banco de dados. Veja mais detalhes em Versões do MySQL compatíveis com o Cloud SQL.
Tamanho do pool de buffer do InnoDB
Para instâncias do MySQL, o InnoDB é o único mecanismo de armazenamento compatível. O tamanho do pool de buffer do Innodb é o primeiro parâmetro que um usuário define para ter o desempenho ideal. O pool de buffer é a área de memória alocada para armazenar caches de tabelas, caches de índices e dados modificados antes da limpeza e outras estruturas internas, como o índice de hash adaptativo (AHI, na sigla em inglês).
O Cloud SQL define o valor padrão de aproximadamente 72% da memória da instância a ser alocada para o pool de buffer do InnoDB com base no tamanho da instância. Os valores padrão variam de acordo com os tamanhos da instância. Veja mais detalhes sobre diferentes tamanhos de instância nas configurações do pool de buffer. O Cloud SQL oferece a flexibilidade de modificar o tamanho do pool de buffer de acordo com as necessidades do aplicativo usando sinalizações de banco de dados.
O pool de buffers deve ser dimensionado para que memória livre suficiente esteja disponível na instância para buffer de sessão, cache de dicionário, tabelas performance_schema (se ativadas), além do pool de buffer do InnoDB.
Os usuários podem verificar as leituras de disco da instância para identificar quantos dados estão sendo lidos nos discos em relação às leituras atendidas pelo pool de buffer. Se houver mais leituras de disco, aumentar o tamanho do pool de buffer e a memória da instância melhorará o desempenho das consultas de leitura.
Tamanho do arquivo de registro do InnoDB/"redo"
O arquivo de registro do InnoDB ou "redo" registra as mudanças nos dados da tabela. O tamanho do arquivo de registro do InnoDB define o tamanho do único arquivo de registro "redo".
No caso de cargas de trabalho de gravação pesadas com um tamanho de registro "redo" mais alto, você tem mais espaço para gravações sem ter que fazer atividade de limpeza de checkpoint frequente e salvar E/S de disco, melhorando o desempenho de gravação. O tamanho total do registro "redo" que pode ser calculado como (innodb_log_file_size * innodb_log_file_size) deve ser suficiente para acomodar pelo menos 1-2 horas de dados de gravação durante períodos movimentados de acesso ao banco de dados.
O Cloud SQL define um valor padrão de 512 MB. O Cloud SQL também oferece a flexibilidade de aumentar o tamanho do arquivo de registros do InnoDB usando sinalizações do banco de dados.
OBSERVAÇÃO: aumentar o valor do tamanho do arquivo de registros do InnoDB aumenta o tempo de recuperação de falhas.
Durabilidade
A sinalização innodb_flush_log_at_trx_commit controla com que frequência os dados de registro são limpos no disco e se eles são limpos para cada confirmação de transação.
É possível aumentar o desempenho de gravação em réplicas de leitura alterando os valores de innodb_flush_log_at_trx_commit para 0 ou 2.
O Cloud SQL não oferece suporte à alteração da configuração de durabilidade no Cloud SQL primário. No entanto, o Cloud SQL permite alterar a sinalização em réplicas de leitura. Reduzir a durabilidade em réplicas de leitura melhora o desempenho da gravação nas réplicas. Isso ajuda a solucionar o atraso de replicação nas réplicas. Saiba mais sobre innodb_flush_log_at_trx_commit.
Tamanho do buffer de registro do InnoDB
O tamanho do buffer de registro do InnoDB é a quantidade de buffer que o InnoDB usa para gravar no arquivo de registros (registro "redo").
Se as transações (inserções, atualizações ou exclusões) no banco de dados forem grandes e o buffer usado for maior que 16 MB, o InnoDB precisará fazer a E/S de disco antes de confirmar a transação, o que afeta o desempenho. Para evitar E/S de disco, aumente o valor de innodb_log_buffer_size.
O Cloud SQL define um valor padrão de 16 MB para o tamanho do buffer de registros do InnoDB. A variável de status do MySQL innodb_log_waits mostra o número de vezes que o innodb_log_buffer_size foi pequeno e que o InnoDB precisou esperar a limpeza ser feita antes de confirmar a transação. Se o valor de innodb_log_waits for maior que 0 e estiver aumentando e, em seguida, aumente o valor de innodb_log_buffer_size usando as sinalizações do banco de dados para melhorar o desempenho. O valor de innodb_log_buffer_size e innodb_log_waits pode ser identificado executando as seguintes consultas no shell do MySQL (CLI). Essas consultas mostram o valor de variáveis de status e de variáveis globais no MySQL.
MOSTRAR VARIÁVEIS GLOBAIS, COMO "innodb_log_buffer_size";
MOSTRAR STATUS GLOBAL, como "innodb_log_waits";
Capacidade de E/S do InnoDB
A capacidade de E/S do InnoDB define o número de IOPs disponíveis para tarefas em segundo plano, como limpeza de página no pool de buffers e mesclagem de dados no buffer de alterações.
O Cloud SQL define o valor padrão de 5.000 para innodb_io_capacity e 10.000 para innodb_io_capacity.
Esse padrão funciona melhor para a maioria das cargas de trabalho, mas se a carga de trabalho tiver muitas alterações de gravação ou não aplicadas na instância, e se você tiver IOPs suficientes disponíveis na instância, considere aumentar o innodb_io_capacity e innodb_io_capacity. O valor das mudanças aplicadas pode ser encontrado usando a seguinte consulta no shell do MySQL:
mysql -e 'mostrar status do mecanismo do InnoDB \G;' | grep Ibuf
Buffers de sessão
Buffers de sessão são a memória alocada para sessões individuais. Se o aplicativo ou as consultas incluírem muitas inserções, atualizações, classificações e mesclagens e precisar de buffers mais altos, definir valores de buffer altos durante a execução da consulta em uma sessão específica vai evitar a sobrecarga do desempenho. Os usuários podem evitar a alocação excessiva de buffer em níveis globais, o que aumenta os valores de todas as conexões e, por sua vez, aumenta o uso total da memória na instância. Alterar o valor padrão dos seguintes buffers ajuda a melhorar o desempenho da consulta. Esses valores podem ser alterados usando sinalizações do banco de dados.
Esses são os valores de buffer por sessão. O aumento dos limites pode afetar todas as conexões e acabar aumentand o uso geral da memória.
Table_open_cache e Table_definition_cache
Se você tiver muitas tabelas (em excesso de milhares) na instância de banco de dados (em um ou vários bancos de dados), aumente os valores do table_open_cache e table_open_cache para melhorar a velocidade de abrir as tabelas.
Table_definition_cache acelera a abertura de tabelas e tem apenas uma entrada por tabela. O cache de definição de tabela ocupa menos espaço e não usa descritores de arquivos. Se o número de instâncias de tabela no cache de objetos do dicionário exceder o limite do table_definition_cache, um mecanismo LRU começará a marcar instâncias da tabela para despejo e, por fim, os removerá do cache de objetos do dicionário para dar espaço à nova definição de tabela. Esse processo é executado sempre que um novo espaço de tabela é aberto. Somente espaços de tabela inativos são fechados. Esse processo de remoção retarda a abertura de tabelas.
Table_open_cache define o número de tabelas abertas para todas as linhas de execução. É possível verificar se é necessário aumentar o cache da tabela verificando a variável de status Opened_tables. Se o valor de Opened_tables for grande e você não usar FLUSH TABLES com frequência, considere aumentar o valor da variável table_open_cache.
Table_open_cache e Table_open_cache podem ser definidos como o número real de tabelas na instância . Saiba mais sobre o recomendador de alta quantidade de tabelas abertas do Cloud SQL.
Observação: o Cloud SQL oferece flexibilidade para alterar esses valores.
Recomendações de esquema
Sempre definir chaves primárias
Definir chaves primárias para a tabela organiza fisicamente os dados para facilitar a pesquisa, a recuperação e a ordenação dos registros e, portanto, melhora o desempenho.
De preferência, as chaves primárias incrementadas automaticamente com valor inteiro são ideais para sistemas OLTP.
A ausência de chaves primárias também é um dos principais motivos para o atraso de replicação em cenários de replicação baseada em linhas.
Criar índices
A criação de índices ajuda na recuperação mais rápida dos dados e, portanto, melhora o desempenho das consultas de leitura. Crie índices para as colunas usadas nas cláusulas WHERE, ORDER BY e GROUP BY das consultas.
OBSERVAÇÃO: índices em excesso ou não utilizados também podem prejudicar o desempenho do banco de dados.
Práticas recomendadas para otimização de desempenho
Executar comparativos
Execute testes de desempenho ou comparações para ver se a configuração é ideal ou se pode ser melhorada ainda mais ajustando as configurações de hardware, banco de dados do MySQL ou design de esquema. Mude um parâmetro por vez e analise os resultados comparados para ver se há alguma melhoria.
Pooling de conexão
O pool de conexões é uma técnica de criação e gerenciamento de um pool de conexões prontas para uso por qualquer processo que precise delas. O pooling de conexões pode aumentar muito o desempenho do aplicativo e, ao mesmo tempo, reduzir o uso geral de recursos. Revise os detalhes sobre como gerenciar conexões no aplicativo, incluindo contagem de conexões e tempo limite.
Distribuir a carga de trabalho de leitura para réplicas de leitura
Réplicas de leitura (várias na zona) podem ser usadas para descarregar a carga de trabalho de leitura a partir da instância principal. Isso reduz a sobrecarga ou a carga na instância principal e, por sua vez, melhora o desempenho dela. Além disso, há mais recursos disponíveis para consultas de leitura na réplica de leitura.
O ProxySQL, um proxy MySQL de código aberto de alto desempenho capaz de rotear consultas do banco de dados, pode ser usado para dimensionar horizontalmente o banco de dados do Cloud SQL para MySQL.
Evitar consultas de longa duração
As consultas que ficam em execução por vários minutos ou horas são conhecidas por causar a degradação do desempenho.
- Os registros "undo" são usados para armazenar a versão antiga das linhas alteradas para reverter a transação e também para fornecer a leitura consistente (snapshot de dados) em uma transação. Esses registros "undo" são armazenados na forma de listas vinculadas com versões recentes que direcionam para as mais antigas, que direcionam para as mais antigas e assim por diante. As transações de longa duração tendem a atrasar a limpeza dos registros "undo" e, portanto, aumentar a lista de registros "undo". O InnoDB precisa percorrer o alto volume de registros "undo" e uma lista longa de links, o que reduz o desempenho.
- Consultas de longa duração também consomem recursos (como memória, buffers, bloqueios), que não são liberados por muito tempo e afetam as outras consultas devido à falta de recursos.
Evitar grandes transações
Muitas alterações de registro (atualização, exclusão, inserção) em uma única transação manterão recursos (bloqueios, buffer) para muitos registros. Isso pode sobrecarregar os buffers de registro, resultando em E/S de disco. As consultas restantes precisarão aguardar a liberação dos recursos ou dos bloqueios. O resultado disso é levar muitos dados para o pool de buffer, evitando o uso do pool. A reversão dessas transações grandes também prejudica o desempenho do banco de dados. Para resolver isso, a recomendação é dividir transações grandes em transações menores e mais rápidas.
Otimizar consultas
Sempre otimize as consultas para ter os melhores resultados, ou seja, menos recursos e execução mais rápida. Revise as recomendações de ajuste de consulta do MySQL.
Ferramentas para ajuste de desempenho
Monitoramento
Monitoramento
O Cloud SQL oferece painéis predefinidos de vários produtos, incluindo um painel de monitoramento padrão do Cloud SQL. Os usuários podem usar esse painel para monitorar a integridade eral das instâncias principal e réplica. Os usuários também podem criar os próprios painéis personalizados para exibir métricas de interesse deles. Ao usar esses painéis e métricas, é possível identificar e resolver vários gargalos de desempenho, como alto uso de CPU ou memória, usando recomendações listadas anteriormente. Os alertas também podem ser configurados com base nessas métricas.
Sinalização de consulta lenta
Sinalização de consulta lenta
A flag de consultas lentas pode ser ativada na instância do Cloud SQL para MySQL para identificar consultas que estão levando mais tempo do que o long_query_time para execução. Essas consultas lentas podem passar por mais análises e ajustes para melhorar o desempenho. Saiba como ativar e verificar as consultas lentas de instâncias do Cloud SQL.
esquema de desempenho
esquema de desempenho
O Esquema de desempenho fornece monitoramento de baixo nível da instância do MySQL. O esquema de desempenho pode ser ativado em uma instância do Cloud SQL para MySQL com memória maior que 15 GB. Os relatórios do esquema SYS fornecem vários relatórios para identificar gargalos, esperas, índices ausentes, uso de memória etc.
Query Insights
Query Insights
O Query Insights é um recurso nativo do Cloud SQL em que as consultas podem ganhar um perfil e serem analisadas para melhorar o desempenho das consultas. O recurso é compatível com monitoramento intuitivo e fornece informações de diagnóstico que ajudam você a ir além da detecção para identificar a causa raiz dos problemas de desempenho.
Recomendações de desempenho
Recomendações de desempenho
O recomendador de alta quantidade de tabelas do Cloud SQL também é um recurso nativo do Cloud SQL que oferece recomendações de desempenho aos usuários do Cloud SQL para melhorar o desempenho dos bancos de dados e fornece sugestões para definir a configuração para melhorar o desempenho e reduzir o custo das instâncias. Consulte as recomendações do Cloud SQL para mais detalhes.
Produtos e serviços relacionados
O Google Cloud oferece um banco de dados MySQL gerenciado para atender às suas necessidades de negócios, desde a desativação de um data center local até a execução de aplicativos SaaS e a migração dos principais sistemas de negócios.
Vá além
Comece a criar no Google Cloud com US$ 300 em créditos e mais de 20 produtos do programa Sempre gratuito.
Precisa de ajuda para começar?
Entre em contato com a equipe de vendasTrabalhe com um parceiro confiável
Encontre um parceiroContinue navegando
Ver todos os produtos











