Übersicht
Looker verwendet die Logik von Aggregate Awareness, um die kleinste und effizienteste Tabelle in Ihrer Datenbank zu finden, für die eine Abfrage ausgeführt werden kann, ohne dass die Genauigkeit beeinträchtigt wird.
Für sehr große Tabellen in Ihrer Datenbank können Looker-Entwickler kleinere aggregierte Datentabellen erstellen, die nach verschiedenen Attributkombinationen gruppiert sind. Die aggregierten Tabellen dienen als Zusammenfassungs- oder Übersichtstabellen, die Looker nach Möglichkeit für Abfragen anstelle der ursprünglichen großen Tabelle verwenden kann. Wenn Aggregate Awareness strategisch implementiert wird, kann die durchschnittliche Abfrage um Größenordnungen beschleunigt werden.
Sie haben beispielsweise eine Datentabelle im Petabyte-Bereich mit einer Zeile für jede Bestellung, die auf Ihrer Website eingegangen ist. Aus dieser Datenbank können Sie eine aggregierte Tabelle mit Ihren täglichen Umsatzzahlen erstellen. Wenn auf Ihrer Website täglich 1.000 Bestellungen eingehen, enthält die tägliche aggregierte Tabelle für jeden Tag 999 Zeilen weniger als die Originaltabelle. Sie können eine weitere zusammengefasste Tabelle mit monatlichen Umsatzzahlen erstellen, die noch effizienter ist. Wenn ein Nutzer jetzt eine Abfrage für den täglichen oder wöchentlichen Umsatz ausführt, wird in Looker die Tabelle mit dem täglichen Gesamtumsatz verwendet. Wenn ein Nutzer eine Abfrage zu den Jahresumsätzen ausführt und Sie keine aggregierte Jahrestabelle haben, verwendet Looker die nächstbeste Option, in diesem Beispiel die aggregierte Monatstabelle für die Umsätze.
Looker beantwortet die Fragen Ihrer Nutzer nach Möglichkeit mit den kleinsten aggregierten Tabellen. Beispiel:
- Für eine Abfrage zum monatlichen Gesamtumsatz verwendet Looker die Aggregat-Tabelle basierend auf dem monatlichen Umsatz (
sales_monthly_aggregate_table). - Für eine Abfrage zum Gesamtbetrag jedes Verkaufs an einem Tag gibt es keine aggregierte Tabelle mit dieser Granularität. Looker ruft die Abfrageergebnisse daher aus der ursprünglichen Datenbanktabelle (
orders_database) ab. Wenn Ihre Nutzer diese Art von Abfrage jedoch häufig ausführen, können Sie eine aggregierte Tabelle dafür erstellen. - Für eine Abfrage zu wöchentlichen Umsätzen gibt es keine aggregierte Tabelle für wöchentliche Umsätze. Daher verwendet Looker die nächstbeste Option, nämlich die aggregierte Tabelle für tägliche Umsätze (
sales_daily_aggregate_table).
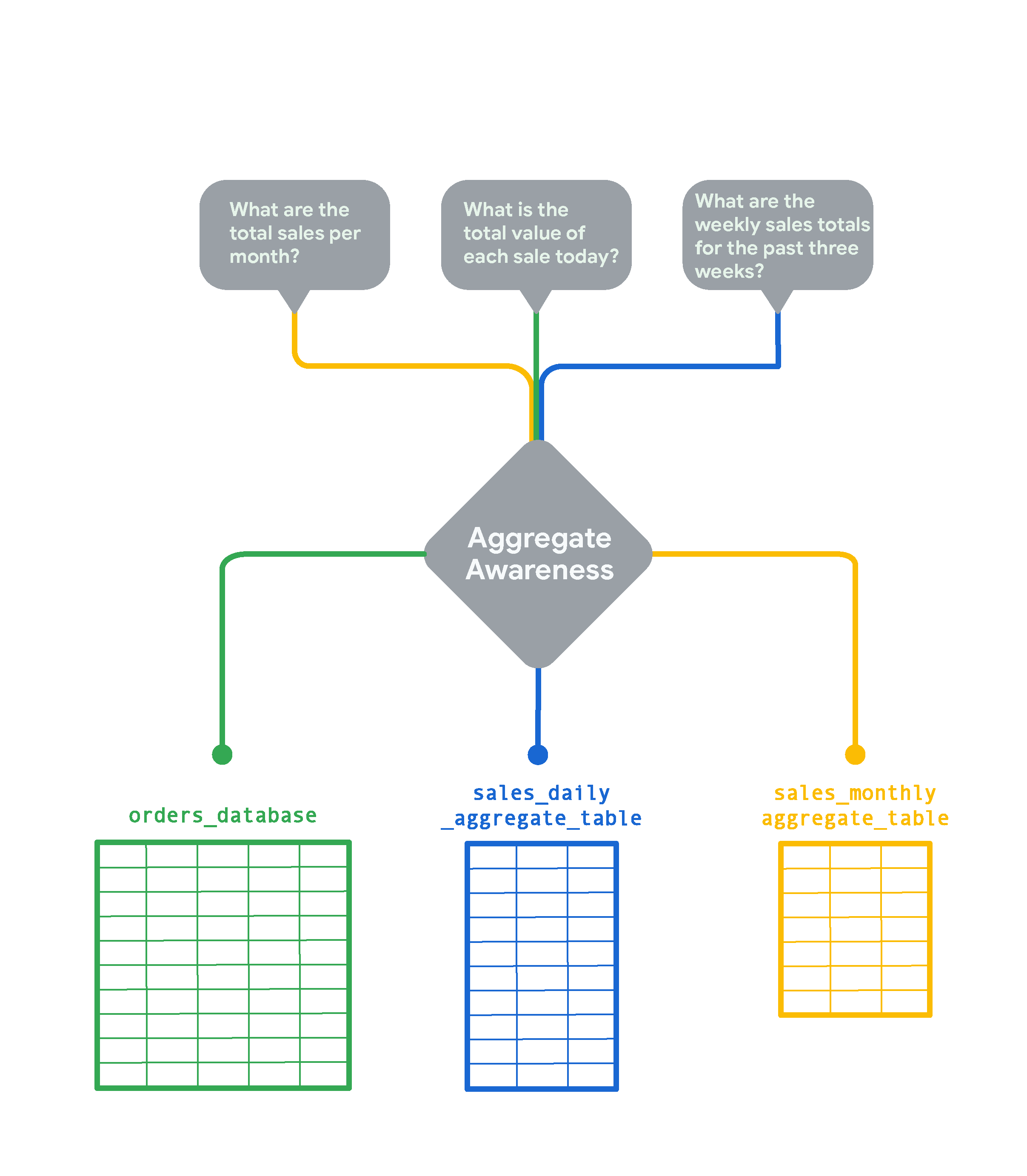
Mithilfe der Logik für Aggregate Awareness fragt Looker die kleinste mögliche Aggregattabelle ab, um die Fragen Ihrer Nutzer zu beantworten. Die Originaltabelle wird nur für Abfragen verwendet, die eine feinere Granularität erfordern, als die aggregierten Tabellen bieten können.
Aggregierte Tabellen müssen nicht verknüpft oder einem separaten Explore hinzugefügt werden. Stattdessen wird die FROM-Klausel der Explore-Abfrage in Looker dynamisch angepasst, um auf die beste Aggregattabelle für die Abfrage zuzugreifen. Das bedeutet, dass Ihre Drilldowns beibehalten werden und Explores zusammengeführt werden können. Mit der Aggregat-Funktion kann in einem Explore automatisch auf Aggregat-Tabellen zurückgegriffen werden. Bei Bedarf können Sie aber trotzdem detaillierte Daten analysieren.
Sie können auch Aggregattabellen verwenden, um die Leistung von Dashboards drastisch zu verbessern, insbesondere bei Kacheln, mit denen riesige Datasets abgefragt werden. Weitere Informationen finden Sie im Abschnitt LookML-Code einer aggregierten Tabelle aus einem Dashboard abrufen auf der Dokumentationsseite zum Parameter aggregate_table.
Aggregierte Tabellen zum Projekt hinzufügen
Looker-Entwickler können strategische aggregierte Tabellen erstellen, um die Anzahl der erforderlichen Abfragen für die großen Tabellen in einer Datenbank zu minimieren. Aggregierte Tabellen müssen in Ihrer Datenbank gespeichert werden, damit sie für die Aggregat-Awareness zugänglich sind. Aggregierte Tabellen sind daher eine Art persistente abgeleitete Tabelle (PAT).
Eine aggregierte Tabelle wird mit dem Parameter aggregate_table unter einem explore-Parameter in Ihrem LookML-Projekt definiert.
Hier sehen Sie ein Beispiel für eine explore mit einer aggregierten Tabelle in LookML:
explore: orders {
label: "Sales Totals"
join: order_items {
sql_on: ${orders.id} = ${order_items.id} ;;
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [created_month]
measures: [order_items.total_sales]
}
}
# other explore parameters
}
Um eine aggregierte Tabelle zu erstellen, können Sie LookML von Grund auf neu schreiben oder LookML für aggregierte Tabellen aus einem Explore oder aus einem Dashboard abrufen. Weitere Informationen zum Parameter aggregate_table und seinen Unterparametern finden Sie auf der Dokumentationsseite zum Parameter aggregate_table.
Zusammengefasste Tabellen entwerfen
Damit eine Explore-Abfrage eine aggregierte Tabelle verwenden kann, muss die aggregierte Tabelle genaue Daten für die Explore-Abfrage liefern können. Looker kann eine Aggregat-Tabelle für eine Explore-Abfrage verwenden, wenn alle folgenden Bedingungen erfüllt sind:
- Die Felder der Explore-Abfrage sind eine Teilmenge der Felder der aggregierten Tabelle (siehe den Abschnitt Feld-Faktoren auf dieser Seite). Bei Zeiträumen können die Zeiträume der Explore-Abfrage aus den Zeiträumen in der aggregierten Tabelle abgeleitet werden (siehe den Abschnitt Zeitraumfaktoren auf dieser Seite).
- Die Explore-Abfrage enthält Messwerttypen, die von der aggregierten Bekanntheit unterstützt werden (siehe den Abschnitt Faktoren für Messwerttypen auf dieser Seite), oder die Explore-Abfrage hat eine aggregierte Tabelle, die genau übereinstimmt (siehe den Abschnitt Aggregierte Tabellen erstellen, die genau mit Explore-Abfragen übereinstimmen auf dieser Seite).
- Die Zeitzone der Explore-Abfrage entspricht der Zeitzone der Aggregattabelle (siehe Abschnitt Zeitzonenfaktoren auf dieser Seite).
- Die Filter der Explore-Abfrage verweisen auf Felder, die als Dimensionen in der aggregierten Tabelle verfügbar sind, oder jeder Filter der Explore-Abfrage entspricht einem Filter in der aggregierten Tabelle (siehe den Abschnitt Filterfaktoren auf dieser Seite).
Eine Möglichkeit, dafür zu sorgen, dass eine aggregierte Tabelle genaue Daten für eine Explore-Abfrage liefert, besteht darin, eine aggregierte Tabelle zu erstellen, die genau einer Explore-Abfrage entspricht. Weitere Informationen finden Sie auf dieser Seite im Abschnitt Aggregattabellen erstellen, die genau mit Explore-Abfragen übereinstimmen.
Feldvariablen
Damit eine aggregierte Tabelle für eine Explore-Abfrage verwendet werden kann, muss sie alle Dimensionen und Messwerte enthalten, die für diese Explore-Abfrage erforderlich sind, einschließlich der Felder, die für Filter in der Explore-Abfrage verwendet werden. Wenn eine Explore-Abfrage eine Dimension oder einen Messwert enthält, die bzw. der nicht in einer aggregierten Tabelle vorhanden ist, kann Looker die aggregierte Tabelle nicht verwenden und greift stattdessen auf die Basistabelle zurück.
Wenn in einer Abfrage beispielsweise nach den Dimensionen A und B gruppiert, nach dem Messwert C aggregiert und nach der Dimension D gefiltert wird, muss die aggregierte Tabelle mindestens die Dimensionen A, B und D sowie den Messwert C enthalten.
Die aggregierte Tabelle kann auch andere Felder enthalten, muss aber mindestens die Felder der Explore-Abfrage enthalten, damit sie für die Optimierung infrage kommt. Die einzige Ausnahme sind Zeitrahmendimensionen, da Zeiträume mit gröberem Detaillierungsgrad aus Zeiträumen mit feinerem Detaillierungsgrad abgeleitet werden können.
Aufgrund dieser Feldüberlegungen ist eine aggregierte Tabelle spezifisch für das Explore, unter dem sie definiert ist. Eine aggregierte Tabelle, die unter einem Explore definiert ist, wird nicht für Abfragen für ein anderes Explore verwendet.
Faktoren für den Zeitraum
Mit der Logik für die aggregierte Bekanntheit von Looker kann ein Zeitraum aus einem anderen abgeleitet werden. Eine aggregierte Tabelle kann für eine Abfrage verwendet werden, solange der Zeitrahmen der aggregierten Tabelle eine höhere (oder genauso große) Granularität wie die Explore-Abfrage aufweist. Beispiel: Eine aggregierte Tabelle, die auf täglichen Daten basiert, kann für eine Explore-Abfrage verwendet werden, in der andere Zeiträume angegeben sind, z. B. Abfragen für tägliche, monatliche und jährliche Daten oder sogar Daten für den Tag des Monats, den Tag des Jahres und die Woche des Jahres. Eine jährliche aggregierte Tabelle kann jedoch nicht für eine Explore-Abfrage verwendet werden, für die stündliche Daten erforderlich sind, da die Daten der aggregierten Tabelle keine ausreichend hohe Granularität für die Explore-Abfrage aufweisen.
Dasselbe gilt für Teilmengen von Zeiträumen. Wenn Sie beispielsweise eine aggregierte Tabelle haben, die nach den letzten drei Monaten gefiltert ist, und ein Nutzer die Daten mit einem Filter für die letzten zwei Monate abfragt, kann Looker die aggregierte Tabelle für diese Abfrage verwenden.
Außerdem gilt dieselbe Logik für Abfragen mit Zeitrahmenfiltern: Eine aggregierte Tabelle kann für eine Abfrage mit einem Zeitrahmenfilter verwendet werden, solange der Zeitrahmen der aggregierten Tabelle eine höhere (oder genauso große) Granularität wie der in der Explore-Abfrage verwendete Zeitrahmenfilter aufweist. Beispiel: Eine aggregierte Tabelle mit dem Zeitrahmen „Täglich“ als Dimension kann für eine Explore-Abfrage verwendet werden, die nach Tag, Woche oder Monat filtert.
Faktoren für den Messungstyp
Damit eine Aggregat-Tabelle für eine Explore-Abfrage verwendet werden kann, müssen die Messwerte in der Aggregat-Tabelle genaue Daten für die Explore-Abfrage liefern können.
Aus diesem Grund werden nur bestimmte Arten von Messwerten unterstützt, wie in den folgenden Abschnitten beschrieben:
- Measures mit unterstützten Measure-Typen
- Mit SQL-Ausdrücken definierte Messwerte
- Messwerte, die nicht mit
${TABLE}definiert sind - Messwerte, die ungefähre Anzahl einzelner Aufrufe liefern
Wenn in einer Explore-Abfrage ein anderer Typ von Messwert verwendet wird, verwendet Looker die Originaltabelle und nicht die aggregierte Tabelle, um Ergebnisse zurückzugeben. Die einzige Ausnahme ist, wenn die Explore-Abfrage genau mit einer Abfrage für eine aggregierte Tabelle übereinstimmt, wie im Abschnitt Aggregierte Tabellen erstellen, die genau mit Explore-Abfragen übereinstimmen beschrieben.
Andernfalls verwendet Looker die Originaltabelle und nicht die aggregierte Tabelle, um Ergebnisse zurückzugeben.
Messwerte mit unterstützten Messwerttypen
Die aggregierte Bekanntheit kann für Explore-Abfragen verwendet werden, in denen sich Messwerte mit den folgenden Messwerttypen befinden:
Damit eine Aggregat-Tabelle für eine Explore-Abfrage verwendet werden kann, muss Looker die Messwerte der Aggregat-Tabelle verarbeiten können, um genaue Daten in der Explore-Abfrage bereitzustellen. Ein Messwert mit type: sum kann beispielsweise für die aggregierte Bekanntheit verwendet werden, da sich mehrere Summen addieren lassen: Eine aggregierte Tabelle mit wöchentlichen Summen kann addiert werden, um eine genaue monatliche Summe zu erhalten. Ebenso kann eine Messung mit type: max verwendet werden, da mit einer aggregierten Tabelle mit täglichen Höchstwerten der genaue wöchentliche Höchstwert ermittelt werden kann.
Bei Messwerten mit type: average wird die aggregierte Bekanntheit unterstützt, da Looker Summen- und Zähldaten verwendet, um Durchschnittswerte aus aggregierten Tabellen abzuleiten.
Mit SQL-Ausdrücken definierte Messwerte
Die Aggregat-Sensibilisierung kann auch für Messwerte verwendet werden, die mit Ausdrücken im Parameter sql definiert sind. Wenn sie mit SQL-Ausdrücken definiert werden, werden auch die folgenden Messwerttypen unterstützt:
Die aggregierte Awareness wird für Messwerte unterstützt, die als Kombinationen anderer Messwerte definiert sind, z. B. in diesem Beispiel:
measure: total_revenue_in_dollars {
type: number
sql: ${total_revenue_in_dollars} - ${inventory_item.total_cost_in_dollars} ;;
}
Die Aggregat-Awareness wird auch für Messwerte unterstützt, bei denen Berechnungen im Parameter sql definiert sind, z. B. für diesen Messwert:
measure: wholesale_value {
type: number
sql: (${order_items.total_sale_price} * 0.60) ;;
}
Die Aggregatberücksichtigung wird für Measures unterstützt, bei denen MIN-, MAX- und COUNT-Vorgänge im Parameter sql definiert sind, z. B. bei diesem Measure:
measure: most_recent_order_date {
type: date
sql: MAX(${users.created_at_raw})
}
Messwerte, die auf LookML-Felder verweisen
Wenn sql-Ausdrücke in Messwerten verwendet werden, unterstützt „Aggregate Awareness“ die folgenden Arten von Feldreferenzen:
- Verweise im Format
${view_name.field_name}, die auf Felder in anderen Ansichten verweisen - Verweise im Format
${field_name}, die auf Felder in derselben Ansicht verweisen
Aggregate Awareness wird nicht für Messwerte unterstützt, die mit dem Format ${TABLE}.column_name definiert werden. Dieses Format gibt eine Spalte in einer Tabelle an. Eine Übersicht über die Verwendung von Referenzen in LookML finden Sie auf der Dokumentationsseite SQL-Einbindung und Verweise auf LookML-Objekte.
Ein mit diesem sql-Parameter definierter Messwert wird beispielsweise nicht in einer Aggregattabelle unterstützt, da er das Format ${TABLE}.column_name verwendet:
measure: wholesale_value {
type: number
sql: (${TABLE}.total_sale_price * 0.60) ;;
}
Wenn Sie diesen Messwert in eine aggregierte Tabelle einfügen möchten, können Sie stattdessen eine Dimension mit dem Format ${TABLE}.column_name erstellen und dann einen Messwert, der auf die Dimension verweist, z. B. so:
dimension: total_sale_price {
sql: (${TABLE}.total_sale_price) ;;
}
measure: wholesale_value {
type: number
sql: (${total_sale_price} * 0.60) ;;
}
Sie können den Messwert wholesale_value jetzt in Ihrer aggregierten Tabelle verwenden.
Messwerte, die ungefähre Anzahl einzelner Aufrufe liefern
Im Allgemeinen werden Distinct Counts nicht mit aggregierter Bekanntheit unterstützt, da Sie keine genauen Daten erhalten, wenn Sie versuchen, Distinct Counts zu aggregieren. Wenn Sie beispielsweise die eindeutigen Nutzer einer Website zählen, kann es sein, dass ein Nutzer die Website zweimal besucht hat, wobei drei Wochen zwischen den Besuchen lagen. Wenn Sie beispielsweise eine wöchentliche Aggregattabelle verwenden, um die monatliche Anzahl eindeutiger Nutzer auf Ihrer Website zu ermitteln, wird dieser Nutzer in Ihrer monatlichen Abfrage für eindeutige Nutzer zweimal gezählt und die Daten sind falsch.
Eine mögliche Lösung besteht darin, eine aggregierte Tabelle zu erstellen, die genau einer Explore-Abfrage entspricht. Eine Anleitung dazu finden Sie auf dieser Seite im Abschnitt Aggregierte Tabellen erstellen, die genau Explore-Abfragen entsprechen. Wenn die Explore-Abfrage und die Abfrage für die aggregierte Tabelle identisch sind, liefern Distinct Count-Messwerte genaue Daten. Sie können also für die aggregierte Bekanntheit verwendet werden.
Eine weitere Option ist die Verwendung von Schätzungen für die Anzahl der eindeutigen Werte. Bei Dialekten, die HyperLogLog-Skizzen unterstützen, kann Looker den HyperLogLog-Algorithmus verwenden, um die Anzahl der eindeutigen Werte für Aggregationstabellen zu schätzen.
Der HyperLogLog-Algorithmus hat einen bekannten Fehler von etwa 2 %. Für den Parameter allow_approximate_optimization: yes müssen Ihre Looker-Entwickler bestätigen, dass es in Ordnung ist, ungefähre Daten für den Messwert zu verwenden, damit er ungefähr aus aggregierten Tabellen berechnet werden kann.
Weitere Informationen und die Liste der Dialekte, die die Anzahl der eindeutigen Werte mit HyperLogLog unterstützen, finden Sie auf der Dokumentationsseite zum Parameter allow_approximate_optimization.
Zeitzonenfaktoren
In vielen Fällen verwenden Datenbankadministratoren UTC als Zeitzone für Datenbanken. Viele Nutzer befinden sich jedoch möglicherweise nicht in der UTC-Zeitzone. Looker bietet mehrere Optionen zum Konvertieren von Zeitzonen, damit Ihre Nutzer Abfrageergebnisse in ihrer eigenen Zeitzone erhalten:
- Zeitzone für Abfragen: Diese Einstellung gilt für alle Abfragen für die Datenbankverbindung. Wenn sich alle Ihre Nutzer in derselben Zeitzone befinden, können Sie eine einzelne Abfragezeitzone festlegen, damit alle Abfragen von der Datenbankzeitzone in die Abfragezeitzone konvertiert werden.
- Nutzerspezifische Zeitzonen, in denen Nutzern Zeitzonen individuell zugewiesen werden können und sie diese selbst auswählen können. In diesem Fall werden Abfragen von der Zeitzone der Datenbank in die Zeitzone des jeweiligen Nutzers konvertiert.
Weitere Informationen zu diesen Optionen finden Sie auf der Dokumentationsseite Zeitzoneneinstellungen verwenden.
Diese Konzepte sind wichtig, um die aggregierte Berücksichtigung zu verstehen. Damit eine aggregierte Tabelle für eine Abfrage mit Datumsdimensionen oder ‑filtern verwendet werden kann, muss die Zeitzone in der aggregierten Tabelle mit der Zeitzoneneinstellung der ursprünglichen Abfrage übereinstimmen.
In aggregierten Tabellen wird die Datenbankzeitzone verwendet, wenn kein timezone-Wert angegeben ist. Für Ihre Datenbankverbindung wird auch die Zeitzone der Datenbank verwendet, wenn eine der folgenden Bedingungen zutrifft:
- Ihre Datenbank unterstützt keine Zeitzonen.
- Die Zeitzone für Abfragen Ihrer Datenbankverbindung ist auf dieselbe Zeitzone wie die Datenbankzeitzone festgelegt.
- Für Ihre Datenbankverbindung ist weder eine Abfragezeitzone noch eine nutzerspezifische Zeitzone angegeben. In diesem Fall wird für die Datenbankverbindung die Zeitzone der Datenbank verwendet.
Wenn eine dieser Aussagen zutrifft, können Sie den Parameter timezone für Ihre aggregierten Tabellen weglassen.
Andernfalls sollte die Zeitzone der aggregierten Tabelle so definiert werden, dass sie mit möglichen Abfragen übereinstimmt, damit die aggregierte Tabelle mit größerer Wahrscheinlichkeit verwendet wird:
- Wenn für Ihre Datenbankverbindung eine einzelne Zeitzone für Abfragen verwendet wird, sollte der
timezone-Wert Ihrer Aggregattabelle mit dem Wert der Zeitzone für Abfragen übereinstimmen. - Wenn für Ihre Datenbankverbindung nutzerspezifische Zeitzonen verwendet werden, sollten Sie identische Aggregattabellen erstellen, die jeweils einen anderen
timezone-Wert haben, der den möglichen Zeitzonen Ihrer Nutzer entspricht.
Faktoren filtern
Seien Sie vorsichtig, wenn Sie Filter in Ihre aggregierte Tabelle aufnehmen. Filter in einer aggregierten Tabelle können die Ergebnisse so weit einschränken, dass die aggregierte Tabelle nicht mehr verwendet werden kann. Angenommen, Sie erstellen eine Aggregattabelle für die täglichen Bestellmengen und die Aggregattabelle wird nur nach Sonnenbrillenbestellungen aus Australien gefiltert. Wenn ein Nutzer eine Explore-Abfrage für die täglichen Bestellmengen von Sonnenbrillen weltweit ausführt, kann Looker die Aggregat-Tabelle für diese Explore-Abfrage nicht verwenden, da sie nur Daten für Australien enthält. Die Daten in der aggregierten Tabelle sind zu stark gefiltert, um für die Explore-Abfrage verwendet werden zu können.
Achten Sie auch auf die Filter, die Ihre Looker-Entwickler möglicherweise in Ihr Explore eingebaut haben, z. B.:
access_filters: Wendet nutzerspezifische Datenbeschränkungen an.always_filter: Nutzer müssen für eine Explore-Abfrage eine bestimmte Gruppe von Filtern angeben. Nutzer können den Standardfilterwert für ihre Abfrage ändern, den Filter jedoch nicht vollständig entfernen.conditionally_filter: Definiert eine Reihe von Standardfiltern, die Nutzer überschreiben können, wenn sie mindestens einen Filter aus einer zweiten Liste anwenden, die ebenfalls im Explore definiert ist.
Diese Filtertypen basieren auf bestimmten Feldern. Wenn Ihr Explore diese Filter enthält, müssen Sie die entsprechenden Felder in den Parameter dimensions der aggregate_table aufnehmen.
Hier sehen Sie beispielsweise ein Explore mit einem Zugriffsfilter, der auf dem Feld orders.region basiert:
explore: orders {
access_filter: {
field: orders.region
user_attribute: region
}
}
Wenn Sie eine aggregierte Tabelle für dieses Explore erstellen möchten, muss sie das Feld enthalten, auf dem der Zugriffsfilter basiert. Im nächsten Beispiel basiert der Zugriffsfilter auf dem Feld orders.region. Dieses Feld ist auch als Dimension in der aggregierten Tabelle enthalten:
explore: orders {
access_filter: {
field: orders.region # <-- orders.region field
user_attribute: region
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_day, orders.region] # <-- orders.region field
measures: [orders.total_sales]
timezone: America/Los_Angeles
}
}
}
Da die Abfrage für die aggregierte Tabelle die Dimension orders.region enthält, kann Looker die Daten in der aggregierten Tabelle dynamisch filtern, sodass sie mit dem Filter aus der Explore-Abfrage übereinstimmen. Daher kann Looker die aggregierte Tabelle weiterhin für die Abfragen des Explores verwenden, obwohl das Explore einen Zugriffsfilter hat.
Das gilt auch für Explore-Abfragen, in denen eine native abgeleitete Tabelle mit bind_filters verwendet wird. Mit dem Parameter bind_filters werden angegebene Filter aus einer Explore-Abfrage an die Unterabfrage der nativen abgeleiteten Tabelle übergeben. Wenn für Ihre Explore-Abfrage eine native abgeleitete Tabelle mit bind_filters erforderlich ist, kann für die Explore-Abfrage nur dann eine aggregierte Tabelle verwendet werden, wenn alle Felder, die im bind_filters-Parameter der nativen abgeleiteten Tabelle verwendet werden, in der Explore-Abfrage dieselben Filterwerte wie in der aggregierten Tabelle haben.
Aggregierte Tabellen erstellen, die genau mit Explore-Abfragen übereinstimmen
Eine Möglichkeit, sicherzugehen, dass eine aggregierte Tabelle für eine Explore-Abfrage verwendet werden kann, besteht darin, eine aggregierte Tabelle zu erstellen, die genau der Explore-Abfrage entspricht. Wenn in der Explore-Abfrage und der aggregierten Tabelle dieselben Messwerte, Dimensionen, Filter, Zeitzonen und andere Parameter verwendet werden, gelten die Ergebnisse der aggregierten Tabelle per Definition für die Explore-Abfrage. Wenn eine Aggregat-Tabelle genau mit einer Explore-Abfrage übereinstimmt, kann Looker Aggregat-Tabellen mit beliebigen Arten von Messwerten verwenden.
Sie können eine aggregierte Tabelle aus einem Explore erstellen, indem Sie im Zahnradmenü eines Explores die Option LookML abrufen auswählen. Sie können auch genaue Übereinstimmungen für alle Kacheln in einem Dashboard erstellen, indem Sie im Zahnradmenü eines Dashboards die Option LookML abrufen auswählen.
Ermitteln, welche aggregierte Tabelle für eine Abfrage verwendet wird
Nutzer mit der Berechtigung see_sql können auf dem Tab SQL eines Explores in den Kommentaren sehen, welche aggregierte Tabelle für eine Abfrage verwendet wird. Die Kommentare auf dem Tab SQL werden auch im Entwicklungsmodus angezeigt. So können Entwickler neue Aggregat-Tabellen testen, um zu sehen, wie Looker sie verwendet, bevor Sie neue Tabellen in die Produktion übertragen.
Anhand der Beispiel-Aggregattabelle für den Monat oben können Sie beispielsweise zu Explore wechseln und eine Abfrage für den jährlichen Gesamtumsatz ausführen. Klicken Sie dann auf den Tab SQL, um die Details der von Looker erstellten Abfrage aufzurufen. Wenn Sie sich im Entwicklungsmodus befinden, zeigt Looker Kommentare an, in denen die Aggregat-Tabelle angegeben ist, die für die Abfrage verwendet wurde.
Anhand der folgenden Kommentare auf dem Tab SQL sehen wir, dass Looker die Aggregattabelle sales_monthly für diese Abfrage verwendet, und Informationen dazu, warum andere Aggregattabellen nicht für die Abfrage verwendet wurden:
-- use existing orders::sales_monthly in sandbox_scratch.LR$LB4151619827209021_orders$sales_monthly
-- Did not use orders::sales_weekly; it does not include the following fields in the query: orders.created_month
-- Did not use orders::sales_daily; orders::sales_monthly was a better fit for optimization.
-- Did not use orders::sales_last_3_days; contained filters not in the query: orders.created_date
Im Abschnitt Fehlerbehebung auf dieser Seite finden Sie mögliche Kommentare, die auf dem Tab SQL angezeigt werden, sowie Vorschläge zur Behebung der Probleme.
Schätzungen der Rechenleistungseinsparungen für die aggregierte Bekanntheit
Wenn Ihre Datenbankverbindung Kostenschätzungen unterstützt und eine Aggregat-Tabelle für eine Abfrage verwendet werden kann, werden im Explore-Fenster die Rechenressourceneinsparungen angezeigt, die sich durch die Verwendung der Aggregat-Tabelle anstelle einer direkten Abfrage der Datenbank ergeben. Die geschätzten Einsparungen bei der Markenbekanntheit werden neben der Schaltfläche Ausführen in einem Explore angezeigt, bevor die Abfrage ausgeführt wird.
Wenn Sie vor dem Ausführen der Abfrage sehen möchten, welche Aggregattabelle verwendet wird, können Sie auf den Tab SQL klicken. Das wird im Abschnitt Ermitteln, welche Aggregattabelle für eine Abfrage verwendet wird auf dieser Dokumentationsseite beschrieben.
Nachdem die Abfrage ausgeführt wurde, wird im Fenster „Erkunden“ neben der Schaltfläche Ausführen angezeigt, welche aggregierte Tabelle verwendet wurde, um die Abfrage zu beantworten.
Die aggregierten Einsparungen bei der Bekanntheit werden für Datenbankverbindungen angezeigt, für die Kostenschätzungen aktiviert sind. Weitere Informationen finden Sie auf der Dokumentationsseite Daten in Looker untersuchen .
Looker führt neue Daten mit Ihren zusammengefassten Tabellen zusammen
Bei zusammengefassten Tabellen mit Zeitfiltern kann Looker neue Daten zusammenführen. Möglicherweise haben Sie eine Aggregattabelle mit Daten für die letzten drei Tage, die gestern erstellt wurde. In der aggregierten Tabelle fehlen die Informationen von heute. Sie können sie also nicht für eine Explore-Abfrage zu den neuesten täglichen Informationen verwenden.
Looker kann die Daten in dieser Aggregat-Tabelle jedoch weiterhin für die Abfrage verwenden, da Looker eine Abfrage für die neuesten Daten ausführt und diese Ergebnisse dann mit den Ergebnissen in der Aggregat-Tabelle zusammenführt.
Unter den folgenden Umständen kann Looker neue Daten mit den Daten Ihrer Aggregattabelle zusammenführen:
- Die zusammengefasste Tabelle hat einen Zeitfilter.
- Die Aggregattabelle enthält eine Dimension, die auf demselben Zeitfeld wie der Zeitfilter basiert.
Die folgende aggregierte Tabelle enthält beispielsweise eine Dimension, die auf dem Feld orders.created_date basiert, und einen Zeitfilter ("3 days"), der auf demselben Feld basiert:
aggregate_table: sales_last_3_days {
query: {
dimensions: [orders.created_date]
measures: [order_items.total_sales]
filters: [orders.created_date: "3 days"] # <-- time filter
timezone: America/Los_Angeles
}
...
}
Wenn diese Aggregattabelle gestern erstellt wurde, ruft Looker die neuesten Daten ab, die noch nicht in der Aggregattabelle enthalten sind, und führt die neuen Ergebnisse dann mit den Ergebnissen aus der Aggregattabelle zusammen. Ihre Nutzer erhalten also die neuesten Daten, während die Leistung weiterhin durch die Nutzung von aggregierten Informationen optimiert wird.
Wenn Sie sich im Entwicklungsmodus befinden, können Sie auf dem Tab SQL eines Explores die Aggregat-Tabelle sehen, die Looker für die Abfrage verwendet hat, sowie die UNION-Anweisung, mit der Looker neuere Daten abgerufen hat, die nicht in der Aggregat-Tabelle enthalten waren.
Zusammengefasste Tabellen müssen beibehalten werden
Damit Ihre aggregierte Tabelle für die aggregierte Analyse verfügbar ist, muss sie in Ihrer Datenbank gespeichert werden. Die Persistenzstrategie wird im Parameter materialization der aggregierten Tabelle angegeben. Da aggregierte Tabellen eine Art persistente abgeleitete Tabelle (PDT) sind, gelten für sie dieselben Anforderungen wie für PDTs. Weitere Informationen finden Sie auf der Dokumentationsseite Abgeleitete Tabellen in Looker.
Sie können inkrementelle PDTs in Ihrem Projekt erstellen, wenn Ihr Dialekt sie unterstützt. Inkrementelle PDTs werden in Looker erstellt, indem neue Daten an die Tabelle angehängt werden, anstatt dass die ganze Tabelle neu erstellt wird. Da aggregierte Tabellen selbst eine Art von PDT sind, können Sie auch inkrementelle aggregierte Tabellen erstellen. Weitere Informationen zu inkrementellen PDTs finden Sie auf der Dokumentationsseite Inkrementelle PDTs. Ein Beispiel für eine inkrementelle Aggregattabelle finden Sie auf der Dokumentationsseite zum Parameter increment_key.
Ein Nutzer mit der Berechtigung develop kann die Persistenzeinstellungen überschreiben und alle Aggregattabellen für eine Abfrage neu erstellen, um die aktuellsten Daten abzurufen. Wenn Sie die Tabellen für eine Abfrage neu erstellen möchten, wählen Sie im Zahnradmenü für Explore-Vorgänge die Option Abgeleitete Tabellen neu erstellen und ausführen aus.
Diese Option ist erst verfügbar, wenn die Explore-Abfrage geladen wurde.
Mit der Option Abgeleitete Tabellen neu erstellen und ausführen werden alle abgeleiteten Tabellen neu erstellt, auf die in der Abfrage verwiesen wird, sowie alle abgeleiteten Tabellen, von denen die Tabellen in der Abfrage abhängen. Dazu gehören auch Aggregattabellen, die selbst eine Art persistente abgeleitete Tabelle sind.
Für den Benutzer, der die Option Rebuild Derived Tables & Run startet, werden die Ergebnisse erst geladen, wenn die Tabellen neu erstellt wurden. Abfragen anderer Nutzer verwenden weiterhin die bestehenden Tabellen. Wenn die persistenten Tabellen erneut erstellt wurden, verwenden alle Benutzer die neu erstellten Tabellen.
Weitere Informationen zur Option Abgeleitete Tabellen neu erstellen und ausführen finden Sie auf der Dokumentationsseite Abgeleitete Tabellen in Looker.
Fehlerbehebung
Wie im Abschnitt Ermitteln, welche Aggregat-Tabelle für eine Abfrage verwendet wird beschrieben, können Sie im Entwicklungsmodus Abfragen für das Explore ausführen und auf den Tab SQL klicken, um Kommentare zur für die Abfrage verwendeten Aggregat-Tabelle zu sehen, sofern vorhanden.
Auf dem Tab SQL finden Sie auch Kommentare dazu, warum aggregierte Tabellen für eine Abfrage nicht verwendet wurden, falls dies der Fall ist. Bei nicht verwendeten aggregierten Tabellen beginnt der Kommentar mit:
Did not use [explore name]::[aggregate table name];
Hier sehen Sie ein Beispiel für einen Kommentar dazu, warum die im Explore order_items definierte aggregierte Tabelle sales_daily nicht für eine Abfrage verwendet wurde:
-- Did not use order_items::sales_daily; query contained the following filters
that were neither included as fields nor exactly matched by filters in the aggregate table:
order_items.created_year.
In diesem Fall wurde die Aggregattabelle aufgrund der Filter in der Abfrage nicht verwendet.
In der folgenden Tabelle sind einige weitere mögliche Gründe dafür aufgeführt, warum eine aggregierte Tabelle nicht verwendet werden kann, sowie Schritte, die Sie unternehmen können, um die Nutzbarkeit der aggregierten Tabelle zu erhöhen.
| Grund für die Nichtverwendung der zusammengefassten Tabelle | Erläuterung und mögliche Schritte |
|---|---|
| Ein solches Feld ist im Explore nicht vorhanden. | Es ist ein LookML-Validierungsfehler aufgetreten. Das liegt höchstwahrscheinlich daran, dass die aggregierte Tabelle nicht richtig definiert wurde oder ein Tippfehler im LookML für die aggregierte Tabelle vorliegt. Ein wahrscheinlicher Grund ist ein falscher Feldname oder Ähnliches.Prüfen Sie, ob die Dimensionen und Messwerte in der aggregierten Tabelle mit den Feldnamen im Explore übereinstimmen, um dieses Problem zu beheben. Weitere Informationen zum Definieren einer aggregierten Tabelle finden Sie auf der Dokumentationsseite zum Parameter aggregate_table. |
| Die Aggregattabelle enthält die folgenden Felder nicht in der Abfrage. | Damit eine aggregierte Tabelle für eine Explore-Abfrage verwendet werden kann, muss sie alle Dimensionen und Messwerte enthalten, die für diese Explore-Abfrage erforderlich sind, einschließlich der Felder, die für Filter in der Explore-Abfrage verwendet werden. Wenn eine Explore-Abfrage eine Dimension oder einen Messwert enthält, die bzw. der nicht in einer aggregierten Tabelle vorhanden ist, kann Looker die aggregierte Tabelle nicht verwenden und greift stattdessen auf die Basistabelle zurück. Weitere Informationen finden Sie im Abschnitt Feld-Faktoren auf dieser Seite. Die einzige Ausnahme sind Zeitrahmendimensionen, da Zeiträume mit gröberem Detaillierungsgrad aus Zeiträumen mit feinerem Detaillierungsgrad abgeleitet werden können. Prüfen Sie, ob die Felder der Explore-Abfrage in der Definition der aggregierten Tabelle enthalten sind, um dieses Problem zu beheben. |
| Die Abfrage enthielt die folgenden Filter, die weder als Felder enthalten noch genau mit Filtern in der Aggregattabelle übereinstimmten. | Die Filter in der Explore-Abfrage verhindern, dass Looker die aggregierte Tabelle verwendet. Sie haben folgende Möglichkeiten, dieses Problem zu beheben:
|
| Die Abfrage enthält die folgenden Measures, die nicht zusammengefasst werden können. | Die Abfrage enthält mindestens einen Messwerttyp, der für die aggregierte Sensibilisierung nicht unterstützt wird, z. B. Anzahl der eindeutigen Werte, Median oder Perzentil.Prüfen Sie zur Behebung dieses Problems den Typ der einzelnen Messwerte in der Abfrage und achten Sie darauf, dass es sich um einen der unterstützten Messwerttypen handelt. Wenn Ihr Explore Joins enthält, prüfen Sie, ob Ihre Measures durch Fanned-Out-Joins in Distinct-Measures (symmetrische Aggregate) umgewandelt werden. Eine Erklärung finden Sie auf dieser Seite im Abschnitt Symmetrische Summen für Explores mit Joins. |
| Eine andere aggregierte Tabelle war besser für die Optimierung geeignet. | Es gab mehrere geeignete aggregierte Tabellen für die Abfrage und Looker hat eine optimale aggregierte Tabelle gefunden, die stattdessen verwendet werden kann. In diesem Fall müssen Sie nichts tun. |
Looker hat keine Gruppierung vorgenommen (aufgrund eines primary_key- oder cancel_grouping_fields-Parameters). Daher kann die Abfrage nicht zusammengefasst werden. |
In der Abfrage wird auf eine Dimension verwiesen, die verhindert, dass sie eine GROUP BY-Klausel enthält. Daher kann Looker keine aggregierte Tabelle für die Abfrage verwenden.
Prüfen Sie, ob der Parameter primary_key der Ansicht und der Parameter cancel_grouping_fields des Explorers richtig eingerichtet sind. |
| Die zusammengefasste Tabelle enthielt Filter, die nicht in der Abfrage enthalten waren. | Die aggregierte Tabelle enthält einen Filter, der nicht auf Zeit basiert und nicht in der Abfrage enthalten ist.Um das Problem zu beheben, können Sie den Filter aus der aggregierten Tabelle entfernen. Weitere Informationen finden Sie im Abschnitt Filterfaktoren auf dieser Seite. |
Ein Feld ist in der Explore-Abfrage als Nur-Filter-Feld definiert, wird aber im Parameter dimensions der aggregierten Tabelle aufgeführt. |
Im Parameter dimensions der aggregierten Tabelle wird ein Feld aufgeführt, das in der Explore-Abfrage nur als filter-Feld definiert ist.Entfernen Sie das Feld aus der Liste dimensions der aggregierten Tabelle, um das Problem zu beheben. Wenn dieses Feld für die aggregierte Tabelle erforderlich ist, fügen Sie es der Liste filters in der Abfrage der aggregierten Tabelle hinzu. |
| Der Optimizer kann nicht feststellen, warum die aggregierte Tabelle nicht verwendet wurde. | Dieser Kommentar ist für Grenzfälle reserviert. Wenn Sie diese Meldung für eine Explore-Abfrage sehen, die häufig verwendet wird, können Sie eine Aggregat-Tabelle erstellen, die genau der Explore-Abfrage entspricht. Sie können LookML für aggregierte Tabellen aus einem Explore abrufen, wie auf der Parameterseite aggregate_table beschrieben. |
Wichtige Punkte
Symmetrische Summen für Explores mit Joins
Wichtig ist, dass Looker in einem Explore, in dem mehrere Datenbanktabellen zusammengeführt werden, Measures vom Typ SUM, COUNT und AVERAGE als SUM DISTINCT, COUNT DISTINCT bzw. AVERAGE DISTINCT rendern kann. So werden Fehlberechnungen des Fanout vermieden. Beispiel: Der Messwert count wird als Messwerttyp count_distinct gerendert. So werden Fehlberechnungen des Fanout für Joins vermieden. Dies ist Teil der Funktion für symmetrische Summen in Looker. Eine Erläuterung dieser Looker-Funktion finden Sie auf der Seite Best Practices für symmetrische Summen.
Die Funktion für symmetrische Aggregate verhindert Fehlberechnungen, kann aber auch dazu führen, dass Ihre Aggregattabellen in bestimmten Fällen nicht verwendet werden. Daher ist es wichtig, sie zu verstehen.
Für die von der aggregierten Sensibilisierung unterstützten Messarten gilt dies für sum, count und average. In Looker werden diese Arten von Messwerten als DISTINCT gerendert, wenn:
- Die Messung stammt aus der „1“-Ansicht eines n:1-Joins oder 1:n-Joins.
- Die Messung erfolgt aus einer der beiden Ansichten eines n:n-Joins.
Eine Erläuterung dieser Arten von Joins finden Sie auf der Dokumentationsseite zum Parameter relationship.
Wenn Ihre aggregierte Tabelle aus diesem Grund nicht verwendet wird, können Sie eine aggregierte Tabelle erstellen, die genau einer Explore-Abfrage entspricht, um diese Messwerttypen für einen Explore mit Joins zu verwenden. Weitere Informationen finden Sie auf dieser Seite im Abschnitt Aggregierte Tabellen erstellen, die genau mit Explore-Abfragen übereinstimmen.
Wenn Sie einen SQL-Dialekt haben, der HyperLogLog-Skizzen unterstützt, können Sie dem Messwert auch den Parameter allow_approximate_optimization: yes hinzufügen. Wenn ein Zählmesswert mit allow_approximate_optimization: yes definiert wird, kann Looker ihn für die aggregierte Bekanntheit verwenden, auch wenn er als Anzahl unterschiedlicher Werte gerendert wird.
Weitere Informationen und eine Liste der SQL-Dialekte, die HyperLogLog-Skizzen unterstützen, finden Sie auf der Dokumentationsseite zum Parameter allow_approximate_optimization.
Unterstützung von Dialekten für die Aggregat-Awareness
Die Möglichkeit, Aggregate Awareness zu nutzen, hängt von dem Datenbankdialekt ab, den Ihre Looker-Verbindung verwendet. In der aktuellen Version von Looker unterstützen die folgenden Dialekte die Aggregatberücksichtigung:
| Dialekt | Unterstützt? |
|---|---|
| Actian Avalanche | Ja |
| Amazon Athena | Ja |
| Amazon Aurora MySQL | Ja |
| Amazon Redshift | Ja |
| Amazon Redshift 2.1+ | Ja |
| Amazon Redshift Serverless 2.1+ | Ja |
| Apache Druid | Nein |
| Apache Druid 0.13+ | Nein |
| Apache Druid 0.18+ | Nein |
| Apache Hive 2.3+ | Ja |
| Apache Hive 3.1.2+ | Ja |
| Apache Spark 3+ | Ja |
| ClickHouse | Nein |
| Cloudera Impala 3.1+ | Ja |
| Cloudera Impala 3.1+ with Native Driver | Ja |
| Cloudera Impala with Native Driver | Ja |
| DataVirtuality | Nein |
| Databricks | Ja |
| Denodo 7 | Nein |
| Denodo 8 & 9 | Nein |
| Dremio | Nein |
| Dremio 11+ | Nein |
| Exasol | Ja |
| Google BigQuery Legacy SQL | Ja |
| Google BigQuery Standard SQL | Ja |
| Google Cloud PostgreSQL | Ja |
| Google Cloud SQL | Nein |
| Google Spanner | Nein |
| Greenplum | Ja |
| HyperSQL | Nein |
| IBM Netezza | Ja |
| MariaDB | Ja |
| Microsoft Azure PostgreSQL | Ja |
| Microsoft Azure SQL Database | Ja |
| Microsoft Azure Synapse Analytics | Ja |
| Microsoft SQL Server 2008+ | Ja |
| Microsoft SQL Server 2012+ | Ja |
| Microsoft SQL Server 2016 | Ja |
| Microsoft SQL Server 2017+ | Ja |
| MongoBI | Nein |
| MySQL | Ja |
| MySQL 8.0.12+ | Ja |
| Oracle | Ja |
| Oracle ADWC | Ja |
| PostgreSQL 9.5+ | Ja |
| PostgreSQL pre-9.5 | Ja |
| PrestoDB | Ja |
| PrestoSQL | Ja |
| SAP HANA | Ja |
| SAP HANA 2+ | Ja |
| SingleStore | Ja |
| SingleStore 7+ | Ja |
| Snowflake | Ja |
| Teradata | Ja |
| Trino | Ja |
| Vector | Ja |
| Vertica | Ja |
Dialektunterstützung für das inkrementelle Erstellen von Aggregattabellen
Damit Looker inkrementelle Aggregationstabellen in Ihrem Looker-Projekt unterstützen kann, müssen diese auch von Ihrem Datenbankdialekt unterstützt werden. In der folgenden Tabelle ist zu sehen, welche Dialekte das inkrementelle Erstellen von PDTs in der aktuellen Version von Looker unterstützen:
| Dialekt | Unterstützt? |
|---|---|
| Actian Avalanche | Nein |
| Amazon Athena | Nein |
| Amazon Aurora MySQL | Nein |
| Amazon Redshift | Ja |
| Amazon Redshift 2.1+ | Ja |
| Amazon Redshift Serverless 2.1+ | Ja |
| Apache Druid | Nein |
| Apache Druid 0.13+ | Nein |
| Apache Druid 0.18+ | Nein |
| Apache Hive 2.3+ | Nein |
| Apache Hive 3.1.2+ | Nein |
| Apache Spark 3+ | Nein |
| ClickHouse | Nein |
| Cloudera Impala 3.1+ | Nein |
| Cloudera Impala 3.1+ with Native Driver | Nein |
| Cloudera Impala with Native Driver | Nein |
| DataVirtuality | Nein |
| Databricks | Ja |
| Denodo 7 | Nein |
| Denodo 8 & 9 | Nein |
| Dremio | Nein |
| Dremio 11+ | Nein |
| Exasol | Nein |
| Google BigQuery Legacy SQL | Nein |
| Google BigQuery Standard SQL | Ja |
| Google Cloud PostgreSQL | Ja |
| Google Cloud SQL | Nein |
| Google Spanner | Nein |
| Greenplum | Ja |
| HyperSQL | Nein |
| IBM Netezza | Nein |
| MariaDB | Nein |
| Microsoft Azure PostgreSQL | Ja |
| Microsoft Azure SQL Database | Nein |
| Microsoft Azure Synapse Analytics | Ja |
| Microsoft SQL Server 2008+ | Nein |
| Microsoft SQL Server 2012+ | Nein |
| Microsoft SQL Server 2016 | Nein |
| Microsoft SQL Server 2017+ | Nein |
| MongoBI | Nein |
| MySQL | Ja |
| MySQL 8.0.12+ | Ja |
| Oracle | Nein |
| Oracle ADWC | Nein |
| PostgreSQL 9.5+ | Ja |
| PostgreSQL pre-9.5 | Ja |
| PrestoDB | Nein |
| PrestoSQL | Nein |
| SAP HANA | Nein |
| SAP HANA 2+ | Nein |
| SingleStore | Nein |
| SingleStore 7+ | Nein |
| Snowflake | Ja |
| Teradata | Nein |
| Trino | Nein |
| Vector | Nein |
| Vertica | Ja |