Programmatische Analysetools
In diesem Dokument werden mehrere Möglichkeiten zum Schreiben und Ausführen von Code zum Analysieren von in BigQuery verwalteten Daten beschrieben.
Obwohl SQL eine leistungsstarke Abfragesprache ist, bieten Programmiersprachen wie Python, Java oder R Syntaxen und eine Vielzahl integrierter statistischer Funktionen, die für Datenanalysten für bestimmte Arten der Datenanalyse möglicherweise aussagekräftiger und einfacher zu bearbeiten sind.
Tabellenkalkulationen sind zwar weit verbreitet, jedoch bieten andere Programmierumgebungen wie Notebooks manchmal eine flexiblere Umgebung für die Durchführung einer komplexen Datenanalyse und -exploration.
Colab Enterprise-Notebooks
Sie können Colab Enterprise-Notebooks in BigQuery verwenden, um Analyse- und ML-Workflows mithilfe von SQL, Python und anderen gängigen Paketen und APIs abzuschließen. Notebooks bieten eine verbesserte Zusammenarbeit und Verwaltung mit den folgenden Optionen:
- Sie können Notebooks mit Identity and Access Management (IAM) für bestimmte Nutzer und Gruppen freigeben.
- Prüfen Sie den Notebook-Versionsverlauf.
- Kehren Sie zu früheren Versionen des Notebooks zurück oder wechseln Sie zu diesen.
Notebooks sind BigQuery Studio-Code-Assets, die auf Dataform basieren. Sie sind jedoch nicht in Dataform sichtbar. Gespeicherte Abfragen sind ebenfalls Code-Assets. Alle Code-Assets werden in einer Standardregion gespeichert. Durch das Aktualisieren der Standardregion wird die Region für alle Code-Assets geändert, die danach erstellt werden.
Notebook-Funktionen sind nur in der Google Cloud Console verfügbar.
Notebooks in BigQuery bieten folgende Vorteile:
- BigQuery DataFrames sind in Notebooks eingebunden, ohne dass eine Einrichtung erforderlich ist. BigQuery DataFrames ist eine Python API, mit der Sie BigQuery-Daten in großem Maßstab mithilfe von pandas-DataFrame und scikit-learn -APIs analysieren können.
- Unterstützung für die unterstützende Codeentwicklung auf Basis von generativer KI von Gemini
- Automatische Vervollständigung von SQL-Anweisungen, wie im BigQuery-Editor.
- Die Möglichkeit, Versionen von Notebooks zu speichern, freizugeben und zu verwalten.
- Die Möglichkeit, matplotlib, seaborn und andere beliebte Bibliotheken zu verwenden, um Daten zu jedem Zeitpunkt im Workflow zu visualisieren.
- Die Möglichkeit, SQL zu schreiben und auszuführen, die auf Python-Variablen aus Ihrem Notebook verweisen kann.
- Interaktive DataFrame-Visualisierung, die Aggregation und Anpassung unterstützt.
Sie können mit Notebook-Galerievorlagen mit Notebooks beginnen. Weitere Informationen finden Sie unter Notizbuch über die Notizbuchgalerie erstellen.
BigQuery DataFrames
BigQuery DataFrames besteht aus einer Reihe von Open-Source-Python-Bibliotheken, mit denen Sie die BigQuery-Datenverarbeitung mithilfe vertrauter Python APIs nutzen können. BigQuery DataFrames implementiert die pandas- und scikit-learn-APIs, indem die Verarbeitung durch SQL-Konvertierung an BigQuery übertragen wird. Mit diesem Design können Sie BigQuery verwenden, um Terabyte an Daten zu untersuchen und zu verarbeiten und um ML-Modelle zu trainieren – alles mit Python APIs.
BigQuery DataFrames bietet folgende Vorteile:
- Mehr als 750 Pandas- und Scikit-Learn-APIs, die durch eine transparente SQL-Konvertierung in BigQuery- und BigQuery ML-APIs implementiert werden.
- Verzögerte Ausführung von Abfragen für verbesserte Leistung.
- Datentransformationen mit benutzerdefinierten Python-Funktionen erweitern, um Daten in der Cloud zu verarbeiten. Diese Funktionen werden automatisch als BigQuery-Remote-Funktionen bereitgestellt.
- Einbindung in Vertex AI, damit Sie Gemini-Modelle für die Textgenerierung verwenden können.
Andere Lösungen für programmatische Analysen
Die folgenden Lösungen für programmatische Analysen sind auch in BigQuery verfügbar.
Jupyter-Notebooks
Jupyter ist eine webbasierte Open Source-Anwendung zum Veröffentlichen von Notebooks, die Live-Code, Textbeschreibungen und Visualisierungen enthalten. Data Scientists, Spezialisten für maschinelles Lernen und Studenten verwenden diese Plattform häufig für Aufgaben wie Datenbereinigung und -transformation, numerische Simulation, statistische Modellierung, Datenvisualisierung und maschinelles Lernen.
Jupyter-Notebooks basieren auf dem IPython, einer leistungsstarken interaktiven Shell, die mithilfe von magischen IPython-Befehlen für BigQuery direkt mit BigQuery interagieren kann. Alternativ können Sie auch von Ihren Jupyter-Notebooks-Instanzen aus auf BigQuery zugreifen, indem Sie eine der verfügbaren BigQuery-Clientbibliotheken installieren. Sie können mit Jupyter-Notebooks BigQuery GIS-Daten über die GeoJSON-Erweiterung visualisieren. Weitere Informationen zur BigQuery-Integration finden Sie in der Anleitung BigQuery-Daten in einem Jupyter-Notebook visualisieren.
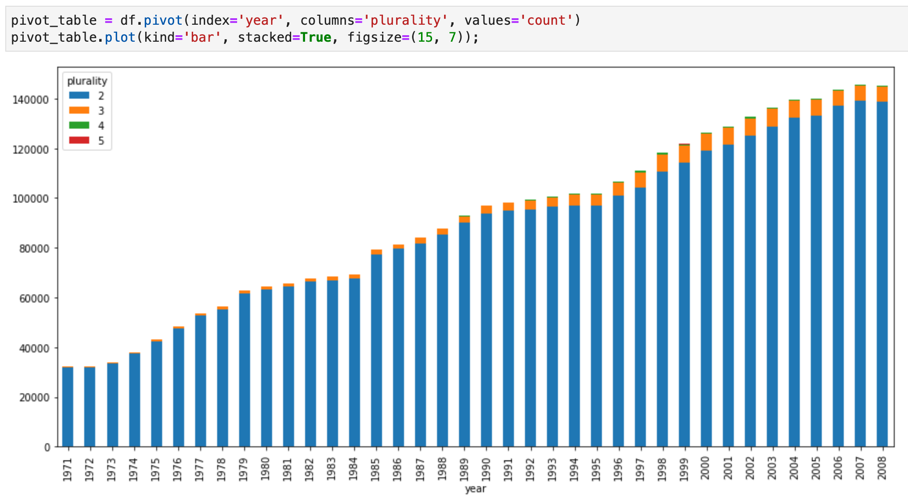
JupyterLab ist eine webbasierte Benutzeroberfläche zum Verwalten von Dokumenten und Aktivitäten wie Jupyter-Notebooks, Texteditoren, Terminals und benutzerdefinierten Komponenten. Mit JupyterLab können Sie mithilfe von Tabs und Aufteilungen mehrere Dokumente und Aktivitäten nebeneinander im Arbeitsbereich anordnen.
Sie können Jupyter-Notebooks und JupyterLab-Umgebungen mit einem der folgenden Produkte inGoogle Cloud bereitstellen:
- Vertex AI Workbench-Instanzen, ein Dienst mit einer integrierten JupyterLab-Umgebung, in der ML-Entwickler und Data Scientists einige der neuesten Data-Science- und ML-Frameworks (maschinelles Lernen) verwenden können. Vertex AI Workbench ist in andere Google Cloud Datenprodukte wie BigQuery eingebunden, was den Weg von der Datenaufnahme über die Vorverarbeitung und Exploration bis zum Modelltraining und zur Bereitstellung vereinfacht. Weitere Informationen finden Sie unter Einführung in Vertex AI Workbench-Instanzen.
- Dataproc, ein schneller, nutzerfreundlicher und vollständig verwalteter Cloud-Dienst, über den Apache Spark- und Apache Hadoop-Cluster einfach und kostengünstig ausgeführt werden können. Sie können Jupyter-Notebooks und JupyterLab mithilfe der optionalen Jupyter-Komponente in einem Dataproc-Cluster installieren. Die Komponente bietet einen Python-Kernel zum Ausführen von PySpark-Code. Standardmäßig konfiguriert Dataproc Notebooks automatisch so, dass sie in Cloud Storage gespeichert werden. Auf diese Weise können andere Cluster auf dieselben Notebookdateien zugreifen. Prüfen Sie beim Migrieren Ihrer vorhandenen Notebooks zu Dataproc, ob die Abhängigkeiten Ihrer Notebooks von den unterstützten Dataproc-Versionen abgedeckt werden. Wenn Sie benutzerdefinierte Software installieren müssen, können Sie ein eigenes Dataproc-Image erstellen, eigene Initialisierungsaktionen schreiben oder benutzerdefinierte Python-Paketanforderungen festlegen. Informationen zum Einstieg finden Sie in der Anleitung Jupyter-Notebook in einem Dataproc-Cluster installieren und ausführen.
Apache Zeppelin
Apache Zeppelin ist ein Open Source-Projekt, das webbasierte Notebooks für die Datenanalyse anbietet.
Zum Bereitstellen einer Instanz von Apache Zeppelin auf Dataproc können Sie die optionale Zeppelin-Komponente installieren.
Notebooks werden standardmäßig im Dataproc-Staging-Bucket in Cloud Storage gespeichert. Dieser Bucket wird vom Nutzer festgelegt oder beim Erstellen des Clusters automatisch generiert. Sie können den Speicherort des Notebooks ändern, indem Sie beim Erstellen des Clusters das Attribut zeppelin:zeppelin.notebook.gcs.dir hinzufügen. Weitere Informationen zum Installieren und Konfigurieren von Apache Zeppelin finden Sie im Zeppelin-Komponentenleitfaden.
Ein Beispiel finden Sie unter BigQuery-Datasets mit BigQuery Interpreter für Apache Zeppelin analysieren.
Apache Hadoop, Apache Spark und Apache Hive
Für einen Teil Ihrer Datenanalyse-Pipeline-Migration können Sie ältere Apache Hadoop-, Apache Spark- oder Apache Hive-Jobs migrieren, die Daten direkt aus Ihrem Data Warehouse verarbeiten müssen. Sie können beispielsweise Features für Ihre ML-Arbeitslasten extrahieren.
Mit Dataproc können Sie vollständig verwaltete Hadoop- und Spark-Cluster effizient und kostengünstig bereitstellen. Dataproc lässt sich in Open-Source-BigQuery-Connectors einbinden. Diese Connectoren verwenden die BigQuery Storage API, die Daten direkt von BigQuery über gRPC parallel überträgt.
Wenn Sie Ihre vorhandenen Hadoop- und Spark-Arbeitslasten zu Dataproc migrieren, können Sie prüfen, ob die Abhängigkeiten Ihrer Arbeitslasten von den unterstützten Dataproc-Versionen abgedeckt werden. Falls Sie benutzerdefinierte Software installieren müssen, können Sie ein eigenes Dataproc-Image erstellen, eigene Initialisierungsaktionen schreiben oder benutzerdefinierte Python-Paketanforderungen festlegen.
Sehen Sie sich als Erstes die Dataproc-Kurzanleitungen und die Codebeispiele für den BigQuery-Connector an.
Apache Beam
Apache Beam ist ein Open-Source-Framework, das zahlreiche Windowing- und Sitzungsanalyse-Primitive sowie ein System von Quell- und Senk-Connectors bietet, einschließlich eines Connectors für BigQuery. Mit Apache Beam können Sie Daten sowohl im Stream-Modus (Echtzeitdaten) als auch im Batch-Modus (Verlaufsdaten) mit gleicher Zuverlässigkeit und Ausdruckskraft transformieren und anreichern.
Dataflow ist ein vollständig verwalteter Dienst zum Ausführen umfangreicher Apache Beam-Jobs. Dank des serverlosen Ansatzes von Dataflow entfällt der operative Aufwand, da Aspekte wie Leistung, Skalierung, Verfügbarkeit, Sicherheit und Compliance automatisch berücksichtigt werden. So können Sie sich auf die Programmierung statt auf die Verwaltung von Serverclustern konzentrieren.
Sie können Cloud Dataflow-Jobs entweder über die Befehlszeile, das Java SDK oder das Python SDK senden.
Wenn Sie Ihre Datenabfragen und Pipelines von anderen Frameworks zu Apache Beam und Dataflow migrieren möchten, lesen Sie die Informationen zum Programmiermodell für Apache Beam und die offizielle Dataflow-Dokumentation.
Andere Ressourcen
BigQuery bietet eine Vielzahl von Client-Bibliotheken in verschiedenen Programmiersprachen wie Java, Go, Python, JavaScript, PHP und Ruby. Einige Datenanalyse-Frameworks, z. B. pandas, bieten Plug-ins, die direkt mit BigQuery interagieren. Einige praktische Beispiele finden Sie in der Anleitung BigQuery-Daten in einem Jupyter-Notebook visualisieren.
Wenn Sie lieber Programme in einer Shell-Umgebung schreiben möchten, können Sie das bq-Befehlszeilentool verwenden.