Auf dieser Seite finden Sie Informationen zum Monitoring und zur Fehlerbehebung von Dataproc-Jobs sowie zum Verständnis von Dataproc-Job-Fehlermeldungen.
Monitoring und Fehlerbehebung für Jobs
Verwenden Sie die Google Cloud CLI, die Dataproc REST API und die Google Cloud -Konsole, um Dataproc-Jobs zu analysieren und Fehler zu beheben.
gcloud-CLI
So prüfen Sie den Status eines laufenden Jobs:
gcloud dataproc jobs describe job-id \ --region=region
Informationen zum Aufrufen der Job-Treiberausgabe finden Sie unter Jobausgabe ansehen.
REST API
Rufen Sie jobs.get auf, um die Felder JobStatus.State, JobStatus.Substate, JobStatus.details und YarnApplication zu untersuchen.
Konsole
Informationen zum Aufrufen der Job-Treiberausgabe finden Sie unter Jobausgabe ansehen.
Wenn Sie das Dataproc-Agent-Log in Logging aufrufen möchten, wählen Sie Dataproc-Cluster → Clustername → Cluster-UUID aus der Clusterauswahl im Log-Explorer aus.
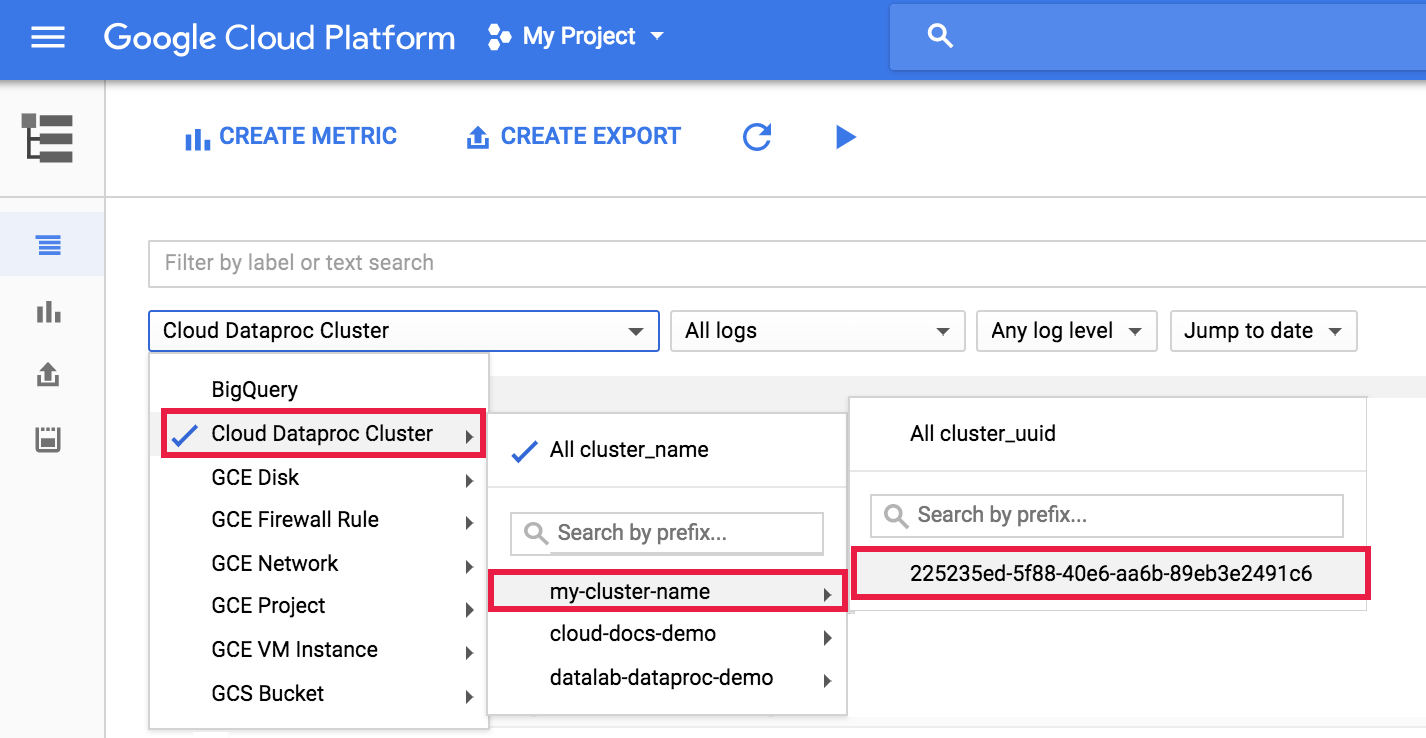
Wählen Sie dann mit der Logauswahl google.dataproc.agent Logs aus.
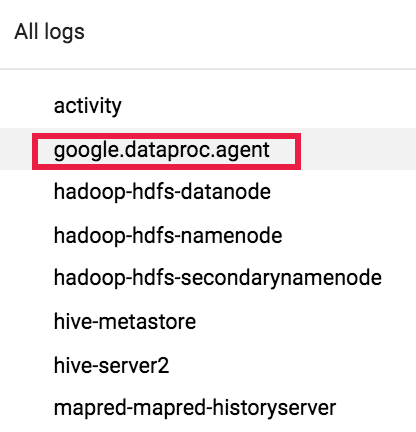
Joblogs in Logging ansehen
Wenn ein Job fehlschlägt, können Sie auf Joblogs in Logging zugreifen.
Bestimmen, wer einen Job gesendet hat
In den Jobdetails: Im Feld submittedBy können Sie einsehen, wer diesen Job gesendet hat. Diese Jobausgabe zeigt beispielsweise, dass user@domain den Beispieljob an einen Cluster gesendet hat.
... placement: clusterName: cluster-name clusterUuid: cluster-uuid reference: jobId: job-uuid projectId: project status: state: DONE stateStartTime: '2018-11-01T00:53:37.599Z' statusHistory: - state: PENDING stateStartTime: '2018-11-01T00:33:41.387Z' - state: SETUP_DONE stateStartTime: '2018-11-01T00:33:41.765Z' - details: Agent reported job success state: RUNNING stateStartTime: '2018-11-01T00:33:42.146Z' submittedBy: user@domain
Fehlermeldungen
Aufgabe wurde nicht übernommen
Dies weist darauf hin, dass der Dataproc-Agent auf dem Masterknoten die Aufgabe nicht von der Steuerungsebene abrufen konnte. Dies ist oft auf fehlenden Speicher (Out-Of-Memory, OOM) oder auf Netzwerkprobleme zurückzuführen. Wenn der Job zuvor erfolgreich ausgeführt wurde und Sie die Einstellungen für die Netzwerkkonfiguration nicht geändert haben, ist OOM die wahrscheinlichste Ursache. Dies ist häufig die Folge der Einreichung vieler gleichzeitig ausgeführter Jobs oder von Jobs, deren Treiber viel Arbeitsspeicher verbrauchen (z. B. Jobs, bei denen große Datasets in den Arbeitsspeicher geladen werden).
Kein aktiver Agent auf Masterknoten gefunden
Das bedeutet, dass der Dataproc-Agent auf dem Masterknoten nicht aktiv ist und keine neuen Jobs annehmen kann. Dies ist oft auf fehlenden Speicher (Out-Of-Memory, OOM) oder auf Netzwerkprobleme zurückzuführen oder wenn die VM des Masterknotens fehlerhaft ist. Wenn der Job zuvor erfolgreich ausgeführt wurde und Sie die Einstellungen für die Netzwerkkonfiguration nicht geändert haben, ist „Out of Memory“ (OOM) die wahrscheinlichste Ursache. Dies ist häufig auf die Einreichung vieler gleichzeitig ausgeführter Jobs oder Jobs zurückzuführen, deren Treiber viel Arbeitsspeicher verbrauchen (Jobs, bei denen große Datasets in den Arbeitsspeicher geladen werden).
So können Sie das Problem beheben:
- Starten Sie den Job neu.
- Stellen Sie mit SSH eine Verbindung zum Masterknoten des Clusters her und ermitteln Sie dann, welcher Job oder welche andere Ressource den meisten Arbeitsspeicher verwendet.
Wenn Sie sich nicht im Masterknoten anmelden können, können Sie die Logs des seriellen Ports (Konsole) prüfen.

Erstellen Sie ein Diagnosepaket, das das Syslog und andere Daten enthält.
Aufgabe wurde nicht gefunden
Dieser Fehler gibt an, dass der Cluster gelöscht wurde, während ein Job ausgeführt wurde. Mit den folgenden Aktionen können Sie den Prinzipal ermitteln, der den Löschvorgang ausgeführt hat, und bestätigen, dass der Cluster gelöscht wurde, während ein Job ausgeführt wurde:
Sehen Sie sich die Dataproc-Audit-Logs an, um das Hauptkonto zu ermitteln, das den Löschvorgang ausgeführt hat.
Prüfen Sie mit Logging oder der gcloud CLI, ob der letzte bekannte Status der YARN-Anwendung RUNNING war:
- Verwenden Sie den folgenden Filter in Logging:
resource.type="cloud_dataproc_cluster" resource.labels.cluster_name="CLUSTER_NAME" resource.labels.cluster_uuid="CLUSTER_UUID" "YARN_APPLICATION_ID State change from"
- Führen Sie
gcloud dataproc jobs describe job-id --region=REGIONaus und prüfen Sie dannyarnApplications: > STATEin der Ausgabe.
Wenn das Prinzipal, das den Cluster gelöscht hat, das Dataproc-Dienstkonto des Dienst-Agents ist, prüfen Sie, ob der Cluster mit einer Dauer für das automatische Löschen konfiguriert wurde, die kürzer als die Jobdauer ist.
Um Task not found-Fehler zu vermeiden, sollten Sie dafür sorgen, dass Cluster nicht gelöscht werden, bevor alle laufenden Jobs abgeschlossen sind.
Kein Speicherplatz mehr auf dem Gerät
Dataproc schreibt HDFS- und Scratch-Daten auf die Festplatte. Diese Fehlermeldung gibt an, dass der Cluster mit zu wenig Speicherplatz erstellt wurde. So analysieren und vermeiden Sie diesen Fehler:
Prüfen Sie die Größe der primären Cluster-Festplatte, die in der Google Cloud Console auf der Seite Clusterdetails auf dem Tab Konfiguration aufgeführt ist. Die empfohlene Mindestfestplattengröße beträgt
1000 GBfür Cluster mit dem Maschinentypn1-standard-4und2 TBfür Cluster mit dem Maschinentypn1-standard-32.Wenn die Clusterlaufwerksgröße kleiner als die empfohlene Größe ist, erstellen Sie den Cluster neu und verwenden Sie dabei mindestens die empfohlene Laufwerksgröße.
Wenn die Festplattengröße der empfohlenen Größe entspricht oder größer ist, stellen Sie über SSH eine Verbindung zur Master-VM des Clusters her und führen Sie dann
df -hauf der Master-VM aus, um die Festplattennutzung zu prüfen und festzustellen, ob zusätzlicher Speicherplatz erforderlich ist.