Práticas recomendadas para configurar uma instância do Cloud SQL para MySQL
É possível implantar o MySQL manualmente na sua própria máquina física ou até mesmo em uma máquina virtual e gerenciá-lo automaticamente. No entanto, uma opção cada vez mais conhecida é usar uma oferta gerenciada de um provedor de serviços de nuvem responsável pelos vários aspectos operacionais do gerenciamento do MySQL.
Artigos relacionados
Práticas recomendadas
O Cloud SQL para MySQL é um serviço de banco de dados totalmente gerenciado que ajuda a configurar, manter, gerenciar e administrar seus bancos de dados relacionais do MySQL no Google Cloud. Quando estiver tudo pronto para criar uma instância do Cloud SQL para MySQL, você terá algumas opções, incluindo o console da IU, a CLI gcloud, o Terraform e uma API REST. Você pode acompanhar nossa documentação para ver detalhes sobre cada um desses caminhos, mas, para os fins deste artigo, usaremos a IU para ilustrar à medida que mostramos várias práticas recomendadas para configurar uma instância.
Informações da instância
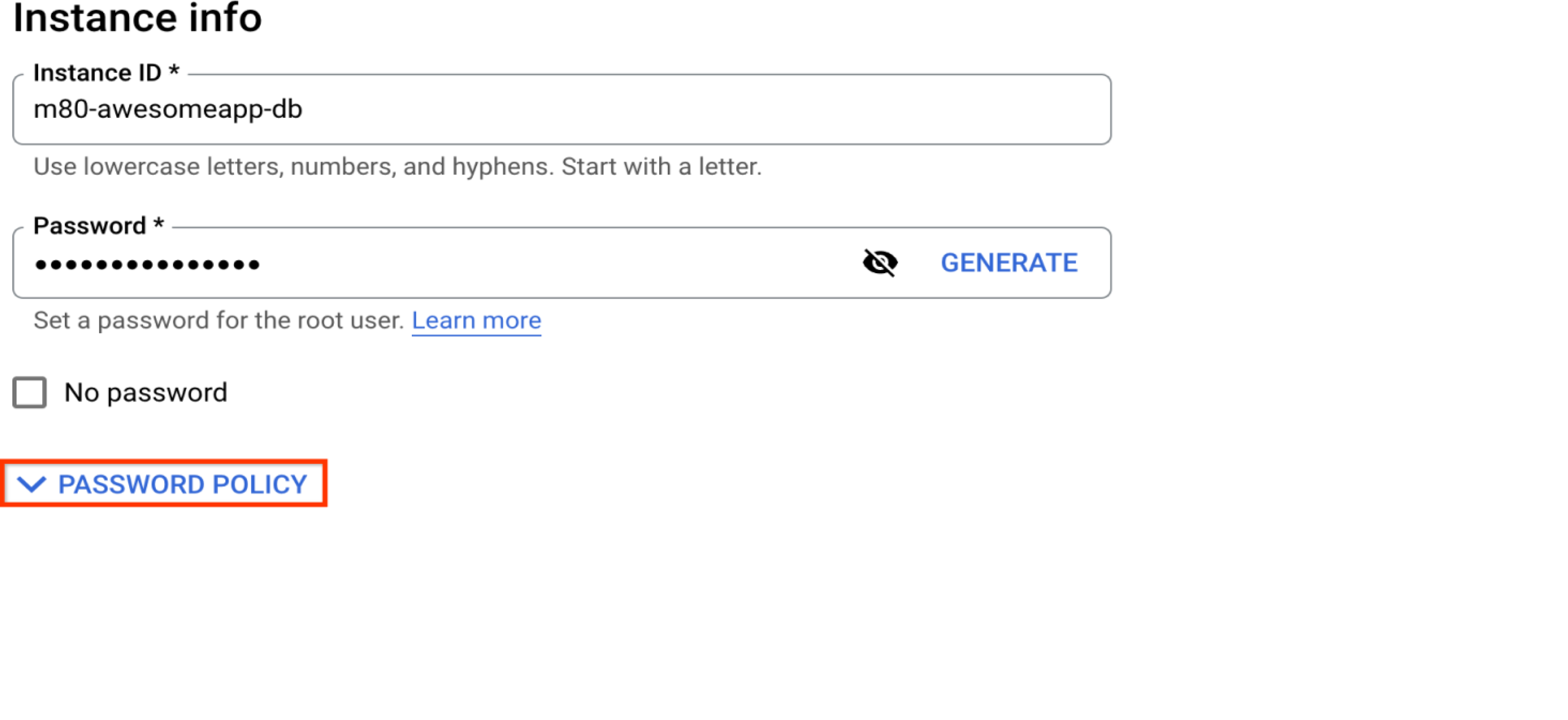
Escolha uma senha forte
Esta é a senha do usuário padrão do banco de dados “root”@”%" que será criado com a instância. Se você pretende manter o usuário raiz como usuário administrador, escolha uma senha forte aqui. É uma boa ideia usar um usuário administrador não tão comum em vez de "raiz" por questões de segurança. Consulte a seção "Gerenciar usuários do banco de dados".
Criar uma política de senhas no nível da instância
O recurso de política de senha permite maior segurança do banco de dados. Ele permite configurar políticas sobre tamanho, complexidade, validade e reutilização restrita da senha. Consulte Como aumentar a proteção de uma instância do MySQL para mais detalhes.
Versão do banco de dados
Use o 8.0 para um melhor desempenho
O Cloud SQL MySQL é compatível com várias versões secundárias da versão 8.0, sendo a v8.0.26 o padrão atual. Os testes de comparativo de mercado em vários tipos de máquina mostram uma capacidade de consulta melhor com a versão padrão 8.0 do que as versões 5.7 e 5.6.
Não coloque sua instância de produção na versão mais recente do GA
Apesar de todos os esforços de teste da Oracle e do Cloud SQL, as versões de atualização do MySQL não são totalmente verificadas com cenários complexos do mundo real. Portanto, recomendamos manter as instâncias de produção em uma versão estável e usar as instâncias de desenvolvimento e preparo para testar os upgrades de versão secundária mais recentes no Cloud SQL para MySQL.
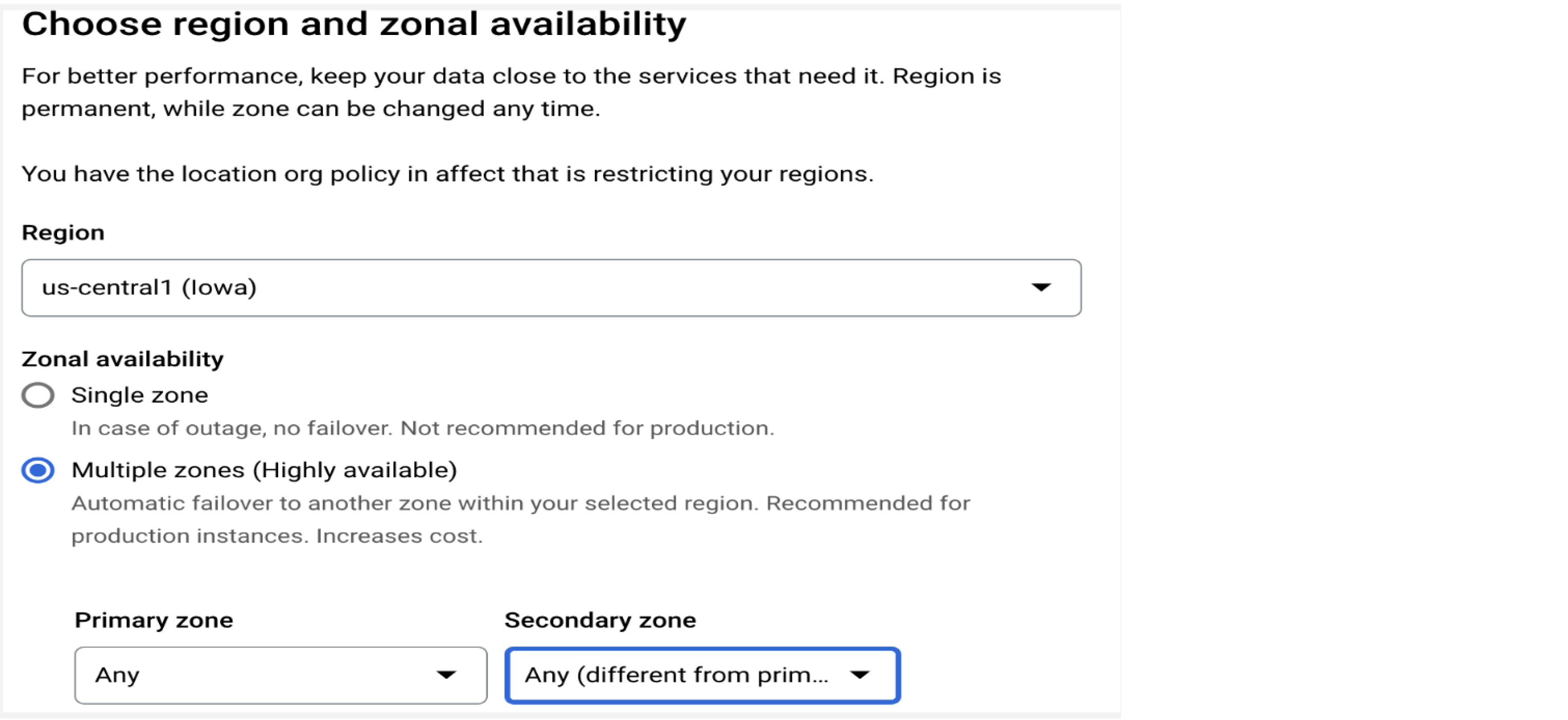
Alta disponibilidade
Configure várias zonas para sua instância de produção
O Cloud SQL para MySQL oferece disponibilidade regional por meio de failover automático para uma segunda zona como uma solução de alta disponibilidade. Para ter melhor disponibilidade, configure a opção de várias zonas para instâncias de produção para que você tenha backups diários e recuperação pontual automaticamente (consulte a seção "Programação de backup" para mais informações).
Tipo de máquina
Avalie o uso atual de CPU/memória para tomar decisões informadas para a migração
Ao migrar uma instância atual para o Cloud SQL, sua carga de trabalho atual pode ajudar a escolher o tamanho adequado da VM.
- CPU: qual é o uso da CPU em condições normais de carga de trabalho? E a carga de trabalho de pico? A instância está vinculada à CPU ou à E/S? Se a porcentagem da CPU do usuário e/ou do sistema for relativamente alta, essa é uma indicação de uma carga de trabalho vinculada à CPU. Se a porcentagem de E/S for relativamente alta, isso indica uma carga de trabalho vinculada à E/S.
- Memória: da mesma forma, qual é o uso normal da memória para a instância e qual é o uso máximo?
Como referência, uma vCPU no Cloud SQL para MySQL pode suportar até 6,5 GB de memória.
Planeje de 20% a 50% de espaço extra para CPU e memória
Mesmo em uma instância geralmente estável, planeje pelo menos 20% de espaço extra para a CPU e a memória absorver picos não planejados. Isso é ainda mais importante para uma empresa em crescimento. Considere um espaço extra de 50%.
O Cloud SQL facilita o upgrade do seu tipo de máquina. Porém, há inatividade associada a um upgrade.
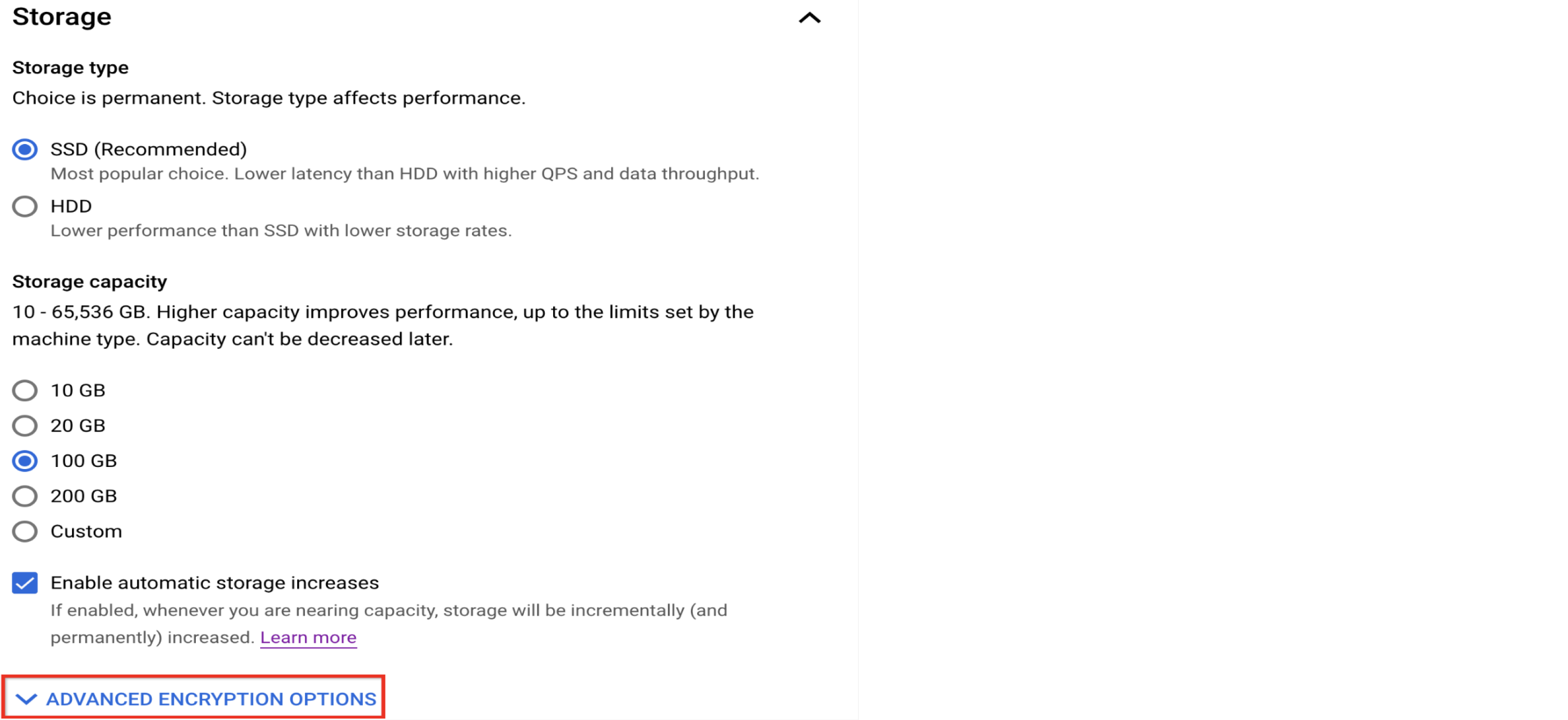
Personalizar o armazenamento
Use SSD para melhorar o desempenho do banco de dados
O Cloud SQL para MySQL oferece HDD como opção de armazenamento econômica, mas se você precisa de um banco de dados de alto desempenho, use a opção SSD. Veja uma comparação do desempenho de E/S.
Planeje um equilíbrio entre desempenho e custo quando se trata da capacidade de armazenamento
As IOPS e a capacidade do disco estão relacionadas ao tamanho do disco permanente. Uma capacidade maior fornece mais IOPS e capacidade de processamento dentro do limite da instância.
No caso de SSD, as configurações regionais e zonais vão afetar o desempenho. Consulte os dados de desempenho do SSD regional e zonal para mais detalhes. Se você selecionou a disponibilidade de várias zonas, consulte os dados de desempenho do SSD regional. Em resumo, as IOPS de leitura e gravação são de 30 GB por GB, e a capacidade de processamento é de 0,48 MB por GB. Com o SSD regional, os dados de desempenho são semelhantes, exceto que a IOPS de gravação por instância e a capacidade de gravação são menores.
O tamanho máximo de armazenamento suportado é de 64 TB em uma instância do Cloud SQL.
Ative o aumento automático de armazenamento e monitore o crescimento do disco
O Cloud SQL tem um recurso automático de aumento de armazenamento para evitar que instâncias fiquem sem espaço em disco (OOD). Quando o recurso está ativado, o armazenamento é verificado a cada 30 segundos, e a capacidade de armazenamento incremental é adicionada quando necessário.
Embora esse recurso seja protegido contra OOD, a maior capacidade é permanente. Não é possível reduzir o tamanho da instância mais tarde. Configure alertas no tamanho do disco para gerenciar e planejar a capacidade de armazenamento.
Conheça as opções de criptografia
Por padrão, o Cloud SQL criptografa os dados em repouso. No entanto, se for melhor para você, será possível usar uma chave de criptografia gerenciada pelo cliente (CMEK, na sigla em inglês) em vez da chave padrão gerenciada pelo Google e de propriedade dele.
Configurar conexões
Avalie a compensação entre o IP privado e o IP público
Os IPs particulares e públicos se referem aos tipos de endereços usados pelos dispositivos em uma rede. O IP privado oferece melhor segurança de rede e menor latência de rede em comparação com o IP público. No entanto, o IP privado exige outras configurações da API e do IAM, e às vezes o IP público é exigido. Se você sabe que precisa usar o IP público, mas quer melhorar a segurança, é possível exigir uma rede autorizada ou usar o proxy do Cloud SQL Auth.
Considere o proxy do Cloud SQL Auth para conexões seguras
O proxy do Cloud SQL Auth fornece acesso seguro à instância do Cloud SQL, em vez de configurar SSL ou redes autorizadas. O aplicativo se comunica com o cliente proxy Auth, que é executado no ambiente local e usa um túnel seguro para se comunicar com o servidor proxy na instância do Cloud SQL.
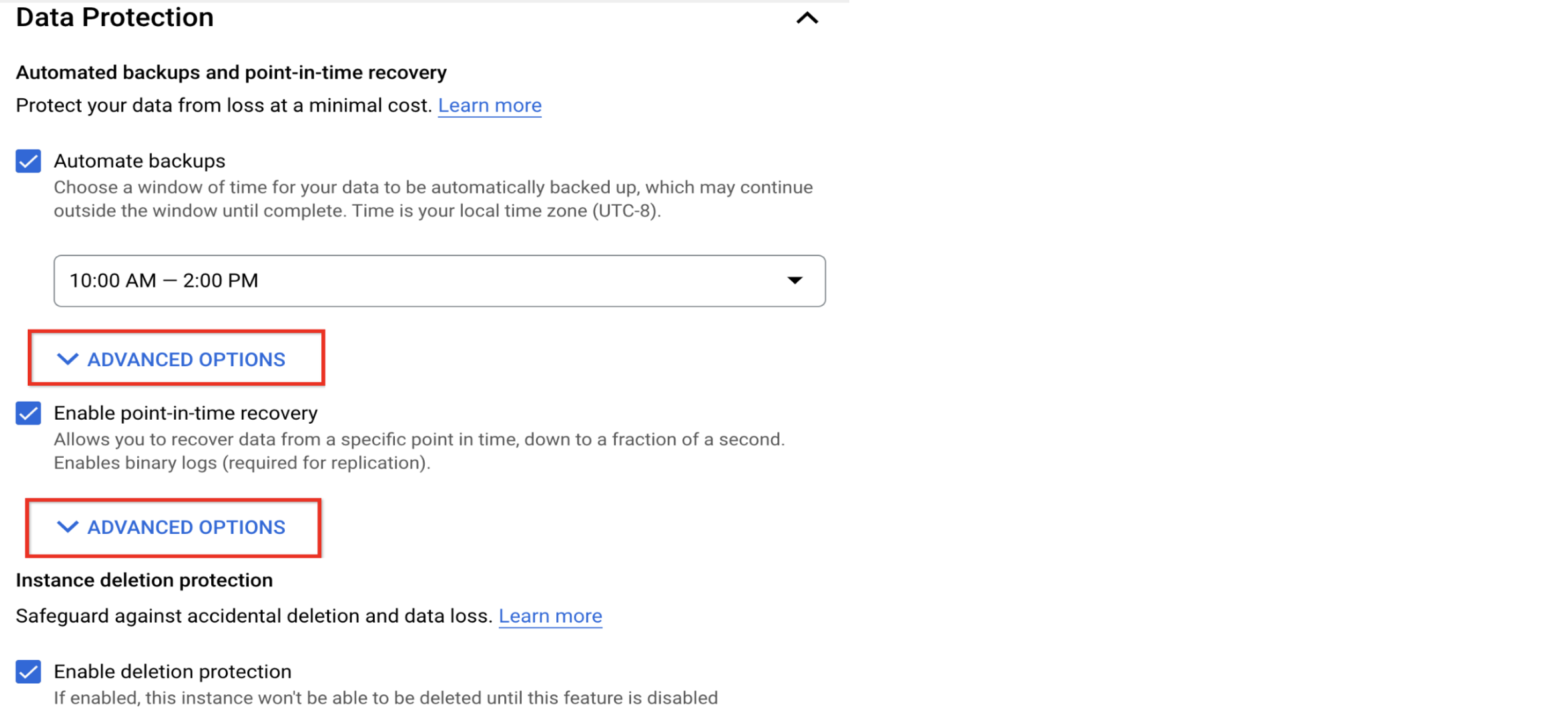
Configurar a programação e a retenção de backup
Ative backups e recuperação pontual e revise sua política de retenção
Backups regulares e recuperação de dados verificáveis são essenciais para um gerenciamento de banco de dados íntegro. Essas práticas são valiosas em situações como corrupção de dados ou operações de dados não intencionais, e nenhuma delas pode ser mitigada pela alta disponibilidade.
O Cloud SQL oferece backups automatizados, verificação de backup e recuperação pontual (PITR, na sigla em inglês). Eles são ativados por padrão e são necessários em instâncias com várias zonas. Os backups automáticos são feitos diariamente, e a política de retenção padrão é sete cópias de backups e sete dias de registros binários (necessários para PITR). É possível ajustar a política de retenção na seção "Opções avançadas".
Configurar flags de bancos de dados
As sinalizações do banco de dados são configurações do servidor que vão para o arquivo my.cnf. Há uma lista de sinalizações de banco de dados configuráveis, e determinadas sinalizações gerenciadas não são configuráveis. Recomendamos revisar as sinalizações do banco de dados e configurá-las com o valor adequado no momento da criação da instância. Como algumas sinalizações do banco de dados não são dinâmicas, isso significa que alterá-las acionaria uma reinicialização da instância.
Revise caractere_set_server
Nas instâncias do Cloud SQL para MySQL, o character_set_server padrão é utf8 na v5.6 e v5.7 e o utf8mb4 na v8.0. O character_set_server define character_set_server, character_set_server, character_set_server e character_set_server como o mesmo valor. Para character_set_system, o padrão é utf8mb3 na v8.0.
Se você estiver migrando uma instância e a configuração atual usar um conjunto de caracteres diferente (por exemplo, latin1), defina character_set_server explicitamente na nova instância.
Revise o time_zone
O fuso horário é padronizado para system_time_zone, que é UTC. Se você quiser usar um time_zone diferente, defina-o via default_time_zone. Essa sinalização tem dois formatos: deslocamento de fuso horário, por exemplo, +08:00, e nomes de fuso horário, como América/Los_Angeles. Quando o fuso horário é definido por nome de fuso horário, ele é ajustado automaticamente de acordo com o horário de verão (se relevante). A sinalização default_time_zone não é dinâmica e requer que a instância do banco de dados seja reiniciada para fazer uma alteração.
Ative o registro de consulta lenta
Por padrão, o slow_query_log é definido como DESATIVADO. É altamente recomendável ativar o registro de consulta lenta e definir o slow_query_log como um limite que faça sentido para o aplicativo. O registro de consulta lenta ajuda a capturar consultas de longa duração para análise e otimização. Essas informações não só ajudam com consultas individuais, mas também a capacidade geral do servidor e a análise retrospectiva de cargas de trabalho inesperadas.
Revise innodb_buffer_pool_size
Essa é a configuração mais eficaz para o desempenho do InnoDB. Quanto mais dados puderem ser armazenados em buffer na memória, melhor será o desempenho do servidor. Ao mesmo tempo, é preciso ter memórias suficientes reservadas para buffers globais e buffers dinâmicos por linha de execução.
No Cloud SQL, os valores padrão, mínimo e máximo permitidos da sinalização innodb_buffer_pool_size dependem da memória da instância, conforme descrito na documentação
Um bom innodb_buffer_pool_size não precisa conter todos os dados, apenas os dados acessados com frequência. As variáveis de status que refletem a eficiência do pool de buffer são Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests. Innodb_buffer_pool_read_requests é o número de solicitações de leitura lógicas, e Innodb_buffer_pool_read_requests é o número de leituras lógicas que não são atendidas pelo pool de buffer e precisavam ser lidas no disco. No caso ideal em que os dados estão totalmente no pool de buffer, a proporção de Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests seria próxima de zero. O monitoramento dessas variáveis teria uma ideia da eficiência do pool de buffers do InnoDB. Se innodb_buffer_pool_size estiver no valor máximo permitido, e a eficiência do pool de buffer não for boa e o aplicativo tiver problemas de desempenho da consulta, faça upgrade da instância para ter uma memória maior.
Essa variável se torna dinâmica no MySQL v5.7 e v8.0, enquanto que na v5.6, a alteração requer uma reinicialização da instância.
Revise innodb_log_file_size
Antes da versão 8.0.30, innodb_log_file_size e innodb_log_file_size não eram dinâmicos e para alterar innodb_log_file_size era necessário um encerramento simples. Na versão 8.0.30, innodb_redo_log_capacity foi introduzido para substituir innodb_redo_log_capacity e innodb_redo_log_capacity.
As instâncias do Cloud SQL para MySQL são configuradas com innodb_log_file_size=512 MB, innodb_log_file_size=2 (ou innodb_log_file_size=1 GB). Isso permite que o InnoDB mantenha mais alterações no pool de buffers sem sincronizar com o disco, o que melhora o desempenho do servidor. A desvantagem de grandes arquivos de registros "redo" é o aumento do tempo de recuperação de falhas. Dependendo dos requisitos de alta disponibilidade e da configuração da instância, essa decisão demanda um equilíbrio entre desempenho e disponibilidade.
Geralmente, recomendamos ter arquivos de registro "redo" grandes o suficiente para armazenar uma hora de atividades de gravação. Uma maneira de avaliar isso é observar Innodb_os_log_written ao longo de um dia e depois garantir que Innodb_os_log_written * Innodb_os_log_written é grande o suficiente para a hora de pico observada.
Revise innodb_log_buffer_size
No MySQL v5.6 e v5.7, innodb_log_buffer_size não é dinâmico, e alterá-lo requer que uma instância seja reiniciada. Portanto, é melhor defini-lo na inicialização.
Quando innodb_log_buffer_size for grande o suficiente para conter a transação inteira, o disco não será mais limpo durante a execução da transação. Por padrão, innodb_log_buffer_size é definido como 16 MB, o que geralmente é suficiente. Mas, para ter uma ideia se uma transação grande pode precisar de um buffer maior, monitore a variável de status Innodb_log_waits quando emitir uma transação grande. Se innodb_log_buffer_size for muito pequeno e precisar aguardar uma limpeza, innodb_log_buffer_size aumentará em um.
Ajuste as variáveis dinâmicas à medida que avança
Algumas sinalizações do banco de dados relacionadas ao desempenho são dinâmicas, como table_open_cache, thread_cache_size. É bom ter o tamanho certo no início, mas é recomendável estabelecer medições e ajustar conforme necessário.
O table_open_cache indica o número de tabelas abertas. Um cache suficiente ajuda a reduzir o tempo de abertura da tabela e, portanto, melhora o desempenho da consulta. A variável de status Opened_tables mostra o número de tabelas que foram abertas. Se Opened_tables continuar crescendo, aumente Opened_tables.
O thread_cache_size é usado para o armazenamento em cache de linhas de execução para reutilização após a desconexão dos clientes. Se uma instância esperar muitas conexões novas simultâneas, defina um tamanho maior. A proporção das variáveis de status Threads_created e Connections mostra a eficiência do cache da linha de execução. Uma proporção baixa é melhor.
Use uma abordagem conservadora com as sinalizações de memória por linha de execução
Há buffers de memória por linha de execução que afetam o desempenho da consulta, por exemplo, tmp_table_size, tmp_table_size, tmp_table_size, tmp_table_size e mais. Essas variáveis têm escopo global e de sessão. O escopo global define o valor por linha de execução de todas as novas conexões, enquanto o escopo de sessão é eficaz para consultas subsequentes na sessão atual. Uma memória maior para configurações como essas melhora o desempenho da consulta. No entanto, por serem dinâmicas e alocarem uma ou mais por linha de execução, elas podem levar a cenários de falta de memória (OOM, na sigla em inglês).
É melhor usar números moderados para valores globais e reservar números maiores para sessões específicas a fim de alcançar um melhor desempenho de maneira controlada.
Considere performance_schema
O performance_schema é desativado por padrão antes do MySQL v8.0.26 e requer uma reinicialização para ativá-lo. O performance_schema permite várias instrumentações e fornece um conjunto completo de dados para analisar as operações do servidor, mas tem custos de desempenho e memória. As instrumentações padrão rendem cerca de 5% de queda de desempenho, e esse número cresce conforme mais instrumentos são adicionados. Faça comparações de instrumentações com sua carga de trabalho, já que o consumo de memória pode aumentar para 1 GB ou mais. Esse consumo de memória é observado na tabela memory_summary_global_by_event_name.
Gerenciar usuários de banco de dados
Depois de criar a instância do Cloud SQL, há um usuário de banco de dados disponível, 'root'@'%'. Você provavelmente precisará criar outros usuários do banco de dados.
Restrinja o acesso do usuário às operações necessárias
Sempre restrinja o acesso do usuário às necessidades mínimas.
Ao criar um usuário com a CLI do MySQL, você precisa conceder privilégios explicitamente.
Ao criar um usuário no console do Cloud, ele terá os mesmos privilégios que o usuário "root'@'%". No MySQL v5.6 e v5.7, os privilégios padrão incluem todos os privilégios com opção de concessão, exceto os privilégios SUPER e FILE. Na versão 8.0, o usuário tem privilégios dinâmicos e, enquanto os privilégios SUPER e FILE ainda estão restritos, mais funções de administrador estão disponíveis para os usuários (por exemplo, APPLICATION_PASSWORD_ADMIN, APPLICATION_PASSWORD_ADMIN, APPLICATION_PASSWORD_ADMIN, APPLICATION_PASSWORD_ADMIN e APPLICATION_PASSWORD_ADMIN). Será necessário revogar os privilégios desnecessários pela CLI MySQL. Nas instâncias v8.0, a variável partial_revokes está ativada.
Considere substituir 'root'@'%' por um usuário administrador específico
O usuário "root'@'%' é o superusuário padrão e mais popular e, portanto, é frequentemente alvo de hackers. Recomendamos criar seus próprios usuários administradores com o mesmo conjunto de privilégios que o usuário "root'@'%" e substituí-lo por uma segurança melhor.
Configurar o monitoramento
É muito importante monitorar e acompanhar vários aspectos das operações do banco de dados e dos recursos do sistema. Ele permite revisar e analisar a integridade operacional da instância ao longo do tempo, o que também pode ajudar no planejamento de recursos.
- A página de visão geral do console do Cloud vem com uma lista de principais métricas.
- O Cloud Monitoring oferece métricas adicionais. É possível criar um painel com as métricas selecionadas para suas instâncias do banco de dados. No console do Cloud, no menu de navegação no canto superior esquerdo, escolha OPERAÇÕES --> Monitoramento para acessar o Cloud Monitoring.
- Use o Query Insights no Cloud SQL para análise de desempenho da consulta. A seção de visão geral mostra a carga da CPU dividida por banco de dados, usuário ou endereço do cliente. O uso da CPU também é detalhado para mostrar a espera de E/S e de espera de bloqueio. Também é listado as principais consultas pelo resumo da consulta. Para cada resumo de consulta, é possível ver o tempo médio de execução, o número de consultas e a média de linhas verificadas e retornadas. Essas métricas são muito úteis para identificar pontos de acesso e consultas a serem otimizados.
- Também é possível complementar o conteúdo acima com ferramentas de monitoramento locais e/ou ferramentas de terceiros. O objetivo principal é entender suas operações de banco de dados que podem influenciar a otimização e a solução de problemas no servidor e nas consultas.
Configurar alerta
Os alertas adequados são essenciais para a integridade do servidor. Eles ajudam a evitar interrupções do serviço, como falta de memória (OOM, na sigla em inglês) ou interrupções do sistema devido à saturação da CPU.
Se você usa o Cloud Monitoring, é possível criar alertas baseados em métricas. Para detalhes, consulte a documentação.
Se você usa outras ferramentas de monitoramento, configure os alertas.
Configure réplicas
Para escalonar as leituras, considere adicionar réplicas de leitura. É possível usar o HAProxy, ProxySQL ou outro balanceador de carga para distribuir leituras entre várias réplicas de leitura.
O Cloud SQL também aceita replicação encadeada, que você pode aprender sobre em Réplicas em cascata.
As réplicas de leitura são criadas com a mesma versão do MySQL que a instância principal. Após a criação, é possível fazer upgrade da réplica para a principal.
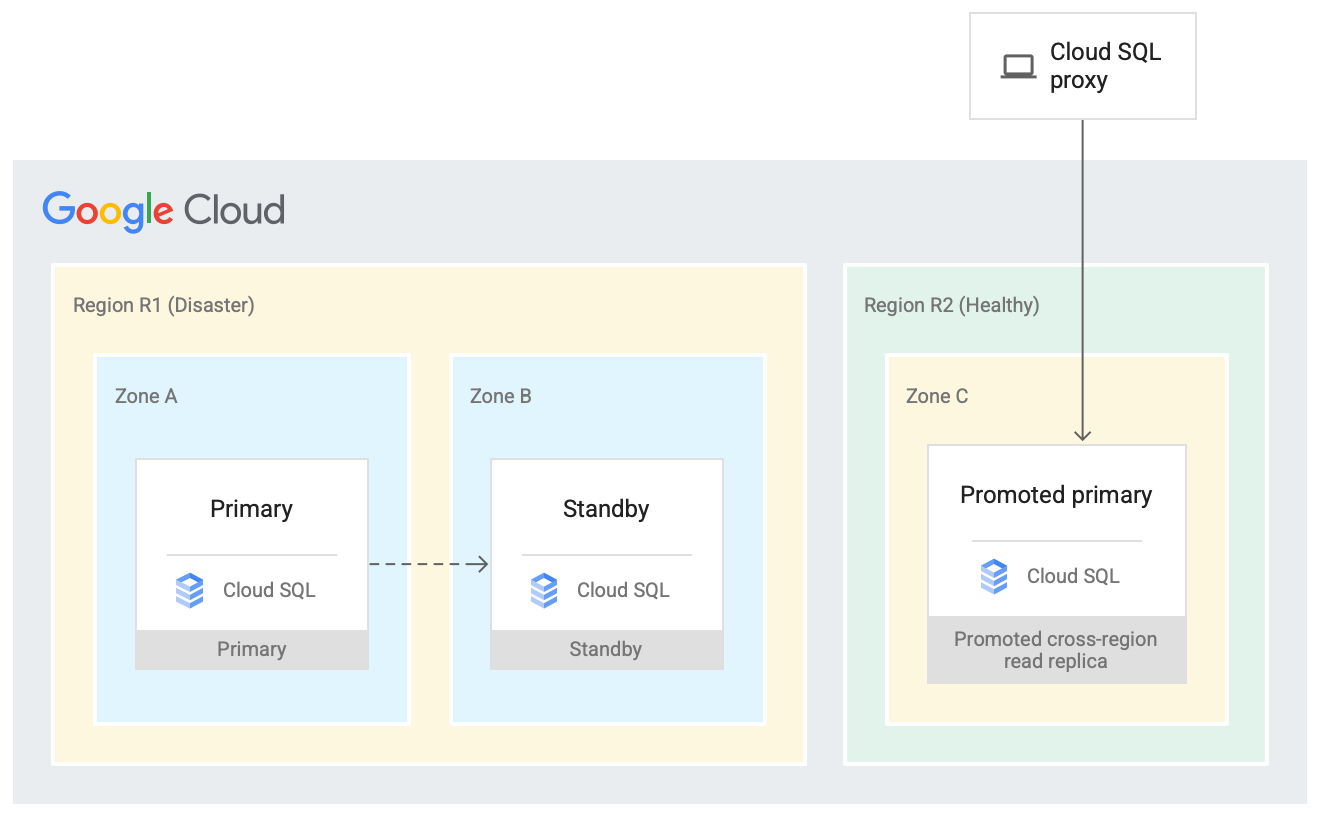
Planejar a recuperação de desastres
A solução de alta disponibilidade oferece redundância de dados em uma zona secundária na mesma região. Em um desastre, uma região pode ficar indisponível. As réplicas de leitura entre regiões são um recurso forte em um plano de recuperação de desastres, porque podem ser promovidas a uma instância principal quando necessário. Consulte a documentação para mais informações.
Produtos e serviços relacionados
O Google Cloud oferece um banco de dados MySQL gerenciado para atender às suas necessidades de negócios, desde a desativação de um data center local até a execução de aplicativos SaaS e a migração dos principais sistemas de negócios.
Vá além
Comece a criar no Google Cloud com US$ 300 em créditos e mais de 20 produtos do programa Sempre gratuito.
Precisa de ajuda para começar?
Entre em contato com a equipe de vendasTrabalhe com um parceiro confiável
Encontre um parceiroContinue navegando
Ver todos os produtos











