Eine abgeleitete Tabelle in Looker ist eine Abfrage, deren Ergebnisse so verwendet werden, als wäre die Abfrage eine tatsächliche Tabelle in der Datenbank.
Angenommen, Sie verwenden eine Datenbanktabelle mit dem Namen orders mit zahlreichen Spalten. Sie möchten einige aggregierte Kennzahlen auf Kundenebene berechnen, wie zum Beispiel die Anzahl der von den einzelnen Kunden platzierten Aufträge oder den Zeitpunkt des ersten Auftrags der verschiedenen Kunden. Mit einer nativen abgeleiteten Tabelle oder einer SQL-basierten abgeleiteten Tabelle können Sie eine neue Datenbanktabelle mit dem Namen customer_order_summary erstellen, die diese Messwerte enthält.
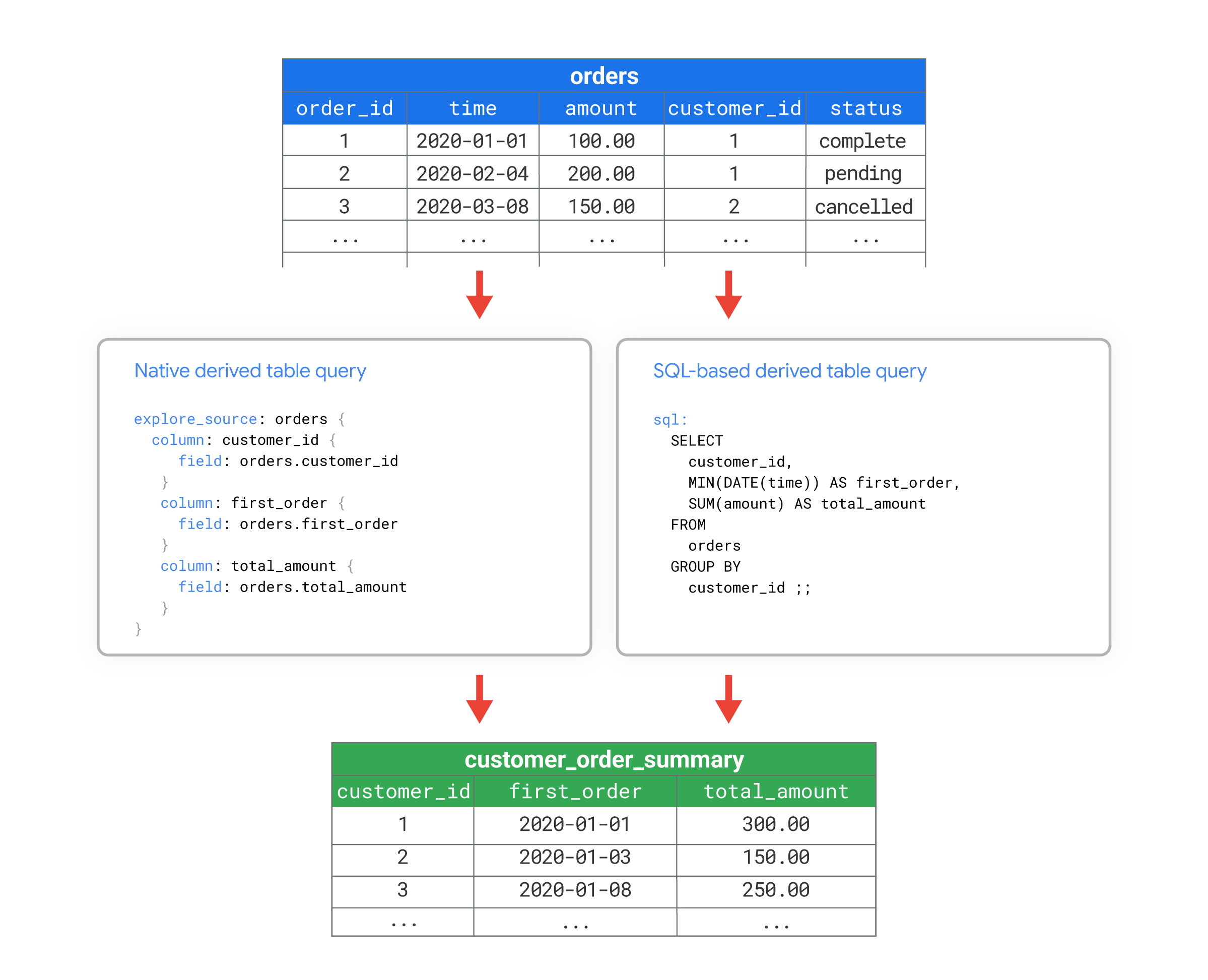
Jetzt können Sie mit der abgeleiteten Tabelle customer_order_summary genauso wie mit jeder anderen Tabelle in der Datenbank arbeiten.
Häufige Anwendungsfälle für abgeleitete Tabellen finden Sie unter Looker-Cookbooks: Abgeleitete Tabellen in Looker optimal nutzen.
Native abgeleitete Tabellen und SQL-basierte abgeleitete Tabellen
Wenn Sie in Ihrem Looker-Projekt eine abgeleitete Tabelle erstellen möchten, verwenden Sie den Parameter derived_table unter einem view-Parameter. Im Parameter derived_table können Sie die Abfrage für die abgeleitete Tabelle auf eine von zwei Arten definieren:
- Bei einer nativen abgeleiteten Tabelle definieren Sie die abgeleitete Tabelle mit einer LookML-basierten Abfrage.
- Eine SQL-basierte abgeleitete Tabelle definieren Sie mit einer SQL-Abfrage.
Die folgenden Ansichtsdateien zeigen beispielsweise, wie Sie mit LookML eine Ansicht aus einer abgeleiteten Tabelle vom Typ customer_order_summary erstellen können. Die zwei Versionen der LookML veranschaulichen, wie Sie äquivalente abgeleitete Tabellen mit LookML oder SQL erstellen können, um die Abfrage für die abgeleitete Tabelle zu definieren:
- Die native abgeleitete Tabelle definiert die Abfrage mit LookML im Parameter
explore_source. In diesem Beispiel basiert die Abfrage auf einer vorhandenenorders-Ansicht, die in einer separaten Datei definiert ist, die in diesem Beispiel nicht gezeigt wird. Mit derexplore_source-Abfrage in der nativen abgeleiteten Tabelle werden die Feldercustomer_id,first_orderundtotal_amountaus der Ansichtsdateiordersabgerufen. - In der SQL-basierten abgeleiteten Tabelle wird die Abfrage mit SQL im Parameter
sqldefiniert. In diesem Beispiel ist die SQL-Abfrage eine direkte Abfrage der Tabelleordersin der Datenbank.
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: first_order {
field: orders.first_order
}
column: total_amount {
field: orders.total_amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
view: customer_order_summary {
derived_table: {
sql:
SELECT
customer_id,
MIN(DATE(time)) AS first_order,
SUM(amount) AS total_amount
FROM
orders
GROUP BY
customer_id ;;
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
In beiden Versionen wird eine Ansicht namens customer_order_summary erstellt, die auf der Tabelle orders mit den Spalten customer_id, first_order, und total_amount basiert.
Abgesehen vom Parameter derived_table und seinen Unterparametern funktioniert diese customer_order_summary-Ansicht wie jede andere Ansichtsdatei. Unabhängig davon, ob Sie die Abfrage der abgeleiteten Tabelle mit LookML oder SQL definieren, können Sie LookML-Messwerte und -Dimensionen basierend auf den Spalten der abgeleiteten Tabelle erstellen.
Nachdem Sie die abgeleitete Tabelle definiert haben, können Sie sie wie jede andere Tabelle in der Datenbank verwenden.
Native abgeleitete Tabellen
Native abgeleitete Tabellen basieren auf Abfragen, die Sie mit LookML-Begriffen definieren. Zum Erstellen einer nativen abgeleiteten Tabelle verwenden Sie den Parameter explore_source innerhalb des Parameters derived_table eines view-Parameters. Sie erstellen die Spalten der nativen abgeleiteten Tabelle, indem Sie die LookML-Dimensionen oder -Messwerte in Ihrem Modell referenzieren. Im vorherigen Beispiel finden Sie die Ansichtsdatei für die native abgeleitete Tabelle.
Im Vergleich zu SQL-basierten abgeleiteten Tabellen sind native abgeleitete Tabellen bei der Modellierung Ihrer Daten wesentlich leichter zu lesen und zu verstehen.
Weitere Informationen zum Erstellen nativer abgeleiteter Tabellen finden Sie auf der Dokumentationsseite Native abgeleitete Tabellen erstellen.
SQL-basierte abgeleitete Tabellen
Um eine SQL-basierte abgeleitete Tabelle zu erstellen, definieren Sie eine Abfrage in SQL-Begriffen und erstellen Spalten in der Tabelle mit einer SQL-Abfrage. In einer SQL-basierten abgeleiteten Tabelle sind keine Verweise auf LookML-Dimensionen und -Messwerte möglich. Im vorherigen Beispiel finden Sie die Ansichtsdatei für die SQL-basierte abgeleitete Tabelle.
Am häufigsten definieren Sie die SQL-Abfrage mit dem Parameter sql innerhalb des Parameters derived_table eines view-Parameters.
Eine nützliche Abkürzung zum Erstellen von SQL-basierten Abfragen in Looker ist, SQL Runner zum Erstellen der SQL-Abfrage und zum Umwandeln in eine Definition für abgeleitete Tabellen zu verwenden.
In manchen Edge-Fällen kann der Parameter sql nicht verwendet werden. In diesen Fällen unterstützt Looker die folgenden Parameter zum Definieren einer SQL-Abfrage für persistente abgeleitete Tabellen (PDTs):
create_process: Wenn Sie den Parametersqlfür eine PDT verwenden, umschließt Looker im Hintergrund dieCREATE TABLE-DDL-Anweisung (Data Definition Language) des Dialekts mit Ihrer Abfrage, um die PDT aus Ihrer SQL-Abfrage zu erstellen. Eine SQL-CREATE TABLE-Anweisung in einem einzigen Schritt wird von einigen Dialekten nicht unterstützt. Bei diesen Dialekten können Sie keine PDT mit demsql-Parameter erstellen. Sie können stattdessen aber dencreate_process-Parameter verwenden, um PDTs in mehreren Schritten zu erstellen. Informationen und Beispiele finden Sie auf der Dokumentationsseite zum Parametercreate_process.sql_create: Wenn für Ihren Anwendungsfall benutzerdefinierte DDL-Befehle erforderlich sind und Ihr Dialekt DDL unterstützt (z. B. das Google-Vorhersageprodukt BigQuery ML), können Sie den Parametersql_createverwenden, um eine abgeleitete Tabelle zu erstellen, anstatt den Parametersqlzu verwenden. Informationen und Beispiele finden Sie auf der Dokumentationsseite zusql_create.
Unabhängig davon, ob Sie den Parameter sql, create_process oder sql_create verwenden, definieren Sie die abgeleitete Tabelle in allen Fällen mit einer SQL-Abfrage. Daher gelten diese alle als SQL-basierte abgeleitete Tabellen.
Achten Sie beim Definieren einer SQL-basierten abgeleiteten Tabelle darauf, jeder Spalte einen eindeutigen Alias mit AS zuzuweisen. Grund dafür ist, dass Sie die Spaltennamen Ihres Ergebnissatzes in Ihren Dimensionen referenzieren müssen, z. B. ${TABLE}.first_order. Aus diesem Grund wird im vorherigen Beispiel MIN(DATE(time)) AS first_order anstelle von MIN(DATE(time)) verwendet.
Temporäre und persistente abgeleitete Tabellen
Neben der Unterscheidung zwischen nativen abgeleiteten Tabellen und SQL-basierten abgeleiteten Tabellen gibt es auch eine Unterscheidung zwischen einer temporären abgeleiteten Tabelle, die nicht in die Datenbank geschrieben wird, und einer persistenten abgeleiteten Tabelle (PDT), die in ein Schema in Ihrer Datenbank geschrieben wird.
Native abgeleitete Tabellen und SQL-basierte abgeleitete Tabellen können entweder temporär oder persistent sein.
Temporäre abgeleitete Tabellen
Die zuvor gezeigten abgeleiteten Tabellen sind Beispiele für temporäre abgeleitete Tabellen. Sie sind temporär, da im Parameter derived_table keine Persistenzstrategie definiert ist.
Temporäre abgeleitete Tabellen werden nicht in die Datenbank geschrieben. Wenn ein Nutzer eine Explore-Abfrage mit mindestens einer abgeleiteten Tabelle ausführt, erstellt Looker eine SQL-Abfrage mit einer dialektspezifischen Kombination des SQL-Codes für die abgeleitete(n) Tabelle(n) sowie für die angeforderten Felder, Joins und Filterwerte. Wenn die Kombination schon einmal ausgeführt wurde und die Ergebnisse im Cache noch gültig sind, verwendet Looker die Ergebnisse aus dem Cache. Weitere Informationen zum Zwischenspeichern von Abfragen in Looker finden Sie auf der Dokumentationsseite Abfragen zwischenspeichern.
Wenn Looker keine zwischengespeicherten Ergebnisse verwenden kann, muss jedes Mal, wenn ein Nutzer Daten aus einer temporären abgeleiteten Tabelle anfordert, eine neue Abfrage in der Datenbank ausgeführt werden. Daher sollten Sie sich sicher sein, dass Ihre temporären abgeleiteten Tabellen leistungsstark sind und die Datenbank nicht übermäßig belasten. Wenn die Abfrage längere Zeit in Anspruch nimmt, ist eine PDT oftmals die bessere Lösung.
Unterstützte Datenbankdialekte für temporäre abgeleitete Tabellen
Damit Looker abgeleitete Tabellen in Ihrem Looker-Projekt unterstützen kann, müssen diese auch von Ihrem Datenbankdialekt unterstützt werden. In der folgenden Tabelle ist zu sehen, welche Dialekte abgeleitete Tabellen in der aktuellen Looker-Version unterstützen:
Klicken Sie hier, um die Tabelle aufzurufen.
| Dialekt | Unterstützt? |
|---|---|
| Actian Avalanche | Ja |
| Amazon Athena | Ja |
| Amazon Aurora MySQL | Ja |
| Amazon Redshift | Ja |
| Amazon Redshift 2.1+ | Ja |
| Amazon Redshift Serverless 2.1+ | Ja |
| Apache Druid | Ja |
| Apache Druid 0.13+ | Ja |
| Apache Druid 0.18+ | Ja |
| Apache Hive 2.3+ | Ja |
| Apache Hive 3.1.2+ | Ja |
| Apache Spark 3+ | Ja |
| ClickHouse | Ja |
| Cloudera Impala 3.1+ | Ja |
| Cloudera Impala 3.1+ with Native Driver | Ja |
| Cloudera Impala with Native Driver | Ja |
| DataVirtuality | Ja |
| Databricks | Ja |
| Denodo 7 | Ja |
| Denodo 8 & 9 | Ja |
| Dremio | Ja |
| Dremio 11+ | Ja |
| Exasol | Ja |
| Google BigQuery Legacy SQL | Ja |
| Google BigQuery Standard SQL | Ja |
| Google Cloud PostgreSQL | Ja |
| Google Cloud SQL | Ja |
| Google Spanner | Ja |
| Greenplum | Ja |
| HyperSQL | Ja |
| IBM Netezza | Ja |
| MariaDB | Ja |
| Microsoft Azure PostgreSQL | Ja |
| Microsoft Azure SQL Database | Ja |
| Microsoft Azure Synapse Analytics | Ja |
| Microsoft SQL Server 2008+ | Ja |
| Microsoft SQL Server 2012+ | Ja |
| Microsoft SQL Server 2016 | Ja |
| Microsoft SQL Server 2017+ | Ja |
| MongoBI | Ja |
| MySQL | Ja |
| MySQL 8.0.12+ | Ja |
| Oracle | Ja |
| Oracle ADWC | Ja |
| PostgreSQL 9.5+ | Ja |
| PostgreSQL pre-9.5 | Ja |
| PrestoDB | Ja |
| PrestoSQL | Ja |
| SAP HANA | Ja |
| SAP HANA 2+ | Ja |
| SingleStore | Ja |
| SingleStore 7+ | Ja |
| Snowflake | Ja |
| Teradata | Ja |
| Trino | Ja |
| Vector | Ja |
| Vertica | Ja |
Persistente abgeleitete Tabellen
Eine persistente abgeleitete Tabelle (PDT) ist eine abgeleitete Tabelle, die in ein Scratch-Schema in der Datenbank geschrieben und nach dem Zeitplan neu generiert wird, den Sie mit einer Persistenzstrategie angeben.
Eine PDT kann entweder eine native abgeleitete Tabelle oder eine SQL-basierte abgeleitete Tabelle sein.
Anforderungen für PDTs
Um persistente abgeleitete Tabellen (Persistent Derived Tables, PDTs) in Ihrem Looker-Projekt zu verwenden, benötigen Sie Folgendes:
- Einen Datenbankdialekt, der PDTs unterstützt. Im Abschnitt Unterstützte Datenbankdialekte für PDTs weiter unten auf dieser Seite finden Sie Listen der Dialekte, die persistente SQL-basierte abgeleitete Tabellen und persistente native abgeleitete Tabellen unterstützen.
Ein Scratch-Schema in der Datenbank. Dabei kann es sich um ein beliebiges Schema in Ihrer Datenbank handeln. Wir empfehlen aber, ein neues Schema zu erstellen, das nur zu diesem Zweck eingesetzt wird. Der Datenbankadministrator muss das Schema mit Schreibberechtigung für den Looker-Datenbankbenutzer konfigurieren.
Eine Looker-Verbindung, die mit der Ein/Aus-Schaltfläche PDTs aktivieren konfiguriert ist. Die Einstellung PDTs aktivieren wird normalerweise bei der Ersteinrichtung Ihrer Looker-Verbindung konfiguriert. Eine Anleitung für Ihren Datenbankdialekt finden Sie auf der Dokumentationsseite Looker-Dialekte. Sie können PDTs aber auch nach der Ersteinrichtung für Ihre Verbindung aktivieren.
Unterstützte Datenbankdialekte für PDTs
Damit Looker PDTs in Ihrem Looker-Projekt unterstützen kann, müssen diese auch von Ihrem Datenbankdialekt unterstützt werden.
Um persistente abgeleitete Tabellen (sowohl LookML-basiert als auch SQL-basiert) zu unterstützen, muss der Dialekt unter anderem Schreibvorgänge in die Datenbank unterstützen. Es gibt einige schreibgeschützte Datenbankkonfigurationen, die Persistenz verhindern (vor allem Postgres Hot-Swap-Replikationsdatenbanken). In diesen Fällen können Sie stattdessen temporäre abgeleitete Tabellen verwenden.
In der folgenden Tabelle sind die Dialekte aufgeführt, die persistente SQL-basierte abgeleitete Tabellen in der aktuellen Version von Looker unterstützen:
Klicken Sie hier, um die Tabelle aufzurufen.
| Dialekt | Unterstützt? |
|---|---|
| Actian Avalanche | Ja |
| Amazon Athena | Ja |
| Amazon Aurora MySQL | Ja |
| Amazon Redshift | Ja |
| Amazon Redshift 2.1+ | Ja |
| Amazon Redshift Serverless 2.1+ | Ja |
| Apache Druid | Nein |
| Apache Druid 0.13+ | Nein |
| Apache Druid 0.18+ | Nein |
| Apache Hive 2.3+ | Ja |
| Apache Hive 3.1.2+ | Ja |
| Apache Spark 3+ | Ja |
| ClickHouse | Nein |
| Cloudera Impala 3.1+ | Ja |
| Cloudera Impala 3.1+ with Native Driver | Ja |
| Cloudera Impala with Native Driver | Ja |
| DataVirtuality | Nein |
| Databricks | Ja |
| Denodo 7 | Nein |
| Denodo 8 & 9 | Nein |
| Dremio | Nein |
| Dremio 11+ | Nein |
| Exasol | Ja |
| Google BigQuery Legacy SQL | Ja |
| Google BigQuery Standard SQL | Ja |
| Google Cloud PostgreSQL | Ja |
| Google Cloud SQL | Ja |
| Google Spanner | Nein |
| Greenplum | Ja |
| HyperSQL | Nein |
| IBM Netezza | Ja |
| MariaDB | Ja |
| Microsoft Azure PostgreSQL | Ja |
| Microsoft Azure SQL Database | Ja |
| Microsoft Azure Synapse Analytics | Ja |
| Microsoft SQL Server 2008+ | Ja |
| Microsoft SQL Server 2012+ | Ja |
| Microsoft SQL Server 2016 | Ja |
| Microsoft SQL Server 2017+ | Ja |
| MongoBI | Nein |
| MySQL | Ja |
| MySQL 8.0.12+ | Ja |
| Oracle | Ja |
| Oracle ADWC | Ja |
| PostgreSQL 9.5+ | Ja |
| PostgreSQL pre-9.5 | Ja |
| PrestoDB | Ja |
| PrestoSQL | Ja |
| SAP HANA | Ja |
| SAP HANA 2+ | Ja |
| SingleStore | Ja |
| SingleStore 7+ | Ja |
| Snowflake | Ja |
| Teradata | Ja |
| Trino | Ja |
| Vector | Ja |
| Vertica | Ja |
Um persistente native abgeleitete Tabellen (mit LookML-basierten Abfragen) zu unterstützen, muss der Dialekt auch eine CREATE TABLE-DDL-Funktion unterstützen. Hier finden Sie eine Liste der Dialekte, die persistente native (LookML-basierte) abgeleitete Tabellen in der aktuellen Version von Looker unterstützen:
Klicken Sie hier, um die Tabelle aufzurufen.
| Dialekt | Unterstützt? |
|---|---|
| Actian Avalanche | Ja |
| Amazon Athena | Ja |
| Amazon Aurora MySQL | Ja |
| Amazon Redshift | Ja |
| Amazon Redshift 2.1+ | Ja |
| Amazon Redshift Serverless 2.1+ | Ja |
| Apache Druid | Nein |
| Apache Druid 0.13+ | Nein |
| Apache Druid 0.18+ | Nein |
| Apache Hive 2.3+ | Ja |
| Apache Hive 3.1.2+ | Ja |
| Apache Spark 3+ | Ja |
| ClickHouse | Nein |
| Cloudera Impala 3.1+ | Ja |
| Cloudera Impala 3.1+ with Native Driver | Ja |
| Cloudera Impala with Native Driver | Ja |
| DataVirtuality | Nein |
| Databricks | Ja |
| Denodo 7 | Nein |
| Denodo 8 & 9 | Nein |
| Dremio | Nein |
| Dremio 11+ | Nein |
| Exasol | Ja |
| Google BigQuery Legacy SQL | Ja |
| Google BigQuery Standard SQL | Ja |
| Google Cloud PostgreSQL | Ja |
| Google Cloud SQL | Nein |
| Google Spanner | Nein |
| Greenplum | Ja |
| HyperSQL | Nein |
| IBM Netezza | Ja |
| MariaDB | Ja |
| Microsoft Azure PostgreSQL | Ja |
| Microsoft Azure SQL Database | Ja |
| Microsoft Azure Synapse Analytics | Ja |
| Microsoft SQL Server 2008+ | Ja |
| Microsoft SQL Server 2012+ | Ja |
| Microsoft SQL Server 2016 | Ja |
| Microsoft SQL Server 2017+ | Ja |
| MongoBI | Nein |
| MySQL | Ja |
| MySQL 8.0.12+ | Ja |
| Oracle | Ja |
| Oracle ADWC | Ja |
| PostgreSQL 9.5+ | Ja |
| PostgreSQL pre-9.5 | Ja |
| PrestoDB | Ja |
| PrestoSQL | Ja |
| SAP HANA | Ja |
| SAP HANA 2+ | Ja |
| SingleStore | Ja |
| SingleStore 7+ | Ja |
| Snowflake | Ja |
| Teradata | Ja |
| Trino | Ja |
| Vector | Ja |
| Vertica | Ja |
Inkrementeller Aufbau von PDTs
Eine inkrementelle PDT ist eine persistente abgeleitete Tabelle, die von Looker aufgebaut wird. Dabei werden neue Daten an die Tabelle angehängt, anstatt dass die ganze Tabelle neu erstellt wird.
Wenn Ihr Dialekt inkrementelle PDTs unterstützt und Ihre PDT eine triggerbasierte Persistenzstrategie (datagroup_trigger, sql_trigger_value oder interval_trigger) verwendet, können Sie die PDT als inkrementelle PDT definieren.
Weitere Informationen finden Sie auf der Dokumentationsseite Inkrementelle PDTs.
Unterstützte Datenbankdialekte für inkrementelle PDTs
Damit Looker inkrementelle PDTs in Ihrem Looker-Projekt unterstützen kann, müssen diese auch von Ihrem Datenbankdialekt unterstützt werden. In der folgenden Tabelle ist zu sehen, welche Dialekte inkrementelle PDTs in der aktuellen Looker-Version unterstützen:
Klicken Sie hier, um die Tabelle aufzurufen.
| Dialekt | Unterstützt? |
|---|---|
| Actian Avalanche | Nein |
| Amazon Athena | Nein |
| Amazon Aurora MySQL | Nein |
| Amazon Redshift | Ja |
| Amazon Redshift 2.1+ | Ja |
| Amazon Redshift Serverless 2.1+ | Ja |
| Apache Druid | Nein |
| Apache Druid 0.13+ | Nein |
| Apache Druid 0.18+ | Nein |
| Apache Hive 2.3+ | Nein |
| Apache Hive 3.1.2+ | Nein |
| Apache Spark 3+ | Nein |
| ClickHouse | Nein |
| Cloudera Impala 3.1+ | Nein |
| Cloudera Impala 3.1+ with Native Driver | Nein |
| Cloudera Impala with Native Driver | Nein |
| DataVirtuality | Nein |
| Databricks | Ja |
| Denodo 7 | Nein |
| Denodo 8 & 9 | Nein |
| Dremio | Nein |
| Dremio 11+ | Nein |
| Exasol | Nein |
| Google BigQuery Legacy SQL | Nein |
| Google BigQuery Standard SQL | Ja |
| Google Cloud PostgreSQL | Ja |
| Google Cloud SQL | Nein |
| Google Spanner | Nein |
| Greenplum | Ja |
| HyperSQL | Nein |
| IBM Netezza | Nein |
| MariaDB | Nein |
| Microsoft Azure PostgreSQL | Ja |
| Microsoft Azure SQL Database | Nein |
| Microsoft Azure Synapse Analytics | Ja |
| Microsoft SQL Server 2008+ | Nein |
| Microsoft SQL Server 2012+ | Nein |
| Microsoft SQL Server 2016 | Nein |
| Microsoft SQL Server 2017+ | Nein |
| MongoBI | Nein |
| MySQL | Ja |
| MySQL 8.0.12+ | Ja |
| Oracle | Nein |
| Oracle ADWC | Nein |
| PostgreSQL 9.5+ | Ja |
| PostgreSQL pre-9.5 | Ja |
| PrestoDB | Nein |
| PrestoSQL | Nein |
| SAP HANA | Nein |
| SAP HANA 2+ | Nein |
| SingleStore | Nein |
| SingleStore 7+ | Nein |
| Snowflake | Ja |
| Teradata | Nein |
| Trino | Nein |
| Vector | Nein |
| Vertica | Ja |
PDTs erstellen
Um eine abgeleitete Tabelle in eine persistente abgeleitete Tabelle (PDT) umzuwandeln, definieren Sie eine Persistenzstrategie für die Tabelle. Zur Leistungsoptimierung sollten Sie zudem eine Optimierungsstrategie hinzufügen.
Persistenzstrategien
Die Persistenz einer abgeleiteten Tabelle kann von Looker oder, für Dialekte, die materialisierte Ansichten unterstützen, von Ihrer Datenbank mithilfe von materialisierten Ansichten verwaltet werden.
Um eine abgeleitete Tabelle persistent zu machen, fügen Sie einen der folgenden Parameter zur derived_table-Definition hinzu:
- Von Looker verwaltete Persistenzparameter:
- Von Datenbanken verwaltete Parameter:
Bei auslöserbasierten Persistenzstrategien (datagroup_trigger, sql_trigger_value und interval_trigger) behält Looker die PDT in der Datenbank bei, bis die PDT für die Neuerstellung ausgelöst wird. Nach Auslösen der PDT erstellt Looker die PDT neu, um die vorherige Version zu ersetzen. Das heißt, die Benutzer müssen mit Trigger-basierten PDTs in den meisten Fällen nicht auf die Erstellung der PDT warten, um Antworten für Explore-Abfragen aus der PDT zu erhalten.
datagroup_trigger
Datengruppen sind die flexibelste Methode zur Schaffung von Persistenz. Wenn Sie eine Datengruppe mit sql_trigger oder interval_trigger definiert haben, können Sie mit dem Parameter datagroup_trigger die Neuerstellung Ihrer persistenten abgeleiteten Tabellen (Persistent Derived Tables, PDTs) initiieren.
Looker behält die PDT in der Datenbank bei, bis die zugehörige Datengruppe ausgelöst wird. Nach Auslösen der Datengruppe erstellt Looker die PDT neu, um die vorherige Version zu ersetzen. Das heißt, die Benutzer müssen in den meisten Fällen nicht auf die Erstellung der PDT warten. Wenn ein Nutzer Daten aus der PDT anfordert, während diese erstellt wird, und die Abfrageergebnisse nicht im Cache enthalten sind, gibt Looker Daten aus der vorhandenen PDT zurück, bis die neue PDT erstellt wurde. Eine Übersicht über Datengruppen finden Sie unter Abfragen im Cache speichern.
Weitere Informationen zur Erstellung von PDTs durch den Regenerator finden Sie im Abschnitt Looker-Regenerator.
sql_trigger_value
Der Parameter sql_trigger_value löst die Neuerstellung einer persistenten abgeleiteten Tabelle (Persistent Derived Table, PDT) aus, die auf einer von Ihnen bereitgestellten SQL-Anweisung basiert. Wenn das Ergebnis der SQL-Anweisung sich vom vorherigen Wert unterscheidet, wird die PDT neu generiert. Andernfalls wird die vorhandene PDT in der Datenbank beibehalten. Das heißt, die Benutzer müssen in den meisten Fällen nicht auf die Erstellung der PDT warten. Wenn ein Nutzer Daten aus der PDT anfordert, während diese erstellt wird, und die Abfrageergebnisse nicht im Cache enthalten sind, gibt Looker Daten aus der vorhandenen PDT zurück, bis die neue PDT erstellt wurde.
Weitere Informationen zur Erstellung von PDTs durch den Regenerator finden Sie im Abschnitt Looker-Regenerator.
interval_trigger
Der Parameter interval_trigger löst die Neuerstellung einer persistenten abgeleiteten Tabelle (Persistent Derived Table, PDT) basierend auf einem von Ihnen angegebenen Zeitintervall aus, z. B. "24 hours" oder "60 minutes". Ähnlich wie beim Parameter sql_trigger bedeutet dies, dass die PDT normalerweise vorab erstellt wird, wenn der Nutzer sie abfragt. Wenn ein Nutzer Daten aus der PDT anfordert, während diese erstellt wird, und die Abfrageergebnisse nicht im Cache enthalten sind, gibt Looker Daten aus der vorhandenen PDT zurück, bis die neue PDT erstellt wurde.
persist_for
Eine weitere Option ist die Verwendung des Parameters persist_for, um festzulegen, wie lange die abgeleitete Tabelle gespeichert werden soll, bevor sie als abgelaufen markiert wird. Sie wird dann nicht mehr für Abfragen verwendet und aus der Datenbank gelöscht.
Eine persist_forpersistente abgeleitete Tabelle (Persistent Derived Table, PDT) wird erstellt, wenn ein Nutzer die erste Abfrage damit ausführt. Looker behält die PDT dann so lange wie im persist_for-Parameter der PDT angegeben in der Datenbank bei. Wenn ein Nutzer die PDT innerhalb der persist_for-Zeit abfragt, verwendet Looker nach Möglichkeit zwischengespeicherte Ergebnisse. Andernfalls wird die Abfrage mit der PDT ausgeführt.
Nach der persist_for-Zeit löscht Looker die PDT aus der Datenbank. Sie wird dann bei der nächsten Abfrage durch einen Nutzer neu erstellt. In dem Fall muss die Abfrage warten, bis die Neuerstellung abgeschlossen ist.
PDTs, für die persist_for verwendet wird, werden vom Looker-Regenerator nicht automatisch neu erstellt, außer bei einer Kaskade von PDTs mit Abhängigkeiten. Wenn eine persist_for-Tabelle Teil einer Abhängigkeitskaskade mit triggerbasierten PDTs ist (PDTs, die die Persistenzstrategie datagroup_trigger, interval_trigger oder sql_trigger_value verwenden), überwacht und erstellt der Regenerator die persist_for-Tabelle neu, um andere Tabellen in der Kaskade neu zu erstellen. Weitere Informationen finden Sie im Abschnitt So erstellt Looker kaskadierende abgeleitete Tabellen auf dieser Seite.
materialized_view: yes
Nutzen Sie die Funktion für eine materialisierte Ansicht Ihrer Datenbank, um abgeleitete Tabellen in Ihrem Looker-Projekt zu persistieren. Wenn Ihr Datenbankdialekt materialisierte Ansichten unterstützt und Ihre Looker-Verbindung mit der Ein/Aus-Schaltfläche PDTs aktivieren konfiguriert ist, können Sie eine materialisierte Ansicht erstellen, indem Sie materialized_view: yes für eine abgeleitete Tabelle angeben. Materialisierte Ansichten werden sowohl für native abgeleitete Tabellen als auch für SQL-basierte abgeleitete Tabellen unterstützt.
Ähnlich wie eine persistente abgeleitete Tabelle (PDT) ist eine materialisierte Ansicht ein Abfrageergebnis, das im Scratch-Schema Ihrer Datenbank als Tabelle gespeichert wird. Der Hauptunterschied zwischen einer PDT und einer materialisierten Ansicht besteht in der Aktualisierung der Tabellen:
- Bei PDTs wird die Persistenzstrategie von Looker definiert und die Persistenz von Looker verwaltet.
- Bei materialisierten Ansichten ist die Datenbank für die Verwaltung und Aktualisierung der Daten in der Tabelle zuständig.
Deshalb benötigen Sie für die Funktionalität der materialisierten Ansicht fortgeschrittenes Wissen um Ihren Dialekt und seine Funktionen. In den meisten Fällen aktualisiert Ihre Datenbank die materialisierte Ansicht jedes Mal, wenn die Datenbank neue Daten in den Tabellen erkennt, die von der materialisierte Ansicht abgefragt werden. Materialisierte Ansichten eignen sich ideal für Szenarien, die Echtzeitdaten erfordern.
Informationen zur Unterstützung von Dialekten, zu Anforderungen und wichtigen Überlegungen finden Sie auf der Dokumentationsseite zum Parameter materialized_view.
Optimierungsstrategien
Da persistente abgeleitete Tabellen (Persistent Derived Tables, PDTs) in Ihrer Datenbank gespeichert werden, sollten Sie die PDTs mit den folgenden Strategien optimieren, je nach Unterstützung durch Ihren Dialekt:
Wenn Sie beispielsweise die abgeleitete Tabelle persistent machen möchten, können Sie festlegen, dass sie neu erstellt wird, wenn die Datengruppe orders_datagroup ausgelöst wird, und Indizes für customer_id und first_order hinzufügen:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
Wenn Sie keinen Index (oder eine Entsprechung für Ihren Dialekt) hinzufügen, werden Sie von Looker gewarnt, dass Sie dies zur Steigerung der Abfrageleistung nachholen sollten.
Anwendungsfälle für PDTs
Persistent Derived Tables (PDTs, persistente abgeleitete Tabellen) sind nützlich, weil sie die Leistung einer Abfrage verbessern können, indem die Ergebnisse der Abfrage in einer Tabelle gespeichert werden.
Als allgemeine Best Practice sollten Entwickler versuchen, Daten ohne PDTs zu modellieren, bis dies unbedingt erforderlich ist.
In einigen Fällen können Daten auf andere Weise optimiert werden. Wenn Sie beispielsweise einen Index hinzufügen oder den Datentyp einer Spalte ändern, lässt sich ein Problem möglicherweise beheben, ohne dass eine PDT erstellt werden muss. Analysieren Sie die Ausführungspläne langsamer Abfragen mit dem Tool „Explain from SQL Runner“.
Neben der Verkürzung der Abfragezeit und der Verringerung der Datenbanklast bei häufig ausgeführten Abfragen gibt es mehrere andere Anwendungsfälle für PDTs, darunter:
Sie können auch einen PDT verwenden, um einen Primärschlüssel zu definieren, wenn es keine sinnvolle Möglichkeit gibt, eine eindeutige Zeile in einer Tabelle als Primärschlüssel zu identifizieren.
PDTs zum Testen von Optimierungen verwenden
Mit temporären abgeleiteten Tabellen können Sie verschiedene Indexierungs-, Verteilungs- und andere Optimierungsoptionen testen, ohne dass Sie viel Unterstützung von Ihrem Datenbankadministrator oder ETL-Entwicklern benötigen.
Angenommen, Sie haben eine Tabelle, möchten aber verschiedene Indexe testen. Ihr ursprüngliches LookML für die Ansicht könnte so aussehen:
view: customer {
sql_table_name: warehouse.customer ;;
}
Wenn Sie Optimierungsstrategien testen möchten, können Sie mit dem Parameter indexes Indexe zur LookML hinzufügen:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Fragen Sie die Ansicht einmal ab, um die PDT zu generieren. Führen Sie dann Ihre Testabfragen aus und vergleichen Sie die Ergebnisse. Wenn die Ergebnisse positiv sind, können Sie Ihr DBA- oder ETL-Team bitten, die Indexe der Originaltabelle hinzuzufügen.
Denken Sie daran, den Ansichtscode wieder zu ändern, um die PDT zu entfernen.
PDTs zum Vorab-Verknüpfen oder -Aggregieren von Daten verwenden
Es kann sinnvoll sein, Daten vorab zu verknüpfen oder zusammenzufassen, um die Abfrageoptimierung für große Datenmengen oder mehrere Datentypen anzupassen.
Angenommen, Sie möchten eine Abfrage für Kunden nach Kohorte erstellen, die auf dem Zeitpunkt der ersten Bestellung basiert. Diese Abfrage kann teuer sein, wenn sie jedes Mal ausgeführt werden muss, wenn die Daten in Echtzeit benötigt werden. Sie können die Abfrage jedoch nur einmal berechnen und die Ergebnisse dann mit einem PDT wiederverwenden:
view: customer_order_facts {
derived_table: {
sql: SELECT
c.customer_id,
MIN(o.order_date) OVER (PARTITION BY c.customer_id) AS first_order_date,
MAX(o.order_date) OVER (PARTITION BY c.customer_id) AS most_recent_order_date,
COUNT(o.order_id) OVER (PARTITION BY c.customer_id) AS lifetime_orders,
SUM(o.order_value) OVER (PARTITION BY c.customer_id) AS lifetime_value,
RANK() OVER (PARTITION BY c.customer_id ORDER BY o.order_date ASC) AS order_sequence,
o.order_id
FROM warehouse.customer c LEFT JOIN warehouse.order o ON c.customer_id = o.customer_id
;;
sql_trigger_value: SELECT CURRENT_DATE ;;
indexes: [customer_id, order_id, order_sequence, first_order_date]
}
}
Kaskadierende abgeleitete Tabellen
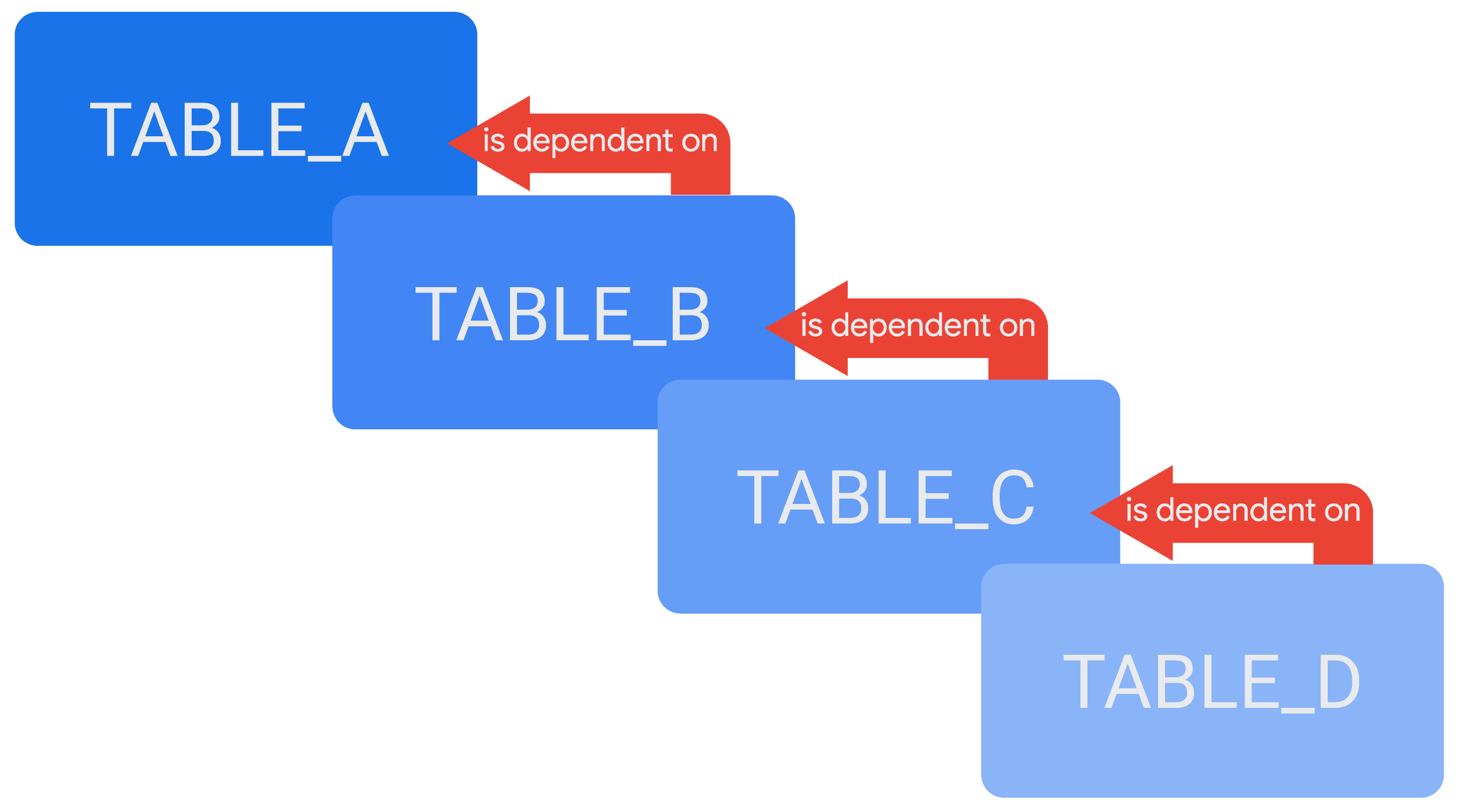
Es ist möglich, in der Definition einer abgeleiteten Tabelle auf eine andere zu verweisen. So entsteht eine Kette von kaskadierenden abgeleiteten Tabellen oder kaskadierenden persistenten abgeleiteten Tabellen (Persistent Derived Tables, PDTs). Ein Beispiel für kaskadierende abgeleitete Tabellen ist eine Tabelle TABLE_D, die von einer anderen Tabelle TABLE_C abhängt, während TABLE_C von TABLE_B und TABLE_B von TABLE_A abhängt.
Syntax für den Verweis auf eine abgeleitete Tabelle
Verwenden Sie diese Syntax, um in einer abgeleiteten Tabelle auf eine andere abgeleitete Tabelle zu verweisen:
`${derived_table_or_view_name.SQL_TABLE_NAME}`
In diesem Format ist SQL_TABLE_NAME ein Literalstring. Beispiel: Sie können mit der folgenden Syntax auf die abgeleitete Tabelle clean_events verweisen:
`${clean_events.SQL_TABLE_NAME}`
Mit derselben Syntax können Sie auch auf eine LookML-Ansicht verweisen. Auch in diesem Fall ist SQL_TABLE_NAME ein Literalstring.
Im nächsten Beispiel wird die PDT clean_events aus der Tabelle events in der Datenbank erstellt. Bei der PDT clean_events werden unerwünschte Zeilen aus der Datenbanktabelle events ausgelassen. Dann wird eine zweite PDT angezeigt. Die event_summary-PDT ist eine Zusammenfassung der clean_events-PDT. Die Tabelle event_summary wird immer dann neu generiert, wenn clean_events neue Zeilen hinzugefügt werden.
Die PDT event_summary und die PDT clean_events sind kaskadierende PDTs, wobei event_summary von clean_events abhängig ist, da event_summary mit der PDT clean_events definiert wird. Dieser spezielle Beispielvorgang könnte in einer einzelnen PDT effizienter durchgeführt werden, doch zur Veranschaulichung von Verweisen auf abgeleitete Tabellen ist dies nützlich.
view: clean_events {
derived_table: {
sql:
SELECT *
FROM events
WHERE type NOT IN ('test', 'staff') ;;
datagroup_trigger: events_datagroup
}
}
view: events_summary {
derived_table: {
sql:
SELECT
type,
date,
COUNT(*) AS num_events
FROM
${clean_events.SQL_TABLE_NAME} AS clean_events
GROUP BY
type,
date ;;
datagroup_trigger: events_datagroup
}
}
Oftmals ist es hilfreich, beim Verweisen auf eine abgeleitete Tabelle in dieser Form einen Aliasnamen für die Tabelle im folgenden Format zu verwenden:
${derived_table_or_view_name.SQL_TABLE_NAME} AS derived_table_or_view_name
Das ist im vorherigen Beispiel der Fall:
${clean_events.SQL_TABLE_NAME} AS clean_events
Es bietet sich an, einen Alias zu verwenden, da PDTs in der Datenbank lange Codes als Namen erhalten. Bisweilen (insbesondere bei ON-Klauseln) vergisst man schnell, dass man zum Abrufen dieses langen Namens die Syntax ${derived_table_or_view_name.SQL_TABLE_NAME} verwenden muss. Mit einem Aliasnamen kann dieser Fehler vermieden werden.
So erstellt Looker kaskadierende abgeleitete Tabellen
Wenn die Abfrageergebnisse eines Nutzers bei kaskadierenden temporären abgeleiteten Tabellen nicht im Cache enthalten sind, erstellt Looker alle abgeleiteten Tabellen, die für die Abfrage benötigt werden. Wenn Sie ein TABLE_D haben, dessen Definition einen Verweis auf TABLE_C enthält, ist TABLE_D von TABLE_C abhängig. Wenn Sie in diesem Fall TABLE_D abfragen und die Abfrage nicht im Cache von Looker enthalten ist, erstellt Looker TABLE_D neu. Zuerst muss TABLE_C jedoch neu aufgebaut werden.
Stellen Sie sich ein Szenario mit kaskadierenden temporären abgeleiteten Tabellen vor, in dem TABLE_D von TABLE_C, TABLE_C von TABLE_B und TABLE_B von TABLE_A abhängt. Wenn Looker keine gültigen Ergebnisse für eine Abfrage von TABLE_C im Cache enthält, erstellt Looker alle für die Abfrage benötigten Tabellen. Looker erstellt also zuerst TABLE_A, dann TABLE_B und dann TABLE_C:
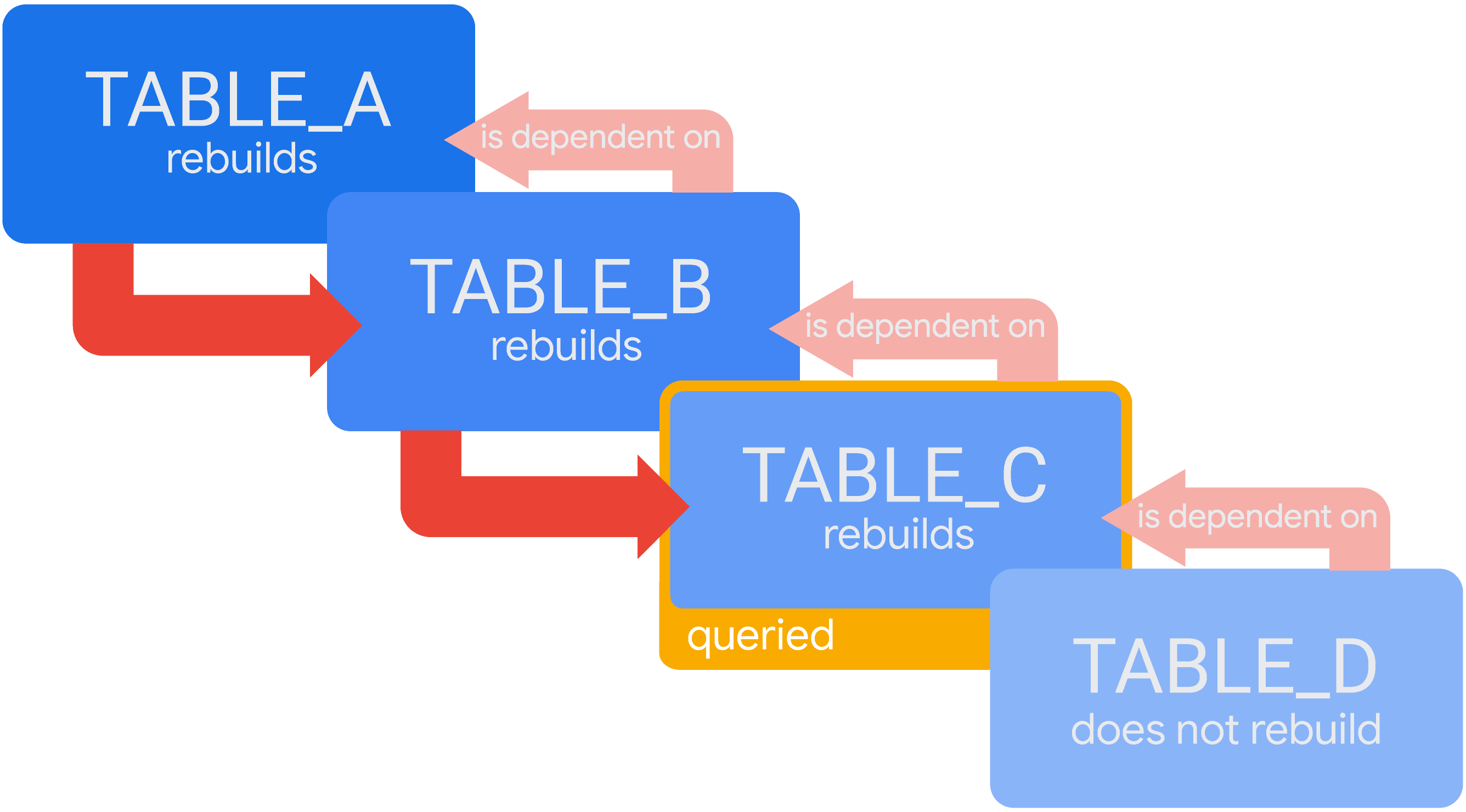
In diesem Szenario muss TABLE_A fertig generiert werden, bevor Looker mit der Generierung von TABLE_B beginnen kann. Außerdem muss TABLE_B fertig generiert werden, bevor Looker mit der Generierung von TABLE_C beginnen kann. Wenn TABLE_C abgeschlossen ist, werden die Abfrageergebnisse in Looker angezeigt. Da TABLE_D nicht erforderlich ist, um diese Anfrage zu beantworten, wird TABLE_D derzeit nicht neu erstellt.
Ein Beispiel für kaskadierende PDTs, die dieselbe Datengruppe verwenden, finden Sie auf der Dokumentationsseite zum Parameter datagroup.
Dieselbe grundlegende Logik gilt für PDTs: Looker erstellt alle zum Beantworten einer Abfrage erforderlichen Tabellen entlang der ganzen Abhängigkeitskette. Bei PDTs sind die Tabellen aber oft schon vorhanden, sodass sie nicht neu erstellt werden müssen. Bei Standardbenutzerabfragen mit kaskadierenden PDTs erstellt Looker die PDTs in der Kaskade nur dann neu, wenn keine gültige Version der PDTs in der Datenbank vorhanden ist. Wenn Sie eine Neuerstellung für alle PDTs in einer Kaskade erzwingen möchten, können Sie die Tabellen für eine Abfrage manuell über ein Explore neu erstellen.
Beachten Sie unbedingt im Zusammenhang mit einer PDT-Kaskade, dass eine abhängige PDT im Wesentlichen die PDT abfragt, von der sie abhängig ist. Das ist vor allem bei PDTs wichtig, die die persist_for-Strategie verwenden. In der Regel werden persist_for-PDTs erstellt, wenn ein Nutzer sie abfragt. Sie verbleiben dann bis zum Ende ihres persist_for-Intervalls in der Datenbank und werden dann erst wieder neu erstellt, wenn sie erneut von einem Nutzer abgefragt werden. Wenn eine persist_for-PDT jedoch Teil einer Kaskade mit triggerbasierten PDTs ist (PDTs, die die Persistenzstrategie datagroup_trigger, interval_trigger oder sql_trigger_value verwenden), wird die persist_for-PDT im Wesentlichen immer dann abgefragt, wenn ihre abhängigen PDTs neu erstellt werden. In diesem Fall wird die persist_for-PDT also gemäß dem Zeitplan ihrer abhängigen PDTs neu erstellt. Das bedeutet, dass persist_for-PDTs von der Persistenzstrategie ihrer abhängigen PDTs betroffen sein können.
Persistente Tabellen für eine Abfrage manuell neu erstellen
Nutzer können im Menü eines Explores die Option Abgeleitete Tabellen neu erstellen und ausführen auswählen, um die Persistenzeinstellungen zu überschreiben und alle persistenten abgeleiteten Tabellen (PDTs) und aggregierten Tabellen neu zu erstellen, die für die aktuelle Abfrage im Explore erforderlich sind:
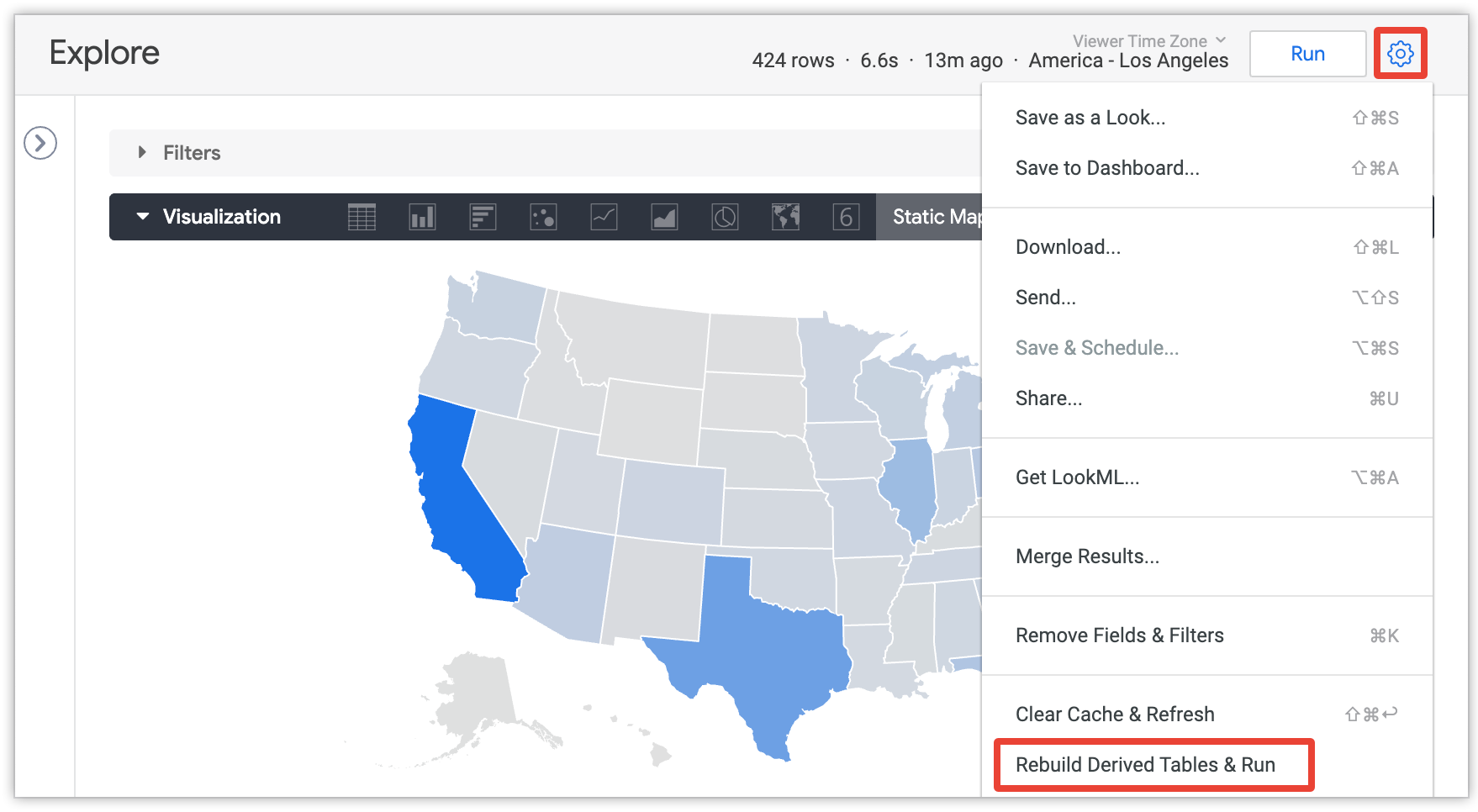
Diese Option ist nur für Nutzer mit der Berechtigung develop sichtbar und erst, nachdem die Explore-Abfrage geladen wurde.
Mit der Option Abgeleitete Tabellen neu erstellen und ausführen werden alle persistenten Tabellen (alle PDTs und aggregierten Tabellen) neu erstellt, die zum Beantworten der Abfrage erforderlich sind, unabhängig von ihrer Persistenzstrategie. Dazu gehören alle aggregierten Tabellen und PDTs in der aktuellen Abfrage sowie alle aggregierten Tabellen und PDTs, die von den aggregierten Tabellen und PDTs in der aktuellen Abfrage referenziert werden.
Bei inkrementellen PDTs wird mit der Option Abgeleitete Tabellen neu erstellen und ausführen die Erstellung eines neuen Inkrements ausgelöst. Bei inkrementellen PDTs umfasst ein Inkrement den Zeitraum, der im Parameter increment_key angegeben ist, sowie die Anzahl der vorherigen Zeiträume, die im Parameter increment_offset angegeben sind (falls vorhanden). Auf der Dokumentationsseite Inkrementelle PDTs finden Sie einige Beispielszenarien, die zeigen, wie inkrementelle PDTs je nach Konfiguration erstellt werden.
Bei kaskadierenden PDTs werden alle abgeleiteten Tabellen in der Kaskade von oben nach unten neu erstellt. Das ist mit dem Verhalten beim Abfragen einer Tabelle in einer Kaskade aus temporären abgeleiteten Tabellen identisch:
Beachten Sie Folgendes zum manuellen Neuerstellen abgeleiteter Tabellen:
- Für den Nutzer, der den Vorgang Rebuild Derived Tables & Run startet, werden die Ergebnisse erst geladen, wenn die Tabellen neu erstellt wurden. Abfragen anderer Nutzer verwenden weiterhin die bestehenden Tabellen. Wenn die persistenten Tabellen erneut erstellt wurden, verwenden alle Benutzer die neu erstellten Tabellen. Dieser Prozess soll verhindern, dass die Abfragen anderer Nutzer während der Neuerstellung der Tabellen unterbrochen werden. Diese Nutzer können allerdings dennoch von der zusätzlichen Belastung der Datenbank betroffen sein. Wenn das Auslösen einer Neuerstellung während der Arbeitszeit die Datenbank übermäßig belasten würde, müssen Sie möglicherweise die Benutzer informieren, dass bestimmte PDTs oder aggregierte Tabellen nicht während der Geschäftszeiten neu erstellt werden sollten.
Wenn sich ein Nutzer im Entwicklungsmodus befindet und das Explore auf einer Entwicklungstabelle basiert, wird mit dem Vorgang Abgeleitete Tabellen neu erstellen und ausführen die Entwicklungstabelle und nicht die Produktionstabelle für das Explore neu erstellt. Wenn im Entwicklungsmodus jedoch die Produktionsversion einer abgeleiteten Tabelle verwendet wird, wird die Produktionstabelle neu erstellt. Weitere Informationen zu Entwicklungs- und Produktionstabellen finden Sie unter Persistente Tabellen im Entwicklungsmodus.
Wenn die Neuerstellung einer abgeleiteten Tabelle in Looker-gehosteten Instanzen länger als eine Stunde dauert, wird die Tabelle nicht erfolgreich neu erstellt und die Browsersitzung läuft ab. Weitere Informationen zu Zeitüberschreitungen, die sich auf Looker-Prozesse auswirken können, finden Sie in der Dokumentation Administratoreinstellungen – Abfragen im Abschnitt Zeitüberschreitungen bei Abfragen und Warteschlangen.
Persistente Tabellen im Entwicklungsmodus
In Looker gibt es spezielle Verhaltensweisen zum Verwalten persistenter Tabellen im Entwicklungsmodus.
Wenn Sie eine persistente Tabelle im Entwicklungsmodus abfragen, ohne Änderungen an ihrer Definition vorzunehmen, fragt Looker die Produktionsversion dieser Tabelle ab. Wenn Sie Änderungen an der Tabellendefinition vornehmen, die sich auf die Daten in der Tabelle auswirken oder auf die Abfrageart der Tabelle, wird beim nächsten Abfragen der Tabelle im Entwicklungsmodus eine neue Entwicklungsversion der Tabelle erstellt. Mit einer solchen Entwicklungstabelle können Sie Änderungen testen, ohne Nutzer zu stören.
Was veranlasst Looker zur Erstellung einer Entwicklungstabelle?
Soweit möglich, verwendet Looker die vorhandene Produktionstabelle zum Beantworten von Abfragen, unabhängig davon, ob Sie sich im Entwicklungsmodus befinden. Es gibt jedoch bestimmte Fälle, in denen Looker die Produktionstabelle nicht für Abfragen im Entwicklungsmodus verwenden kann:
- Wenn die persistente Tabelle einen Parameter aufweist, mit dem das Dataset verringert wird, damit es im Entwicklungsmodus schneller funktioniert.
- Wenn Sie Änderungen an der Definition der persistenten Tabelle vorgenommen haben, die sich auf die Daten in der Tabelle auswirken.
Looker erstellt eine Entwicklungstabelle, wenn Sie sich im Entwicklungsmodus befinden und eine SQL-basierte abgeleitete Tabelle abfragen, die mit einer bedingten WHERE-Klausel mit if prod- und if dev-Anweisungen definiert ist.
Bei persistenten Tabellen, für die es keinen Parameter zum Einschränken des Datasets im Entwicklungsmodus gibt, verwendet Looker die Produktionsversion der Tabelle zum Beantworten von Abfragen im Entwicklungsmodus, es sei denn, Sie ändern die Definition der Tabelle und fragen die Tabelle dann im Entwicklungsmodus ab. Dies gilt für alle Änderungen an der Tabelle, die sich auf die Daten in der Tabelle auswirken oder auf die Art und Weise, wie die Tabelle abgefragt wird.
Im Folgenden finden Sie einige Beispiele für die Arten von Änderungen, die Looker zum Erstellen einer Entwicklungsversion einer persistenten Tabelle veranlassen (Looker erstellt die Tabelle nur dann, wenn Sie die Tabelle abfragen, nachdem Sie die Änderungen vorgenommen haben):
- Ändern der Abfrage, auf der die persistente Tabelle basiert, z. B. durch Ändern des Parameters
explore_source,sql,query,sql_createodercreate_processin der persistenten Tabelle selbst oder in einer erforderlichen Tabelle (bei kaskadierenden abgeleiteten Tabellen) - Ändern der Persistenzstrategie der Tabelle, z. B. durch Ändern des Parameters
datagroup_trigger,sql_trigger_value,interval_triggeroderpersist_forder Tabelle - Name der
vieweiner abgeleiteten Tabelle ändern increment_keyoderincrement_offseteiner inkrementellen PDT ändernconnectionändern, das vom zugehörigen Modell verwendet wird
Bei Änderungen, die die Daten der Tabelle nicht modifizieren oder sich auf die Abfrage der Tabelle durch Looker auswirken, erstellt Looker keine Entwicklungstabelle. Der Parameter publish_as_db_view ist ein gutes Beispiel: Wenn Sie im Entwicklungsmodus nur die publish_as_db_view-Einstellung für eine abgeleitete Tabelle ändern, muss Looker die abgeleitete Tabelle nicht neu erstellen und erstellt deshalb keine Entwicklungstabelle.
Wie lange sind Entwicklungstabellen in Looker abgeleitet?
Unabhängig von der tatsächlichen Persistenzstrategie der Tabelle behandelt Looker Entwicklungstabellen so, als hätten sie die Persistenzstrategie persist_for: "24 hours". So wird sichergestellt, dass Entwicklungstabellen nicht länger als einen Tag lang persistent bleiben. Immerhin könnte ein Looker-Entwickler viele Iterationen einer Tabelle bei der Entwicklung abfragen, sodass jedes Mal eine neue Entwicklungstabelle erstellt wird. Um zu verhindern, dass die Datenbank mit zu vielen Entwicklungstabellen überlastet wird, wendet Looker die persist_for: "24 hours"-Strategie an. Damit werden die Tabellen regelmäßig aus der Datenbank gelöscht.
Davon abgesehen erstellt Looker persistente abgeleitete Tabellen (PDTs) und aggregierte Tabellen im Entwicklungsmodus genauso wie persistente Tabellen im Produktionsmodus.
Wenn eine Entwicklungstabelle in der Datenbank persistent ist, wenn Sie Änderungen an einer PDT oder aggregierten Tabelle bereitstellen, kann Looker die Entwicklungstabelle häufig als Produktionstabelle verwenden, sodass die Nutzer nicht erst auf die Erstellung der Tabelle warten müssen, wenn sie sie abfragen.
Hinweis: Wenn Sie Ihre Änderungen bereitstellen, muss die Tabelle unter Umständen immer noch neu erstellt werden, um in der Produktion abgefragt werden zu können. Das hängt von der jeweiligen Situation ab:
- Wenn Sie die Tabelle seit mehr als 24 Stunden nicht im Entwicklungsmodus abgefragt haben, wird die Entwicklungsversion der Tabelle als abgelaufen markiert und nicht für Abfragen verwendet. Sie können in der Looker-IDE oder auf dem Tab Entwicklung der Seite Abgeleitete persistente Tabellen nach nicht erstellten PDTs suchen. Falls nicht erstellte PDTs vorhanden sind, können Sie diese unmittelbar vor dem Vornehmen Ihrer Änderungen im Entwicklungsmodus abfragen, damit die Entwicklungstabelle in der Produktion verwendet werden kann.
- Wenn eine persistente Tabelle den Parameter
dev_filters(für native abgeleitete Tabellen) oder die bedingteWHERE-Klausel mit den Anweisungenif produndif dev(für SQL-basierte abgeleitete Tabellen) enthält, kann die Entwicklungstabelle nicht als Produktionsversion verwendet werden, da die Entwicklungsversion einen reduzierten Datensatz enthält. In diesem Fall können Sie nach Abschluss der Tabellenentwicklung und vor Bereitstellung der Änderungen den Parameterdev_filtersoder die bedingteWHERE-Klausel herauskommentieren und anschließend die Tabelle im Entwicklungsmodus abfragen. Looker erstellt dann eine vollständige Version der Tabelle, die für die Produktion verwendet werden kann, wenn Sie Ihre Änderungen bereitstellen.
Wenn Sie Ihre Änderungen bereitstellen, obwohl keine gültige Entwicklungstabelle vorhanden ist, die als Produktionstabelle verwendet werden kann, wird die Tabelle in Looker beim nächsten Mal neu erstellt, wenn sie im Produktionsmodus abgefragt wird (für persistente Tabellen, die die persist_for-Strategie verwenden), oder beim nächsten Ausführen des Regenerators (für persistente Tabellen, die datagroup_trigger, interval_trigger oder sql_trigger_value verwenden).
Nach nicht erstellten PDTs im Entwicklungsmodus suchen
Wenn eine Entwicklungstabelle in der Datenbank persistent ist, wenn Sie Änderungen an einer persistenten abgeleiteten Tabelle (Persistent Derived Table, PDT) oder einer aggregierten Tabelle bereitstellen, kann Looker die Entwicklungstabelle häufig als Produktionstabelle verwenden, sodass die Nutzer nicht erst auf die Erstellung der Tabelle warten müssen, wenn sie sie abfragen. Weitere Informationen finden Sie in den Abschnitten Wie lange sind Entwicklungstabellen in Looker abgeleitet? und Was veranlasst Looker zur Erstellung einer Entwicklungstabelle? auf dieser Seite.
Daher sollten im Optimalfall alle Ihre PDTs bei der Bereitstellung in der Produktion erstellt sein, damit die Tabellen sofort als Produktionsversionen verwendet werden können.
Sie können Ihr Projekt im Bereich Projektzustand auf nicht erstellte PDTs überprüfen. Klicken Sie in der Looker-IDE auf das Symbol Project Health (Projektstatus), um den Bereich Project Health zu öffnen. Klicken Sie dann auf die Schaltfläche PDT-Status validieren.
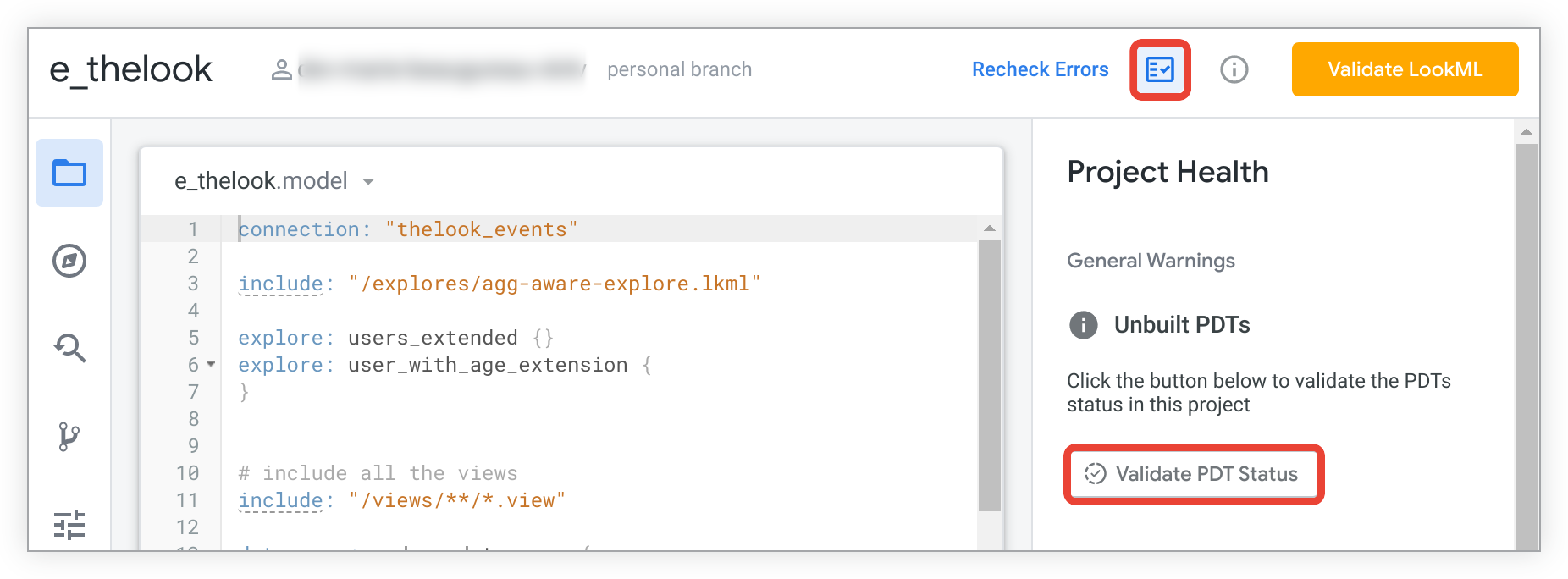
Falls nicht erstellte PDTs vorhanden sind, werden diese im Bereich Project Health aufgeführt:
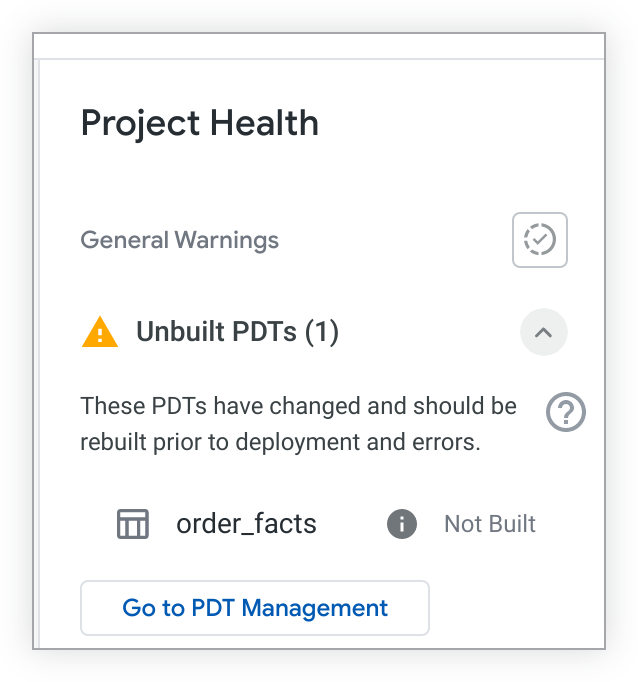
Wenn Sie die Berechtigung see_pdts haben, können Sie auf die Schaltfläche Zur PAT-Verwaltung klicken. Looker öffnet den Entwicklungs-Tab der Seite Persistente abgeleitete Tabellen und filtert die Ergebnisse nach Ihrem LookML-Projekt. Hier können Sie feststellen, welche Entwicklungs-PDTs erstellt und welche nicht erstellt wurden, und auf andere Informationen zur Fehlersuche zugreifen. Weitere Informationen finden Sie auf der Dokumentationsseite Administratoreinstellungen – Persistente abgeleitete Tabellen.
Nachdem Sie eine nicht erstellte PDT in Ihrem Projekt gefunden haben, können Sie eine Entwicklungsversion davon erstellen, indem Sie einen Explore öffnen, der die Tabelle abfragt, und dann die Option Abgeleitete Tabellen neu erstellen & ausführen im Explore-Menü verwenden. Weitere Informationen finden Sie im Abschnitt Persistente Tabellen für eine Abfrage manuell neu erstellen auf dieser Seite.
Tabellen gemeinsam nutzen und bereinigen
Innerhalb einer Looker-Instanz können Tabellen von Benutzern gemeinsam verwendet werden, wenn die Tabellen über dieselbe Definition und dieselbe Einstellung für die Persistenzmethode verfügen. Außerdem wird eine Tabelle von Looker als abgelaufen markiert, sobald ihre Definition nicht mehr vorhanden ist.
Das bringt mehrere Vorteile mit sich:
- Wenn Sie keine Änderungen an einer Tabelle im Entwicklungsmodus vorgenommen haben, werden Ihre Abfragen auf die vorhandenen Produktionstabellen angewendet. Dies ist nur dann nicht der Fall, wenn Ihre Tabelle eine SQL-basierte abgeleitete Tabelle ist, die mit einer bedingten
WHERE-Klausel mitif prod- undif dev-Anweisungen definiert wird. Wenn die Tabelle mit einer bedingtenWHERE-Klausel definiert wird, erstellt Looker eine Entwicklungstabelle, wenn Sie die Tabelle im Entwicklungsmodus abfragen. Bei nativen abgeleiteten Tabellen mit dem Parameterdev_filtersverfügt Looker über die Logik für die Verwendung der Produktionstabelle zum Beantworten von Abfragen im Entwicklungsmodus, es sei denn, Sie ändern die Definition der Tabelle und fragen die Tabelle dann im Entwicklungsmodus ab. - Sollten zwei Entwickler zufällig im Entwicklungsmodus dieselbe Änderung an einer Tabelle vornehmen, verwenden sie gemeinsam dieselbe Entwicklungstabelle.
- Sobald Ihre Änderungen vom Entwicklungsmodus an den Produktionsmodus übergeben wurden, ist die alte Produktionsdefinition nicht mehr vorhanden. Daraufhin wird die alte Produktionstabelle als abgelaufen markiert und verworfen.
- Wenn Sie Ihre Änderungen im Entwicklungsmodus verwerfen, ist diese Tabellendefinition nicht mehr vorhanden. Daher werden die nicht mehr benötigten Entwicklungstabellen als abgelaufen markiert und verworfen.
Schnelleres Arbeiten im Entwicklungsmodus
Es gibt Situationen, in denen das Generieren der persistenten abgeleiteten Tabelle (Persistent Derived Table, PDT), die Sie gerade erstellen, sehr lange dauert. Wenn Sie viele Änderungen im Entwicklungsmodus testen möchten, kann dies sehr zeitaufwendig sein. In diesen Fällen können Sie Looker auffordern, kleinere Versionen einer abgeleiteten Tabelle zu erstellen, wenn Sie sich im Entwicklungsmodus befinden.
Bei nativen abgeleiteten Tabellen können Sie mit dem Unterparameter dev_filters von explore_source Filter angeben, die nur auf Entwicklungsversionen der abgeleiteten Tabelle angewendet werden:
view: e_faa_pdt {
derived_table: {
...
datagroup_trigger: e_faa_shared_datagroup
explore_source: flights {
dev_filters: [flights.event_date: "90 days"]
filters: [flights.event_date: "2 years", flights.airport_name: "Yucca Valley Airport"]
column: id {}
column: airport_name {}
column: event_date {}
}
}
...
}
Dazu gehören der Parameter dev_filters, der die Tabelle nach den Daten der letzten 90 Tage filtert, und der Parameter filters, der die Tabelle nach den Daten der letzten zwei Jahre filtert, die sich auf den Yucca Valley Airport beziehen.
Der Parameter dev_filters agiert in Kombination mit dem Parameter filters, sodass alle Filter auf die Entwicklungsversion der Tabelle angewendet werden. Wenn sowohl dev_filters als auch filters Filter für dieselbe Spalte angeben, hat dev_filters in der Entwicklungsversion der Tabelle Vorrang. In diesem Beispiel wird die Entwicklungsversion der Tabelle nach den Daten der letzten 90 Tage für den Yucca Valley Airport gefiltert.
Für SQL-basierte abgeleitete Tabellen unterstützt Looker eine bedingte WHERE-Klausel mit verschiedenen Optionen für Produktions- (if prod) und Entwicklungsversionen (if dev) der Tabelle:
view: my_view {
derived_table: {
sql:
SELECT
columns
FROM
my_table
WHERE
-- if prod -- date > '2000-01-01'
-- if dev -- date > '2020-01-01'
;;
}
}
In diesem Beispiel umfasst die Abfrage alle Daten ab 2000 im Produktionsmodus, im Entwicklungsmodus jedoch nur die Daten ab 2020. Änderungen im Entwicklungsmodus lassen sich wesentlich leichter validieren, wenn Sie mit dieser Funktion Ihren Ergebnissatz strategisch klug beschränken und die Abfragegeschwindigkeit erhöhen.
So erstellt Looker PDTs
Nachdem eine persistente abgeleitete Tabelle (Persistent Derived Table, PDT) definiert wurde und entweder zum ersten Mal ausgeführt oder vom Regenerator gemäß ihrer Persistenzstrategie zum Neuerstellen ausgelöst wird, führt Looker die folgenden Schritte aus:
- Verwenden Sie den SQL-Code für die abgeleitete Tabelle, um eine CREATE TABLE AS SELECT-Anweisung (oder CTAS-Anweisung) zu erstellen und auszuführen. Um beispielsweise eine PDT mit dem Namen
customer_orders_factsneu zu erstellen:CREATE TABLE tmp.customer_orders_facts AS SELECT ... FROM ... WHERE ... - Anweisungen zum Erstellen der Indexe beim Erstellen der Tabelle ausgeben
- Benennen Sie die Tabelle von LC$.. („Looker Create“) in LR$.. („Looker Read“) um, um anzugeben, dass die Tabelle verwendet werden kann.
- Löschen Sie alle älteren Versionen der Tabelle, die nicht mehr verwendet werden sollen.
Das hat einige wichtige Auswirkungen:
- Der SQL-Code, der die abgeleitete Tabelle bildet, muss in einer CTAS-Anweisung gültig sein.
- Die Spaltenaliase in der Ergebnismenge der SELECT-Anweisung müssen gültige Spaltennamen sein.
- Die Namen, die beim Angeben von Verteilung, Sortierschlüsseln und Indexen verwendet werden, müssen die Spaltennamen sein, die in der SQL-Definition der abgeleiteten Tabelle aufgeführt sind, nicht die Feldnamen, die in LookML definiert sind.
Der Looker-Regenerator
Der Looker-Regenerator prüft den Status und löst Neuerstellungen für Auslöser-persistente Tabellen aus. Eine Auslöser-persistente Tabelle ist eine persistente abgeleitete Tabelle (PDT) oder eine aggregierte Tabelle, die einen Trigger als Persistenzstrategie nutzt:
- Bei Tabellen, die
sql_trigger_valueverwenden, ist der Trigger eine Abfrage, die imsql_trigger_value-Parameter der Tabelle angegeben ist. Der Looker-Regenerator löst die Wiedererstellung der Tabelle auf, wenn sich das Ergebnis der letzten Auslöser-Abfrageprüfung von dem Ergebnis der vorherigen Prüfung unterscheidet. Wenn Ihre abgeleitete Tabelle beispielsweise mit der SQL-AbfrageSELECT CURDATE()persistent ist, baut der Looker-Regenerator die Tabelle neu auf, wenn er den Auslöser das nächste Mal überprüft, nachdem das Datum geändert wurde. - Bei Tabellen, die
interval_triggerverwenden, ist der Trigger eine Zeitdauer, die iminterval_trigger-Parameter der Tabelle angegeben wird. Der Looker-Regenerator löst die Wiedererstellung der Tabelle nach Ablauf der angegebenen Zeit aus. - Bei Tabellen, die
datagroup_triggerverwenden, kann der Trigger eine Abfrage sein, die im Parametersql_triggerder zugehörigen Datengruppe angegeben ist, oder eine Zeitdauer, die im Parameterinterval_triggerder Datengruppe angegeben ist.
Der Looker-Regenerator löst auch Neuerstellungen für persistenten Tabellen aus, die den Parameter persist_for verwenden, jedoch nur, wenn die persist_for-Tabelle eine Kaskadenabhängigkeit einer Auslöser-persistenten Tabelle ist. In diesem Fall erstellt der Looker-Regenerator eine persist_for-Tabelle neu, da die Tabelle für die Neuerstellung der anderen Tabellen in der Kaskade benötigt wird. Andernfalls überwacht der Regenerator keine persistenten Tabellen mit der persist_for-Strategie.
Der Looker-Regenerator-Zyklus beginnt in einem regelmäßigen Intervall, das von Ihrem Looker-Administrator in der Einstellung Wartungszeitplan für Ihre Datenbankverbindung konfiguriert wird (das Standardintervall beträgt fünf Minuten). Der Looker-Regenerator startet jedoch erst dann einen neuen Zyklus, wenn er alle Prüfungen und PDT-Neuerstellungen aus dem letzten Zyklus abgeschlossen hat. Wenn Sie also PDT-Builds mit langer Ausführungszeit haben, wird der Looker-Regeneratorzyklus möglicherweise nicht so oft ausgeführt, wie in der Einstellung Wartungszeitplan definiert. Die Dauer der Neuerstellung Ihrer Tabellen kann allerdings von anderen Faktoren beeinflusst werden, wie im Abschnitt Wichtige Überlegungen zur Implementierung persistenter Tabellen auf dieser Seite beschrieben.
In Fällen, in denen eine PDT nicht erstellt werden kann, kann der Regenerator versuchen, die Tabelle im nächsten Regenerator-Zyklus neu zu erstellen:
- Wenn die Einstellung Retry Failed PDT Builds (Fehlgeschlagene PDT-Builds noch einmal versuchen) für Ihre Datenbankverbindung aktiviert ist, versucht der Looker-Regenerator, die Tabelle im nächsten Regenerator-Zyklus neu zu erstellen, auch wenn die Auslösebedingung der Tabelle nicht erfüllt ist.
- Wenn die Einstellung Fehlgeschlagene PDT-Builds wiederholen deaktiviert ist, versucht der Looker-Regenerator erst dann, die Tabelle neu zu erstellen, wenn die Auslösebedingung der PDT erfüllt ist.
Wenn ein Nutzer Daten aus der persistenten Tabelle anfordert, während diese erstellt wird, und die Abfrageergebnisse nicht im Cache enthalten sind, prüft Looker, ob die vorhandene Tabelle noch gültig ist. (Die vorherige Tabelle ist möglicherweise nicht mehr gültig, wenn sie nicht mit der neuen Version der Tabelle kompatibel ist. Dazu kann es beispielsweise kommen, wenn die neue Tabelle eine andere Definition aufweist, eine andere Datenbankverbindung verwendet oder mit einer anderen Looker-Version erstellt wurde.) Wenn die vorhandene Tabelle noch gültig ist, gibt Looker Daten aus der vorhandenen Tabelle zurück, bis die neue Tabelle erstellt wurde. Wenn die vorhandene Tabelle nicht gültig ist, gibt Looker Abfrageergebnisse an, sobald die neue Tabelle erstellt wurde.
Wichtige Aspekte beim Implementieren persistenter Tabellen
Da persistente Tabellen (PDTs und aggregierte Tabellen) sehr nützlich sind, können sich schnell viele von ihnen in Ihrer Looker-Instanz ansammeln. Es kann vorkommen, dass der Looker-Regenerator viele Tabellen gleichzeitig erstellen muss. Insbesondere bei kaskadierenden Tabellen oder Tabellen mit langer Laufzeit kann es vorkommen, dass die Neuerstellung von Tabellen lange dauert oder Nutzer eine Verzögerung bei den Abfrageergebnissen einer Tabelle feststellen, während die Datenbank die Tabelle generiert.
Der Regenerator von Looker prüft PDT-Auslöser, um festzustellen, ob Auslöser-persistente Tabellen neu erstellt werden sollten. Der Regenerator-Zyklus wird in einem regelmäßigen Intervall ausgeführt, das von Ihrem Looker-Administrator in der Einstellung Wartungszeitplan für Ihre Datenbankverbindung konfiguriert wird (standardmäßig fünf Minuten).
Die Dauer der Neuerstellung Ihrer Tabellen kann von verschiedenen Faktoren beeinflusst werden:
- Ihr Looker-Administrator hat möglicherweise das Intervall der Regenerator-Triggerprüfungen mit der Einstellung Wartungszeitplan für Ihre Datenbankverbindung geändert.
- Der Looker-Regenerator startet erst dann einen neuen Zyklus, wenn alle Prüfungen und PDT-Neuerstellungen aus dem letzten Zyklus abgeschlossen sind. Wenn Sie also PDT-Builds mit langer Laufzeit haben, ist der Looker-Regeneratorzyklus möglicherweise nicht so häufig wie in der Einstellung Wartungszeitplan angegeben.
- Standardmäßig kann der Regenerator die Neuerstellung von jeweils einer PDT oder aggregierten Tabelle über eine Verbindung starten. Ein Looker-Administrator kann die zulässige Anzahl gleichzeitiger Neuerstellungen des Regenerators über das Feld Max. Anzahl der Verbindungen für PDT-Generator in den Einstellungen einer Verbindung anpassen.
- Alle PDTs und aggregierten Tabellen, die durch dasselbe
datagroupausgelöst werden, werden während desselben Regenerierungsprozesses neu erstellt. Das kann eine große Belastung darstellen, wenn die Datengruppe von vielen Tabellen verwendet wird, entweder direkt oder aufgrund von kaskadierenden Abhängigkeiten.
Zusätzlich zu den vorhergehenden Überlegungen gibt es außerdem Situationen, in denen Sie es vermeiden sollten, einer abgeleiteten Tabelle Persistenz hinzuzufügen:
- Wenn abgeleitete Tabellen erweitert werden: Bei jeder Erweiterung einer persistenten abgeleiteten Tabelle wird eine neue Kopie der Tabelle in Ihrer Datenbank erstellt.
- Wenn abgeleitete Tabellen Filtervorlagen oder Liquid-Parameter verwenden: Für abgeleitete Tabellen, die Filtervorlagen oder Liquid-Parameter verwenden, wird keine Persistenz unterstützt.
- Wenn native abgeleitete Tabellen aus Explores erstellt werden, in denen Nutzerattribute mit
access_filtersoder mitsql_always_whereverwendet werden, werden Kopien der Tabelle in Ihrer Datenbank für jeden möglichen angegebenen Nutzerattributwert erstellt. - Wenn sich die zugrunde liegenden Daten häufig ändern und Ihr Datenbankdialekt inkrementelle PDTs nicht unterstützt.
- Wenn die Kosten und der Zeitaufwand für die Erstellung von PDTs zu hoch sind.
Je nach Anzahl und Komplexität der persistenten Tabellen in Ihrer Looker-Verbindung kann die Warteschlange viele persistente Tabellen enthalten, die in jedem Zyklus geprüft und neu erstellt werden müssen. Daher sollten Sie diese Faktoren beim Implementieren abgeleiteter Tabellen in Ihrer Looker-Instanz unbedingt berücksichtigen.
PDTs mit API in großem Maßstab verwalten
Das Überwachen und Verwalten von persistenten abgeleiteten Tabellen (PDTs), die in variierenden Zeitplänen aktualisiert werden, wird zunehmend komplexer, je mehr PDTs Sie in Ihrer Instanz erstellen. Sie können die Apache Airflow-Integration von Looker verwenden, um Ihre PDT-Zeitpläne zusammen mit Ihren anderen ETL- und ELT-Prozessen zu verwalten.
PDTs überwachen und Fehler beheben
Wenn Sie PDTs (nichtflüchtige abgeleitete Tabellen) und insbesondere kaskadierende PDTs verwenden, ist es hilfreich, den Status Ihrer PDTs zu sehen. Auf der Admin-Seite Persistente abgeleitete Tabellen in Looker können Sie den Status Ihrer PDTs einsehen. Weitere Informationen finden Sie auf der Dokumentationsseite Administratoreinstellungen – Persistente abgeleitete Tabellen.
Beachten Sie Folgendes, wenn Sie versuchen, Fehler bei PDTs zu beheben:
- Achten Sie bei der Untersuchung des PDT-Ereignisprotokolls besonders auf den Unterschied zwischen Entwicklungstabellen und Produktionstabellen.
- Prüfen Sie, ob die Einstellung Temp Database in Ihrer Looker-Verbindung mit Ihrem tatsächlichen Scratch-Schema oder Ihrer tatsächlichen Scratch-Datenbank übereinstimmt. Wenn die Einstellung Temporäre Datenbank für die Verbindung nicht mit dem Scratch-Schema in Ihrer Datenbank übereinstimmt, aktualisieren Sie die Einstellung Temporäre Datenbank, damit Looker abgeleitete Tabellen in Ihrer Datenbank speichern kann.
- Finden Sie heraus, ob es nur mit einer PDT oder mit allen Probleme gibt. Ist nur eine PDT betroffen, wird das Problem wahrscheinlich durch einen LookML- oder SQL-Fehler verursacht.
- Finden Sie heraus, ob Probleme mit der PDT mit den Zeiten übereinstimmen, zu denen sie planmäßig neu erstellt werden soll.
- Achten Sie darauf, dass alle
sql_trigger_value-Abfragen erfolgreich ausgewertet werden und nur eine Zeile und Spalte zurückgeben. Bei SQL-basierten PDTs können Sie sie in SQL Runner ausführen. (Durch Anwenden vonLIMITwird vor unkontrollierten Abfragen geschützt.) Weitere Informationen zur Verwendung von SQL Runner zum Debuggen abgeleiteter Tabellen finden Sie im Community-Beitrag Using sql runner to test derived tables . - Überprüfen Sie bei SQL-basierten PDTs mithilfe von SQL Runner, ob der SQL-Code der PDT fehlerfrei ausgeführt wird. (Achten Sie darauf, in SQL Runner einen
LIMIT-Wert anzuwenden, damit die Abfragedauer im Rahmen bleibt.) - Vermeiden Sie bei SQL-basierten abgeleiteten Tabellen die Verwendung von allgemeinen Tabellenausdrücken (Common Table Expressions, CTEs). Die Verwendung von CTEs mit DTs generiert verschachtelte
WITH-Anweisungen, die einen Fehlschlag von PDTs ohne Warnung verursachen können. Verwenden Sie stattdessen den SQL-Code für den CTE, um einen sekundären Zeitraum zu erstellen, und verweisen Sie mit der Syntax${derived_table_or_view_name.SQL_TABLE_NAME}vom ersten Zeitraum auf diesen Zeitraum. - Überprüfen Sie, ob Tabellen, von denen die problematische PDT abhängig ist (ob normale Tabellen oder PDTs), vorhanden sind und abgefragt werden können.
- Stellen Sie sicher, dass Tabellen, von denen die problematische PDT abhängig ist, keine gemeinsamen oder exklusiven Sperren aufweisen. Damit Looker eine PDT erfolgreich erstellen kann, muss eine exklusive Sperre für die zu aktualisierende Tabelle eingerichtet werden. Diese würde mit anderen für die Tabelle eingerichteten gemeinsamen oder exklusiven Sperren in Konflikt stehen. Looker kann die PDT erst aktualisieren, wenn alle anderen Sperren entfernt wurden. Dasselbe gilt für alle exklusiven Sperren für die Tabelle, aus der Looker eine PDT erstellt. Wenn eine exklusive Sperre für eine Tabelle eingerichtet ist, kann Looker erst dann eine gemeinsame Sperre für die Ausführung von Abfragen einrichten, wenn die exklusive Sperre entfernt wurde.
- Verwenden Sie in SQL Runner die Schaltfläche Show Processes. Wenn viele Prozesse aktiv sind, kann die Abfragedauer zunehmen.
- Überwachen Sie Kommentare in der Abfrage. Weitere Informationen finden Sie im Abschnitt Abfragekommentare für PDTs auf dieser Seite.
Abfragekommentare für PDTs
Datenbankadministratoren können zwischen normalen Abfragen und Abfragen unterscheiden, die persistente abgeleitete Tabellen (Persistent Derived Tables, PDTs) generieren. Looker fügt der CREATE TABLE ... AS SELECT ...-Anweisung Kommentare hinzu, die das LookML-Modell der PDT und die zugehörige Ansicht sowie eine eindeutige Kennung (Slug) für die Looker-Instanz enthalten. Wenn die PDT im Auftrag eines Benutzers im Entwicklungsmodus generiert wird, wird in Kommentaren die ID des Benutzers angegeben. Die Kommentare zur PDT-Generierung werden nach diesem Muster erstellt:
-- Building `<view_name>` in dev mode for user `<user_id>` on instance `<instance_slug>`
CREATE TABLE `<table_name>` SELECT ...
-- finished `<view_name>` => `<table_name>`
Der Kommentar zur PDT-Generierung ist auch auf der SQL-Registerkarte eines Explores zu sehen, wenn Looker für die Abfrage des Explores eine PDT erstellen musste. Der Kommentar wird oben in der SQL-Anweisung angezeigt.
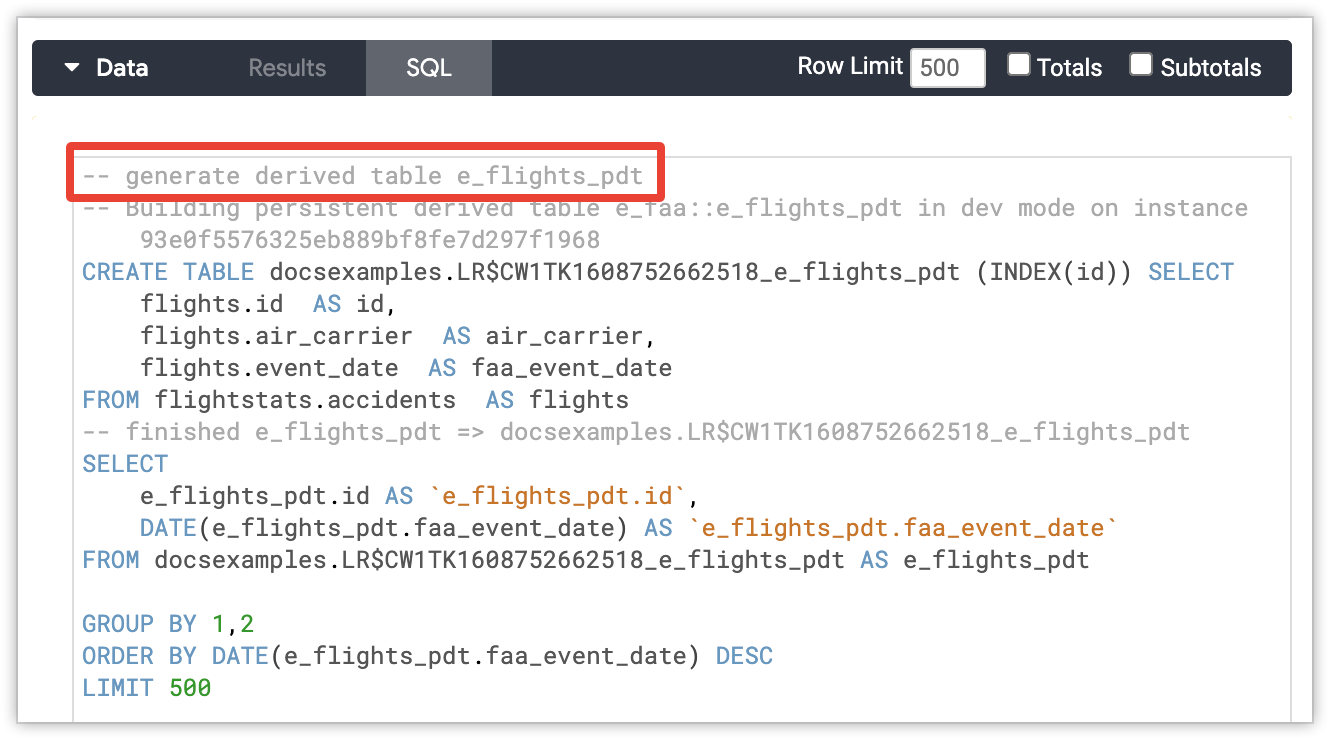
Schließlich wird der Kommentar zur PDT-Generierung im Feld Mitteilung auf dem Tab Info des Pop-ups Abfragedetails für jede Abfrage auf der Admin-Seite Abfragen angezeigt.
PDTs nach einem Fehler neu erstellen
Wenn eine persistente abgeleitete Tabelle (PAT) einen Fehler aufweist, geschieht Folgendes beim Abfragen dieser PAT:
- Looker prüft anhand der Ergebnisse im Cache, ob dieselbe Abfrage bereits ausgeführt wurde. Eine Erläuterung dazu finden Sie auf der Dokumentationsseite Abfragen im Cache speichern.
- Wenn die Ergebnisse nicht im Cache enthalten sind, ruft Looker Ergebnisse von der PDT in der Datenbank ab, sofern eine gültige Version der PDT vorhanden ist.
- Wenn die Datenbank keine gültige PDT enthält, versucht Looker, die PDT neu zu erstellen.
- Wenn die PDT nicht neu erstellt werden kann, gibt Looker einen Fehler bei einer Abfrage zurück. Der Looker-Regenerator versucht, die PDT neu zu erstellen, wenn sie das nächste Mal abgefragt wird oder wenn die Persistenzstrategie der PDT eine Neuerstellung auslöst.
Bei kaskadierenden PDTs gilt dieselbe Logik mit folgenden Ausnahmen:
- Wenn eine Tabelle nicht erstellt werden kann, können auch die nachfolgenden PDTs in der Abhängigkeitskette nicht erstellt werden.
- Eine abhängige PDT fragt im Grunde die PDT ab, von der sie abhängig ist. Daher kann die Persistenzstrategie einer Tabelle Neuerstellungen der PDTs weiter oben in der Kette auslösen.
Sehen wir uns noch einmal das vorherige Beispiel mit kaskadierenden Tabellen an, in dem TABLE_D von TABLE_C, TABLE_C von TABLE_B und TABLE_B von TABLE_A abhängt:
Wenn bei TABLE_B ein Fehler auftritt, gilt das gesamte Standardverhalten (nicht kaskadierend) für TABLE_B:
- Wenn
TABLE_Babgefragt wird, versucht Looker zuerst, den Cache zu verwenden, um Ergebnisse zurückzugeben. - Wenn dieser Versuch fehlschlägt, versucht Looker als Nächstes, eine frühere Version der Tabelle zu verwenden, sofern verfügbar.
- Wenn auch dieser Versuch fehlschlägt, versucht Looker, die Tabelle neu zu erstellen.
- Wenn
TABLE_Bnicht neu erstellt werden kann, gibt Looker einen Fehler zurück.
Looker versucht erneut, TABLE_B neu zu erstellen, wenn die Tabelle das nächste Mal abgefragt wird oder wenn die Persistenzstrategie der Tabelle eine Neuerstellung auslöst.
Dasselbe gilt auch für die abhängigen Elemente von TABLE_B. Wenn TABLE_B also nicht erstellt werden kann und eine Anfrage zu TABLE_C vorliegt, passiert Folgendes:
- Looker versucht, den Cache für die Abfrage für
TABLE_Czu verwenden. - Wenn die Ergebnisse nicht im Cache enthalten sind, versucht Looker, Ergebnisse aus
TABLE_Cin der Datenbank abzurufen. - Wenn keine gültige Version von
TABLE_Cvorhanden ist, versucht Looker,TABLE_Cneu zu erstellen. Dadurch wird eine Abfrage fürTABLE_Berstellt. - Looker versucht dann,
TABLE_Bneu zu erstellen. (Dieser Vorgang schlägt fehl, wenn das Problem mitTABLE_Bnicht behoben wurde.) - Wenn
TABLE_Bnicht neu erstellt werden kann, kannTABLE_Cnicht neu erstellt werden. Looker gibt dann einen Fehler für die Abfrage fürTABLE_Czurück. - Looker versucht dann,
TABLE_Cgemäß der üblichen Persistenzstrategie neu zu erstellen. Das kann auch beim nächsten Abfragen der PDT geschehen (einschließlich des nächsten Versuchs vonTABLE_D, die PDT zu erstellen, daTABLE_DvonTABLE_Cabhängt).
Sobald Sie das Problem mit TABLE_B behoben haben, wird versucht, TABLE_B und jede der abhängigen Tabellen gemäß ihren Persistenzstrategien neu zu erstellen. Alternativ wird die Neuerstellung beim nächsten Abfragen der Tabellen versucht. Das gilt auch für den Fall, dass eine abhängige PDT neu erstellt werden soll. Wenn eine Entwicklungsversion der PDTs in der Kaskade im Entwicklungsmodus erstellt wurde, können die Entwicklungsversionen als die neuen Produktions-PDTs verwendet werden. (Dieser Vorgang wird im Abschnitt Persistente Tabellen im Entwicklungsmodus auf dieser Seite erläutert.) Alternativ können Sie ein Explore verwenden, um eine Abfrage für TABLE_D auszuführen, und dann die PDTs für die Abfrage manuell neu erstellen. Dadurch wird eine Neuerstellung aller PDTs in der Abhängigkeitskaskade erzwungen.
PDT-Leistung verbessern
Wenn Sie persistente abgeleitete Tabellen (PDTs) erstellen, kann die Leistung ein Problem sein. Insbesondere wenn die Tabelle sehr groß ist, kann das Abfragen der Tabelle langsam sein, wie bei jeder großen Tabelle in Ihrer Datenbank.
Sie können die Leistung verbessern, indem Sie die Daten filtern oder festlegen, wie die Daten im PDT sortiert und indexiert werden.
Filter hinzufügen, um den Datensatz einzuschränken
Bei besonders großen Datasets verlangsamt eine große Anzahl von Zeilen Abfragen für eine dauerhafte abgeleitete Tabelle (Persistent Derived Table, PDT). Wenn Sie normalerweise nur aktuelle Daten abfragen, sollten Sie der WHERE-Klausel Ihrer PDT einen Filter hinzufügen, der die Tabelle auf maximal 90 Tage mit Daten beschränkt. So werden der Tabelle bei jeder Neuerstellung nur relevante Daten hinzugefügt, sodass die Ausführung von Abfragen viel schneller erfolgt. Anschließend können Sie eine separate, größere PDT für die Verlaufsanalyse erstellen, um sowohl schnelle Abfragen für aktuelle Daten als auch Abfragen für alte Daten zu ermöglichen.
indexes oder sortkeys und distribution verwenden
Wenn Sie eine große persistente abgeleitete Tabelle (Persistent Derived Table, PDT) erstellen, kann es sich positiv auf die Leistung auswirken, die Tabelle zu indexieren (für Dialekte wie MySQL oder Postgres) oder Sortierschlüssel und Verteilung hinzuzufügen (für Redshift).
In der Regel ist es am besten, den Parameter indexes in ID- oder Datumsfelder einzufügen.
Bei Redshift ist es in der Regel am besten, den Parameter sortkeys in ID- oder Datumsfelder und den Parameter distribution in das Feld einzufügen, das für den Join verwendet wird.
Empfohlene Einstellungen zur Leistungsverbesserung
Mit den folgenden Einstellungen wird gesteuert, wie die Daten in der persistenten abgeleiteten Tabelle (Persistent Derived Table, PDT) sortiert und indexiert werden. Diese Einstellungen sind optional, werden aber dringend empfohlen:
- Verwenden Sie für Redshift und Aster den Parameter
distribution, um den Spaltennamen anzugeben, dessen Wert zum Verteilen der Daten auf einen Cluster verwendet wird. Wenn zwei Tabellen über die im Parameterdistributionangegebene Spalte verknüpft werden, kann die Datenbank die Join-Daten auf demselben Knoten finden. Dadurch wird die I/O zwischen Knoten minimiert. - Legen Sie für Redshift den Parameter
distribution_styleaufallfest, damit die Datenbank auf jedem Knoten eine vollständige Kopie der Daten speichert. Dies wird häufig verwendet, um die E/A zwischen Knoten zu minimieren, wenn relativ kleine Tabellen verknüpft werden. Legen Sie diesen Wert aufevenfest, damit die Daten gleichmäßig im Cluster verteilt werden, ohne dass eine Verteilungsspalte verwendet wird. Dieser Wert kann nur angegeben werden, wenndistributionnicht angegeben ist. - Verwenden Sie für Redshift den Parameter
sortkeys. Die Werte geben an, welche Spalten der PDT zum Sortieren der Daten auf der Festplatte verwendet werden, um die Suche zu erleichtern. In Redshift können Sie entwedersortkeysoderindexesverwenden, aber nicht beides. - Verwenden Sie in den meisten Datenbanken den Parameter
indexes. Die Werte geben an, welche Spalten des PDT indexiert werden. In Redshift werden Indizes zum Generieren von überlappenden Sortierschlüsseln verwendet.