Trino (früher Presto) ist eine verteilte SQL-Abfrage die zur Abfrage großer Datensätze, die über ein oder mehrere und heterogenen Datenquellen arbeiten. Trino kann Hive, MySQL, Kafka und andere Daten abfragen über Connectors hinzufügen. In dieser Anleitung wird Folgendes erläutert:
- Trino-Dienst in einem Dataproc-Cluster installieren
- Öffentliche Daten über einen installierten Trino-Client abfragen auf Ihrem lokalen Computer, der mit einem Trino-Dienst kommuniziert im Cluster
- Führen Sie Abfragen über eine Java-Anwendung aus, die mit dem Trino-Dienst auf Ihrem Cluster über den Trino Java JDBC-Treiber.
Lernziele
- Daten aus BigQuery extrahieren
- Daten in Cloud Storage als CSV-Dateien laden
- Daten transformieren:
- Daten als externe Hive-Tabelle zur Verfügung stellen, um die Daten zu erstellen abfragbar durch Trino
- Daten aus dem CSV-Format in das Parquet-Format konvertieren, um die Abfrage zu beschleunigen
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweise
Erstellen Sie ein Google Cloud-Projekt und einen Cloud Storage-Bucket für die in dieser Anleitung verwendeten Daten, sofern noch nicht geschehen. 1. Projekt einrichten- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs aktivieren.
- Installieren Sie die Google Cloud CLI.
-
Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs aktivieren.
- Installieren Sie die Google Cloud CLI.
-
Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init
- Wechseln Sie in der Google Cloud Console zur Cloud Storage-Seite Buckets.
- Klicken Sie auf Bucket erstellen.
- Geben Sie auf der Seite Bucket erstellen die Bucket-Informationen ein. Klicken Sie auf Weiter, um mit dem nächsten Schritt fortzufahren.
- Geben Sie unter Bucket benennen einen Namen ein, der den Anforderungen für Bucket-Namen entspricht.
-
Gehen Sie unter Speicherort für Daten auswählen folgendermaßen vor:
- Wählen Sie eine Option für Standorttyp aus.
- Wählen Sie eine Standort-Option aus.
- Wählen Sie unter Standardspeicherklasse für Ihre Daten auswählen eine Speicherklasse aus.
- Wählen Sie unter Zugriffssteuerung für Objekte auswählen eine Option für die Zugriffssteuerung aus.
- Geben Sie für Erweiterte Einstellungen (optional) eine Verschlüsselungsmethode, eine Aufbewahrungsrichtlinie oder Bucket-Labels an.
- Klicken Sie auf Erstellen.
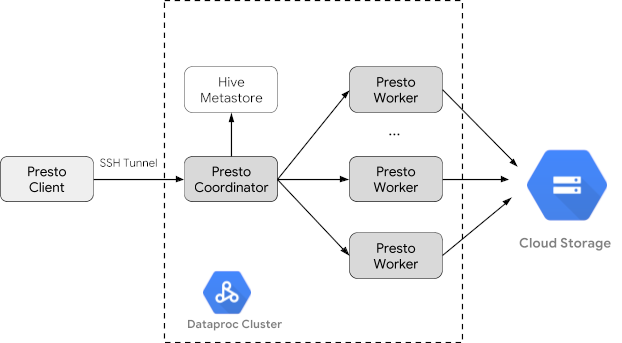
Dataproc-Cluster erstellen
Dataproc-Cluster mit dem Flag optional-components erstellen
(verfügbar ab Image-Version 2.1) zur Installation des
Optionale Trino-Komponente auf der
und das Flag enable-component-gateway, um den
Zuzulassendes Component Gateway
können Sie über die Google Cloud Console
auf die Trino-Web-UI zugreifen.
- Umgebungsvariablen festlegen:
- PROJECT: Ihre Projekt-ID
- BUCKET_NAME: Der Name des Cloud Storage-Buckets, den Sie unter Hinweise erstellt haben
- REGION: Die Region, in der der Cluster für diese Anleitung erstellt wird, z. B. "us-west1"
- WORKERS: Für diese Anleitung werden drei bis fünf Worker empfohlen.
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- Führen Sie die Google Cloud CLI auf Ihrem lokalen Computer aus, um
Erstellen Sie den Cluster.
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway
Daten vorbereiten
Exportieren Sie das bigquery-public-data-Dataset chicago_taxi_trips als CSV-Dateien in Cloud Storage und erstellen Sie dann eine externe Hive-Tabelle, um auf die Daten zu verweisen.
- Führen Sie auf Ihrem lokalen Computer den folgenden Befehl aus, um die Taxidaten zu importieren
BigQuery als CSV-Dateien ohne Header in Cloud Storage
Bucket, den Sie unter Hinweise erstellt haben.
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - Erstellen Sie externe Hive-Tabellen, die von den CSV- und Parquet-Dateien im Cloud Storage-Bucket unterstützt werden.
- Erstellen Sie die externe Hive-Tabelle
chicago_taxi_trips_csv.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - Prüfen Sie die Erstellung der externen Hive-Tabelle.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - Weitere externe Hive-Tabelle erstellen
chicago_taxi_trips_parquetSpalten, aber mit Daten gespeichert in Parquet-Format für eine bessere Abfrageleistung.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - Laden Sie die Daten aus der Hive-CSV-Tabelle in die
Hive-Parquet-Tabelle
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - Prüfen Sie, ob die Daten korrekt geladen wurden.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- Erstellen Sie die externe Hive-Tabelle
Abfragen ausführen
Sie können Abfragen lokal über die Trino CLI oder eine Anwendung ausführen.
Trino CLI-Abfragen
In diesem Abschnitt wird gezeigt, wie Sie das Hive Parquet-Taxi-Dataset mit der Methode Trino CLI
- Führen Sie den folgenden Befehl auf Ihrem lokalen Computer aus, um eine SSH-Verbindung zum Masterknoten des Clusters herzustellen. Das lokale Terminal reagiert während der Ausführung des Befehls nicht mehr.
gcloud compute ssh trino-cluster-m
- Führen Sie im SSH-Terminalfenster auf dem Masterknoten Ihres Clusters den
Trino CLI, die eine Verbindung zum Trino-Server herstellt, der auf dem Master ausgeführt wird
Knoten.
trino --catalog hive --schema default
- Prüfen Sie an der Eingabeaufforderung
trino:default, ob Trino die Hive-Tabellen finden kann.show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- Führen Sie Abfragen an der Eingabeaufforderung
trino:defaultaus und vergleichen Sie die Leistung von Parquet-Datenabfragen mit CSV-Datenabfragen.- Parquet-Datenabfrage
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - CSV-Datenabfrage
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Parquet-Datenabfrage
Java-Anwendungsabfragen
So führen Sie Abfragen aus einer Java-Anwendung über den Trino Java JDBC-Treiber aus:
1. Laden Sie die
Trino Java JDBC-Treiber
1. Fügen Sie eine trino-jdbc-Abhängigkeit hinzu
Maven pom.xml.
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>Java-Beispielcode
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
Logging und Monitoring
Logging
Die Trino-Logs befinden sich unter /var/log/trino/ auf dem Master des Clusters und
Worker-Knoten.
Web-UI
Siehe Component Gateway-URLs ansehen und auf diese zugreifen um die Trino-Web-UI, die auf dem Masterknoten des Clusters ausgeführt wird, in Ihrem lokalen Browser zu öffnen.
Monitoring
Trino stellt Informationen zur Clusterlaufzeit über Laufzeittabellen bereit.
Führen Sie in einer Trino-Sitzung (über den Prompt trino:default) folgende Schritte aus:
Führen Sie die folgende Abfrage aus, um Laufzeittabellendaten anzuzeigen:
select * FROM system.runtime.nodes;
Bereinigen
Nachdem Sie die Anleitung abgeschlossen haben, können Sie die erstellten Ressourcen bereinigen, damit sie keine Kontingente mehr nutzen und keine Gebühren mehr anfallen. In den folgenden Abschnitten erfahren Sie, wie Sie diese Ressourcen löschen oder deaktivieren.
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten durch Löschen des für die Anleitung erstellten Projekts.
So löschen Sie das Projekt:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Cluster löschen
- So löschen Sie den Cluster:
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION}
Bucket löschen
- So löschen Sie den Cloud Storage-Bucket, den Sie in
Vorbereitung: Datendateien
im Bucket gespeichert:
gcloud storage rm gs://${BUCKET_NAME} --recursive